關聯規則挖掘在高校網絡教學平臺中的應用研究
2019-03-14 12:42:40葉根梅吳志霞
電腦知識與技術 2019年1期
關鍵詞:網絡教學
葉根梅 吳志霞

摘要:針對目前大多高校網絡教學平臺教學資源呈現單一、不能根據學習者的學習軌跡進行內容推薦的弊端,研究關聯規則和Apriori算法,以及Apriori算法在網絡教學平臺中的應用。運用關聯規則挖掘獲取學習內容相關的頁面集合,從而一定程度地優化網站結構,并對學習者進行個性化內容推薦服務,提高學習者的網絡平臺學習體驗。
關鍵詞:關聯規則 Apriori 網絡教學
中圖分類號: TP434? ? ?文獻標識碼:A? ? ? 文章編號:1009-3044(2019)01-0017-02
1 背景
隨著互聯網技術的發展,各大高校陸續構建自己的網絡教學平臺,以實現學習資源數字化、教學方式網絡化、學習方式多元化的網絡教學方式。但是,目前高校的網絡教學平臺普遍存在網絡資源呈現單一化特征,網站不能根據學習者的學習行為提供個性化的內容推薦服務。因此,在教學平臺中,加入基于關聯規則的個性化內容推薦對提升學生的學習體驗和效果很有意義。
2 關聯規則挖掘
關聯規則挖掘最早用來發現超市交易數據中商品之間的關聯[1],近幾年在網站和移動應用的個性化推薦系統中,如電子商務、新聞網站、社交等領域被廣泛應用。通過關聯規則挖掘可以發現事務之間的聯系,提升信息篩選的效率,對于決策者和用戶來說,具有現實的意義,因此,關聯規則挖掘也作為數據挖掘一個重要的課題和方法被廣泛研究和應用。
3 關聯規則在高校網絡教學平臺中的應用
3.1 網絡教學平臺的關聯規則挖掘功能模型
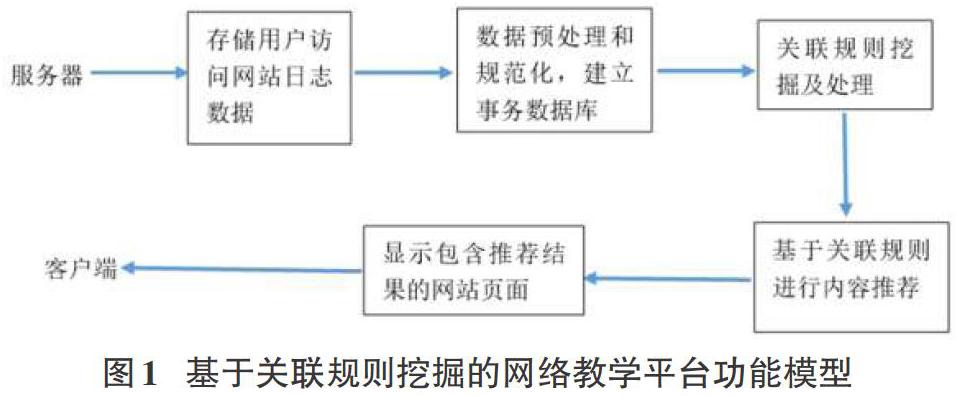
網絡教學平臺中要實現學習者因人而異、按需學習的內容自動推薦功能,運用關聯規則,可建立如下功能模型,如圖1所示。
參照《WEB挖掘技術在網絡教學中的應用研究》和精品課程論文。
在該模型中,服務器端記錄用戶訪問信息并存儲用戶日志數據,包括用戶在教學平臺中的訪問內容和行為,如頁面瀏覽內容和時間、訪問路徑、超鏈接的點擊行為等。對這些數據進行收集、預處理和規范化,構成事務集,再運用關聯規則挖掘技術,挖掘出有價值的網頁集合,從而明確學習者的學習興趣和需求,根據關聯規則結果進行個性化內容推薦,方便學習者快速發現自己需要的學習內容[2]。
3.2 關聯規則挖掘算法--Apriori算法
Apriori算法是關聯規則最成熟的算法,因其數據要求低、推導相對簡單,使其得到廣泛應用。
設I={i1,i2,…,im},是m個不同的項目的集合, 長度為m的項集I稱為m-項集,T={T1,T2,…Tn}是與任務相關的事務的集合,每個事務Ti都是項集I的一個子集。假定X,Y均為項集,均是T的非空子集,且X和Y的交集不為空,則表示X和Y是相關聯的項集,項集X在某一事務中出現,會導致Y以某一概率也會出現[3]。將蘊含表達式X=>Y稱作T中的關聯規則。關聯規則的強弱通過指標支持度和置信度來衡量。事務集T中項目集X出現的次數count(X)與事務集T中事務總數|T|的百分比,稱作項目集X的支持度support(X),可通過以下計算公式獲得:
support(X)=[count(X)|T|]*100%
相應地,關聯規則X=>Y的支持度support(X=>Y)的計算公式如下:
support(X=>Y)=[count(X?Y)|T|]*100%
事務集T中X、Y同時出現的次數與事務集T中項目集X出現的次數的百分比,稱作關聯規則X=>Y的置信度confidence(X=>Y),可通過以下計算公式獲得:
confidence(X=>Y)= [supportX?Y supportX]*100%
最小支持度minsup和最小置信度minconf是用戶設定的衡量支持度和置信度的一個閾值,如果關聯規則X=>Y的支持度support(X=>Y)和置信度confidence(X=>Y)大于等于用戶定義的最小支持度minsup和最小置信度minconf,則稱X=>Y為強關聯規則。關聯規則挖掘的目的就是找出強關聯規則。同時,對于項目集X,如果support(X)>= minsup,則X為頻繁項集。
3.3 運用Apriori算法挖掘關聯規則
運用Apriori算法實施數據挖掘主要分為兩步:
首先,找出事務數據庫中所有大于等于指定的最小支持度的頻繁項集,然后根據指定的最小置信度找出需要的關聯規則。
針對高校網絡教學課程,學生訪問網站不同頁面時,其訪問信息都將在網頁路徑中體現出來。 如用戶訪問http://localhost:8080/course/s20.php,然后又訪問http://localhost:8080/course/s23.php,并在這些頁面及其子頁面停留了一定的時間,表示用戶學習了頁面分別為s20.php和s23.php的兩門課程及其對應的知識點資源。將用戶在網站訪問期間的頁面路徑暫存在用戶會話文件中,當用戶離開網站時,將該信息作為用戶學習日志記錄表中的一條記錄保存起來。然后,對事務數據庫進行預處理,運用Apriori算法挖掘學生學習網絡課程的訪問日志,找出學生頻繁訪問的知識點頁面所在的網頁路徑,基于學生頻繁訪問的網頁路徑,找出頻繁項集,進而進行個性化內容推薦[4]。
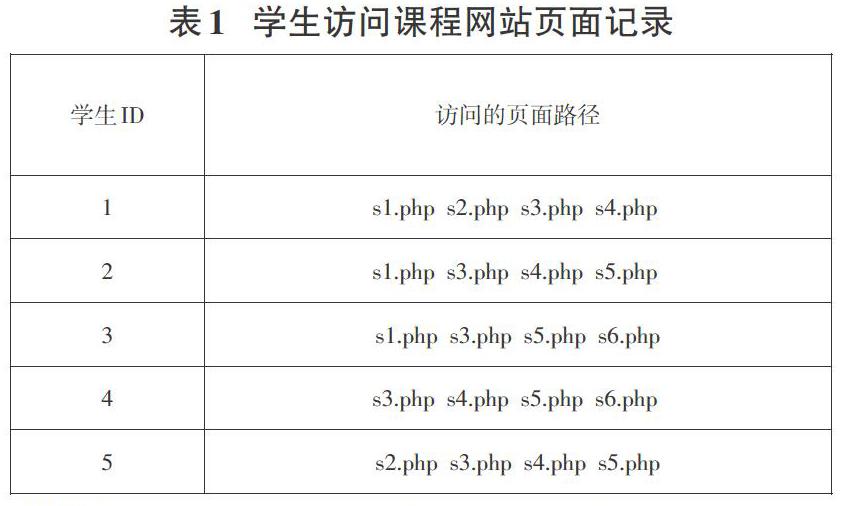
按照上述步驟,這里,抽取5個學生對網絡教學平臺課程訪問信息,表1記錄了其訪問網站的網頁路徑。
假設最小支持度minsup為3,最小置信度minconf為70%。Fk表示頻繁k-項集的集合,Ck表示產生FK項集的候選項集,算法的處理步驟如下:
對置信度進行計算:
confidence(s3=>s4)=4/5=80%
confidence(s3=>s5=4/5=80%
confidence(s4=>s5)=3/4=75%
由此可見,{s3 s4 s5}是學習者訪問頻率較高的一種網頁組合,因此可以通過建立超鏈接的方式對這些頁面進行關聯,或者將該關聯規則存儲到關聯規則表中,提供學習者的訪問效率,實現網絡教學平臺的個性化推薦功能。
4 結束語
在高校網絡教學平臺中引入關聯規則,優化網站課程結構,實現一定程度的教學內容的個性化推薦,提升學習者的學習體驗,對高校網絡教學平臺的建設具有非常現實的意義。
參考文獻:
[1] 王濤偉, 楊愛民. 加權關聯規則研究及其在個性化推薦系統中的應用[J]. 鄭州大學學報: 理學版, 2007(2): 65-69.
[2] 梁燕紅. WEB挖掘技術在網絡教學中的應用研究[J]. 信息技術與信息化, 2017(9): 128.
[3] 盧小華, 劉靜. Apriori算法在網絡教學平臺自動推薦學習資源功能中的應用[J]. 現代工業經濟和信息化,2016(15): 101-102.
[4] 于華. 網站結構優化方案的設計與實現[J]. 現代計算機, 2017(20): 82-84.
猜你喜歡
現代經濟信息(2016年8期)2016-12-26 18:11:54
未來英才(2016年2期)2016-12-26 13:44:01
黑龍江教育·理論與實踐(2016年12期)2016-12-24 19:05:13
中學課程輔導·教學研究(2016年14期)2016-12-23 17:55:19
青春歲月(2016年21期)2016-12-20 15:59:13
中學教學參考·理科版(2016年9期)2016-12-15 06:36:39
電腦知識與技術(2016年24期)2016-11-14 01:33:22
南北橋(2016年10期)2016-11-10 17:03:47
中國市場(2016年36期)2016-10-19 04:43:09
電腦知識與技術(2016年21期)2016-10-18 22:05:35
