一種基于異步決策的智能交通信號協調方法
2023-12-15 04:47:36蔡乾婭鄭燕柳
計算機研究與發展 2023年12期
高 涵 羅 娟 蔡乾婭 鄭燕柳
(湖南大學信息科學與工程學院 長沙 410082)(hangao1974@hnu.edu.cn)
物聯網、大數據、邊緣計算等新一代人工智能技術飛速發展,為智能交通系統的實現提供技術支持.智能交通系統(intelligent traffic system,ITS)是一種綜合運用多種先進技術的交通運輸管理系統,用于營造安全、高效、環保的交通環境.智能交通信號控制是智能交通系統的核心,它提供動態更新、綜合計算、實時決策等功能.
近年來,物聯網技術的研究取得突破性進展,也推動智能交通信號控制的廣泛應用.基于物聯網技術實現對交通環境的全方位感知,云計算技術為海量數據提供計算服務,以數據為中心進行決策[1],具有實時精準的特性.然而,采用云計算技術難以滿足大規模場景下信號控制器低時延、高響應、實時計算的需求.邊緣計算技術將云計算能力從中心下沉到邊緣節點,形成端—邊—云一體化協同計算系統,實現就近實時計算,更加滿足信號控制系統高實時性要求.
與此同時,對交通信號優化控制問題的研究也從未停止,采用整數規劃、群體智能方法、傳統機器學習方法等傳統優化方法尋求最優控制方案的研究取得一定成果.強化學習[2](reinforcement learning,RL)在解決連續決策問題上表現優異,被提出可適用于解決交通場景問題[3],在解決大規模交通信號協同控制問題上發揮著越來越重要的作用.
強化學習通過智能體試錯的方式探索環境,并根據探索環境得到的經驗自學習建立最優行為策略模型,最大化累計獎勵.當環境中智能體數量增加,每個智能體單獨進行環境探索并學習.從單個智能體的角度來看,環境出現非平穩性,方法不利于收斂.在目前的研究中對多智能體協同方式大部分采用的同步決策機制,即統一時鐘頻率,以固定的決策周期進行決策.
在實際場景中,由于交叉口地理位置、交通管制要求以及功能的不同,車流通過交叉口的時間往往具有很大差異.同步決策方式導致交通信號綠燈利用率較低,交叉口通行服務質量下降.如圖1 所示,在時刻t交叉口i進行動作決策并切換交通燈相位.在t+Δt時,交叉口i可通行車道(東西方向車道)已無等待車輛,但仍然持有通行權(綠燈空放現象).由于未到約定好的動作決策周期,導致其他車道無法競爭通行權, 從而造成一部分綠燈時間損失,交通信號利用率降低.
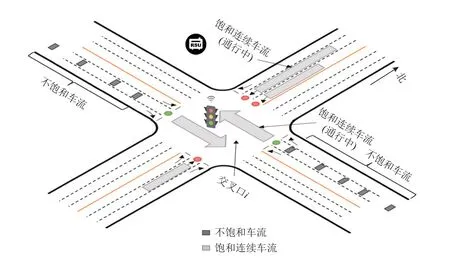
Fig.1 Traffic signal control scene diagram圖1 交通信號控制場景圖
在本研究中設計一種基于端—邊—云協同的交通信號控制架構,并將異步通信與交通信號自適應控制相結合,提出一種多智能體之間可以使用不同決策周期的異步決策機制,降低綠燈損失時間,提高交叉口時間利用率.
本文的主要貢獻包括3 個方面:
1)針對集中控制系統高、時延低效率這一問題,提出一種基于端—邊—云的交通信號分布式控制架構.實現在邊緣節點進行數據預處理,在端節點決策的方式減少傳輸時延.
2)針對同步決策導致交叉口時間利用率低問題,設計一種基于異步決策的交通信號優化機制.智能體根據交叉口車輛等待時間更新決策周期的方法,增加單個交叉口有效綠燈時間,避免交叉口綠燈空放現象.
3)針對強化學習智能體之間實時通信受限問題,提出一種基于鄰居信息庫的多智能體協作交通信號自適應協調方法.降低因異步方式產生的智能體之間信息不平衡情況,從而提升多參與者協同效率.
1 相關工作
邊緣計算為智慧交通的建設提出高效的分布式計算解決方案,該方案構建計算、存儲、決策一體化的邊緣開放平臺,為交通信號控制系統提供一種新型計算模式[4].在大規模路網的交通信號控制研究中,文獻[5]提出一種為每個交叉口控制智能體分配對應邊緣學習平臺,在協作時僅考慮直接相連的鄰居信息的方法.這種分散協作式具有較高的成本效益,難以適用于大規模路網.
實際交通信號控制應用場景存在環境建模難的問題,基于數據驅動的無模型強化學習方法可以在探索中自身學習,實現控制閉環反饋.獨立學習的單智能體之間不進行相互之間的溝通與協作,每個智能體只能感知自己控制范圍內的狀態,每次以優化局部Q 值最大化為目標.但當周圍環境變得復雜時,不考慮上下游智能體的決策帶來的非平穩性的影響將會導致自身學習無法收斂.基于通信的多智能體聯合學習通常采用集中式控制[6],以最大化所有區域智能體的聯合動作對應的Q 值為目標.全局智能體所需要處理數據龐大,現有計算能力難以實時處理,集中式控制方式的弊端逐漸暴露出來,因此有學者提出分散式多智能體控制方式.當掌握全局的統領者被撤走后,使用協作圖[7-8]簡化多個智能體之間關系或采用博弈論[9-11]解決智能體之間的聯合問題是較為常用的辦法.文獻[12]中提出一種完全可擴展的去中心化多智能體強化學習(muti-agent reinforcement learning,MARL)方法,將其他智能體的策略以廣播的方式告知環境中的其他代理,并應用空間折現因子縮小距離較遠的智能體帶來的影響.除此之外,其他MARL 方法應用到多路口場景,如MADDPG[13],APEX DQN[14],AC[15],A2C[16]等,也被證明是可行的.將多智能體協作問題轉換成圖也被廣泛研究,如MARL與GAN[17]、圖卷積[18-20]等圖方法結合.
交通信號控制系統中關于異步的研究集中在降低數據相關性方面.文獻[21]基于并行強化學習范式采用異步梯度下降優化神經網絡參數,提高資源利用率,提升訓練速度.文獻[22]提出一種異步協同信號框架,信號控制器根據并行方式異步共享的相鄰信息進行決策,該框架能夠提高實際控制的穩定性,但要求所有控制器必須同步進行決策.文獻[23]提出一種異步多步Q-Learning 方法,該方法采樣多個步驟后進行估值,降低因估計造成的誤差,并利用多核CPU 并行模擬多個代理與環境進行交互的過程,異步更新全局參數.
在關于多智能體協同的研究中可以發現,在同一環境下的智能體直接進行通信需要同步決策才能實現同步通信.本研究采用間接通信方式,借助邊緣節點存儲的鄰居信息庫間接實現智能體之間通信,智能體之間不必要求同步決策.異步決策方式能夠達到提高智能體之間的通信效率、優化交通信號配時方案、降低車輛在交叉口的等待時間.
2 基于端—邊—云的交通信號控制架構
本文研究以常見十字交叉口場景為例,每個交叉口內安裝多種信息采集裝置,由m個十字交叉口構成的路網中分布著n個邊緣服務器以及1 個中心云服務器,并提出交通信號分層協同控制[24].
如圖2 所示,在單個十字交叉口中布設多種智能終端傳感設備,如網聯車、交通信號控制器、攝像頭和傳感器等.這些終端設備用于感知環境信息,并向邊緣服務器節點傳輸環境數據.
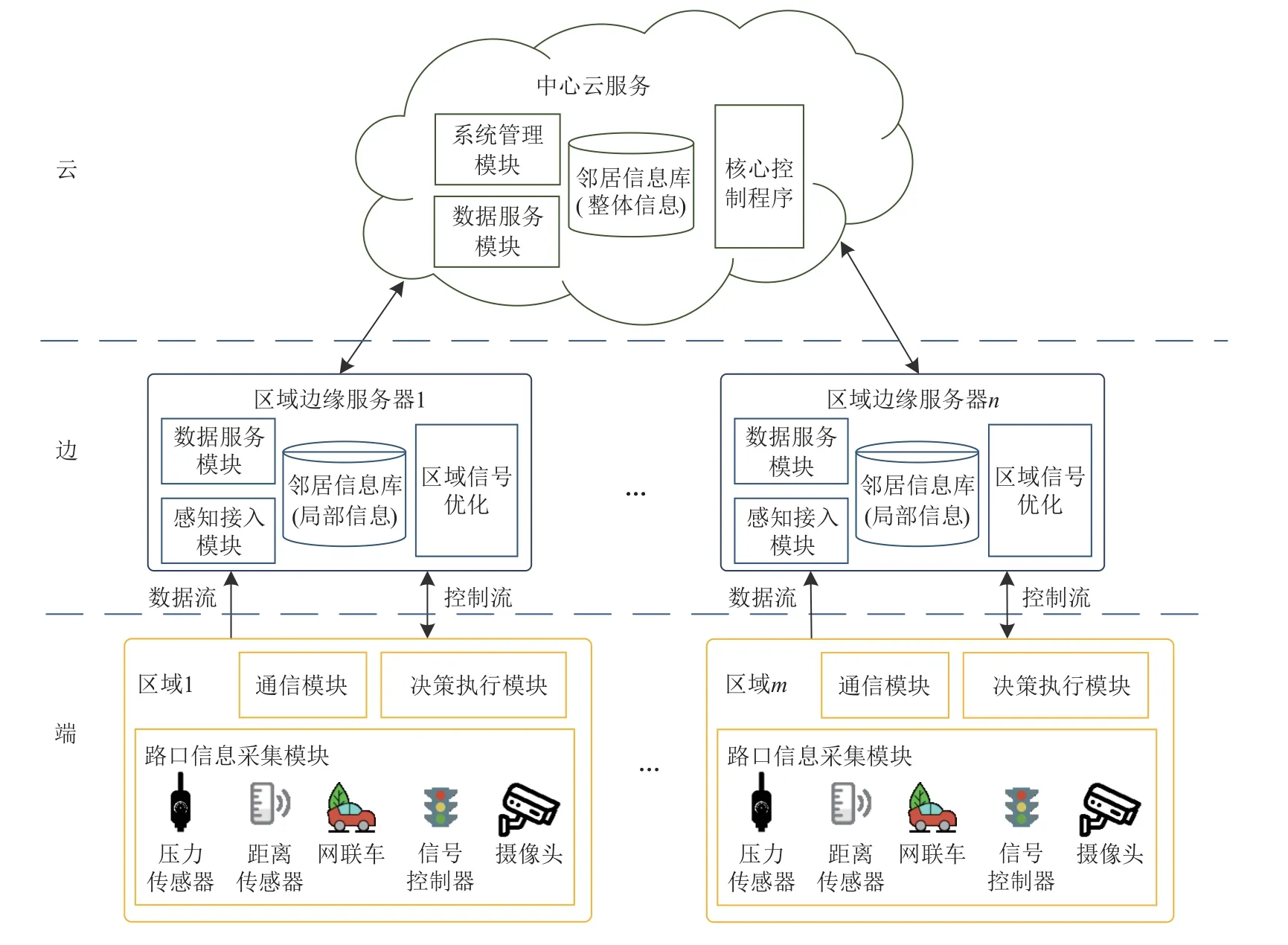
Fig.2 Architecture diagram of traffic signal control based on end-edge-cloud圖2 基于端—邊—云架構的交通信號控制架構圖
根據具體交通需求將m個交叉口劃分為n個區域,縮小交通信號控制器控制范圍.每個區域由對應的邊緣服務器進行管理,負責初步處理多源異構的感知數據、小規模的智能分析,以及提供存儲與決策相關的服務.此外,邊緣節點還需要維護一個小型鄰居信息庫(參見3.2.1 節),用于降低決策時的通信延遲,提升智能體之間的合作效率.
在中心云服務層,云節點核心控制程序從全局角度實現資源調度和決策,同時存儲和維護路網整體的鄰居信息庫,進行深入分析,接收邊緣節點定時傳輸的數據并更新.
3 智能交通信號協調方法
在基于提出的端—邊—云協同交通信號控制架構上,面向多交叉口交通信號控制場景,構建強化學習控制模型,提出一基于邊緣計算的異步決策的多智能體交通信號自適應協調方法(adaptive coordination method,ADM),該方法包括交通信號配時優化機制和基于異步決策的多智能體交通信號自適應協調算法.在3.1 節中重點描述決策周期計算方法.由于系統中多個智能體采取不同決策周期,相互之間的通信方式是需要研究的重點,因此,在3.2 節中提出基于鄰居信息庫的多智能體協作機制,并給出智能體的定義以及學習過程.
3.1 交通信號配時優化機制
根據車輛跟馳方式,車流可劃分為飽和連續車流(包含首車及后續連續車流)和非飽和車流.受到信號燈的控制,當首車狀態發生改變后,在停車線前排隊等候的車輛傳遞性發生連續狀態改變,形成交通流,并以一定的傳播速度向后傳播.能夠與前車一起形成連續不間斷的車流為飽和連續車流,包含綠燈亮起時已排隊車輛以及放行時到達車輛,后加入到隊列中的車輛作為隊尾進行研究.后續到達車輛無法與前車構成連續車流時稱為非飽和車流,此時車頭時距較大,由車輛到達率決定.因不受前車速度制約,非飽和車流以自由流速度行駛通過交叉口.通常情況下,在最長綠燈時間允許范圍內,最后一輛車駛離停車線后切換信號相位.然而,實際情況中因非飽和車流通行的不確定性導致通行時間被浪費.為了貼合實際場景中動態的交通流,提供更好的優化交通信號配時方案, ADM 方法基于車輛跟馳理論針對不同交叉口狀態實時調整綠信比.
交通模式劃分為相對模式(C1)、相鄰模式(C2)和匯聚模式(C3),每個模式中含有4 個相位,每個相位默認綠燈時間為tg, 默認黃燈時間為ty,信號默認周期ta是默認綠燈和黃燈時間之和,如式(1)所示:
根據不同階段的車頭時距,將實際信號周期ta′的計算分為4 個部分.
1)首車啟動及飽和跟馳階段t1,如式(2)所示:
其中carN表示具有通行權車道上的車輛數,waitN表示車道上實際停車數,當車速小于0.1 m/s 時視為車輛處于等待狀態,d是飽和連續車流末尾車輛所在位置到停車線的距離,v是飽和連續車流正常通行情況下的平均速度估計值.
2)非飽和跟馳階段t2,如式(3)所示:
其中runN表示具有通行權車道上正在行駛的車輛,du為非飽和車流末尾車輛所在位置到停車線的距離,vu為非飽和車流繼續通行時平均行駛速度.
3)當飽和跟馳階段執行完畢后,再次觀察交通環境并計算除當前車道外其他車道的飽和連續通行時間t3,并判斷當前交叉口競爭狀態.
①如果t3<t2,交叉口處于弱競爭狀態,不需要切換動作;
②如果t3≥t2,交叉口處于強競爭狀態,需要根據鄰居信息切換新動作.根據3.2.3 節描述的協調機制,重新選擇新動作并執行.
4)黃燈實際執行時間ty′,如式(4)所示:
修正后的實際相位周期時間ta′為這4 部分之和,對應智能體的實際動作執行時間之間與默認動作執行時間存在一定差異,整個系統中智能體難以實現同步決策.因此,ADM 方法引入異步概念,允許智能體根據交通環境情況適當調整自身綠信比.當前相位執行完畢后無需等待與其他智能體時鐘頻率同步的時刻,可以直接決策并執行新動作.
3.2 多智能體交通信號自適應協調算法
3.2.1 基于鄰居信息庫的協調機制
考慮到異步決策機制會降低多智能體之間的通信效率這一問題,ADM 算法提出在云節點維護整體路網的鄰居信息庫,邊緣節點維護與其目標節點相關的鄰居信息庫,并按一定周期將數據同步更新給云節點.
智能體在決策時僅參考與目標交叉口相鄰接的交叉口狀態信息,并將自身新決策發送給對應邊緣節點更新.鄰居信息庫中存儲交叉口之間鄰接信息、每個交叉口的決策時間、決策結果以及持續時間.當交叉口控制智能體i決策時,向其對應的邊緣服務器發送數據請求.邊緣服務器根據交叉口間鄰接關系,將其鄰接交叉口集合Ji的最新決策信息返回給智能體i,智能體i與鄰居協調決策(協調策略詳細描述見3.2.3 節)后將自己最新決策再次發送給邊緣服務器,用于更新存儲在邊緣節點的局部信息庫.一段時間后,邊緣服務器集群集中向云服務器進行同步信息,用于云服務器訓練模型,云服務器訓練模型后將最新模型參數發送給邊緣服務器更新.
3.2.2 模型設置
根據強化學習理論,可以將控制過程建模為馬爾可夫決策過程(MDP),使用五元組表示(O,A, R,α,γ).其中O表示狀態空間向量,A表示動作空間向量,R表示獎勵函數R(o,a):O×A→R,α為智能體的學習率,γ為折扣因子.控制過程的根本原理是通過試錯的方式探索環境,即在智能體執行動作后,環境根據執行該動作產生的效果給予獎勵,如果獲得較好獎勵,表明在當前狀態執行該動作較為合適,可以增加該動作的出現概率.智能體根據探索環境得到的經驗進行自身學習,主要學習任務是行為策略,目標是在環境中最大化累計獎勵.要素的具體定義有3 方面:
1)狀態空間
根據3.1 節中劃分的3 組交通模式,智能體觀測空間也由3 組不同交通模式共計12 種車流的狀態向量構成,O =(S1,S2,…,Si)(1≤i≤12).其中Si表示第i種車流的狀態,由最長連續等待車流f和與f間隔最小的預計到達車流f′的估計停車等待時間Tw表示,如式(5)所示.
其中waitN′是車道上估計停車數,waitN是車道上實際停車數,tw是車道上單位車輛等待時間,e是車道上車輛行駛狀態不均衡系數,e計算公式如式(7)所示.
其中I′是車流在理想行駛與實際行駛狀態下該統計分布面積之差,I是車流實際狀態下該統計分布面積,車流內部以可協調的最大速度同速行駛.
2)動作空間
本文中動作定義采取在預定義的相位方案中選擇需要更改的相位方法.動作空間A= (C1,C2,C3),根據 交 通 模 式 劃 分為3 組C1={NSs,EWs,NSl,EWl},C2={Wsl,Ssl,Esl,Nsl},C3={WsNl,SsWl,EsSl,NsEl},共 計12 種動作構成.N,S,W,E 分別表示北向、南向、西向、東向,下標s 和l 表示直行和左轉.出于安全性考慮,每個動作執行后均默認執行一個對應的黃燈過渡相位.由于右轉車流不受交通信號控制,因此在相位方案中省去對于右轉車輛的指示,默認一直是綠燈狀態.
3)獎勵函數
累計獎勵函數最大是強化學習算法優化學習的目標,其設置需要能夠準確反饋動作執行帶來的影響.本文中獎勵函數R的定義如式(8)所示:
其中是 路口整體車流狀態不均衡系數,取路口直行和左轉車道上行駛車輛狀態不均衡系數e的平均值.Hw是執行動作a后路口擁堵狀態持續加劇程度的估計值,反映執行綠燈相位對路口擁堵狀態變化的影響,計算公式如式(9)所示:
3.2.3 基于多智能體的自適應控制算法
多個智能體在環境中需要相互協調以獲得最大累計獎勵值,智能體在充分考慮與目標節點鄰接的節點的交通狀態下,根據道路實際通行情況和交通信號控制器選擇結果進行決策投票.在強競爭場景下實現控制車流傳輸速度,盡量降低上游路口對下游路口的負面影響.
具體而言,智能體根據觀察到的目標交叉口環境狀態信息,以ε-greedy 策略選取基于動作選擇策略選取動作a1;從鄰居經驗庫中獲取目標交叉口鄰接交叉口的信息,計算得到根據協同后建議采取動作a2;當a1≠a2時,表示與鄰居協同失敗,重新選擇動作.根據交叉口估計等待時間最長車道需要先疏通這一原則對車道設置優先級,從動作a1所屬交通模式的相位集合中選擇具有最高優先級的車道賦予通行權,即動作a3.從動作候選集合{a1,a2,a3}中選擇最終動作后得到對應默認執行周期ta,根據3.1 節計算智能體實際執行周期ta′.每次決策后都要將決策結果發給附近邊緣節點,智能體通過自適應以及與鄰居之間經驗不斷優化學習,提高協調控制的效果,具體如算法1 所示.
算法1.基于多智能體異步協作的信號優化算法.
輸入:學習率α,折扣因子γ,搜索概率ε,最大仿真步數T,交叉口集合J,鄰居經驗庫B;
輸出:最優執行動作序列A*.
① 初始化ot←getObservation(),t←0;/*初始化狀態和時間*/
② fort=1,2, … ,Tdo
③ forj=1,2, … ,Jdo
④ ifat,j,1≠at,j,2
⑤at,j=at,j,1
⑥ elseat,j=at,j,3; /*智能體根據鄰居信息采用投票策略獨立進行決策*/
⑦ end if
⑧t1,t2,t3←calDescisionTime();
⑨ ift2≥t3/*判斷交叉口狀態*/
⑩ break;
? end if
?rt=execute(at,j,t1,t2,t3);
?Qj(o*t,j,a*t,j)=(1-α)×Qj(ot,j,at,j)+α[γ×Qj(ot+1,j,a*)+R(ot,j,at,j)];/*更新Q-table*/
?ot+1,j←getObservation();
? end for
? end for
? return {a1,0*,a1,1*,…,a1,J*,…,aT,0*,aT,1*,…,aT,J*}.
4 實驗結果與分析
4.1 仿真實驗設置
為了評估所提出的ADM 方法,在阿里云服務器上實現云服務核心控制程序、構建全局鄰居信息庫及相關操作API.基于RSU 設備實現數據預處理、控制決策、區域鄰居信息庫創建及更新的程序.在交通仿真軟件SUMO 中對多交叉口仿真環境進行建模,在SUMO 中搭建的路網如圖3 所示.
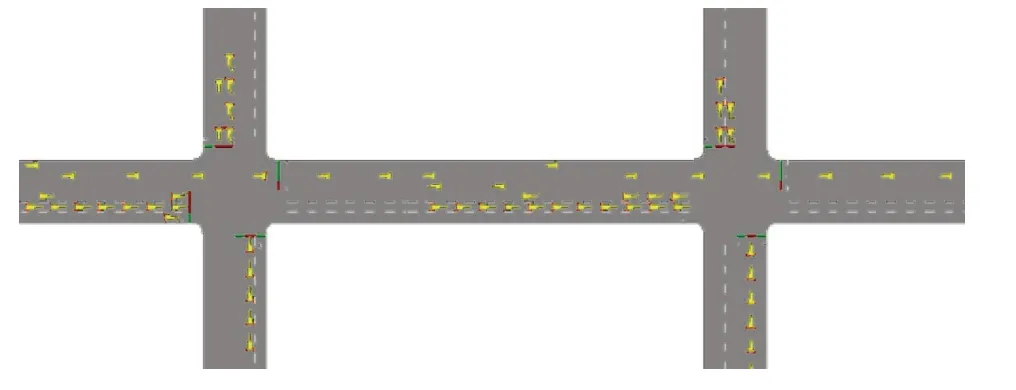
Fig.3 Schematic diagram of the simulated intersection model圖3 仿真交叉口模型示意圖
ADM 方法基于Q 學習方法,經過多次實驗調整后對方法和道路相關參數設置如表1 所示.
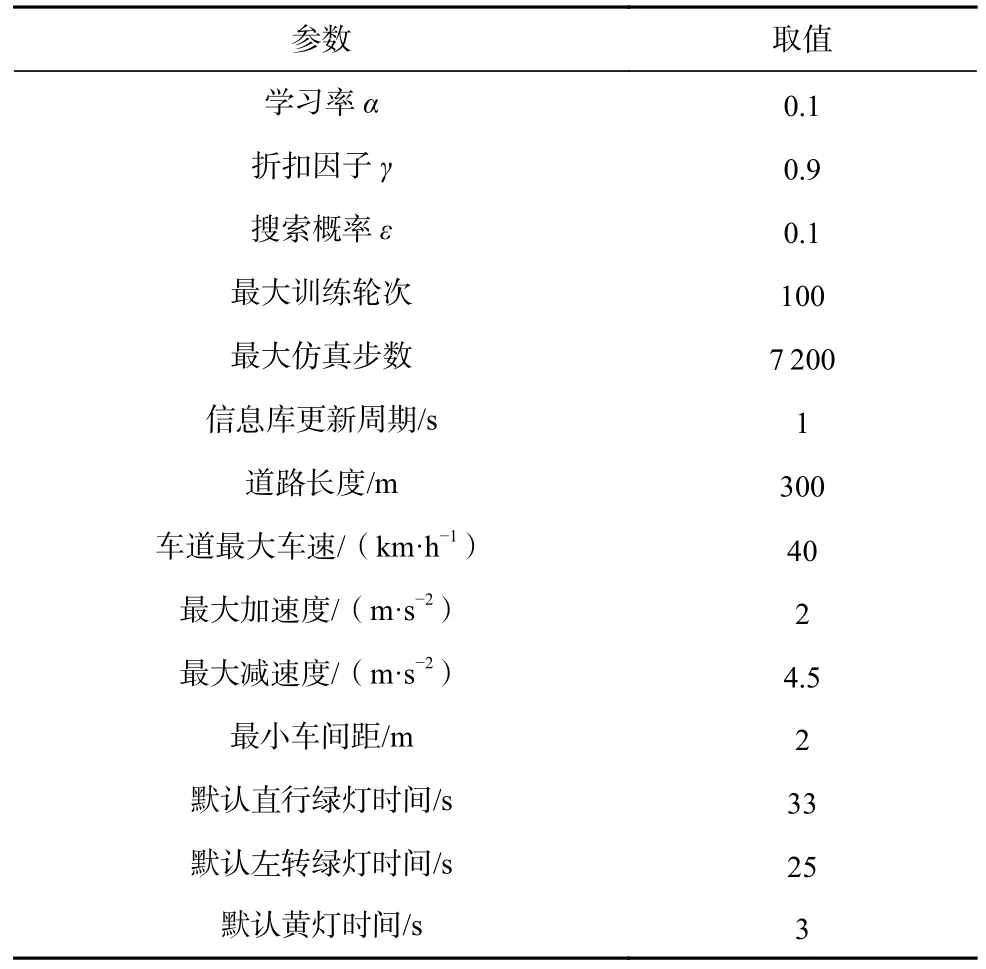
Table 1 Major Parameter List表1 主要參數列表
實驗中仿真車流數據使用濟南市某交叉口實際數據,數據來自于交叉口附近布設的監控攝像,每個交叉口具有相對完整的記錄.數據集中信息包括地理位置信息、車輛到達時間及其他信息,以及對信息處理后生成與仿真環境匹配的路由文件.加載路網和車輛路由文件后,使用Python 語言編程實現ADM方法,借助Traci 接口與仿真環境進行交互獲取數據.
4.2 對比實驗及評價指標
ADM 方法將與2 種方法進行對比.
1)傳統固定配時法(fixed time, FT).按照默認相位方案和信號周期順序執行.默認相位方案為{NSs,EWs,NSl,EWl,Wsl,Ssl,Esl,Nsl,WsNl,SsWl,EsSl,NsEl},默認直行綠燈時長為33 s,左轉綠燈時長為25 s,黃燈時長為3 s.
2)基于Q 學習的獨立交通信號自適應控制方法IQA(independent Q-learning decision algorithm).智能體之間無協同,根據自身信息進行動作選擇,并采用同步決策方式.
評價指標包括:路口平均等待車輛數、路口車輛等待時間、路口最大排隊長度.
4.3 實驗結果
1)控制有效性分析.在4 800 s 的仿真實驗中,路網中車流量總數約為3 000 輛,實驗中2 個交叉口車流量經過優化控制后時變如圖4 和圖5 所示,可以看出2 個交叉口車流量均呈先增后減的趨勢.受路網通行能力的限制,單位時間內可通行車輛數恒定、流量波動大時,代表交叉口通行效率不穩定.當流量小時,表示交通暢通或出現綠燈空放現象;當流量大時,表示交通緩慢或已經擁堵.
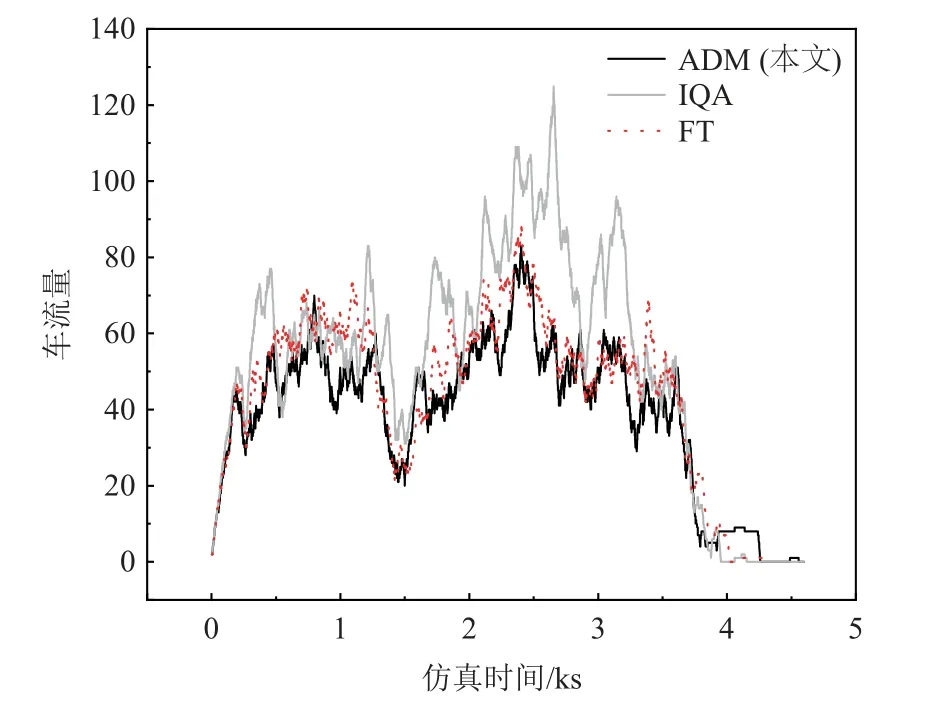
Fig.4 Traffic flow variation of intersection 1圖4 路口1 車流量變化
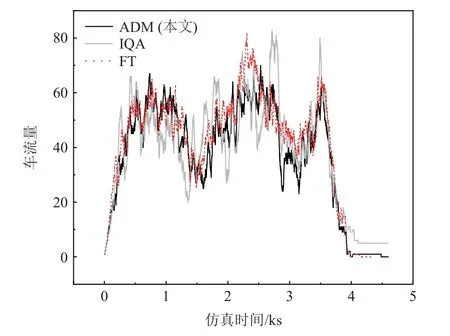
Fig.5 Traffic flow variation of intersection 2圖5 路口2 車流量變化
結合圖4 和圖5 可以發現,在FT 方法中,相位執行順序和時長恒定不變,在整個仿真過程中車流量波動較小,對車流具有一定的疏通作用.而不具有協調機制的IQA 方法獨立決策,無需考慮相鄰交叉口情況.當路網中流量增大時,因交叉口1 和交叉口2無相互協調造成車流量大幅度波動.最高峰時交叉口1 中有近130 輛車在行駛或等待,高于同時刻其他2 種方法近1 倍.同時,在交叉口2 車流明顯低于其他2 種方法,這表明相鄰交叉口之間的協調控制能夠有效減少獨立控制方式的盲目判斷,從而預防大量車輛擁堵現象的產生,最大限度地減少車輛停車次數對于提高路網通行有明顯的作用.本文研究中提出的ADM 方法和FT 方法的波動大致相同,但ADM 整體上低于FT 方法對應的曲線.這表明采用動態信號決策周期能夠有效提升信控優化效率.對于突然大量增加的車流量,也能及時疏導避免在交叉口造成擁堵,展示出具有自適應學習能力和實時決策能力.
2)平均等待長度和平均等待車輛數對比分析.在仿真過程中對2 個交叉口平均等待長度進行記錄,并計算出不同方法的平均值,如表2 所示.固定配時平均等待長度和平均等待車輛數這2 項指標均較高,這表示車輛在交叉口聚集時間過長,產生擁堵現象,但方法由于不具有自適應性無法調節.無協同的IQA 方法優化效果不明顯,經過分析得到,當發生擁堵時IQA 能夠根據環境變化對相位進行靈活調整,因此控制效果比固定配時方法好.圖6 展示在仿真過程中不同方法控制下平均等待車輛數的變化,從圖6 中可以看出,ADM 方法在運行整體調節效果較好,從長遠角度考慮決策,盡量避免擁堵情況的發生,降低平均等待車輛數.圖7 為在仿真過程中不同等待車輛數出現的頻次,可以發現,在ADM 方法的調控下,平均等待40 輛車甚至更多事件發生的頻率明顯少于其他2 種方法,這表明ADM 方法能夠有效避免擁堵情況的發生.
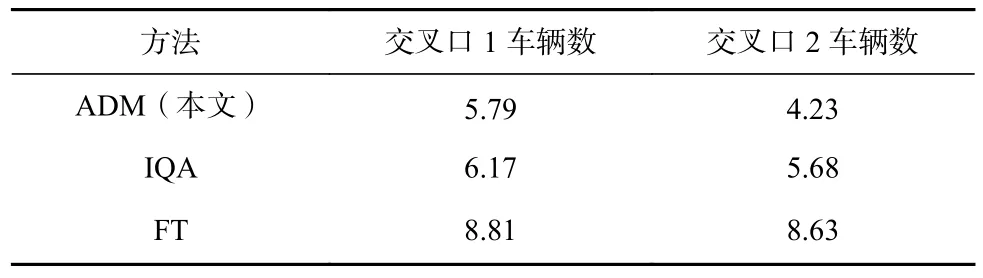
Table 2 Average Waiting Car Numbers at Intersections表2 交叉口平均等待車輛數
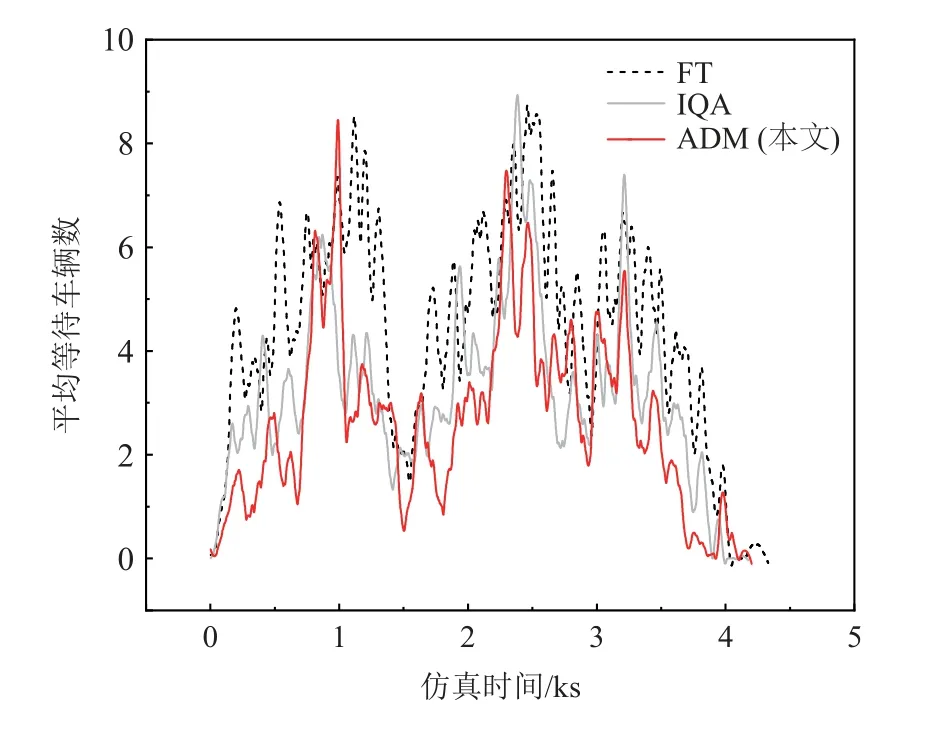
Fig.6 Average waiting car numbers at intersection圖6 交叉口平均等待車輛數
3)累計等待時間對比分析.如圖8 所示,ADM 方法相較于其他方法對路口整體的車輛等待通行時間的控制效果更好,可以較穩定地將路口車輛的等待時間控制在較小范圍內波動,并且ADM 方法的累計等待時間更短并且收斂速度相比其他2 種方法更快.
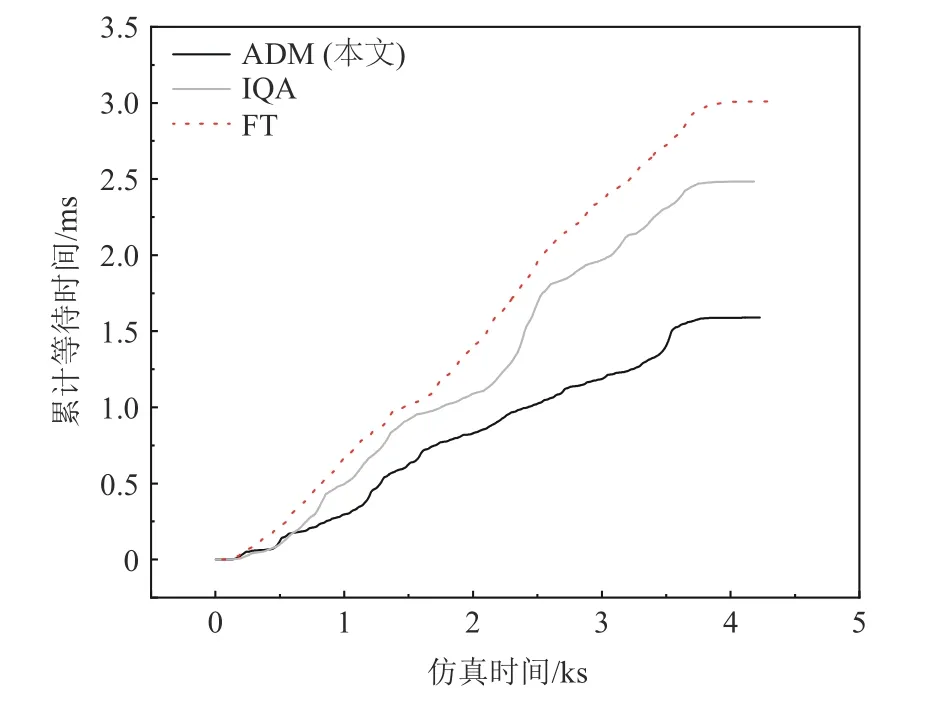
Fig.8 Cumulative waiting time at intersection圖8 交叉口累計等待時間
5 結 論
本文提出一種異步決策的多智能體交通信號自適應協調方法,該方法基于邊緣計算技術實現,適用于大規模路網分布式控制場景.基于本文提出的端—邊—云架構,實現使用多種物聯網終端設備采集環境信息,邊緣進行小規模計算及決策,并在云上部署存儲設備,進行全局計算和管理.此外,針對同步決策中綠燈有效時間短問題,本文將異步引入多智能體協調決策中,并提出采用鄰居信息庫解決多智能體通信效率低的問題,在實驗中驗證本文提出方法的有效性.
未來擬進行的研究工作包括:考慮在不同拓撲結構的路網中使用智能體協同決策機制[14],以及基于分布式多層端—邊—云架構的智能交通控制系統的設計,進一步研究部分網聯車環境下實時交通信號優化控制方法,以及進行流量預測和行駛路線規劃.
作者貢獻聲明:高涵設計實驗方案和驗證實驗,并撰寫論文;羅娟提出研究思路,對論文模型方法提出指導意見;蔡乾雅負責完成對比實驗;鄭燕柳對論文進行修改和完善.
猜你喜歡
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
