基于2 階段集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法
2023-12-15 04:47:48趙興旺張珧溥梁吉業(yè)
計算機研究與發(fā)展 2023年12期
趙興旺 張珧溥 梁吉業(yè)
(山西大學計算機與信息技術學院 太原 030006)
(計算智能與中文信息處理教育部重點實驗室(山西大學) 太原 030006)(zhaoxw84@163.com)
社團結(jié)構(gòu)是復雜網(wǎng)絡的一個重要特征,即同一個社區(qū)內(nèi)節(jié)點之間連接緊密而不同社區(qū)間節(jié)點之間連接稀疏[1].例如,社交網(wǎng)絡的社區(qū)代表具有相似特征的人群,蛋白質(zhì)交互網(wǎng)絡中社區(qū)代表具有相似功能的生物組織模塊,萬維網(wǎng)中不同的社區(qū)代表不同功能的網(wǎng)頁.社區(qū)發(fā)現(xiàn)是復雜網(wǎng)絡分析挖掘中的重要任務之一,對于網(wǎng)絡拓撲結(jié)構(gòu)分析、功能分析和行為預測具有重要意義,已在社會學、生物信息學、交通系統(tǒng)等領域得到了廣泛應用[2-4].例如,在社交網(wǎng)絡中,社區(qū)發(fā)現(xiàn)有助于分析個體的行為模式、信息的傳播方式和網(wǎng)絡的變化趨勢[5];在生物網(wǎng)絡中,社區(qū)發(fā)現(xiàn)有助于分析屬于共同功能模塊的蛋白質(zhì)之間的相互作用[6];在交通網(wǎng)絡中,社區(qū)發(fā)現(xiàn)可以通過將城市道路網(wǎng)絡劃分為多個支線網(wǎng)絡來實現(xiàn)對城市交通網(wǎng)絡的區(qū)域控制,從而緩解城市交通擁堵問題[7].
針對不同的應用領域,研究者近年來已經(jīng)開展了廣泛研究,并提出了系列社區(qū)發(fā)現(xiàn)算法,主要包括:基于劃分的方法[8]、基于模塊度的方法[9-10]、基于譜的方法[11]、基于動力學的方法[12]、基于標簽傳播的方法[13]等.已有算法大多適用于單層網(wǎng)絡,然而現(xiàn)實世界中由多種類型節(jié)點及其連邊關系組成的多層網(wǎng)絡存在更為普遍[14].例如,社交網(wǎng)絡中的個體之間可能存在不同類型的社交關系,如好友、關注、評論、轉(zhuǎn)發(fā)等;在生物網(wǎng)絡中,對于某些生物體來說,完整的蛋白質(zhì)與蛋白質(zhì)相互作用涉及數(shù)千種蛋白質(zhì)分子之間多種不同的相互作用模式;在航空運輸系統(tǒng)中,通過直飛航班對機場之間的連接建模,不同的商業(yè)航空公司可以被視為機場之間的不同連接模式.與單層網(wǎng)絡相比,多層網(wǎng)絡結(jié)構(gòu)具有更加豐富的拓撲信息,有助于更為準確地探測網(wǎng)絡中蘊含的社區(qū)結(jié)構(gòu).但是不同網(wǎng)絡層蘊含的社區(qū)結(jié)構(gòu)之間既存在一定的相關性又存在異質(zhì)性,為社區(qū)發(fā)現(xiàn)任務帶來了新的挑戰(zhàn).
近年來,一些學者針對多層網(wǎng)絡的社區(qū)發(fā)現(xiàn)問題已經(jīng)開展了有益探索,提出了相應的算法[15-16].其中,基于聚合的方法由于實現(xiàn)簡單、具有良好的可擴展性等優(yōu)點,得到了廣泛關注.第1 類基于聚合的方法為網(wǎng)絡聚合,直接將多層網(wǎng)絡合并為單層網(wǎng)絡,然后利用傳統(tǒng)社區(qū)發(fā)現(xiàn)算法實現(xiàn)社區(qū)劃分.該類方法雖然降低了社區(qū)發(fā)現(xiàn)后續(xù)研究的難度,但是在聚合過程中丟失了不同層網(wǎng)絡結(jié)構(gòu)的獨特性,造成社區(qū)結(jié)果的不準確.第2 類方法為基于集成學習的方法,首先在每層網(wǎng)絡上分別利用傳統(tǒng)社區(qū)發(fā)現(xiàn)算法進行社區(qū)劃分,然后基于集成學習機制將每層的社區(qū)劃分融合得到最終的社區(qū)結(jié)構(gòu).這類方法在不同網(wǎng)絡層得到基社區(qū)劃分后,往往各層社區(qū)劃分分別進行融合或者不同層的社區(qū)劃分進行統(tǒng)一融合,忽視了不同層社區(qū)之間的異質(zhì)性;另一方面在融合過程中忽略了不同的基社區(qū)結(jié)構(gòu)和社區(qū)劃分之間的重要性,難以獲得準確的社區(qū)結(jié)構(gòu)[17].
針對上述問題,本文提出了一種基于2 階段集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法,旨在有效融合不同網(wǎng)絡層獲得的基社區(qū)劃分之間的信息,提高社區(qū)發(fā)現(xiàn)結(jié)果的準確性和可解釋性.在第1 階段,分別以各層網(wǎng)絡生成的基社區(qū)劃分為主,并結(jié)合其他各層網(wǎng)絡得到的基社區(qū)劃分中最優(yōu)的社區(qū)劃分結(jié)構(gòu)信息進行局部集成;在第2 階段,首先對得到的局部社區(qū)劃分及各個社區(qū)結(jié)構(gòu)的重要性度量,然后進行全局加權(quán)集成得到最終的社區(qū)劃分結(jié)果.
1 相關工作
1.1 基于擴展的方法
基于擴展的方法主要指將單層網(wǎng)絡的社區(qū)發(fā)現(xiàn)方法直接擴展到多層網(wǎng)絡,通常通過優(yōu)化社區(qū)質(zhì)量評估函數(shù)來實現(xiàn).基于模塊度函數(shù)優(yōu)化是探測社區(qū)結(jié)構(gòu)的經(jīng)典方法,其核心思想是通過最大化模塊度來獲得社區(qū)劃分結(jié)果.例如,Mucha 等人[18]將模塊度擴展到了多層網(wǎng)絡,開發(fā)了一種多層網(wǎng)絡社區(qū)質(zhì)量函數(shù)的廣義框架用于檢測多層網(wǎng)絡的社區(qū)結(jié)構(gòu).該算法就是通過優(yōu)化多層模塊度擴展了傳統(tǒng)的Louvain算法,從而得到一個多層模塊度高的社區(qū)劃分.Ma等人[19]提出了一種用于多層網(wǎng)絡社區(qū)檢測的定量函數(shù)——多層模塊化密度,解決了模塊度的分辨率限制問題,為社區(qū)發(fā)現(xiàn)算法的設計提供了理論基礎,并提出了一種半監(jiān)督聯(lián)合非負矩陣分解的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法S2-jNMF.該算法用貪婪搜索方法提取多層網(wǎng)絡所有層中連接良好的子圖作為先驗信息,然后將與多層網(wǎng)絡相關的矩陣和先驗信息聯(lián)合分解為一個基矩陣和一個多系數(shù)矩陣用于社區(qū)發(fā)現(xiàn).LART[20]是一種基于局部自適應隨機游走的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法,它首先對每一層網(wǎng)絡運行不同的隨機游走;然后利用每層轉(zhuǎn)移概率獲得節(jié)點之間的不同度量;最后,采用層次聚類方法生成社區(qū)劃分,最終在多層模塊度的最優(yōu)值對應的水平上得到社區(qū)劃分結(jié)果.Laishram 等人[21]提出了一種新穎的基于采樣的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法,使用來自探索成本低的層的信息來幫助探索成本高的層的信息.盡管該類方法通過對單層網(wǎng)絡社區(qū)發(fā)現(xiàn)方法進行直接擴展可以對多層網(wǎng)絡進行有效社區(qū)發(fā)現(xiàn),但是存在著需要設置的參數(shù)較多、時間復雜度較高、易受噪聲影響等缺點.
1.2 基于聚合的方法
為了降低社區(qū)檢測的難度,基于多層網(wǎng)絡的聚合結(jié)構(gòu)進行社區(qū)發(fā)現(xiàn)的相關研究具有實現(xiàn)簡單、可擴展性強的特點.這些研究主要包括基于網(wǎng)絡聚合和基于集成學習2 類思路.
基于網(wǎng)絡聚合的方法是將一個多層網(wǎng)絡壓縮成單個網(wǎng)絡,然后采用單層網(wǎng)絡的社區(qū)發(fā)現(xiàn)算法對其進行社區(qū)檢測.最簡單的策略就是對鄰接矩陣進行加權(quán),其中2 個節(jié)點之間的權(quán)值為它們在多層網(wǎng)絡中相連的層數(shù).Berlingerio 等人[22]對簡單的加權(quán)策略進行了修改并提出了基于共同鄰居數(shù)的鄰接矩陣的加權(quán)策略,這種策略不再考慮2 個節(jié)點之間的直接聯(lián)系,而是關注它們的鄰居,共同鄰居數(shù)越多則越可能在同一個社區(qū).Zhu 等人[23]進一步考慮了每層網(wǎng)絡的重要性,將單層網(wǎng)絡之間的相關性與單層網(wǎng)絡的重要性密切聯(lián)系起來,若某一單層網(wǎng)絡與其他的單層網(wǎng)絡之間的相關性更大,則表明其重要性更強.同時判斷2 個節(jié)點之間是否存在路徑來衡量節(jié)點相似度,然后利用單層網(wǎng)絡重要性和節(jié)點相似度構(gòu)造統(tǒng)一矩陣,最后再用單層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法得到最終的社區(qū)劃分結(jié)果.基于網(wǎng)絡聚合方法在聚合過程中丟失了不同層網(wǎng)絡結(jié)構(gòu)的獨特性,造成社區(qū)結(jié)果的不準確.
基于集成學習的方法首先利用傳統(tǒng)算法對多層網(wǎng)絡的各個層進行社區(qū)發(fā)現(xiàn),然后基于集成學習機制將各層得到的社區(qū)劃分結(jié)果進行融合得到最終的社區(qū)劃分[17].Tang 等人[24]提出了主模塊化最大化方法,首先通過模塊化最大化從多層網(wǎng)絡的每個層中提取結(jié)構(gòu)特征,然后對這些特征進行跨層次分析,采用PCA 技術找到低維嵌入,使從所有層中提取的特征彼此高度相關,最后通過k-means 聚類算法找到社區(qū)劃分.Berlingerio 等人[25]提出了一種基于頻繁模式挖掘的多層網(wǎng)絡的社區(qū)發(fā)現(xiàn)算法,能夠從單層社區(qū)成員中提取頻繁的封閉項集來提取多層社區(qū).首先用單層社區(qū)發(fā)現(xiàn)算法獲得每層網(wǎng)絡上的社區(qū),然后用頻繁封閉項集算法將至少在最少數(shù)量的層上屬于同一社區(qū)的節(jié)點分配到同一社區(qū).Tagarelli 等人[17]提出了一種新的基于模塊化優(yōu)化的集成的多層社區(qū)發(fā)現(xiàn)算法,此方法在尋找共識社區(qū)結(jié)構(gòu)時,不僅捕獲了節(jié)點的原型社區(qū)成員,而且能夠保存多層網(wǎng)絡的拓撲信息,在獲得共識解的過程中將多層網(wǎng)絡的拓撲上界和拓撲下界作為搜索空間,共識函數(shù)也是通過基于模塊化優(yōu)化的方法,同時考慮了社區(qū)內(nèi)和社區(qū)間的連通性.這類方法在得到不同層的社區(qū)劃分后,往往各層社區(qū)劃分分別進行融合或者不同層的社區(qū)劃分進行統(tǒng)一融合.由于每一層網(wǎng)絡中節(jié)點之間的交互方式以及社區(qū)結(jié)構(gòu)的不同,進行簡單集成容易忽視不同層社區(qū)之間的異質(zhì)性;而且在融合過程中忽略了不同的基社區(qū)結(jié)構(gòu)和社區(qū)劃分之間的重要性,難以獲得準確的社區(qū)結(jié)果.
2 基于集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法
本節(jié)首先對基于集成學習的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)問題進行了描述,接著對本文提出的基于2 階段集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法進行了介紹.
2.1 問題描述
一個多層網(wǎng)絡可以定義為
其 中G={Gα|α ∈{1,2,…,L}}表 示L層 網(wǎng) 絡 構(gòu) 成 的 集合,Gα=(Vα,Eα) 為 多層網(wǎng)絡中的第 α 層,Vα?V={v1,v2,…,vN},Vα表示第 α層的節(jié)點集,V為多層網(wǎng)絡的所有節(jié)點的集合,Eα?Vα×Vα表 示第 α層內(nèi)節(jié)點之間連接的邊集; A表示任意2 個不同層的節(jié)點之間的連接,可以表示為
即Eα中 的元素表示層內(nèi)頂點間連接,Eαβ表示層間頂點間的連接.本文主要討論的對象為所有層共享相同節(jié)點集的多層網(wǎng)絡,即在給定的多層網(wǎng)絡GL=(G,A) 中,對于每一層Gα=(Vα,Eα)∈G都 有Vα=V(V={v1,v2,…,vN}), 但是每一層內(nèi)的邊集不同,即Gα=(V,Eα).另外,對于層間連接
即所有層的節(jié)點是對齊的.如圖1 為一個多層網(wǎng)絡示意圖,由3 層網(wǎng)絡組成,每層均包括6 個節(jié)點,每層內(nèi)的連邊表示節(jié)點間的一種關系,層間的虛線表示不同層的節(jié)點是對齊的.
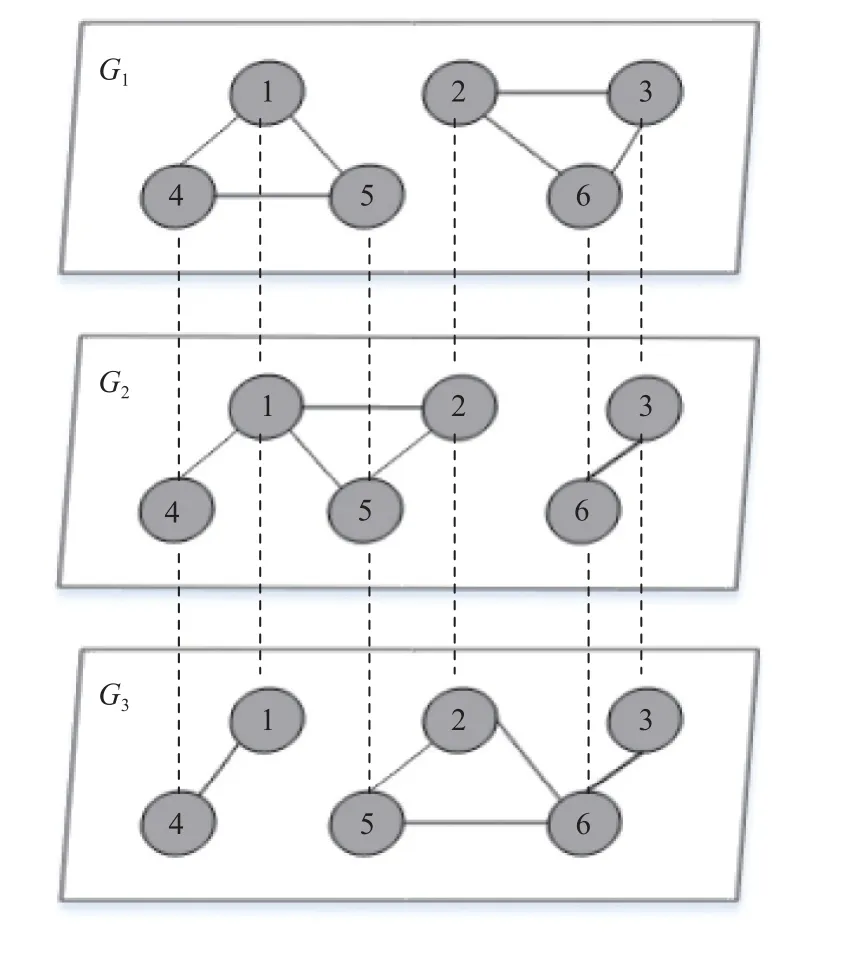
Fig.1 An example of multi-layer network圖1 多層網(wǎng)絡示例
給定一個L層的多層網(wǎng)絡 GL=(G,A),針對每層網(wǎng)絡Gα=(V,Eα)分別多次利用傳統(tǒng)單層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法得到該層的社區(qū)結(jié)構(gòu)為其中表示第 α 層 網(wǎng)絡共生成Mα個基社區(qū)劃分,則多層網(wǎng)絡 GL的基社區(qū)結(jié)構(gòu)表示為B={B1,…,Bα,…,BL},基于集成的社區(qū)發(fā)現(xiàn)算法的目的是基于各層網(wǎng)絡產(chǎn)生的基社區(qū)結(jié)構(gòu)B={B1,…,Bα,…,BL},通過集成函數(shù)獲得給定多層網(wǎng)絡 GL=(G,A)的最終社區(qū)劃分結(jié)果C*={C1,C2,…,Ck} ,且 ∪ki=1Ci=V,Ci∩Cj=?, 其 中k表示最終社區(qū)個數(shù).多層網(wǎng)絡總的社區(qū)結(jié)構(gòu)劃分方案個數(shù)為
2.2 基于2 階段集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法
本文算法的主要步驟如圖2 所示,主要包括基社區(qū)劃分生成、局部集成、全局加權(quán)集成3 個步驟.具體地:1)基社區(qū)劃分生成是指在多層網(wǎng)絡的每一層分別多次利用相同的傳統(tǒng)單層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法產(chǎn)生一組基社區(qū)劃分;2)分別基于單層網(wǎng)絡生成的基社區(qū)劃分和其他各層網(wǎng)絡得到的基社區(qū)劃分中最優(yōu)的社區(qū)劃分信息對各層進行局部集成得到局部社區(qū)劃分結(jié)果;3)分別對局部集成得到的社區(qū)劃分及各個社區(qū)的重要性進行度量并進行全局加權(quán)集成得到最終社區(qū)結(jié)果.
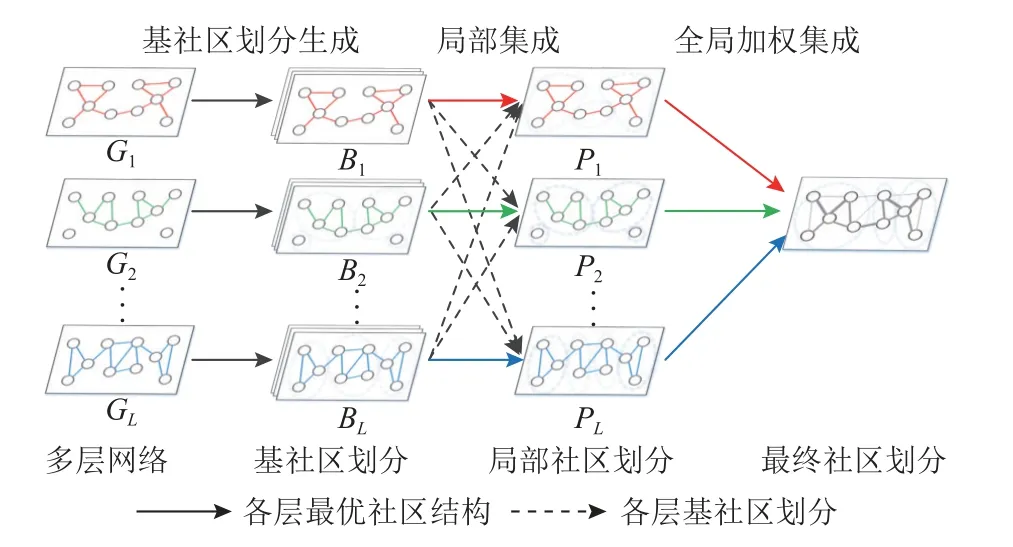
Fig.2 Illustration of our proposed algorithm process圖2 本文算法流程示意圖
2.2.1 基社區(qū)劃分生成
該步驟的目的是為不同層的網(wǎng)絡分別生成多組準確性高、差異性強的基社區(qū)劃分.給定一個L層的多層網(wǎng)絡 GL=(G,A) ,在每層網(wǎng)絡Gα=(V,Eα)分別多次利用傳統(tǒng)單層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法獲得該層的社區(qū)劃分表示第 α層網(wǎng)絡共生成Mα個基社區(qū)劃分.為了生成準確性高、多樣性強的基社區(qū)劃分,本文采用經(jīng)典的LM 算法[10]對每層網(wǎng)絡分別進行社區(qū)發(fā)現(xiàn).
2.2.2 局部集成
由于不同層產(chǎn)生的基社區(qū)劃分之間既存在異質(zhì)性,又存在一定的相關性.因此,在局部社區(qū)劃分集成階段各層結(jié)合其他各層的最優(yōu)社區(qū)結(jié)構(gòu)信息進行集成.本文中將各個層中最優(yōu)的社區(qū)劃分結(jié)果加入其他層,以此達到提升局部模型性能的目的.模塊度是社區(qū)劃分質(zhì)量優(yōu)劣的評價指標[26].模塊度反映了網(wǎng)絡社區(qū)結(jié)構(gòu)內(nèi)部連接的強弱,指的是社區(qū)內(nèi)的邊占所有邊的比例減去在同樣的社區(qū)結(jié)構(gòu)下隨機放置社區(qū)內(nèi)部的邊占所有邊的比例的期望值,定義為
其中m表示網(wǎng)絡的總邊數(shù),A表 示網(wǎng)絡的鄰接矩陣,ki和kj分 別代表節(jié)點vi和vj的 度,當節(jié)點vi和vj屬于同一個社區(qū)時, δ (i,j)=1, 否則, δ(i,j)=0.模塊度越高,則社區(qū)劃分質(zhì)量越高.針對第 α層網(wǎng)絡獲得的基社區(qū)劃分Bα={B1α,B2α,…,BαMα},可以通過計算各個劃分下的模塊度指標來選出第 α層中最優(yōu)的基社區(qū)劃分.因此,在進行局部集成時,每一層的基社區(qū)劃分由該層產(chǎn)生的Mα個 基社區(qū)和其他L-1層分別選出的最優(yōu)社區(qū)劃分組成.基于基社區(qū)劃分信息,從局部角度每層分別構(gòu)造節(jié)點之間的共協(xié)矩陣Aα(1 ≤α ≤L),記為
其中nij表示在第 α層中節(jié)點vi和vj在參與集成的基社區(qū)劃分中被分配到同一個社區(qū)的數(shù)量,Mα+L-1是參與集成的社區(qū)劃分的數(shù)量.基于共協(xié)矩陣,利用層次聚類即可得到每層的局部社區(qū)劃分結(jié)果Pα(1 ≤α ≤L), 則多層網(wǎng)絡 GL的局部社區(qū)劃分結(jié)果記為E={P1,P2,…,PL}.
2.2.3 全局加權(quán)集成
在集成過程中,不同社區(qū)劃分以及社區(qū)的優(yōu)劣均會對最終社區(qū)的檢測產(chǎn)生不同的影響.本節(jié)通過社區(qū)劃分和社區(qū)質(zhì)量進行評價來對集成過程進行加權(quán).局部社區(qū)劃分結(jié)果E中,每層網(wǎng)絡的Pα的優(yōu)劣通過該劃分方案運用到其他層網(wǎng)絡上的模塊度來衡量,定義為
其中mβ表 示第 β 層 網(wǎng)絡的總邊數(shù),Aβ表示第 β層網(wǎng)絡的鄰接矩陣,kβi和kβj分別代表節(jié)點vi和vj在 第 β層網(wǎng)絡中 的 度,當 節(jié) 點vi和vj在Pα屬 于 同 一 個 社 區(qū) 時,δα(i,j)=1, 否則, δα(i,j)=0.如果Q(Pα,Gβ)越高,則表示相對于第 β層Pα的質(zhì)量越優(yōu).因此,在全局集成中第 α 層 獲得的Pα的權(quán)重定義為
然 后,對 E={P1,P2,…,PL} 中 各 層Pα(1 ≤α ≤L)的 權(quán)重進行歸一化,則有
信息熵是信息論中用于度量系統(tǒng)不確定性的一種重要度量方法.如果一個社區(qū)結(jié)構(gòu)相對其他劃分越穩(wěn)定,則表明該社區(qū)的不確定性越小、可靠性越強,該社區(qū)在集成過程中的權(quán)重越大.
局部社區(qū)劃分結(jié)果 E={P1,P2,…,PL} 中第 α層的社 區(qū) 劃 分 記 為Pα={C1α,C2α,…,Cnαα}, 其 中Ciα表 示Pα中的第i個社區(qū),nα表示Pα中 社區(qū)的數(shù)量.因此, E中所有社區(qū)可以表示為
其中Ci表 示第i個社區(qū),nC表 示 E中所有社區(qū)的總個數(shù).
給定一個社區(qū)Ci∈C 和網(wǎng)絡層Gα的Pα∈E,如果社區(qū)Ci不 屬于Pα, 那么Ci中 的節(jié)點可能屬于Pα中的多個社區(qū),Ci相 對于Pα的 不確定性可以通過考慮Ci中的對象在Pα中各個社區(qū)中的分布來進行計算.那么,社區(qū)Ci關 于第 α 層網(wǎng)絡Gα的Pα的不確定性可表示為
其中
其中nα表示社區(qū)劃分Pα中的社區(qū)數(shù)量,Cαj表示Pα中的第j個社區(qū),表示2 個社區(qū)中共有節(jié)點的個數(shù), |Ci|表 示Ci中 節(jié) 點的 個 數(shù).p(Ci,Cαj)∈[0,1],所以Hα(Ci)∈[0,+∞).
因此,Ci關 于多層網(wǎng)絡 GL的局部社區(qū)劃分 E的不確定性可以通過Ci關 于 E中每層網(wǎng)絡的社區(qū)劃分結(jié)構(gòu)的不確定性的和來表示,即
基于信息熵來衡量每個社區(qū)關于局部社區(qū)劃分E的不確定性,那么進一步可通過歸一化來衡量E中每個社區(qū)的權(quán)重,即
由于HE(Ci)∈[0,+∞) , 所以W(Ci)∈[0,1],即一個社區(qū)的不確定越小,則該社區(qū)的可靠性就越高,在集成過程中的權(quán)重越大.
基于式(8)(13)給出的社區(qū)劃分以及社區(qū)的權(quán)重,從全局角度構(gòu)造節(jié)點之間的加權(quán)共協(xié)矩陣,表示為
其中
其中Clsα(vi)表 示節(jié)點vi在Pα中所屬社區(qū)的標簽.
基于加權(quán)共協(xié)矩陣,通過層次聚類獲得多層網(wǎng)絡 GL的最終社區(qū)劃分結(jié)果C*={C1,C2,…,Ck}.
基于以上對各階段集成過程的描述,本文提出的基于2 階段集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法描述如算法1.
算法1.基于2 階段集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法.
輸入:多層網(wǎng)絡 GL=(G,A) ,社區(qū)劃分個數(shù)k,各層網(wǎng)絡社區(qū)基劃分次數(shù)M;
輸出:多層網(wǎng)絡 GL的最終社區(qū)劃分結(jié)果C*={C1,C2,…,Ck}.
① 在每層網(wǎng)絡上利用傳統(tǒng)的LM 社區(qū)發(fā)現(xiàn)算法獲得基社區(qū)劃分結(jié)果,記為B={B1,B2,…,BL};
② forBα∈B
④ {B1,…,Bα-1,Bα+1,…,BL}←; /*將添加到B中除Bα外的其他集合中*/
⑤ end for
⑥ forGα∈G
⑦Aα←Bα; /*根據(jù)式(5)計算共協(xié)矩陣*/
⑧Pα←Aα;/*利用層次聚類獲得局部社區(qū)劃分*/
⑨ end for
⑩ forPα∈E
?W(Pα)←Pα;/*根據(jù)式(7)計算局部社區(qū)劃分的權(quán)重*/
? end for
?(Pα)←W(Pα);/*根據(jù)式(8)對權(quán)重進行歸一化 */
? forCi∈E
?HE(Ci) ←Ci;/*根據(jù)式(12)計算社區(qū)不確定性*/
? end for
?W(Ci)←HE(Ci);/*根據(jù)式(13)計算各個社區(qū)權(quán)重*/
? 根據(jù)式(14)構(gòu)造加權(quán)共協(xié)矩陣,并利用層次聚類得到最終社區(qū)結(jié)構(gòu)C*={C1,C2,…,Ck}.
2.3 時間復雜度分析
本文提出的基于2 階段集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法主要包括3 個步驟:1)基社區(qū)劃分生成;2)局部集成;3)全局加權(quán)集成.
在步驟1 中采用LM 算法[10],假設一個單層網(wǎng)絡的邊的數(shù)量為e,則其時間復雜度為O(e),所以步驟1的時間復雜度為O(LMe).步驟2 中主要包括構(gòu)造共協(xié)矩陣,因為Bα中 的社區(qū)劃分數(shù)量為Mα+L-1,因此其時間復雜度為O((Mα+L-1)N2);此外,利用層次聚類算法獲得局部社區(qū)劃分結(jié)果的時間復雜度為O(N2),所以步驟2 的時間復雜度為O(L(Mα+L-1)N2+LN2).步驟3 通過信息熵來計算各個社區(qū)的穩(wěn)定性,假設步驟2 得到的總社區(qū)數(shù)量為nC,則計算社區(qū)不穩(wěn)定性的時間復雜度為O(nC),基于共協(xié)矩陣利用層次聚類計算最終社區(qū)劃分結(jié)果的時間復雜度為O(N2),所以步驟3 的時間復雜度為O(nC+N2).因此,算法的總時間復雜度為O(LMe+L(Mα+L-1)N2+LN2+nC+N2).由于L,M,nC均 小于節(jié)點個數(shù)N,所以算法的總時間復雜度為O(N2).
3 實驗分析
為了驗證本文算法的有效性,與已有的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法在人工合成多層網(wǎng)絡和12 個真實多層網(wǎng)絡數(shù)據(jù)集上進行了實驗比較分析.
3.1 數(shù)據(jù)集
3.1.1 人工合成多層網(wǎng)絡
為了生成人工合成多層網(wǎng)絡數(shù)據(jù),本文采用了Bazzi 等人[27]提出的算法.算法參數(shù)設置為:網(wǎng)絡的層數(shù)L= 3,5,7,每層網(wǎng)絡的規(guī)模N= 1 000 或N=5 000,社區(qū)個數(shù)分別為10 和50,其中每個節(jié)點都出現(xiàn)在每一層中,即在這些網(wǎng)絡中分別總共有3 000,5 000,7 000,15 000,25 000,35 000 個節(jié)點,節(jié)點的度設置為其算法默認值,即最小度為3,最大度為150.混合參數(shù) μ∈[0,1], μ的值越接近1,生成網(wǎng)絡的隨機性越強.參數(shù)∈[0,1]表 示層間相關系數(shù),當=0時,表示產(chǎn)生的多層網(wǎng)絡各層之間社區(qū)劃分是相互獨立;當=1時,所產(chǎn)生的多層網(wǎng)絡各層之間的社區(qū)劃分是相同的.由于本文算法為通過集成策略產(chǎn)生統(tǒng)一的社區(qū)劃分,因此選擇參數(shù)=1.
3.1.2 真實多層網(wǎng)絡
實驗中采用的真實多層網(wǎng)絡數(shù)據(jù)集的基本情況如表1 所示.所有真實網(wǎng)絡數(shù)據(jù)的社區(qū)劃分未知.
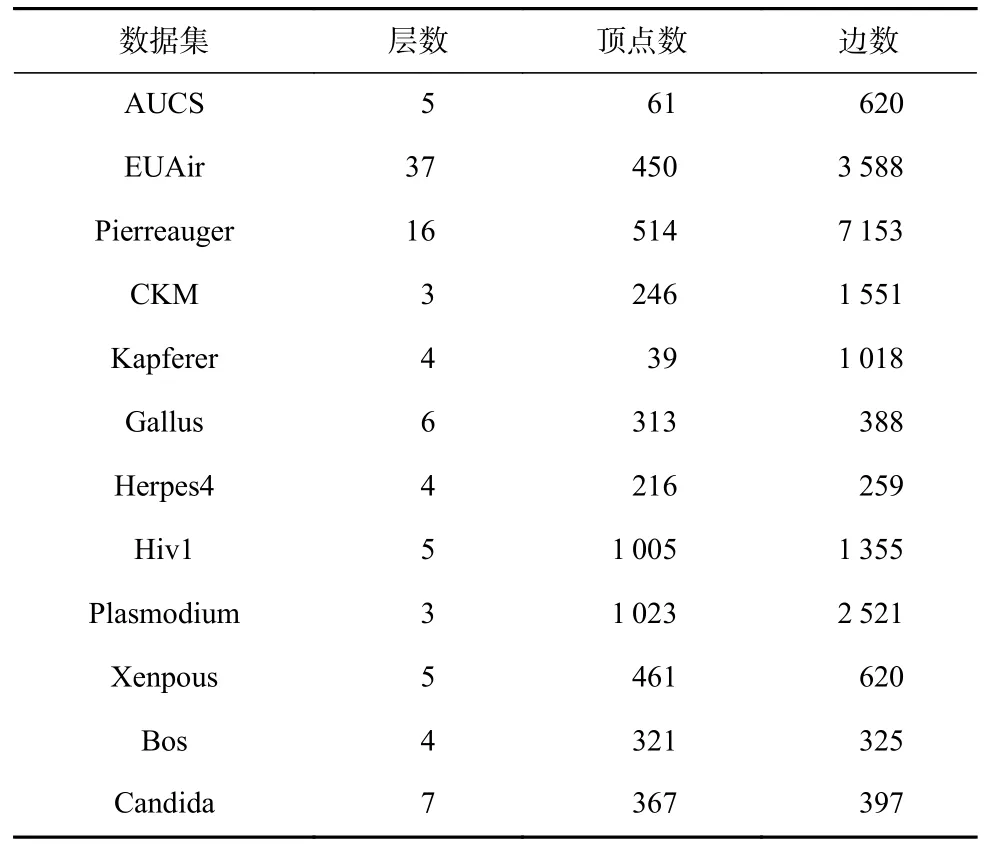
Table 1 Real Multilayer Networks表1 真實多層網(wǎng)絡
AUCS 數(shù)據(jù)集描述某大學研究部門的61 名員工節(jié)點(包括教授、博士后、博士生和行政人員)之間的Facebook 關系、午餐關系、合作關系、休閑關系和工作關系[28].EUAir 數(shù)據(jù)集是歐洲航空交通網(wǎng)絡,每層網(wǎng)絡對應在歐洲運營的不同航空公司[29].Pierreauger數(shù)據(jù)集表示天文臺科學家之間的協(xié)作關系,每一層代表一種協(xié)作任務[30].CKM 數(shù)據(jù)集由美國4 個城鎮(zhèn)的246 名醫(yī)生組成,主要討論網(wǎng)絡關系對醫(yī)生用藥決策的影響,包括通常找誰獲取用藥建議、經(jīng)常與誰討論和與誰關系最好3 層網(wǎng)絡[30].Kapferer 網(wǎng)絡中節(jié)點為裁縫店的工人,關系為他們之間的工作和友誼互動[31].
另外,在包含相互作用數(shù)據(jù)集的生物通用存儲庫中選取了Gallus[32],Herpes4[33], Hiv1[33], Plasmodium[32],Xenopus[33], Bos[32],Candida[32]共7 個多層網(wǎng)絡數(shù)據(jù)集.這些網(wǎng)絡代表蛋白質(zhì)之間的相互作用,不同的層對應于不同性質(zhì)的相互作用,即直接作用、物理關聯(lián)、共定位、關聯(lián)、抑制、增強和合成遺傳相互作用.每種生物體所對應的層數(shù)為3~7 不等.
3.2 評價指標
當數(shù)據(jù)集的真實社區(qū)結(jié)果未知時,采用Mucha等人[18]提出的多層網(wǎng)絡模塊度QM來評價多層網(wǎng)絡的社區(qū)質(zhì)量,定義為
其中 μ表示多層網(wǎng)絡中的連接的數(shù)量,分辨率 γ以控制每層網(wǎng)絡的社區(qū)規(guī)模和數(shù)量.Ai jα表 示網(wǎng)絡第 α層的鄰接矩陣節(jié)點vi和 節(jié)點vj之 間的連接關系, δαβ在第α 層和第 β 層 為同一層時為1,否則為0; δij在 節(jié)點vi和節(jié)點vj為 同層節(jié) 點時為1,否則為0.Cjαβ表 示 α 層 和β層之間與節(jié)點vj的 層間連邊數(shù),表示節(jié)點vi在 α 層上的度,表示 α層的總邊數(shù).如果節(jié)點vi和 節(jié) 點vj的 社 區(qū) 分 布 相 同,則 δ(giα,gjβ)=1,否 則為0.
對于有真實社區(qū)劃分的數(shù)據(jù)集,利用標準化互信息(NMI)[34]來評價社區(qū)劃分結(jié)果的質(zhì)量,NMI定義為
其中X和Y分別表示數(shù)據(jù)集的真實社區(qū)劃分結(jié)果和算法得到的社區(qū)劃分結(jié)果,cX和cY分別表示X和Y中的社區(qū)數(shù)量,是一個混淆矩陣,其元素Nij表示在X的社區(qū)i與Y的社區(qū)j中共同出現(xiàn)的節(jié)點數(shù)量,Ni表示的第i行的元素的和,Nj表示的第j列的元素的和,N表示節(jié)點數(shù)量.NMI(X,Y)的范圍為[0,1],如果X和Y完全相同,則NMI(X,Y) =1;如果X和Y完全不同,則NMI(X,Y)=0.
3.3 對比方法及參數(shù)設置
本文算法與已有多層網(wǎng)絡社區(qū)發(fā)現(xiàn)基線方法進行了比較,代表性方法包括PMM[24],SCML[35],PM[36],CoReg[37],AWP[38],EVM[39].
根據(jù)已有文獻實驗分析中的建議,對基線方法的參數(shù)進行了設置.其中,本文方法與基線方法PMM,SCML,PM,CoReg,AWP 共同的參數(shù)為社區(qū)個數(shù)k,為了比較的公平性,對于社區(qū)已知的人造網(wǎng)絡個數(shù)k均設置為真實的社區(qū)個數(shù),對于社區(qū)未知的真實網(wǎng)絡將社區(qū)個數(shù)k設置為其中N表示節(jié)點個數(shù),各個算法分別在不同的k值下運行,并從結(jié)果中選取最優(yōu)值進行比較.PMM 算法中結(jié)構(gòu)特征的數(shù)量可以是1~(N-2)(N為節(jié)點總數(shù))之間的任意數(shù)字,根據(jù)建議,對于人工多層網(wǎng)絡和真實多層網(wǎng)絡均設置了2 個值,人工多層網(wǎng)絡比較低的常數(shù)為50,真實多層網(wǎng)絡比較低的常數(shù)為10,用PMMl來表示;另一個是根據(jù)節(jié)點總數(shù)來設定的值,2 類數(shù)據(jù)集上都設置為N/2,用PMMh來表示,k-means 算法執(zhí)行的次數(shù)設置為10.SCML 算法中正則化參數(shù) λ= 0.5;PM 算法中參 數(shù)p=-10 ; CoReg 算 法 正 則 化 參 數(shù) λ=0.01;EVM算法正則化參數(shù) γ=0.5.本文算法中各層網(wǎng)絡生成的基社區(qū)劃分個數(shù)M= 10.
3.4 實驗結(jié)果分析
3.4.1 人工網(wǎng)絡實驗結(jié)果分析
在不同的參數(shù)下生成了60 個不同的人工合成網(wǎng)絡,針對各個網(wǎng)絡,對比算法均在不同參數(shù)設置下運行10 次,然后取結(jié)果的平均值進行比較.各個算法在不同人工網(wǎng)絡的NMI值隨網(wǎng)絡參數(shù) μ的變化如圖3所示.隨著 μ的逐漸增大,不同算法的性能均出現(xiàn)了下降趨勢.這是因為隨著 μ的增大網(wǎng)絡的隨機性變強,網(wǎng)絡蘊含的社區(qū)結(jié)構(gòu)復雜導致社區(qū)發(fā)現(xiàn)算法識別正確社區(qū)的難度加大.當多層網(wǎng)絡的節(jié)點數(shù)量N= 1 000時,PMMh產(chǎn)生了較差的結(jié)果,且在所有網(wǎng)絡中,PMMl和PMMh產(chǎn)生的結(jié)果有著較大的差異,說明不同的結(jié)構(gòu)特征數(shù)量對PMM 產(chǎn)生了較大的影響,而其取值為1~(N-2),特別對于規(guī)模較大的網(wǎng)絡,選取合適的結(jié)構(gòu)特征數(shù)量并不容易.其他算法的結(jié)果都隨著 μ的變化出現(xiàn)了較大的波動,從圖3 可以看出本文算法在大部分情況下優(yōu)于其他算法.當多層網(wǎng)絡的節(jié)點數(shù)量N= 5 000 時,基本上所有算法的結(jié)果隨著μ的增大而減小.例如,PM 算法的結(jié)果在L= 3,5,7 的情況下分別在 μ= 0.4,0.5,0.6 的時候明顯下降,PMM算法對于不同的提取的結(jié)構(gòu)特征數(shù)量值,結(jié)果產(chǎn)生了較大的差異;AWP 算法的結(jié)果在3 種不同層數(shù)的網(wǎng)絡中 μ<0.7 時均表現(xiàn)較好,但在 μ = 0.7 出現(xiàn)了明顯下降; SCML 算法表現(xiàn)較好,這是因為SCML 算法通過將包含在單個圖層中的信息轉(zhuǎn)換為Grassmann 流形上的子空間并利用Grassmann 流形上的距離分析找到一個具有代表性的子空間,最后在這個代表子空間上進行聚類.但是,SCML 的聚類結(jié)果容易受到與代表性子空間距離更近的單個圖層子空間上聚類結(jié)果的影響,當所有單個圖層都包含豐富的信息時,SCML 將產(chǎn)生更好的結(jié)果,若與代表性子空間距離更近的單個圖層上的聚類質(zhì)量較差時也會導致SCML產(chǎn)生較差的結(jié)果.下面我們選取L= 3,N= 5 000, μ=0.5 和L= 3,N= 1 000, μ= 0.6 這2 種不同情況的人工網(wǎng)絡來說明SCML 算法為何在N= 5 000 時取得較好的結(jié)果.如表2 所示,在L= 3,N= 5 000, μ= 0.5 上代表性子空間與第2 層的子空間距離最近,且從表2 中SCML 算法在單層網(wǎng)絡上得到的結(jié)果和NMI值,可以看出各層網(wǎng)絡均包含較為豐富的信息,所以SCML得到了更好的結(jié)果.如表3 所示,在L= 3,N= 1 000,μ= 0.6 上代表性子空間與第2 層的子空間距離最近,與表2 不同的是該網(wǎng)絡的第2 層得到了低質(zhì)量的聚類結(jié)果,SCML 產(chǎn)生了較差的結(jié)果.說明當多層網(wǎng)絡的各層網(wǎng)絡中都包含較為豐富的信息時,SCML 產(chǎn)生更好的結(jié)果,而當各層網(wǎng)絡中存在信息較少且該層網(wǎng)絡的子空間與SCML 計算所得的代表性子空間距離即使較近時,SCML 也會忽略信息較多的層,從而導致最終產(chǎn)生較差的結(jié)果.基于以上2 個人工網(wǎng)絡對本文提出的方法進行分析,在L= 3,N= 5 000, μ= 0.5上,本文算法的NMI分別為0.802 1,0.813 1,0.802 3.可以看出,該網(wǎng)絡中各層都包含了較為豐富的信息,通過式(14)進行全局加權(quán)集成后,得到的NMI= 0.850 1;在L= 3,N= 1 000, μ = 0.6 上,本文算法的NMI分別為0.544 0,0.224 7,0.024 7.可以看出該網(wǎng)絡中各層之間的差異性較大.
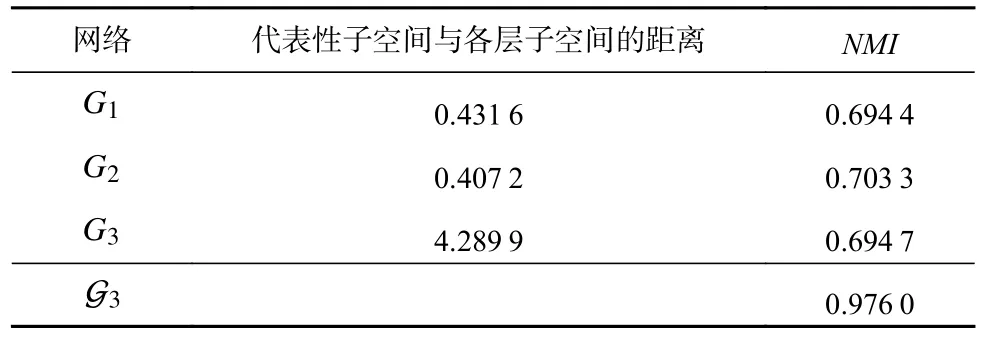
Table 2 Result Analysis of SCML on Network with L=3, N=5 000, μ=0.5表2 SCML 在L=3, N =5 000, μ=0.5 網(wǎng)絡上的結(jié)果分析
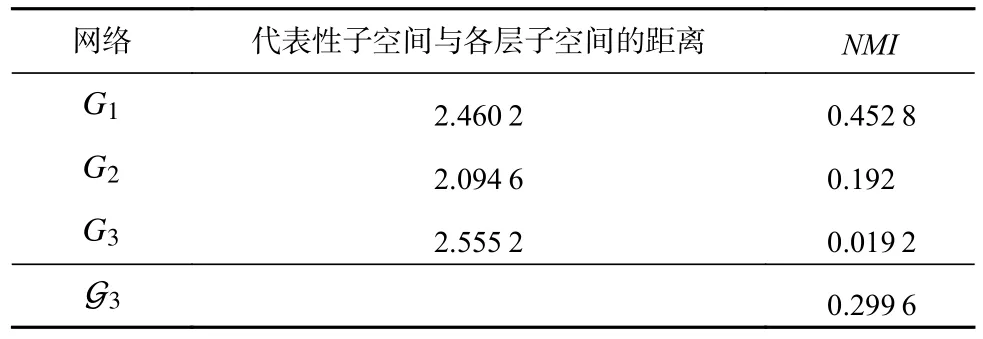
Table 3 Result Analysis of SCML on Network with L=3, N=1 000, μ=0.6表3 SCML 在L=3, N=1 000, μ=0.6 網(wǎng)絡上的結(jié)果分析
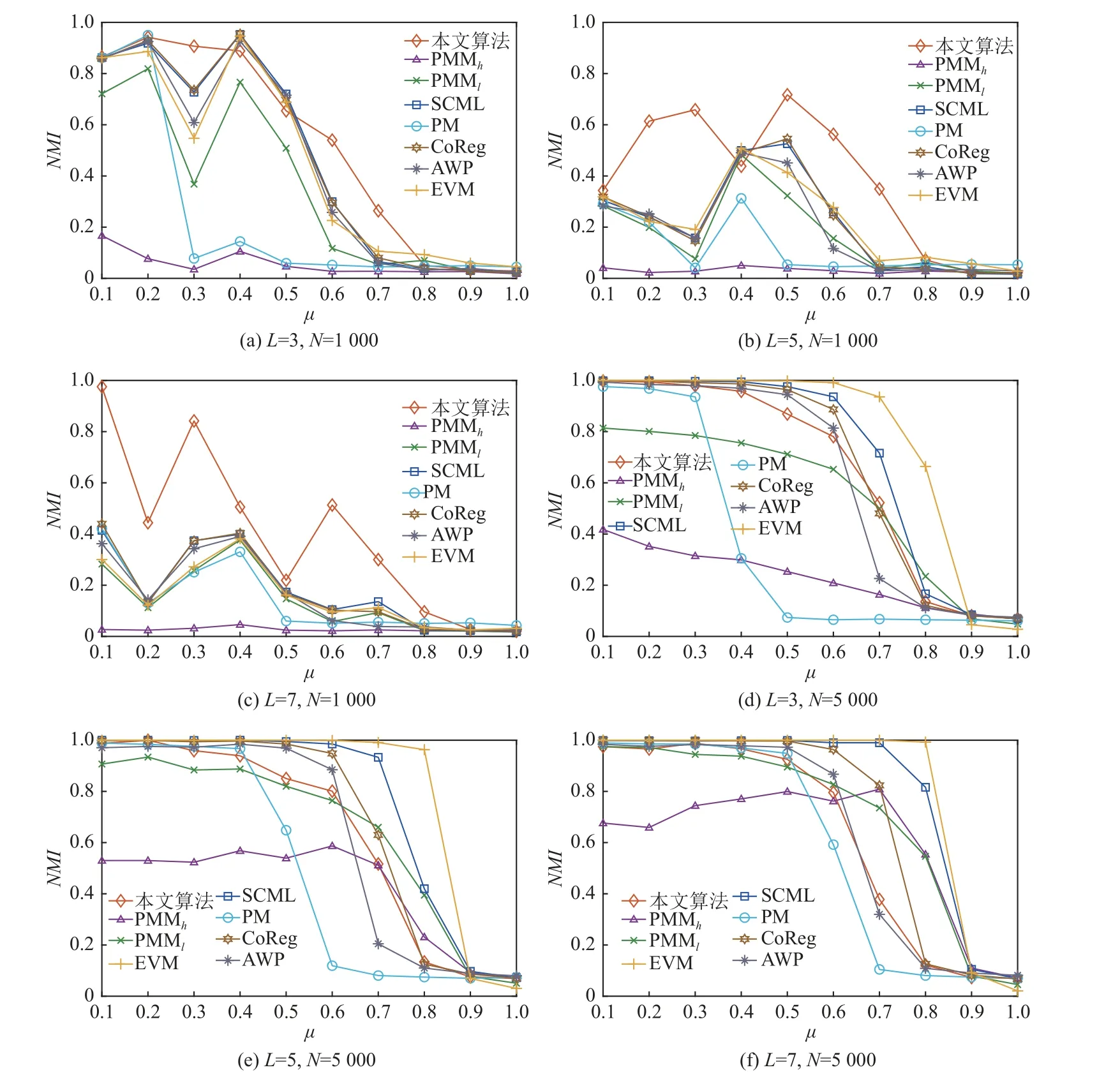
Fig.3 Comparison results of NMI on synthetic networks圖3 不同算法在合成網(wǎng)絡上的NMI 比較結(jié)果
通過式(14)進行全局加權(quán)集成后,得到的最終結(jié)果的NMI=0.548 9.通過對比表2、表3 與本文算法得到的NMI值可以看出L= 3,N=5 000, μ=0.5 中各層網(wǎng)絡包含信息較為平均,而L= 3,N=1 000, μ=0.6 中各層網(wǎng)絡包含信息的差異較大,所以當N=5 000 時,由于單層網(wǎng)絡之間差異較小,且隨著 μ的增大,各層網(wǎng)絡社區(qū)結(jié)構(gòu)難以識別,導致各層網(wǎng)絡上得到的基社區(qū)劃分較差,從而導致經(jīng)過集成產(chǎn)生的社區(qū)質(zhì)量也較低;當 μ<0.7時,本文算法在3 種不同層數(shù)的網(wǎng)絡上的實驗結(jié)果變化較小,說明本文算法的魯棒性較強.CoReg 和EVM 同樣在N=5 000,即單層網(wǎng)絡差異較小的人工網(wǎng)絡上表現(xiàn)出了良好的性能,而在單層網(wǎng)絡差異較大的人工網(wǎng)絡上表現(xiàn)較差.
3.4.2 真實網(wǎng)絡實驗結(jié)果分析
不同算法在真實網(wǎng)絡的實驗結(jié)果如表4 所示,其中每個算法在不同參數(shù)設置下均運行10 次,從不同社區(qū)個數(shù)得到的結(jié)果中選取最優(yōu)模塊度值進行比較.對不同算法在每個數(shù)據(jù)集上社區(qū)發(fā)現(xiàn)結(jié)果的最優(yōu)結(jié)果和次優(yōu)結(jié)果進行加粗標注.從表4 可以看出,本文算法在除AUCS 之外的11 個數(shù)據(jù)集上都取得了最優(yōu)結(jié)果或次優(yōu)的結(jié)果,其中在EUAir ,Gallus,Herpes4,Hiv1,Plasmodium,Xenopus,Bos 共7 個數(shù)據(jù)集上本文算法的結(jié)果明顯優(yōu)于次優(yōu)的結(jié)果.總之,本文算法在真實數(shù)據(jù)集上表現(xiàn)出了較為良好的性能.
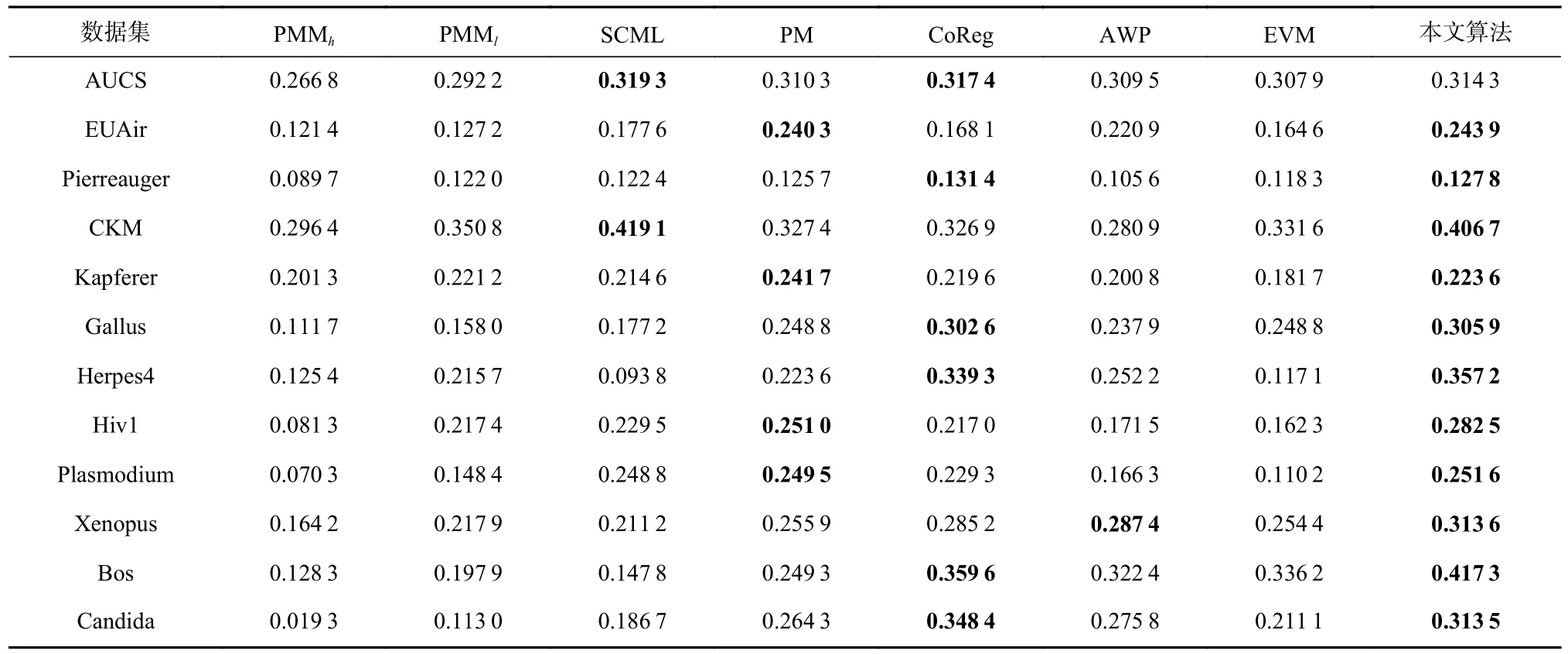
Table 4 Comparison of Experimental Results on Real Networks in Terms of QM表4 真實網(wǎng)絡實驗結(jié)果的QM 比較
3.4.3 魯棒性分析
為了驗證本文算法的有效性受基社區(qū)劃分數(shù)M變化的影響,對采用 μ=0.3 時不同規(guī)模的6 個人工多層網(wǎng)絡和部分層數(shù)較少的真實多層網(wǎng)絡進行了魯棒性 測 試.其 中,M∈{10,20,30,40,50},對 于 不 同 的M值,取本文算法在每個網(wǎng)絡上執(zhí)行10 次的結(jié)果的平均值進行比較,實驗結(jié)果如圖4 和圖5 所示.
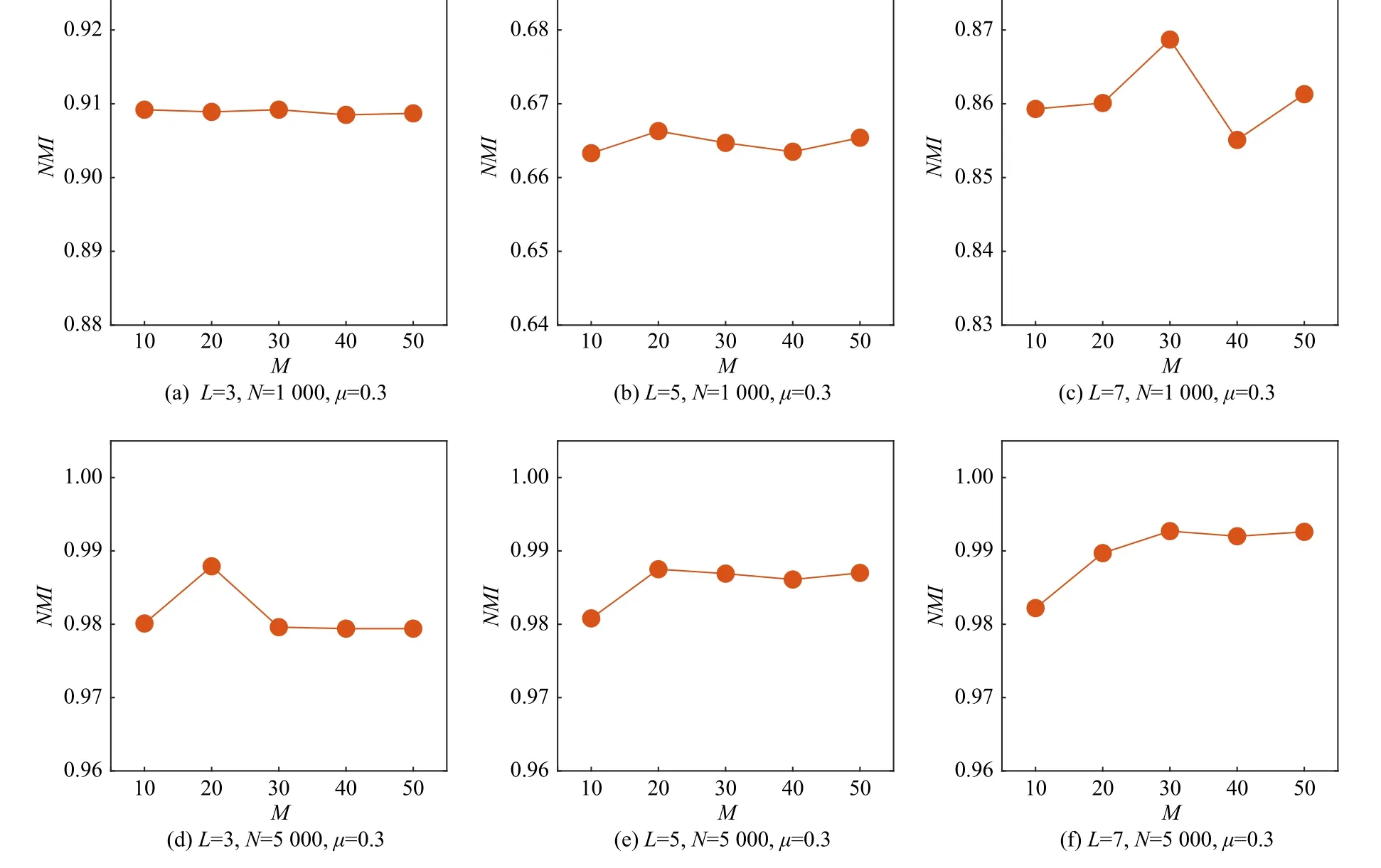
Fig.4 NMI of the proposed algorithm changes with varying ensemble number M圖4 本文算法的NMI 隨基社區(qū)劃分數(shù)M 的變化
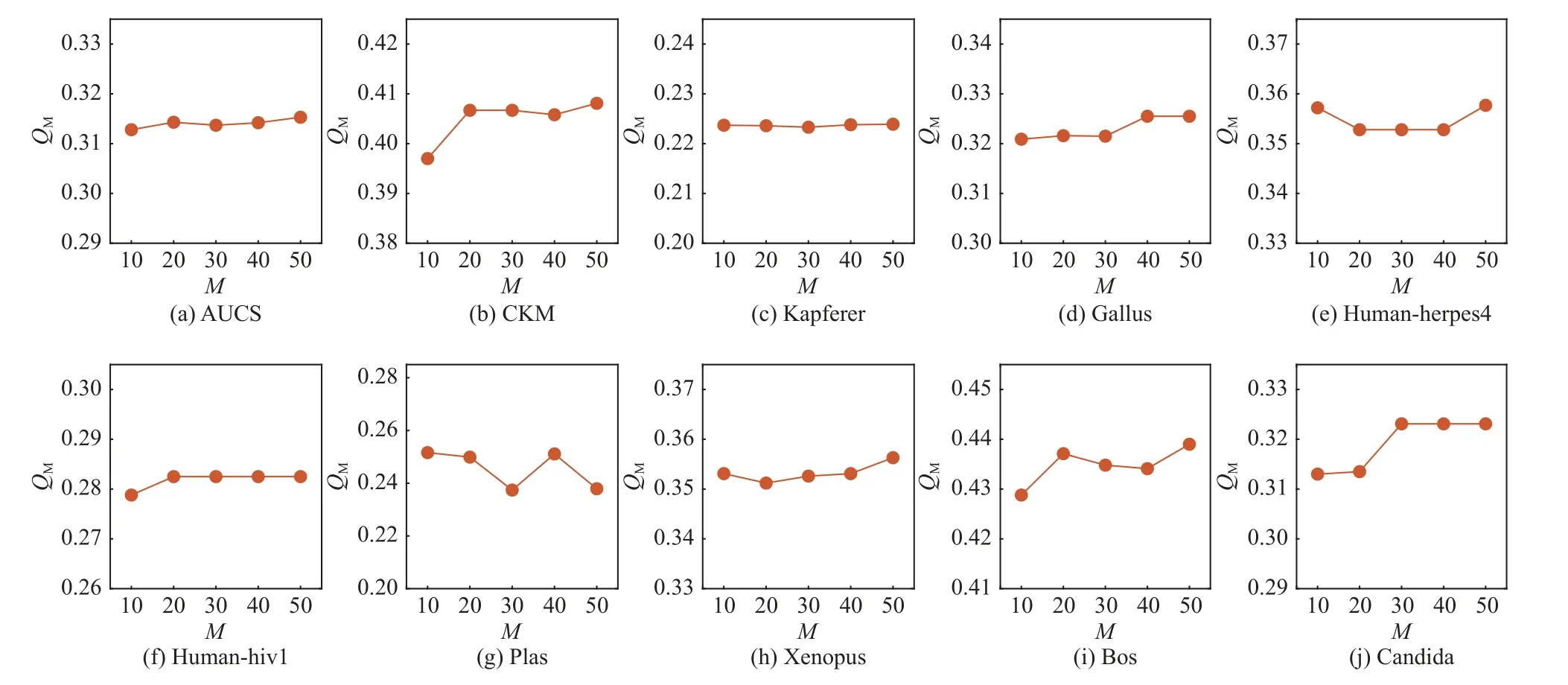
Fig.5 Q M of the proposed algorithm changes with varying ensemble number M圖5 本文算法的QM 隨基社區(qū)劃分數(shù)M 的變化
在人工多層網(wǎng)絡數(shù)據(jù)集中,采用NMI指標對社區(qū)劃分結(jié)果進行評價,統(tǒng)計在不同M下NMI的變化情況.由圖4 可知,當L= 7,N=1 000, μ=0.3 時本文算法的NMI值出現(xiàn)了最大的波動(0.013),其次當L=7,N=5 000, μ=0.3 時NMI值為0.01,在其他人工網(wǎng)絡數(shù)據(jù)集上NMI值的波動范圍均在0.01 以內(nèi).在真實多層網(wǎng)絡數(shù)據(jù)集中,通過多層模塊度指標QM對各個結(jié)果的變化范圍進行分析.在Plas 數(shù)據(jù)集上,本文算法的結(jié)果在不同的M值下QM值的波動為0.015,在CKM 和Candida 數(shù)據(jù)上的QM值的波動范圍均為0.011,而在其他數(shù)據(jù)集上不同的M值下QM值變化范圍均小于0.01.結(jié)果表明,本文算法的性能受基各層社區(qū)劃分個數(shù)M的影響較小,具有良好的魯棒性.
4 總 結(jié)
近年來,有效融合多層網(wǎng)絡信息并對其進行社區(qū)發(fā)現(xiàn)成為了一個重要的研究內(nèi)容.為此,本文提出了一種基于2 階段集成的多層網(wǎng)絡社區(qū)發(fā)現(xiàn)算法.首先,第1 階段在各層進行局部集成時結(jié)合了其他層的最優(yōu)社區(qū)劃分信息,有效利用了不同網(wǎng)絡層社區(qū)結(jié)構(gòu)的相關性;其次,第2 階段中基于其他網(wǎng)絡層的社區(qū)結(jié)構(gòu)信息對各層融合得到的社區(qū)劃分及社區(qū)結(jié)構(gòu)的重要性進行評價加權(quán),再進行全局加權(quán)集成,綜合考慮了各層局部社區(qū)劃分結(jié)果對集成的影響;最后,通過在人工生成多層網(wǎng)絡和真實多層網(wǎng)絡上進行實驗分析,對本文算法的有效性和魯棒性進行了驗證.然而,本文提出的算法面臨時間復雜度較高的問題,在未來的工作中將考慮如何提高算法的計算效率來應對大規(guī)模多層網(wǎng)絡社區(qū)發(fā)現(xiàn)面臨的挑戰(zhàn).
作者貢獻聲明:趙興旺提出論文算法思想、設計實驗方案并修訂論文;張珧溥完成實驗并撰寫論文;梁吉業(yè)提出算法的指導意見和審核論文.
