高校學業文本命名實體識別及數據集構建研究
2023-11-27 05:35:46苑迎春王克儉
計算機工程與應用 2023年22期
何 晨,苑迎春,2,王克儉,2,陶 佳
1.河北農業大學 信息科學與技術學院,河北 保定071001
2.河北省農業大數據重點實驗室,河北 保定071001
教育部2020 年發布的全國教育事業統計結果顯示,全國共有普通高校2 668所,其中本科院校1 265所,全國各類高等教育在校學生總規模達4 002 萬人[1]。高等教育的普及致使出現學業問題的學生數量不斷增多,與高校現有教學管理師資力量出現了極大的不平衡。教育部發布的信息顯示,當前我國高等學校平均每學年因學業等原因退學的本專科學生人數已超過10 萬人,每學年因各種學業問題延期畢業與肄業的學生數量更是居高不下[2]。因此,學業問題成為亟待解決的重要問題。當前,國家修訂了《高等學校學生行為準則》《普通高等學校學生安全教育及管理暫行規定》等一系列規章制度,且全國高校都編撰了具有一定體系的學業管理規定,為大學學業領域進行實體命名識別數據集的構建提供了大量文本數據。
Rau[3]首次提出了命名實體識別任務,作為信息抽取中的基本工作,該技術一直以來得到眾多學者在不同廣度與深度上的關注和研究[4-6]。命名實體識別即文本語義信息挖掘[7],從文本的語義表征層面出發,對上層關系抽取[8]以及領域知識圖譜[9]構建起到了決定性作用,精準的命名實體識別有利于后續工作的順利開展。通過完成實體識別任務,抽取出文本中的關鍵實體,從而有效構建三元組(<頭實體h,關系r,尾實體t>[10])。傳統識別方法主要依賴于大量人工標注構建的手工模版、專家先驗知識構建的詞典和具有統一文本格式所建立的正則表達式開展研究。以隱馬爾可夫(hidden Markov model,HMM)[11]、條件隨機場(conditional random field,CRF)[12]為主流的傳統識別模型,依據統計方法選用最大預測概率進行輸出,其中CRF模型被廣泛使用。隨著深度學習的不斷發展,基于深度學習的文本語義方法作為實體抽取的主流技術被眾多學者引入。長短期記憶(long short-term memory,LSTM)[13]網絡與雙向長短期記憶(bidirectional long short-term memory,BiLSTM)[14]網絡被先后提出。深度學習模型通過文本語言的前后向感知,開展對字詞向量以及位置向量的自動學習,使得面向各行業領域、地域和組織機構等目標的實體識別準確率有了顯著提升。
在教育領域,程哲[15]提出了針對中學某一特定學科的命名實體識別方法,但針對高校學業領域的相關文本信息抽取,目前還未有相關學者進行研究。鑒于當前我國高校大量存在的學業問題,開展面向具有普遍性和通識性的高校學業管理的命名實體識別方法研究變得極為迫切。構建高校學業領域數據集并完成命名實體識別研究,作為構建知識圖譜的首要工作,為實現基于知識圖譜的高校學業智能問答服務研究提供了有效支撐。同時也能輔助學生便捷、高效、自助式完成學業問答,實現學業自我管理,從而順利完成學業。并且可以提升教輔人員解決學生學業問題的效率,減輕工作壓力。高校學業領域與普通領域文本存在很大區別,具體表現在:(1)高校領域中包含大量的專業領域詞匯。(2)相同類別的高校領域實體具有不同表述方式。(3)高校學業實體大多存在實體嵌套特點。(4)在確保最小細粒度類別劃分的情況下,實體的類別標注需要更加精準。
為解決上述問題,本文的主要研究內容為以下四點:(1)收集高校學業管理規定文件,提出一種適用于學業領域的實體分類標準。(2)按照公開數據集NLPCCKQBA 構建高校學業問答文本數據集。(3)將構建后的數據集作為實驗對象,通過公開數據集確定命名實體識別模型,再對分類后的數據集進行測試。(4)評價分類后數據集在命名實體識別主流模型中的表現。
1 高校學業文本數據
本文原始數據取自《中華人民共和國高等教育法》[16]、《國家教育考試違規處理辦法》[17]、《普通高等學校學生管理規定》[18](教育部令第41號)以及某高校普通本科學生專業培養與專業分流實施辦法等(該辦法為適應國家高考制度改革,結合學校實際所制定)。層級上按照普通高等學校學生管理規定劃分為7 個大類,如表1 所示。每一類別分別針對高校和學生做出相應規定,管理規定原始數據樣例如表2所示。

表1 普通高等學校學生管理規定Table 1 Management regulations on students in institutions of higher education

表2 管理規定原始數據樣例Table 2 Raw data samples of management regulations
2 高校學業問答文本原始數據集構建
由于國家出臺的相關管理規定旨在為各高校提供學業管理方向,規定學業管理內容,僅依據國家規定進行高校學業領域數據集構建,不足以表示實際應用情況。本文采用經國家規定、學校章程以及學校實際情況所制定的某高校普通本科學生專業培養與專業分流實施辦法等相關文件作為高校具體實施學業管理規定樣例。該類文件共計13 萬余字,涵蓋學生綜合素質測評辦法、獎勵管理辦法、違紀處分實施辦法等內容,從實際層面詳細制定了高校在校學生的學業管理細則,由此構建的數據集具有實用性和代表性。
NLPCC-KQBA數據集由中國計算機學會(CCF)舉辦的中文信息技術專業委員會年度學術會議發布。該數據集由包含14 609個問答對的訓練集和包含9 870個問答對的測試集組成,并提供一個知識庫,包含6 502 738個實體、587 875個屬性以及43 063 796個三元組。作為命名實體識別通用數據集,本文將高校學業領域相關管理規定和收集到的學業問題仿照NLPCC數據集完成知識庫與問答對的構建,如表3所示。

表3 數據集構建的知識庫和問答對樣例Table 3 Knowledge base and question-answer pair examples constructed from datasets
3 高校學業文本分類與特性分析
通過對高校學業管理規定和在校學生普遍存在的問題進行匯總分析,可知高校學業主要涵蓋領域包括學生日常行課的基本要求、考試形式、學分修讀、學籍異動和專業變動等方面。其中學生對于修讀專業的選課類別、課程重修限制、所學科目考試規定與參加補考要求等最為關注。因此,在滿足國家針對學生培養方案的基本需求上,本文參照學生關注點,融合高校專業學業管理人員的專家知識,對高校學業文本進行命名實體識別的類別劃分。在確保類別不重疊、種類精簡且涵蓋范圍全面的原則下完成劃分,共計分為八大類,分別為考試(EXAM)、課程(C)、選課(CV)、學分(CR)、學籍(STAT)、轉專業(CMJR)、畢業(GRAD)和其他(ELSE)。最終實現以最小粒度為出發點,對學生提出的學業問題文本進行命名實體識別操作。例如問題文本描述為“課程既有理論課又有實驗課,選其中之一可以嗎?”,則將“理論課”“實驗課”均標注為課程(C)實體。表4 為高校學業領域文本命名實體類別與樣例。
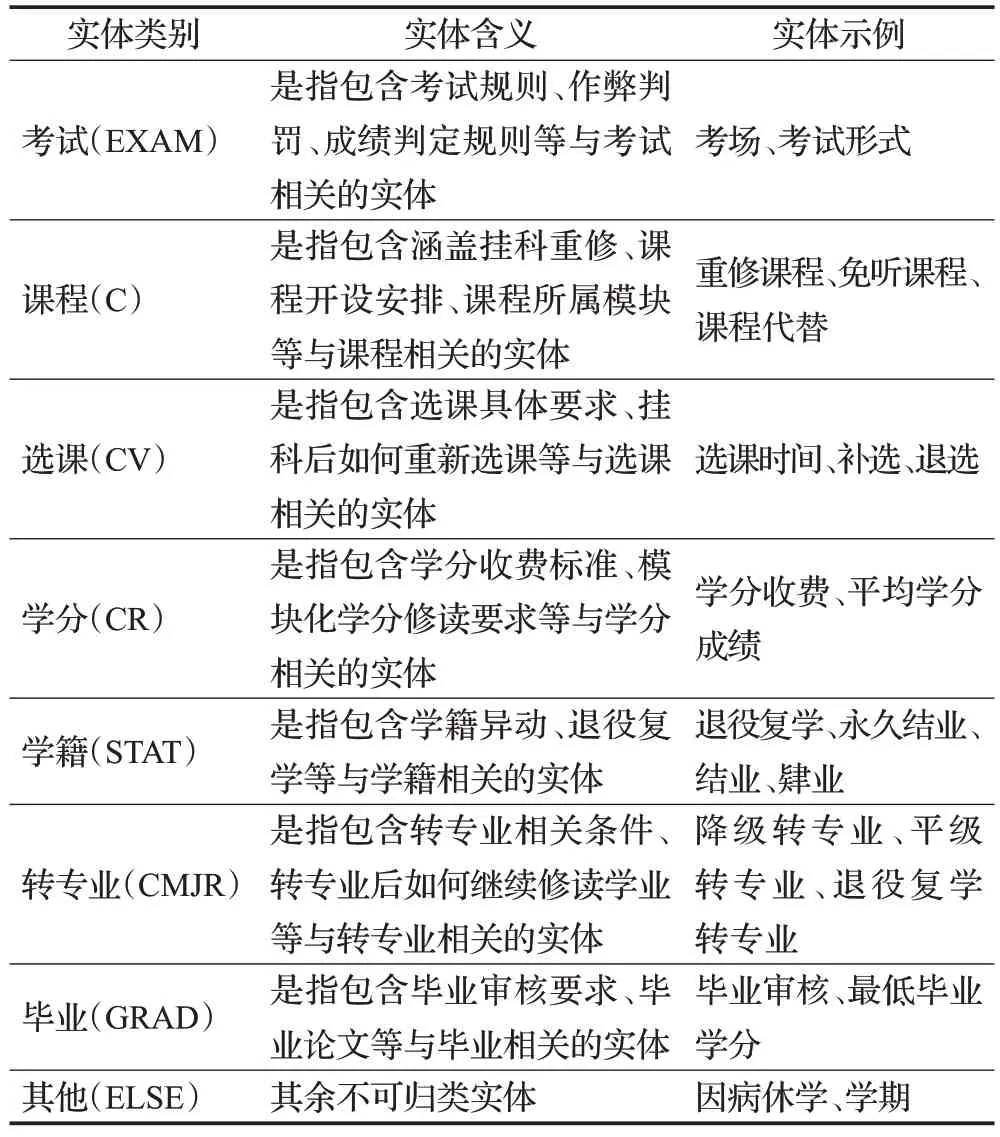
表4 高校學業領域文本命名實體類別與樣例Table 4 Types and examples of text named entity in academic fields of universities
學業領域的命名實體識別目標與通用領域中地點、人物和組織等待識別實體存在較大區別。更是由于面向群體的獨特性以及各高校規范細則存在差異化(以修讀課程編號為例),難以獲取具有較高普遍性的海量實驗語料。上述各命名實體類別還存在獨特的領域特性。
(1)考試(EXAM)類別中,多數的問題文本中不會直接提及名詞“考試”。例如“規定以外的筆或者紙答題或者在試卷規定以外的地方書寫姓名、考號或者以其他方式在答卷上標記信息”這一文本,其所表述含義實為該行為是否會被認定為考試作弊。為保證該領域分類精簡,實體不再被繼續劃分為“作弊”類別,本文依靠深度學習模型準確識別問題文本語義,確保表述實體識別時實現正確標注并分類。
(2)名詞因該領域獨特性,在不同語句中充當的成分不同會影響命名實體識別的最終標注結果。例如“退役復學哪些課程免修?”中的“退役復學”作為課程免修的限制性條件,并非為構成三元組的實體組成部分。而在“退役復學轉專業有條件限制嗎?”中的“退役復學轉專業”可識別為一個實體,且應將其歸為轉專業(CMJR)類。
(3)學生在進行提問時,大多問題會包含多個相同類別的實體。例如“畢業審核通過,但是畢業設計或者畢業實習不合格怎么辦?”中包含“畢業設計”與“畢業實習”兩個待識別實體,且該問題應構成的三元組形式為<畢業設計 畢業實習,不合格,無法順利畢業>。因此,只有合理抽取出實體才可以正確構造所需的三元組,使得問題的回答合理有效,并構建出無誤的高校學業領域知識圖譜。
由此可見,高校學業領域的命名實體識別包含眾多的專業名詞、不明確指向性實體以及涉及到上下文位置關聯性實體。對實體合理地進行類別劃分,并結合專家的先驗知識進行實體數據集的標注與構造,可為順利開展高校學業領域文本命名實體識別工作提供有力支撐。
4 高校學業領域實驗數據集構建
在高校學業實驗語料處理方面,如上所述,本次處理結合教育部《普通高等學校本科專業類教學質量國家標準》規定以及學業管理領域專家的意見,合理按照實體類別劃分標準將自建專業領域實驗語料進行實體標注。整體采用了BIO標注策略,結合所提出的語料標簽設置完成標注工作。以實體類別“考試”為例,與考試內容相關實體的開始部分以“B-EXAM”表示,剩余實體內容標注為“I-EXAM”,句中其余成分均標注為“O”。高校學業領域實驗語料標簽設置情況如表5所示。
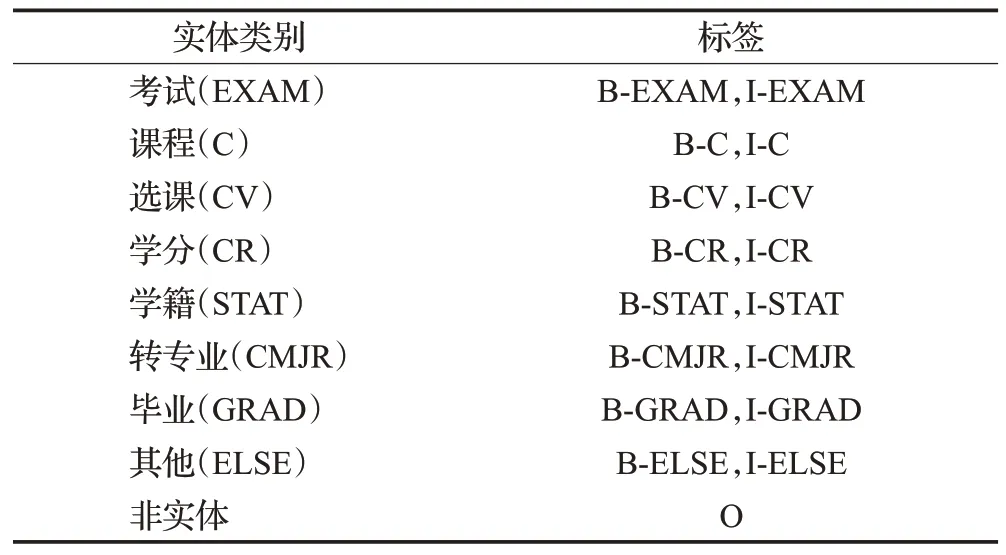
表5 高校學業領域實驗語料標簽設置Table 5 Label setting of experimental corpus in academic field of universities
引用高校學業問答原始數據集文本即表3 中原始問句樣例,舉例說明命名實體識別數據集進行人工標注的過程。樣例問句內容為“選課的學分限制是什么?”,參照NLPCC-KQBA 公開數據集格式標準進行標注,具體標注格式如表6所示。

表6 NLPCC-KQBA數據集標注格式Table 6 Annotation format of NLPCC-KQBA dataset
根據表6 公開數據集標注格式以及本文提出的高校學業領域文本分類標準,同專業學業管理人員確定文本所包含實體并進行相應標注工作。按照表5所示標簽完成所有高校領域文本標注工作,標注后的數據如表7所示。

表7 高校學業領域標注后數據集Table 7 Annotated dataset in academic field of universities
5 實驗
5.1 實驗環境與參數設置
實驗采用3.8.5版本的Python編程語言,分別對公開數據集NLPCC-ICCPOL 2016 KQBA、NLPCC-ICCPOL 2018 KQBA和實驗數據集進行對比實驗。所有實驗程序均部署于配置為i7-10700 CPU、16 GB內存、NVIDIA GeForce RTX 3060 12 GB顯卡、1 TB硬盤并安裝Windows 10操作系統的主機上。
首先驗證BiLSTM-CRF模型的命名實體識別效果,分別選用了機器學習方法的HMM 和CRF 模型以及深度學習方法的BiLSTM 模型進行對比實驗。該實驗在NLPCC-ICCPOL 2016 KQBA 與NLPCC-ICCPOL 2018 KQBA公開數據集上進行,展現BiLSTM模型的雙向長短期特征提取的優勢和命名實體識別的穩定性,以及同CRF 模型組合后的整體性能。然后將該模型運用到實驗數據集進行命名實體識別實驗,證明本文構建的高校學業領域數據集的可用性。
實驗中BiLSTM模型的訓練參數設置分別為:學習速率lr為0.001,epoch 迭代次數為100 次,詞向量維數為128,隱向量維數為128。CRF 模型中L1 正則化系數與L2正則化系數均為0.1,最大迭代次數為100次。
實驗結果采用評價指標分別為準確率(precision,P)、召回率(recall,R)和F1值(F1-score)三個常用指標。準確率為實體被正確識別個數與識別實體總個數的比值,召回率為正確識別實體個數與測試集合中實體總數比值,F1 值為準確率與召回率的調和平均數。通過上述三個指標來體現模型的命名實體識別性能。
5.2 實驗結果與分析
本文共進行了三組對比實驗,分別開展了HMM、CRF、BiLSTM 和BiLSTM-CRF 四種模型在NLPCCICCPOL 2016 KQBA、NLPCC-ICCPOL 2018 KQBA公開數據集中命名實體識別的效果分析,四種模型在未分類下的高校學業文本數據集中命名實體識別的適用性分析,四種模型針對分類標注后數據集中命名實體識別的效果分析。
(1)各模型對公開數據集的對比實驗
表8為無預訓練下面向NLPCC-ICCPOL 2016 KQBA和NLPCC-ICCPOL 2018 KQBA公開數據集,分別進行機器學習命名實體識別方法與深度學習命名實體識別方法的對比結果。由所得數據可知,將CRF模型與BiLSTM模型結合后,在開放領域的準確率、召回率和F1 值三個評價指標對比命名實體識別效果均優于其他模型,具有更強的識別能力。因此,BiLSTM-CRF模型的識別效果可有效說明本文構建的高校學業數據集是否合理有效。
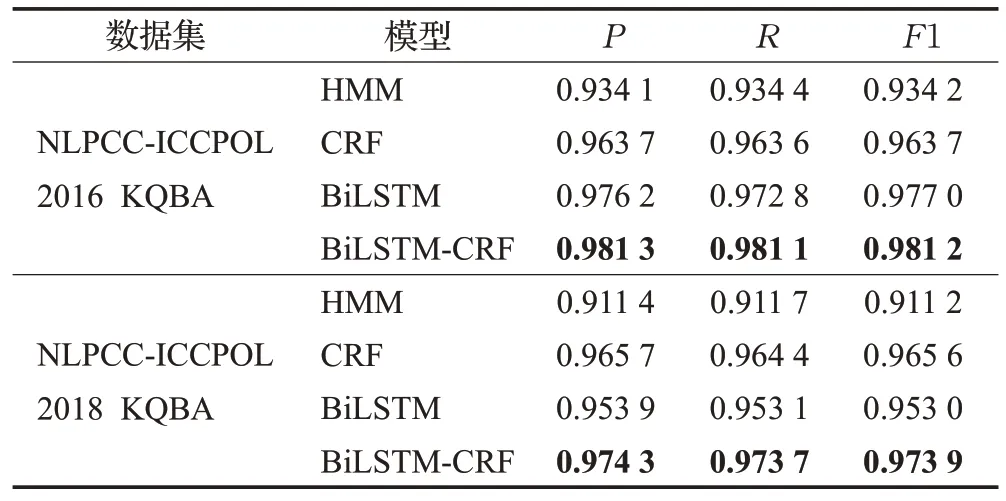
表8 NLPCC語料下不同模型對比實驗結果Table 8 Results of experiments comparison of different models with NLPCC corpus
為確保對比實驗的公平性,機器學習命名實體識別方法CRF的最大迭代次數與深度學習命名實體識別方法BiLSTM 的epoch 均設定為100 次。由實驗數據可知,HMM模型的識別效果較差,綜合評價指標F1 分別僅達到了93.42%、91.12%。其原因是隱馬爾可夫模型存在兩個假設:一是輸出的觀測之間是嚴格獨立的;二是狀態的轉移只與當前狀態的前一狀態有關。其無法將待標注文本信息有效結合,單一地限定在了狀態與觀測值之間。而CRF 模型在HMM 模型的基礎上進行了改善,合理引入了全局概率,且該模型在歸一化操作時也從局部面向了整體。因此,在機器學習模型上CRF模型較HMM 模型的性能得到有效提升。基于深度學習神經網絡的BiLSTM 模型為該領域的主流模型,在LSTM 模型的基礎上通過雙向對文本字符序列進行學習,相較機器學習中的模型CRF 仍存在一定的提升空間。對兩種不同類型的方法進行有效結合后,分別利用BiLSTM 模型的雙向學習能力和CRF 模型對標注的全局性優勢,在各項評價指標上均達到了較優的實體命名識別效果,實體命名識別的準確率在NLPCC-ICCPOL 2018 KQBA 上達到了97.43%,相較單一BiLSTM 模型提升了2.1%。
(2)各模型對學業領域數據集的對比實驗
將構建完成的高校學業問答文本進行了十折交叉驗證實驗,將其隨機分成10 份,每次選擇9 份作為訓練集,剩余1 份作為測試集進行HMM、CRF、BiLSTM 和BiLSTM-CRF模型的對比實驗。表9為對比實驗結果,其中加粗部分為每份測試集下準確率與F1 值最優結果。
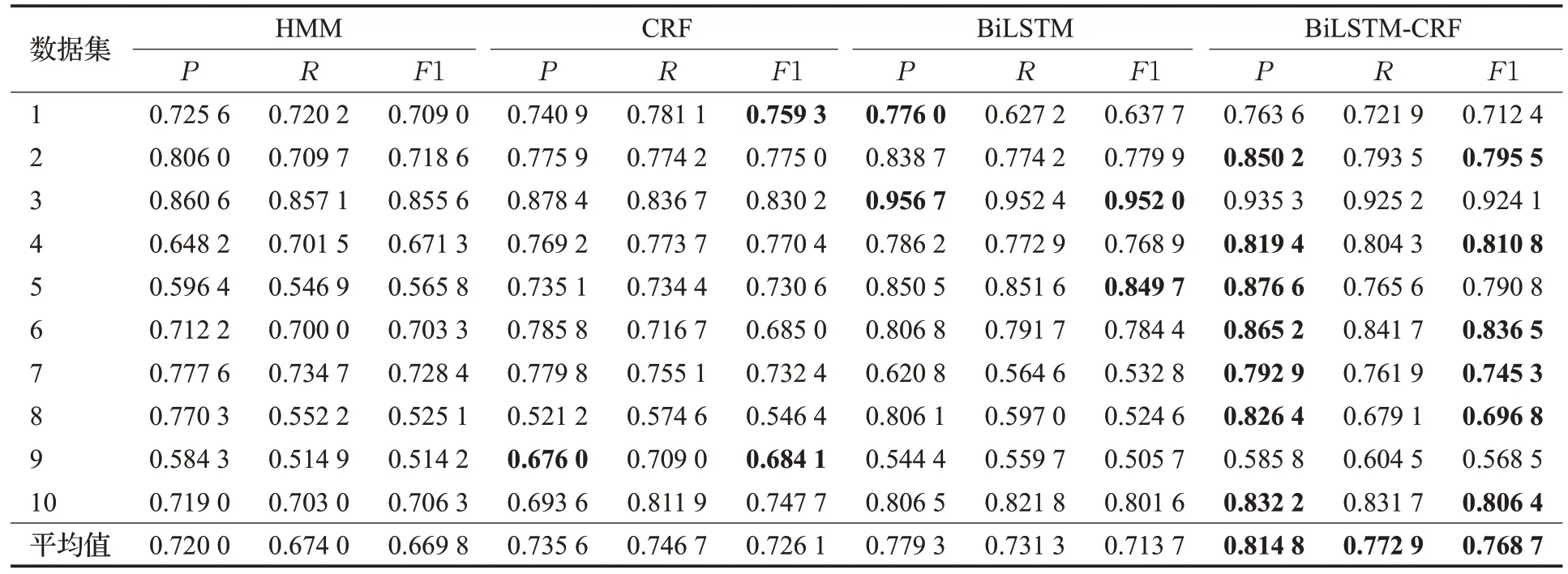
表9 高校學業問答數據集下各模型對比實驗Table 9 Comparative experiment of various models for college academic question answering datasets
由于對比實驗文本發生調整,對參與訓練的BiLSTM模型參數進行微調,學習率調升至0.005,且為避免過擬合,將迭代次數修改為50 次。根據上述實驗結果分析可知,在該領域BiLSTM仍可有效利用雙向長短期提取特性的獨特優勢學習領域文本中所包含的專業術語。但因存在實體嵌套等問題,相較機器學習模型,F1 值提升范圍僅保持在5%~10%之間。通過CRF 模型的輔助后,整體模型將F1 值平均提升了6.55%。通過對比各命名實體識別模型在同一數據集下進行十折交叉驗證實驗的結果中F1 值的平均值和方差可知,BiLSTM-CRF模型的整體識別效果優于其他模型,識別不具有偶然性。HMM 模型與CRF 模型在命名實體識別時并不對訓練集進行有效學習,僅憑借其前向算法或全局特性對測試集進行實體標注。同時也說明了BiLSTM-CRF 模型在該領域的實體命名識別上較為穩定,具有更佳的綜合識別效果。
(3)各模型對不同類別命名實體識別對比實驗
為更好地進一步驗證經分類后所構建的高校學業命名實體識別數據集效果,根據表9 實驗結果,選取該模型識別效果最優數據集完成分類標注。對各模型進行不同類別命名實體識別的對比實驗,表10 為對比實驗結果。

表10 各模型對不同類別命名實體識別實驗的F1 值對比Table 10 Comparison of F1 values of each model for different types of named entity recognition experiments
如上文所述,學生對“學分”領域、“轉專業”領域以及“選課”領域提問相對較多,故CR 實體、CV 實體和CMJR 實體在文本中大量存在。且該類別實體大部分包含相同內容,例如“最低畢業學分”與“平均學分成績”兩實體均包含學分字樣,在雙向循環網絡中通過模型對實體上下文順序特征的有效學習,會更好地提取文本特征。因此,在本實驗中對CR 實體進行命名實體識別時具有最佳的F1 值。
在包含C 實體的文本中,不僅存在中文文本實體,還存在以課程編號為待識別實體文本。例如,“課程號是BL1623000S 和BY1623000 兩種都是實驗課,兩者有何區別?”問題中,存在“BL1623000S”與“BY1623000”兩實體。該類別實體的組成會存在更細粒度元素,使得命名實體識別難度增大。因此在所有模型中C 實體的評價指標F1 值相較其他實體識別結果偏低。
CMJR 實體是針對轉專業領域構建的實體,CV 實體是針對選課領域構建的實體。由于轉專業后的學生大多需要重新進行選課,二者實體會更為頻繁地出現在同一識別文本中,且部分實體還存在實體嵌套關系。針對此類實體需對學生問題進行合理分析,判別嵌套實體在語義層面應如何標注。BiLSTM-CRF 模型通過詞語在句中的前后順序,可更好地捕捉句間的字詞距離的依賴關系。對比模型HMM與CRF,本文方法在該類別進行命名實體識別時F1 值提升了5%左右,達到了91%以上。
(4)深度模型時間性能對比
對基準模型BiLSTM 與組合模型BiLSTM-CRF 分別在未分類下BIO 標注的高校學業數據集和經過專家先驗知識標注后的高校學業數據集上耗費的訓練時間進行分析,檢測模型的時間性能。使用訓練過程中的最后一個epoch所花費時間,進行時間性能對比。由表11實驗結果可知,經過分類標注后的數據集,BiLSTM 模型耗費時間提升了40%,BiLSTM-CRF耗費時間提升了32%,而實體識別的精準率提升了9%。實驗結果證明了組合模型BiLSTM-CRF通過較低的時間成本,有效地提升了實體的識別效果。

表11 不同數據集下深度模型訓練時間Table 11 Deep model training time for different datasets
6 結束語
高校學業文本的命名實體識別可以幫助教輔工作人員快速便捷地提取學生所存在問題的關鍵信息,緩解教學工作帶來的壓力,同時也為高校學業領域知識圖譜的構建以及智能問答系統的研發奠定了基礎,從而實現學生學業困惑的自助檢索,并提升精準度和查詢效率。本文提出一種高校學業文本命名實體識別數據集的構造方法,針對領域特性結合專家先驗知識給出了實體分類標準,并依據該標準仿照公開數據集格式完成分類標注。在確保涵蓋內容全面以及實體細粒度劃分合理的標準下,共包含8 類實體關系,可應用于高等學校學業領域的命名實體識別任務。
本文首先在公開數據集驗證了BiLSTM-CRF 等4種識別模型的有效性,之后通過選用模型證明了所構建的高校學業文本原始數據集可以為命名實體識別任務提供實驗數據。各模型在分類標注后數據集上的標注效果,證明了本文提出的分類標準與構造方法具有普遍性與實用性,為構建高校學業領域知識圖譜的命名實體識別任務做出了貢獻,響應了教育部信息技術與教育教學相融合的號召,為智能化高校教育開展打下了堅實基礎。
本文的研究重點放在了高校學業文本命名實體識別的數據集構建方面,且標注范圍僅針對學生日常出現的問題以及工作積累的學業問題,可能存在學業領域內細小問題未涉及等情況,未來還需不斷細化完善該工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
