基于多種同構(gòu)化變換的SLP 向量化方法
2023-12-15 04:48:02馮競舸賀也平陶秋銘馬恒太
計算機研究與發(fā)展 2023年12期
馮競舸 賀也平,2 陶秋銘 馬恒太
1 (基礎軟件國家工程研究中心(中國科學院軟件研究所) 北京 100190)
2 (計算機科學國家重點實驗室(中國科學院軟件研究所) 北京 100190)(jingge@iscas.ac.cn)
自動向量化[1]是利用處理器單指令多數(shù)據(jù)(single instruction multiple data,SIMD)擴展部件實現(xiàn)程序數(shù)據(jù)級并行的編譯優(yōu)化方法,它與手工編寫SIMD 向量程序相比,不需要程序員深入理解SIMD 擴展部件的功能特性,減少了程序員的負擔.隨著SIMD 硬件擴展指令集的不斷發(fā)展,向量指令應用的領(lǐng)域和需求也越來越多,然而如何生成高效的向量指令至今依然是個挑戰(zhàn)[2-3].
目前自動向量化主要有2 大類方法:基于循環(huán)的自動向量化方法[4]和超字級并行(superword level parallelism,SLP)自動向量化方法[5],其分別旨在實現(xiàn)循環(huán)和基本塊的自動向量化.SLP 一直是向量化領(lǐng)域關(guān)注的重要方法,本文重點對其展開研究.
SLP 方法通過尋找同構(gòu)指令序列[5],將數(shù)據(jù)合并到同一向量寄存器中并行處理.由于同構(gòu)指令序列在實際程序中占比不是很高以及方法自身的原因[6],SLP 的適用范圍受限.近年來,有研究者開始關(guān)注于通過等價變換將滿足特定條件的非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列,從而為實施SLP 創(chuàng)造條件.如PSLP 方法[7]采用基于程序差異特征的圖模式匹配,通過添加選擇(select)指令進行擴充,從而將非同構(gòu)指令序列轉(zhuǎn)換成同構(gòu)指令序列.LSLP 方法[8]利用交換律等價關(guān)系式對非同構(gòu)序列中的運算操作和操作數(shù)進行重排,從而獲得同構(gòu)指令序列.類似地,SNSLP 方法[9]和SLP-E 方法[10]分別采用減法/除法的等價關(guān)系式和擴展等價關(guān)系式對非同構(gòu)序列中的運算操作和操作數(shù)進行變換,從而獲得同構(gòu)指令序列.
除了采用的同構(gòu)化轉(zhuǎn)換方法外,我們發(fā)現(xiàn)實際還存在其他方法可應用于指令序列同構(gòu)化轉(zhuǎn)換中.例如利用二元表達式等價替換關(guān)系(如X× 4=X<<2)將非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列.
在對非同構(gòu)指令序列進行SLP 向量化時,充分利用多種同構(gòu)化轉(zhuǎn)換方法比只考慮單一轉(zhuǎn)換方法更有優(yōu)勢.例如在SPEC CPU 基準測試程序中存在一些包含多條二元操作且存在常量操作數(shù)的語句,需要經(jīng)過多種方法的同構(gòu)化轉(zhuǎn)換后才可對其有效實施自動向量化.然而,目前還無文獻專門針對同時利用多種同構(gòu)化轉(zhuǎn)換的向量化方法進行研究.
與只考慮單一同構(gòu)化轉(zhuǎn)換不同,當考慮多種同構(gòu)化轉(zhuǎn)換方法時,需解決同構(gòu)化轉(zhuǎn)換方法的選擇問題.對于任一非同構(gòu)指令序列,首先需要分析確認哪些同構(gòu)化轉(zhuǎn)換方法適用;其次,對于同一指令序列不同同構(gòu)化轉(zhuǎn)換方法產(chǎn)生的代價是不同的,需要選擇合適的同構(gòu)化轉(zhuǎn)換方法,提升程序的自動向量化性能收益.因此指令序列同構(gòu)化轉(zhuǎn)換方法的選擇涉及2個問題:問題1:一些指令序列存在不同的同構(gòu)化轉(zhuǎn)換方法,需進行適用同構(gòu)化轉(zhuǎn)換方法的識別和搜索.問題2:不同同構(gòu)化轉(zhuǎn)換方法產(chǎn)生的收益不同,需要針對各種同構(gòu)化轉(zhuǎn)換方法給出收益評估方法.
本文提出一種SLP 擴展方法——SLP-M 向量化方法,將多種方法應用于非同構(gòu)指令序列的同構(gòu)化轉(zhuǎn)換中,并評估每種同構(gòu)化轉(zhuǎn)換方法的性能收益,根據(jù)收益進行同構(gòu)化轉(zhuǎn)換方法的選擇.為了解決同構(gòu)化轉(zhuǎn)換方法選擇的第1 個問題,本文利用處理程序的特性和同構(gòu)化轉(zhuǎn)換方法的特點進行分析,采用啟發(fā)式方法,優(yōu)先搜索那些需轉(zhuǎn)換指令數(shù)量較少以及引入自動向量化的性能收益相對較高的同構(gòu)化轉(zhuǎn)換方法.為了解決同構(gòu)化轉(zhuǎn)換方法選擇的第2 個問題,本文發(fā)現(xiàn)指令的操作類型相似程度越大,那么這些語句越容易被實施自動向量化,越有機會帶來自動向量化的性能收益,因此利用程序操作及操作數(shù)的類型相似程度并結(jié)合同構(gòu)化轉(zhuǎn)換方法的特征進行收益評估.
SLP-M 方法與先前工作的主要區(qū)別在于:
1)SLP-M 綜合利用多種方法(包括二元表達式等價替換、擴展變換、基于shuffle 指令的變換等)進行同構(gòu)化轉(zhuǎn)換,而先前的PSLP 和LSLP 等方法都只采用了單一類型的同構(gòu)化轉(zhuǎn)換方法.SLP-M 與先前工作比較,提高了將非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列的能力.其中,基于二元表達式替換的指令序列同構(gòu)化轉(zhuǎn)換方法與PSLP 比較,對于特定類型程序,不需要生成引入額外運行代價的指令就可進行同構(gòu)化轉(zhuǎn)換.基于二元表達式的替換變換與LSLP 和SNSLP 進行比較,能夠同構(gòu)化轉(zhuǎn)換一些先前方法不能同構(gòu)化轉(zhuǎn)換的指令序列.
2)由于SLP-M 綜合采用多種同構(gòu)化轉(zhuǎn)換方法,為了選擇合適的同構(gòu)化轉(zhuǎn)換方式,SLP-M 方法解決了采用多種方法進行同構(gòu)化轉(zhuǎn)換過程中的一些特殊問題,如多種同構(gòu)化轉(zhuǎn)換方法的識別、搜索和選擇等,這些是PSLP 和LSLP 等工作未涉及的.
本文基于LLVMv10.0 實現(xiàn)了SLP-M 方法,并基于SPEC CPU 2017 等測試集進行了測試和評估.實驗結(jié)果表明,本方法相比已有方法在核心函數(shù)測試中性能提升了21.8%,在基準測試程序整體性能測試中性能提升了4.1%.
本文的主要貢獻包括3 個方面:
1)提出基于多種指令序列同構(gòu)化轉(zhuǎn)換方法的SLP-M 向量化方法,擴展了對非同構(gòu)指令序列的自動向量化適用范圍;
2)除了已有指令序列同構(gòu)化轉(zhuǎn)換方法,本文還引入和利用了基于二元表達式替換的方法,該方法不僅不會引入額外運行代價,而且減少了指令的操作類型和數(shù)量;
3)提出指令序列同構(gòu)化轉(zhuǎn)換的選擇方法,發(fā)揮了多種同構(gòu)化轉(zhuǎn)換方法的優(yōu)勢,提升了對非同構(gòu)指令序列自動向量化的性能收益.
1 背景與研究動機
目前大部分關(guān)于自動向量化的研究主要是針對某類特殊類型的程序向量化,將某個具體的程序變換方法與自動向量化結(jié)合,或利用某個特殊SIMD 擴展指令優(yōu)化自動向量化等方法,這些研究往往對特定類型程序是有效的,但是利用單一自動向量化方法變換后得到的結(jié)果并不總是有效.例如循環(huán),既可包含循環(huán)內(nèi)的并行語句又可包含循環(huán)間的并行語句,如果單獨利用基于循環(huán)或基本塊內(nèi)的自動向量化方法,得到的向量化方案不總是最優(yōu)的.
超字級并行[5]是對基本塊內(nèi)同構(gòu)指令序列進行自動向量化的方法,可有效提升程序的性能,得到許多研究者的關(guān)注和進一步研究,相關(guān)成果集中于基于同構(gòu)指令序列構(gòu)建同構(gòu)鏈[7]的研究,具體包含2 方面內(nèi)容:1)擴展SLP 向量化的適用范圍,如旨在對循環(huán)[11-15]和包含分支程序[16]的向量化,以及多級融合(跨循環(huán)和跨基本塊融合)[17]的向量化.2)提高向量化的性能收益,利用全局策略或局部貪心策略構(gòu)建同構(gòu)鏈,提高生成向量指令收益,減少重組指令的代價.全局策略構(gòu)建同構(gòu)鏈方法是基于全局搜索的方式構(gòu)建同構(gòu)鏈[18-21].局部貪心策略構(gòu)建同構(gòu)鏈方法是基于局部貪心策略逐層構(gòu)建同構(gòu)鏈[22-24].此外,除了應用于自動向量化,SLP 方法也被擴展應用于動態(tài)二進制翻譯[25]、內(nèi)嵌匯編形式向量代碼優(yōu)化[26]和非SIMD向量指令優(yōu)化[27]等領(lǐng)域.
SLP 方法有賴于先找到程序中的同構(gòu)指令序列,這對SLP 方法的實際應用造成一定局限.近年來,有學者[7]開始關(guān)注如何將SLP 方法擴展應用到非同構(gòu)指令序列如PSLP 和LSLP 等,PSLP 和LSLP 等方法將特定的非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列,然后再進一步實施向量化.然而,PSLP 和LSLP 等方法都存在其特定的適用范圍,如果單一實施,向量化能力有限.
圖1 描繪了SPEC CPU 2017 625case 中的一段程序代碼采用幾種不同的自動向量化方法進行處理的過程.其中圖1(a)(b)分別為一段包含非同構(gòu)指令序列的輸入程序及其對應的數(shù)據(jù)依賴圖.圖1(c)(e)(g)(i)是將多條標量指令轉(zhuǎn)換為向量形式的分組圖,其中,陰影長方形表示可自動向量化的操作或操作數(shù);虛線框的長方形表示自動向量化所需生成的存在額外運行代價的指令.向量分組圖中的benefit表示自動向量化的收益,即標量指令代價與向量指令代價的差值,若benefit>0,則自動向量化有收益,編譯器實施自動向量化;否則自動向量化無收益,編譯器不進行程序轉(zhuǎn)換.圖1(d)(f)(h)表示不同自動向量化方法處理輸入程序的轉(zhuǎn)換過程.
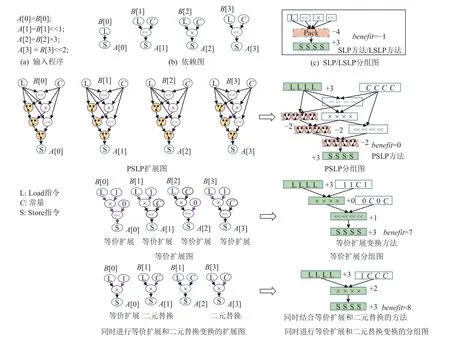
Fig.1 Process of various auto-vectorization methods adopted by an example program圖1 一個示例程序采用不同自動向量化方法進行處理的過程
SLP 方法的向量分組如圖1(c)所示.SLP 方法先以A[0],A[1],A[2],A[3]連續(xù)內(nèi)存訪問為種子,并基于種子擴展同構(gòu)指令序列,擴展中發(fā)現(xiàn)訪存、移位、乘法操作,其類型不同,因而停止同構(gòu)指令序列的進一步擴展,編譯器評估自動向量化無收益,因此不對輸入程序進行轉(zhuǎn)換.
PSLP 方法對輸入程序的處理流程如圖1(d)(e)所示,代碼中4 條語句對應數(shù)據(jù)依賴圖的差異較大,PSLP 方法在自動向量化中生成較多額外運行代價的選擇指令,編譯器評估自動向量化無收益,因此不對輸入程序進行程序轉(zhuǎn)換.
LSLP 方法只能對可交換運算操作的操作數(shù)進行重排序,由于處理中的訪存、移位、乘法操作不都是可交換運算操作,因此無法實施同構(gòu)化轉(zhuǎn)換.SNSLP 方法與LSLP 方法類似,無法對輸入程序?qū)嵤┳詣酉蛄炕?
對于圖1(a)中的原始輸入程序,其實存在的多種適用的同構(gòu)化轉(zhuǎn)換方法至少有2 種:
1)通過擴展轉(zhuǎn)換關(guān)系將非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列.如圖1(f)(g)所示,先將第1 行語句的B[0]擴展變換為B[0]<<0,然后將第3 行的B[2]×3擴展變換為(B[2]×3)<<0,這樣程序轉(zhuǎn)為A[0]=B[0]<<0;A[1]=B[1]<<1;A[2]=(B[2]×3)<<0;A[3]=B[3]<<2,最后對第1,2,4 行語句擴展乘法操作,將程序轉(zhuǎn)為同構(gòu)形式.從性能收益上考慮,由于將輸入程序中的2 個標量移位和1 個標量乘法替換為1 個向量移位和1個向量乘法,對于移位和乘法而言自動向量化的收益為1,再加上將輸入程序的8 個標量訪存轉(zhuǎn)換為2個向量訪存,自動向量化總體收益是7,可有效實施自動向量化.
2)同時采用擴展轉(zhuǎn)換關(guān)系和二元表達式等價替換關(guān)系將非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列.如圖1(h)(i)所示,首先將第1 行語句的B[0]擴展變換為B[0]×1,然 后 將 第2 行 語 句 的B[1]<<1 替 換 為B[1]×2,最后同理對第4 行語句進行二元表達式替換,使非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列,與上文單獨采用擴展變換比較,減少了向量移位操作,此時自動向量化可帶來收益(benefit= 8),因此,進一步提升了自動向量化的性能收益.
從上面2 種轉(zhuǎn)換示例可以看出:1)當引入多種同構(gòu)化轉(zhuǎn)換方法的時候,確實能夠獲得更多的向量化機會和性能收益;2)選擇不同同構(gòu)化轉(zhuǎn)換方法會影響向量化的性能收益.有鑒于此,本文希望研究和實現(xiàn)能夠有效利用多種指令序列同構(gòu)化轉(zhuǎn)換方式的向量化方法.
2 指令序列同構(gòu)化轉(zhuǎn)換方法
目前已有的指令序列同構(gòu)化轉(zhuǎn)換方法不是很多.PSLP 方法可以被認為是第1 個對非同構(gòu)指令序列進行轉(zhuǎn)換研究的工作,它利用硬件選擇指令來實施同構(gòu)化轉(zhuǎn)換.此后,有研究者注意到可以基于表達式等價關(guān)系實現(xiàn)同構(gòu)化轉(zhuǎn)換.例如LSLP 方法利用交換律進行同構(gòu)化轉(zhuǎn)換,SN-SLP 方法利用減法以及除法等價關(guān)系式進行同構(gòu)化轉(zhuǎn)換,SLP-M 利用等價擴展變換進行同構(gòu)化轉(zhuǎn)換.除了上述涉及操作符/操作數(shù)順序和個數(shù)變化的表達式等價變換外,我們發(fā)現(xiàn)實際還存在多種其他涉及操作符類型變化的等價轉(zhuǎn)換關(guān)系 可 應 用 于 同 構(gòu) 化 轉(zhuǎn) 換 中,如X<<2=X×4,X×2=X+X等,也就是可將“形式不同但本質(zhì)功能相同”的操作符等價轉(zhuǎn)為類型相同的操作符.
結(jié)合目前已有方法以及我們自己的分析歸納,本文采用了4 種指令序列同構(gòu)化轉(zhuǎn)換方法:基于shuffle 指令的同構(gòu)化轉(zhuǎn)換、重排序變換、擴展變換、二元表達式替換.下面逐一介紹.
2.1 基于shuffle 指令的同構(gòu)化轉(zhuǎn)換
shuffle 是將多個數(shù)據(jù)合并、重組和排序的指令,通常包含2 個輸入操作數(shù)和1 個輸出操作數(shù),輸出操作數(shù)是輸入操作數(shù)重組后的數(shù)據(jù).絕大部分處理器都支持類似shuffle 功能的指令,如x86 和ARM 系列處理器等.
基于shuffle 指令的同構(gòu)化轉(zhuǎn)換方法是指利用shuffle 指令將不同的操作合并到同一向量寄存器,并基于它們相同位置的操作數(shù),向“定義—使用”鏈和“使用—定義”鏈的方向繼續(xù)建立擴展同構(gòu)指令序列的程序變換方式.基于shuffle 指令的同構(gòu)化轉(zhuǎn)換與PSLP 方法中采用選擇指令的轉(zhuǎn)換方法本質(zhì)相同,都是將不同類型的操作通過特殊指令合并到同一向量寄存器中.選擇指令的向量形式是基于shuffle 指令實現(xiàn)的.
具體示例如圖2 所示,其中圖2(a)(b)分別是輸入程序以及對應的依賴圖,圖2(c)表示利用shuffle指令將減法和乘法操作合并到同一向量寄存器中.
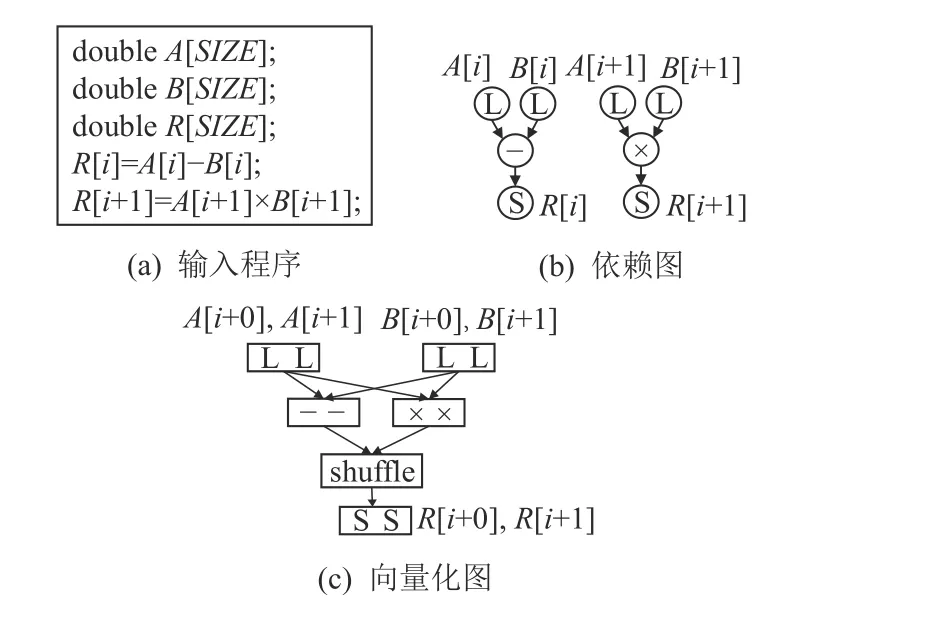
Fig.2 An example of program transformation based on shuffle instruction圖2 基于shuffle 指令的程序轉(zhuǎn)換示例
2.2 重排序變換
重排序變換指基于交換律、減法性質(zhì)[9]或者除法性質(zhì)[9]的等價變換,通過重排序操作符或操作數(shù)獲得同構(gòu)指令序列,涉及操作符或操作數(shù)順序變化,不涉及其個數(shù)和類型的改變.
基于交換律的重排序等價變換式如:A?B= =B?A,其中?是可交換運算,A和B是?的操作數(shù).滿足交換律的運算普遍存在于實際程序中,包括加法、乘法、與運算、或運算等.重排序可交換運算的操作數(shù),如LSLP 方法,使得多個可交換運算的操作數(shù)所對應的指令組成同構(gòu)指令序列,如將c[0]=a[0]+b[0]和c[1]=b[1]+a[1]的第2 條語句變換為c[1]=a[1]+b[1].則這2 條語句加法的第1 個和第2 個操作數(shù)分別是a[0],a[1],b[0],b[1],它們是連續(xù)的內(nèi)存訪問,可實施向量化.
SN-SLP 所采用的減法性質(zhì)是只由減法或加法所組成的表達式,交換其減法以及對應操作數(shù)的順序,輸出值不變?nèi)鏰-b+c=a+c-b,所采用的除法性質(zhì)類似.SN-SLP 方法采用運算符性質(zhì)的重排序變換,使得多個減法或者除法運算的操作數(shù)組成同構(gòu)指令序列,如a[0]=b[0]-c[0]-d[0]和a[1]=b[1]-d[1]-c[1]可通過減法性質(zhì)將a[1]=b[1]-d[1]-c[1]變換為a[1]=b[1]-c[1]-d[1],則這2 條語句減法對應的操作數(shù)分別為a[0],a[1];b[0],b[1];c[0],c[1],它們是連續(xù)的內(nèi)存訪問,可實施向量化.
2.3 擴展變換
擴展變換是通過對表達式進行等價的擴展變換[10],將程序中非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列,涉及操作符和操作數(shù)的個數(shù)改變.
首先介紹擴展等價表達式.如果一個二元運算?、常數(shù)C(C為0 或1),以及X(X可為變量、常量或者表達式)滿足X?C= =X或C?X= =X,那么本文把X?C或C?X稱為X的擴展等價表達式.擴展等價表達式存在多種類型,表1 給出了本文已實現(xiàn)的擴展等價表達式.

Table 1 Equivalent Extended Expression of X表1 X 的擴展等價表達式
擴展變換就是將表達式X轉(zhuǎn)換為X的擴展等價表達式,使其擴展表達式的操作在特定條件可與其他的操作組成同構(gòu)指令序列.擴展變換示例如圖3 所示,其中圖3(a)(b)分別是輸入程序以及對應的依賴圖.圖3(c)表示通過擴展變換方法將第1 行語句的B[0]擴展為B[0]×1,擴展變換后獲得同構(gòu)語句.
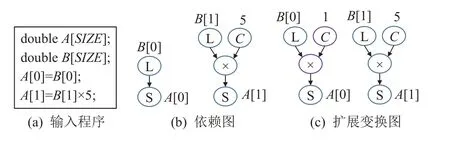
Fig.3 An example of extended transform圖3 擴展變換示例
2.4 二元表達式替換
二元表達式替換是本文新引入的一種等價變換.在介紹該變換前,先引入二元替換等價表達式的概念.對于表達式1 :X?Y,表達式2 :Z?K,若同時滿足3 個條件則表達式2 被稱為表達式1 的二元替換等價表達式:
1)表達式1 和表達式2 中的?和?都是二元操作符,且操作符類型不同;
2)表達式1 和表達式2 至少存在1 個相同的操作數(shù);
3)表達式1 中?可被直接替換為?(不涉及操作符個數(shù)的變化),且表達式1 和表達式2 輸出值相同.
二元表達式替換是指將程序中特定的二元表達式轉(zhuǎn)換為其二元替換等價表達式,進而將程序中的非同構(gòu)指令序列轉(zhuǎn)換為同構(gòu)指令序列.二元替換等價表達式在程序中存在多種類型,本文已實現(xiàn)的表達式類型如表2 所示.二元表達式替換不同于重排序變換和擴展變換,不涉及操作符順序和個數(shù)的改變,而涉及操作符類型的改變.

Table 2 List of Patterns of Replacement for Binary Expressions表2 二元表達式替換模式列表
二元表達式替換示例如圖4 所示,其中圖4(a)(b)分別是輸入程序以及對應的依賴圖.圖4(c)表示通過二元表達式替換的方法將第1 行語句的移位操作替換為乘法操作,進而將其轉(zhuǎn)換為同構(gòu)的形式.
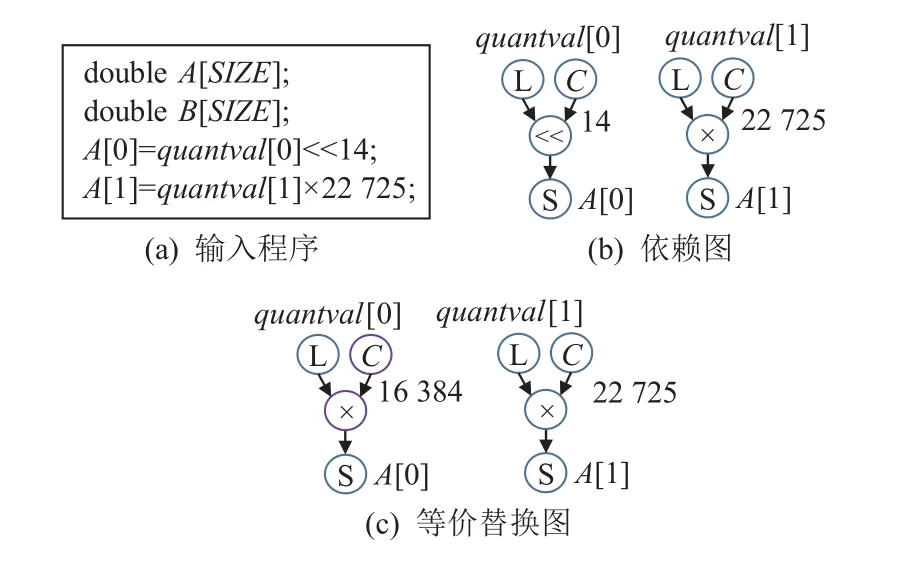
Fig.4 An example of replacement of binary expression圖4 二元表達式替換示例
3 SLP-M 向量化方法
3.1 方法概述
SLP-M 是一種改進的SLP 向量化方法.SLP 的基本處理過程是基于“種子”并根據(jù)“定義-使用(defuse)”鏈和“使用-定義(use-def)”鏈擴展同構(gòu)圖,然后結(jié)合同構(gòu)圖分析向量及標量形式代碼的代價,若向量代碼代價相對較低,則實施自動向量化.SLP 方法不考慮對非同構(gòu)指令序列的向量化,而SLP-M 對SLP 的改進就在于對非同構(gòu)指令序列的分析和處理,SLP-M 會嘗試對非同構(gòu)指令序列進行同構(gòu)化轉(zhuǎn)換,并在條件滿足時對非同構(gòu)指令序列實施自動向量化.
SLP-M 引入和運用了多種同構(gòu)化轉(zhuǎn)換方法,包括基于shuffle 指令的轉(zhuǎn)換、重排序變換、擴展變換、二元表達式替換.如引言所述,當考慮多種同構(gòu)化轉(zhuǎn)換方法時候,對于同一指令序列有時存在多種適用的同構(gòu)化轉(zhuǎn)換方法,需解決同構(gòu)化轉(zhuǎn)換方法的選擇問題.同時,對于同一指令序列不同的同構(gòu)化轉(zhuǎn)換方法產(chǎn)生的代價不同,需要選擇合適的同構(gòu)化轉(zhuǎn)換方法,提升程序的自動向量化性能收益.該問題主要涉及2 個問題.
問題1.同構(gòu)化轉(zhuǎn)換方法的識別和搜索.
有些指令序列存在大量適用的同構(gòu)化轉(zhuǎn)換方法,例如shuffle 指令理論上可把任意的操作存放到同一向量寄存器中,這就引入了很多轉(zhuǎn)換方法.若采用窮舉法遍歷每種適用的同構(gòu)化轉(zhuǎn)換方法,那么方法數(shù)量成指數(shù)級增長,計算復雜度太高.因此需要尋找和設計高效的同構(gòu)化轉(zhuǎn)換方法的識別和搜索方法.
問題2.針對特定同構(gòu)化轉(zhuǎn)換方法的收益評估.
不同同構(gòu)化轉(zhuǎn)換方法不僅影響目標處理指令序列,而且影響其操作數(shù),進而影響自動向量化的整體性能收益,需針對每種方法進行整體性能收益評估.
對于問題1,本文結(jié)合處理程序及同構(gòu)化轉(zhuǎn)換方法的特點,給出了一種啟發(fā)式方法用以識別和搜索更有機會帶來性能收益的轉(zhuǎn)換方式.同構(gòu)化轉(zhuǎn)換的目的是以選擇1 個指令作為基準參照指令,通過等價轉(zhuǎn)換使指令序列中其他所有指令與其操作類型相同.原則上指令序列中的每個指令都可選作基準參照指令.但如果啟發(fā)式將指令序列中的每個指令都嘗試作為基準參照指令,遍歷所有適用的同構(gòu)化轉(zhuǎn)換方式,計算復雜度太大.其實,許多非同構(gòu)指令序列是可以被自動向量化的,這些指令序列中大部分指令的操作類型是相似的.若將指令序列中的與其他指令相似程度最高的指令作為基準參照指令(本文中被稱為基準指令,參見3.2 節(jié)),那么以基準指令作為參照的同構(gòu)化轉(zhuǎn)換的候選集合大概率會包含適用于這類指令序列的同構(gòu)化轉(zhuǎn)換方式.鑒于此,SLPM 以基準指令作為參照,然后結(jié)合不同同構(gòu)化轉(zhuǎn)換方法的具體特點,如轉(zhuǎn)換方式對操作的處理以及引入自動向量化的額外運行代價等,啟發(fā)式識別和搜索更有機會帶來自動向量化性能收益的具體變換方式.
對于問題2,需要評估指令序列在不同方法同構(gòu)化轉(zhuǎn)換下自動向量化的整體性能收益,SLP-M 利用程序?qū)蕾噲D中的操作類型相似信息評估自動向量化的性能收益,從目標處理指令對應依賴圖中的節(jié)點開始,并遞歸沿著其子孫節(jié)點的方向,分析指令操作及其操作數(shù)的同構(gòu)化轉(zhuǎn)換方法,評估并統(tǒng)計整體的性能收益.
本文利用多種方法來進行同構(gòu)化轉(zhuǎn)換,利用基準指令的選擇方法來啟發(fā)式識別和選擇合理的同構(gòu)化轉(zhuǎn)換方法,降低選擇的代價,通過同構(gòu)化轉(zhuǎn)換方法的搜索并利用評估模型來評估適合的方法,由此得到自動向量化性能收益較高的具體變換方式.而PSLP 和LSLP 等采用單一類型的同構(gòu)化轉(zhuǎn)換方法,不存在多種同構(gòu)化轉(zhuǎn)換方法的搜索和選擇問題,因此未用到基準指令的選擇和同構(gòu)化轉(zhuǎn)換的搜索方法.
SLP-M 的方法處理流程圖如圖5 所示,其中同構(gòu)化分析及轉(zhuǎn)換包括4 個具體步驟:1)基準指令的選擇.根據(jù)程序?qū)蕾噲D中操作節(jié)點及子孫節(jié)點的信息選擇基準指令.2)同構(gòu)化轉(zhuǎn)換方法的搜索.針對特定的指令序列搜索適用的同構(gòu)化轉(zhuǎn)換方法.3)同構(gòu)化轉(zhuǎn)換方法的選擇.評估收益并選擇其中評估性能收益最高的同構(gòu)化轉(zhuǎn)換方法.4)同構(gòu)化轉(zhuǎn)換.下面對這4 個步驟分別進行介紹.
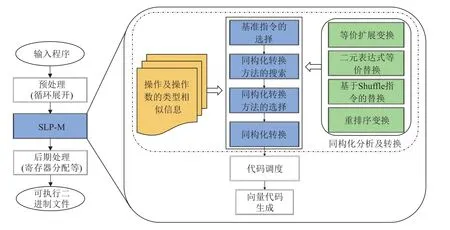
Fig.5 Process flow of SLP-M圖5 SLP-M 的處理流程
3.2 基準指令的選擇
為了選擇基準指令,SLP-M 遍歷指令序列中的每個指令,計算該指令與其他指令對應依賴圖中的操作類型相同節(jié)點(下文稱為“匹配節(jié)點”)的個數(shù),或者可通過二元表達式替換轉(zhuǎn)換為匹配節(jié)點的個數(shù).SLP-M 將與指令序列中其他指令的匹配節(jié)點個數(shù)最多的指令作為基準指令.SLP-M 選擇基準指令的步驟有2 個.
1)遍歷處理指令序列insts中的每個指令(記為指令x_inst),計算指令x_inst與指令序列中其他指令(記為指令y_inst)的對應依賴圖中的匹配節(jié)點或者可通過二元表達式替換轉(zhuǎn)換為匹配節(jié)點總數(shù).計算匹配節(jié)點個數(shù)的方法是:從指令x_inst和指令y_inst對應依賴圖的節(jié)點開始自底向上統(tǒng)計匹配節(jié)點個數(shù).
①若指令x_inst和指令y_inst的操作類型相同,統(tǒng)計計數(shù)加1,繼續(xù)向它們的子節(jié)點方向統(tǒng)計計算;
②若指令x_inst和指令y_inst的操作類型不同,但可通過二元等價替換的方式將指令y_inst轉(zhuǎn)換為與指令x_inst相同類型的操作,實施二元等價替換,并統(tǒng)計計數(shù)加1,繼續(xù)向它們的子節(jié)點方向統(tǒng)計計算;
③若指令x_inst和指令y_inst的操作類型不同,且無法通過二元表達式替換轉(zhuǎn)換為與其相同的操作,或者遇到葉子節(jié)點,則停止向它們的子節(jié)點方向統(tǒng)計計算.
2)根據(jù)步驟1 計算的匹配節(jié)點個數(shù),選擇指令序列insts中與其他指令對應匹配個數(shù)最多的指令為基準指令.當多個指令與其他指令的匹配節(jié)點個數(shù)相同時,可啟發(fā)式選擇排在更前面的指令.
3.3 同構(gòu)化轉(zhuǎn)換方法的搜索
在求得基準指令后,SLP-M 以基準指令作為參照,搜索將指令序列中的指令轉(zhuǎn)換為與基準指令類型相同操作的轉(zhuǎn)換方式.本文根據(jù)特定方法的轉(zhuǎn)換特征,如轉(zhuǎn)換方式對操作的處理以及引入自動向量化的額外運行代價,搜索每種同構(gòu)化轉(zhuǎn)換方法具體的轉(zhuǎn)換方式.
基于shuffle 指令的程序轉(zhuǎn)換會生成shuffle 指令,引入額外運行代價.SLP-M 排除引入較多額外運行代價轉(zhuǎn)換的具體變換方式,僅考慮對于指令序列包含2 類二元操作的條件下將基于shuffle 指令的同構(gòu)化轉(zhuǎn)換納入候選同構(gòu)化的轉(zhuǎn)換方式.
重排序變換通過重排序指令的操作以及操作數(shù)使得在特定條件下增多自動向量化語句的數(shù)量[8-9]不會引入額外代價.因此,若在指令序列中存在與基準指令操作類型相同的可交換運算操作,SLP-M 會將對其的重排序變換納入候選同構(gòu)化轉(zhuǎn)換方式.
擴展變換將指令轉(zhuǎn)換為其的擴展等價表達式,使得擴展后的指令與原始程序的指令組成同構(gòu)指令序列,盡管在程序擴展轉(zhuǎn)換中增加了運算指令,但是這些指令可與原程序中標量代碼一同轉(zhuǎn)為向量形式,不會引入自動向量化的額外運行代價.因此,若指令存在與基準指令操作類型相同的等價擴展式,SLPM 會將對其的擴展變換納入候選同構(gòu)化轉(zhuǎn)換方式.
二元表達式替換變換是在特定的條件下將一個表達式替換為另一個表達式,使替換后指令與原始程序的指令組成同構(gòu)指令序列,盡管存在會將代價較低的標量指令轉(zhuǎn)為代價較高的標量指令的情形,但是轉(zhuǎn)換生成的指令可與原始程序一同轉(zhuǎn)為向量形式,因此向量化不會引入額外運行代價,且由于替換變換減少了源程序標量操作的種類,因此向量化后進一步減少生成指令的種類和數(shù)量.若指令存在與基準指令操作類型相同的二元表達式替換式,SLPM 會將對其的二元表達式替換變換納入候選同構(gòu)化轉(zhuǎn)換方式.
為了表示指令序列的同構(gòu)化轉(zhuǎn)換方式,本文沿用文獻[18]中指令對和轉(zhuǎn)換模式的術(shù)語,并結(jié)合本文要解決的同構(gòu)化轉(zhuǎn)換問題進一步明確其含義:1)指令對.指由2 個指令組成的集合.2)轉(zhuǎn)換模式.指對于特定的指令對,描述其操作、操作數(shù)、具體的同構(gòu)化轉(zhuǎn)換方式的集合,包括操作指令集合v、同構(gòu)化轉(zhuǎn)換方式action和同構(gòu)化轉(zhuǎn)換后的操作集合v′這3 個部分,可表示為(v,action,v′)三元組形式,轉(zhuǎn)換模式示例如圖6 所示.1 個指令序列可由1 個或者多個指令對組成,其同構(gòu)轉(zhuǎn)換方式可描述為其中多個指令對的轉(zhuǎn)換模式集合.
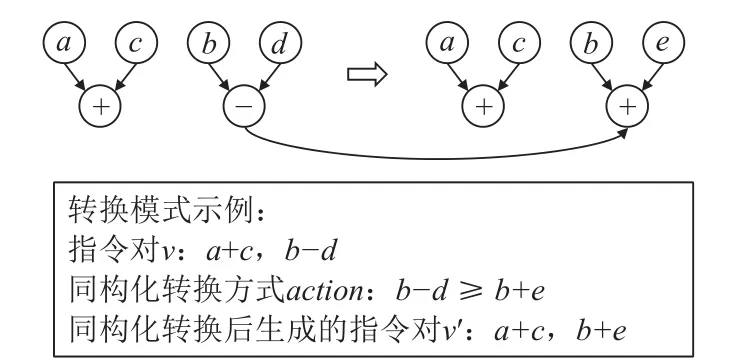
Fig.6 An example of conversion pattern圖6 轉(zhuǎn)換模式示例
對于指令序列insts,SLP-M 首先搜索滿足2 個條件的指令對集合inst_pairs:1)指令對中的指令都屬于指令序列insts;2)指令對中必須包含insts的基準指令.然后,針對inst_pairs中的每個指令對,在第2.1~2.3 節(jié)描述的同構(gòu)化轉(zhuǎn)換的可轉(zhuǎn)換條件所述滿足特定條件的候選同構(gòu)轉(zhuǎn)換方式中遍歷所有可將其中的非基準指令轉(zhuǎn)換為與基準指令相同類型操作的轉(zhuǎn)換方式,將其記錄于轉(zhuǎn)換模式集合patterns中.
3.4 同構(gòu)化轉(zhuǎn)換方法的選擇及實施
在搜索完所有具體適用的同構(gòu)化轉(zhuǎn)換方法后,需評估每種方法自動向量化的性能收益,根據(jù)收益進行同構(gòu)化轉(zhuǎn)換方法的選擇.考慮到評估方法的效率和準確度,同構(gòu)化轉(zhuǎn)換方法的選擇以及實施向量化的評估分步處理,本文設計相對高效的基于操作符和操作數(shù)類型的相似信息評估模型進行同構(gòu)化轉(zhuǎn)換方法的選擇,待確定具體的同構(gòu)化轉(zhuǎn)換方式后,利用準確度相對較高的LLVM 自帶的評估模型判定是否實施向量化,若評估有收益則實施向量化,否則程序以原標量形式執(zhí)行.為了評估自動向量化的性能收益,本文介紹2 個基本概念.
1)單層指令對的自動向量化收益.指對于1 個指令對,對其進行自動向量化獲得性能收益.這里給出單層指令對的自動向量化收益評估方法,具體描述為:
①若指令對的2 條指令的操作類型相同,則單層指令對的收益計為1;
②若指令對的2 條指令經(jīng)過二元表達式替換或者重排序變換后,其操作的類型相同,則單層指令對的收益計為1;
③若指令對的2 條指令需經(jīng)過擴展變換后,其操作的類型相同,則單層指令對的收益計為0;
④若指令對2 條指令的操作類型不同,且無法通過同構(gòu)化轉(zhuǎn)換方法將其轉(zhuǎn)為操作類型相同的形式,則單層指令對的收益計為0.
2)整體指令對的自動向量化收益.指對于1 個指令對,若對其進行自動向量化,其本身指令對以及子操作數(shù)所依賴所有指令對自動向量化性能收益的總和.這里給出評估整體指令對自動向量化收益的方法,即整體指令對的自動向量化收益是單層指令對的自動向量化收益與其操作數(shù)所組成指令對的整體指令對自動向量化收益之和.整體指令對的自動向量化收益計算如式(1)所示,其中x和y都是指令,x.operands(k)和y.operands(k)分別是指令x和指令y的第k個操作數(shù),scorewhole是整體指令對〈x,y〉的自動向量化收益,scoresingle是單層指令對〈x,y〉的自動向量化收益.
SLP-M 通過評估每個指令對在特定轉(zhuǎn)換模式下的整體指令,對自動向量化收益選擇同構(gòu)化轉(zhuǎn)換方法,同構(gòu)化轉(zhuǎn)換選擇函數(shù)pattern_selection偽代碼如函數(shù)1 所示.
函數(shù)1.pattern_selection.
輸入:指令序列insts;
輸出:匹配分數(shù)score,相對最優(yōu)的同構(gòu)化轉(zhuǎn)換方法pattern.
①base_inst = get_base_inst(insts); /*求得基準指令*/
/*遍歷指令序列中每條指令*/
② for(eachinstininsts)
③patterns=search_pattern(inst,base_inst);/*遍歷搜索指令適用的轉(zhuǎn)換模式,
將其存儲到集合patterns中*/
④ if(patterns= NULL)then
⑤ return;
⑥ end if
⑦ if (inst=base_inst)then
⑧ continue;
⑨ end if
⑩best_score= 0; /*best_score用于記錄最優(yōu)轉(zhuǎn)換模式的分數(shù)*/
?best_pattern= NULL; /*best_pattern用于記錄最優(yōu)的轉(zhuǎn)換模式*/
/*遍歷所有的轉(zhuǎn)換模式*/
? for eachpatterninpatterns
?out_inst=patterns.out_inst(); /*out_inst用于存儲特定轉(zhuǎn)換模式轉(zhuǎn)換后輸出的指令*/
?score=init_score(patterns); /*初始化特定轉(zhuǎn)換模式的分數(shù)*/
?score=score+cal_match_score(base_inst,inst); /*計算特定轉(zhuǎn)換模式的分數(shù)*/
? if(score>best_score)then
?best_score=score;
?best_pattern=pattern;
? end if
? end for
?insts_score+=best_score;
?insts_pattern[inst] =best_pattern; /*insts_pattern用于存儲指令序列的最優(yōu)轉(zhuǎn)換模式*/
? end for
? return(insts_score,insts_pattern).
為了計算整體指令對自動向量化的收益,需要計算指令對的單層自動向量化收益以及其子操作數(shù)所組成指令對的整體指令對的自動向量化收益.SLPM 的目標是找到使得整體指令對自動向量化收益相對最大的同構(gòu)化轉(zhuǎn)換方式.SLP-M 利用每種方法轉(zhuǎn)換后的指令序列的依賴圖,沿著對應的節(jié)點自底向上遞歸統(tǒng)計和評估,先評估子操作數(shù)對應指令對在每種轉(zhuǎn)換方法下的整體收益,并選擇收益最大的同構(gòu)化轉(zhuǎn)換方式,再進行指令對的整體自動向量化的收益評估和同構(gòu)化轉(zhuǎn)換方法的選擇.具體整體指令對自動向量化收益評估函數(shù)的偽代碼詳見函數(shù)2 和函數(shù)3.
函數(shù)2.cal_match_score.
輸入:指令base_inst,指令inst;
輸出:匹配分數(shù)match_score.
①best_score= 0;
/*若可進行擴展變換,則進行分數(shù)評估*/
② if(can_extend_trans(get_opcode(base_inst),get_opcode(inst)))then
③new_inst=get_extended_expression(base_inst,inst); /*嘗試進行擴展變換分析*/
④extend_score=cal_match_score_1(base_inst,new_inst); /*遞歸計算指令的操作數(shù)分數(shù)*/
⑤ if(extended_score>best_score)then
⑥best_score=extended_score;
⑦ end if
⑧ end if
/*若可進行二元表達式替換或重排序變換,則進行分數(shù)評估*/
⑨ if(can_binary_trans(get_opcode(base_inst),get_opcode(inst)))then
⑩new_inst=get_bin_trans_expression(base_inst,inst); /*嘗試進行二元表達式替換或重排序變換分析*/
?bin_trans_score= 1 +cal_match_score_1(base_inst,new_inst); /*遞歸計算指令的操作數(shù)分數(shù)*/
? if(bin_trans_score>best_score)then
?best_score=bin_trans_score;
? end if
? end if
/*若原始指令可進行向量化*/
? if(can_vectorize(base_inst,inst))then
?original_score= 1 +cal_match_score_1(base_inst,inst);
? if(original_score>best_score)then
?best_score=original_score;
? end if
? end if
? returnbest_score.
函數(shù)3.cal_match_score_1.
輸入:指令base_inst,指令inst;
輸出:匹配分數(shù)score.
①score= 0;
② for eachoperand_idxofbase_inst
③base_operand=get_operand(base_inst,operand_idx); /*求得基準指令的操作數(shù)*/
④new_operand=get_operand(new_inst,operand_idx);/*求得轉(zhuǎn)換得到新指令的操作數(shù)*/
/*調(diào)用函數(shù)cal_match_score求得最優(yōu)轉(zhuǎn)換模式和分數(shù)*/
⑤operand_score=cal_match_score(base_operand,new_operand);
⑥score+=operand_score;
⑦ end for
⑧ returnscore.
值得注意的是,由于基于shuffle 指令的變換方式會引入額外運行代價,SLP-M 評估其收益需特殊考慮,在上述類似評估方法的基礎上減去生成shuffle 指令的代價.SLP-M 在評估完基于shuffle 指令的收益后,將其與其他同構(gòu)化轉(zhuǎn)換方法的收益比較,選擇收益較高的同構(gòu)化轉(zhuǎn)換方法.待完成處理程序的整體同構(gòu)化轉(zhuǎn)換方式的選擇后,SLP-M 利用LLVM中SLP 實現(xiàn)的評估模型判定該程序是否實施向量化,若評估有收益則實施向量化.
處理程序?qū)蕾噲D的高度對SLP-M 的性能收益和編譯時間存在較大的影響.SLP-M 利用操作符和操作數(shù)的類型信息進行同構(gòu)化轉(zhuǎn)換方法的選擇,分析程序?qū)蕾噲D高度越高,采用的類型相似信息越多,越有助于同構(gòu)化轉(zhuǎn)換方法的選擇.然而,采用優(yōu)化程序?qū)蕾噲D高度過高并不總能有效提升程序的性能收益,并且由于需要分析更多的同構(gòu)化轉(zhuǎn)換選擇方式和評估計算,增加了較多的編譯優(yōu)化時間.其實,為了有效提升程序的性能,考慮整體優(yōu)化程序?qū)蕾噲D不是必要的.由于SLP-M 方法與SLP 都是類似自底向上構(gòu)建同構(gòu)圖,與根節(jié)點距離較近的節(jié)點對于向量化的收益評估更重要[7],而節(jié)點的高度越高,其對應向量化的收益評估的重要性越低.由于依賴圖高度較高的節(jié)點依賴于高度較低節(jié)點,因同構(gòu)化轉(zhuǎn)換需要生成更多數(shù)量的額外代價指令的概率增高,因此高度較高的節(jié)點可向量化的難度更大.我們在實驗中發(fā)現(xiàn)絕大部分可有效向量化的層數(shù)不超過20.
同構(gòu)化轉(zhuǎn)換方法選擇的具體實施過程示例如圖7 所示.圖7(a)(b)分別為一段包含4 條語句的輸入程序及其對應的數(shù)據(jù)依賴圖.假設SLP-M 正在處理由指令x0,x1,x2,x3 組成的指令序列〈x0,x1,x2,x3〉,其操作分別為訪存、移位、乘法、移位.為了選擇基準指令,SLP-M 遍歷指令序列中的每條指令,計算與其他指令在對應依賴圖中匹配的節(jié)點個數(shù)或者可通過二元表達式替換可轉(zhuǎn)換為匹配的節(jié)點個數(shù),將其作為基準指令的評估分數(shù).
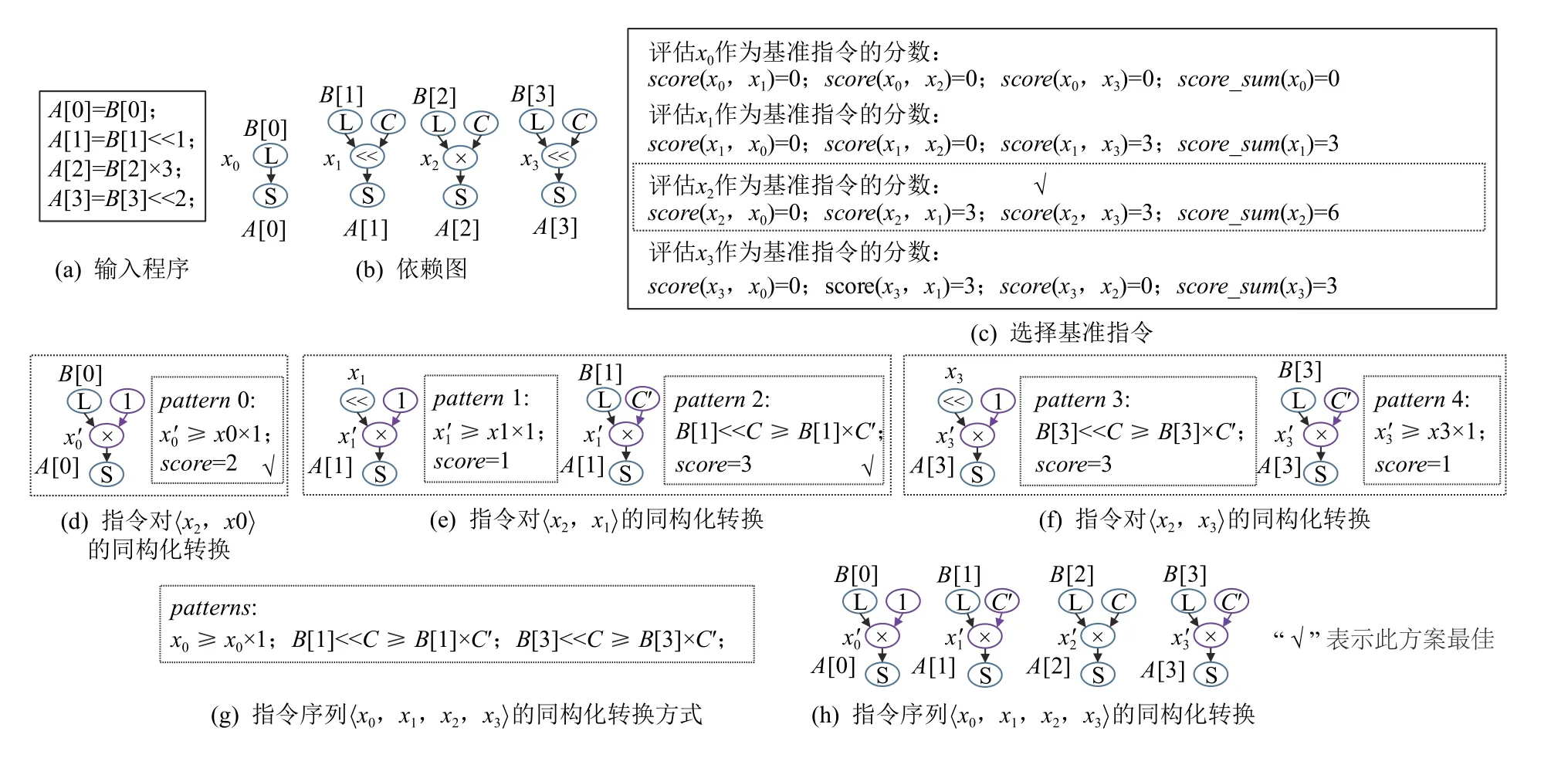
Fig.7 An example of isomorphism transform selection method圖7 同構(gòu)化轉(zhuǎn)換選擇方法示例
首先,評估x0 作為基準指令的分數(shù),其他指令及其二元表達式替換后的指令與x0 都沒有操作類型相同的形式,因此指令x0 作為基準指令的評估分數(shù)是0.
其次,評估x1 作為基準指令的分數(shù),x0 和x2 及其二元表達式替換后的指令與x1 都沒有操作類型相同的形式,因此x1 分別與x0 和x2 的匹配分數(shù)均是0,x3 與x1 的操作類型相同,繼續(xù)沿著對應依賴圖,向其子孫節(jié)點遞歸計算匹配分數(shù),共計包含3 個匹配節(jié)點,分別是移位操作、內(nèi)存訪問操作、常量操作.因此x1 與x3 的匹配分數(shù)是3.綜上,x1 作為基準指令的評估分數(shù)是與上述其他指令匹配分數(shù)的總和,即score_sum(x1)=0+0+3=3.
然后,評估x2 作為基準指令的分數(shù),x0 與x2 沒有操作類型相同的形式,因此x2 與x0 的匹配分數(shù)是0,x1 和x3 都可通過二元表達式替換轉(zhuǎn)換為與x2 操作類型相同的形式,繼續(xù)沿著對應依賴圖,向其子孫節(jié)點遞歸計算匹配分數(shù)得到x2 分別與x1 和x3 的匹配分數(shù)都是3.綜上,x2 作為基準指令的評估分數(shù)score_sum(x2)= 0+3+3=6.
最后,評估x3 作為基準指令的分數(shù),與計算x1作為基準指令的評估過程類似,計算得到x3 作為基準指令的評估分數(shù)是3.根據(jù)上文計算得到的匹配分數(shù),指令x2 的分數(shù)最多,因此SLP-M 將其作為基準指令.
SLP-M 在確定基準指令后,搜索在指令序列〈x0,x1,x2,x3〉中包含基準指令x2 的所有指令對,如指令對〈x2,x0〉,〈x2,x1〉,〈x2,x3〉,然后針對每個指令對,搜索所有適用的轉(zhuǎn)換模式pattern0,pattern1,pattern2等.接下來計算每個同構(gòu)化轉(zhuǎn)換模式下的指令對的整體自動向量化的收益.
指令對〈x2,x0〉包含同構(gòu)化轉(zhuǎn)換模式pattern0.pattern0 將x0 擴展變換為x0′,根據(jù)3.4 節(jié)所示的單層指令對收益評估方法,x2 與x0′的單層指令對的收益為0,繼續(xù)沿著對應依賴圖,向其子孫節(jié)點遞歸計算單層指令對的收益,x2 和x0′的第1 個操作數(shù)節(jié)點對應的指令分別是B[2]和B[0],其操作類型相同,因此B[2]和B[0]的單層指令對的收益為1,同理x2 和x0′的第2 個操作數(shù)都是常量操作,它們對應的單層指令對的收益為1,進而得出指令對〈x2,x0〉在轉(zhuǎn)換模式pattern0 下的整體指令對的自動向量化收益為score(pattern0)=0+1+1=2.
指令對〈x2,x1〉包含同構(gòu)化轉(zhuǎn)換模式pattern1 和pattern2.pattern1 將x1 擴展變換為x1′,根據(jù)3.4 節(jié)所示的單層指令對收益評估方法,x2 與x1′的單層指令對收益為0,繼續(xù)沿著對應依賴圖,向其子孫節(jié)點遞歸計算單層指令對的收益,x2 和x1′的第1 個操作數(shù)節(jié)點對應的指令分別是B[2]和移位操作,其操作類型不同,并且沒有適用的同構(gòu)化方法可將移位操作轉(zhuǎn)為與B[2]操作類型相同的形式,因此B[2]和移位操作的單層指令對的收益為0.x2 和x1′的第2 個操作數(shù)都是常量操作,它們對應的單層指令對的收益為1.進而得出指令對〈x2,x1〉在轉(zhuǎn)換模式pattern1 下的整體指令對的自動向量化收益為score(pattern1)=1.pattern2 是將B[1]<<C等價替換為B[1]×C′,其中x1′是由x1 二元表達式替換生成的,x2 與x1′的單層指令對的收益為1,繼續(xù)沿著對應依賴圖,向其子孫節(jié)點遞歸計算單層指令對的收益,x2 和x1′的第1 個操作數(shù)節(jié)點對應的指令分別是B[2]和B[1],其操作類型相同,B[2]和B[1]的單層指令對的收益為1.同理x2和x1′的第2 個操作數(shù)都是常量操作,它們對應的單層指令對的收益為1,進而得出指令對〈x2,x1〉在轉(zhuǎn)換模式pattern2 下的整體指令對的自動向量化收益為score(pattern2)=1+1+1=3.
指令對〈x2,x3〉包含同構(gòu)化轉(zhuǎn)換模式pattern3 和pattern4,其計算過程與pattern1 和pattern2 的計算過程類似,它們整體指令對的自動向量化收益分別為3 和1.
在計算完所有轉(zhuǎn)換模式下的整體指令對的自動向量化收益,根據(jù)收益選擇每個指令對的同構(gòu)化轉(zhuǎn)換方式.指令對〈x2,x0〉只包含一種同構(gòu)化轉(zhuǎn)換模式pattern0,將其作為指令對〈x2,x0〉同構(gòu)化轉(zhuǎn)換方式.指令對〈x2,x1〉包含2 種同構(gòu)化轉(zhuǎn)換方式pattern1 和pattern2,由于pattern2 下的整體指令對的自動向量化收益相對較高,因此pattern2 作為指令對〈x2,x1〉的同構(gòu)化轉(zhuǎn)換方式,同理,pattern3 作為指令對〈x2,x3〉的同構(gòu)化轉(zhuǎn)換方式.
在分析完成指令對〈x2,x0〉,〈x2,x1〉,〈x2,x3〉的同構(gòu)化轉(zhuǎn)換方式后,SLP-M 也就確定了指令序列〈x0,x1,x2,x3〉中每條指令的同構(gòu)化轉(zhuǎn)換方式,如圖7(g)(h)所示.
在選出同構(gòu)化轉(zhuǎn)換方法后,SLP-M 方法實施相應轉(zhuǎn)換,并繼續(xù)向其子節(jié)點方向擴展同構(gòu)鏈,直到遇到葉子節(jié)點或者無適用的同構(gòu)化轉(zhuǎn)換為止.
對于可同時處理的指令數(shù)量,SLP-M 方法與已有方法如PSLP 和LSLP 等類似,根據(jù)實際處理器所支持的SIMD 擴展部件的寄存器長度和程序特征選擇向量化因子[14].若處理指令存在差異如指令類型或排布等,本文將嘗試利用擴展變換和二元表達式替換等同構(gòu)化轉(zhuǎn)換方法并進行選擇.若可利用上述方式進行同構(gòu)化轉(zhuǎn)換且有收益則進行向量化,否則采用與PSLP 和LSLP 類似的方法,將向量化因子減半,繼續(xù)進行同構(gòu)化分析及轉(zhuǎn)換,直到存在有收益的向量化轉(zhuǎn)換方式或者向量化因子等于1 時為止.
4 實驗與結(jié)果分析
本文基于LLVMv10.0 實現(xiàn)了SLP-M 方法,從構(gòu)造函數(shù)、基于SPEC CPU 2017/2006/2000 和MediaBench[28]測試集提取的核心函數(shù)、整體測試3 個方面對SLPM 方法進行測試,并與SLP 方法和PSLP 方法進行對比.目前LLVM 中實現(xiàn)的SLP 方法如LLVM-SLP 已經(jīng)集成了LSLP 和SN-SLP 方法,本文不再另外單獨將LSLP 和SN-SLP 與SLP-M 比較.實驗所用計算機的處理器型號為Intel i7-4 790,其主頻為 3.2 GHz,支持AVX2,AVX1,SSE 向量指令集,其中AVX2 的向量寄存器長度為256 b,它能同時處理4 個double 數(shù)據(jù)或者8 個float 數(shù)據(jù).AVX1 和SSE 的向量寄存器長度為128 b,它能同時處理2 個double 數(shù)據(jù)或者4 個float 數(shù)據(jù).測試處理器包含4 個物理核,每個物理核可 支持2 個 邏 輯 核,L1 緩 存 大 小 為32 KB(8way,64B/line),L2 為256 KB(8way,64B/line),L3 為8 MB(共享內(nèi)存),內(nèi)存為20 GB,操作系統(tǒng)為Ubuntu20.04.實數(shù)域的運算性質(zhì)在計算機的浮點實現(xiàn)存在偏差[29-30],為了保證基于等價表達式的程序變換,維持原始程序語義不變,本文采用原始LLVM 編譯器中相關(guān)變換對操作及操作數(shù)類型的限制規(guī)則,具體詳見LLVM 的常量折疊以及強度削弱優(yōu)化的具體實現(xiàn)[31].如3.4 節(jié)所述隨著彼此依賴指令數(shù)量的增多,本文方法所需的編譯運行時間逐步增多,絕大部分可有效向量化程序?qū)蕾噲D高度較低,為了確保SLP-M編譯優(yōu)化在合理時間范圍內(nèi),本文實驗限定優(yōu)化程序?qū)蕾噲D的高度不超過20.后續(xù)程序員可綜合考慮程序特征和優(yōu)化時間設定該數(shù)值.
4.1 構(gòu)造函數(shù)測試
為了考察各種SLP 向量化方法的分析處理能力,本文構(gòu)造了多種非同構(gòu)指令序列的程序,覆蓋了各種典型的語句間差異,包括操作類型不同、操作個數(shù)不同、數(shù)據(jù)類型不同及語句數(shù)量不同.具體如表3所示.
本文測試了多種自動向量化方法在構(gòu)造測試程序上運行時間,計算了各種自動向量化方法相對于在關(guān)閉SLP 向量化優(yōu)化條件下的O3 優(yōu)化加速比,也就是LLVM 編譯器關(guān)閉SLP 向量化功能的優(yōu)化,并打開其他所有LLVM O3 編譯優(yōu)化功能,包括開啟循環(huán)自動向量化和循環(huán)展開優(yōu)化等,其編譯選項為-O3-march=haswell -mtune=haswell -fno-slp-vectorize,后續(xù)為描述方便,本文利用O3 表示上述的編譯優(yōu)化.其他多種自動向量化方法都是在O3 優(yōu)化條件的基礎上打開特定的向量化優(yōu)化方法.除了測試SLPM 外,本文還測試了在SLP-M 優(yōu)化基礎上關(guān)閉二元表達式替換功能優(yōu)化的性能,用于評估二元表達式替換優(yōu)化對性能的影響,為了描述方便,用SLP-MRelaceOff 表示.性能結(jié)果如圖8 所示,其中,橫軸表示測試程序,縱軸表示不同方法在測試程序上相對于O3 的 性 能 加 速 比.LLVM-SLP、 PSLP、 SLP-MRelaceOff、SLP-M 的 平 均 加 速 比 分 別 為1.08,1.29,1.34,3.17.對于大部分程序,SLP-M 顯著提升了程序的性能,而LLVM-SLP 和PSLP 對程序的性能提升幅度相對較小.

Fig.8 Speedup ratios of various methods on constructing kernel functions圖8 不同方法在構(gòu)造核心函數(shù)上的加速比
下面分析多種優(yōu)化方法對構(gòu)造函數(shù)編譯優(yōu)化的測試結(jié)果,分別從操作個數(shù)不同、操作類型不同、操作個數(shù)及操作類型都不同的3 類構(gòu)造函數(shù)進行分析.
1)操作個數(shù)不同的程序包括測試程序s1,s4,s8 等.LLVM-SLP 對其中大部分程序,如s1 和s4,未實施自動向量化,也未有效提升該類程序的性能.PSLP,SLP-M-RelaceOff,SLP-M 對其中所有程序?qū)嵤┝俗詣酉蛄炕M一步提升了程序的性能.
2)操作類型不同的程序包括測試程序s2,s5 和s9 等.LLVM-SLP,PSLP,SLP-M-RelaceOff 通 過 生 成shuffle 指令,對其中少數(shù)程序?qū)嵤┝俗詣酉蛄炕ㄈ鐂2 和s5),提升了該類程序的性能.SLP-M 對該類程序都實施了自動向量化,且通過二元表達式替換和減少了其中的操作種類數(shù)量,進一步提升了該類程序的 性 能.例 如LLVM-SLP,PSLP,SLP-M-RelaceOff,SLP-M 都對s9 實施了自動向量化,LLVM-SLP,PSLP,SLP-M-RelaceOff 都利用了向量乘法、向量除法、shuffle 指令組合實施了自動向量化.我們發(fā)現(xiàn)盡管LLVM-SLP 方法采用了向量的代碼形式,而與O3 采用標量的代碼形式比較,并未帶來實際性能提升.SLPM 將s9 中的除法轉(zhuǎn)為乘法,并實施了自動向量化,由于乘法操作相比于除法操作在Intel 機器上實際執(zhí)行快數(shù)倍,因此顯著提升了程序的性能,s2 也類似.
3)操作數(shù)量及類型都不同的程序包括測試程序s6,s10,s15 等,LLVM-SLP,PSLP,SLP-M-RelaceOff 對于其中大部分程序要么未實施向量化,要么只對其中部分語句實施向量化,對該類程序的程序的性能提升幅度較少.SLP-M 對該類程序都實施了自動向量化,顯著地提升了該類程序的性能.例如s6 包含訪存、乘法、移位操作.LLVM-SLP 未對該類程序?qū)嵤┳詣酉蛄炕琍SLP 方法和SLP-M-RelaceOff 方法盡管可將該類程序轉(zhuǎn)換為同構(gòu)的形式,但是向量化無收益,因此未實施向量化.SLP-M 方法采用了多種同構(gòu)化轉(zhuǎn)換方法,將s6 第1 條語句的b[0]轉(zhuǎn)換為b[0]×1,將第3條語句中的移位操作轉(zhuǎn)為乘法操作,進而實施了向量化,有效提升了程序的性能.對于s15,SLP-M 可顯著提升其性能的原因與s9 類似,都是減少了向量除法操作以及重組指令操作帶來的性能提升.
除了測試和計算了性能加速比外,本文還通過LLVM 自帶的性能評估模型,評估了各種向量化方法對于構(gòu)造核心函數(shù)的性能收益.圖9 是LLVM 統(tǒng)計多種優(yōu)化方法對測試程序相對于O3 編譯優(yōu)化減少指令代價的統(tǒng)計圖,其中橫軸表示核心函數(shù),縱軸表示程序經(jīng)過自動向量化方法的優(yōu)化后,利用LLVM評估模型得出的減少的指令代價.總體而言,SLP-M方法自動向量化減少的指令代價多于其他方法,這反映出SLP-M 方法較強的自動向量化優(yōu)化能力,能夠有效提升向量化的性能收益.
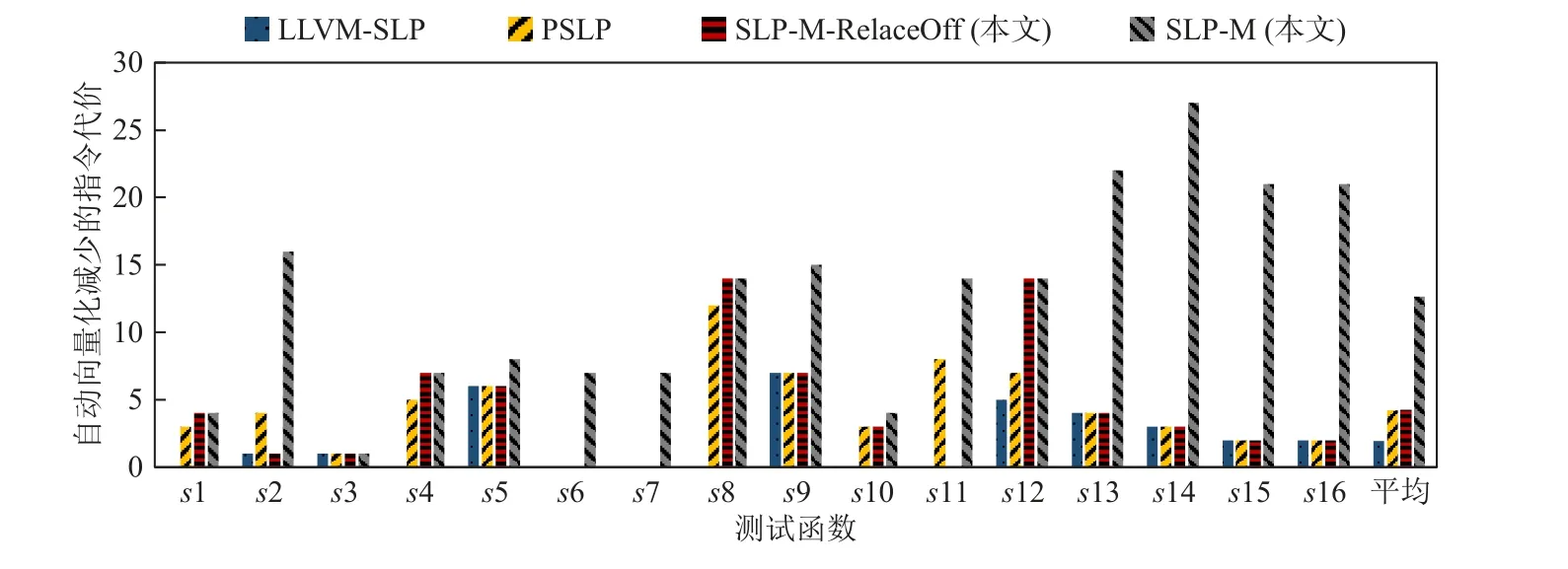
Fig.9 Reduced instruction costs of auto-vectorization methods on constructing kernel functions圖9 構(gòu)造核心函數(shù)自動向量化方法減少的指令代價
4.2 實際應用核心函數(shù)測試
本文從實際應用如SPEC CPU 2017/2006/2000 和MediaBench2 基準測試集中提取代表性的核心函數(shù)代碼片段,如表4 所示.提取的核心函數(shù)代碼片段主要來自在科學計算領(lǐng)域和多媒體領(lǐng)域計算密集型的代碼(如生物系統(tǒng)模擬和影像關(guān)系追蹤等),其熱點包含較多的非同構(gòu)指令序列,代碼覆蓋了程序中語句間的典型差異,包括操作類型不同、操作個數(shù)不同,同時包含類型及個數(shù)上的差異.本文通過在循環(huán)中多次執(zhí)行同一個核心函數(shù),使得總體運行時間超過20 min,以減小環(huán)境因素影響.
Table 4 Description of the Kernel Functions表4 核心函數(shù)描述
本文測試了多種自動向量化方法在核心函數(shù)上的運行時間,計算了各種自動向量化方法相對于O3的加速比,結(jié)果如圖10 所示,其中,橫軸表示測試程序,縱軸表示不同方法在測試程序上相對于O3 的性能加速比,LLVM-SLP,PSLP,SLP-M-RelaceOff,SLPM 的平均加速比分別為1.0,1.25,1.1,1.6.SLP-M 相對于LLVM-SLP(包含LSLP 和SN-SLP)的平均性能提升了40.4%,相對于PSLP 的平均性能提升了21.8%.

Fig.10 Speedup ratios of various methods on kernel functions圖10 不同方法在核心函數(shù)上的加速比
下面分析多種優(yōu)化方法對實際應用核心函數(shù)編譯優(yōu)化的測試結(jié)果,也是分別對不同操作個數(shù)、不同操作類型、不同操作個數(shù)及操作類型的3 類程序進行分析.
對于第1 類操作個數(shù)不同的程序,SLP 未能有效提升該類程序的性能,PSLP,SLP-M-RelaceOff,SLPM 可顯著提升其中部分程序的性能.對于函數(shù)gl_render_vb,其核心代碼片段如圖11(a)所示,盡管4 條語句都是同構(gòu)的,但是第4 條語句在自動向量化前編譯器將其中的i- 0 變換為i,使得轉(zhuǎn)換后的語句不是同構(gòu)的,LLVM-SLP 未對該程序?qū)嵤┳詣酉蛄炕琍SLP,SLP-M-RelaceOff,SLP-M 對其實施了自動向量化,具體的不同自動向量化生成的匯編代碼如圖12所示.對于函數(shù)u2s,其核心代碼片段如圖11(b)所示,LLVM-SLP 和PSLP 同構(gòu)化轉(zhuǎn)換能力較弱,無法對其進行同構(gòu)化轉(zhuǎn)換,因此未對其實施自動向量化,實際以標量形式執(zhí)行.而SLP-M-RelaceOff 和SLP-M 盡管可對其實施自動向量化,但是性能反而不如標量程序的性能,通過查看匯編程序發(fā)現(xiàn),SLP-M 將32 b 轉(zhuǎn)換為8 b 類型數(shù)據(jù)中生成了代價較高的非對齊訪存以及重組指令,在這種情況下自動向量化不能帶來性能收益,然而在實施向量化評估中本文采用了LLVM 的評估代價模型,其分析是有收益的,因此對該程序?qū)嵤┝讼蛄炕湫阅懿蝗鐦肆砍绦?函數(shù)calc_pair_energy與函數(shù)gl_render_vb類似,如圖11(c),SLP 未對其實施自動向量化,PSLP,SLP-M-RelaceOff,SLP-M 對其實施了自動向量化.

Fig.11 Code fragments of the kernel function with different numbers with opcodes圖11 不同操作數(shù)量的核心函數(shù)代碼片段
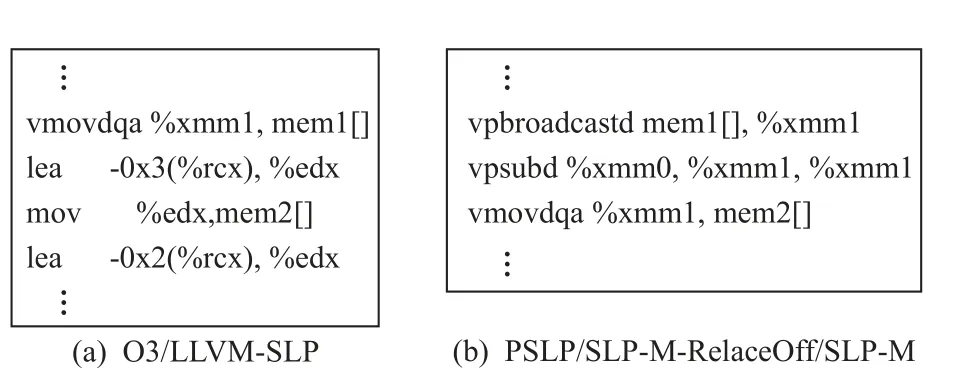
Fig.12 Assembly instructions generated by the code fragments of the function gl_render_vb圖12 函數(shù)gl_render_vb 代碼片斷生成的匯編指令
對于第2 類操作類型不同的程序,SLP-M 與LLVM-SLP,PSLP,SLP-M-RelaceOff 比較,對該類程序性能的提升幅度更大.對于函數(shù)start_pass_fdctmgr,其核心代碼片段如圖13(a)所示,LLVM-SLP,PSLP,SLP-M-RelaceOff,SLP-M 都對其實施了向量化.函數(shù)box_UVCoord多處包含如圖13(b)所示的代碼片段,編譯器在自動向量化前將其中的第1 個除法轉(zhuǎn)為乘法,使得2 條語句轉(zhuǎn)換為非同構(gòu)的形式.LLVM-SLP未對圖13(b)中程序?qū)嵤┝俗詣酉蛄炕琍SLP 和SLPM-RelaceOff 通過生成向量除法指令,對圖13(b)中的程序?qū)嵤┝俗詣酉蛄炕?SLP-M 方法將除法指令轉(zhuǎn)為乘法指令,并利用向量乘法指令對其實施向量化,與PSLP 比較,未生成延時較大的向量除法,由于乘法操作相比于除法操作在Intel 機器上實際執(zhí)行將近數(shù)倍,因此顯著提升了程序的性能,具體不同自動向量化生成的匯編代碼如圖14所示.函數(shù)ssim_end1 核心代碼以及優(yōu)化方法生成的匯編代碼如圖13(c)和圖14所示,LLVM-SLP,PSLP,SLP-M-RelaceOff,SLP-M 都未對其實施自動向量化,它們優(yōu)化后程序的性能差異不大.

Fig.13 Code fragments of the kernel function of different types of opcodes圖13 不同操作類型的核心函數(shù)代碼片段

Fig.14 Assembly instructions for the code fragments of the function box_UVCoord generated by various auto-vectorization methods圖14 多種自動向量化方法對于函數(shù)box_UVCoord 代碼片斷生成的匯編指令
對于第3 類操作數(shù)量及類型都不同的程序,這類程序需利用多種同構(gòu)化轉(zhuǎn)換方法并進行合理選擇,才能對其實施自動向量化,目前在被測試的優(yōu)化方法中只有SLP-M 顯著提升了該類程序的性能.如函數(shù)intra16x16_plane_pred_mbaff,其單層循環(huán)的核心代碼片段如圖15(a)所示,其中i是歸納變量,編譯器在自動向量化優(yōu)化前,對于不同的i值將代碼轉(zhuǎn)為不同的形式如i= 8,那么第1 行語句,(i-7)×ib會被轉(zhuǎn)換為ib,第4 行 語 句 的(i-4)×ib轉(zhuǎn) 為ib<<2.LLVM-SLP 未對原始程序?qū)嵤┳詣酉蛄炕琍SLP 將函數(shù)實施了同構(gòu)化轉(zhuǎn)換,但是需添加較多數(shù)量的重組指令,使得向量化無性能收益,因而未實施向量化.SLP-M 同時選擇運用了擴展變換和二元表達式替換變換,將函數(shù)轉(zhuǎn)為同構(gòu)的形式,有效實施了自動向量化,提升了性能,具體不同方法生成的匯編代碼如圖15(b)(c)(d)所示.

Fig.15 Code fragments of the function intra16x16_plane_pred_mbaff圖15 函數(shù)intra16x16_plane_pred_mbaff 代碼片段
函數(shù)intra16x16_plane_pred核心代碼片段如圖16所示,與函數(shù)intra16x16_plane_pred_mbaff類似,只有SLP-M 方法能夠?qū)ζ鋵嵤┳詣酉蛄炕?

Fig.16 Code fragments of the function intra16x16_plane_pred圖16 函數(shù)intra16x16_plane_pred 代碼片段
函數(shù)start_pass核心代碼片段如圖17 所示,盡管原始代碼是同構(gòu)的,但是編譯器在自動向量化前通過常量折疊優(yōu)化將語句1 中((b[0]×16 384)+1 024)>>11 轉(zhuǎn)為b[0]<<3,變換后的語句并不是同構(gòu)的,LLVMSLP,PSLP,SLP-M-RelaceOff 都未對其實施自動向量化,SLP-M 利用多種同構(gòu)化轉(zhuǎn)換方法,對左移和右移操作時通過添加shuffle 指令進行擴展,然后通過2步擴展變換將b[0]轉(zhuǎn)換為b[0]×1+0 的形式,進而將原始程序轉(zhuǎn)為同構(gòu)的形式,并實施了自動向量化,有效提升了程序的性能,具體匯編代碼如圖17 所示.

Fig.17 Assembly instructions for the code fragments of the function start_pass generated by various auto-vectorization methods圖17 多種自動向量化方法對于函數(shù)start_pass 代碼片斷生成的匯編指令
通過上述核心函數(shù)測試結(jié)果可以看出,對于第1類程序,除了u2s外,SLP-M 與目前業(yè)界測試最優(yōu)方法的向量化優(yōu)化能力持平,對于第2,3 類程序,SLPM 優(yōu)于其他方法.尤其對于第3 類程序,其他測試方法無法對該類程序進行有效向量化,而SLP-M 可顯著提升了該類程序的性能.從上述測試看出,對于操作個數(shù)或操作類型不同的程序,采用單一的同構(gòu)化轉(zhuǎn)換方法帶來的自動向量化性能收益并不總是最優(yōu)的,SLP-M 利用了多種同構(gòu)化轉(zhuǎn)換方法,并對其進行選擇,可有效提升這類程序的性能.
與4.1 節(jié)類似,本文也通過LLVM 自帶的性能評估模型評估了各種自動向量化方法對于實際應用核心函數(shù)的性能收益.具體結(jié)果如圖18 所示.總體而言,SLP-M 自動化向量化減少的指令代價多于LLVM-SLP和PSLP,這反映出SLP-M 具備較強的向量化優(yōu)化能力,能夠有效提升向量化的性能收益.
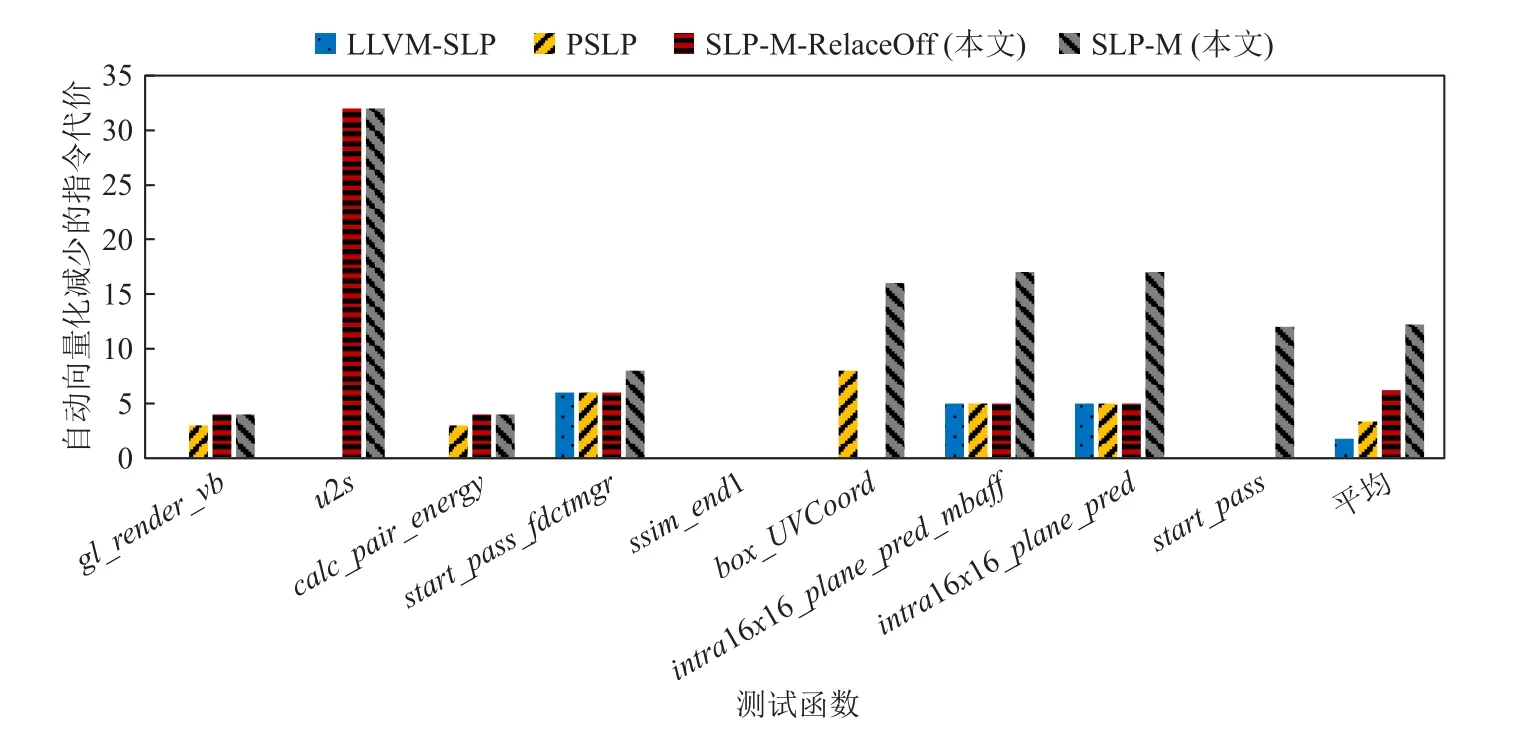
Fig.18 Reduced instruction costs of auto-vectorization methods on kernel functions圖18 核心函數(shù)自動向量化方法減少的指令代價
4.3 整體測試
本文利用SPEC CPU 2017/2006/2000 和MediaBench2基準測試集測試SLP-M 的整體加速比,排除了實驗的自動向量化方法都未有效觸發(fā)實施轉(zhuǎn)換的程序,執(zhí)行基準測試集12 次,分別剔除性能最優(yōu)以及最差的測試數(shù)據(jù),然后對剩余的測試數(shù)據(jù)取幾何平均值.整體加速比如圖19 所示,其中橫軸表示測試程序,縱軸表示不同方法在測試程序上相對于O3 的性能加速比.LLVM-SLP,PSLP,SLP-M-RelaceOff,SLP-M的平均加速比分別為1.06,1.07,1.09,1.11.SLP-M 方法對于整體性能的提升優(yōu)于實驗的其他自動向量化方法.
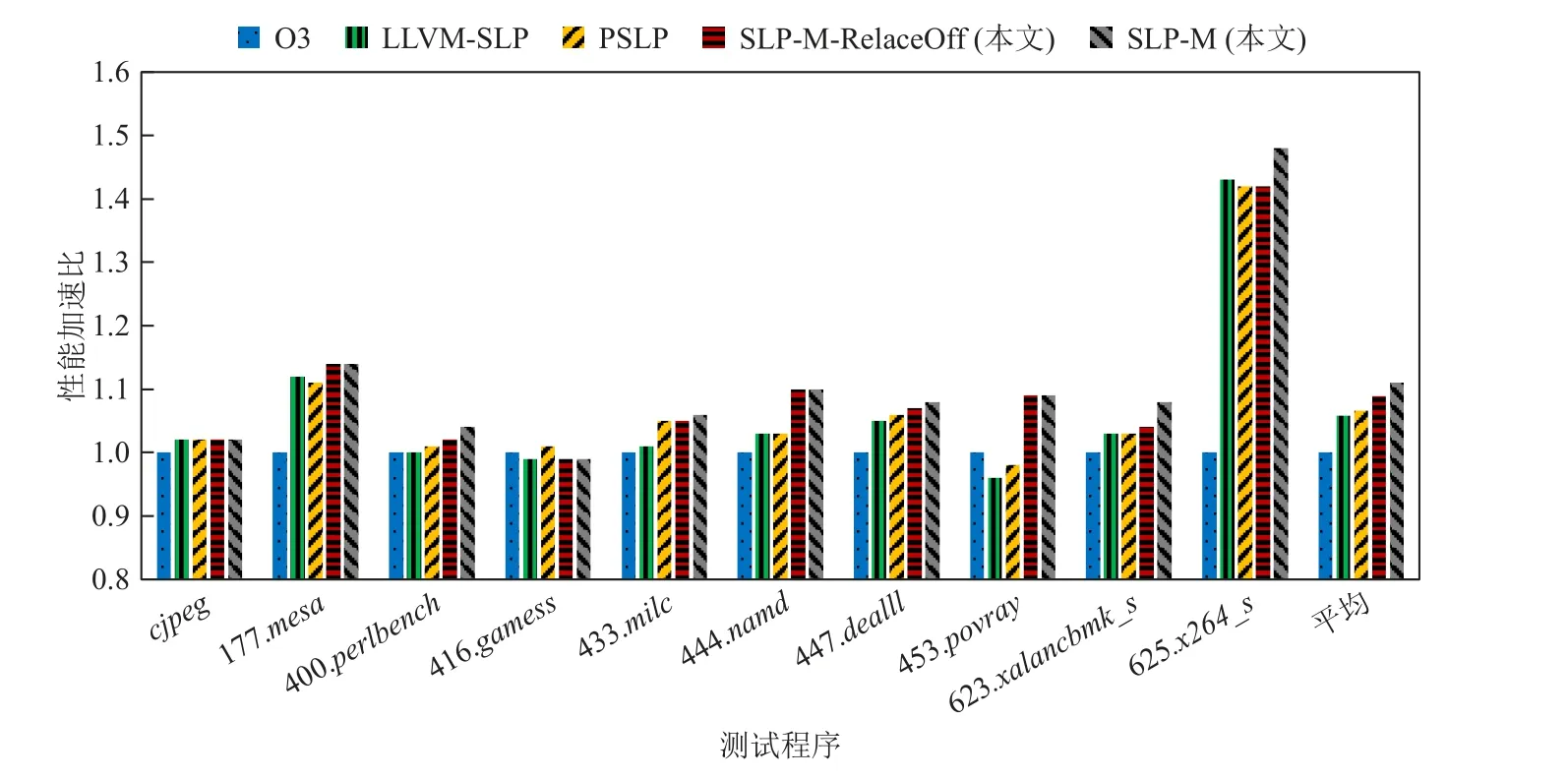
Fig.19 Speedup ratios of various auto-vectorization methods on whole benchmarks圖19 不同自動向量化方法在整體基準測試程序集上的加速比
SLP-M 相比于其他向量化方法對不同類型程序性能提升幅度不同,分別對3 類情況進行論述:1)SLP-M 與已有方法相比程序的性能進一步提升;2)SLP-M 與已有方法相比程序的性能下降;3)SLP-M與已有方法相比程序性能提升幅度趨同.
對于第1 種類型如453.povray,623.xalancbmk_s,625.x264_s測試程序,SLP-M 與已有方法比較進一步提升了程序的性能.由于SLP-M 應用了多種同構(gòu)化轉(zhuǎn)換方法并進行選擇,提升了同構(gòu)化轉(zhuǎn)換能力,進而增加了向量化的機會.453.povray,623.xalancbmk_s,625.x264_s包含較多加法、減法、乘法組合運算操作,SLP-M 對這些程序利用二元表達式等價替換及其他同構(gòu)化轉(zhuǎn)換方法對該類程序轉(zhuǎn)換同構(gòu)指令序列,并實施了自動向量化,有效提升了這些程序的性能.
對于第2 種類型如416.gamess,SLP-M 相比于PSLP 使得416.gamess性能下降.我們查看程序編譯后生成的匯編代碼,分析LLVM 的評估模型,發(fā)現(xiàn)程序性能下降并不是SLP-M 程序變換引起的,而是由于LLVM 的評估模型不準確造成的.LLVM 未充分考慮超標量處理器中標量指令級并行和訪存因素,對于本質(zhì)上無收益的程序變換,卻認為有收益,進而實施無效的程序變換,導致程序性能下降.
對 于第3 種 類 型 如cjpeg,433.milc,447.dealII測試程序,SLP-M 與PSLP 對于上述程序性能提升幅度趨同,這是由于利用這2 種方法后實施相同優(yōu)化轉(zhuǎn)換方式程序的占比較高,對于這些程序SLP-M 應用了與PSLP 類似的同構(gòu)化轉(zhuǎn)換方法(基于shuffle 指令的變換方式)進行向量化,如433.milc和447.dealII熱點區(qū)域,或都不對其向量化.
SLP-M 對整體的性能提升沒有像對核心函數(shù)那樣提升顯著,主要有3 方面的原因:1)SLP-M 能夠有效觸發(fā)的程序并不是都是應用程序的熱點區(qū)域;2)SLP-M 進行同構(gòu)化轉(zhuǎn)換方法的選擇屬于啟發(fā)式方法,對有些程序的同構(gòu)化方法的選擇并不是最優(yōu)的,這就使得程序優(yōu)化引入的性能提升是有限的;3)LLVM 的自動向量化代價模型準確性能有待提高,本文采用LLVM 自帶的自動向量化評估模型,發(fā)現(xiàn)有些程序經(jīng)過SLP-M 的同構(gòu)化分析評估是有收益的,可實施自動向量化,然而,實際上對于有些程序并未帶來性能提升,甚至使其性能略有下降.
SLP-M 與現(xiàn)有方法比較可有效提升程序的性能.由于SPEC CPU Benchmark 是編譯優(yōu)化領(lǐng)域標桿式的測試集,許多研究者針對該測試集進行研究及優(yōu)化[20],且SLP 本身是自動向量化領(lǐng)域重要的優(yōu)化方法,也可用于其他多個領(lǐng)域如二進制翻譯等,SLP-M 對于SPEC CPU Benchmark 的性能提升依然是難能可貴的.
5 總 結(jié)
基本的SLP 方法在處理非同構(gòu)指令序列時存在局限性.本文提出了一種SLP 擴展方法——SLP-M,它與現(xiàn)有方法相比,將多種方法應用于非同構(gòu)指令序列的同構(gòu)化轉(zhuǎn)換中,發(fā)揮了多種同構(gòu)化轉(zhuǎn)換方法的優(yōu)勢,進一步擴大了“同構(gòu)化轉(zhuǎn)換”處理的對象范圍,整體提升了自動向量化的性能收益.該方法并不局限于本文提到的幾種同構(gòu)化轉(zhuǎn)換方法,還可在此基礎上擴展應用更多的同構(gòu)化轉(zhuǎn)換方法,如三角函數(shù)等價變換、指數(shù)等價變換等.隨著更多方法的應用,有助于進一步發(fā)揮多種方法的優(yōu)勢,提升SLP 向量化的適用范圍和收益.
本文基于LLVM 編譯器實現(xiàn)了SLP-M 方法,并基于SPEC CPU 2017 等測試集進行了測試實驗.實驗表明,對于核心函數(shù)代碼片段,SLP-M 方法相對于LLVM-SLP 方法(包含LSLP 和SN-SLP 方法)的平均性能提升了40.4%,相對于PSLP 方法的平均性能提升了21.8%.對于整體性能測試,SLP-M 方法相對于LLVM-SLP 方法(包含LSLP 和SN-SLP 方法)的平均性能提升了5%,相對于PSLP 方法的平均性能提升了4.1%.
指令序列同構(gòu)化轉(zhuǎn)換方法的選擇直接影響SLPM 方法的適用范圍及性能收益,本文采用的單層指令對和整體指令的向量化收益結(jié)合性能評估和選擇方法有效提升了程序的性能收益,然而該方法屬于啟發(fā)式方法,實驗發(fā)現(xiàn)對于少數(shù)程序未帶來性能提升.下一步深入分析各種同構(gòu)化轉(zhuǎn)換方法的特點,從適用范圍、性能收益和程序特征等角度考慮,研究更好的選擇策略和方法如機器學習方法[32].
作者貢獻聲明:馮競舸提出了方法思路和實驗方案,完成實驗并撰寫論文;賀也平、陶秋銘、馬恒太提出指導性意見.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
人大建設(2019年12期)2019-05-21 02:55:44
測控技術(shù)(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環(huán)球時報(2017-03-30)2017-03-30 06:44:45
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛(wèi)生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
