基于中間域語義傳導的跨領域文本生成方法
2023-12-15 04:47:50馬廷淮
計算機研究與發展 2023年12期
馬廷淮 于 信 榮 歡
1 (南京信息工程大學軟件學院 南京 210044)
2 (南京信息工程大學人工智能學院(未來技術學院) 南京 210044)(thma@nuist.edu.cn)
21 世紀以來,隨著互聯網的快速發展,出現了大批的互聯網媒體平臺,例如新聞傳媒機構、網絡購物網站、社交網絡平臺等,這些平臺的出現使得互聯網中的數據呈指數級增長.在這其中,文本數據由于其編寫容易、傳播方便的特性成為了這些平臺中數據的主要組成.大量文本數據的涌現,導致平臺中的用戶很難在短時間內獲取到自己想要的信息,這既不利于互聯網平臺的發展同時又降低了用戶的瀏覽體驗,為此需要快速有效的方法從海量文本中提煉出關鍵的信息.文本生成方法作為自然語言處理領域的重要研究內容之一,利用深度神經網絡模型可以實現自動化的文本摘要(automatic text summarization)生成,例如給長文章生成相應的摘要內容,或者給新聞生成對應的標題等.通過自動文摘技術可以從海量文本數據中生成能準確反映原文中心內容的簡短文本,這既幫助用戶快速篩選出了有價值的文本信息內容,又降低了各個平臺的人工編輯成本,提升了內容的傳播速率,因此具有重要的現實意義[1].
然而,傳統的基于深度神經網絡的自動文摘生成模型依賴于大量的含有標注的數據進行模型的訓練[2],且訓練出來的模型只適用于單一的任務領域,無法在其他領域中有效地泛化.但在實際的應用場景中,文本數據往往存在多主題、多領域的特點[1],且一個新領域出現時,很難在短時間內獲得該領域中大量含有標注的數據對文本生成模型進行傳統有監督地訓練.因此,在目標領域參考真值標注數據缺失的情況下,如何有效訓練深度神經網絡文本生成模型,以達到較好的領域泛化效果值得進一步研究.
為了解決上述的問題,現有工作多采用遷移學習中的“預訓練-微調”(pre-train & fine-tune)方法,來緩解目標任務領域中已標注真值數據缺失的限制[2],即針對給定的深度神經網絡文本生成模型,由相關源域中大量已標注的文本數據對生成模型進行預訓練;在此基礎上,基于從源域學習到的模型參數,通過目標域中少量已標注的文本數據對模型進行微調[2],以使生成模型由源域有效遷移至目標域,從而達到領域適應的目的.由此,通過引用相關源域的先驗知識,輔助標注數據量較少的目標域完成摘要文本的生成.
然而,“預訓練-微調”的遷移學習范式仍存在不足.首先,源域和目標領域之間存在較明顯的數據差異,除通過微調手段外,仍需進一步從數據分布的角度消除數據差異對領域遷移效果的負面影響.其次,當目標域中缺少足夠或不存在任何可用于微調的標注數據時,所給定深度文本生成模型無法通過微調有效適應至目標領域,進而導致遷移式文本生成性能欠佳,直接削弱了文本生成模型在目標領域上的適應性.
對此,零次學習(zero-shot learning)提供了較好的思路啟發[3],通過特征屬性為各領域構建“領域要素”(domain prototype)以描述該領域下的數據語義,通過不同領域要素之間的語義關聯性,由最相關源域的“已標注樣本”輔助處理目標域“未標注樣本”(即語義要素傳導),進而針對自動文本摘要生成任務.即便沒有給定任何目標域人工標注數據,仍可借助深度文本生成模型,根據零次學習語義要素傳導原理,為目標域中大量未標注原始文本產生領域適應性較好的目標領域摘要文本[4].
綜上所述,本文提出了一種基于中間域語義傳導的跨領域文本生成方法,旨在通過源域和目標域數據之間的語義關聯,由最為相關的源域已標注樣本指導目標域文本生成,從而克服新領域標注樣本稀缺的限制,提升深度文本生成模型在真實場景中的可用性.本文的主要貢獻有5 點:
1)為源域數據和目標域數據構建文本數據語義要素;
2)改進深度神經網絡文本生成模型內部結構,強化模型編碼和解碼過程,使模型可以接收文本語義要素的各個要素,從模型結構上提升領域間的可遷移性;
3)在核空間中,對源域數據和目標域數據進行數據表示分布對齊,緩解不同領域間數據表示的分布差異對領域間遷移所帶來的負面影響,在數據表示層面增強了領域間的可遷移性;
4)將源域數據和目標域數據按照文本相似性綜合指標劃分至K個中間過渡域中,由此目標域數據可以通過更為恰當的領域數據選擇,在生成過程中參考更具有語義相似性的源域數據;
5)基于改進后的文本生成模型,為文本語義要素中的不同要素構建相應的文本生成損失函數,以此引導模型捕捉跨領域數據在語義要素上的近似參考關系,進而學習到跨領域數據間的語義關聯,從而在中間域內將相關新源域已標注文本作為目標域無標注原始文本的可參考真值.
1 相關工作
自動文本摘要生成技術屬于自然語言處理領域中文本生成任務的一個分支[1].當前主流的自動文本摘要生成模型主要依賴于大量已標注真值摘要樣本對生成模型進行有監督訓練,從而得到具有較好生成性能的模型.但在實際應用場景中常出現真值文本缺失的問題,由此引入了遷移學習相關方法用于解決此問題.現對自動文本摘要生成方法、文本生成任務中傳統的遷移學習方法以及零次學習方法相關工作進行歸納總結.
1.1 自動文本摘要生成方法
自動文本摘要生成是指利用計算機通過算法自動地將文本或文本集合轉換成簡短摘要,幫助用戶通過摘要全面準確了解原始文獻的中心內容[1],此類自動文本摘要生成任務的變體包括論文生成摘要、新聞生成標題[5]、海量社交媒體文本生成的關鍵內容.
當前主流的自動文本摘要生成方法可分為抽取式(extractive)和生成式(abstractive).抽取式方法是從原始文章中提取突出的句子或短語[1];而生成式方法則產生新的詞語或短語,這些詞語可能會改寫或使用原始文章中沒有的詞語[6].在本文中,主要研究生成式文本摘要生成模型,具體是根據給定原始文本產生相應的標題.
近年來,許多研究者采用序列到序列(sequence to sequence)的模型結構建立生成式文本摘要生成模型.Rush 等人[7]在“編碼器-解碼器”的形式中,將包含注意力(attention)機制的循環神經網絡(recurrent neural network,RNN)應用于生成式摘要任務,與傳統的方法相比,該方法的性能得到了有效的提升;吳仁守等人[8]同樣基于“編碼器-解碼器”的形式,但在編碼器端引入全局自匹配機制,根據文本中每個單詞的語義和文本整體語義的匹配程度,尋找出文本的核心內容為給定文本生成核心摘要內容;Narayan 等人[9]使用指針生成器網絡[10]在輸入文檔中識別突出的句子和關鍵詞,將句子和關鍵詞結合以形成最終的摘要.此外,文本摘要生成模型也可以通過基于自注意力(self-attention)機制的神經網絡組件進行構建,如Transformer[11].基于Transformer 的文本生成模型同樣以“編碼器-解碼器”的形式進行構建,解決了傳統RNN 架構不能并行計算的問題,提高了文本生成的效率.勞南新等人[12]將改進的預訓練語言模型作為編碼器,用于提取詞級粒度的信息特征,同時采用多層Transformer 作為解碼器,以字為粒度生成混合字詞特征的中文文本摘要.
由此可見,目前主流的文本生成模型結構仍為“編碼器-解碼器”的形式.目前采用RNN 或Transformer對其構建,結構為“編碼器-解碼器”的生成式文本摘要生成模型通常采用傳統有監督方式進行訓練[13],并不適用于目標域已標注真值樣本缺失的應用場景[14],這意味著需要研究針對此類場景下的遷移式文本生成方法,以克服目標域已標注真值數據稀缺的限制.
1.2 文本生成中的遷移學習方法
對于遷移學習方法在文本生成任務中的應用,已有研究工作表明,使用特定語料數據訓練的模型不能跨領域通用[15].目前,傳統遷移學習方法側重于通過某種遷移策略,由源域數據輔助目標域完成特定任務[13].典型的遷移策略包括3 個方面:
1)基于參數的遷移策略.先從源域數據中學習模型參數;再基于全部或部分已學習到的模型參數,在目標域數據上進行微調;最后使用微調后的模型完成目標任務.這也是目前最常見的遷移學習策略.
2)基于特征的遷移策略.側重于尋找“好的”特征表示,以減少源域和目標域之間數據的表示差異.
3)基于關系的遷移策略.根據領域語義關聯在源域和目標域之間建立映射.
在基于參數的遷移策略研究方面,隨著深度學習的不斷發展,預訓練模型被引入到自然語言生成任務中并獲得了廣泛的應用.通過使用大規模語料庫獲得預訓練模型,并使用目標域中相對少量的訓練數據對預訓練模型進行微調,實現從源域到目標域的遷移[16].按照“預訓練-微調”模式,多種預訓練語言模型被提出.具體地:Raffel 等人[17]提出了預訓練文本生成模型T5,通過使用包含多個領域數據的大規模common crawl 數據庫來進行不同跨度掩碼填充任務的預訓練;Lewis 等人[18]使用去噪自動編碼器預訓練了序列到序列的模型BART,在預訓練過程中采用噪聲函數來掩碼隨機跨度的文本,引導模型學習如何重建原始文本;Zhang 等人[19]提出的預訓練文本生成模型PEGASUS 在語料庫中學習如何重新填充多個被掩碼的句子以進行預訓練.
在基于特征的遷移策略研究方面,有研究者提出了用多種方法來獲得文本或特征上的可遷移表示,從而在不同特征空間的領域之間轉移知識.由于不同特征空間之間通常沒有對應關系,因此需要額外的信息來連接各個領域[20].通過將不同領域之間的數據聯系起來,在盡可能保留數據原始特征信息的同時,減少源域和目標域之間的數據特征差異,從而達到領域適應目的.具體地,Chen 等人[21]設計了一種廣義協變量遷移假設方法對無監督領域適應問題進行建模,通過在子空間中應用分布適應函數并使用凸優化損失函數,使源域數據分布適應于目標域數據分布,從而解決當領域差異較大時,傳統特征轉換方法不能使轉換后的源域分布和目標域分布近似的問題;Li 等人[22]提出一種基于矩陣分解的半監督異構域適應方法,在再生希爾伯特核空間(reproducing kernel Hilbert space,RKHS)內進行矩陣分解,利用特征和數據實例之間的非線性關系學習源域和目標域的異質特征,以彌補核空間中源域和目標域之間的特征差異;Zellinger 等人[23]提出了基于度量的正則化方法,該方法通過最大化不同領域中特定激活分布之間的相似性,來表示不同領域中相似的潛在特征,以實現無監督的領域自適應;王文琦等人[24]和Deng等人[25]沒有直接將不同領域的數據表示進行對齊,而是利用生成對抗網絡,將源域和目標域中的原始文檔輸入到生成器中生成新的文本,使判別器無法區分生成文本所屬領域,從而獲得不同領域數據潛在的遷移式文本表示.
現有的研究表明[16],一方面,通過少量目標域數據微調預訓練語言模型,可以有效地進行語言模型的領域適應.但另一方面,將預訓練語言模型應用到目標領域時,仍需通過一定量的數據對模型進行微調才能達到較好的領域適應效果[26].若目標域缺乏已標注真值數據,會直接影響模型在目標域中的泛化效果,新領域標注數據缺失的限制仍然存在.因此越來越多的研究者開始關注在目標域缺乏已標注數據的情況下,研究更有效的方法將文本生成模型從源域向目標域遷移,從而在目標域中達到較好的文本生成效果.
1.3 文本生成中的零次學習方法
在基于關系的遷移策略方面,近年來,許多研究者將零次學習[27]相關方法應用于遷移式文本生成任務中.零次學習方法相比于傳統的遷移學習方法,更加針對于解決目標域已標注樣本缺失的問題.在目標域可參考真值數據缺失的條件下,零次學習方法通常會給每個領域構建相應的“要素描述”.由此,即使輸入數據是未標注的,但若輸入數據的一組屬性“接近”某個領域的“要素描述”,就可以推斷出給定輸入數據的類別標簽[4].由此,目標域中缺乏可參考真值數據的問題就可以通過領域要素傳導的方式解決.具體地:Zhao 等人[28]通過從各領域數據選擇若干具有代表性的對話文本,將相應的真值文本作為種子,以及將代表性對話文本中的關鍵實體詞作為注釋,使用跨域編碼器對源域和目標域之間共享的領域要素進行編碼,再通過解碼器生成對話文本,由此根據不同領域間領域要素的相似性實現了從源域到目標域的遷移;Liu 等人[29]在多語言場景下的源語言和目標語言中收集語義相似的術語(包括從目標語言真值文本中所收集的詞匯)作為領域語義要素,并在此基礎上,使用隱變量模型處理不同語言間相似句子的領域分布差異;Ayana 等人[30]和Duan 等人[31]提出的遷移式文本生成模型將源域的原始文檔作為輸入,直接為目標域生成文本,并采用目標域真值文本訓練生成模型,并通過建立結構相同的精簡文本生成模型,模仿“輸入→輸出”過程,建立從源域到目標域的語義要素映射,最終將目標域的原始文檔作為輸入,以產生目標域對應的文本生成結果.由此可見,目前已有大量的零次學習方法用于解決跨域的文本生成任務,但目前應用在跨域文本生成任務中的零次學習方法通常會使用目標域真值數據參與領域語義要素構建.但是當目標域真值數據缺失時,相關工作仍存在限制.
綜上所述,通過對現有遷移式文本生成方法的歸納總結,發現仍有3 個方面需進一步研究:首先,通過大規模語料庫預訓練的語言模型應用到目標域上時,仍然需要目標域中一定量的已標注數據進行微調,從而使模型適應到目標域,這意味著目標域中可參考真值數據缺失的限制依然存在;其次,不同領域間數據在數據表示分布上的差異性會對模型產生跨域的負面影響[15],這意味需要通過有效的方法減少不同領域數據表示之間的差異性;最后,在進行跨域的模型生成過程中,目標域數據要盡可能地借助源域數據進行輔助,以提升文本生成效果,這意味需要從已有源域數據中挖掘出對目標域數據有幫助的信息,通過獲取數據間信息的關聯性改進模型獲取關聯信息的能力,針對目標域數據找出最有幫助的源域數據,從而輔助目標域數據生成.
2 方法設計與實現
采用基于零次學習方法進行遷移式文本生成的任務,主要的挑戰是如何充分借助源域中已有的標注數據,幫助無參考真值的目標域數據進行文本生成.
本文要解決的問題可以定義為:給定源域的原始正文Xsource、源域真值文本Ysource和目標域的原始文本Xtarget.在目標域沒有可參考真值文本Ytarget的情況下,通過提出的基于零次學習語義要素傳導的文本生成方法,生成出目標域的相應摘要文本Ytarget.
本節將分別從文本語義原型構建、遷移式文本生成模型構建、領域數據分布對齊、中間域重劃分和零次學習語義要素傳導這5 個方面闡述所提出的遷移式文本生成方法.
1)在各個中間域中,為不同領域形如(新聞x, 標題y)的數據構建“語義要素”.
2)針對跨域遷移式的文本生成場景,改進“編碼器-解碼器”結構的文本生成模型,以適用于零次學習中的語義要素傳導方法,實現從源域到目標域的遷移.
3)將源域和目標域數據的文本表示投射到再生希爾伯特核空間中,將源域的數據分布與目標域的數據分布對齊,從而減少不同領域之間數據分布差異所帶來的負面影響,從數據表示層面提升領域間的可遷移性.
4)建立中間域,將源域和目標域中的數據根據文本相似性的綜合指標重新劃分至若干中間域中,使得在中間域內進行更為恰當的領域數據選擇,為目標域數據分配了更具有語義相似性的源域數據.
5)通過零次學習語義要素傳導,將中間域中的目標域無標注原始文本與新源領域中最相關的標題進行語義關聯,根據語義要素上的相似或接近,為目標域原始文本遷移式生成摘要文本.
最終,在遷移式文本生成過程中,相關源域中的真值文本將充當目標域文本生成的參考真值,從而不再依賴于對目標域數據進行人工標注.
2.1 文本語義要素構建
首先,利用原始文本x、相應的真值文本y和基于原始文本x得到的語義注釋a這3 個要素,為源域和目標域中各個數據(原始文本x,摘要文本y)構建一個語義要素,記為z=(xd, yd, ad), 其中,d表示領域(domains),d∈{src,tar}.表 示 數 據 來 自 源 域(source domains,src)或目標域(target domain,tar).語義要素z中源域和目標域的原始文本表示為xsrc和xtar;源域的摘要文本表示為ysrc.在涉及到目標域的摘要文本數據ytar時,將根據相應的原始文本xtar中每個子句與整個原始文本xtar之間的ROUGE-L指標得分,從原始文本xtar中抽取得分最高的前n個子句作為當前目標域原始文本的“偽真值”ytar(即目標域偽摘要文本).此處,抽取的子句數量n由當前目標域原始文本xtar所屬中間域內源域(原始文本x,摘要文本y)數據的平均長度壓縮率決定;源域和目標域的語義注釋asrc和atar是將源域和目標域的原始文本xsrc和xtar分詞轉換為關鍵詞序列得到的,該關鍵詞序列中各詞匯詞性屬于名詞、動詞、形容詞或副詞中的一種,并且各詞匯均被賦予相應的情感極性值(即在[-1,1]之間).由此,通過上述過程為源域和目標域中各“原始文本x-(偽)摘要文本y”對構建了數據級語義要素,記為z=(xd, yd, ad),d∈{src,tar}.
2.2 遷移式文本生成模型構建
遷移式文本生成模型可以有效應對生成過程中目標域缺少參考真值的問題,本文設計了基于中間域的零次學習語義要素傳導遷移式文本生成模型.通過語義要素傳導策略,遷移式文本生成模型可以學習到不同領域之間的文本語義關聯,這樣的語義關聯可以被認為是所涉及領域的先驗知識.當為目標領域生成文本時,若無可供參考的真值數據,可將領域先驗知識作為參考.
本文提出的遷移式文本生成模型基于“編碼器-解碼器”的形式進行構建,如圖1 所示.

Fig.1 Structure of the transferable text generation model圖1 遷移式文本生成模型結構
圖1 中,編碼器端由2 個結構相同的編碼器模塊E1和E2組成.E1和E2以及解碼器端的解碼器模塊D是將Transformer 模型[11]與雙向長短期記憶網絡(bidirectional long-short term memory,Bi-LSTM)相結合構建的,這樣的設計使得遷移式文本生成模型可以整合自注意力機制與循環神經網絡.此外在模型解碼端添加了指針生成器網絡[10],以解決文本生成任務中的未登錄詞(out-of-vocabulary,OOV)問題.
圖2 中遷移式文本生成模型的編碼器模塊E以及解碼器模塊D參考原始的Transformer 模型[11]設計,每個模塊中都包括了N個堆疊的子層,每一個子層中由多頭注意力機制(multi-head attention)與全連接前饋(feed forward)網絡組成,同時都采用了殘差連接再歸一化的處理.將Bi-LSTM 層添加到E和D的每個子層中,構建增強型的編碼器與解碼器.在這樣設計的每個子層中,Bi-LSTM 層的輸入與子層的原輸入相同,而輸出在子層最后的歸一化之前,與子層的原輸出相加.此外,如果Bi-LSTM 使用與Transformer 模型相同數量的隱藏單元數h,就會得到維度為2h的Bi-LSTM 輸出,因此設計添加一個線性層(linear layer),將Bi-LSTM 的輸出維度2h投射到維度h,以便與Transformer 的輸出維度相匹配.
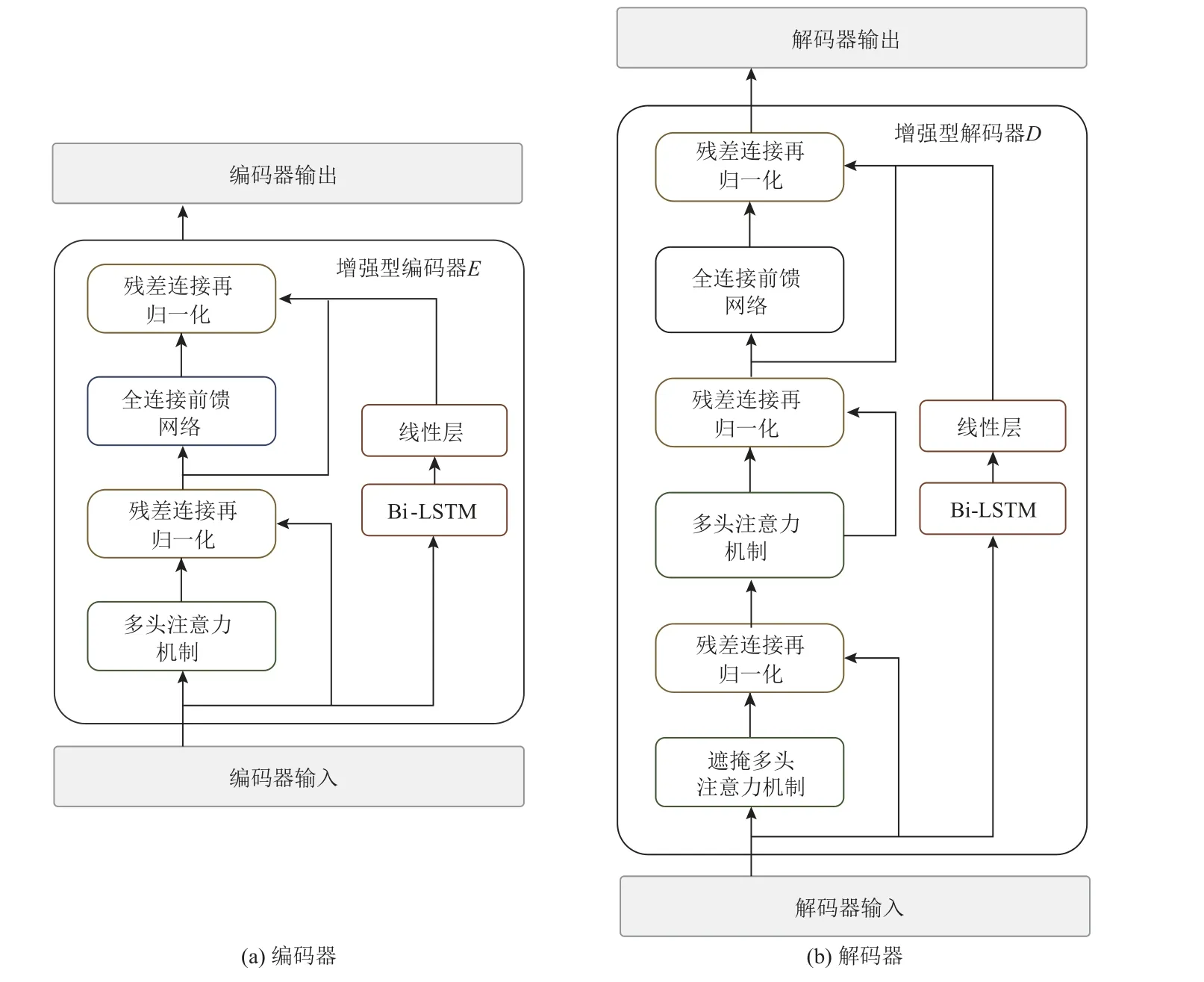
Fig.2 Internal structure of encoder E and decoder D圖2 編碼器E 和解碼器D 內部結構
由此,輸入數據中的語義關聯性(由Transformer中的自注意力機制提供)和時序依賴性(由Bi-LSTM提供)可以同時得到保留.在模型訓練過程中編碼器端的編碼器模塊E1用于接收原始文本xd作為輸入,另一個編碼編碼器模塊E2用于接收摘要文本yd或語義注釋ad作為輸入,而解碼器端模塊D會接收摘要文本yd參與模型訓練.當摘要文本yd是來自源域時,使用源域的真值摘要文本ysrc;當摘要文本yd來自目標域時,則使用目標域的偽摘要文本ytar.
通過上述方式,將源域和目標域的原始文本xd和摘要文本yd同時反饋給編碼器和解碼器,從而在零次學習語義要素傳導階段建立源域和目標域數據之間的語義關聯.由此,在遷移式文本生成模型的訓練過程中,解碼器模塊會分別和2 個編碼器模塊的輸出進行多頭注意力計算[11],在編碼器端和解碼器端捕捉原始文本xd、語義注釋ad和摘要文本yd之間的全局依賴性.此外,由于指針生成器網絡的加入,解碼器在生成文本的過程中,會使用指針生成器網絡提供的“復制機制”[10],在生成摘要文本的每個時間步上決定是從編碼器端的輸入文本中復制詞匯或是從詞表中生成詞匯,從而完成最終的摘要文本生成.
本文構建的適用于語義要素傳導的文本生成模型,接收語義要素z=(xd,yd,ad),d∈{src, tar}作為輸入,輸出生成的摘要文本yd'.具體地,模型編碼器接收語義要素z=(xd,yd,ad),d∈{src, tar}作為輸入,在編碼階段,編碼器接收輸入v=(w1,w2, …,wn)得到編碼器隱藏狀態h=(h1,h2, …,hn).在解碼階段,給定輸入xt后,可以得出時間步驟t的解碼隱藏狀態st,并計算出編碼器隱藏狀態h的注意力分布at,以結合編碼器隱藏狀態h和解碼器狀態st的線性轉換.接下來,在時間步驟t,由編碼器隱藏狀態對注意力分布的加權和計算得出上下文向量表示ct.于是可以得到詞匯分布Pvocab(wt),而Pvocab(wt)表示在時間步驟t預測單詞時詞表中所有單詞的概率分布.
此外,使用指針生成器網絡在解碼的時間步驟t采用指針ptgen作為軟開關,以選擇是按概率Pvocab(wt)從詞匯表中選擇生成一個詞匯,或根據注意力權重at從輸入的文本中復制一個詞匯.因此,得到最終擴展詞表的概率分布P(wt).其中,ptgen是根據上下文向量ct、解碼器狀態st和解碼器輸入xt計算得到的.圖1所示模型生成摘要文本ydgen的具體過程如式(1)所示:
其中v,Wh,Ws,batt,Vp,bv,Wc,Wx,bgen都是可學習的參數.
由此,在圖1 所示模型的訓練過程中,模型接收輸入xd,yd,ad,并按式(1)將詞匯生成概率分布Pvocab和注意力概率分布at與指針開關ptgen加權求和獲得最終的詞序分布概率P(wt),以生成相應的摘要文本ydgen.
2.3 領域數據分布對齊
一般而言,2 個領域的特征空間存在相似性與差異性[3].具體地,不同的領域間有一些共同的特征,但每個領域也有自己域的特有特征.在領域適應的過程中,利用不同領域的共同特征將不同的領域聯系起來,可以有效減少不同領域數據分布之間的差異性.如圖3 所示,2 個領域間會存在一些共同特征Sc和Tc,其中Sc表示源域內部所包含的源域和目標域的共同特征,Tc表示目標域內部所包含的源域和目標域的共同特征.同時每個領域中也存在各自特有的領域特征Ss和Tt,其中Ss表示源域特有特征,Tt表示目標域特有特征.因此,為了在遷移式文本生成上取得更好的性能指標,首先要對齊源域和目標域之間的數據分布表示,以減小不同領域間數據表示的分布差異對遷移式文本生成造成的影響.
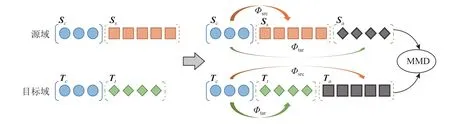
Fig.3 Feature fill alignment圖3 特征填充對齊
具體地,通過預訓練語言模型BERT[32]分別輸出源域和目標域的文本詞嵌入(word embedding)表示.將源域原始文本表示為Xsrc,輸入特征的詞嵌入表示為Xsrc=[Sc;Ss],其中Sc表示Xsrc中包含c個共同特征的特征矩陣,Ss表示Xsrc中包含s個源域特有特征的特征矩陣;目標域原始文本數據表示為Xtar,輸入特征的詞嵌入表示為Xtar=[Tc;Tt],其中Tc表示Xtar中包含c個共同特征的特征矩陣,Tt表示Xtar中包含t個目標域特有特征的特征矩陣,如圖3 所示.
圖3 中,Xsrc和Xtar之間的數據分布首先通過類交叉填充的方式實現特征填充對齊,減小領域特有特征影響;在此基礎上,使用最大均值差異(maximum mean discrepancy,MMD)在再生希爾伯特核空間內通過最小化最大均值差異以減小填充后的領域數據分布差異,從數據分布層面對齊填充后的源域和目標域數據.
具體地:
1)特征映射函數Φsrc和Φtar將源域和目標域中的共同特征與各自領域中的特有特征進行映射聯系,如式(2)所示:
2)將所得特征映射Φsrc和Φtar交叉作用于Tc和Sc上以進行特征填充,如圖3 所示,將從目標域得到的特征映射Φtar應用到源域的共同特征Sc上,得到領域適應化特征矩陣Sa.為目標域做相同的交叉操作,得到領域適應化特有特征矩陣Ta:
3)將源域和目標域的原始特征矩陣Sc、特有特征矩陣Ss和適應化特征矩陣Sa進行填充,分別得到填充后的特征矩陣Xsf和Xtf,如式(4)所示:
特別地,式(3)中的2 個特征映射Φsrc和Φtar可以分 別 表 示為Φsrc(Sc)=WSTSc和Φtar(Tc)=WTTTc,則Sa=于是式(2)可以進一步推導為式(5):
4)為了使源域更好地適應于目標域,還需要確保式(4)所輸出源域和目標域的特征矩陣Xsf和Xtf在分布上盡可能接近.將填充對齊后的表示映射到再生希爾伯特核空間中;在此核空間中,通過最大均值差異來度量不同領域數據映射到核空間后的分布距離Dist.通過縮小Xsf和Xtf映射結果之間的分布距離Dist從而減小源域和目標域數據的分布差異,如式(6)所示:
最后,源域文本詞嵌入表示通過全連接層與激活函數sigmoid 進行特征變換,再將其結果投射到核空間中,而目標域的文本詞嵌入表示則直接投射到核空間中,如圖4 所示.
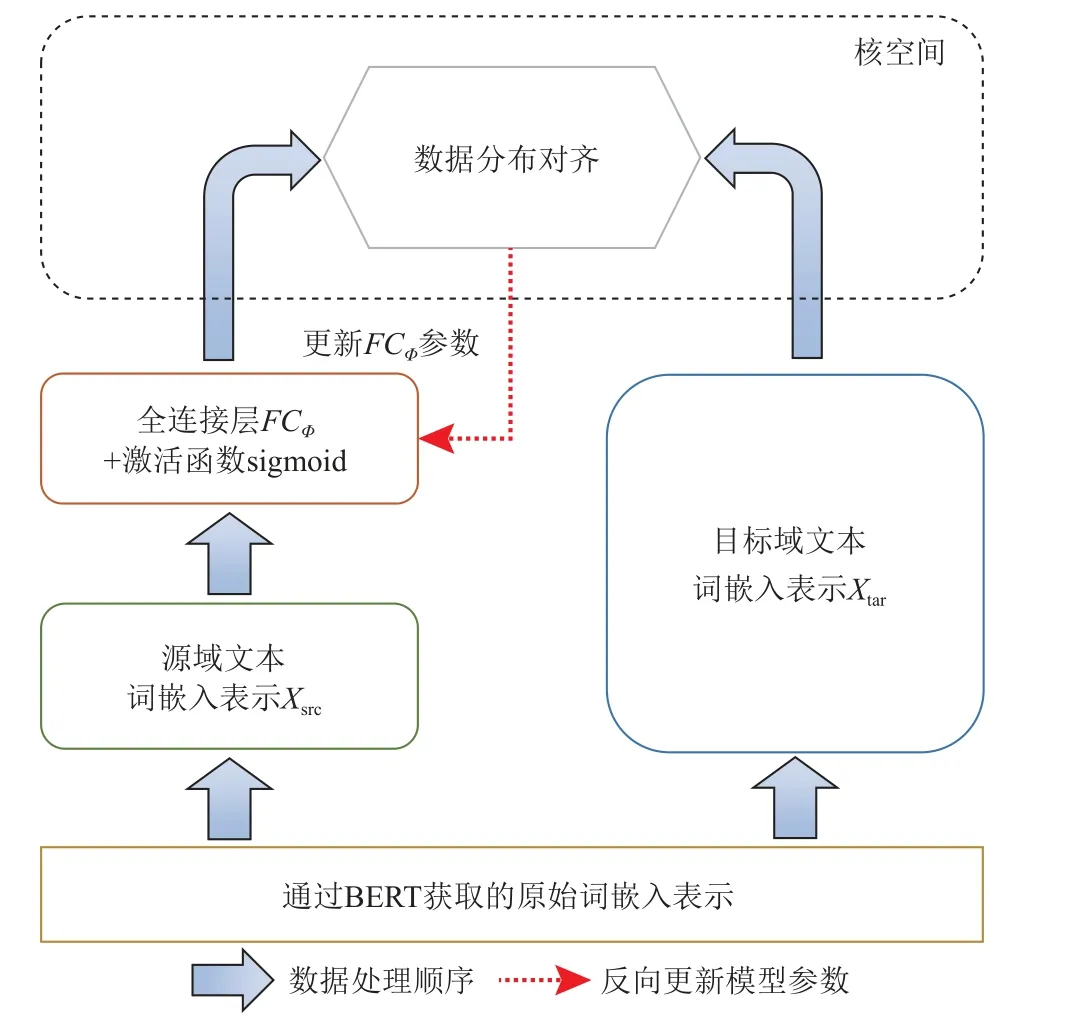
Fig.4 Data distribution alignment schematic diagram圖4 數據分布對齊示意圖
通過最小化式(6)中的目標函數Dist(Xsf,Xtf)使源域與目標域的數據分布接近.由此,圖4 中全連接層的參數將在式(6)目標函數最小化的過程中被更新.
按式(6)訓練后,將源域全連接層映射FCΦ輸出的源域文本表示X'src作為與目標域分布對齊的表示結果.而目標域自身的文本表示X'tar則是通過將目標域的原始詞嵌入表示輸入至源域映射FCΦ中計算所得,如式(7)所示:
當有多個源域時,如式(7)所示,則目標域的文本表示將為多個源域上的平均表示.此處,式(7)中N表示所有領域的總數量.綜上,針對源域原始文本Xsrc和目標域原始文本Xtar的領域數據分布對齊總體過程如算法1 所示.
算法1.領域數據分布對齊過程.
輸入:源域原始文本Xsrc,目標域原始文本Xtar;源域特征表示Xsrc=[Sc;Ss],目標域特征表示Xtar=[Tc;Tt];
輸出:源域分布對齊表示X'src,目標域分布對齊表示X'tar.
① 通過最小化式(2)的目標函數,獲取特征映射函數Φsrc和Φtar;
② 將特征映射Φsrc和Φtar交叉作用于Tc和Sc上獲取式(3)中的領域適應化特征矩陣和Ta;
③ 進行式(4)中的特征填充操作,獲取源域和目標域填充對齊后的特征矩陣Xsf和Xtf;
④ 通過最小化式(6)中的最大均值差異Dist來減小分布差異,獲取源域全連接層映射FCΦ;
⑤ 將③中得到的Xsf輸入式(7)中源域全連接層映射FCΦ,獲取對齊后的源域分布對齊表示X'src;
⑥ 將③中得到的Xtf輸入式(7)中源域全連接層映射FCΦ,獲取對齊后的目標域分布對齊表示X'tar.如果有多個源域則取平均表示.
2.4 中間過渡域重劃分
為加強源域和目標域之間的可遷移性,提高遷移過程中領域數據的相關性,從而為目標域原始文本尋找更為適配的源域摘要文本作為生成參考,本文進一步將源域和目標域中所有數據根據文本相似性綜合指標歸納成簇,重新劃分至K個中間過渡域中,從而在中間域中,為目標域數據分配更為合適的源域數據,即更為恰當的領域數據選擇,如圖5 所示.
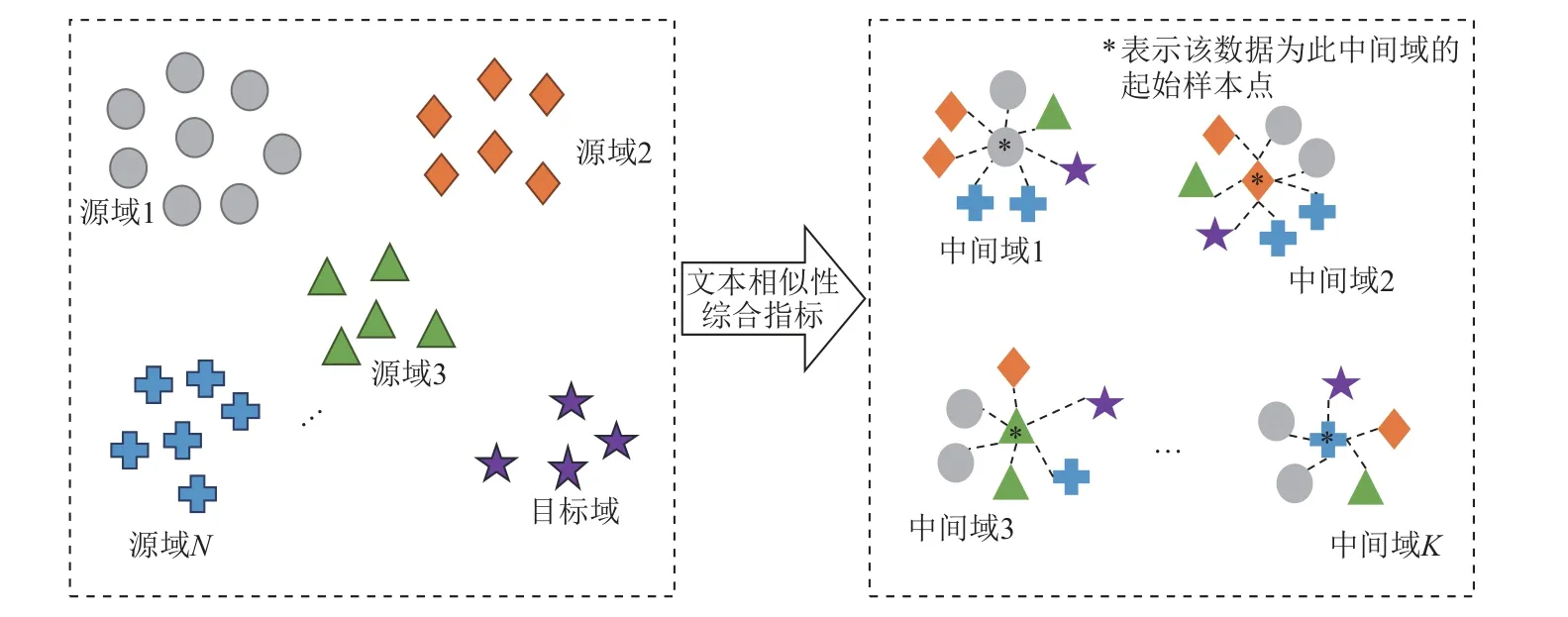
Fig.5 Intermediate domain redistribution schematic diagram圖5 中間域重劃分示意圖
具體地,每個重劃分的中間域內包含了最具有相似性的源域和目標域數據.由于不同領域數據之間具有語義差異,不恰當的中間域劃分會導致其所包含的源域和目標域數據之間產生負遷移問題[3].因此,各中間域內的數據應擁有盡可能多的相似特征.
首先,由式(7)得到各源域和目標域的分布對齊表示X'src和X'tar之后,對每個源域中所有數據的分布對齊表示取平均,得到各源域內的平均分布對齊表示向量.接著,將各源域內與平均分布對齊表示向量距離最相近的數據點作為各中間域的起始點,由此得到源域個數N-1 個中間域起始點.最后,本文研究并選擇了4 個相似性計算指標,從文本內容相似性角度進行中間域重劃分:
1)特定詞重合度Soverlap.計算給定文本對的相似度,即文本中特定用詞的重合度越高,表示文本傳達的主要信息越相似.使用余弦相似度來量化這一指標,如式(8)所示:
其中xi和yi表示源域文本和目標域文本經過OneHot編碼后,詞頻向量x和y在同位i上的值,即每個分詞出現的次數.
2)用詞覆蓋率Scoverage.將給定文本對中重合詞的數量除以目標域文本中的詞數量,即文本中相同用詞越多表明源域文本與目標域文本越相似.根據召回率(recall)來衡量源域文本和目標域文本在單個詞語上的共現性,如式(9)所示:
其中gram1表示共現詞的詞粒度為1,式(9)中分子部分表示源域文本與目標域文本中同時出現gram1的個數,式(9)中分母部分表示目標域文本中出現的gram1個數.
3)信息密度Sdensity.將給定文本對中的重合詞數量除以源域文本中的詞數量,即高信息密度表明源域文本中有大量可遷移至目標域的信息.根據信息密度(density)來衡量源域文本和目標域文本在詞語上的重復度,如式(10)所示:
其中gram1表示共現詞的詞粒度為1,式(10)分子部分表示源域文本與目標域文本中同時出現的gram1個數,式(10)分母部分表示源域文本中出現的gram1個數.
4)文本長度Slength.文本長度可以反映出所包含信息量的多少,即擁有相似長度的文本對所包含的信息量大致相同.使用源域文本和目標域文本標記長度絕對差值與文本標記長度和比值的負值來量化這一指標,如式(11)所示:
其中Star_len表示目標域文本經過分詞后得到的詞序列中的詞數量,Ssrc_len表示源域文本經過分詞后得到的詞序列中的詞數量.
最終如式(12)所示,將特定詞重合度Soverlap、用詞覆蓋率Scoverage、信息密度Sdensity和文本長度Slength相加,得到用于計算源域文本和目標域文本內容相似性的綜合指標S:
然后,在得到源域個數N-1 個中間域起始點后,使用聚類方法中常用的輪廓系數(silhouette coefficient)[33]對起始點個數進行評價,從而從N-1 個中間域起始點中確定最佳的K個中間域起始點.假設已經將源域和目標域數據按照文本內容相似性的綜合指標S劃分為源域數量個中間域,對于每個中間域中的每個樣本點i,分別計算其輪廓系數.具體地,需要對每個樣本點i計算2 個指標:a(i)表示樣本點i到同一中間域中其他樣本點距離的平均值;b(i)表示樣本點i到其他中間域Cj中所有樣本的距離的平均值bi,j,其中b(i)=min{bi1,bi2, …,bik}.則樣本點i的輪廓系數如式(13)所示:
中間域中所有樣本點i的輪廓系數的平均值,即為該中間域總的輪廓系數S∈[-1, 1],S越接近于1,說明中間域劃分效果越好.接著將每個中間域的輪廓系數進行相加排名,獲得輪廓系數總和得分最高的中間域組合,此時組合的中間域個數即為中間域劃分最優K取值.最后,將源域和目標域剩余的原始文本分別與K個中間域起始點所對應的原始文本,通過式(12)進行內容相似性指標計算,按所得綜合相似性指標評分排序,逐個將源域和目標域剩余的原始文本劃分到得分排名第1 的中間域中,由此將所有領域文本劃分到各自最相似的中間域中,如圖5所示,形成K個中間域每個中間域均同時包含了最相似的源域和目標域數據,由此在后續利用語義要素傳導策略進行遷移時,中間域內的目標域原始文本可按照語義要素的相似性將最為相關的源域摘要文本作為模型訓練參考真值.圖5 基于文本相似性指標的領域文本中間域重劃分總體過程如算法2 所示.
算法2.中間域重劃分過程.
輸入:源域原始文本,源域數量為N-1,目標域原始文本,目標域數量為1;
輸出:重新劃分為K個(不超過N-1 個)中間域的新源域原始文本和目標域原始文本.
① 對式(7)獲取的源域分布對齊詞嵌入表示取平均,獲取源域中的平均分布對齊表示;
② 獲取源域中與平均分布對齊表示最相近的原始文本作為起始文本,獲取N-1 個中間域起始點新聞文本數據;
③ 根據式(13)的輪廓系數,獲得每個起始點為中心的新中間域輪廓系數s;
④ 根據N-1 個輪廓系數,得出排名最高的中間域廓系數s的得分組合,此時的中間域個數即為最佳K取值;
⑤ 將剩余的源域和目標域中的數據分別與K個中間域起始新聞文本通過式(12)計算文本相似性綜合指標S,并根據得分進行排序,根據指標得分,將文本劃分到得分最高的中間域中;
⑥ 對源域和目標域剩余的原始文本重復⑤操作,直到所有數據被劃分到新的K個中間域中.
2.5 基于中間域的語義要素傳導
基于圖1 中構建的遷移式文本生成模型、分布對齊后的源域數據表示X'src和目標域數據表示X'tar,以及圖5 中重新劃分的K個中間域D′i中的數據,本文設計了一種基于中間域的語義要素傳導方法,訓練遷移式的文本生成模型,從而有效解決新領域存在的數據缺失問題.
值得注意的是:1)原始文本xd、摘要文本yd和語義注釋ad(包含關鍵詞序列及關鍵詞情感極性值)均通過BERT 模型獲取其詞嵌入表示;2)在構建語義要素z=(xd, yd, ad),d∈{src,tar}時,所有領域數據均已遵循圖5 所示的領域重劃分原則被劃分至K個中間域中,并且原始文本表示xd已按式(7)進行了領域數據分布對齊;3)所構建語義要素z=(xd, yd, ad),d∈{src,tar}將會輸入至如圖1 所示的適用于語義要素傳導的遷移式文本生成模型中.
具體地,基于式(1)所示的生成過程,針對零次學習語義要素傳導,按式(14)為語義要素z中的(xd,yd)設計損失函數Loss1,從而使所輸入原始文本xd生成的摘要文本“接近于”xd對應的參考摘要文本yd,以此推導出原始文本xd、真值摘要文本yd和所生成摘要文本?d三者間的語義轉導關系.
具體地,如式(14)所示,E1(xd)表示將原始文本xd輸入到編碼器端的編碼器模塊E1中;E2(yd)表示將摘要所包含的領域數據而言,給定語義要素z=(xd, yd, ad),d∈{src,tar},通過最小化損失函數Loss1,可以在中間域D′i內建立隱式的語義轉導關系
類似地,基于式(1)所示的生成過程,針對零次學習語義要素傳導,按式(15)為語義要素z中的(ad,yd)設計損失函數Loss2,從而使所輸入語義注釋ad生成的標題“接近于”ad對應的真值摘要文本yd,以此推導出語義注釋ad、摘要文本yd和所生成摘要文本?d三者間的語義轉導關系.
具體地,如式(15)所示,將原始文本xd對應的語義注釋ad輸入到編碼器模塊E2后,仍然令模型生成摘要文本?d.與此同時,通過最小化MSE[E2(ad)||E2(yd)],引導編碼器模塊E2輸出的隱藏狀態E2(ad)“接近于”E2(yd)輸出的隱藏狀態.最終,對于中間域所包含的領域數據而言,給定數據語義要素z=(xd, yd, ad),d∈{src, tar},通過最小化損失函數Loss2,可以在中間域內建立隱式的語義轉導關系
最后,如式(16)所示,通過將損失函數Loss1和Loss2相結合,構建了復合生成損失函數Lossco,從而間接反映了基于語義要素傳導的遷移式文本生成原理,即當輸入語義要素z=(xd, yd, ad),d∈{src,tar}時,圖1 中遷移式文本生成模型的參數將通過式(16)中的復合損失函數Lossco進行訓練,從而如圖6 所示,在中間域內建立語義轉導關系xd≈yd≈ad→?d≈yd.
因此,在每個中間域中,當給定來自新源域的語義要素zsrc=(xsrc,ysrc,asrc)時,新源域內可建立語義關聯xsrc≈ysrc≈asrc→ysrc.接著,當給定來自目標域的語義要素ztar=(xtar,ytar,atar)時,目標域內可建立語義關聯xtar≈ytar≈atar.當涉及新源域和目標域之間的語義要素傳導時,如圖6 所示,如果在一個中間域中,存在任何一對(原始文本x, 摘要文本y)的語義要素ztar=(xtar,ytar,atar)與zsrc=(xsrc,ysrc,asrc)接近或相似,則會產生一 個 跨 域 的 語 義 關聯xtar≈ysrc≈asrc→ysrc,即 為xtar→ysrc,如圖6 所示.
因此,當給定目標域原始文本xtar時,可以參考新源域中相關的真值文本ysrc來輔助生成目標域中的摘要文本ytar.由此,即使目標域中沒有真值文本數據,也可以通過零次學習語義要素傳導的方式借助新源域數據幫助目標域中的原始文本生成摘要文本,整體過程如算法3 所示.
算法3.基于零次學習語義要素傳導的遷移式文本生成過程.
輸入:源域語義要素zsrc=(xsrc,ysrc,asrc),目標域語義要素ztar=(xtar,ytar,atar);
輸出:生成摘要文本?d,d∈{src, tar}.
① 在中間域內,通過式(14)中Loss1訓練遷移式文本生成模型,構建源域內語義關聯:
xsrc≈ysrc≈asrc→ysrc;
xtar≈ysrc≈asrc→ysrc;
③ 在中間域內,通過式(16)中Lossco訓練遷移式文本生成模型,構建跨域語義關聯:
xtar≈ysrc≈asrc→ysrc,即為xtar→ysrc;
④ 模型通過式(1)生成摘要文本?d,d∈{src, tar}.生成過程中更新遷移式文本生成模型參數.
3 實驗及分析
3.1 實驗數據與實驗設置
在實驗中,針對本文設計的多領域場景下的遷移式文本生成任務,因為新聞天然地具有多領域、多主題的特點,所以選擇了新聞標題生成任務進行實驗.本文選取了公開數據集PENS(personalized news headlines)[5]個性化新聞標題生成數據集.PENS 中包含113 762 篇新聞,分為15 個主題,每篇新聞包含標題和正文.本文從PENS 數據集中隨機選擇8 個新聞主題作為不同領域,包括體育(sports)、金融(finance)、音 樂(music)、天 氣(weather)、汽 車(auto)、電 影(movie)、健康(health)和兒童(kid).在每一個領域中,隨機選擇8 000 條新聞數據作為訓練數據集.
表1 中描述了實驗所使用數據集的相關信息.其中,“平均長度”和“最大長度”表示每個領域中,所有新聞正文和新聞標題通過預訓練BERT 模型進行分詞后,所得詞序列的最大長度與平均長度.“壓縮率”表示一個領域中新聞標題的文本平均長度與新聞正文文本平均長度的比率.
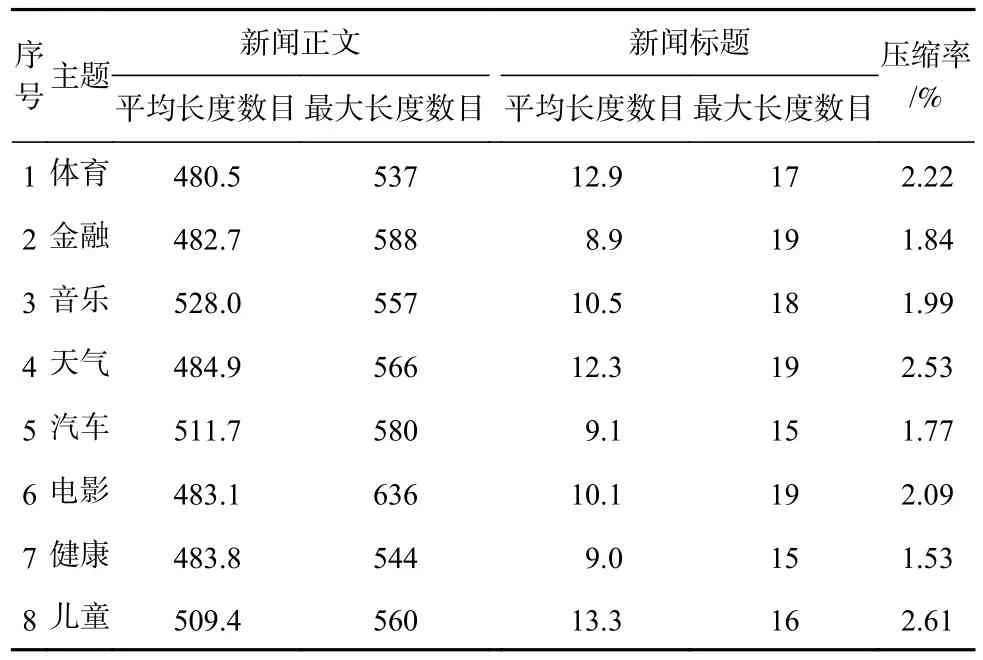
Table 1 Statistical Information on the News Data Extracted from PENS Dataset表1 PENS 數據集中提取的新聞數據的統計信息
在實驗中,圖6 中遷移式文本生成模型編碼器模塊和解碼器模塊的子層數量均為4,子層的輸入輸出維度為512,多頭注意力的注意力頭數量為8;用于獲取詞嵌入表示的預訓練BERT 模型采用維度大小為512 的BERT-Medium;Bi-LSTM 的 隱 藏 單 元 數 量 為512;模型訓練采用帶有自定義學習率的Adam 優化器[11];在每個領域上訓練的迭代次數(epochs)為1 000;本文所有實驗均采用Python 3.8 和tensorflow-gpu 2.5.0 實現,實驗平臺配置為Windows 10 操作系統,GPU 為NVIDIA 2080Ti 顯 卡,內 存 為32GB RAM,CPU 為Intel Core i7-11700K 處理器.
3.2 評價指標及基準模型
為了評估本文提出的遷移式文本生成模型應用到新聞標題生成任務時的有效性,將本文提出的遷移式文本生成模型與現有性能表現出眾的預訓練語言模型和零樣本數據或小樣本數據學習相關的文本生成模型進行比較.
本實驗選擇T5[17],BART[18],PEGASUS[19],BertSum[34]預訓練語言模型.這4 個預訓練語言模型均使用預訓練參數作為模型的初始參數,在不改變其他超參數情況下,使用表1 中的數據對這4 個模型在預訓練初始參數的基礎上繼續進行訓練.
對于零樣本數據或小樣本數據文本生成模型,選擇ZSDG[28], TransferRL[35], DAML[36], MTL-ABS[37].其中,ZSDG 通過將“種子級別”的數據描述投射到一個子空間中,再在領域層面上進行語義描述遷移,從而使用零次學習方法通過領域描述進行目標域零數據的遷移式文本生成.TransferRL 包含一個在不同領域之間共享的解碼器,并通過強化學習自我批評(self-critic)策略最大化解碼器泛化至不同領域的“獎勵”,提升模型的領域適應性,從而只需要在小批量數據上進行微調便可快速適應至目標領域.DAML和MTL-ABS 均根據元學習(meta-learning)原理,使用序列到序列的形式構建生成模型,但DAML 使用門控循環神經網絡作為編碼器和解碼器,而MTL-ABS以Transformer 作為編碼器和解碼器.DAML 和MTLABS 通過元學習方式從梯度優化層面,為模型搜索最具潛力的參數取值,使模型對目標域少樣本數據反應更加靈敏,提升模型的領域泛化性.與預訓練語言模型相比,零樣本數據或少樣本數據學習模型都直接使用表1 中的數據,并根據各自的遷移策略對模型進行訓練.
本文對比模型的生成效果采用文本生成任務中常用的評價指標ROUGE-1/2/L[38],BLEU[38],METEOR[38]來評估.將目標域中的新聞正文輸入至訓練后的模型中,計算模型生成的新聞標題與相應的真值新聞標題之間的評價指標得分.其中,目標域中的真值新聞標題僅用于評估而不參與模型訓練過程.基于上述指標得分,考察本文提出的遷移式文本生成模型能否有效地從源域數據中獲取相關的可借鑒知識,從而在不給定目標域文本參考真值的前提下,有效輔助目標域完成文本生成任務.
3.3 實驗結果與分析
3.3.1 數據分布對齊效果
為了更直接展示本文所提出遷移式文本生成模型各階段內部機制實際效果,如圖7 所示,以“兒童”新聞主題作為目標域,進一步展示領域數據分布對齊效果.其中源域與目標域數據按式(7)進行映射訓練.圖7(a)中源域和目標域的原始詞嵌入表示Xsrc與Xtar,以及圖7(b)中通過式(7)獲得的對齊后表示X'src和X'tar均采用主成分分析(principal component analysis,PCA)方法進行降維表示.
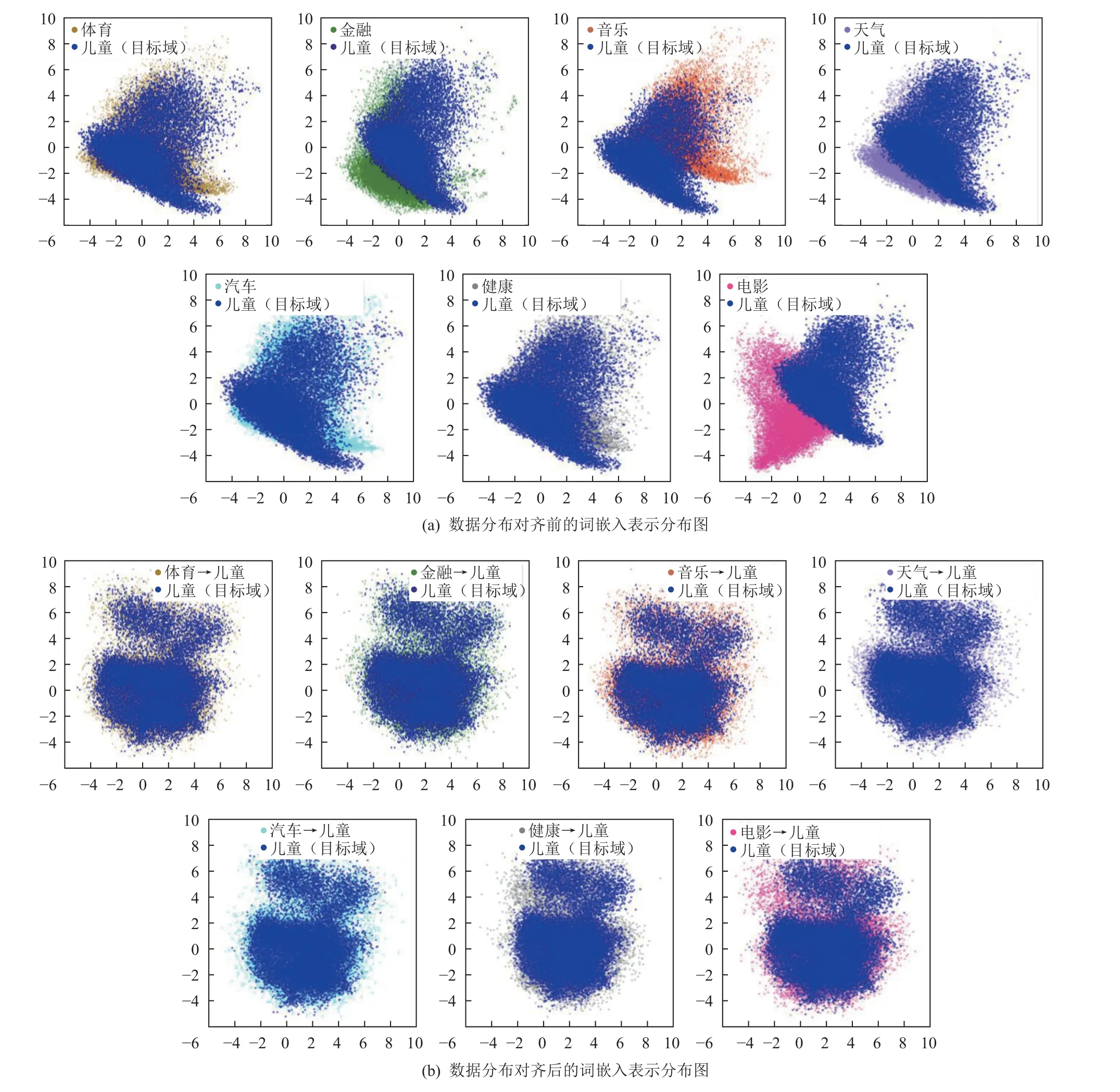
Fig.7 Visualization of the alignment effect of the data distribution after dimensionality reduction圖7 降維后的數據分布對齊效果可視化
具體地,在圖7 中,不同領域的數據表示采用不同顏色進行顯示,位于上層的深藍色區域表示“兒童”新聞主題作為目標域時,領域中數據的詞嵌入分布表示.
圖7(a)中展示了8 個領域的文本數據通過預訓練BERT 模型輸出的原始表示分布,此時的原始表示分布沒有經過任何交叉特征填充和數據分布對齊處理.可以發現,所給定的8 個領域的原始表示分布存在明顯差異.其次,如圖7(b)所示,將除了“兒童”以外的其他7 個領域作為源域.源域中的數據與目標域“兒童”領域新聞數據首先按式(2)~(6)進行源域和目標域之間的交叉特征填充;在此基礎上,按圖4 所示過程由式(7)做領域數據分布對齊處理,最終結果如圖7(b)所示.可以發現,經領域數據分布對齊后,源域和目標域數據之間雖然仍有輕微差異,但不同領域間數據的分布差異已明顯縮小.將對齊前的圖7(a)和對齊后的圖7(b)進行對比可以發現,本文所提出模型涉及的領域數據分布對齊在不同領域間先采用交叉填充為源域和目標域數據填充特征,再用最小化源域與目標域間的最大均值差異距離度量,有效降低了源域和目標域之間的數據分布差異.
3.3.2 目標域輪循實驗
針對零次學習語義要素傳導,依次將表1 列出的8 個域中的1 個域選作目標域,其余的7 個域作為源域.根據中間域重劃分方法將7 個源域和1 個目標域組成如圖5 所示的K個中間域進行實驗.在目標域輪循過程中,通過式(13),即K-聚類(K-means)方法中常用的輪廓系數(silhouette coefficient)[33]來評價不同K取值下的中間域劃分效果,從而確定K的取值,此時K的取值不超過源域數量7.輪廓系數的取值范圍為[-1,1],若輪廓系數的值越趨近于1,代表內聚度和分離度相對較優,聚類效果較好,由此確定中間域個數K.
圖8 表示通過算法2 確定在每個領域作為目標域時,不同的K值取值下輪廓系數的大小.取輪廓系數最大的K值點作為該領域下的中間域最佳個數K.在得到每個領域作為目標域時的最佳中間域個數K的取值后,表2 中ROUGE-1/2/L,BLEU,METEOR 指標得分是輪循實驗中每次確定目標域后,在相應的中間域劃分方案下,由模型生成的新聞標題和相應的標題參考真值計算得出的.具體地,首先評估每個目標域中的文本生成效果.在這種情況下,只有源域的真值新聞標題文本數據參與了模型訓練,目標域中沒有標題真值數據參與,目標域僅使用從新聞正文抽取的偽新聞標題文本.由此,基于式(7)獲得的領域數據分布對齊表示和按式(14)(15)進行的零次學習語義要素傳導,每個目標域中的新聞正文可以不依賴于任何人工標注的參考真值,直接生成新聞標題.
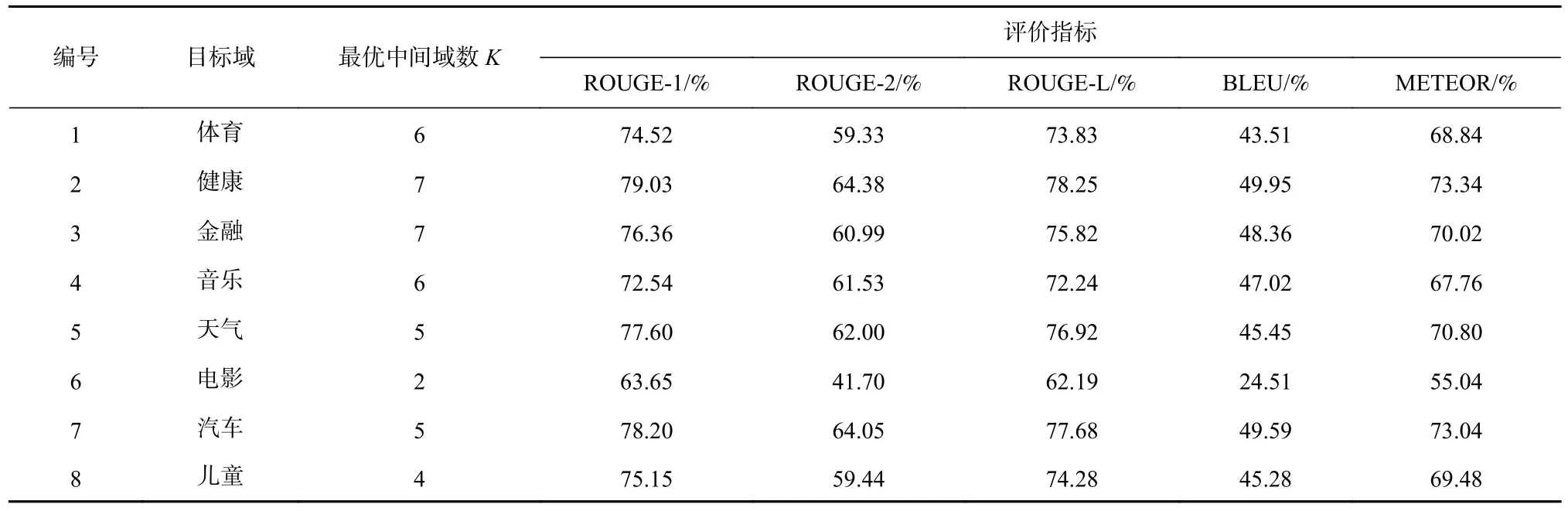
Table 2 Different Evaluating Indicator Scores in Different Target Domains表2 不同目標域中各項評價指標的得分
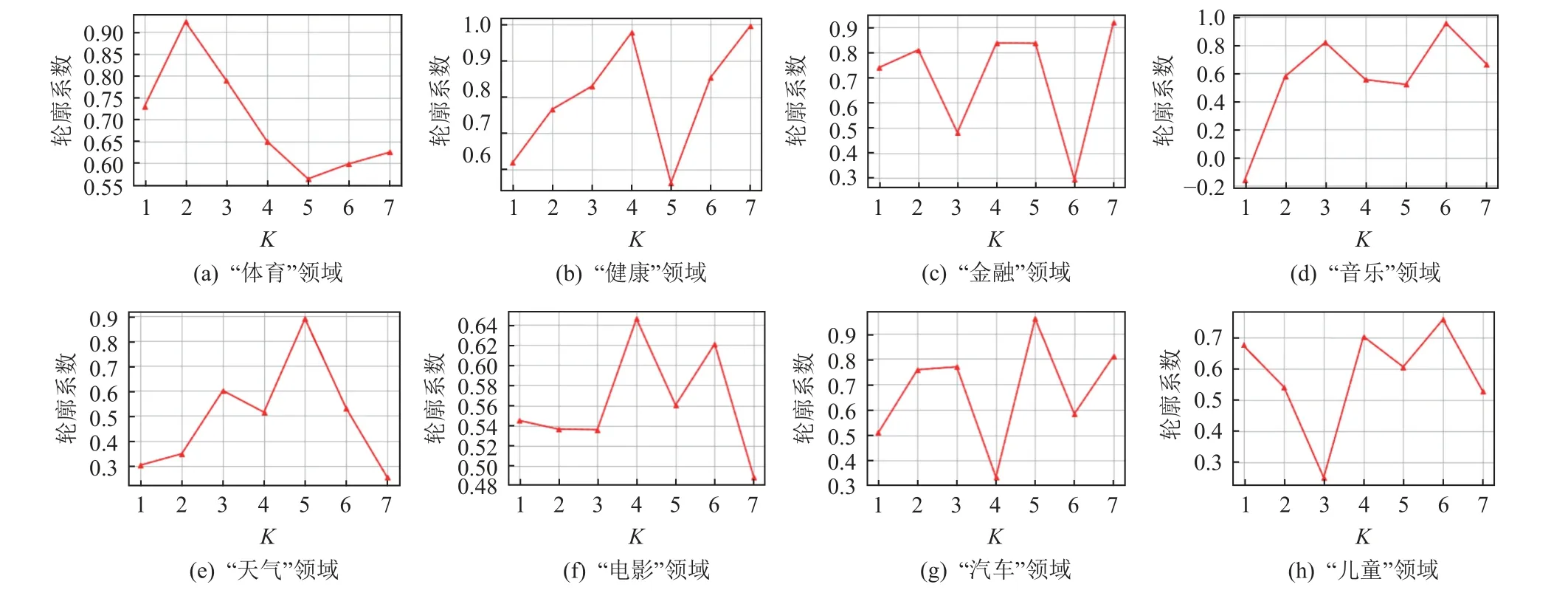
Fig.8 The silhouette coefficients corresponding to different K values in different fields圖8 不同領域中不同K 值對應的輪廓系數
表2 列出了本文提出的適用于語義要素傳導的遷移式文本生成模型在不同目標域中的新聞標題生成性能.可以看出,除了“電影”領域外,其余各領域的指標表現相對穩定;“健康”“汽車”“天氣”領域的指標表現綜合來看排在前3 位.由此,雖然模型在生成訓練過程中沒有參考目標域中的標題真值數據,但通過圖4 中根據式(7)所采用的領域數據分布對齊和圖6 中基于(新聞x,標題y)進行的語義要素傳導遷移,獲取到不同領域之間的數據語義關聯性,從而在不同目標域輪循的過程中和各評價指標上都能獲得較好的得分.該現象可以歸因于:首先基于圖4 在領域數據分布對齊后,數據在不同領域間的分布差異被縮小,因此可以在模型從源域遷移至目標域的過程中,減少不同領域數據分布差異所帶來的負面影響;接著通過零次學習語義要素傳導,本文提出的遷移式文本生成模型通過圖2 中增強型編碼器與解碼器中的注意力機制與時序依賴性來同時獲取不同領域數據之間的語義關聯性,從而調整模型參數以提高模型領域遷移效果.
更進一步,圖9 展示了全部領域作為目標域時在零次學習語義要素傳導階段,文本生成模型的訓練表現.在該階段中,模型通過式(16)定義的損失函數Lossco經過1 000 次迭代進行訓練.詞匯準確率是計算生成文本在每個時間步上生成的文本與參考真值文本之間相同詞匯的比率.從圖9 可以看出,即使是文本生成評價指標最低的3 個領域,訓練中的損失函數Lossco也在逐漸減小,證明了模型在目標域無參考真值情況下,能夠通過為語義要素z中(xd,yd)設計的損失函數Loss1和(ad,yd)設計的損失函數Loss2,使得編碼器和解碼器按零次學習語義要素傳導方法充分解析各領域數據的語義要素,使模型在生成過程中捕捉到不同領域數據語義要素間的關聯性,從而進行從源域至目標域的有效遷移;而詞匯準確率的平穩上升,證明了本文提出的遷移式文本生成模型在從源域遷移至目標域后所生成文本的準確性,其中指針生成器網絡負責處理未登錄詞問題,進一步提升了文本質量.
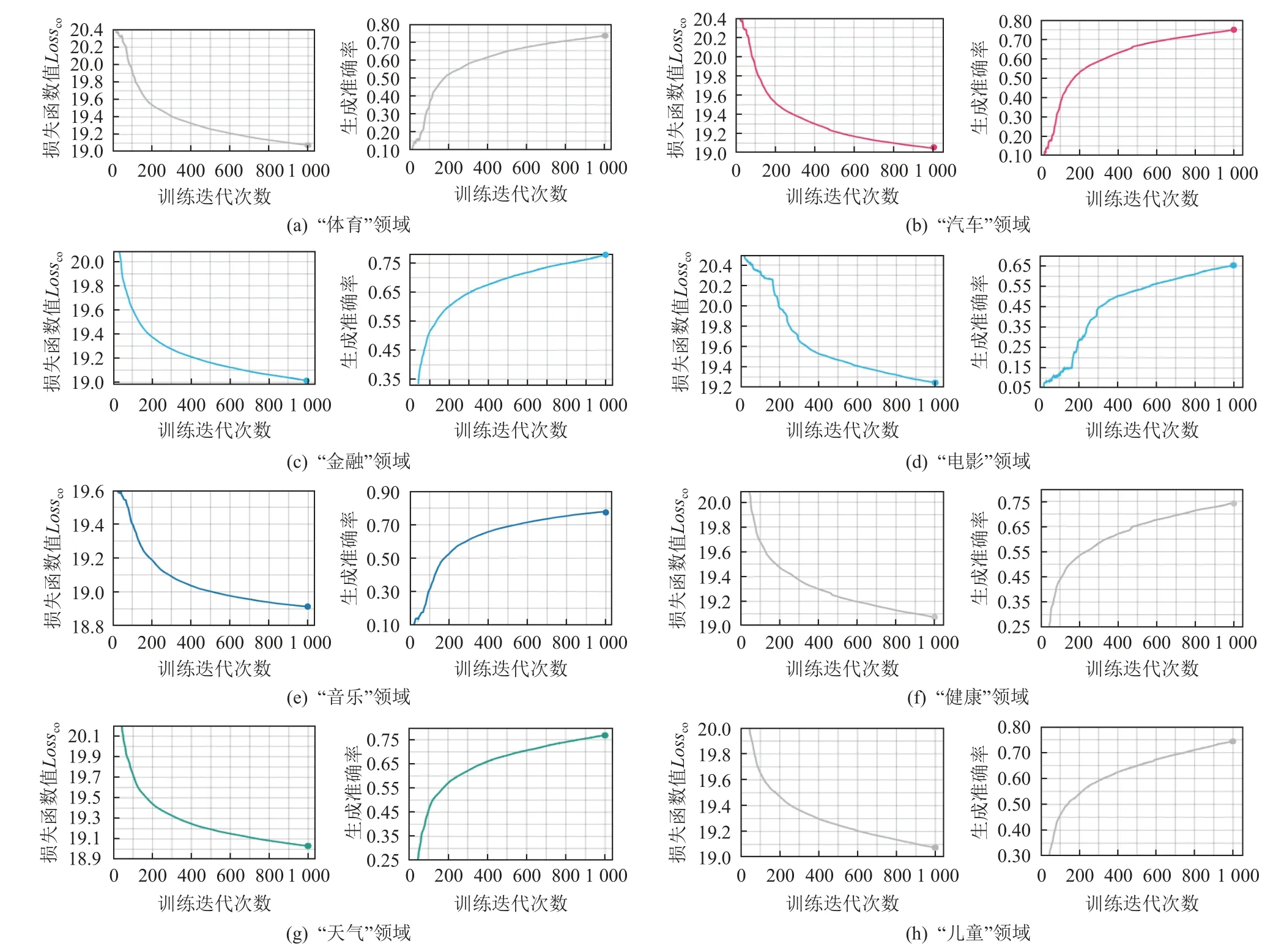
Fig.9 Loss function curves and word accuracy curves in different target domains圖9 不同目標域中的損失函數曲線與詞匯準確率曲線
3.3.3 消融性實驗
從表2 可以看出,當“健康”“汽車”“天氣”這3個領域作為目標域時,遷移式文本生成性能最佳.因此,使用這3 個域進一步對本文提出的遷移式文本生成方法進行消融實驗,結果如表3 所示.
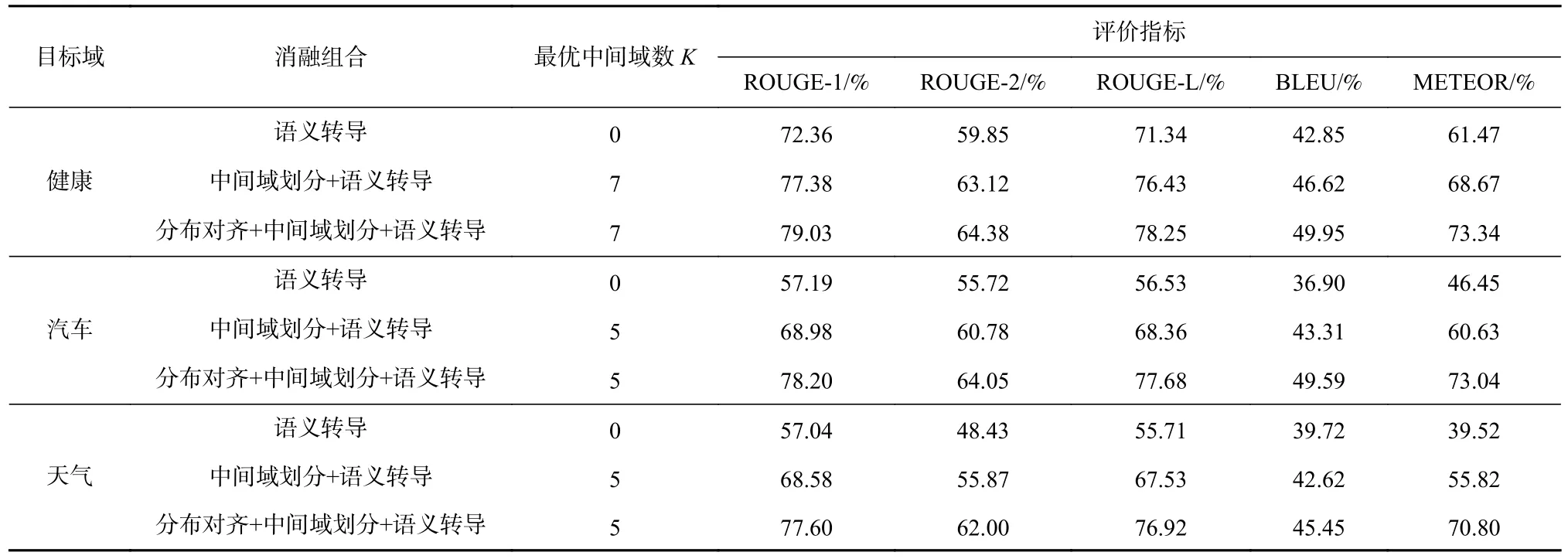
Table 3 Results of Ablation Experiments表3 消融性實驗結果 %
表3 中,“語義轉導”表示直接采用預訓練BERT模型輸出的原始詞嵌入表示,不進行中間域劃分,直接使用圖6 中基于式(14)~(16) 的語義要素傳導進行模型訓練;“中間域劃分+語義傳導”表示直接采用預訓練BERT 模型輸出的原始表示,按最佳中間域個數K取值進行中間域劃分后,再使用圖6 中基于式(14)~(16) 的語義要素傳導進行模型訓練;“分布對齊+中間域劃分+語義轉導”表示基于圖4 中按式(7)采用分布對齊后的數據表示,按最佳中間域個數K取值進行中間域劃分后,再進行圖6 中基于式(14)~(16) 的語義要素傳導訓練.
從表3 可以看出,在每個目標域中采用了分布表示對齊方法后,其文本生成效果要優于直接使用原始表示的方法,這意味著通過領域數據分布對齊可以有效消除領域間的數據分布差異,提升從源域向目標域的可遷移性.此外,將表3 與表4 對比可以看出,本文提出的模型僅使用語義要素傳導方法進行訓練,與多數其他的遷移式文本生成模型相比,也可以獲得更高的評價指標得分.該現象表明了在本文提出的遷移方案中,零次學習語義要素傳導在不同領域間探索數據語義關聯性,通過“編碼器-解碼器”結構中增強型編碼器與解碼器使目標領域中的無標注新聞正文與源領域中最相關的新聞標題進行關聯,根據注意力機制與時序依賴性獲得語義要素上的相似性或接近性,得出目標域在文本生成時對源域數據的參考,從而提升了遷移的文本生成效果.
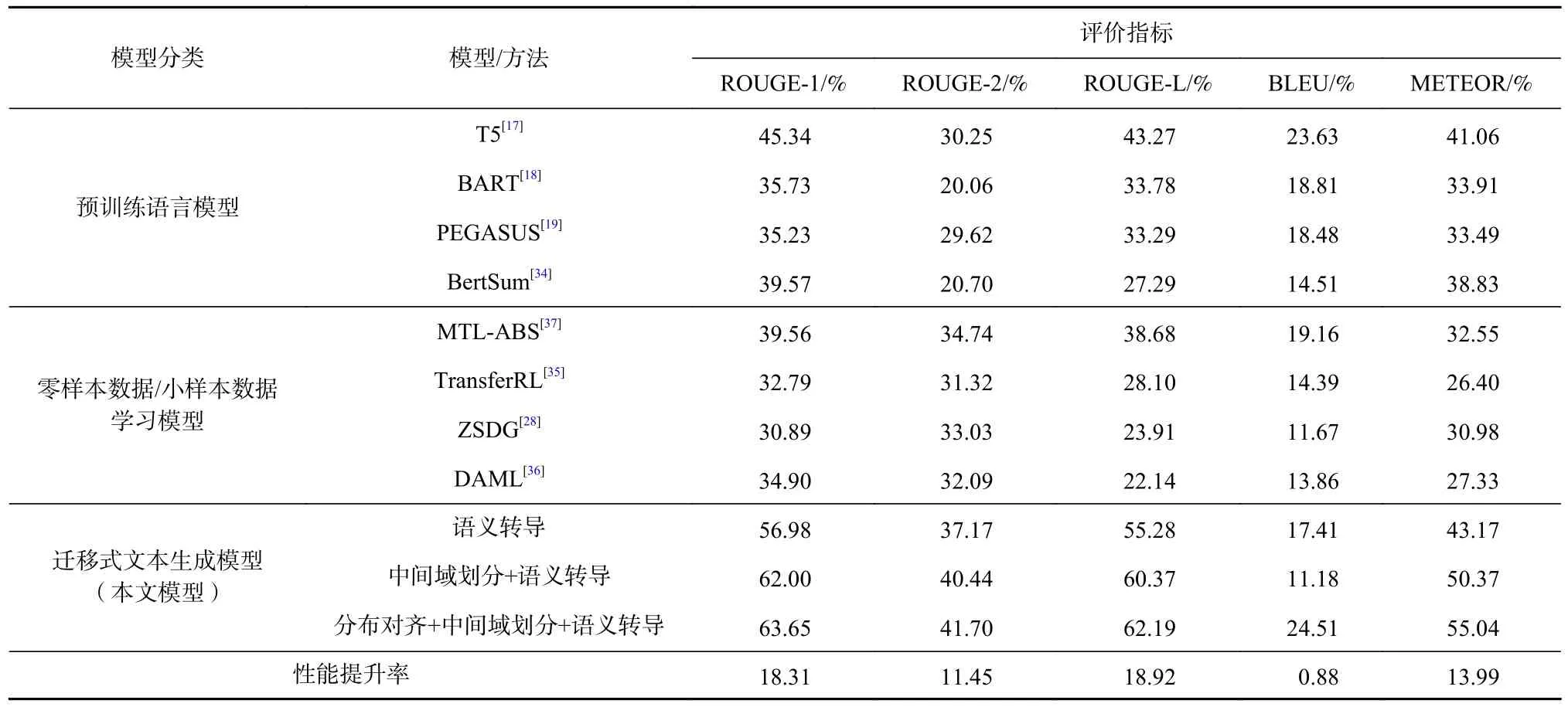
Table 4 Comparison of Experimental Results表4 實驗結果對比
另外,從圖10 可以看出,采用了“中間域劃分+語義轉導”組合的方法相比僅采用“語義轉導”的方法獲得了更高的評價指標得分,說明了在通過內容相似性綜合指標劃分的中間域中,目標域文本在生成過程中根據更具有語義相似性的相關源域數據,實現了更好的遷移式文本生成性能.同時,完整采用表3 中的“分布對齊+中間域劃分+語義轉導”的方法能夠取得模型最優的文本生成效果,意味著模型在獲得式(7)的領域數據分布對齊表示和通過式(16)進行零次學習語義要素傳導的復合遷移策略時,能在目標域沒有參考真值數據的情況下,在中間域中從相關源域中獲取有幫助的信息,從而在目標域上帶來最優的遷移式文本生成性能,同時指針生成器網絡也會提升生成文本的準確性.

Fig.10 Comparison results of the ablation experiments圖10 消融性實驗對比結果
3.3.4 對比實驗
如表2 所示,“電影”域作為目標域時模型的文本生成性能最差,因此針對“電影”領域,從預訓練語言模型(即T5,BART,PEGASUS,BertSum)和“零數據/小數據學習模型”(即TransferRL,ZSDG,DAML,MTL-ABS)2 方面,進一步比較本文提出的適用于零次學習語義要素傳導的文本生成模型方法與其他遷移式文本生成模型方法之間的性能,結果如表4 所示.
在經過領域數據分布對齊后,表4 中所有模型均采用圖5 所示的中間域數據進行訓練,且所有模型在訓練過程中都未使用目標域中的真值數據.其中,性能提升率是指本文提出的“分布對齊+中間域劃分+語義轉導”方法在各項性能評價指標得分上相較于對比模型中最高得分的提升差值.
具體地,如圖11 所示,在本文方法效果最差的“電影”領域作為目標域的情況下,首先,根據各項評價指標得分,本文提出的遷移式文本生成模型在對比中取得了最佳性能表現,其次是預訓練語言模型的方法,最后是零樣本數據/小樣本數據學習模型的方法.該現象可歸因于本文提出的遷移式方案首先基于圖4 按式(7)在文本表示層面通過領域數據分布對齊,緩解了領域間的數據分布差異,然后基于圖1通過改進文本生成模型結構,使其更加適用于式(16)進行的零次學習語義要素傳導,從而模型可以更為有效地從相關源域中獲取有助于遷移的先驗知識,提高模型在目標域中的文本生成性能.

Fig.11 Results of comparative experiments圖11 對比實驗結果
表4 中 的 預 訓 練 語 言 模 型T5, BART, PEGASUS,BertSum 已經在大規模語料庫中進行了預訓練,因此更多的先驗知識已經提前被納入此類預訓練語言模型的參數中.但是通過表4 可以看出,T5,BART,PEGASUS,BertSum 的各項評價指標得分均低于遷移式方法.由此可以發現,遷移式文本生成模型在領域可遷移性方面優于通過大規模語料訓練的預訓練語言模型,此現象可歸因為雖然預訓練語言模型通過大規模語料庫預訓練已經獲得了大量的領域先驗知識,但這些知識并不針對特定的目標領域及其任務.相比之下,遷移式文本生成模型首先通過領域數據分布對齊,從目標域角度降低了與其他相關源域數據在數據表示上的分布差異,并通過零次學習語義要素傳導,根據語義要素zsrc=(xsrc,ysrc,asrc)與ztar=(xtar,ytar,atar),建立跨域語義關聯xtar→ysrc,最大程度挖掘了不同領域數據間的語義相關性,確保目標域即使沒有參考真值數據,也可以通過語義要素傳導的方式,借助源域數據幫助目標域生成文本,從而針對特定的目標領域及其下任務有更好的領域遷移適應性.
最后,對于表4 中的零樣本數據/小樣本數據學習模型TransferRL,ZSDG,DAML/MTL-ABS 而言,這些模型分別采用了強化學習、零次學習或元學習方法進行遷移.但從圖11 可以看到,這些方法的各項評價指標得分均低于遷移式文本生成模型.該現象可歸因于本文在圖1 中對遷移式文本生成模型所采取的結構改進.具體地,如圖2 所示,改進后的文本生成模型通過加入Bi-LSTM 層解析文本序列化依賴關系,同時由Transformer 多頭注意力機加大對文本內部上下文觀察,借助指針生成器網絡處理未登錄詞匯,故模型可更大程度挖掘文本蘊含的語義;在此基礎上,通過構建數據級語義要素,將目標域中無標注新聞正文與源域中最相關的新聞標題進行關聯,并根據語義要素上的近似捕捉跨域文本的語義關聯性;由此,當給定目標域新聞正文xtar時,將參考源域中最為相關的真值新聞標題ysrc以輔助生成目標域中的新聞標題ytar,因而在ROUGE-1/2/L,BLEU,METEOR這些評價指標上也就有了更高的得分表現.
4 總結與展望
本文針對多領域的文本生成任務,提出了基于領域數據分布對齊和零次學習語義要素傳導的跨域遷移式文本生成模型,其主要原理是借助相關源域的已標注數據輔助目標域進行文本生成,以克服目標域中參考真值數據缺失的問題.本文提出的方法在傳統文本生成模型的基礎上主要改進了5 個方面:
1)從原始文本、摘要文本和正文語義注釋3 個方面,構建數據級語義要素;
2)在適用于語義要素傳導的生成模型結構上,構建增強型“編碼器-解碼器”,通過為不同語義要素構建的損失函數,從而使模型在生成過程中捕捉不同領域數據語義要素間的關聯性,同時在文本生成過程中通過指針生成器網絡提高生成文本的準確度;
3)在文本數據表示上,通過特征填充與分布對齊使數據在表示層面減少分布差異性;
4)通過文本相似性綜合指標將源域和目標域數據劃分為中間域,從而為目標域數據進行更為合適的源域數據選擇;
5)在基于語義要素的語義轉導方法上,由語義要素之間的相似性使目標域數據在文本生成過程中參考最具關聯性的源域已標注數據,由此不依賴目標域自身的已標注真值.
實驗結果表明,本文提出的遷移式方法可以有效地應用于實際的新聞標題生成場景中,通過領域數據遷移解決目標域真值數據缺失問題.
未來工作有2 個方面值得進一步探討:1)當給定一個目標域時,相關源域的選擇對最終遷移式生成性能來說非常關鍵.因此,需要進一步研究更具有關聯性的領域數據選擇方法.2)源域數據在遷移過程中往往也會提供與目標域不相關的噪聲信息,從而影響遷移效果導致“負遷移”.因此如何避免“負遷移”問題,也是值得進一步研究的方向.
作者貢獻聲明:馬廷淮提出指導意見并修改論文;于信負責完成實驗,并撰寫、修改論文;榮歡提出實驗方案設計和寫作思路.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
