基于多模態方面術語提取和方面級情感分類的統一框架
2023-12-15 04:47:54朱浩澤郭文雅于勝龍
計算機研究與發展 2023年12期
周 如 朱浩澤 郭文雅 于勝龍 張 瑩
(南開大學計算機學院 天津 300350)(zhouru@mail.nankai.edu.cn)
隨著互聯網的發展,社交媒體平臺成為人們發表言論和觀點的主要陣地,高效地識別用戶對重要組織、重要人物、商品等實體及其方面①方面指的是實體或實體的屬性.的情感對平臺治理用戶的不當言論、建模用戶偏好以實現精準的個性化推薦有重要的實用意義.同時也有助于監控消費者行為、評估產品質量、監控輿情、調研市場等.
不同于句子級情感分析任務為整個句子預測情感,方面術語提取和方面級情感分類(aspect-term extraction and aspect-level sentiment classification, AESC)任務的目標是抽取句子中的方面-情感對.方面術語提取(aspect-term extraction, AE)提取句子中包含的方面術語,方面級情感分類(aspect-level sentiment classification, ALSC)預測用戶對給定方面的情感.比如來自Twitter 的一條評論:“I love animals , so nice to see them getting along ! Here are our dogs , Greek and Salem ,laying together”,提取出的方面-情感對為〈“Greek”,正面〉〈“Salem”,正面〉,即句子中包含方面“Greek”和“Salem”,表述者對它們的情感都是正面的.
在文本領域中,已有研究[1-3]實現了方面-情感對提取方法,并應用于商品評論數據的情感分析.然而在Twitter,Instagram 等社交媒體平臺上,人們習慣發表短小且口語化的文字并配以圖片,相關研究指出,文本單模態的模型在此類用戶數據上表現并不好[4-6].考慮圖片非僅僅依靠文本來分析用戶發表的觀點是時代的趨勢,因此在多模態領域實現方面術語提取和方面級情感分類將具有一定的實用價值和現實意義.
在多模態領域,Zhang 等人[7]和Yu 等人[8]分別研究了方面術語抽取和方面級情感分類.通過實體識別技術提取句子中包含的方面術語,接著將提取的方面術語和句子輸入到方面級情感分類模型進行情感預測,可通過這種流水線方式實現方面-情感對的提取.然而,目前的這種方法存在不足之處:首先,使用2 個完全獨立的模型分步實現方面-情感對的提取,使得建模特征的語義深度不同且不關聯,忽略了2 個任務之間潛在的語義關聯,當句子中包含多個方面時,情感分類模型可能會混淆它們之間的上下文信息而造成預測失誤;其次,方面術語提取模型一次提取句子中的多個方面術語,而情感分析模型一次只能預測一個方面的情感,前者的吞吐量大于后者,且情感分析必須在方面術語提取完成后進行,降低了方面-情感對的抽取效率.
針對以上問題,本文提出了一個同時進行方面術語提取和方面級情感分類的統一框架UMAS.該統一框架包含3 個模塊:共享特征模塊、方面術語提取模塊、情感分類模塊.首先,該統一框架使用共享特征的方式表示方面術語提取和情感分類2 個子任務的底層文本和圖像特征,在學習的過程中建立2 個子任務之間的語義聯系.相比于之前的方面術語提取模型和方面級情感分類模型使用不同的網絡編碼文本和圖像的特征,本文所提出的特征共享的方法簡化了模型.其次,采用序列標注的方式,同時輸出句子中包含的多個方面和對應的情感,方面術語提取模塊和情感分類模塊可并行執行,大大提升了方面-情感對提取的效率.
此外,既往多模態方面術語提取方法[7,9-10]未能充分利用文本的語法信息,而方面級情感分析方法[8,11]由于缺乏觀點詞的標注而未能通過觀點信息更好地判斷情感傾向.為提升2 個子任務的性能,本文使用詞性標注工具spaCy[11]獲取單詞的詞性,對2 個子任務做如下改進:在方面術語提取模塊中,使用多頭自注意力機制獲取詞性特征,融合視覺特征、文本特征、詞性特征作為分類層的輸入,提升了方面術語提取的性能;在情感分類模塊,為充分發揮觀點詞對情感分類的作用,通過詞性標注將動詞、形容詞、副詞、介詞標記為觀點詞,在情感分類中增加對這些觀點詞的注意權重,并將觀點詞特征融入到最后的分類層以提升情感分類的性能.本文提出的方法與多個基線模型相比,在方面術語提取、方面級情感分類、AESC 任務上的性能都有明顯的提升.
本文的主要貢獻有3 個方面:
1) 在多模態領域提出方面術語提取和方面級情感分類的統一框架UMAS (unified multi-modal aspect sentiment),通過建模方面術語提取和方面級情感分類任務之間的語義關聯,同時提高了方面-情感對提取的性能和效率.
2) 本文通過引入詞性特征提升了方面術語提取的性能;通過詞性標注獲取觀點詞特征并結合位置信息,提升了方面級情感分類的性能.
3) 該統一框架在Twitter2015,Restaurant2014 這2 個基準數據集上相比于多個基線模型在方面術語提取、方面級情感分類、AESC 任務上都具有優越的性能.
1 相關工作
目前,文本領域的基于方面的情感分析研究發展的比較成熟,現有研究[12-18]在Restaurant,Laptop,Twitter 等數據集上,根據提供的方面術語預測情感類別;Ying 等人[19]根據方面術語提取對應的觀點并判斷情感傾向;Oh 等人[20]、Chen 等人[21]、Xu 等人[22]則使用多任務模型將方面術語提取、觀點詞提取、情感分類3 個任務統一.其中,Chen 等人[21]詳細闡述了3 個任務之間的關系,并在多層的網絡模型RACL中通過關系傳導機制促進子任務之間的協作,最終以序列標注的方式分別輸出3 個任務的結果.RACL將3 個任務的關系總結如下:方面術語和觀點詞存在對應關系(比如“美味”一詞不適合描述地點),方面術語和觀點詞的配對有助于預測情感,觀點詞對情感預測有最直接的幫助,方面術語是情感依托的對象.文本領域的方面術語提取方法更關注文本的語法信息,Phan 等人[23]和薛芳等人[24]借助句法成分、依存關系提升方面術語提取的性能.在情感分類中,Chen 等人[21]、He 等人[25]利用觀點詞的信息提升了情感推斷的準確性,He 等人[25]還利用了位置信息使注意力集中在方面的上下文.文本領域基于方面的情感分析的研究,對多模態基于方面的情感分析的研究有重要的啟發式意義.
在多模態領域,可使用Zhang 等人[7]提出的方面術語抽取模型和Yu 等人[8]提出的方面級情感分類模型流水線式地抽取方面-情感對.盡管流水線方法符合人們處理此類問題的直覺且有利于靈活變動2個模型,但Wang 等人[26]指出該方法在方面術語提取中的錯誤將傳播到情感預測階段,導致方面-情感對預測性能下降.方面術語提取和方面級情感分類2 個模型的獨立無法像RACL 一樣建模2 個任務之間的語義聯系,且串行執行使得模型效率低下.多模態方面術語提取方法[7,9-10]充分關注了圖像對提取方面術語的幫助,并且使用門控機制降低圖像引入的噪音,但忽視了文本中包含的語法信息.在文本領域的方面級情感分類中,多種方法[19-21]利用觀點詞提取作為輔助任務提升情感分類的效果,然而多模態方面級情感分類的數據集主要是Twitter,目前數據集中包含的信息包括句子、圖片、方面、情感等的標準,但是未有觀點詞的標注信息,所以多模態領域中以觀點詞提取為輔助任務的方法不存在監督信息,難以開展.此外,目前多模態方面級情感分類模型如EASFN[8],ABAFN[12],以句子、圖像、方面術語為輸入,一次只能識別一個方面的情感,而文本領域采用序列標注的方法可同時識別句子中所有方面的情感.
2 基于多模態方面術語提取和方面級情感分類的統一框架
本節主要介紹任務定義,并詳細闡述本文所提出的基于多模態方面術語提取和方面級情感分類的統一框架.
2.1 任務定義
給定長度為n的句子,即S={w1,w2,…,wn},方面術語提取任務的目的是獲取句子的方面術語標注序列YA={yA1,yA2,…,yAi,…,yAn},yAi∈{B,I,O},其 中B 表示方面術語的開始單詞,I 表示方面術語的中間單詞及結尾單詞,O 表示不是方面術語.而方面級情感分類任務的目的是獲取句子的情感標注序列YS=∈{0,1,2,3},其中0表示該單詞不是方面術語,不被賦予情感,1 表示情感為負面,2 表示情感中立,3 表示情感為正面.方面術語提取和方面級情感分類的目的是抽取句子中包含的方面-情 感 對, 即YP={as1,ae1,s1,…,asi,aei,si,…,asm,aem,sm},其中asi,aei,si分別為第i個方面術語的起始位置、終止位置和對應的情感類別.
2.2 模型概述
本文設計的方面術語提取和方面級情感分類的統一框架主要分為3 個模塊:共享特征模塊、方面術語提取模塊和情感分類模塊,模型圖如圖1 所示.
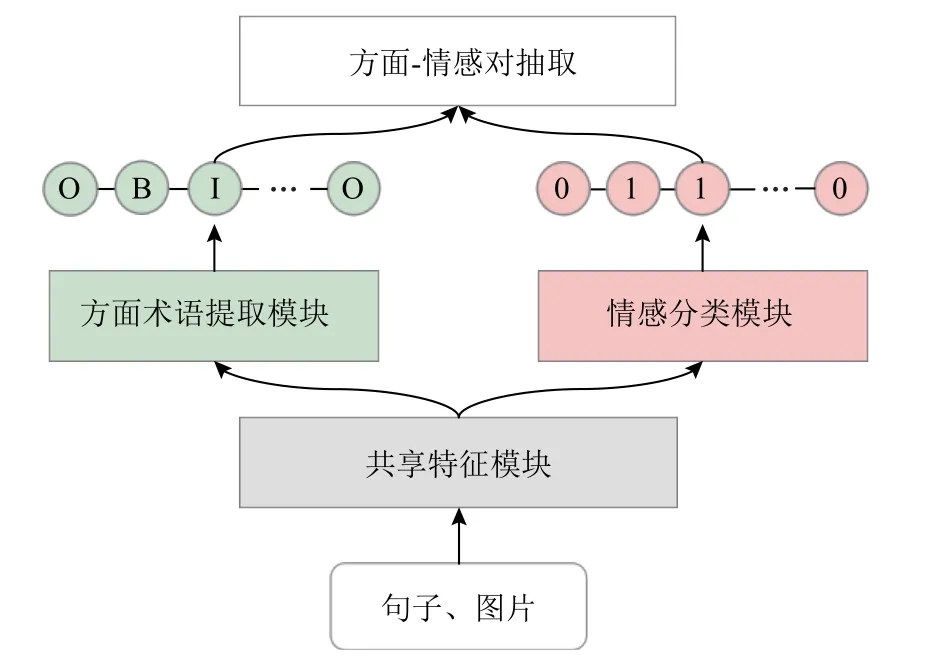
Fig.1 Framework of our proposed model圖1 本文模型框架
在共享特征模塊,使用VGG-16 模型[27]獲取圖片特征表示,通過雙向長短期記憶網絡(bi-long shortterm memory,BiLSTM)獲取單詞和字符的聯合特征表示,通過多頭自注意力機制[28]獲取詞性特征表示.方面術語提取模塊和情感分類模塊以共享特征為輸入,編碼出特定于各自任務的私有特征.在方面術語提取模塊,通過文本和圖像的交互注意力以及門控機制獲取多模態表示,并與文本及詞性特征拼接,作為方面術語提取模塊最終的融合特征,最后通過條件隨機場(conditional random fields,CRF)層獲取方面術語序列標注.情感分類模塊將共享特征和特有特征融合,獲取情感特征和觀點詞特征.通過門控機制融合由情感特征引導的視覺注意特征和情感特征以獲得多模態特征,并通過情感文本注意、位置信息和詞性獲得觀點詞特征,然后,將多模態特征和情感特征以及觀點詞特征融合,通過全連接層及softmax 層獲得情感序列標注.在獲得方面術語序列標簽和情感序列標簽后,通過簡單的代碼提取方面-情感對,實現AESC 任務的目標.圖2 是本文所提出的基于多模態方面術語提取和方面級情感分類的統一框架.
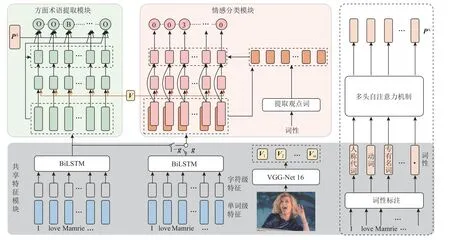
Fig.2 Unified framework based on multimodal aspect term extraction and aspect-level sentiment classification圖2 基于多模態方面術語提取和方面級情感分類的統一框架
本文提出的方面術語提取和方面級情感分類的統一框架借鑒了多任務學習的思路,即通過參數共享建模2 個子任務的語義聯系,提升每個子任務的性能,并使用子任務的加權損失作為模型的損失.但多任務模型通常有多個主要目標,而本文所提出的模型的主要目標只有1 個,即抽取方面-情感對.
2.3 共享特征模塊
共享特征模塊的圖像特征、文本特征、詞性特征分別由圖像編碼器、文本編碼器、詞性編碼器生成.
2.3.1 圖像編碼器
裁剪圖片為224×224 像素,作為VGG-Net16[27]的輸入,圖像編碼器保留最后1 層池化層輸出結果作為圖像特征(維度為512×7×7).其中,7×7 代表圖像的49 個區域,512 表示每個區域的特征維度.所以圖像 特 征 可 表 示 為={vi|vi∈Rdv,i=1,2,…,49},vi代 表圖像區域i的具有512 維度的特征向量.
2.3.2 文本編碼器
字符級的嵌入式表示可以減輕罕見詞和拼寫錯誤的問題,且能捕獲前綴后綴的信息,因此,本文將字符級表示作為單詞表示的一部分.通過查找字符向量表,可以獲取第t個單詞的字符表示ct,W={ct,1,ct,2,…,ct,m} , 其中ct,i∈Rdc為第t個單詞第i個字母的向量表示,m為單詞的長度.k個不同窗口大小的卷積核 [C1,C2,…,Ck]被應用在單詞特征上,每一次卷積后加一步最大池化操作,最后將獲得的k個特征w′t,1,w′t,2,…,w′t,k拼接在一起作為單詞的字符級表示,即
通過查詢預訓練的詞向量矩陣,可獲得單詞t的詞嵌入式表示w′t′,將其與字符特征w′t拼接在一起作為單詞t的聯合表示,即wt=[w′t,w′t′].接著,使用BiLSTM獲取包含上下文信息的單詞t的隱藏特征ht,即
其中H表示最終的共享文本特征,d為隱藏特征的向量維度.
2.3.3 詞性編碼器
Phan 等人[23]使用句法成分信息提升了方面術語提取的準確率,本文同樣也使用spaCy 工具獲取單詞的詞性.根據隨機初始化的詞性向量矩陣,可獲得句子的詞性特征(n為句子長度).然后,本文使用文獻[27]中的多頭自注意力機制進一步獲取深層次的詞性嵌入式特征P.
本文提出的模型中共有2 個結構相同的文本編碼器,分別為共享文本編碼器和情感模塊的私有文本編碼器.方面術語提取模塊和情感分類模塊共享圖像編碼器、詞性編碼器、共享文本編碼器的輸出數據.
2.4 方面術語提取模塊
方面術語提取模塊通過文本注意和視覺注意建模不同模態之間的語義交互作用,使用門控機制獲取多模態融合特征,并使用過濾門減少多模態引入的噪音,最后將多模態融合特征、文本特征、詞性特征拼接作為CRF 解碼器的輸入,獲得方面術語標注序列.
首先,使用線性層分別將圖像特征映射到與文本同維度的空間,將共享文本特征編碼為方面術語提取模塊的私有文本特征,即
其中WIA,WHA,bAI,bAH為可訓練參數.
通常情況下,句子中的單詞只對應圖像中的一小塊區域,為減小圖像其他區域引入的噪音,該模塊使用文本引導的視覺注意來獲取不同區域的權重,圖像區域與單詞越相關,它被賦予的權重越大.給定一 個 單 詞 的 特 征xAt(xAt∈XA),通 過 神 經 網 絡 和softmax 函數來生成單詞t對應的圖像權重分布 αt,并通過加權和生成單詞t對應的圖像特征表示,即
其中∈Rd,d為單詞和圖像特征的維度,∈Rd×N表示N個圖片區域的特征,∈Rd表示圖片第i個區域的特征.為可訓練的參數.符號⊕表示2 個特征的拼接,當2 個操作數分別為矩陣和向量時,表示復制多個向量與矩陣的每一列進行拼接.
類似地,上下文有助于豐富當前單詞特征包含的信息,且對上下文不同的單詞應當有不同的關注程度,所以本文通過視覺引導的文本注意力來獲取單詞t所需關注的上下文的權重 βt,通過對句子中單詞的加權獲得單詞t的新的特征表示.
當句子中包含多個實體時,往往并不是每個實體都存在與圖像中的某個區域對應的關系,可能圖片中描述了一個實體,而句子中有3 個不同的實體.為此,在融合多模態特征時,也需動態權衡視覺特征和文本特征的比例.方面術語提取模塊使用式(12)~(15)獲取多模態融合特征:
盡管多模態融合特征考慮了文本和圖像的權重,但方面術語提取所依賴的最重要的數據應該是文本,所以方面術語提取模塊將初始的文本特征、多模態特征和詞性特征拼接起來作為解碼器的輸入.此外,當預測的單詞是動詞或副詞時,加入圖像特征會引起噪音,所以在拼接之前,對多模態特征進行過濾操作,具體公式為:
最后,方面術語提取模塊使用CRF 作為解碼器進行方面術語的序列標注.以X={w0,w1,...,wT}作為一般化的輸入序列,其中wi表示第i個單詞的特征向量,Y={Y0,y1,...,yT}表示X對應的一種序列標簽,Y表示所有可能的序列標注集合.對于給定的X,所有可能的y可以由式(20)計算得到:
其中 Ω表示可能性函數.
2.5 情感分類模塊
情感分類模塊可以分為4 個部分:情感私有特征、多模態融合、觀點詞特征、情感分類.
2.5.1 情感私有特征
由于方面術語提取和情感分類的目標不一致,使用完全的共享特征機制會使訓練效果不好,同時共享特征包含的信息有助于在底層更好地表現2 個任務之間的語義聯系,特別是方面作為情感的寄托者有助于情感的預測.所以,在情感分類模塊,存在一個私有的文本編碼器以獲取特有的情感特征.接著,將共享表示層的文本特征和特有情感特征進行動態融合.考慮使用動態融合是因為更關注共享特征中的方面而非其他單詞.該模塊的情感私有特征表示XS由式(21)~(25)獲取:
其中,fSC表示表示情感模塊私有文本編碼器的函數,S表示輸入的句子,,WH,,,bH為參數.
2.5.2 多模態融合
用戶在社交媒體發布的文字具有不完整、較短、口語化的特點,僅僅使用文本內容來推測情感是不充分的.因此,情感分類模塊使用圖像信息來提升預測的準確性.與方面術語提取模塊一樣,在判斷單詞t(假設單詞t為方面術語)的情感時,需要著重關注圖像中該方面對應的區域,應盡量減少其他區域引起的干擾,所以使用相同的方法為不同的視覺區域分配不同的權重.首先,將共享圖像特征轉換至與文本同一維度的空間內,然后使用情感引導的注意獲取圖像的權重分布 γt,最終加權獲得單詞t在情感分類模塊對應的圖像特征,運算公式為:
不同于方面術語提取模塊對文本引入視覺注意的處理,在情感分類模塊,為減少視覺特征引起的噪音,本文采用多頭自注意的方式來獲取單詞t對上下文的關注,使某個位置的單詞關注來自不同表示子空間的其他單詞的特征.該模塊多頭自注意力的查詢矩陣、鍵矩陣、值矩陣都為情感特征矩陣.最終多頭自注意力輸出的文本特征為
接著,同樣通過門控機制獲得情感特征和圖像特征的多模態融合特征
2.5.3 觀點詞特征
由于人們表達情感是通過觀點抒發的,即觀點詞有助于情感的判斷,所以本文模塊中使用詞性標注識別的觀點詞信息幫助情感的預測,首先使用簡單的神經網絡編碼得到觀點詞特征表示XO.
觀點描述的短語通常由動詞、副詞、形容詞、介詞構成,比如“agree with”“run fast”“beautiful”等.在獲取第t個單詞的上下文時,應該給予這些單詞更多的權重.此外,通常情況下,觀點詞會出現在描述對象的附近,因此,位置關系也可以被考慮.基于上述的分析,為獲取單詞t對應的觀點信息,本文模塊使用單詞t(假設為方面術語)引導的注意,并考慮形容詞、副詞、動詞和介詞的權重以及位置權重,最終得到單詞t對應的觀點特征.
2.5.4 情感分類
將多模態融合特征、情感特征、觀點特征融合,輸入到分類層,得到最后的情感分類結果為:
其中Ws,bs為可訓練參數.
2.6 模型訓練
AESC 模塊的損失函數是最小化交叉熵損失,實驗的目標是最小化這2 個模塊的加權損失,即
其中 α1,α2為超參,為2 個模塊損失函數的權重.
2.7 方面-情感對提取
通過AESC模塊,可分別獲取句子的方面術語和情感標注序列,即YA={yA1,yA2,…,yAi,…,yAn},yAi∈{B,I,O}和YS={yS1,yS2,…,ySi,…,ySn},ySi∈{0,1,2,3}.為 了 實 現AESC 任務的目標,本文進行方面-情感對抽取,具體的算法如算法1 所示.
算法1.方面-情感對抽取.
輸入:句子長度L,方面術語標注序列YA,情感標注序列YS;
輸出:方面-情感對YP.
① 令YP=[],i=0;
② whilei<Ldo
③ ifYA[i]==B then
④ 令start=i,end=i;
⑤i+=1;
⑥ whilei<LandYA[i]==I do
⑦end=i;
⑧i+=1;
⑨ end while
⑩YP.append((start,end,YS[start]));
? else
?i+=1;
? end if
? end while
3 實 驗
3.1 數據集
為驗證本文所提出的模型的有效性,本文使用了數據集Twitter2015[8]和Restaurant2014[20]進行實驗.Twitter2015[8]是一個多模態數據集,其包含文本內容、圖片、方面信息以及情感類別信息.Restaurant2014[20]屬于文本領域的方面級情感分類數據集,其不包含圖片信息.本文數據集的訓練集、測試集以及驗證集與來源保持一致.表1 和表2 分別是這2 個數據集的統計信息.
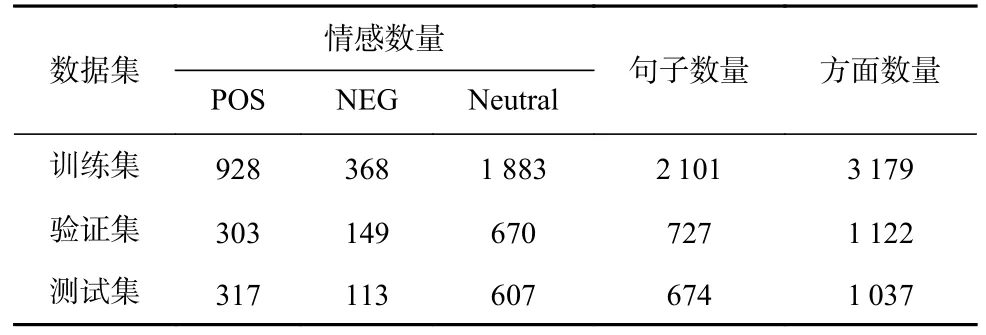
Table 1 Statistics of Twitter2015 Dataset表1 Twitter2015 數據集統計信息
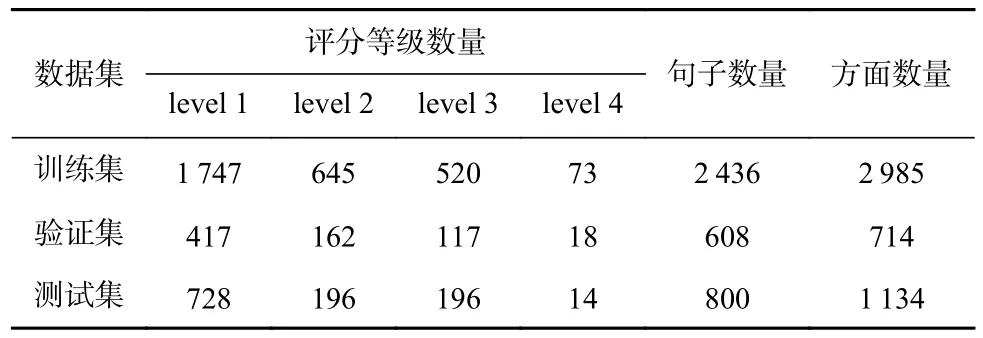
Table 2 Statistics of Restaurant2014 Dataset表2 Restaurant2014 數據集統計信息
3.2 實現細節
為了初始化模型中的詞嵌入式表示,本文使用了Zhang 等人[7]在3 000 萬條推特上預訓練好的GloVe[29]詞嵌入式詞典.詞嵌入式表示的維度為200,不在詞典內的單詞被隨機初始化,并服從-0.25~0.25的均勻分布.字符嵌入式表示、詞性嵌入式表示的維度分別為30 和16,且隨機初始化服從-0.25~0.25 的均勻分布.句子和單詞最大的長度都取數據集中的最大值,不滿足最大值的單詞或句子采用填充的方式使所有單詞或句子等長.BiLSTM 輸出的隱藏向量維度為200,方面術語提取模塊的私有特征維度為200,情感分類模塊私有特征的維度為100.方面術語提取和情感分類2 個模塊的損失權重分別為0.5 和0.5.訓練過程中,周期(epoch)為50,批大小為20,優化器為Adam,學習率為0.001.
3.3 基線模型
在實驗中用作對比的模型主要包括文本領域和多模態領域的模型.
3.3.1 文本領域
CMLA+TCap 和DECNN+TCap.CMLA[30]和DECNN[31]是方面術語提取任務中經典的模型,TCap[32]是方面級情感分類領先的方法,本文分別將2 個方面術語提取模型和1 個情感分類模型進行整合,形成2個流水線模型.
1)MNN[26].該模型是使用聯合標注方法的方面術語提取和情感分類統一的模型.
2)E2E-AESC[33].該模型是使用聯合標注方法,并以觀點詞提取為輔助任務的方面術語提取和情感分類統一的模型.
3)DOER[34].該模型是聯合訓練方面術語提取和情感分類的多任務統一框架.
4)RACL[21].是將方面術語提取、觀點詞提取、情感分類統一的多任務模型,該模型使用多層疊加的框架.
5)UMAS-Text.該模型是本文提出的方面術語提取和方面級情感分類的統一框架,它將模型中關于視覺特征處理的網絡層去除,變成處理純文本數據的模型.
3.3.2 多模態領域
1)VAM[9].VAM 使用視覺注意機制和門控機制的多模態方面術語提取模型.
2)ACN[7].ACN 使用文本注意機制、視覺注意機制和門控機制的多模態方面術語提取模型.
3)UMT[10].UMT 使 用Bert 預 訓 練 模 型 表 征 文 本的多模態方面術語提取模型.
4)Res-RAM 和Res-MGAN.它們是2 個方面級情感分類模型.采用Hazarika 等人[35]提出的多模態融合方法將視覺特征和RAM[36]或MGAN[37]的文本特征融合,最后采用softmax 層分類.
5)Res-RAM-TFN 和Res-MGAN-TFN.它們是采用Zadeh 等人[5]提出的多模態融合方法將視覺特征和RAM 或MGAN 的文本特征融合進行方面級情感分類的模型.
6)MIMN[38].MIMN 是采用多跳記憶網絡建模方面術語、文本和視覺之間交互關系的方面級情感分類模型,具有較高的性能.
7)EASFN[8].EASFN 是目前多模態領域最新的方面級情感分類模型.
8)ACN-ESAFN.ACN-ESAFN 是使用ACN[7]獲取方面術語、ESAFN[8]獲取方面級情感的流水線模型.
9)UMT-ESAFN.UMT-ESAFN 是 使 用UMT[10]獲取方面術語、ESAFN[8]獲取方面級情感的流水線模型.
10)UMAS-AE.UMAS-AE 是將本文提出的模型中的共享特征模塊和方面術語提取模塊組合成單任務的方面術語提取模型.
11)UMAS-SC.UMAS-SC 是將本文提出的模型中的共享特征模塊和情感分類模塊組合成單任務的方面級情感分類模型.
12)UMAS-Pipeline.UMAS-Pipeline 是 將 獨 立 的UMAS-AE 和UMAS-SC 模型使用流水線方式合并而成的模型.
13)UMAS:UMAS 是本文提出的多模態方面術語提取和方面級情感分類的統一框架,由2 個模塊共享淺層的特征表示.
3.4 評價指標
本文使用精確率(precision,P)、召回率(recall,R)、F1 評價方面術語提取模型的性能,以下簡記為AE-P、AE-R、AE-F1;使用準確率(accuracy,ACC)、F1 評價情感分類的性能,簡記為SC-ACC,SC-F1;使用F1 評價方面-情感對提取的性能,簡記為AESC-F1,即當且僅當方面術語提取和情感預測同時正確時記為預測正確.
3.5 實驗結果
3.5.1 與基線模型的對比
表3 報告了本文所提出的模型UMAS 在文本領域與現有方法的性能對比.在文本數據集Restaurant 2014 上,UMAS 的F1 在方面術語提取、情感分類2個子任務上相較于第2 優秀的模型RACL-GloVe 的F1 值分別提升了0.21 個百分點和1.9 個百分點,且方面-情感對的提取表現也是最好的.說明UMAS 在刪除視覺處理的相關網絡后,在文本領域也具有良好的表現.
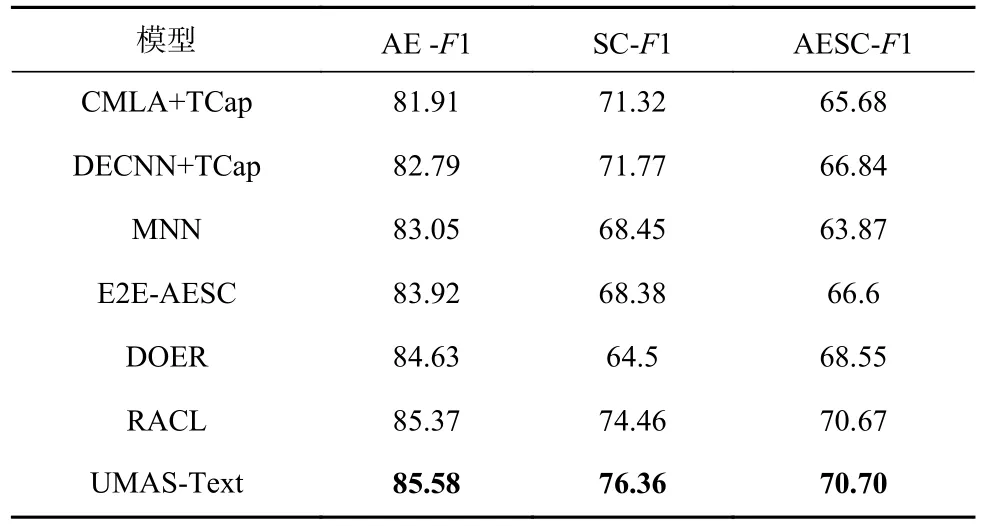
Table 3 Performance Comparison of UMAS-Text and Existing Methods on Restaurant2014 Dataset表3 Restaurant2014 數據集上UMAS-Text與現有方法的性能對比 %
表4 和表5 報告了UMAS 在多模態領域與現有方法在方面術語提取和方面級情感分類2 個子任務上的性能對比.在多模態數據集Twitter2015 上,UMAS 與當前3 個方面術語提取模型相比,F1 值分別提升了21.78 個百分點、4.25 個百分點、0.15 個百分點,比使用BERT 預訓練的方面術語提取模型UMT 略有優勢.方面術語提取的P值比ACN 高了1.99 個百分點.然而R值比UMT 模型低了2.22 個百分點.這一定程度上體現了UMAS 相對于UMT 在識別方面時邊界更加嚴格,提升了P值的同時損失了R值.在情感分類任務中,UMAS 的性能超過了所有的基線模型,比當前最新的模型ESAFN 的F1 值提高了5.97 個百分點、ACC提高了0.1 個百分點.
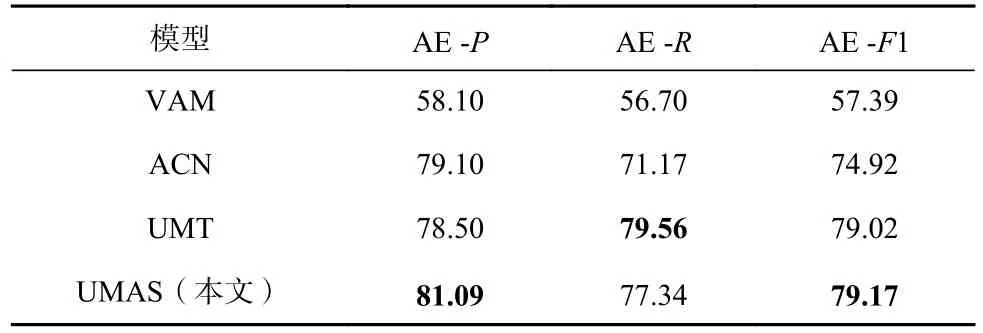
Table 4 Performance Comparison of AE on Twitter2015 Dataset表4 Twitter2015 數據集上AE 性能對比 %
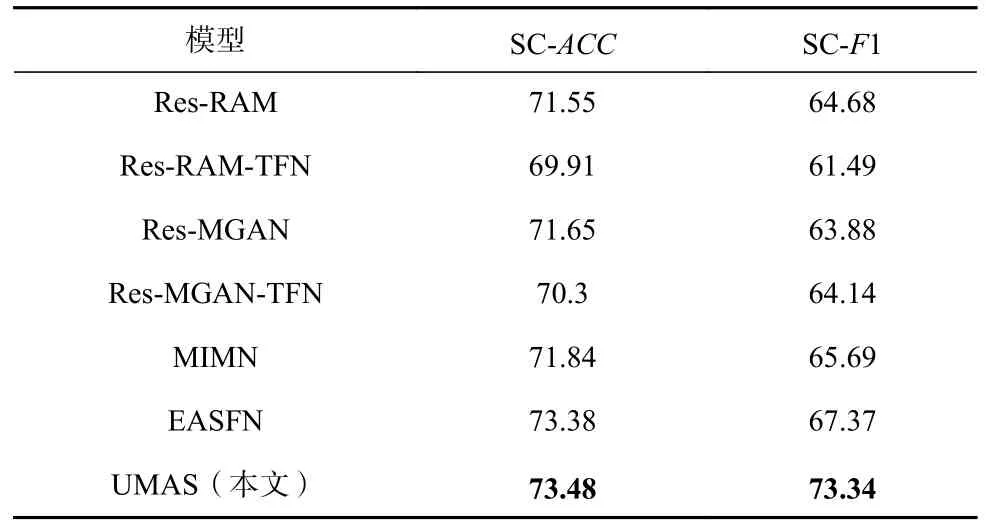
Table 5 Performance Comparison of SC on Twitter2015 Dataset表5 Twitter2015 數據集上SC 性能對比 %
表6 報告了UMAS 和當前多模態流水線方法的性能對比.UMAS 在多模態數據集上提取方面-情感對的F1 值為58.05%,分別高于現有流水線方法2.49個百分點和1.16 個百分點,且時間效率是現有方法的16.3 倍和16 倍,體現了本文所提出的統一框架具有最優的性能.
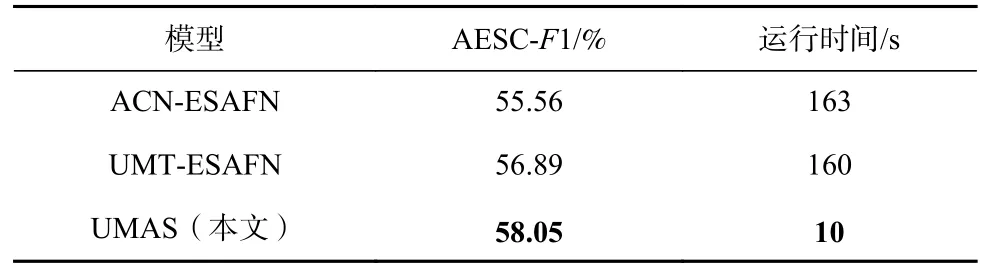
Table 6 Performance Comparison of AESC on Twitter2015 Dataset表6 Twitter2015 數據集上AESC 性能對比
表7 報告了UMAS 和單任務模型的性能對比.結果表明,UMAS 相比于方面術語提取和情感分類單任務模型,性能都有一定的提升,F1 值分別提升了0.01 個百分點和2.55 個百分點,方面術語提取的ACC提升了2.79 個百分點,情感分類的ACC提升了2.22 個百分點.然而,UMAS 中方面術語提取的R值相對于單任務下降了2.7 個百分點,這可能是因為在UMAS 中方面的特征表示受到了情感模塊的影響.此外,UMAS 的AESC 性能與2 個單任務串聯的流水線模型對比,UMAS 對方面-情感對提取性能有1.29個百分點的提升.結果表明了底層的特征共享對2 個子任務的性能提升都有幫助,通過建立2 個任務之間的語義聯系有利于提高方面-情感對提取的準確率.
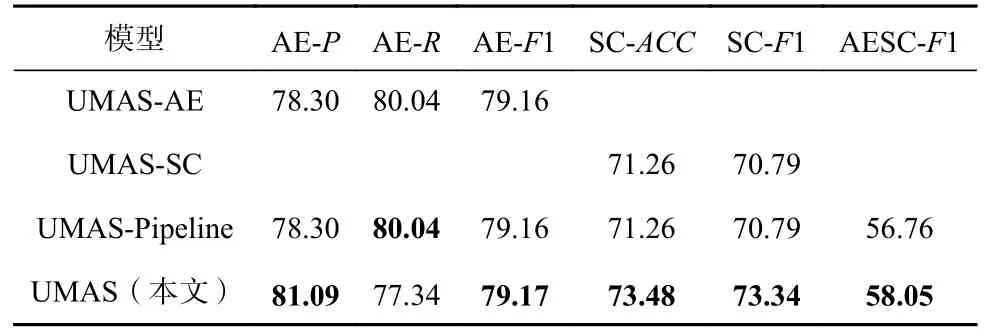
Table 7 Comparison of Unified Model and Single-Task Model表7 統一框架和單任務模型的對比 %
結合表4、表5、表7,可以看出本文的方面術語提取單任務模型比ACN 的性能高了4.24 個百分點,驗證了詞性特征對方面術語提取的重要影響.相比于其他方面級情感分類,本文的單任務情感分類模型也有較大的改善,說明觀點詞和位置信息對情感分類有一定的幫助.
3.5.2 消融實驗
首先介紹UMAS 的7 個變體模型.
1)UMAS-no_visual.刪除視覺特征.
2)UMAS-no_POS_features.刪除詞性特征.
3)UMAS-no_opinion.刪除情感分類模塊中觀點詞特征.
4)UMAS-no_self_attention.刪除情感分類模塊中情感特征的自注意機制.
5)UMAS-no_gate_fusion.將情感分類模塊中私有特征獲取部分的門控融合機制改為直接拼接操作.
6)UMAS-special.只保留情感模塊中私有特征部分中的特有情感特征,刪除共享文本特征.
7)UMAS-share.只保留情感模塊中私有特征部分中的共享文本特征,刪除特有情感特征.
表8 報告了變體模型的性能.通過分別消除視覺特征、詞性特征、觀點特征、情感模塊的自注意機制、情感模塊私有特征的門控融合機制、情感模塊的共享文本特征、情感模塊的特有特征,驗證了各個部分存在的作用.由于2 個模塊之間存在參數的共享,所以一個模塊的結構的變化不僅影響自身,而且影響另一個模塊.表8 的第1 行和最后1 行的對比顯示了視覺特征對方面術語提取和情感分類模塊都有明顯的性能提升,F1 值分別提升了2.45 個百分點和2.07個百分點.情感分類模塊中的觀點詞特征將方面級情感分類的性能整體提升了2.61 個百分點.情感模塊的自注意機制對該模塊的性能有2.83 個百分點的提升.情感模塊私有特征獲取的門控融合機制,既考慮了方面對情感預測的影響,也考慮了情感特征本身的重要性,將情感分類的F1 提升了3.59 個百分點,AESC 性能提升了2.35 個百分點.根據表8 最后3 行的結果,可以看出在情感分類模塊中的私有特征部分單獨使用共享特征或特有特征的效果都不好,將這二者融合是最佳的選擇.
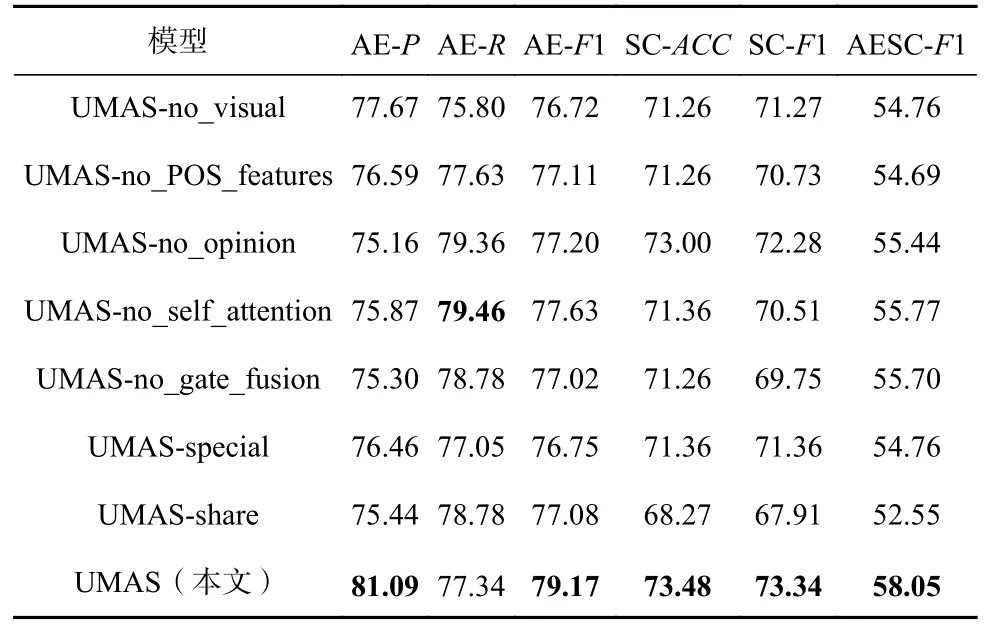
Table 8 Results of Ablation Experiment表8 消融實驗結果 %
3.5.3 補充實驗
為了說明情感分類模塊私有特征部分不同選擇的不同效果,本節進行了相關的可視化分析.首先,情感分類模塊的私有特征可以有3 種選擇:情感模塊私有文本編碼器輸出的特有情感表示、共享文本編碼器輸出的共享文本表示、特有情感表示和共享文本表示的融合特征.為了方便說明,將這3 種特征對應的模型記為UMAS-special,UMAS-share,UMAScombine.表9 說明了圖3、圖4 涉及的統計量的含義.

Table 9 Instruction of Statistics表9 統計量說明
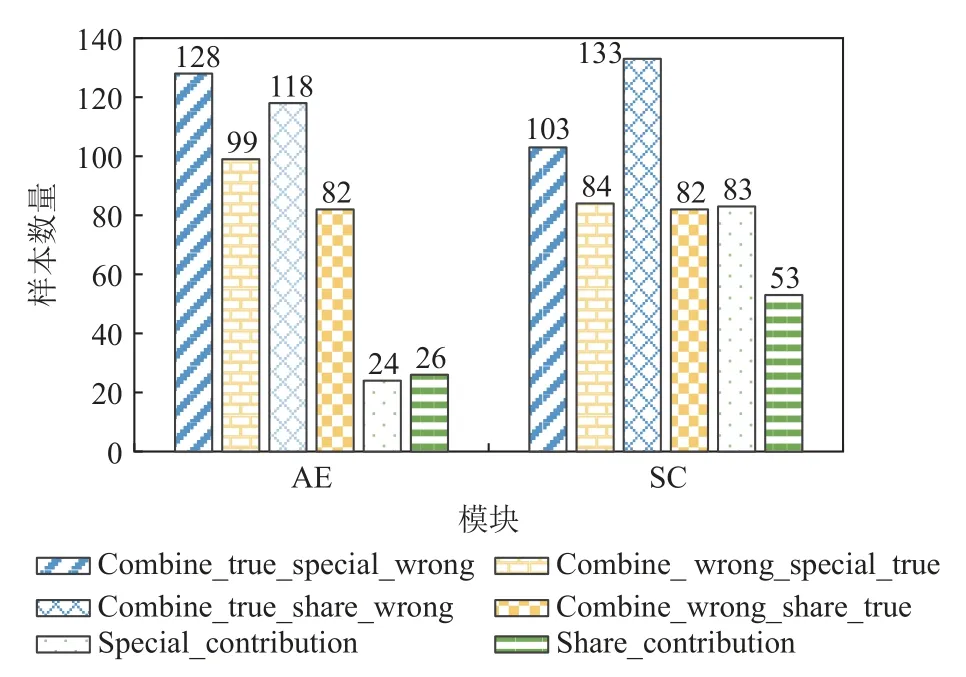
Fig.3 Result comparison of different sentiment private features圖3 不同情感私有特征的結果對比
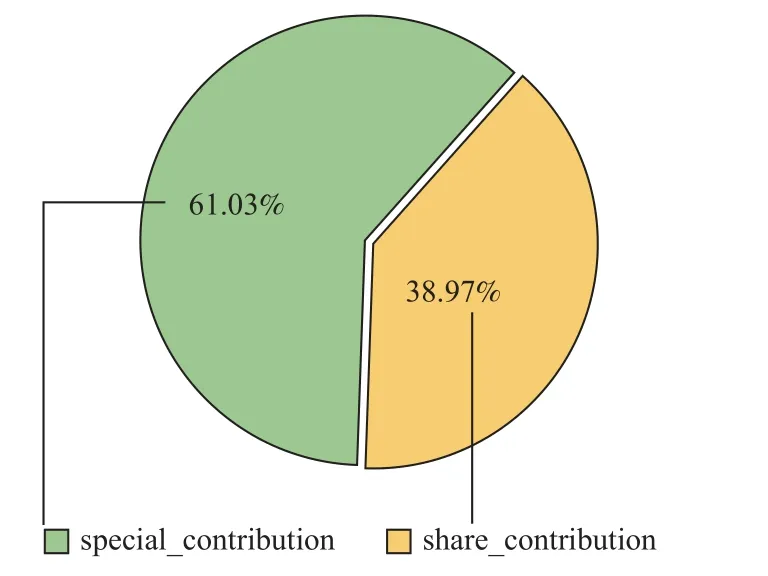
Fig.4 Different representations contribute to sentiment classification圖4 不同表示對情感分類的貢獻
圖3 顯示了不同情感私有特征表示的結果.首先,在AE 模塊,UMAS-combine 預測正確且UMASspecial 預測錯誤的數量為128,而UMAS-combine 預測錯誤且UMAS-special 預測正確的數量為99,說明UMAS-combine 對UMAS-special 的糾正能力要強于UMAS-special 對UMAS-combine 的糾正能力,即UMAScombine 模型的性能較優越.通過圖3 中其他數據的對比分析,可以發現無論是對方面術語提取還是情感分類,UMAS-combine 的性能總是要強于UMASspecial 和UMAS-share.其次,在情感分類模塊,UMASspecial 預測正確而UMAS-share 預測錯誤的數量為83,而UMAS-share 預測正確而UMAS-special 預測錯誤的數量為53,體現了特有情感特征和共享特征對情感模塊性能的不同貢獻.圖4 展示了特有情感特征和共享特征對情感模塊的不同貢獻程度,特有情感特征的貢獻約為60%,共享特征的貢獻程度約為40%.
綜上體現了將特有情感特征和共享文本特征進行動態融合的必要性,且特有情感特征對方面級情感分類的貢獻比較突出.同時,也說明了方面術語提取和方面級情感分類2 個任務之間既有聯系又有區別,既要考慮2 個任務之間的交互關系,又要充分考慮任務本身的特征.
4 總結與展望
為了解決目前AESC 任務流水線方法的不足,本文提出了多模態方面術語提取和方面級情感分類的統一框架UMAS.該統一框架使用3 個共享編碼器,即文本、圖像、詞性編碼器構建方面術語提取模塊和情感分類模塊底層的共享特征模塊.該共享特征模塊不僅使模型在訓練過程中學習到2 個任務之間的語義聯系,而且簡化了模型.同時,該統一框架能并行地執行2 個子任務,同時輸出句子中的多個方面及其對應的情感類別,解決了流水線方法效率低的問題.此外,本文通過詞性標注獲取單詞的詞性,并使用多頭自注意機制獲取詞性特征,將視覺特征、文本特征、詞性特征融合作為方面術語提取模塊解碼器的輸入,提升了方面術語提取的性能.在情感分類模塊,本文使用詞性識別句子中的觀點詞,在情感分析中增加對這些觀點詞的注意權重并考慮位置信息以提升情感分類的性能.本文所提出的統一框架在Twitter2015和Restaurant2014 這2 個數據集上相比于其他基線模型都有良好的表現.
隨著transformer,BERT 等技術的不斷發展,在未來的研究中可以考慮將預訓練技術加入到本文模型中以獲得更好的特征表示.
作者貢獻聲明:周如提出了算法思路和撰寫論文;朱浩澤提出了實驗方案并負責完成實驗;郭文雅、于勝龍、張瑩提出指導意見并修改論文.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
