一種車載控制器局域網絡入侵檢測算法及硬件加速
2023-12-15 04:47:34盧繼武李仁發
計算機研究與發展 2023年12期
許 鶴 吳 迪 盧繼武 李仁發
1 (湖南大學電氣與信息工程學院 長沙 410082)
2 (湖南大學信息科學與工程學院 長沙 410082)
3 (嵌入式與網絡計算湖南省重點實驗室(湖南大學)長沙 410082)(xuhe@hnu.edu.cn)
控制器局域網(controller area network, CAN)總線協議由于其低成本、高可靠性、實時性、抗干擾能力強的特點,已廣泛應用于工業自動化控制系統中[1].在汽車電子領域,CAN 總線協議已經成為實質上的通信標準.隨著汽車智能化的程度不斷提升,車載電子控制單元(electronic control unit,ECU)的數量也在不斷增加,車載系統的功能愈加復雜化[2].
任何產業在網絡化的發展過程中都會面臨信息安全問題,車聯網的發展也不例外[3].2017 年,Mccluskey[4]通過無線信號欺騙手段遠程入侵了Jeep Cherokee的車載娛樂系統,進一步向引擎、變速箱、轉向等控制系統發送惡意指令,致使車輛沖下路邊斜坡.2017年,騰訊科恩實驗室通過特斯拉Model S 車內網絡瀏覽器,讓用戶訪問一個可疑的網站,借此進入到車載網關,控制了Model S 的方向盤和剎車[5].在“2020 中國5G+工業互聯網大會”上,入侵者借助5G 無線技術連接上車載電腦,輕松打開一輛智能網聯汽車車門,并隨后啟動引擎.隨著智能網聯汽車的不斷涌現,惡意攻擊、非法控制、隱私泄露等威脅也日益增加.
自動駕駛輔助系統和新一代電子信息技術在汽車上的應用,使得汽車越來越智能化,可以很大程度保障行車安全,但與此同時,智能輔助功能一旦在某種狀況下突然失效或出現異常,將嚴重威脅行車安全.如圖1 所示,車聯網、移動網絡、GPS 導航以及智能傳感器等對外暴露的接口給車輛安全帶來了諸多不可預知的威脅[6].CAN 協議的安全機制主要是為了保證通信的可靠性,無法防止入侵攻擊或者檢測CAN 網絡是否受到入侵攻擊[7].攻擊者可以通過安全漏洞入侵CAN 網絡,挾持車載ECU,對車輛進行惡意攻擊以及非法控制.CAN 網絡一旦遭受入侵攻擊,一方面有可能造成車載網絡通信癱瘓、阻塞、數據被篡改,最終導致車輛行駛狀態異常,危及車輛與人員安全;另一方面,還可能涉及個人隱私數據泄露及相應的財產損失[8].安全事故往往發生在極短時間內,因此車載入侵檢測具有高實時性、高精度的要求.
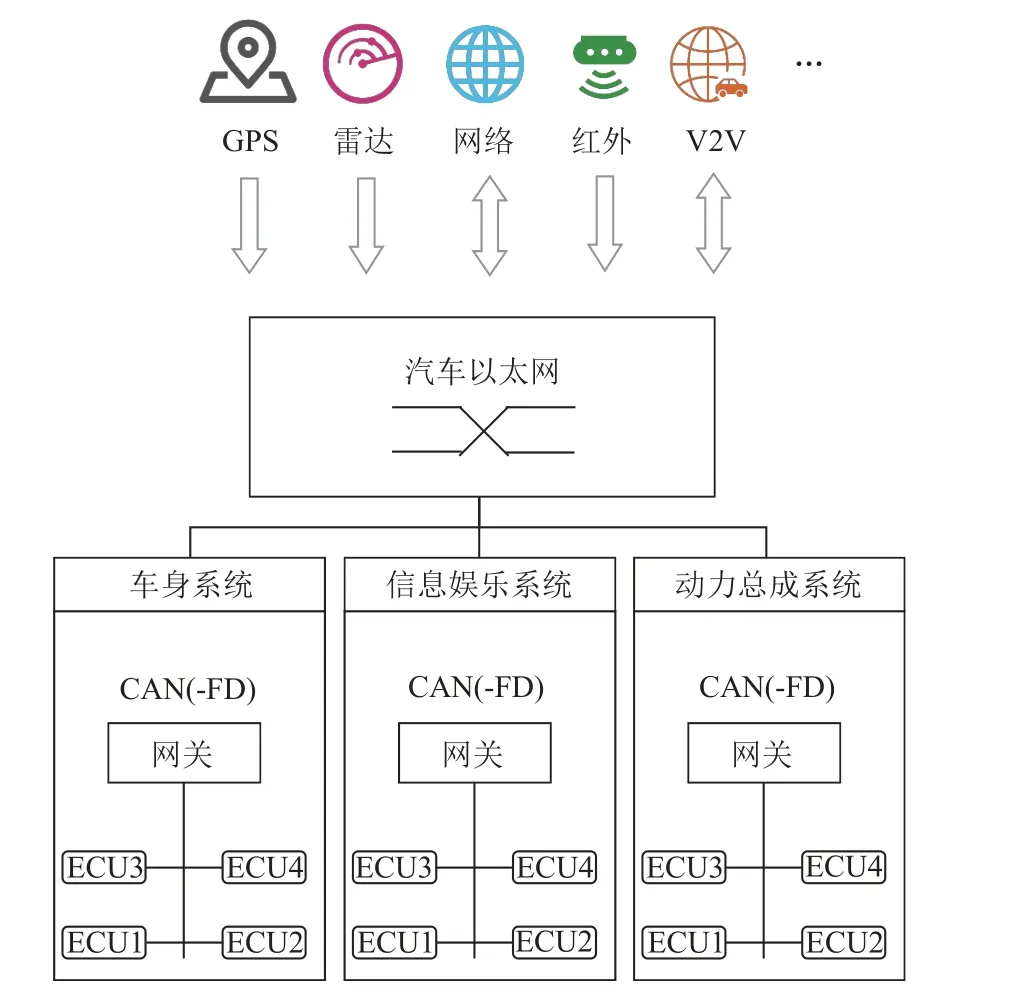
Fig.1 The architecture of vehicular communication network圖1 車載通信網絡架構
近些年來,基于深度學習的入侵檢測系統研究是諸多研究者關注的熱點,但是對于小批量特征攻擊的相關研究較少,并且大部分研究都以高性能的CPU 和GPU 為基礎,受限于車系統硬件性能的限制.深度學習模型在車載系統上部署,其實時性較差,因此研究基于深度學習的入侵檢測模型在實際車載環境下的加速部署方法具有很大的實際意義.本文提出了一種結合網格型長短時記憶(grid long short-term memory, Grid LSTM)[9]網絡與自注意力機制(selfattention mechanism, SAM)[10]的入侵檢測模型SALVID(SAM enhanced Grid LSTM for vehicular intrusion detection,),并基于現場可編程門陣列(field programmable gate array,FPGA)器件,實現了模型加速設計.該模型利用SAM 增強CAN 網絡攻擊數據的特征,進一步基于Grid LSTM 提取時序數據在不同維度上的相關性特征.同時,FPGA 器件具有硬件算法定制能力和并行處理的優勢,非常適合對實時性要求高的應用場景.研究的主要貢獻總結為3 點:
1) 通過分析常見攻擊類型的 CAN ID 分布特征,包括拒絕服務(denial of service, DoS)、模糊(fuzzy)、欺騙(spoofing)、重放(replay)和刪除(delete)等攻擊,設計了一種模擬攻擊系統,利用真實汽車采集的無攻擊數據集模擬生成多種攻擊類型的數據集.
2) 為了能夠分析大量的實時CAN 數據并優化模型的性能,本文采用多維度以及SAM 的思路,設計并實現了SALVID 模型.多維度的設計有利于在FPGA 上實現不同維度的并行化并提取更深層次的特征信息,SAM 的引入可以進一步增強攻擊數據的特征,使得Grid LSTM 網絡更容易區分不同類型的數據.多種基準對比模型的性能評估實驗表明,SALVID 具有最佳的性能表現.
3) 基于FPGA 嵌入式平臺設計并實現了堆疊型長短時記憶(stacked long short-term memory, Stacked LSTM)網絡、Grid LSTM、SALVID 這3 種模型,實驗表明SALVID 具有更高檢測精度以及低延時.傳統的矩陣乘法運算具有靜態特性,而自注意力機制網絡層內部矩陣具有動態生成的特性,如果遵循傳統設計思路,則需要等待內部矩陣完全計算完后才能進行矩陣乘法.為了提高SALVID 的數據吞吐量,本文設計了一種基于動態矩陣的矩陣乘法運算優化方法.實驗表明,該方法有效地提升了SALVID 的時延性能.
1 相關工作
CAN 總線安全防護手段一般可以分成2 種:一種是基于加密和認證的防護手段;另一種是基于入侵檢測的防護手段.基于加密和認證的防護手段主要是對幀數據和ECU 進行認證或者使用安全密鑰對消息進行加密處理,由于CAN 數據幀格式的有效載荷位數只有64 b,加密勢必會增加CAN 總線的網絡負載負擔,導致通信效率降低,而且加密手段升級需要對現有固件進行升級.基于入侵檢測的防護手段是通過分析數據幀的物理特征、統計學特征等建立一個檢測模型,這種方法的優勢在于不會增加CAN總線的通信負擔,并且不需要更新現有的固件程序.
由于通信效率和實時性的要求,基于入侵檢測的防護手段是車載安全研究的熱點,大部分研究可以歸納為基于規則判斷方法和基于機器學習方法.
1.1 基于規則判斷方法
在早期的研究中,基于規則判斷方法較為常見,通過設置一些邏輯判斷規則,對CAN 數據內部存在的邏輯關系進行決策,達到異常分類的目的.例如,Vuong 等人[11]設計了一種基于決策樹的攻擊檢測方法,該模型使用網絡和物理特征,在DoS、命令注入和2 種惡意軟件攻擊場景下進行了離線實驗評估.實驗表明,考慮物理特征顯著提高了檢測精度并減少了所有攻擊類型的檢測延遲,然而該方法具有大約1s 的高檢測延遲,無法滿足車載安全對實時性的需求.Cho 等人[12]將車載ECU 所特有的時鐘偏差作為指紋特征,提出了一種新型入侵檢測系統CIDS(clock-based intrusion detection system),CIDS 通 過 最小二乘算法,實現了0.055%的誤報率(false positive rate,FPR).然而,CIDS 只能檢測周期性消息的攻擊,并且攻擊者可以操縱幀數據繞過CIDS.
1.2 基于機器學習方法
基于機器學習的入侵檢測系統能夠處理具有多維復雜特征的數據,但同時也更加難以被訓練,并且對硬件性能要求也更高.一些研究人員嘗試使用CAN 總線的物理特征對車載ECU 的狀態進行分類,Zhou 等人[13]提出了一種基于CAN 總線數據比特位寬時間的新型入侵檢測系統BTMonitor(bit-time-based monitor),該方法提取了時域和頻域中9 個基本特征作為 ECU 的指紋特征,采用多層感知器 (multilayer perceptron, MLP) 訓練完成識別異常 ECU 的分類任務,并在實際汽車CAN 網絡上進行了測試,成功識別率為99.76%.然而,這種方法容易受到溫度和電磁環境的影響.Choi 等人[14]提出了一種基于CAN 總線電壓的入侵檢測系統,該方法通過檢查CAN 報文對應的電信號的特性,使用多類分類器來識別報文的發送方ECU.然而,與BTMonitor 一樣,車內的電磁環境和溫度會影響CAN 總線信號的電氣特性.Hanselmann等人[15]提出了一種稱為CANet 的新型無監督學習方法,該方法結合了LSTM 和自動編碼器,其穩定性優于其他基于物理特征的檢測方法.但是CANet 需要為每個CAN ID 對應的消息時間序列引入了一個獨立的LSTM 輸入模型,這會導致模型復雜且難以實際部署.Hossain 等人[16]提出了一種基于 LSTM 的入侵檢測算法,研究了不同超參數設置對性能的影響并選擇了最佳參數值,該方法基于真實車輛采集的CAN 數據模擬生成的3 個攻擊數據集,包括DoS、模糊、欺騙等攻擊,實現了高效的檢測準確率.然而,該方法并未考慮小批量注入攻擊類型.基于車輛原始設備制造商(OEM)提供的CAN 通信矩陣,Xie 等人[17]設計了特殊的CAN 消息塊,并利用生成對抗網絡(generative adversarial networks, GAN)檢測CAN 數據是否被篡改.然而,GAN 網絡無法識別具體的攻擊類型并且模型難以訓練.
從目前的研究現狀分析,大部分基于機器學習的入侵檢測算法優于其他方法,常見的模型算法包括MLP, LSTM, GAN 等.盡管如此,對于小批量特征類型的攻擊以及如何在嵌入式系統實現模型部署的相關研究工作還鮮有深入研究,其主要原因在于小批量特征攻擊的識別難度較大,并且機器學習算法對硬件性能要求較高.針對這2 個關鍵問題,提出了一種將SAM 與Grid LSTM 網絡相結合的入侵檢測算法,用于高效地識別車載CAN 總線是否受到攻擊,本文還進行了基于FPGA 嵌入式設備的入侵檢測模型加速設計與性能評估,為深度學習入侵檢測模型的實時在線部署提供一種新思路.
2 車載CAN 網絡攻擊類型
由于車載系統的特點,很難獲取到帶有攻擊特征的數據集,因此需要從攻擊類型本身的特征出發,設計模擬攻擊系統.基于真實車輛所采集的無攻擊數據樣本,利用模擬攻擊系統生成5 種類型的攻擊數據集,包括DoS、模糊、欺騙、重放以及刪除等攻擊,其中DoS、模糊和欺騙等攻擊具有泛洪特性,重放以及刪除等攻擊具有小批量特性.每種攻擊的具體特征有:
1) DoS 攻擊.攻擊者一旦入侵到CAN 總線網絡,會不斷向CAN 網絡發送優先級最高(CAN ID 為0)的CAN 數據幀,占用CAN 總線網絡數據傳輸時間窗口,導致其他正常ECU 無法發送數據.
2) 模糊攻擊.攻擊者可以在不清楚CAN 網絡中ECU 具體功能的情況下,向CAN 網絡注入隨機性數據.由于CAN ID 的隨機性和大量注入的特點,其會導致CAN 網絡通信紊亂.
3) 欺騙攻擊.在欺騙攻擊中,攻擊者通過監聽CAN 總線.記錄歷史消息,并重新大量注入到CAN網絡中,企圖欺騙車載系統接收過時消息更新數據,導致狀態出現錯誤.
4) 重放攻擊.重放攻擊具有小批量的特征,其識別難度相比上述攻擊要更大,攻擊者通過周期性注入某一個CAN ID 的CAN 消息,偽裝成正常的ECU實現重放攻擊.
5) 刪除攻擊.當攻擊者入侵CAN 網絡并挾持車載ECU 之后,往往會導致正常的ECU 喪失其原本的功能,在這種情況下,CAN 總線上特定的CAN 消息將不再出現,有可能導致車輛某些功能失效.
2.1 生成攻擊數據集
本文采用荷蘭4TU 聯盟ResearchData 開源的CAN 總線數據集[18],該數據集包含來自3 個系統的汽車CAN 總線數據:2 輛汽車(歐寶 Astra 和雷諾Clio)以及自行搭建的 CAN 總線原型.本文選取了歐寶Astra 的數據集作為實驗數據集,利用模擬攻擊方法生成了上述5 種攻擊類型的數據.
對于所有攻擊類型而言,都需要按順序從原始數據集中讀取每一個記錄,再提取采集時間戳和CAN ID,以數據集第1 行數據的時間戳作為起始時間,通過攻擊間隔時間確定每次發起攻擊的時間點,擇機發起攻擊.如圖2(a) 所示,對于DoS、模糊、欺騙、重放等攻擊而言,通過比較每一個CAN 消息的采集時間與攻擊時間,確定是否發起攻擊,并在數據集添加一列相應的標志值,發起攻擊時,注入對應的攻擊標志值,其中0, 1, 2, 3, 4 分別表示正常狀態、DoS 攻擊、模糊攻擊、欺騙攻擊以及重放攻擊的標志值.對于刪除攻擊而言,如圖2 (b)所示,通過判斷當前讀取的CAN ID 是否為攻擊目標,如果是,則刪除該CAN 消息,并標記下一個消息狀態為刪除攻擊標記值為5.
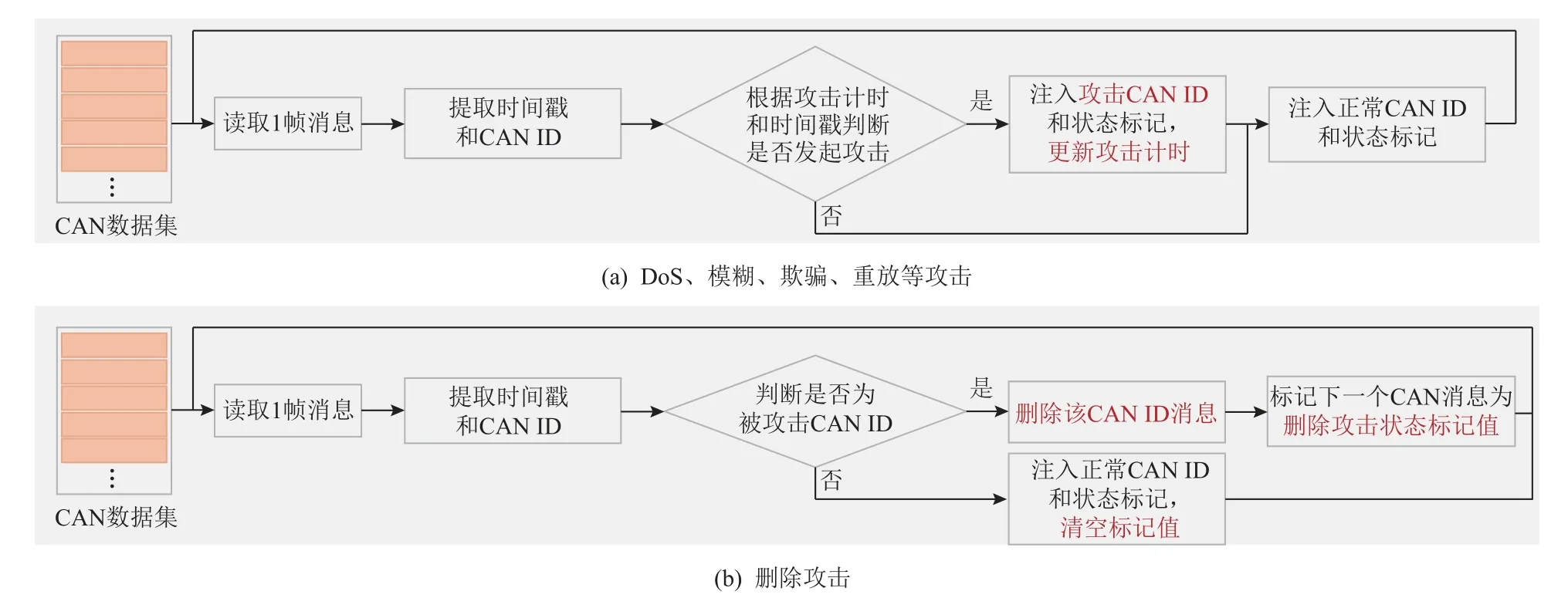
Fig.2 Generation methods of simulation attacks圖2 模擬攻擊生成方法
生成的數據集大小如表1 所示,其中正常狀態的CAN 消息占比最大,3 種泛洪特性的攻擊各自占比約10%,2 種小批量特性的攻擊各自占比約為2%.數據集按照8∶1∶1 的比例分別劃分為訓練、驗證、測試數據集.本文已將實驗所用的數據集開源.
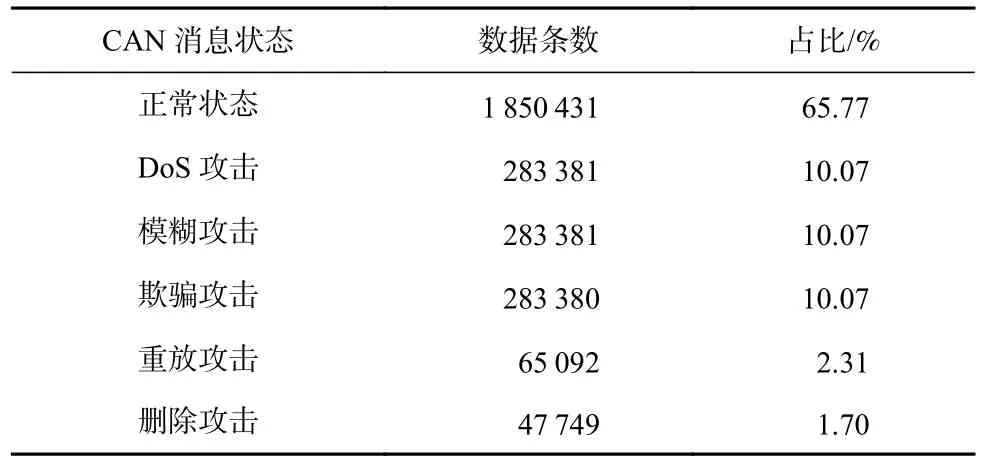
Table 1 The Size of Generated Datasets表1 生成的數據集大小
通過分析車載CAN 總線的攻擊類型特點,發現幾乎所有攻擊都需要注入或者截斷CAN 消息數據幀,這勢必會導致CAN 總線上數據幀特征分布發生變化.因此本文通過提取正常情況和攻擊狀態下的CAN ID 時序數據作為實驗模型的輸入數據.圖3 顯示了正常狀態與5 種攻擊狀態下CAN 消息中CAN ID 的分布特征.從圖3 中可以看出,DoS、模糊和欺騙等攻擊的特征數據與正常狀態數據具有比較明顯的區別,具有小批量特征的重放攻擊和刪除攻擊的特征并不顯著,與正常狀態下的分布特征類似,這意味著小批量特征攻擊更難被區分,更具有迷惑性.
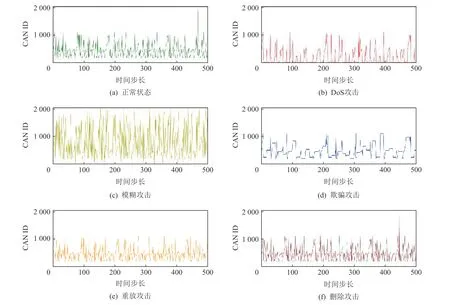
Fig.3 The distribution features of CAN ID in CAN messages of different statuses圖3 各狀態下CAN 消息中CAN ID 的分布特征
2.2 特征提取
如果直接將CAN ID 作為輸入特征,由于CAN ID 在CAN 協議中占有11 b,其十進制范圍在0~2 047.通常為了加快深度學習模型訓練收斂速度,模型訓練時會將輸入數據進行歸一化處理,這對浮點數計算沒有影響,但如果將歸一化后的數據作為FPGA 的輸入,由于需要進行定點數量化處理,會導致輸入特征的精度下降,因此需要針對FPGA 的特點對輸入數據進行特殊處理.
通過式(1)提取CAN ID 的11 b 特征作為輸入,一方面可以解決歸一化帶來的精度問題,另一方面,由于只有0 和1 這2 種輸入,在FPGA 中可以只用1 b進行運算,能夠降低資源開銷.CAN ID 的比特特征如圖4 所示.其中橫向坐標代表時間步長,縱向坐標代表11 b 特征信息.
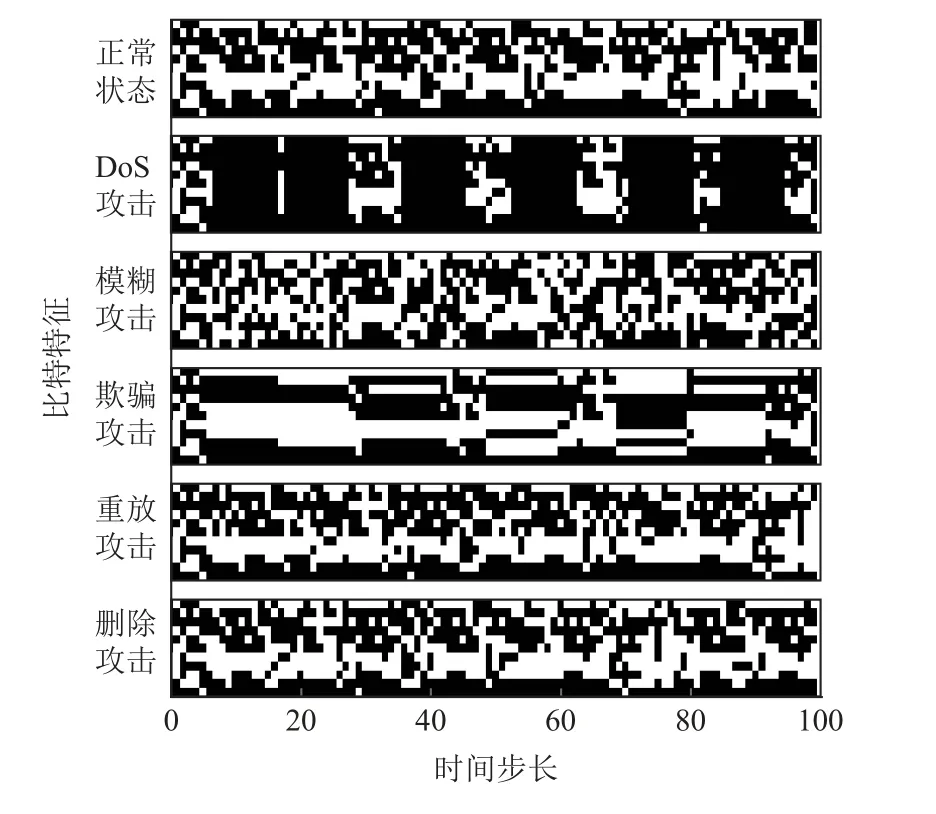
Fig.4 The bit distribution features of CAN ID圖4 CAN ID 的比特特征分布
3 車載CAN 網絡入侵檢測模型
本文結合自注意力機制與Grid LSTM 設計了SALVID 模型,其模型結構如圖5 所示.
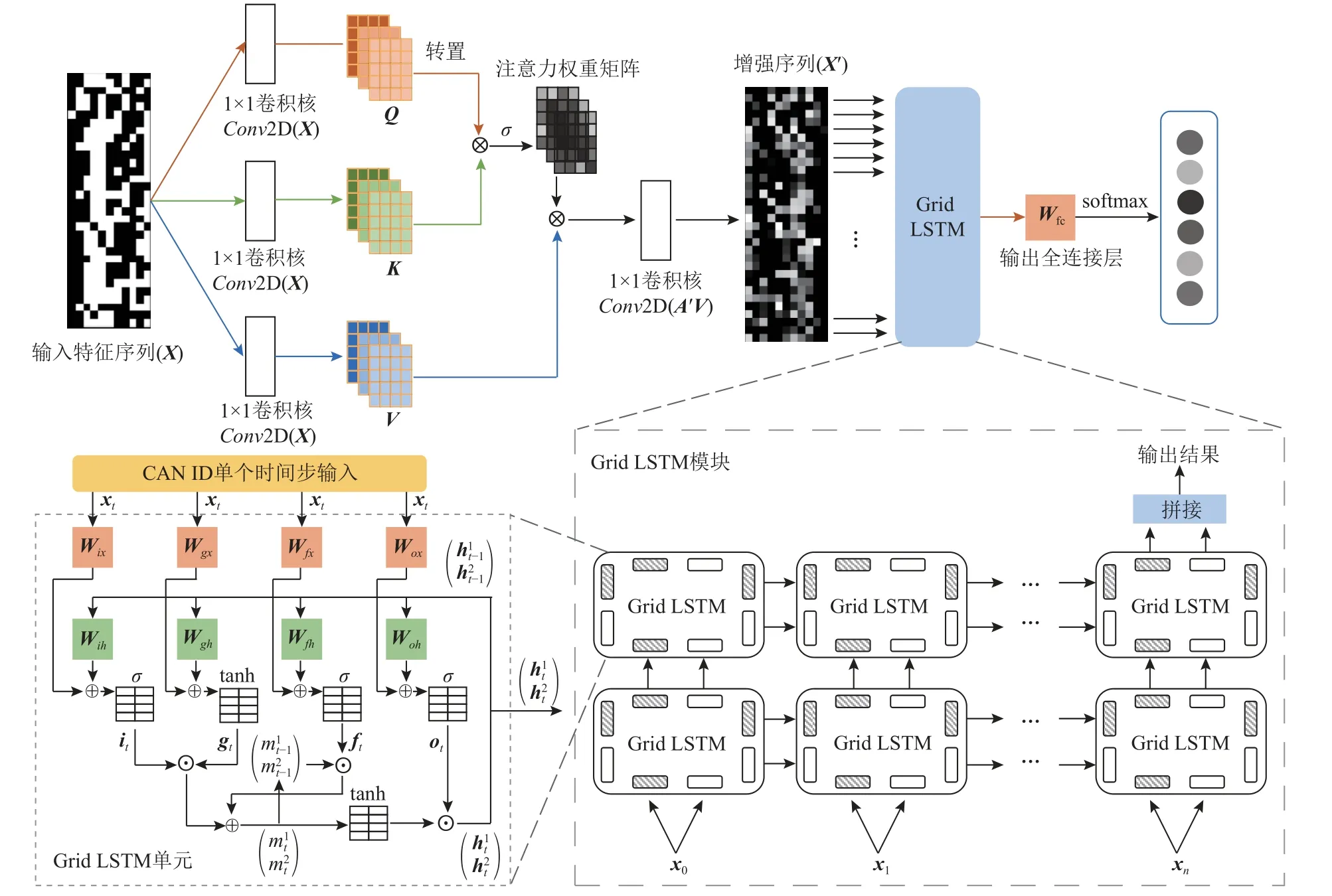
Fig.5 The architecture of SALVID model combining SAM and Grid LSTM圖5 結合SAM 與Grid LSTM 的SALVID 模型架構
3.1 自注意力機制層
自注意力機制是Transformer 模型的重要組成部分,其優勢在于減少了外部信息的時間依賴性,可以更快地捕獲數據特征的內部相關性[9].本文針對FPGA 的并行計算模式,對自注意力機制進行改進.自注意力機制的作用可以理解為通過分配不同的權重比例,對輸入數據進行預處理,典型的自注意力機制如圖6 所示,其內部矩陣Q,K,V是通過全連接網絡實現,其中Q為計算模塊,K為激活函數計算模塊,V為卷積層輸出模塊,所用到的激活函數為softmax函數,為了簡化自注意力機制的內部計算以及降低參數量,本文將全連接網絡使用卷積網絡代替.對于softmax 激活函數,其作用在于將輸出結果歸一化至0~1,并且總和為1,這個過程需要等待所有輸出結果值計算完成,不利于在FPGA 上實現.而sigmoid 函數
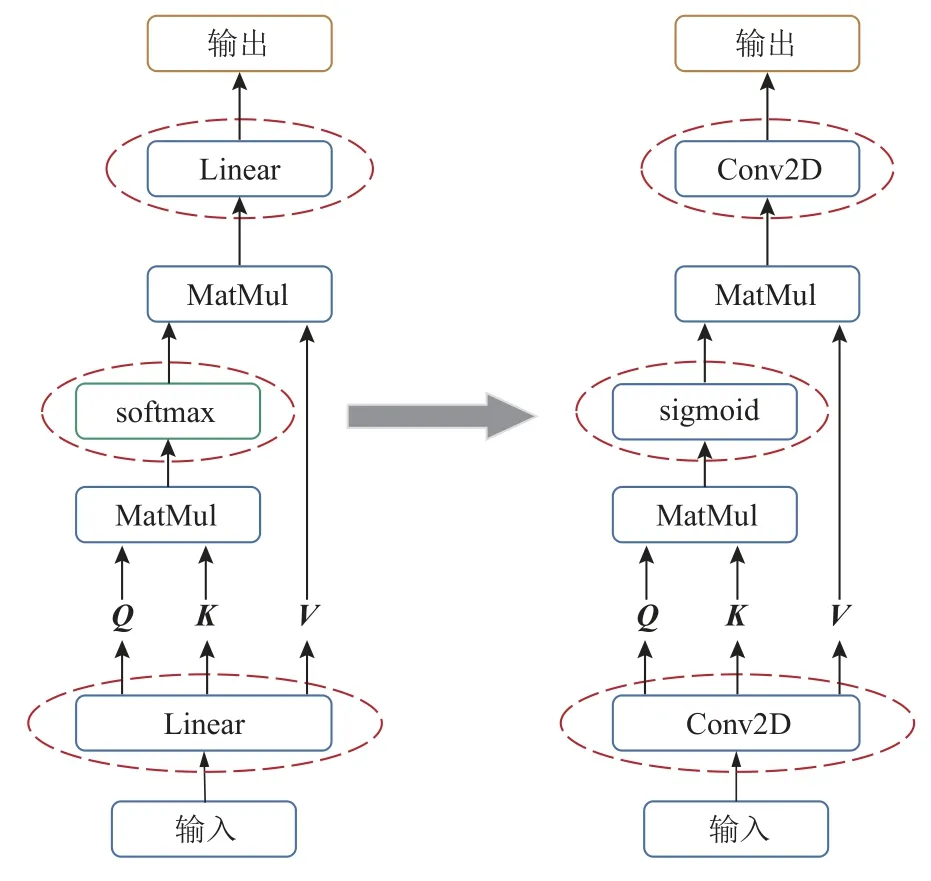
Fig.6 Improvement of network structure of SAM圖6 自注意力機制網絡結構的改進
的激活值范圍也在0~1,激活結果不依賴于外部信息,并且不會改變輸入數據之間的大小關系,同樣能夠作為注意力權重.其他常用的激活函數,例如ReLU函數與tanh 函數的激活值范圍不在0~1,過大的區間范圍需要更多的片上硬件資源用于保存激活值,因此我們采用sigmoid 函數替換softmax 函數.改進后的自注意力機制網絡[19]如圖6 所示.
首先,將輸入數據定義為:
其中X是n×m的矩陣,m為輸入的特征維度,n為一次輸入的總時間步長.
改進后的自注意力機制的定義如式(3)~(5)所示:
根據式(3)計算得到矩陣Q,K,V;其中(1,1)表示卷積核為1×1;F對應一個特征矩陣卷積層的輸出通道數,F*3 表示卷積層總的輸出通道數;Conv2D()表示2 維卷積函數,其輸出值平均切分為3 個部分,分別為Q,K,V;再根據式(4)計算得到自注意力機制網絡層權重矩陣, 將矩陣與V相乘,得到的結果作為式(5)的輸入,最終得到自注意力機制網絡層的輸出結果;D表示最終輸出的通道數,將其設置為1,即表示輸出值的大小與輸入數據的大小一致.
3.2 Grid LSTM 網絡層
LSTM 通過引入若干門控信號解決了RNN 梯度消失和爆炸的問題,被廣泛應用于文本識別、語音識別、時序數據處理、自然語言處理等領域[20].而Grid LSTM 能夠基于不同維度提取時序數據中更深層次的特征.本文采用的Grid LSTM 模型包括時間和深度2 個維度,不同維度的LSTM 內部權重參數可以相互獨立或共享[21].當不同維度之間的參數相互獨立時,時間維度與深度維度互不干擾,有利于緩解梯度消失問題并提取深層次的特征,并且每個維度在FPGA上可以并行執行,因此,本文在Grid LSTM 的不同維度上采用相互獨立的設計.
Grid LSTM 內部的基本計算單元可以拆分為2個LSTM 單元,LSTM 單元通過記憶單元的3 個門控信號,即輸入門、遺忘門和輸出門,避免了RNN 存在的梯度消失和梯度爆炸的問題,LSTM 單元的每一個時間步計算如式(6)所示:
其中 σ表示sigmoid 函數, ⊙表示按元素相乘,Wix,Wf x,Wgx,Wox為 輸入向量的權重矩陣,Wih,Wfh,Wgh,Woh為上一時刻隱藏層單元輸出向量的權重矩陣.將式(6)的LSTM 單元計算過程表示為lstm(), 如式(7)所示:
與LSTM 單元的計算所不同的是,本文所設計的Grid LSTM 單元具有深度維度與時間維度的2 個隱藏層單元輸入向量和2 個記憶單元向量,其計算可獨立拆分如式(8)所示:
對應于標準的LSTM 單元,Grid LSTM 單元具有2 個維度的獨立參數,本文將2 個不同維度的最后一步隱藏層輸出進行拼接,如式(9)所示,最終得到Grid LSTM 的輸入向量.
其中n表示一次輸入的總時間步長.
3.3 基于FPGA 的并行加速設計
為了在邊緣嵌入式設備上進行部署,基于FPGA架構,本文對所提出的SALVID 模型進行加速設計,利用高層次綜合(high-level synthesis, HLS)語言將模型算法綜合為硬件電路[22].
SALVID 模型的加速設計可分成2 部分,包括自注意力層與Grid LSTM 層.為了降低推斷時延和提高開發效率,本文基于模塊化設計與流水線設計思路,將自注意力層進一步分解為Q,K,V,將Grid LSTM層拆分為2 個維度,這2 個維度并行計算,單個維度的LSTM 計算單元模塊可以復用.基于模塊化設計思路,重新設計模型的數據流管道,每個計算模塊之間通過FIFO 隊列資源進行連接,可以實現整個計算過程的流水化.
3.3.1Q,K,V卷積模塊設計
自注意力機制網絡內部的矩陣Q,K,V卷積計算不具有時間上的相互依賴性,因此無論是在CPU,GPU 或者FPGA 都可以并行計算.但對于CPU 或者GPU 而言,需要完整計算出矩陣Q,K,V的所有值才能進行下一步計算,整個計算過程會處于阻塞狀態.相比之下,FPGA 具有并行流水線處理的優勢,由于卷積函數卷積核是訓練后的固定值,此過程可以很容易實現流水化設計,其計算過程如圖7 所示.
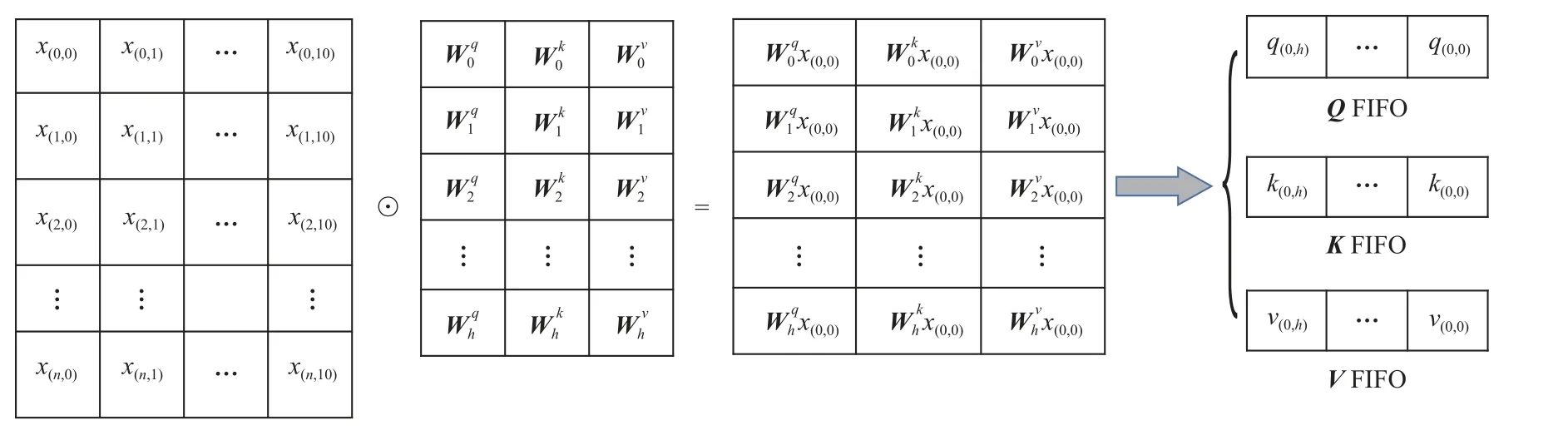
Fig.7 A single step calculation process of Q,K,V convolution modules圖7 Q,K,V 卷積模塊單步計算過程
將Q,K,V的內部計算獨立為一個模塊,其輸入流為一個CAN ID 的時序比特流數據,輸出流為Q,K,V的流數據.假設當前輸入為x(t,i),代表第t個時間步第i個維度的比特值,由于Q,K,V卷積函數卷積核已知,因此根據式(3)可以得到所有通道對應位置的輸出值,d表示輸出通道序號.Q,K,V的輸出流FIFO 隊列將會依次輸出所有通道計算后的值用于輸入到下一模塊的計算過程.在此過程中,矩陣Q,K,V被完全展開成1 維矩陣.
3.3.2 激活函數計算模塊
激活模塊的計算過程對應式(4),本質上整個計算過程是一個累加過程,如式(10)所示:
其中i,m∈{0,1,...,H-1},ai,m表示矩陣A中對應位置的元素,由于矩陣Q,K,V計算模塊輸出的矩陣Q,K是按照通道序號以數據流的形式串行傳輸,如果等接收到所有元素再開始計算A,將會導致很大的時延,因此,基于數據流傳輸的結構,本文設計了優化后的矩陣計算流程,當分別從Q,K隊列讀取q(i,j)和k(i,j)時,ki,j在KT中 為kj,i,可以將qi,jkj,i累 加到元 素ai,i中,同時,當前的qi,j和kj,i也需要和緩存的Q,K元素進行乘法計算,并累加到矩陣A對應位置的元素中,其計算過程如式(11)所示:
其中kj,z和qw,j分 別為緩存的矩陣Q,K元素,z∈{0,1,…,j-1},w∈{0,1,…,i-1}.這種計算方法本質上是將式(10)(11)中乘累加的過程進行拆分,使其適合于Q,K的數據流模式,本文將此方法稱為動態矩陣乘法計算.由于矩陣Q,K的值是動態產生的,因此只能在Q,K隊列全部數據讀取完成之后才能進行激活計算,否則無法得到一個完整的輸出值.
3.3.3 輸出卷積層模塊
計算得到激活值后,將激活值串行輸入到自注意力機制的卷積層輸出模塊,該模塊對應于式(5).由于此時V特征矩陣的值是完全已知的,這種情況的矩陣乘法運算比動態矩陣的計算要簡單.當輸入矩陣的 一行數據時,便可以計算出結果矩陣的一行數據,計算過程如圖8 所示.
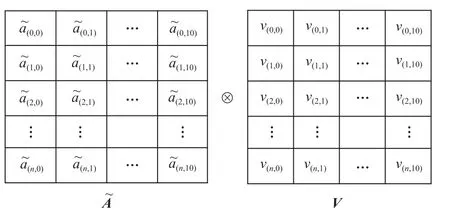
Fig.8 A single step calculation of output convolution module圖8 輸出卷積模塊單步計算
假設當前輸入為A?的 一個元素ai,j,將其與V的第j行元素vj相 乘,再按位累加到結果矩陣第i行元素ri,其計算過程如式(12)所示:
其中m∈{0,1,...,11n}, 11 表示CAN ID 的11 b,n為一次輸入的序列長度.
當計算得到A?V的所有輸出值后,去按行進行累加計算,再做卷積函數計算,如式(13)所示:
圖9 中,MVM 模塊表示LSTM 單元內的矩陣向量乘法.LSTM 單元的計算過程包括LSTM 內部的全連接網絡LSTM-MLP、激活(activation)函數和記憶單元和隱藏層單元狀態計算LSTM-Tail[23].LSTM-MLP用于并行處理內部矩陣向量乘法.LSTM-Tail 以流水線模式計算最終隱藏層單元和記憶單元的輸出值.
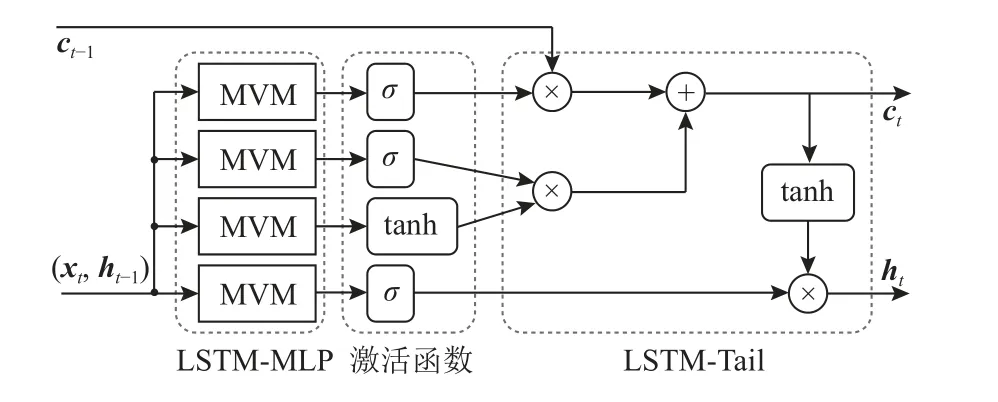
Fig.9 The internal computing architecture of LSTM cell圖9 LSTM cell 內部計算架構
其中j∈{0,1,...,11n},sad,j表 示 第d個輸 出通道的 第j個元素,Wd表示輸出卷積函數的第d個卷積核.為了保持自注意力層的輸入輸出維度一致,將輸出卷積函數的輸出通道設置為1.
3.3.4 LSTM 計算單元模塊
LSTM 計算單元的設計遵循與自注意力機制網絡設計相同的設計原理,采用FIFO 隊列以及數據流的設計思想,對輸入值、中間結果以及輸出值進行串行傳輸以實現整個計算過程流水化.首先對LSTM 單元單個時間步的計算過程進行分析,由于LSTM 內部的全連接層權重矩陣與偏置向量完全已知,因此其優化方法與自注意力機制網絡的輸出層乘累加計算過程的優化方法相同,為了最大化降低時延,不需要等待矩陣乘法完全計算結束得到完整的輸出結果,可以在計算得到一行輸出之后,便開始下一步激活函數的計算以及其他模塊的計算.LSTM 網絡單個時間步的計算過程如圖9 所示.
4 實驗與結果
4.1 實驗設計與評估標準
本節描述實驗的相關硬件與軟件環境以及模型評估標準.實驗的軟件環境為PyCharm 2 021.2.1 專業版以及Xilinx Vivado 2 019.2 集成開發環境(包括Vivado 和HLS),數據特征提取實驗所采用的是Python 3.7,通過提取原始數據集中的CAN ID 字段,注入攻擊數據之后,保存為二進制文件,以提高訓練時內存I/O 讀取速度.基于PyTorch 1.9.0 構建了各類深度學習實驗模型,包括本文提出的SALVID 模型,采用Scikit-learn 0.24.1 機器學習庫用于構建SVM 對比模型,模型加速實驗均基于Vivado HLS 高層次綜合設計.所有PC 端實驗都在同一臺安裝了Windows 10 系統的臺式電腦進行,該電腦CPU 配置為Intel i9-10850K CPU @ 3.6GHz × 10,配有8 GB 顯存的NVIDIA Quadro RTX 4 000 GPU.加速模型部署測試基于Ultra96-v2 開發板,配置有2 GB LPDDR4 的內存和UltraScale+ MPSoC 架構的FPGA 芯片.
為了衡量模型的檢測性能,本文從3 個方面對所提出的SALVID 模型進行評估:
1) 不同模型深度條件下的整體檢測準確率(accuracy,ACC)比較.
2) 7 種不同模型之間的性能比較,如ACC、漏報率(false negative rate,FNR)、FPR.
其中TP,FP,TN,FN分別代表被正確分類的正例、被錯誤分類的正例、被正確分類的負例以及被錯誤分類的負例.
3) 基于FPGA 平臺的3 種不同加速模型的平均推斷時延以及整體檢測準確率比較.
4.2 不同模型深度之間的性能評估
在本節中,根據模擬攻擊方法生成的攻擊數據集以及原始的正常數據集,在不同的模型深度條件下,對3 種基于LSTM 的模型進行性能評估,包括Stacked LSTM、Grid LSTM 和所提出的SALVID.模型深度范圍為10~30,步長為2.為了避免Dropout 層對模型精度造成的影響,本文在每一種模型深度條件下進行了20 次訓練實驗,在測試數據集上測試得到ACC后取平均值.實驗結果如圖10 所示.
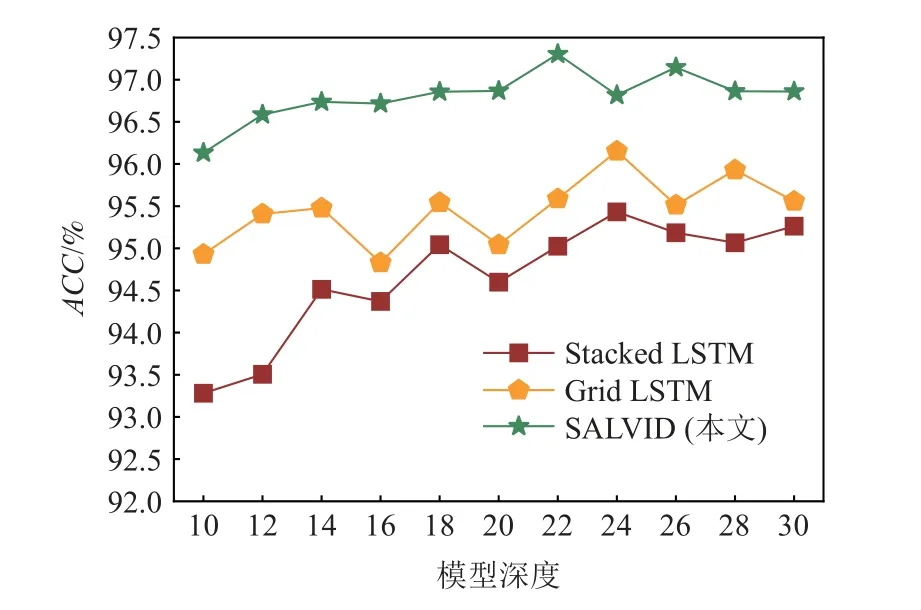
Fig.10 The performance between different model depths圖10 不同模型深度之間的性能
從圖10 可以看出,當模型深度不斷增加時,3 種模型的ACC都有上升的趨勢,在模型深度達到一定值之后,模型的ACC很難繼續提升,SALVID, Grid LSTM, Stacked LSTM 模型分別在模型深度為22, 24,24 時達到最高的ACC,并且SALVID 模型具有最佳的性能表現.實驗表明,多維度的特性以及自注意力機制能夠有效提升模型的檢測性能,特別是在網絡模型深度很小的情況下,SALVID 依舊具有很高的檢測性能.
為了評估模型的訓練穩定性,本文選取了模型深度為16~24 的ACC進行比較.如圖11 所示, SALVID的ACC波動范圍在2%~4%,而Stacked LSTM 的ACC波動范圍在2.4%~6%,Grid LSTM 的ACC波動范圍在2.4%~5%.相 比 于SALVID,Stacked LSTM 和Grid LSTM 模型的ACC波動范圍較大.在模型深度較大時,SALVID 模型的穩定性表現更佳.實驗結果表明,SALVID 具有最佳的訓練穩定性表現,這表明自注意力機制有助于降低模型檢測性能對模型參數的敏感度,能夠提高SALVID 模型的訓練穩定性.
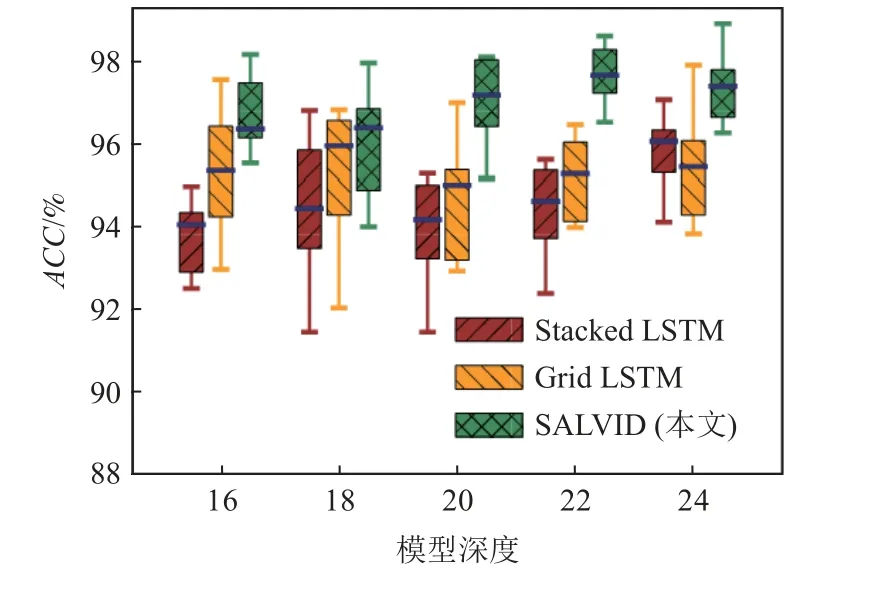
Fig.11 The training stability between different models圖11 不同模型之間的訓練穩定性
為了進一步研究Stacked LSTM, Grid LSTM,SALVID 在檢測性能上的差異,本文選取了3 種模型中具有最佳性能表現模型所對應的模型深度作為比較基礎,通過其分類混淆矩陣進行分析對比,如圖12所示,3 種模型對具有泛洪特性的攻擊都有較好的檢測識別性能,主要原因在于其泛洪特征較為明顯,易于識別.SALVID 對正常狀態的識別率最佳,這能夠有效地降低正常狀態下的FPR.3 種模型的主要差異體現在小批量特性的攻擊類型檢測識別效果上,對于重放攻擊來說,這3 種模型都存在將攻擊識別為正常狀態的誤識別情況,然而,SALVID 的錯誤識別次數僅為233,大約是Grid LSTM 的1/2 和Stacked LSTM 的1/3.這種差異表明多維度特性與自注意力機制有利于捕獲更深層的攻擊特征.

Fig.12 The classification confusion matrix of the three models圖12 3 種模型的分類混淆矩陣
4.3 基準對比模型與超參數設置
將SALVID 與其他基線對比模型的異常檢測性能進行比較,評估指標包括ACC,FNR,FPR.
本文采用交叉熵損失(crossentropy loss)函數作為所有深度學習模型的損失函數,其中p為期望輸出,q為實際輸出.實驗過程中,最大的訓練輪數為100,學習率為1E-3,優化器類型為自適應矩估計優化器adam,一個批次訓練的大小為128,輸出層激活函數采用softmax 函數,并且,當驗證集上的損失值不再連續下降的次數超過所設定的中斷閾值時,訓練過程提前中斷,本文設置中斷閾值為5.具體超參數設置如表2 所示.
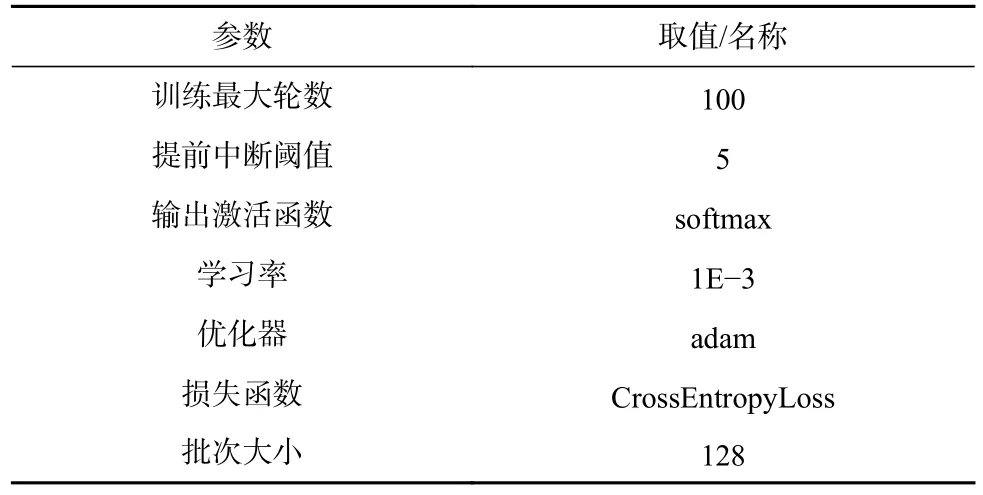
Table 2 Hyperparameter Configuration表2 超參數設置
本文模型包括支持向量機(support vector machines,SVM)、 MLP、 卷 積 神 經 網 絡(convolutional neural network, CNN )、 Stacked LSTM、 Grid LSTM 以 及SALVID 模型.
多種模型的性能對比結果如表3 所示.通過實驗結果分析,基于LSTM 的模型性能表現明顯優于其他非循環神經網絡模型SVM, MLP, CNN,其主要原因在于小批量注入攻擊與正常狀態的特征分布圖很類似,非循環神經網絡不具有捕獲上下文時序相關性的能力,難以區分此類的差異.此外,Stacked LSTM 與Grid LSTM 的實驗結果表明,多維度特性加強了LSTM 對具有復雜特征數據的分類能力.對比SALVID 與Grid LSTM 的實驗結果可以發現,自注意力機制有效地增強了原數據的攻擊特征,提升了SALVID 模型的檢測分類性能.
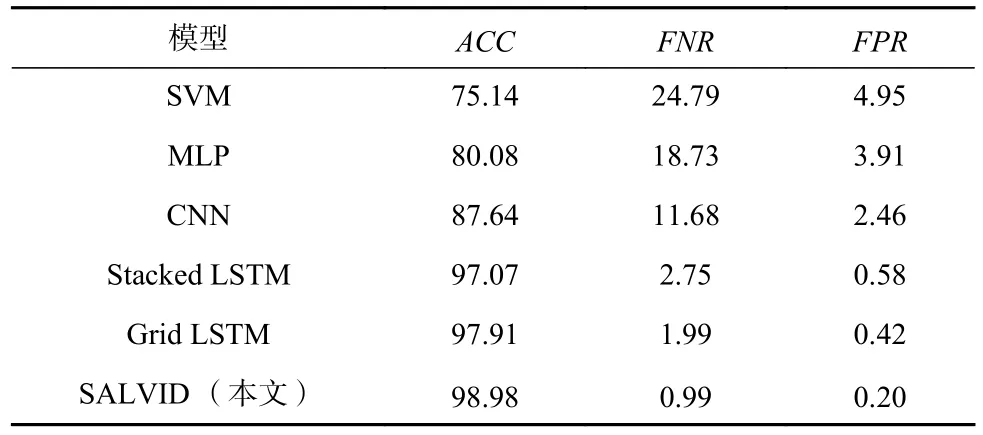
Table 3 The Performance Between Different Models表3 不同模型之間的性能 %
4.4 FPGA 加速模型的參數選擇與效能評估
本節基于FPGA 嵌入式平臺,采用獨立模塊化設計方式實現了自注意力機制網絡層和LSTM cell 基本運算單元,通過將LSTM cell 計算單元在時間維度上進行堆疊得到Stacked LSTM 模型;然后將Stacked LSTM 拼接組合得到具有深度和時間維度的Grid LSTM 模型;最后將自注意力機制網絡層作為前置部分與Grid LSTM 網絡層進行串聯,得到SALVID 模型.基于PC 端訓練得到的模型參數,本文選取了3種表現最佳模型所對應的模型深度列表進行比較,如表4 所示.

Table 4 Model Depth Selection and Their Accuracy表4 模型深度選擇及其準確率
本節將會從參數量化分析、資源消耗以及性能表現3 個方面對基于FPGA 的加速模型設計進行評估.
4.4.1 參數量化分析
為了加速模型推斷,本文利用定點數量化的方式對模型的參數進行壓縮[24].對訓練好的模型參數范圍進行分析,模型參數包括卷積函數的卷積核、LSTM 內部的全連接層以及輸出層的權重矩陣與偏置向量,其分布特征如圖13 所示.
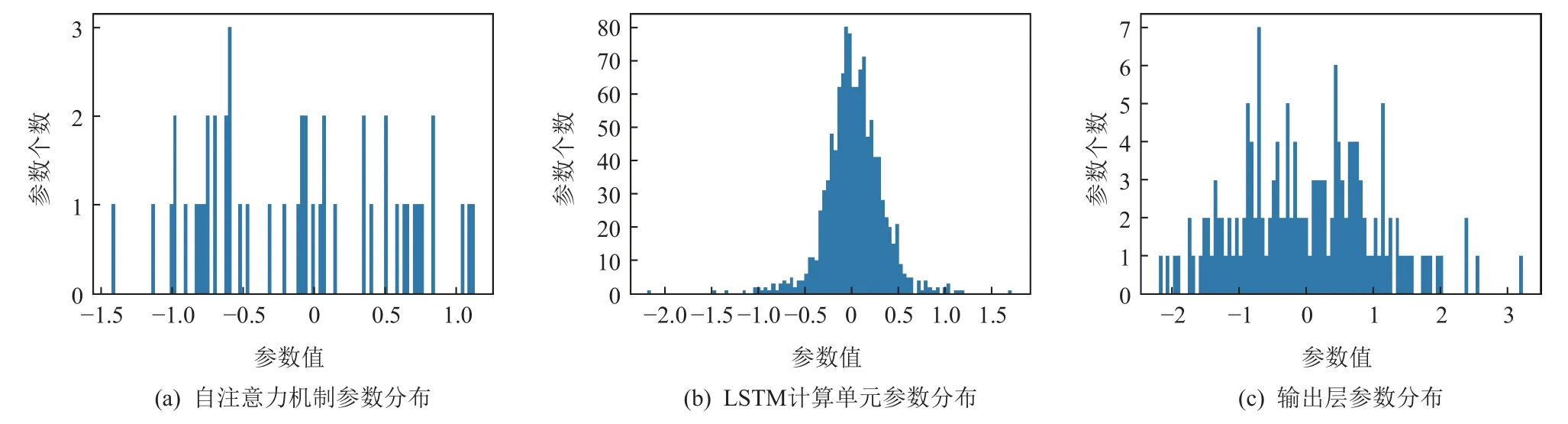
Fig.13 Histogram of parameter distribution for each network layer圖13 各網絡層參數分布直方圖
可以看到自注意力機制參數范圍大致在-2~2,LSTM 內部的參數范圍大致在-2~2,輸出層的參數范圍大致在-3~3,因此,針對模型參數的定點數量化整數部分,定義其為4 b 位寬,16 b 總位寬,同時,模型計算過程中有累加操作,為了避免溢出,對中間計算值采用32 b 總位寬和16 b 整數位進行量化,激活函數則采用16 b 總位寬和8 b 整數位進行量化.由于輸入值只有0 和1 這2 種情況,故用1 b 無符號整數保存,輸出值以8 b 無符號整數存儲,便于在處理系統(PS)和FPGA 器件上的可編程邏輯(PL)中傳輸.FPGA設計中具體參數位寬的定義如表5 所示.

Table 5 The Bit Width Definition of Model Parameter Quantization表5 模型參數量化位寬定義
其中,在FPGA 設計中,未實現輸出層的softmax歸一化函數,這對輸出值的大小順序并不會產生影響,但卻能夠有效減少資源開銷以及降低推斷時延.
4.4.2 基于動態矩陣的矩陣乘法優化設計
在FPGA 設計中,傳統的矩陣乘法通常是已知權重矩陣,計算輸入矩陣與權重矩陣的矩陣乘法結果,而在自注意力機制網絡層中內部矩陣的生成具有動態特性,傳統設計思路會阻塞計算過程,需要等待內部矩陣計算完成,無法與其他計算過程實現流水線優化,因此針對該計算過程,本文設計了一種基于動態矩陣的矩陣乘法運算優化方法,并與傳統設計思路在FPGA 器件上進行板載測試對比.如表6 所示,優化后的設計方法相比傳統的設計方法,在具有相同準確度的基礎上,降低了0.1 ms 的推斷時延.

Table 6 The Performance of Different Design Methods表6 不同設計方法的性能 ms
4.4.3 FPGA 硬件資源消耗
有效利用資源對于嵌入式系統至關重要.基于FPGA 的加速器因其高性能和高能效而被應用于從嵌入式系統到云計算的各種系統[25].本文對加速模型硬件資源利用進行分析.從圖14 可以看出,SALVID由于內部結構復雜,占用的硬件資源最多.Grid LSTM 模型中的基本計算單元具有2 個維度,包括深度和時間,因此,在相同模型深度條件下,Grid LSTM的資源開銷要多于Stacked LSTM.
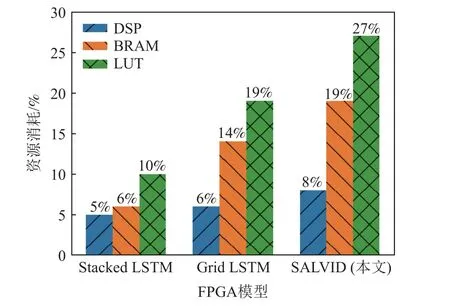
Fig.14 Comparison of resource cost in FPGA model design圖14 FPGA 模型設計的資源消耗比較
4.4.4 準確率與推斷時延性能表現
基于Ultra96-v2 嵌入式FPGA 設備,本文進行了模型板載測試實驗,并對Stacked LSTM, Grid LSTM,SALVID 進行了性能評估.板載測試實驗數據包括從測試數據集中隨機抽取的1 600 個類型均勻分布的樣本,實驗結果如圖15 所示.
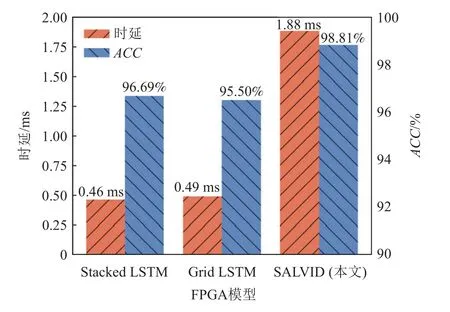
Fig.15 Performance comparison of model tested on FPGA board圖15 模型在FPGA 板上測試的性能比較
從圖15 可以看到,參數量化對Stacked LSTM 與SALVID 模型的ACC影響不大,但對Grid LSTM 的影響比較明顯.其主要原因在于Grid LSTM 有2 個維度,2 個維度的計算互相對立,這種結構有利于在FPGA上進行并行設計,然而多維特性也導致模型對參數的敏感性增強.由于增加了自注意力層,SALVID 的時 延 大于Grid LSTM, 但SALVID 的ACC比Grid LSTM 高約2%.并且自注意力層也有助于降低模型對參數的敏感性.并且實驗中測試數據的總步長為32,對應CAN 網絡大約30 ms 的采集時間.因此,3 種模型的時延遠小于CAN 數據的生成時間.
5 結 論
本文提出了一種結合自注意力機制與Grid LSTM 的車載CAN 總線網絡入侵檢測系統,利用自注意力機制增強原數據時序相關性,再通過多維度的Grid LSTM 模型提取深層次的特征,取得了較好的檢測效果.
通過將本文所提出的SALVID 與深度算法MLP,CNN,Stacked LSTM,Grid LSTM 以及傳統的機器學習算法SVM 進行實驗對比,從整體的檢測效果與不同類別樣本的檢測效果方面進行對比,實驗結果表明SALVID 模型有效地提高了檢測準確率(98.98%)以及降低了誤報率(0.20%).進一步地,本文提供了基于FPGA 平臺的模型設計方案,并在FPGA 嵌入式設備上進行加速模型板載測試,實驗結果表明,參數量化對模型的準確率影響較小,并且對模型的推斷時延影響很小,這為基于深度學習模型的入侵檢測系統的實際部署提供了一種針對FPGA 嵌入式設備的實踐方案.
作者貢獻聲明:許鶴負責完成實驗設計、調研和論文主要內容的撰寫;吳迪、盧繼武參與了討論并提出了修改意見和實驗思路;李仁發對論文結構和內容提出指導意見.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
