面向食品貯藏領域的知識圖譜構建方法研究
2023-11-27 05:35:48謝鎮璽李朋駿王金龍熊曉蕓
計算機工程與應用 2023年22期
辛 輝,謝鎮璽,李朋駿,王金龍,熊曉蕓
青島理工大學 信息與控制工程學院,山東 青島266525
民以食為天,食品不僅是人類賴以生存的必需品,而且也是社會發展的物質基礎。伴隨著國家綜合實力的不斷飛躍,人們對食品的追求從滿足溫飽變為優質健康[1],那么食品貯藏必然是追求高質量飲食不可缺少的關鍵環節。科學貯藏的意義在于保持食物的品質,減少浪費,真正將建設資源節約型社會落到實處[2],是我國致力于建設資源節約型社會這一國家發展決策的重要著力點。同時人們如何居家貯糧,食品產業如何調配貯藏環節,餐飲企業如何維護食品貯藏都是亟待解決的問題。合理的貯藏條件與方式能夠保證食品營養品質、飲食健康以及能源損耗,而現如今處于信息指數爆炸的時代,相關知識分散雜亂,質量參差不齊,而且食品貯藏是具備專業性的特定領域,人們有效便捷地獲取想要的知識信息是比較困難的。
面對紙質技術書籍、電子學術期刊文獻、網絡資源信息以及企業實驗數據庫信息等海量多源異質數據存在信息過載[3]、數據冗余、查詢困難等問題,知識圖譜技術便為整合高質量貯藏知識、理解海量食品數據提供了應用前景和實際意義。知識圖譜具備良好的可讀性、擴展性和解釋性[4],針對多而雜的數據完成結構化系統化表示,得到<實體,關系,實體>三元組,從而構建語義網,為數據分析、智能檢索、決策選擇等提供支持。知識圖譜在醫療、金融、工業等領域的應用取得了可觀的成果[5],然而當前食品領域知識圖譜研究相對匱乏。在國外,Damion 等人[6]于2018 年提出了FoodOn 本體概念,為營養、食品安全等相關知識提供了一套標準化語義表示。Steven 等人[7]于2019 年提出了相對全面的食品飲食方向圖譜構建方法FoodKG,以及后續在此基礎上的健康、個性化推薦等研究[8]。在國內,目前相關研究也處在起步階段,而針對食品貯藏相關信息智能化以及圖譜構建鮮有關注。本文依據蘊含的研究價值和信息特點提出了一整套食品貯藏知識圖譜(food storage knowledge graph,FSKG)構建框架,極大地利用與組織多源異質信息,依托于本文設計的超節點概念模式,采取深度學習等技術完成抽取,結構化表達出大數據中食品貯藏知識,為普通居民、相關從業者和研究人員提供知識庫保障[9],并為該領域后續研究提供參考。本文的主要貢獻如下:
(1)對多源異構的食品貯藏數據進行分析,構建領域本體并提出了超節點概念表示模式,從領域知識視角出發以彌補圖譜三元組知識表示的缺陷。
(2)設計了改進的融合多特征的命名實體識別模型,結合食品貯藏語義和文字信息進行特征編碼,以提高領域知識的識別性能。
(3)基于超節點的表達模式,提出了多元關系抽取算法與多分類模型相結合來完成關系抽取,然后采取基于詞典和相似度匹配的方法完成數據融合。
(4)構建了食品貯藏數據集和食品別名詞典,并通過實驗驗證所提出的FSKG框架的可行性和有效性。
1 相關工作
知識圖譜作為一種由概念、關系和實例構成的知識表示模型,既能滿足人類理解的知識組織結構,又有利于計算機模擬和處理知識。自2012年谷歌公司正式提出知識圖譜的現代化定義以來[10],在通用領域中已有如YAGO[11]、Freebase[12]、CN-DBpedia[13]、OpenKG平臺(openkg.cn)等具有代表性的大型知識圖譜。通用領域知識圖譜往往涵蓋現實世界的大量常識內容,涉及知識跨度廣泛,但面對特定領域場景,從知識深度和專業性上通用知識圖譜則表現得相對乏力。作為通用知識圖譜的衍生,領域知識圖譜彌補了上述缺點,同時具有知識質量高、知識粒度細等特點,且更加專注于領域數據特征和應用需求[14]。
對于知識圖譜的構建流程可以分為自頂向下(topdown)和自底向上(bottom-up)兩種[15]。其中自頂向下是從本體構建的角度出發完成模式層設計,然后利用本體的模式信息完成知識抽取,依據規范分明的概念框架完成圖譜構建,這種方式適用于專業性高、知識范圍明確的領域知識圖譜構建;而自底向上的方式則以底層數據信息為起點,無監督聚類抽取知識,歸納整合得到本體,缺乏顯性類型約束,更適用于數據量大、知識范圍較廣的通用知識圖譜[10]。
由于食品貯藏的知識專業性和領域特征,本文采取自頂向下的方式來完成知識圖譜構建。從技術視角來看,領域知識圖譜構建包括采取本體構建方法完成上層本體的邏輯抽象,以及利用自然語言處理(natural language processing,NLP)技術完成知識抽取、知識融合等特定任務,遵循本體規范,從多源異構數據中獲取領域知識,并根據語義對不同數據源的信息進行融合,最終存儲形成知識圖譜。知識抽取包括實體識別和關系抽取等方面,通常采用基于規則和基于機器學習的方法實現。基于規則的方法常常需要針對特定領域匹配規則,對實體和關系進行設定。雖然存在可移植性較差、泛化能力不高的問題,但在特定領域中具備較高的準確性,并對于抽取表述規范、概念間關聯性較強的數據信息表現出一定的優勢。李峰等人[9]在構建遙感應用領域知識圖譜時,針對同一論文摘要文本中的實體關系按照共現頻次完成規則抽取。錢智勇等人[16]采取規則的方式建立正則表達式,完成對注疏語句和例證句子中實體的抽取,最后完成古代辭書知識圖譜的構建。而對于基于機器學習的方法常常使用隱馬爾可夫模型(hidden Markov model,HMM)、條件隨機場(conditional random field,CRF)等方法來處理實體識別問題。隨著神經網絡的強勢發展,長短期記憶網絡(long short-term memory,LSTM)、門控循環單元(gated recurrent unit,GRU)模型等方法進一步提高了實體識別的性能。近年來以BERT(bidirectional encoder representation from transformers)為代表的預訓練模型結合了遷移學習的思想,以豐富的語義表征信息使識別效果達到了新的高度。對于關系抽取,機器學習方法通常將其作為二分類或多分類問題進行處理,將語句的特征向量作為輸入,以卷積神經網絡(convolutional neural network,CNN)、循環神經網絡(recurrent neural network,RNN)、長短期記憶網絡等模型來完成關系類別預測,研究人員對特征嵌入、模型改進等方面進行創新,進一步提升了抽取效果。王春雨等人[10]在研究船舶舾裝設計經驗知識圖譜的構建方法時,采取基于優化的多層神經網絡完成實體識別,接著應用基于嵌入的BERT分類模型完成關系抽取。袁琦等人[17]在構建寵物知識圖譜時,針對非結構化數據采取CRF與癥狀詞典相結合的方法完成實體抽取。徐春等人[18]借助改進的BERT預訓練模型與指針網絡相融合,對實體和關系進行聯合抽取來實現對旅游知識圖譜的構建。聶同攀等人[15]構建故障診斷領域知識圖譜,采取雙向LSTM 從非結構化文本中抽取實體,然后在雙向LSTM中引入注意力機制來獲取實體間的關系信息。
在構建知識圖譜的過程中,由于異構數據多源,表述方式多樣,通過知識融合完成對抽取數據的整合,解決實體、關系等產生的冗余,旨在提高圖譜質量。知識融合主要集中在實體對齊任務上,即解決不同名稱表達相同實體的問題。Zhou 等人[19]在構建移動應用知識圖譜過程中,采取規則挖掘與知識圖譜嵌入的方法完成各應用市場之間應用程序相關的實體對齊任務。周炫余等人[20]提出一種基于層次過濾的知識融合模型,實現百科及教程文本的實體對齊。李峰等人[9]將不同語料抽取產生的實體集合采取字符串相似度計算的方法判斷實體間的相似性,并將相似度超過閾值且名稱較長的名稱作為統一實體。楊波等人[21]采取融合CNN和余弦相似度的實體鏈接模型完成企業實體融合。一般情況下,在完成實體對齊任務后,包含對應實體的三元組會完成替換,進而去掉重復的三元組。但面對本文研究的食品貯藏領域中無法由簡單三元組表征的復雜關系,抽取時會產生一定的冗余,故按照其數據特征對知識融合方法做了進一步改進。
2 食品貯藏知識圖譜構建框架
本文將食品貯藏領域與知識圖譜技術相結合,提出了一整套食品貯藏知識圖譜構建框架,就領域內存在的多種概念間的復雜聯系,提出了多元關系的表達模式和知識構建方法,以彌補如今大多數知識圖譜僅用<頭實體,關系,尾實體>表示而無法表征更多復雜知識的問題,同時也為相關研究和應用提供新的思路。FSKG構建框架如圖1 所示,依據對領域內數據資源的分析,完成模式層設計,然后根據知識特征采取改進的方法進行知識抽取,并通過知識融合手段消除數據冗余,最后完成知識存儲。下文將對具體環節進行闡述。
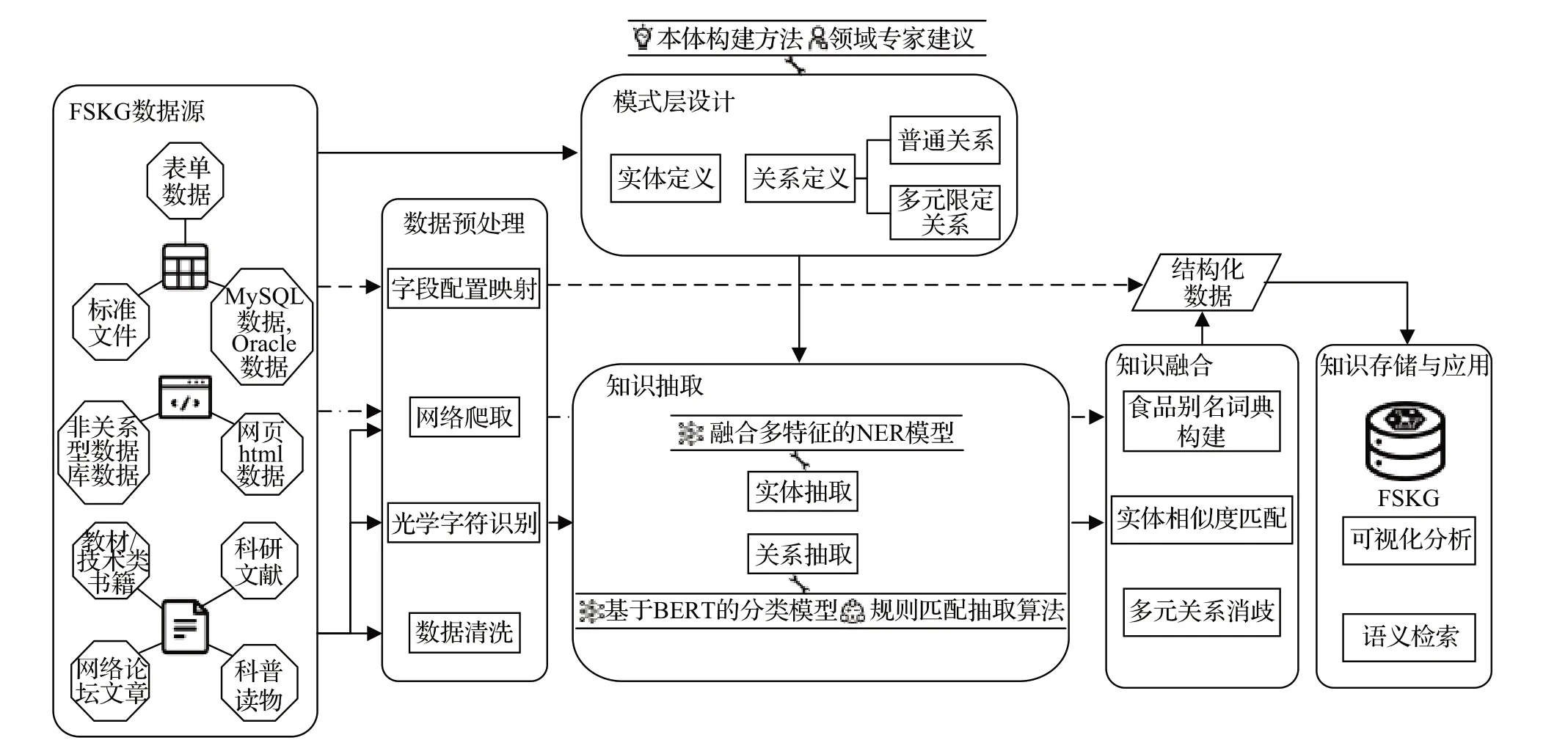
圖1 食品貯藏知識圖譜構建框架Fig.1 Construction framework of food storage knowledge graph
2.1 數據資源分析
據研究發現,現階段大多數的領域知識圖譜研究所關注的抽取知識往往集中在特定的某一類或某幾類數據,而對于本領域其他異構信息卻不能很好地體現其領域知識圖譜的泛化能力。同樣,食品貯藏數據也具有專業性強、數據結構多樣、概念錯綜復雜、信息載體多元等特點,而為探索一套完備且泛化性高的知識圖譜構建技術,首先需要保證食品貯藏信息源多元且全面。從知識的組織形式上來看,食品貯藏數據包含結構化、半結構化和非結構化數據。其中結構化數據主要包括國家標準委等規范文件、文檔書籍中的數據表格,諸如食品冷藏參數表、蘋果部分品種貯藏條件表等,還包括食品企業等機構內部私有數據,往往以關系型數據存儲在MySQL、Oracle 等數據庫中,如食品分類表、食品信息表、貯藏條件表等。上述數據的缺陷在于無法高效地查詢檢索,不易真實表達業務場景,這也正是構建圖譜的需求和優勢所在。而半結構化數據包括維基百科、食品相關網站中的html 網頁數據,如食品別名、適宜貯藏溫度等信息,以及一些MangoDB 等非關系型數據以json數據格式保存。
非結構化數據是構建知識圖譜過程中重點和難點所在,因其具備豐富的語義信息和數據價值,本文將分為如下幾類數據進行分析構建。
(1)教材及技術類書籍,知識整合規范,專業性和權威性強,作為FSKG知識元的主體內容,比如《食品安全保藏學》《食品貯藏保鮮技術》等。
(2)科普讀物,食品類型更加集中于常見品種,表述相對寬泛,涉及溫度、濕度等一系列參數,表達粒度相對較粗,可以作為構建圖譜的知識補充,例如《常用食品的貯藏與保鮮》《食品保藏的秘密》等。
(3)科研文獻,這類數據往往理論性較強,專業術語復雜,為保證抽取知識的高效性,抽取數據以文獻的摘要部分為主。食品貯藏類文獻往往集中發表在食品以及農業類期刊的貯藏保鮮、包裝貯運等欄目中。
(4)網絡論壇文章,主題鮮明,篇幅相對較短,有時候表述不太規范,需要后期通過知識融合完成數據規范,又因缺乏權威背書,抽取構建過程中可以作為補充數據。這類數據包括例如食品論壇、海爾冰箱社群、微信公眾號文章等。
2.2 數據模式設計
知識圖譜從邏輯的角度分為模式層與數據層。模式層是整個知識圖譜的核心部分[22],主要完成專業術語上的語義規范,消除不同數據源中同一概念的歧義,對數據層知識抽取完成約束。食品貯藏相關的資源蘊含著重要的信息價值,涉及到食物品種分類、生理病蟲害特性、各種工農業技術及參數指標、生產生活中的方法經驗等。本文按照斯坦福七步法[23]的設計思路,并參考食品專業研究者以及企業專家等相關領域專家建議,針對食品貯藏領域的內容抽象概括完成本體構建。
在分析設計過程中,食品貯藏數據主要存在以下一些特點:領域數據中大多數以食品為主體進行表述,一般包含相關的溫度、濕度、貯藏時間、使用貯藏技術等信息,且往往伴隨著對食品品種關系、化學生物特性、病蟲害腐敗現象的表述;一些文本則會以具體貯藏操作行為進行表述,例如“充分冷卻”“加蓋密封”等,以及操作方式防止或者緩解“冷害”“腐敗”等現象;食品貯藏數據條件往往是在特定場景下存在的,若變換為其他場景則各種條件將會發展變化,例如一些貯藏場景的表述為“廣大農村地區常用”“家庭中貯藏”“遮光封閉條件下”“冷庫中進行”等。按照上述數據特點和方法將食品貯藏領域知識分成10種實體類型,詳細信息如表1所示。

表1 實體類型表Table 1 Entity type
為了完整描述食品貯藏領域的語義網絡,需要明確實體與實體之間的關系,本文將其定義為普通關系和多元限定關系兩大類。其中普通關系指領域概念之間的常規關系,即以二元一階謂詞邏輯表示,包括食品與食品的“包含”關系、“貯藏條件相似”關系、“不可混合貯藏”關系;食品與貯藏特性以及病蟲害敗壞現象的“具有特性”關系;保藏方法或者貯藏操作與病蟲害敗壞現象的“防止/緩解”關系。詳細描述如表2所示。

表2 普通關系類型表Table 2 Common relation type
根據對食品貯藏數據的特性分析發現,包括貯藏溫度、空氣狀況、貯藏時間、保藏方法、貯藏操作、場景以及包裝在內的7 類實體在文本描述中常常作為相互制約的條件約束表征某一食品的貯藏知識。例如“芒果的氣調貯藏法下要保證5%氧氣和5%二氧化碳,壽命可達20天。”食品“芒果”在“氣調貯藏法”“5%氧氣”“5%二氧化碳”的條件限制下貯藏時間為“20天”。由于這些實體并不是食品的特征且實體間存在隱含的限制關系,不能將其作為食品屬性的概念來簡單處理。同時如果顯式地以二元關系表示出來會使整個語義網絡復雜且冗余,同時也存在知識表示的缺陷。而本文借鑒Freebase 知識圖譜中的復合值類型(compound value types,CVT)[24]提出了超節點的概念來表達多元實體間的限定關系。超節點不代表實際數據,而是作為虛擬節點連接食品實體與其他多個制約條件實體,它既表示父節點食品實體與其葉子節點實體間的條件關系,又表達在父節點已知的條件下各葉子節點兩兩之間的限制關系,達到食品貯藏領域下特定復雜知識的表征。經上述分析設計得到食品貯藏知識圖譜的模式層設計,如圖2所示。
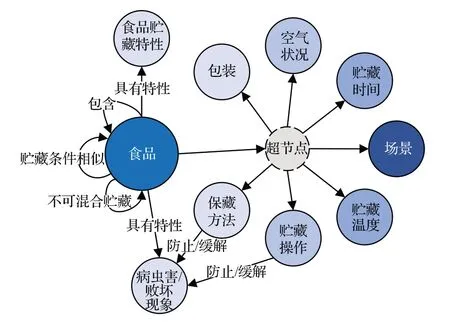
圖2 食品貯藏知識圖譜模式層Fig.2 Schema layer of food storage knowledge graph
2.3 數據預處理
由第2.1節分析可知,對于結構化數據,其原始各字段語義明確,故按照模式層與其具體語義設計相應的字段映射規則[25],保證異構數據在完成知識圖譜構建后的完整性和一致性,提取出對應的實體組。比如就蘋果部分品種貯藏條件和貯藏期表而言,由品種、溫度、相對濕度、貯藏期4 列組成,按照規則映射成為模式層中多元限定關系下的實體組,形成譬如<元帥,0~1 ℃,相對濕度95%,3~5月>,<金冠,0~2 ℃,相對濕度95%,2~4月>等,為后續知識融合與知識存儲做準備。對于半結構化數據,本文采取Scrapy 框架爬取維基百科等相關網站,獲取食品、別名、貯藏特性相關的半結構化網頁數據,將別名字段構建成為食品別名詞典為后續知識融合提供數據支撐,而將爬取的其他短文本信息作為待抽取的數據源集合。
相比結構化和半結構化數據,處理非結構化數據抽取是最為復雜,也是自然語言處理的重點研究對象。其中對于包括文本描述,以及包括圖、表等結構化數據的紙質書籍,利用光學字符識別技術(optical character recognition,OCR)將紙質數據處理為計算機可以處理的格式[26],本文采取基于深度學習的PaddleOCR開源技術框架完成紙質書籍到文本形式轉換,并進行數據清洗工作,如統一格式、轉換識別非法字符、清除空格、剔除無效文本、篩選有效可構成語料的文本數據。對于網絡數據中知網數據庫文獻、網絡文章和論壇評論同半結構化數據一樣進行爬取,并經正則表達式清除無關標簽,完成數據清洗后形成語料數據。
2.4 融合多特征的實體抽取
結構化和半結構化數據抽取工作已在數據處理中完成,故本文不再過多贅述。而對于非結構化數據,實體及關系隱藏在自然語言文本中,則需要進行識別抽取,這是實現大規模知識圖譜構建過程中的關鍵工作和技術難點。實體抽取完成自然語言處理中的命名實體識別(named entity recognition,NER)任務,隨著自然語言處理技術和硬件算力的發展,目前采用深度學習的NER 技術則是較為廣泛和高效的方法[27]。針對食品貯藏領域的數據特點,本文設計了一種融合多特征的命名實體識別模型,分為特征編碼層、上下文信息提取層、輸出層三層結構,模型采取了遷移學習的思想來獲取先驗語義信息,同時融合食品貯藏數據的字符特征,確保模型的泛化效果,有效解決了大規模語料標注和抽取效果不明顯等限制性問題[28]。模型完成實體抽取的工作原理如圖3所示。
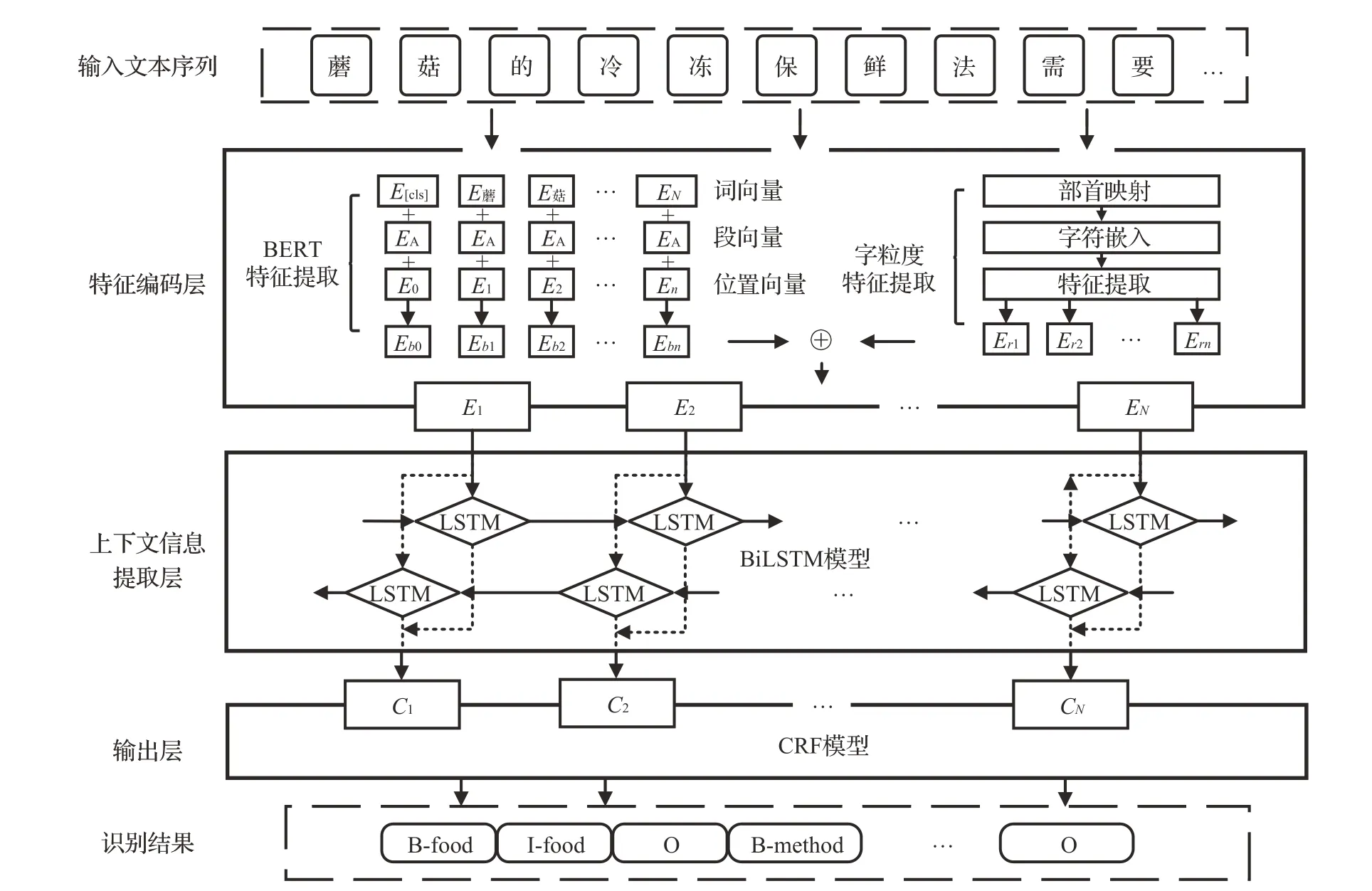
圖3 實體抽取工作原理圖Fig.3 Working principle diagram of entity extraction
首先在特征編碼層中引入BERT預訓練模型,充分利用上下文的關聯語義,學習到豐富的特征表示信息,能夠解決不同語境下的詞多義性的表征[29]。例如在食品貯藏文本中,“意大利”在不同語境下既有可能表達為食品產地,也有可能是一種葡萄品類。BERT 在預訓練中分別融入字符嵌入token、句子嵌入segment以及位置嵌入position 三類特征,經過多重雙向Transformer 編碼器得到豐富表征的動態詞向量,從而理解句子以及詞語間的位置和語義關系[30]。同時為了提升食品貯藏文本的識別效果,本文進一步融合了字粒度的部首信息,來增強特征空間中的語義嵌入。相較于英文,漢字中的部首信息能夠使字符信息表達更加準確,一般情況下同部首字義相近[31],例如“椒”“柚”“梨”等部首為“木”,屬于植物性食品;“粉”“糖”“糕”等部首為“米”,屬于碳水類食品;再例如“螟”“螨”“蚜”等部首為“蟲”,常常出現在食品病蟲害類型實體的表述當中。本文以漢字碼表作為部首對照字典,對于輸入的文本進行部首特征映射,如將圖3 中的輸入文本“蘑菇的冷凍保鮮法……”轉換為“艸艸白冫冫亻魚氵……”,接著對映射后的序列采用已學習部首信息的word2vec 模型來獲取部首向量,然后通過全連接層提取上下文特征,計算公式如下:
其中,xi為字符的部首表示,feature_dic 為部首對照字典,ci為輸入字符,word2vecrad表示經部首特征訓練后的詞向量模型,ri表示xi的特征嵌入,ei表示最后輸出的部首特征向量,dense 表示全連接操作。最后經字粒度的特征提取后將部首特征向量Er與BERT動態詞向量Eb進行拼接,作為接下來模型的輸入。
第二層上下文信息提取層將融合了多重特征的詞向量由BiLSTM神經網絡模型繼續捕獲文本特征,有效解決遠距離依賴問題,完成上下文信息提取,進行實體識別,經過解碼輸出字符在各類實體的預測分數。但由于其作為實體識別概率值是相對獨立的,無法學習到輸出序列標注的約束條件,需要在第三層輸出層中使用CRF概率模型來解決。這是因為經過BiLSTM模塊輸出可能會出現以I-food預測標簽為實體首部的情況,或在B-food 之后緊接著I-method 這樣與語法結構相悖的序列。在BIO標注體系下缺少相關約束條件,例如實體開頭字符的預測標簽須為B-xxx,label_a 類型的I-label_a后面不能出現label_b 類型的I-label_b 預測標簽。對此在輸出層中使用CRF模型學習前后標簽的依賴約束,通過轉移分數矯正上一層發射分數的偏差,降低出現無效標簽的概率,從而計算得到概率值最大的預測標簽。最后得到與輸入文本一一對應的最佳預測標注序列,完成對實體的抽取任務。
2.5 關系抽取
在完成實體抽取任務之后,關系抽取則是挖掘海量食品貯藏相關數據知識價值的另一個核心步驟。關系抽取旨在從文本中抽取出二元或者多元實體間的語義關系[32],由于食品貯藏實體間語義的特殊性和復雜性,本文按照模式層設計采取基于規則和深度學習兩類方法來完成抽取工作。
2.5.1 基于規則的關系抽取
基于規則的方法應用在具有多元限定關系的實體之間,首先選擇在實體抽取任務中含有特定類型實體的語料作為接下來規則抽取的數據,其中抽取到的實體包含食品以及貯藏溫度、空氣狀況、貯藏時間、保藏方法、貯藏操作、場景、包裝7 類實體中一類或多類。然后發掘數據中的表述規律,設計抽取規則算法完成關系抽取,通過對相關語料分析可以總結出:
(1)絕大部分語料都是以食品類型實體作為主語進行表述,且一條語料以一種食品居多,常常出現在句子開頭。
(2)貯藏溫度等7 類實體在文本中不單獨存在,而是依附于食品實體,表述中具有多元限定關系的實體往往在一句話或者相同句式內。
(3)貯藏溫度、貯藏時間和保藏方法3 類實體根據實際語義可知,同種類型實體不會同時出現在一個超節點下,即以上3種類型的同種實體間不構成多元限定關系。
(4)在一條語料當中,多個貯藏條件(即一個超節點下具有多元限定關系的實體組成一個貯藏條件)往往以“;”或者以不同的保藏方法、貯藏溫度實體作為界限來劃分,語料在進行實體抽取后的實體序列常常具有規律性。比如抽取的正則實體序列為“(食品,貯藏溫度,空氣狀況(,(貯藏操作|場景|包裝))*)+”,可以表達“龍眼貯藏適宜溫度3~5 ℃,氧含量3%~5%,二氧化碳5%~8%;巨峰適宜溫度0%,氧含量3%~4%,二氧化碳含量5%~6%。”
(5)對于多個食品類型實體的表述往往呈并列形式出現,常用“和”“;”以及“、”隔開或采取相同句式表述。例如“白梨和沙梨適宜貯溫一般為0~1 ℃,大多西洋梨和秋子梨適宜貯溫-1~0 ℃”“各種罐頭、飲料、油料、干制食品等都適宜在常溫下貯藏和流通”。
本文基于食品貯藏領域內數據特點設計規則匹配關系抽取算法,完成對多元實體對應關系的篩選與結合,繼而完成多元限定關系中實體序列的抽取。需要說明的是,對于輸入的每一條語料C都有與之對應的經實體抽取任務后得到的實體組E和實體類型組M。分割文本c、分割實體類型組mc[h..t]和分割實體組ec[h..t]同樣也一一對應,h、t表示從M和E中分割的頭位置和尾位置。算法中步驟6 表示將實體類型組與正則實體序列進行匹配,若匹配結果不空則完成數據提取。步驟9 旨在匹配那些缺少上文已提及食品指代的分割文本中的多元限定關系,其中mc-1[h′..t′]表示上一條分割文本的分割實體類型組。
算法規則匹配關系抽取算法
2.5.2 基于BERT的關系分類
關系抽取任務應用深度學習方法進行高效解決,則可以將其建模為多標簽分類問題。對于模式層構建中的五種普通關系,本文采取基于BERT的關系分類模型[33],使用預訓練模型來獲得豐富語義的特征向量,提升關系抽取的效果[34]。與BERT在實體抽取任務的作用不同在于,本文不僅進行句子embedding 表征信息,同時又結合了實體以及實體位置信息,經由特征向量對關系分類進行預測。
抽取模型的輸入信息包含實體的文本,以及待抽取關系的頭尾實體信息。在數據預處理時,以特殊標識符表示待確定關系的兩個實體位置,其中實體位置前后加“#”表示,尾實體位置前后加“$”表示。并以[CLS]作為句子的開始,以[SEP]作為句子結束。然后采取BERT模型特征提取后將句子信息特征、實體語義特征和實體位置信息拼接,經全連接層和softmax 層完成關系分類的概率預測,最終輸出待預測的結果。普通關系抽取工作原理如圖4 所示,圖中關系標簽3 為關系“不可混合貯藏”的編碼信息。
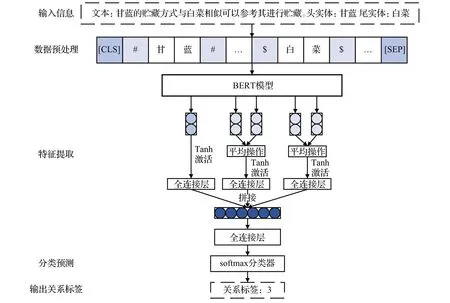
圖4 普通關系抽取工作原理圖Fig.4 Working principle diagram of common relation extraction
2.6 知識融合
由于食品貯藏領域數據多元,文字表述存在差異,對于同一個概念的描述會存在差異,常常會抽取不同的實體卻表達同一種語義概念,經過抽取任務后完成存儲會使知識產生大量冗余并占有額外的存儲空間,因此需要進行實體對齊。例如“洋蔥和土豆這兩種蔬菜卻并不適合放在一起。”中的“土豆”和語句“馬鈴薯的貯藏方式很多,依據各地不同條件可做堆藏、窖藏、溝藏等。”的“馬鈴薯”表達為同一種食品名稱;還有“水果蔬菜”對應“果蔬”的略寫,“軟飲料”對應“軟飲”的表達;對于貯藏溫度的表達“1 ℃~2 ℃”“1~2 攝氏度”,若不進行處理則會按照不同的實體進行存儲;針對其他類型實體,比如貯藏方法中的“氣調貯藏”和“氣調貯藏法”的表述需要進行知識合并。針對多元限定關系同樣也會產生關系冗余的情況,這是由于在完成關系抽取和實體對齊任務后,會出現不同的多元限定關系實體組內含有多個相同實體。例如r1=[“金冠”,“0~2 ℃”,“3個多月”],r2=[“金冠”,“0~2 ℃”,“相對濕度95%”,“3 個多月”],對于“金冠”的同一個貯藏條件(由于r1?r2),顯然r2對應的原文本比r1描述得更全面,那么r1相對于r2來說則作為冗余信息存在。由于食品貯藏條件復雜,實體間關系相互制約,只有當多元限定關系實體組之間存在包含關系時,認為該食品在相同貯藏條件下存在冗余,否則作為不同的貯藏方式進行存儲。
根據上述分析,本文采取依據詞典和相似度匹配的知識融合方法,流程圖如圖5所示。經關系抽取任務后將實體分成實體對和多元組兩類,識別為多元組中的實體在經過實體對齊任務后,需要額外判斷是否存在冗余多元信息,完成超節點對齊任務,即消除多元限定關系冗余。首先依次輸入組內實體判斷類型,若輸入實體為“食品”類型,則利用食品別名詞典進行匹配查找,若找到則依據詞典中主名進行替換,若沒有找到則進入相似度匹配計算。對于含有數值信息的實體類型(貯藏時間、貯藏溫度、空氣狀況),需進行標準化處理,即將實體內容統一為“(描述)+數值范圍+單位/%”,若與已更新實體表述相同則視為同一實體。針對食品貯藏領域數據,經上述兩類實體對齊處理即可消除較大比例的冗余信息,故對于剩余類型實體,本文采取快捷且效果良好的余弦相似度算法來匹配實體間的相似性,采用sklearn中tfidf工具完成實體詞匯級別的向量化表示,依次計算其與圖譜中同類型各實體間的余弦相似度S,計算公式如下:
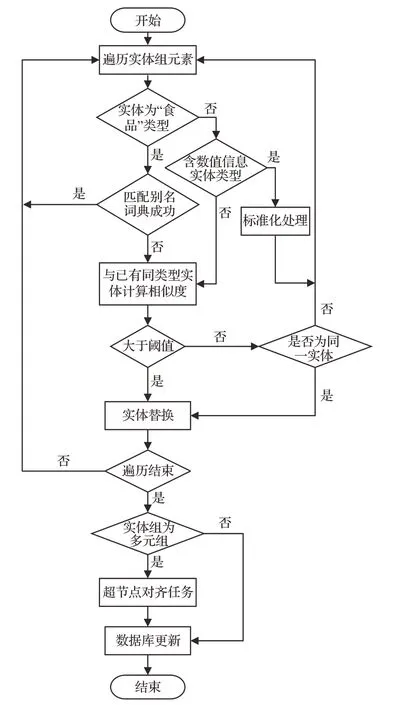
圖5 知識融合流程圖Fig.5 Knowledge fusion flowchart
其中,E和X表示實體的詞向量,n表示向量維度,ei和xi分別表示E和X的第i個分量,S越大表示兩向量的余弦相似性越強,即兩實體語義越接近,選擇超過設定閾值且數值最大的實體作為融合對象,若匹配失敗則作為新的實體,依次循環上述過程完成組內實體對齊任務。由于上述處理可能會存在一定的誤差,為保證準確性,在循環結束后應輔助校驗未匹配成功的實體是否需要實體對齊。若是實體對中的實體則完成實體對齊任務,取得新的三元組或鏈接到圖譜中已有的節點中完成數據庫更新。若是多元組內的實體,則繼續完成超節點對齊,即遍歷圖譜中超節點下多元限定關系中實體集合是否與輸入多元組集合有包含關系,若沒有則作為新的多元限定關系以超節點形式存儲在知識圖譜當中,反之取兩者的超集(superset)作為存儲在圖譜中的內容來更新數據庫。經過知識融合后,使得知識元質量得到提升,節省了存儲空間。
3 實驗分析
3.1 實體抽取
按照第2.1 節中非結構化數據的劃分方式,分別選取韓艷麗編著的《食品貯藏保鮮技術》、劉興華編著的《食品安全保藏學》、王城榮編著的《常用食品的貯藏與保鮮》以及105 篇科研文獻摘要、50 篇網絡短文作為數據來源,經數據預處理相應操作后,共獲得13萬字的語料,從中隨機抽取2 000條作為命名實體識別的數據集,訓練集和測試集比例為8∶2,數據預處理后待抽取語料示例圖如圖6所示。

圖6 待抽取語料示例Fig.6 Examples of unextracted corpus
本文采取BIO 實體標注方法完成對語料中字符的表征,其中B表示命名實體的開頭字符,I表示命名實體的剩余字符,O表示所有命名實體以外的字符。語料共有21種標簽,命名實體標注示例如表3所示。實體識別模型的BERT預訓練模型版本采用BERT-Base-Chinese,訓練批量大小為16,最大序列長度為246,部首特征向量維度為32,BiLSTM隱藏層維數為128,學習率為5E-5,訓練輪次為50。
為了驗證本文提出模型的性能優勢,分別選取在命名實體識別中常用的BiLSTM-CRF、BERT-CRF、Word2vec-BiLSTM-CRF、BERT-BiLSTM-CRF模型在構建的食品貯藏數據集上進行對比實驗,實驗結果采取召回率R、精確率P和F1 分數三種評價指標。實驗結果如表4所示,本文融合多特征的實體識別模型識別效果最佳,其中F1 值為91.07%,比直接融合動態詞向量的BERT-BiLSTM-CRF 模型以及采取傳統靜態特征向量的Word2vec-BiLSTM-CRF 模型分別在F1 值上提高1.52 個百分點和13.03 個百分點,相較于沒有學習語義特征進行隨機編碼的BiLSTM-CRF 模型識別效果更有優勢,證明本文模型能夠有效捕獲食品貯藏文本中的語義特征和上下文信息來完成實體抽取任務。采用本文模型對于10 類不同類型實體抽取的實驗結果如表5 所示,分析可知其中“貯藏時間”“食品”等實體類型識別效果最好,原因在于這些類型在表述上較為規范,且模型在這些類型實體上的語義特征提取表現較好;然而對于“貯藏操作”“場景”等實體類型識別效果相對一般,這是由于與其他類型實體相比包含該類實體的文本相對較少,模型學習特征稍顯欠缺,同時該類型實體表述方式往往相對復雜,標注可能存在部分偏差。
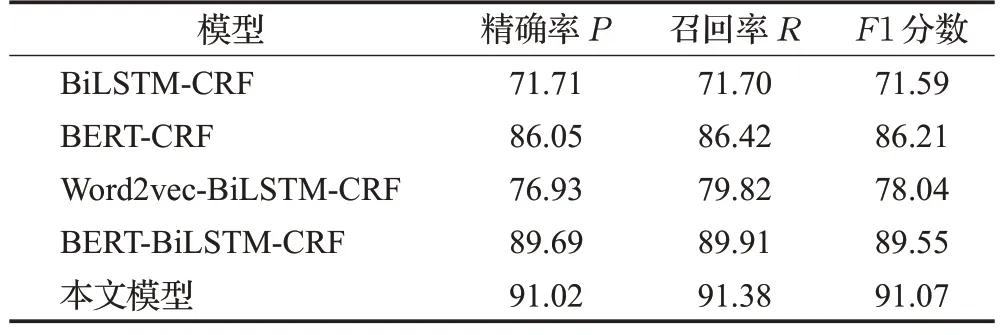
表4 不同模型的識別結果對比Table 4 Comparison of recognition results of different models 單位:%
3.2 關系抽取與知識融合
3.2.1 基于規則的關系抽取
規則匹配關系抽取算法主要完成對實體間的多元限定關系進行匹配抽取,其詳細流程已在第2.5.1 小節中闡述。首先將經實體抽取任務后具有實體標簽的文本和原實體標注語料作為候選數據,然后根據實體標簽類別對候選數據進行篩選,剔除僅含有例如“食品”或者“食品”“貯藏特性”等不具備多元限定關系的句子,共計得到2 104條待抽取語料,對應2 104組實體組15 649個實體。將待抽取語料、對應實體組和實體類型組作為算法的輸入,保證實體序列要與語料中的語序保持一致,經過算法中正則表達式以及文本匹配方法抽離出存在多元限定關系的實體集合。經過規則匹配關系抽取算法循環遍歷所有輸入語料,輸出得到多元限定關系實體組,并以json 格式進行存儲,為后續實體融合與知識存儲做準備。抽取結果示例如圖7 所示,共計抽取2 638組多元限定關系。圖8 展示了抽取得到的多元限定關系中各類型實體的占比情況,其中除食品類型外,保藏方法和空氣狀況類型實體相對較多。

圖7 實體組抽取結果示例Fig.7 Examples of entity group extraction results
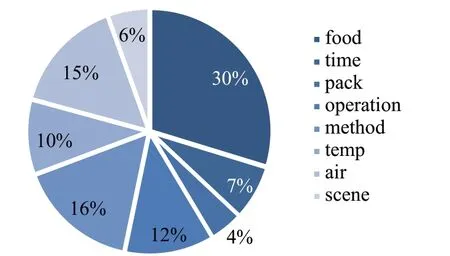
圖8 多元限定關系中各類型實體占比情況Fig.8 Proportion of various types of entities in multi-restricted relation
3.2.2 多分類關系抽取
本文同樣從第3.2.1小節提及的候選數據中選擇具有潛在普通關系的文本作為關系分類實驗的語料,即句子中包含“食品”“病蟲害/敗壞現象”“保藏方法”“貯藏操作”“食品貯藏特性”5種實體類型,共計得到2 040條語料,并完成6類關系標注,包括5種普通關系和未知關系。由于語料中對于“貯藏條件相似”“不可以混合貯藏”2類關系的知識較少,即與其他關系類型數據分布不均衡,故采取數據增強的方法來彌補相對其他長尾類型關系的影響,共計構建4 063 條語料,關系編碼、各關系數量以及抽取文本示例如表6所示。需要注意的是,其中數據增強獲得的語料僅作為模型訓練數據,而不能作為圖譜構建的知識元。標注語料按照8∶2 的比例劃分訓練集和驗證集,訓練模型中使用的BERT預訓練模型為BERT-Chinese-base,訓練批量大小為32,最大序列長度為128,學習率為3E-5,訓練輪次為30。經過實驗驗證各類關系的評價分數如表7 所示,平均F1 值達到94.14%,分類效果較好。相比于實體識別任務和多元限定關系,普通關系的表述相對單一,文本中常常會出現“具有”“防止”“相類似”“包括”等內容,使得模型學習到的數據特征較為準確。依據評價指標和具體抽取情況表明,利用基于BERT的分類模型抽取效果較好。

表6 普通關系抽取示例Table 6 Examples of common relation extraction
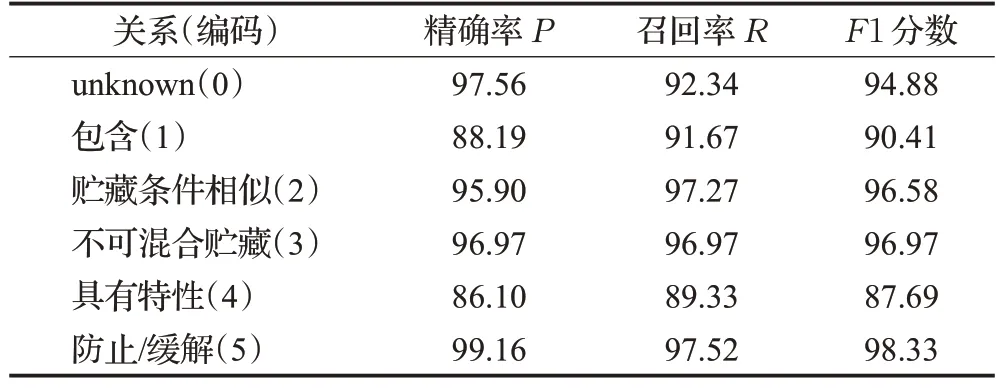
表7 普通關系抽取實驗結果Table 7 Experimental results of common relation extraction單位:%
3.2.3 知識融合
將完成規則抽取和模型抽取的數據分成三元組和多元組兩類,作為本文提出的知識融合方法的輸入項,融合過程中包括食品別名詞典的檢索,向量化相似性比較,多元組集合重疊等。其中構建食品別名詞典采取Scrapy框架爬取相關網站常見的食品別名,共計食品種類為766種,別名數量4 360個,并以json格式存儲以方便算法中字符查找匹配,同時將余弦相似度閾值設置為0.7。經過知識融合方法后獲得高質量實體關系組,完成實體對齊和多元限定關系的冗余消除,融合前后的知識對比效果如表8所示。

表8 知識融合前后示例Table 8 Examples of before and after knowledge fusion
4 知識圖譜可視化和語義檢索
將抽取得到的知識進行合適的存儲與表示是構建知識圖譜的重要環節,本文選取開源圖數據庫Neo4j(neo4j.com)存儲食品貯藏領域知識圖譜。Neo4j 具備處理龐雜數據敏捷和查詢速度快等優勢,同時還具備直觀、易于理解的可視化前端,但在Neo4j 中常常以三元組的形式進行表示。然而本文提出的超節點表示方式可以很好地嵌入到Neo4j當中,從而避免兩兩實體間錯亂復雜的關系表示形式,大大減少關系數據的存儲量。
將相關的各類異構數據資源利用本文的知識圖譜構建框架技術,在Neo4j 數據庫中完成存儲,構建可視化食品貯藏知識圖譜用于各類語義檢索。為了提升存入速度,本文使用Neo4j提供的Py2neo工具包批量導入數據,將抽取完成的數據轉換為csv 格式,使用Node、Relationship 等方法完成實體和關系的創建,同時使用merge方法完成節點與邊的導入。共計導入10 211個實體,普通關系2 697 組,多元限定關系2 419 組。圖9 展示了食品貯藏知識圖譜構建的整體可視化效果,圖10和圖11分別展示具有多元限定關系和普通關系的部分圖譜示例,有效表達出食品不同條件下的貯藏知識和相互之間的關聯關系。
圖9 食品貯藏知識圖譜可視化Fig.9 Visualization of food storage knowledge graph
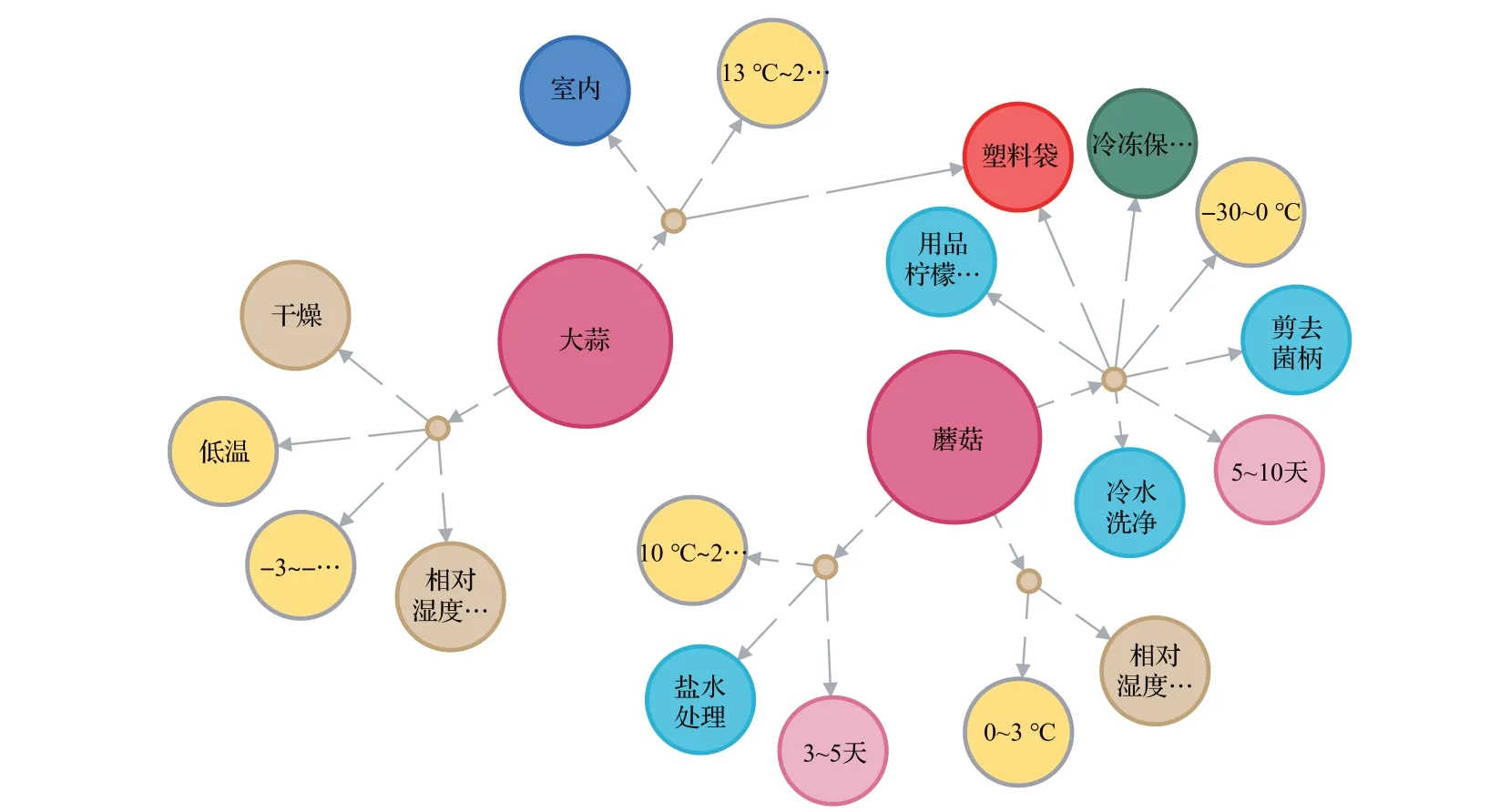
圖10 具有多元限定關系的部分圖譜示例Fig.10 Examples of part of knowledge graph in multi-restricted relation

圖11 具有普通關系的部分圖譜示例Fig.11 Examples of part of knowledge graph in common rela-tion
通過構建的圖譜可視化結構,可以直觀看到“蘋果”與哪些食品不宜貯藏在一起,在哪些貯藏條件下溫度濕度等的不同,具體“蘋果”有哪些品種以及貯藏方式等。為了更精準的語義檢索,可以使用Cypher 語言進行查詢。例如查詢“葡萄”有哪些貯藏特性且適合在什么條件下貯藏,可以通過“match(n:food{name:“葡萄”})-[r1:`具有特性`]->(p)returnn,punion match(n:food{name:“葡萄”})-[r2:` `]->(m)-[r3:` `]->(p)returnn,p”查詢可知“葡萄”較耐貯藏,且適宜在2℃、濕度78%下采取窖藏法貯藏。再者例如查詢如何防止“高粱米”在存儲過程中變味的現象,通過“match(n:food{name:“高粱米”})-[r1:`具有特性`]->(p:bad{name:“變味”})<-[r2:`防止/緩解`]-(q)returnn,p,q”可知貯藏“高粱米”時應該保證“風晾降濕”來防止“變味”“裂紋”。將繁雜的食品貯藏數據通過本文的知識圖譜構建技術形成結構化知識表達,便于知識理解與高效查詢,可以多角度地獲取想要的知識,為后續該領域的相關建設與應用提供幫助。
5 結束語
本文在大數據的社會背景和食品貯藏研究的背景下,針對食品貯藏領域數據海量異構、資源利用率較低和缺乏系統化表示等問題,提出了一套較為完整的食品貯藏知識圖譜構建框架,包含了不同結構不同來源的數據處理方法。本文首先針對領域內數據特點提出了多元關系的表達模式,設計了融合多特征的實體抽取模型和多元關系抽取算法完成知識抽取,其次利用構建的食品別名詞典和相似性匹配算法完成知識融合,然后將形成的結構化知識通過圖數據庫Neo4j 進行存儲和可視化表達。本文分別將技術書籍、科學文獻、網絡文章等作為數據源進行實驗驗證,充分證明了所提出框架的合理性和有效性,為食品貯藏相關研究開辟了新的智能視角,同時也為其他領域數據分析表達和知識圖譜構建提供借鑒。未來將在完善FSKG構建以及自動問答、知識補全等方面開展研究。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
