我國GDP影響因素計量分析
2021-10-12 07:02:07趙浩然
中國集體經濟 2021年30期
關鍵詞:影響因素
趙浩然
摘要:文章使用了自2000年到2018年共19年的統計數據進行計量分析,以國內生產總值作為被解釋變量,全國居民人均消費支出、全社會固定資產投資、政府預算支出、出口貿易總額以及就業人口總數作為解釋變量建立多元線性回歸模型,并使用stata軟件進行參數估計。最后文章對回歸模型的經濟意義進行了解釋,同時依據該模型提出促進GDP進一步提高的政策建議。
關鍵詞:國內生產總值;多元回歸;影響因素
一、引言
國內生產總值(GDP),英文全稱是Gross Domestic Product,是指在一定時期內,一個國家或地區運用其生產要素所生產出的最終產品以及勞動的價值。通常國內生產總值可以較好地衡量一個國家的生產、消費能力,是評價國家經濟實力和綜合國力的重要指標。自改革開放之后,我國GDP一直保持較高增速,2010年成為全球第二,在此過程中,國家財富不斷累積,經濟實現顯著增長。2013年習近平總書記在中央經濟工作會議上首次指出中國經濟進入“新常態”發展階段,我國的經濟增長側重點從單一追求GDP數量的高增長轉為追求GDP數量與質量雙增長。
同時,由于經濟增長放緩以及工作、房價等壓力使得近幾年來我國的生育率不斷走低,新生人口不斷減少,這也加劇了老齡化進程。一般經驗來看,老齡化程度對經濟增長有消極意義,因為老齡化水平直接影響了就業人口數量,也就影響了國內總產出。而中國發展基金會的預測報告顯示:中國將在2022年進入老齡化社會。
綜上所述,探究人口等因素對GDP的影響程度和影響原因是十分有必要的,有助于我們對GDP的調控政策有據可依。
二、模型建立
(一)變量選取
我國經濟情況復雜,GDP影響因素眾多而無法一一列舉,出于研究所需、數據獲取等多因素考慮,論文選取了我國GDP(億元)作為被解釋變量,選擇了全國居民人均消費支出(元)、全社會固定資產投資(億元)、政府預算支出(億元)、出口貿易總額(億元)和就業人口總數(萬人)作為解釋變量。
國內生產總值的計算法包括三種:收入法、支出法和生產法。其中支出法是現在國際進行GDP計算的常用方法。這種方法認為國內生產總值由四個部門的支出組成:消費、投資、政府支出和凈出口額。
參考GDP的支出計算法,論文先選取了四個解釋變量:全國居民人均消費支出、全社會固定資產投資、政府預算支出以及出口貿易總額。全國居民人均消費支出是當年的總消費支出/全國居民總人數,該指標反映了居民消費水平的高低,而消費水平的高低直接關系到GDP的數量,對應了支出計算法中的消費項。投資主要包括固定資產投資和存貨投資,隨著近幾年固定資產價格的上升,可以使用固定資產投資額進行投資的近似替代。全社會固定資產投資是建設和購買固定資產活動對應的貨幣量,該指標反映了社會運行中用于投資的生產總值,因此本解釋變量對應了支出法中的投資項。政府預算支出是指國家或地區的職能部門為了完成公共職能,為所購買的商品和勞務進行支付的貨幣量的預算。在歷史上的多次經濟危機中,政府支出往往以“以工代賑”的形式流入社會運行體系,促進國內生產總值的增長,幫助國家走出經濟危機。因此,政府支出對國內生產總值同樣有著不可忽視的影響,政府預算支出對應了支出法中的政府支出一項。過去的二十多年,我國依靠出口導向型經濟實現了經濟的迅速增長,甚至被稱為“世界工廠”,中國依靠著貿易順差積攢了大量外匯。而出口總額就是衡量國家生產的產品和服務中流入外國的部分,參考中國過去二十年的發展,其對國內生產總值也有較大影響。凈出口額度等于出口總額減去進口總額,因此二者之間存在較大的相關性,出口總額在一定水平上衡量了凈出口額度,故本解釋變量對應了支出法中的凈出口額度。
最后,為了探究老齡化對GDP的影響,本文選取了就業人口總數作為老齡化評價的標準。隨著老齡化程度的加深,即使進行延遲退休,由于客觀因素限制,只能延緩就業人口的下降。而就業人口的下降盡管減少了結構性失業,但同時也會減少消費,總體會對GDP造成消極影響。因此論文選取就業人口數量作為解釋變量,探究其對GDP的影響。
(二)數據選取
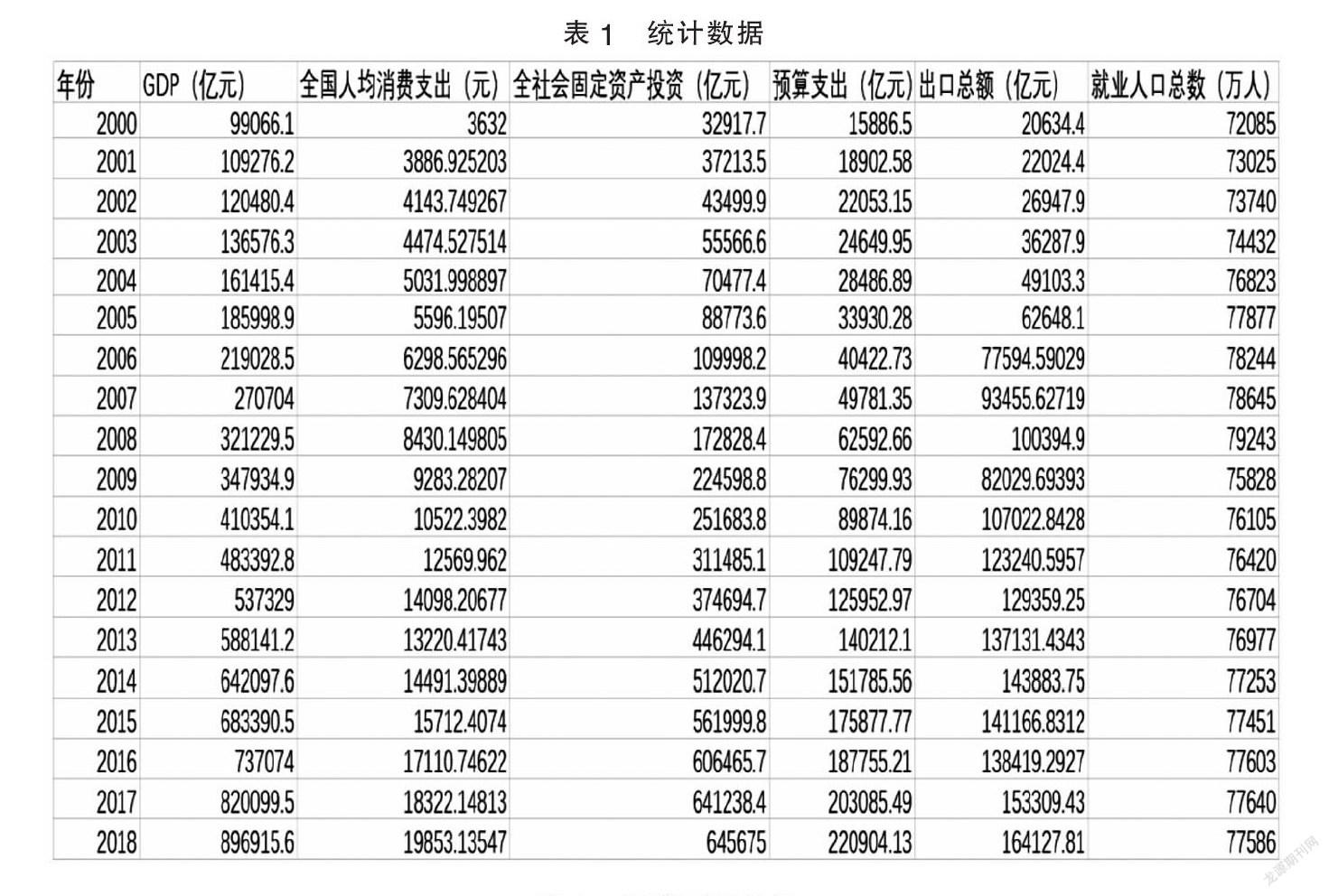
文章選取2000~2018年的《中國統計年鑒》中對應數據,由于2000年之前部分數據只進行五年一次的離散統計,故選取時間截止到該年。數據如表1所示:
(三)模型形式選擇
從表1數據可發現變量之間存在量級上的差距,為提高模型的可靠程度,選取對數模型如下:
lnY=β0+λ1lnX1+λ2lnX2+λ3lnX3+λ4lnX4+λ5lnX5+u
其中Y是國內生產總值,β0為常數項,X1為全國人均消費支出,X2為全社會固定資產投資,X3為政府預算支出,X4為出口總額,X5為就業人口總數,u為服從正態分布N(0,σ2)的隨機擾動項。
(四)模型初步回歸
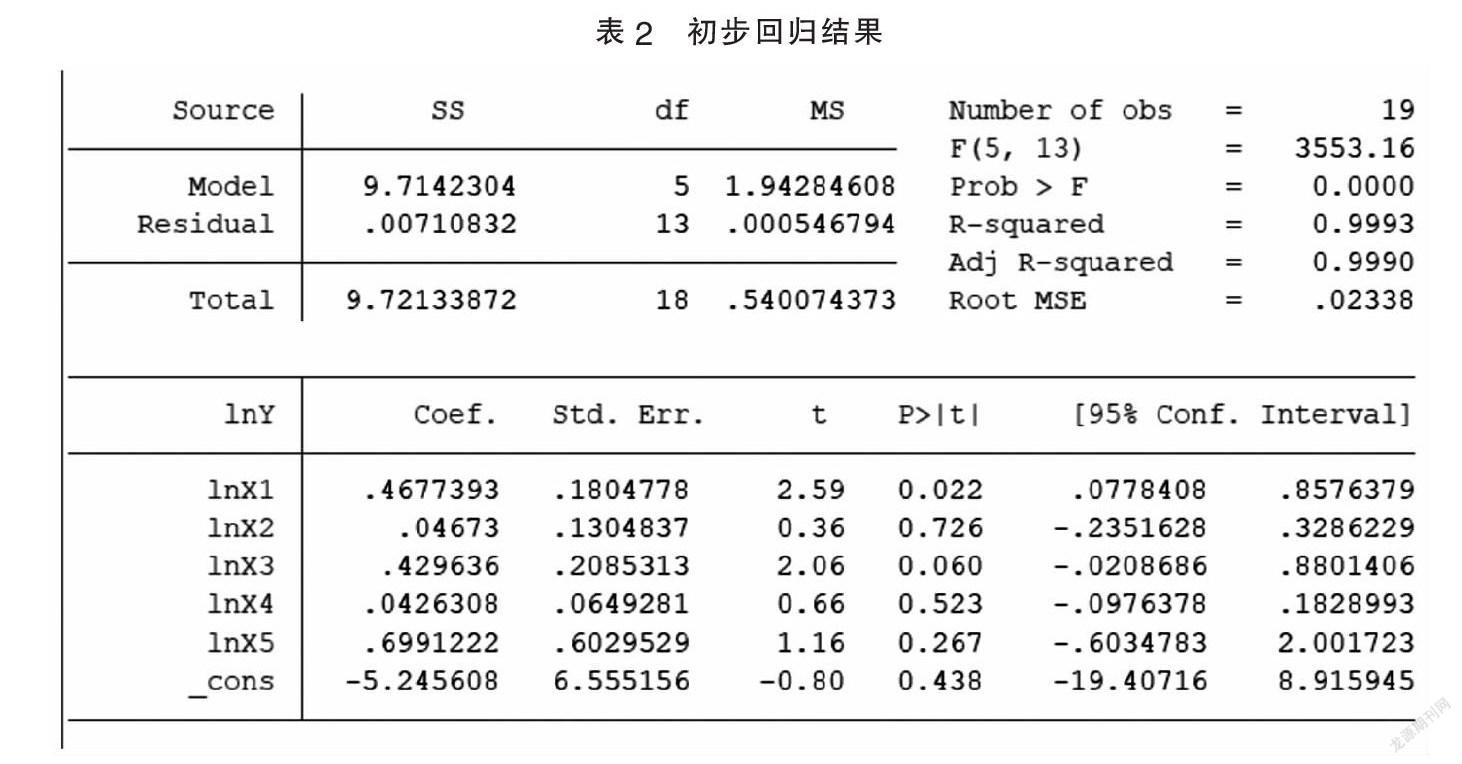
使用stata軟件對模型進行回歸分析,首先將數據進行對數化,處理減小量級差距,再按照模型進行最小二乘法回歸,初步回歸的結果如表2:
(五)模型的顯著性檢驗
設置置信水平α為0.05,觀察模型回歸的各項指標。模型的各項系數均大于0,表明選取的經濟指標均對國內生產總值有促進作用。對模型進行F檢驗,F檢驗的原假設為估計參數均為零。模型的F檢驗P值=0.00<α,說明模型通過了F檢驗,估計的系數不均為零。也可以看到模型調整后可決系數為0.9990,說明GDP有約0.99%可由解釋變量解釋,同樣證明了模型有較好的擬合能力。
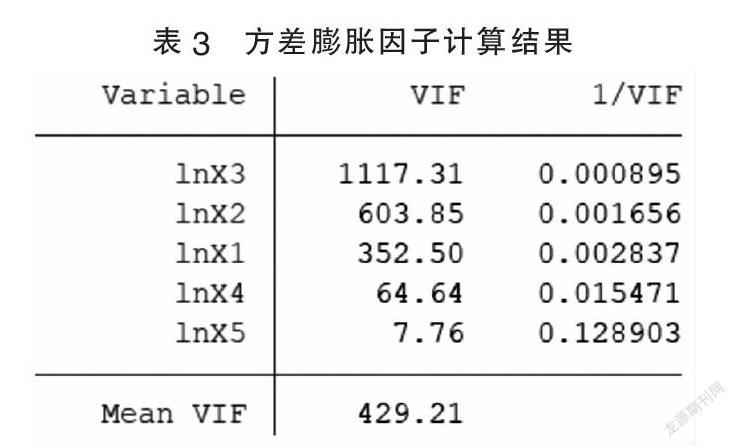
再對各個參數分別進行t檢驗,t檢驗的原假設是參數值為零。通過表2可知,在估計出的參數中,只有λ1的t檢驗P值=0.022<α,通過了t檢驗。說明大多數參數不顯著。再觀察參數的置信區間,發現同樣只有λ1的置信區間無零點,說明只有λ1顯著。因此要考慮模型的多重共線性問題。
猜你喜歡
現代經濟信息(2016年19期)2016-10-20 18:46:44
現代經濟信息(2016年19期)2016-10-20 18:12:28
現代經濟信息(2016年19期)2016-10-20 16:20:30
中國科技博覽(2016年19期)2016-10-19 13:33:22
中國科技博覽(2016年18期)2016-10-19 10:49:54
中國科技博覽(2016年18期)2016-10-19 08:16:45
中國科技博覽(2016年18期)2016-10-19 06:39:44
中國市場(2016年36期)2016-10-19 03:54:01
中國市場(2016年35期)2016-10-19 02:30:10
商(2016年27期)2016-10-17 07:09:07
