基于分離對比學習的個性化語音合成
2023-11-27 05:35:10吳克偉
計算機工程與應用 2023年22期
尚 影,韓 超,吳克偉
1.阜陽幼兒師范高等專科學校 小學教育學院,安徽 阜陽236015
2.合肥工業大學 計算機與信息學院,合肥230601
個性化語音合成是指根據目標說話人的參考語音,合成具有目標說話人風格的語音。該任務廣泛應用于增強現實、虛擬現實、游戲開發和視頻編輯等領域。
在個性化語音合成任務中,模型需要學習不同的說話人風格,即從參考語音中提取說話人語速、口音、情感等方面的特征。為了提取目標說話人的風格特征,Wang 等人[1]使用循環神經網絡從參考語音序列中提取風格特征“Style Tokens”,該模型使用線性層估計不同Token 的注意力,并組合多個Token 來學習目標說話人的風格特征。Jia 等人[2]使用長短時記憶網絡來學習參考語音中的說話人特征,并嵌入到自回歸語音編碼解碼器中實現語音合成。Paul等人[3]將說話人特征嵌入到時間條件概率模型中,用于逐幀的語音合成。Choi等人[4]從語音幀和整個參考語音序列兩方面,來描述說話人之間的差異。Chen 等人[5]從說話人身份編號中提取線性層參數,用于說話人身份特征的調整。為了避免目標說話人風格特征變化過大,Min 等人[6]使用線性層來估計參考語音中的風格特征之間的關系,并促進相同目標說話人語音的風格特征一致。Huang等人[7]對目標說話人的樣本進行多次采樣構建子數據集合,并使用多個子數據集合來避免說話人風格特征學習的過擬合。上述方法沒有對比不同說話人之間的風格特征,容易忽略風格特征之間的差異,從而造成目標說話人風格特征學習不準確。
個性化語音合成依賴于參考語音的分割特征分解。參考語音同時依賴于目標說話人風格和語音中的文本內容。對比聲學語言模型(contrastive acoustic-linguistic module,CALM)[8]將參考語音作為一個整體進行對比分析,但是在說話人風格和語言內容兩方面沒有進行分離對比分析,導致了合成語音受到語言內容的干擾,而偏離目標說話人風格的問題。因此,對參考語音中的風格特征和內容特征進行分離學習,仍然是個性化語音合成的重要任務。
本文關注于風格-內容分離的對比學習,用于從參考語音中提取可分離的風格和內容特征。本文設計了一種基于分離對比學習的個性化語音合成模型。該模型包括風格-內容分離對比模塊、說話人模塊、語音解碼器模塊。風格-內容分離對比模塊引入分離負例,該分離負例能夠促使查詢的風格和其他參考語音中的內容分離,同時能夠促使查詢的內容與其他參考語音中的風格分離。風格內容分離模塊用于學習兼顧風格-內容的語音特征。說話人模塊學習說話人身份特征,并用于引導說話人風格學習。語音解碼器模塊融合風格-內容的語音特征和說話人身份特征,來提高對持續時間、音高、能量這些說話人風格的描述能力。
本文主要貢獻如下:
(1)設計了一種風格與內容分離的對比損失,該分離損失能夠促使查詢的風格和其他參考語音中的內容分離,同時能夠促使查詢的內容與其他參考語音中的風格分離。
(2)將分離學習的風格-內容特征與說話人身份特征融合,來預測說話人風格中的持續時間、音高、能量,從而實現全面的風格特征描述和個性化語音合成。
(3)在VCTK 和LibriTTS 兩個數據集上的實驗表明,本文方法合成語音的質量優于現有方法。
1 相關工作
1.1 個性化語音合成
語音合成模型通常使用大型說話人數據集來學習風格特征,然后使用小樣本的數據,來微調目標說話人的風格。Moss 等人[9]使用貝葉斯優化器來微調說話人風格。風格特征可以從參考語音中提取說話人身份特征[10-11]。此外,一些方法從語音樣本中提取風格特征。Nachmani等人[12]使用說話人編碼器,從語音樣本中捕獲說話人特征。Zhou等人[13]使用局部幀級的語音特征,描述細粒度的說話人特征。So-vits-svc(SoftVC VITS singing voice conversion)方法[14]使用了持續時間長度預測器和第0幀的語音預測器,并使用了條件變分自動編碼器和生成對抗網絡策略,提高語音合成質量。然而,So-vits-svc 沒有對說話人身份特征和說話人風格特征進行建模。如果沒有考慮說話人身份特征和風格特征,在語音合成中容易受到不同身份和不同風格特征的干擾,限制了語音合成質量。為了解決上述問題,本文設計了說話人模塊,用于提取說話人的身份信息。此外,本文設計了風格-內容分離對比模塊,用于描述說話人在不同內容表述上的不同風格。
1.2 對比學習
對比學習通過采集與查詢樣本相關的正例集合和負例集合,來分析查詢樣本和正負例之間的對比關系。對比學習的目的是促使查詢樣本與正例相似,以增強正例對模型的影響。同時,對比學習促使查詢樣本與負例分離,最大化減少負例對模型的影響。在計算機視覺領域,簡單對比學習表達模型SimCLR[15]設計了一個視覺特征對比學習的框架,用于圖像分類。Khosla等人[16]設計了一種有監督的對比學習方法。在自然語言處理領域,簡單對比學習語句嵌入模型SimCSE[17]使用對比學習驗證語義文本相似度,并用于自然語言翻譯。融合模態模型UNIMO[18]使用對比方法來增強圖像-文本多模態特征學習,用于描述圖像內容。2022年,對比學習也用于語音合成中,CALM[8]將參考語音作為一個整體特征,并利用對比學習來提取其中的說話人風格。該方法忽略了參考語音中說話人風格和語言文本內容之間的相互干擾,導致合成語音的說話人風格和參考語音的說話人風格相似性較差。
2 分離對比學習語音合成模型
本章首先概述了對比學習個性化語音合成模型的框架,然后詳細介紹了風格-內容分離對比模塊、說話人模塊和解碼器模塊。
2.1 模型框架
本文模型采用FastSpeech 2[19]網絡作為基礎模型。模型的整體設計如圖1所示。FastSpeech 2方法[19]通過設計持續時間預測器、音高預測器、能量預測器,來描述豐富的語音變化信息,用于提高語音合成的質量。本文在FastSpeech 2網絡的基礎上,添加了說話人模塊和風格-內容分離對比模塊。其中說話人模塊用于提取說話人的身份信息,風格-內容分離對比模塊用于描述說話人在不同內容表述上的風格。由于本文考慮了說話人身份信息和具有內容差異的風格,可以較充分地使用上述語音信息,來減少語音合成中說話人變化和內容變化的干擾,從而提高語音合成的質量。本文模型由風格-內容分離對比模塊、說話人模塊和語音解碼器模塊組成。
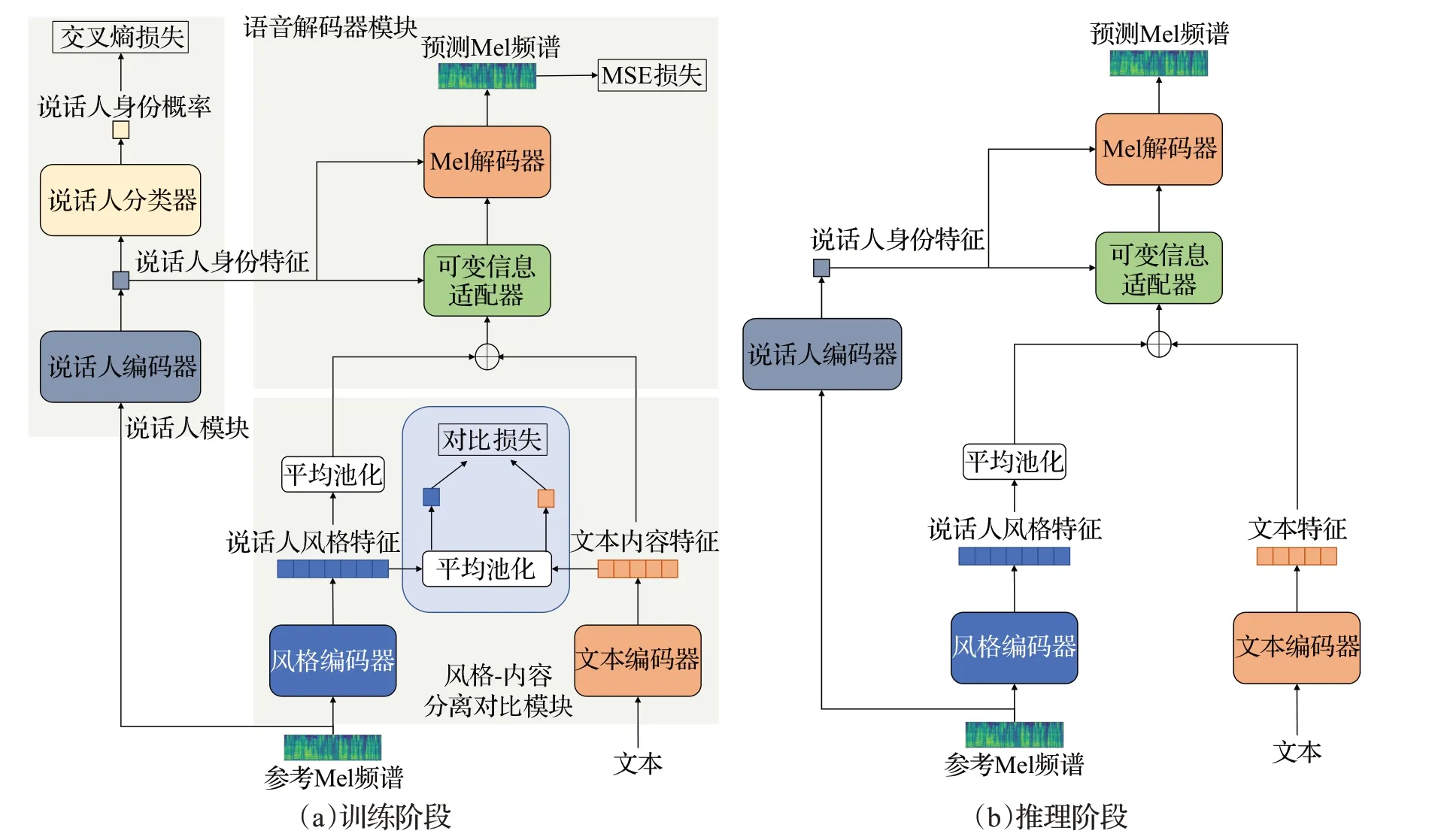
圖1 分離對比學習語音合成模型Fig.1 Separated contrastive learning speech synthesis model
2.2 風格-內容分離對比模塊
風格-內容分離對比模塊由文本編碼器和風格編碼器組成。文本編碼器使用Conformer Block[20]結構,風格編碼器使用卷積網絡加上Conformer Block結構。在該模塊中,文本編碼器提取文本特征,風格編碼器從語音中提取說話人風格特征。然后,該模塊通過分離對比學習,從參考語音中提取可分離的風格和內容特征。
首先,文本編碼器從長度為Ttext的文本表示xi中提取文本特征。使用風格編碼器從參考Mel頻譜yi中提取說話人風格特征表示第i對文本和語音的樣本對,Ttext是文本的長度,Tstyle是語音的長度,d是文本和語音的特征維度。然后,使用平局池化操作,將文本特征和說話人風格特征映射到相同的維度進行對比學習。計算如下:
最后,對比學習通過聯合訓練風格編碼器和文本編碼器來學習特征空間,以最大化正樣本特征之間的余弦相似度,并最小化負樣本特征之間的余弦相似度。
本文對比學習中的正樣本表示、語音風格和文本內容之間具有支持關系,即正關系。負樣本表示語音風格和文本內容之間支持關系不明顯,即負關系。本文使用一個語音及其支持的文本,將(文本,語音)對作為正樣本。本文使用的負樣本包括兩種情況:(1)一個語音和同一批次中不是該語音的文本,將語音和沒有支持關系的文本作為文本分離負樣本。(2)一個文本和同一批次中不是該文本的語音,將文本和沒有支持關系的語音作為語音分離負樣本。分離負例能夠促使查詢的風格和其他參考語音中的內容分離,同時能夠促使查詢的內容與其他參考語音中的風格分離。
給定正樣本文本和語音對應的特征為和,分離對比損失包括兩部分,分別是不同語音負樣本的對比損失,以及不同文本負樣本的對比損失,計算如下:
其中,N是樣本數量,τ是對比學習的溫度參數,sim(·)是余弦相似度函數,sim(u,v)=uTv/‖u‖‖v‖。
2.3 說話人模塊
說話人模塊由說話人編碼器和說話人分類器組成。說話人編碼器用來捕捉不同說話人身份特征,而不受語音內容和背景噪音的影響。說話人分類器用來區分不同說話人的語音特征,可以使模型更好地適應不同說話人的風格。
模塊框架如圖2 所示。首先,說話人編碼器使用Conformer Block來分析參考語音Mel頻譜yi幀信號之間的關系,提取說話人身份特征。然后,將說話人編碼器獲得的特征通過說話人分類器來區分不同說話人。說話人分類器包括三個線性層,每個線性層都具有ReLU激活函數。分類器使用Softmax層來輸出不同說話人身份概率,如下:

圖2 說話人模塊Fig.2 Speaker module
說話人編碼器能夠將說話人的語音信號轉化為說話人身份特征。說話人身份特征輸入到解碼器中,解碼器可以集中關注于該說話人,促使合成語音與說話人的參考語音更加相似。
給定真實的人工標注的說話人身份標簽和基于語音信號預測的說話人身份標簽,說話人模塊使用二元交叉熵損失函數,來計算說話人身份損失:
2.4 解碼器模塊
盡管說話人身份特征可以作為條件,但是靜態的權重不能對多樣化的說話人風格進行建模,因此解碼器模塊需要根據說話人身份特征調整網絡權重。解碼器中的每個自注意和前饋網絡都采用了條件層歸一化,這可以通過尺度向量和偏差向量影響風格。
解碼器模塊由可變信息適配器和Mel解碼器組成,如圖3所示。可變信息適配器由持續時間預測器、音高預測器、能量預測器、長度規整器和條件層歸一化組成。可變信息預測器用于預測語音的韻律特征,如持續時間、音高和能量。對于持續時間預測器,輸出是對數尺度中每個音素的長度,并利用均方誤差損失進行優化。對于音高預測器和能量預測器,輸出分別是幀級基頻和Mel 譜圖的能量,并使用平均絕對誤差進行優化。條件層歸一化由兩個線性層和層歸一化組成。

圖3 解碼器模塊Fig.3 Decoder module
首先,將編碼器提取的特征進行融合,得到融合后特征H∈?Ttext×d,計算如下:
持續時間預測器預測文本所對應的時長。長度規整器將特征H擴展到Mel頻譜的長度。條件層歸一化層對預測器提取的特征的每個維度進行處理H′={h1,h2,…,hM}。M表示特征維度。條件層歸一化層使用兩個線性層來確定說話人身份特征的尺度向量a和偏差向量b,用于特征的縮放和平移。上述操作的計算過程如下:
其中,H″表示條件層歸一化后的特征;μ和σ是特征H′的均值和方差。
2.5 損失函數
整個模型的損失函數包括對比文本-語音模塊的對比學習損失、說話人模塊的交叉熵損失、解碼器模塊中的持續時間均方誤差損失、音高和能量的平均絕對誤差損失,以及預測Mel頻譜圖和真實Mel頻譜圖之間的平均絕對誤差損失。本文的總損失函數計算如下:
其中,LCTS是分離對比損失,Lspeaker是說話人模塊的交叉熵損失,Lduration、Lpitch、Lenergy和Lmel損失函數采用FastSpeech 2的損失函數。
3 實驗
3.1 數據集
本文選取了VCTK[21]和LibriTTS[22]兩個多說話人數據集。VCTK數據集是一個具有108個說話人的多說話人數據集,包含44 h的語音數據和相應的文本。LibriTTS數據集是一個具有2 456 個說話人的多說話人數據集,包含586 h的語音數據和相應的文本。LibriTTS數據集中,將train-clean-100和train-clean-360用于訓練,dev-clean用于驗證,test-clean用于測試。
3.2 實驗設置
預處理階段:使用開源的字形到音素工具將文本序列轉換為音素序列,并將音素序列作為輸入。將音頻的采樣率設為16 000 Hz,并修剪前導和尾隨靜音的片段。然后,本文設置窗口大小為1 024,跳躍大小為256,采用Hann窗函數,來將原始波形轉換為具有80個頻率的Mel頻譜圖。
訓練階段:實驗使用顯卡為NVIDIA GeForce RTX 3090,操作系統為Ubuntu 18.04,深度學習框架為PyTorch。根據內容依賴細節語音嵌入模型(content-dependent fine-grained speaker embedding,CDFSE)[13],使用Fast-Speech 2[19]作為基礎模型來構建文本分離對比學習模型,并將訓練集劃分為預訓練數據部分和微調數據部分,分別用于預訓練階段和微調階段。在預訓練階段,選擇10 個作為未見說話人,剩下的說話人構成可見說話人數據集,用于模型訓練。在微調階段,對每個未見說話人,隨機選擇20個句子,構成微調數據集,用于模型微調。在每個階段,模型采用的批量大小為64,訓練步驟為3.0×105。學習率初始化為0.001。根據FastSpeech 2[19],設置學習率的衰減方式,使用Adam 作為優化器,優化器參數為β1=0.9,β2=0.98,ε=1E-9。
測試階段:模型微調過程中凍結了所有模型參數,僅更新說話人編碼器和條件層歸一化。本文在2 000步中訓練模型和基線。為了確保生成語音的目標說話人的特征都來自聲學模型,而不是聲碼器,選擇了一個預訓練的聲碼器。因此,本文在推理過程中使用高保真生成對抗網絡(high fidelity generative adversarial network,HiFi-GAN)作為聲碼器[23]。由于測試說話人在聲碼器訓練過程中是看不見的,可能存在泛化問題,這會影響語音質量,而且聲碼器可能無法很好地保留目標說話人的Mel 頻譜圖特征。因此,采用預訓練的HiFi-GAN將真實Mel 頻譜圖轉換為波形作為參考標準。此外,轉換后語音和真實語音之間的差距表明聲碼器的泛化差距。
3.3 評價標準
評價標準包括:(1)可見說話人的語音自然度,用于評價訓練集中已經出現的說話人的語音合成結果。(2)未見說話人的語音自然度,用于評價訓練集中沒有出現的說話人的語音合成結果。(3)說話人的相似度,用于評價合成語音與參考語音在說話人風格方面的相似程度。
評價指標分為主觀評價和客觀評價兩種。主觀評價采用平均意見分數(mean opinion score,MOS)來評價自然度。采用相似度評價意見分數(similarity mean opinion score,SMOS)來評價相似性。這兩個評價標準的評分都在1(差)到5(優)之間,為了避免實驗的偶然性,進行多次打分,以95%的置信區間進行評估。
客觀評價采用Mel倒譜失真(Mel cepstral distortion,MCD)來描述語音質量。采用說話人的余弦相似度(speaker cosine similarity,SCS)來衡量多說話人音頻中說話人相似度。SCS 分數在-1 和1 之間,得分越高,表明相似性越高。MCD 和SCS 都不是評估的絕對指標,因此只用它們進行相對比較。主觀評價的方式是選取5名通過英語六級的學生,進行人工評估。為了保證評估的公平性和正確性,同時在眾包平臺上發布了語音評估任務,由5名英語母語人士評價。
3.4 對比實驗
對比方法包含:(1)Attentron[4]模型,利用細粒度編碼器和粗粒度編碼器,分別生成可變長度特征和全局特征,對未見說話人進行語音合成。(2)AdaSpeech[5]模型,在聲學條件建模基礎上,使用條件層歸一化來提高對說話人風格的適應能力。(3)Meta-StyleSpeech[6]模型,在生成器中使用風格適應歸一化層從參考語音中提取的風格向量,來適應說話人的偏差。(4)Meta-TTS[7]模型,對目標說話人樣本進行多次采樣構建多個子數據集合,并使用多個子數據集合來避免說話人風格特征學習過擬合。(5)CDFSE[13]模型,使用文本內容的細粒度說話人特征,來實現零樣本說話人適應。(6)本文模型,關注于使用風格-內容分離對比損失,該分離損失能夠促使查詢的風格和其他參考語音中的內容分離,同時能夠促使查詢的內容與其他參考語音中的風格分離,從而增強說話人風格特征的學習。
3.4.1 可見說話人語音質量評價
表1 顯示了在LibriTTS 數據集上不同模型的可見說話人的語音質量評估結果。表1 中,Ground Truth 表示真實語音。Ground Truth Mel+HiFi-GAN 表示使用真實的Mel頻譜圖與HiFi-GAN聲碼器合成的波形。

表1 可見說話人的語音質量評價結果Table 1 Evaluation results of speech quality of seen speaker
本文方法在所有指標上都優于現有方法。具體來說,Attention[4]模型使用注意力機制對文本和語音進行對齊。由于注意力容易受到風格和內容的干擾,注意力自身不夠穩定,導致語音質量較低。本文模型關注于從參考語音中分離出風格特征和內容特征,使用風格-內容分離對比損失,來增強說話人的風格特征,從而實現高質量的語音合成。
3.4.2 未見說話人語音質量評價
表2 顯示了在VCTK 和LibriTTS 數據集上不同模型的未見說話人的語音質量評價結果。由于缺乏對應說話人的訓練數據,未見說話人的語音質量低于可見說話人的語音質量。本文方法在所有指標上都優于現有方法,這是由于本文方法引入了分離對比損失。該損失可以有效描述不同說話人在風格和內容上的區別,從而有效捕獲預訓練數據集中和微調數據集中說話人的風格特征差異,從而增強了未見說話人的語音合成質量。

表2 未見說話人的語音質量評價結果Table 2 Evaluation results of speech quality of unseen speaker
3.4.3 說話人相似度評價
表3 給出了LibriTTS 數據集上可見說話人和未見說話人的說話人相似度的結果。將本文模型的風格-內容分離對比模塊替換為標準化流模塊[14],來分析兩者設計之間的差異。在訓練時,標準化流模塊從風格編碼器提取特征,并用于監督文本編碼器的學習,從而將風格特征嵌入到文本特征中。在測試時,標準化流模塊使用嵌入風格的文本特征作為輸入,用于后續的Mel 解碼。與標準化流模塊相比,本文風格-內容分離對比模塊合成的語音與參考語音的相似性得分更高。這說明分離對比損失能夠有效提取說話人風格特征,并幫助增加合成語音與參考語音的相似度。

表3 說話人相似度的評價結果Table 3 Evaluation results of speaker similarity
3.5 消融實驗
表4 給出了LibriTTS 數據集上的消融實驗結果。基礎模型(Baseline)采用FastSpeech 2 模型。該模型融合風格編碼器提取的說話人風格特征,以及文本編碼器提取的文本內容特征,并輸入到語音解碼器,用于合成語音。本文模型引入分離對比學習,合成語音的質量和說話人相似度都有提高。這是因為對比學習能夠準確地提取說話人風格相關的信息。同時,引入說話人模塊和條件層歸一化會顯著提高未見說話人的相似度。從這個結果中,可以發現對于未見說話人,說話人模塊和條件層歸一化相比于對比學習提升效果更明顯。因為說話人模塊和解碼器模塊能夠適應模型沒有見過的數據,所以對于未見說話人有更好的泛化能力。

表4 LibriTTS數據集上的消融實驗結果Table 4 Ablation results on LibriTTS dataset
3.6 可視化分析
為了進一步證實本文模型的有效性,對合成語音的Mel頻譜進行可視化分析,如圖4所示。本文從LibriTTS數據集的未見說話人中選取一個參考音頻,說話人身份為Bill Kneeland,音頻內容為“It seems the king will not consent to it.”。以參考音頻的說話人風格來合成文本“She walked towards him and then halted.”。
從圖4中可以看出:(1)由于在參考音頻中存在king will not 的連讀現象,Baseline 方法在合成音頻中,也存在him and then halted 的連讀現象。本文方法由于使用了風格-內容分離策略,有效區分出then和halted之間的關系,通過音調的波谷,給出了更為清晰的halted 的發音時間范圍。(2)標準化流模塊和本文方法都較好地描述了then 和halted 之間的音調波谷位置。考慮到參考音頻中consent中音素“N”的音高處理方式,標準化流模塊采用減弱的音高,而本文方法采用較低的音高,本文方法與參考音頻中處理方式更為相似。(3)Baseline方法合成音頻對halted 進行弱讀處理。本文方法由于使用了風格-內容分離策略,關注到句子需要理解的重點,是前半句行為引起的后半句結果。而后半句的結果中halted 中的過去式后綴,對讀者理解整句話的內容比較重要。模仿參考音頻中對Consent發音重讀在第二個音節的特點,本文方法halted 的處理,也對第二個音節ed增加了音高。
4 結束語
本文對于實際生活中使用廣泛的個性化語音合成進行了研究,設計了基于對比學習的個性化語音合成模型,以提高合成語音的質量和說話人的相似度。首先,設計了對比文本-語音模塊,通過獲取風格相近的文本特征和說話人風格特征,來解決說話人相似度低的問題。然后,設計了說話人模塊和解碼器模塊,利用說話人模塊來區分不同說話人身份特征,解碼器模塊通過引入條件層歸一化,將說話人特征當作權重,來調整編碼器輸入的特征,合成說話人風格相關的語音。在VCTK和LibriTTS兩個數據集上的實驗說明,本文方法能夠合成高質量的語音,同時提高說話人相似度。在未來的工作中,可以考慮對參考音頻中的說話人特征進行解耦合,從而控制合成語音的音高、音色、情感等因素。此外,可以嘗試使用無監督或半監督的方法對少樣本的語音合成進行研究。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
臺聲(2016年2期)2016-09-16 01:06:53
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
