面向神經(jīng)網(wǎng)絡(luò)池化層的靈活高效硬件設(shè)計
2023-11-27 05:35:46朱國權(quán)岳克強
計算機工程與應用 2023年22期
何 增,朱國權(quán),岳克強
1.杭州電子科技大學 電子信息學院,杭州310018
2.之江實驗室 智能計算硬件研究中心,杭州311100
近年來,在語音識別[1]、自然語言處理[2]和目標檢測等領(lǐng)域[3]中,卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)的貢獻是十分巨大的。不同卷積神經(jīng)網(wǎng)絡(luò)中,大多數(shù)網(wǎng)絡(luò)都需要池化層來降低卷積層輸出的特征向量。
對于池化層,研究者們提出了許多硬件方案:陳浩敏等人[4]基于YOLOv3-tiny的硬件加速設(shè)計中池化層輸入圖像最大可支持416,但僅支持核大小為2×2 的池化。許杰等人[5]設(shè)計的cifar10_quick 優(yōu)化網(wǎng)絡(luò),采取兩兩比較的層間流水實現(xiàn)核2×2的池化,該方法無任何數(shù)據(jù)復用,因此在重疊池化中性能較低。Cho 等人[6]的卷積神經(jīng)網(wǎng)絡(luò)加速器使用HLS(high-level synthesis)設(shè)計,HLS 綜合后采取狀態(tài)機控制運行流程,資源使用量較低,但無法完全發(fā)揮硬件設(shè)計加速器的性能優(yōu)勢。王肖等人[7]在可重構(gòu)卷積神經(jīng)網(wǎng)絡(luò)加速器中設(shè)計的核為3×3,步長為2 的池化使用臨時緩存保存上一層卷積數(shù)據(jù)并逐一比較,該臨時緩存根據(jù)池化核滑行需重復讀取池化核最后一列數(shù)據(jù),其數(shù)據(jù)的讀取復用卷積資源,但池化窗口滑行中的數(shù)據(jù)依然沒有復用。
上述方案,從不同程度上反映出以下問題:眾多池化的參數(shù)差異使得各自的池化設(shè)計僵化,兼容性低;在重疊池化中,數(shù)據(jù)復用[8]程度低,影響了性能。
本文旨在克服上述不足,提出了面向神經(jīng)網(wǎng)絡(luò)池化層的靈活高效硬件設(shè)計。本設(shè)計結(jié)合行緩存與二維拆分提高了兼容性,并且憑借數(shù)據(jù)全復用提高性能。為了驗證該設(shè)計的功能與性能,本文將在LeNet-5[9]、AlexNet[9]、ZFNet[10]、GoogleNet[11]、MobileNet[12]、DenseNet[13]、YOLOv4[14]、YOLOv5[15]和YOLOv6[16]等網(wǎng)絡(luò)中,與CPU 和文獻[17]的方案進行實驗。
通過FPGA(field programmable gate array)實現(xiàn)網(wǎng)絡(luò)加速器以Verilog HDL 與HLS 為主,而使用HLS設(shè)計在工程細節(jié)上的優(yōu)化不如Verilog HDL。Verilog HDL自頂向下的設(shè)計方法幫助設(shè)計者了解整體結(jié)構(gòu)與各模塊間的聯(lián)結(jié),利于進一步地調(diào)試與優(yōu)化,故本文采用Verilog HDL來設(shè)計靈活高效的池化層。
1 池化層介紹
池化層本質(zhì)上是一種下采樣,是卷積神經(jīng)網(wǎng)絡(luò)的一個重要組成部分。池化是對信息進行抽象的過程,卷積神經(jīng)網(wǎng)絡(luò)的信息量巨大,池化作用于卷積神經(jīng)網(wǎng)絡(luò),擴大了感受野,降低了參數(shù)量,控制了過擬合,提高了網(wǎng)絡(luò)魯棒性。池化示意圖如圖1所示。
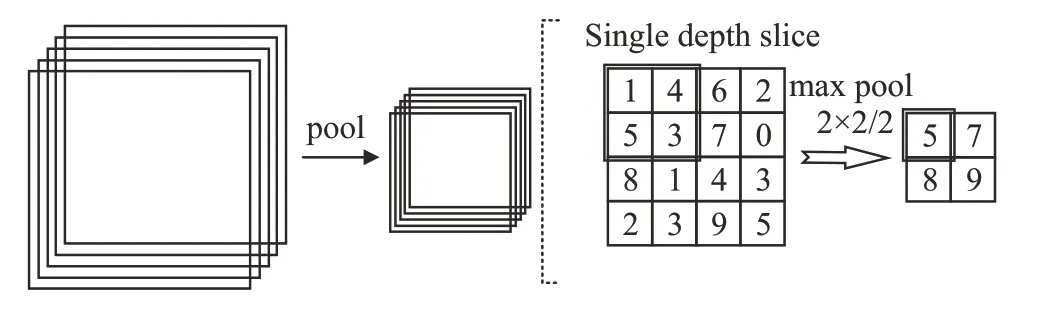
圖1 池化示意圖Fig.1 Diagram of pooling
池化按池化方法可以分為平均池化、最大池化和最小池化;根據(jù)池化核與步長關(guān)系可分為非重疊池化與重疊池化。LeNet-5 的池化層,輸入圖像28,池化核為2,步長為2,為無重疊池化,其設(shè)計無需考慮數(shù)據(jù)復用;YOLOv3-tiny 的池化層,其輸入特征圖需要支持416 的數(shù)據(jù)輸入;YOLOv5 對池化層需要支持池化核13,且步長小于池化核,屬于重疊池化,需要same處理模式。
一般情況下,池化層的設(shè)計均針對特定網(wǎng)絡(luò)獨立設(shè)計,這樣的設(shè)計會導致兼容性差,故對于池化層提高兼容性設(shè)計是十分必要的。傳統(tǒng)的池化方案均為取出池化核所需數(shù)據(jù)進行逐一比較得出結(jié)果,不存在或僅做到少許的數(shù)據(jù)復用,導致池化層的性能低下。本文實現(xiàn)數(shù)據(jù)的全復用,兼顧性能的同時也具備靈活通用性。
2 池化層設(shè)計
2.1 池化層設(shè)計流程
本文提出的靈活高效池化層設(shè)計主要包含控制模塊、參數(shù)配置、通道使能、端口選擇、數(shù)據(jù)緩存和數(shù)據(jù)處理。本文提出的池化層架構(gòu)如圖2所示。
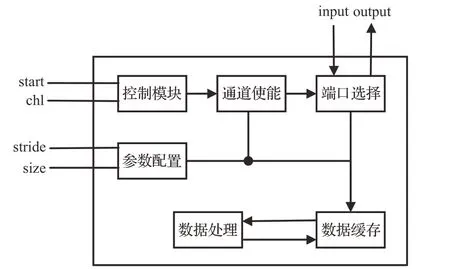
圖2 池化層架構(gòu)Fig.2 Pooling layer architecture
結(jié)合以上池化層架構(gòu),運行流程如圖3所示。
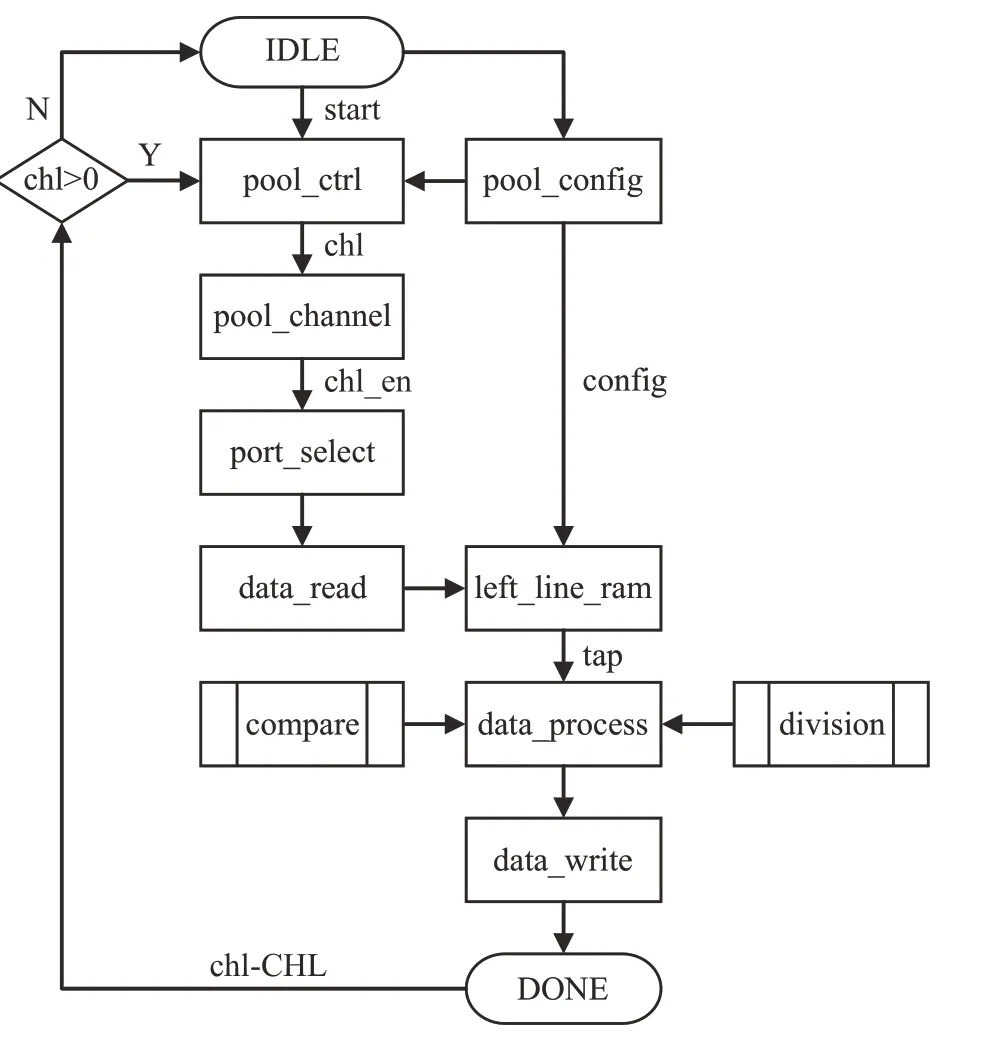
圖3 池化層運行流程Fig.3 Pooling layer running process
參數(shù)配置模塊用于初始化配置參數(shù)的接收與預處理,所有參數(shù)輸入后均進行打拍處理以減少后續(xù)組合邏輯長度,預處理后的參數(shù)傳遞給通道使能、端口選擇與數(shù)據(jù)緩存。
控制模塊接收start 信號與每輪池化結(jié)束后的通道信號,使用三段式狀態(tài)機對當前運行狀態(tài)進行識別并輸出本次實際運行的通道數(shù)chl。
通道使能接收控制模塊提供通道數(shù)chl生成使能信號,后續(xù)處理模塊均基于通道使能的使能信號進一步運行。
端口選擇作為池化模塊對外接口可以自由選擇相連的內(nèi)存組作為輸入還是輸出,滿足不同需求,實現(xiàn)乒乓處理機制。
數(shù)據(jù)處理從數(shù)據(jù)緩存接收tap 數(shù)據(jù),進一步判定是否形成窗口并進行進一步處理,其中包括最大池化、平均池化和最小池化可供選擇。數(shù)據(jù)可支持有符號數(shù)據(jù)處理,數(shù)據(jù)處理中的比較均采取三級流水線的多數(shù)據(jù)遞進比較形式,平均則采取累加-緩存-除法三級流水線形式,均在保障性能的同時也確保時序準確。
數(shù)據(jù)緩存提供讀寫時序控制,同時作為中間數(shù)據(jù)的緩沖輸出tap 給數(shù)據(jù)處理,配合池化機制實現(xiàn)數(shù)據(jù)高效復用,提升整體性能。最終數(shù)據(jù)處理將結(jié)果輸出于目標內(nèi)存,完成一輪池化。一輪池化結(jié)束后,傳遞當前狀態(tài)于控制模塊,進一步判斷是否需要進行下一輪池化。
2.2 主要設(shè)計方案
2.2.1 左移行緩存器
借鑒并結(jié)合行緩存器與移位寄存器的特點,并區(qū)別于FIFO,對緩存器數(shù)據(jù)行首進行輸出;使用該方案可實現(xiàn)池化核移動進程中數(shù)據(jù)全復用,從而提高處理速度。左移行緩存器運行示意圖如圖4所示。
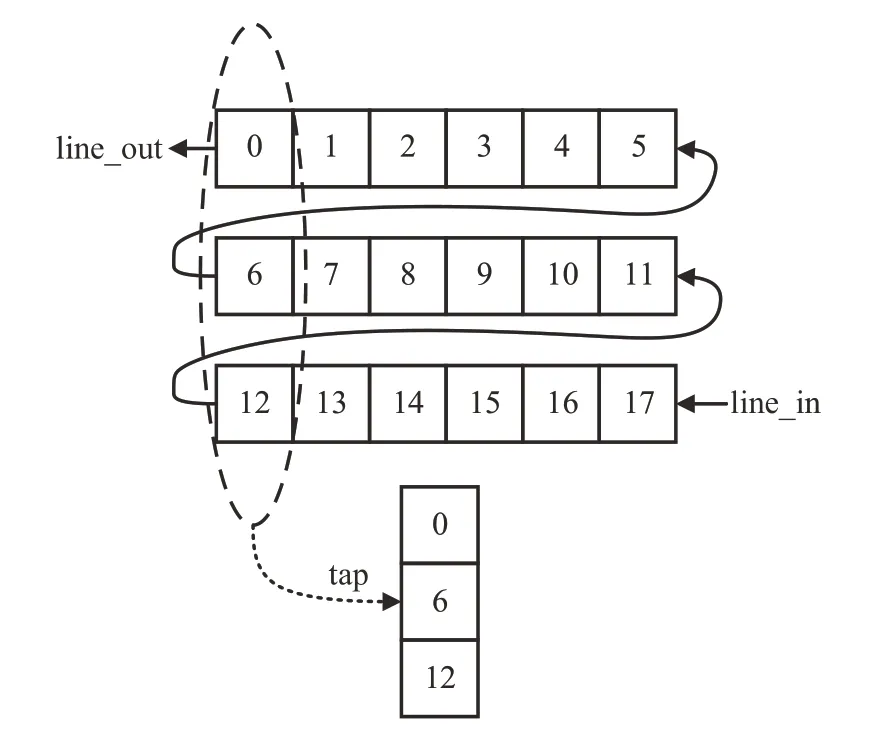
圖4 左移行緩存器示意圖Fig.4 Left transition cache schematic
左移行緩存器具備傳統(tǒng)行緩存器的數(shù)據(jù)緩存功能,基于此輸出行首十分貼合池化核滑行規(guī)則,為后續(xù)多數(shù)據(jù)遞進比較奠定基礎(chǔ)。
2.2.2 多數(shù)據(jù)遞進比較
池化核滑行中,先對二維的池化核數(shù)據(jù)進行橫向與縱向拆分,將其拆分為一維向量,基于左移行緩存器輸出的行首數(shù)據(jù)作為池化核列向量,經(jīng)過一次多數(shù)據(jù)遞進比較,比較后數(shù)據(jù)稱為一級比較數(shù)據(jù)。對一級比較數(shù)據(jù)進行緩存,循環(huán)一定次數(shù)后,當一級比較數(shù)據(jù)形成池化核的行向量時,再進行一次多數(shù)據(jù)遞進比較即可得到最終結(jié)果。整體拆分運行過程如圖5所示。
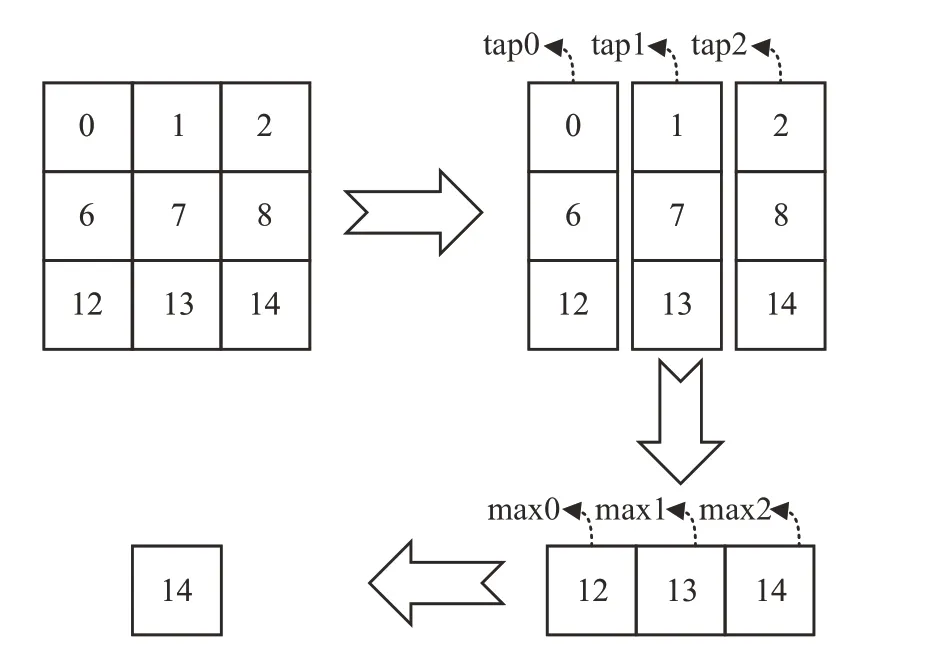
圖5 二維拆分運算Fig.5 Two dimensional split operation
本文結(jié)合上述二維拆分并采用多數(shù)據(jù)遞進比較方法(如圖6 所示),比較模塊呈二叉樹展開,對比較方案歸一化,無需針對不同大小的池化核而采取不同的比較方式,且較傳統(tǒng)比較方法,可減少比較次數(shù),提高性能。
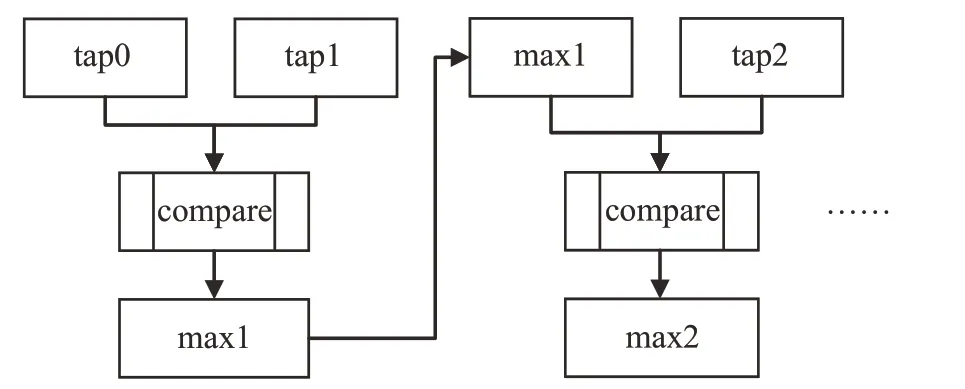
圖6 多數(shù)據(jù)遞進比較Fig.6 Multi-data progressive comparison
2.2.3 乒乓處理機制
乒乓處理機制應用于數(shù)據(jù)流控制,不同時刻可以選擇不同內(nèi)存組作為輸入。
乒乓處理機制主要由端口選擇模塊實現(xiàn),基于地址首位判斷輸入內(nèi)存組。乒乓處理機制根據(jù)不同時間節(jié)點可以分為層間乒乓或?qū)觾?nèi)乒乓,均在兩個不同時刻交換作為輸入。層間乒乓指上層輸出可作為下層輸入,兩組內(nèi)存組相互交換輸入與輸出;層內(nèi)乒乓當特征圖過大或其他原因分布在兩個內(nèi)存組內(nèi)時,可隨時切換內(nèi)存組作為輸入。乒乓處理示意圖如圖7所示。
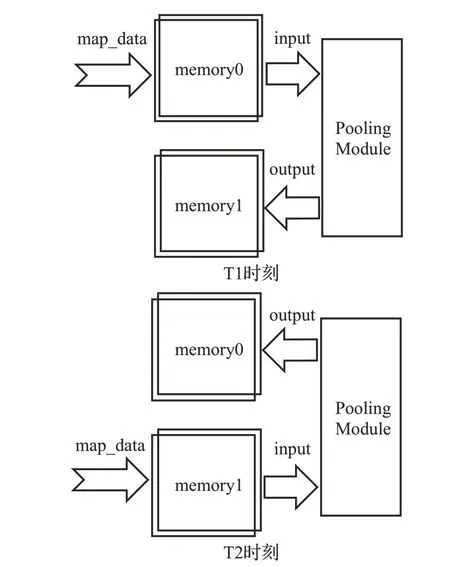
圖7 乒乓處理機制Fig.7 Ping-pong processing mechanism
乒乓處理依據(jù)池化層所處網(wǎng)絡(luò)位置與現(xiàn)場內(nèi)存組使用情況,指定內(nèi)存組作為池化模塊的輸入或輸出,提高現(xiàn)場自適應能力。
2.2.4 same模式支持
池化層窗口滑行分為valid 與same 模式,兩者的滑行主要區(qū)別在于:窗口滑行至行尾,當行尾剩余數(shù)據(jù)寬度小于核大小時,valid模式將舍棄該數(shù)據(jù)進入下一行,same模式將利用padding補充數(shù)據(jù)并進一步計算。故而同參數(shù)下兩者輸出圖像大小可能不同,公式如下所示。
valid模式:
same模式:
在一些特定應用環(huán)境中,例如GoogleNet和YOLOv5等網(wǎng)絡(luò)中,會對池化層有same處理模式的需求,本設(shè)計同樣支持same模式。
same模式需要padding支持。傳統(tǒng)padding采用填0實現(xiàn),會影響比較與平均計算的結(jié)果,并造成資源的浪費。本設(shè)計中的padding 采取偽填充,不針對輸入圖像進行填充,而是自適應改變滑行中的池化核尺寸,從而實現(xiàn)填充后的效果。same模式如圖8所示,實線框為實際自適應后的池化核,填充可選擇左上或右下進行,或者整圈進行。偽填充的same 模式,可省去填充所需的預留硬件資源,較大程度地減少了資源使用量;自適應變化滑行中的池化核較傳統(tǒng)same減少了特征圖四周的處理數(shù)據(jù),提高了same模式的性能。
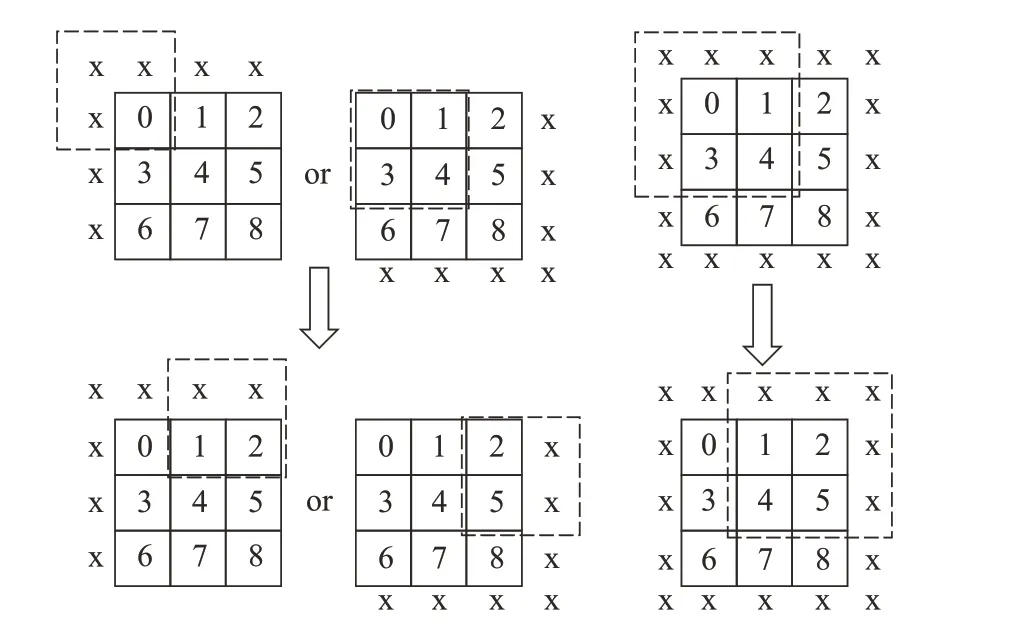
圖8 same模式Fig.8 Same mode
2.2.5 池化核延伸
本設(shè)計同時具備池化核延伸功能。利用拆分機制并契合池化核滑行原理,使同等資源實現(xiàn)更大的池化核配置成為可能。
池化核的拆分機理與滑行過程如圖9 所示,將8×8的大池化核等分為4個4×4的小池化核,再結(jié)合本文的池化核滑行原理,以小池化核為實際滑行的池化核進行運算,并對第一行池化核運算結(jié)果進行緩存,當池化核滑行至下半部分并得出結(jié)果時,與上半部分進行比對,最終得出拆分后形成的2×2池化核的結(jié)果。
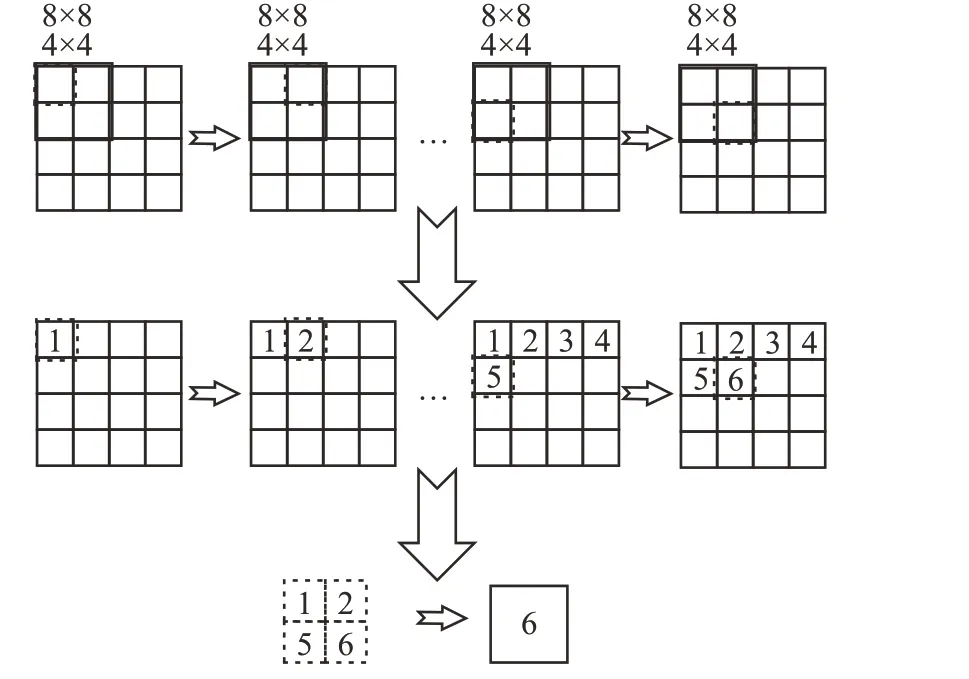
圖9 池化核延伸Fig.9 Pooling nuclei extend
池化核延伸功能在運行大池化核池化時可節(jié)約大量資源,但也有局限性:(1)池化核滑行中大小不發(fā)生改變,故大池化核的拆分僅支持4等分;(2)由于未添加多余的行或列緩存,不支持池化核的重疊,池化核的滑行步長需大于等于小池化核尺寸。
3 實驗結(jié)果與分析
3.1 硬件實現(xiàn)
本設(shè)計使用Verilog 硬件描述語言實現(xiàn),最終代碼通 過Synopsys 的spyglass 與Design Compiler 工具進行檢查。創(chuàng)建UVM 驗證環(huán)境對該設(shè)計進行功能驗證,其中用于實驗的DUT 如圖10 所示,采用64 通道并行,時鐘為200 MHz。
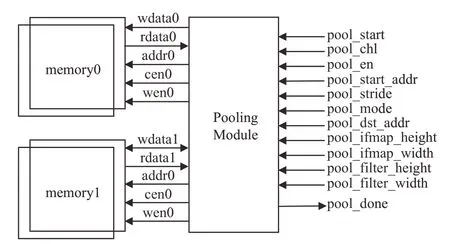
圖10 池化層設(shè)計Fig.10 Pooling layer design
3.2 實驗結(jié)果
實驗平臺配置為64核CPU(AMD TR Pro 3995WX),基于不同CNN 網(wǎng)絡(luò)的池化層作為數(shù)據(jù)集進行對比實驗。對比設(shè)計為基于CPU的Python實現(xiàn),基于文獻[17]、文獻[18]思路設(shè)計的仿制實現(xiàn)。記錄不同網(wǎng)絡(luò)所需不同池化參數(shù)配置進行對比,記錄文獻[17]、文獻[18]與本文DUT運行時間和加速比,如表1所示。
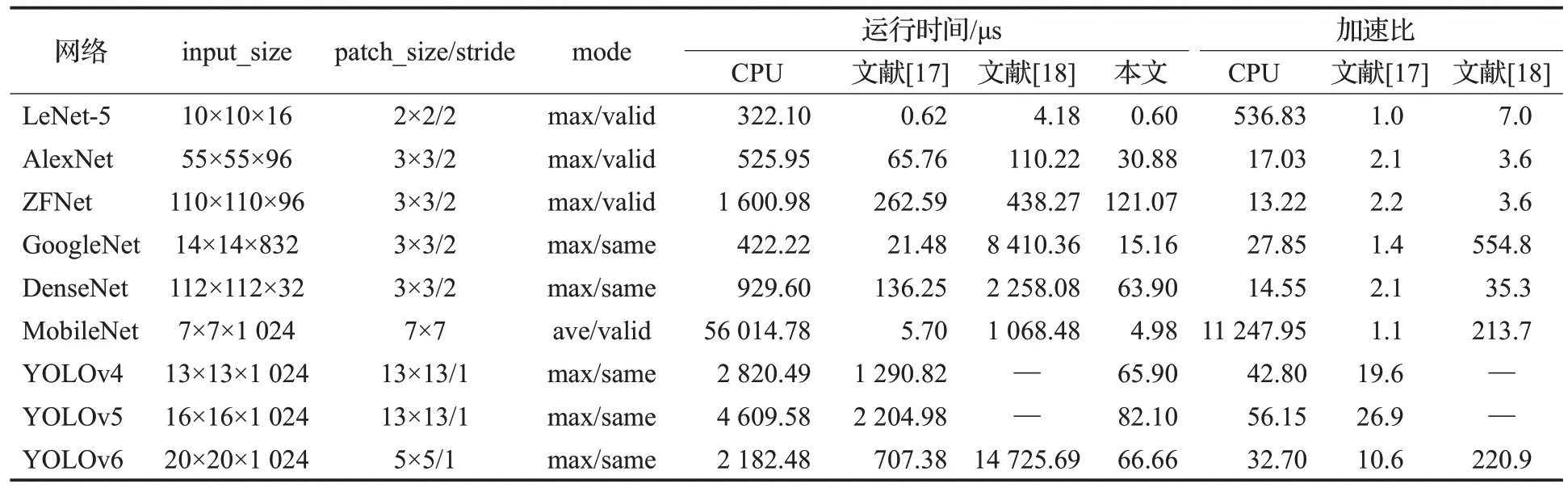
表1 不同參數(shù)下的性能對比Table 1 Performance comparison under different parameters
文獻[17]提出了一種專用的卷積神經(jīng)網(wǎng)絡(luò)加速器,針對LeNet-5網(wǎng)絡(luò)結(jié)合RISC-V聯(lián)結(jié)各算子層進行加速,其加速器中的池化層采取數(shù)據(jù)不復用方案,即根據(jù)池化核所在位置取出特征圖對應數(shù)據(jù)進行處理;文獻[18]提出了可實現(xiàn)時分復用的CNN 卷積層和池化層IP 核設(shè)計,針對LeNet-5網(wǎng)絡(luò)結(jié)合HLS設(shè)計通過5層嵌套for循環(huán)實現(xiàn)。與本文的工作相比,在資源方面,文獻[17]的池化設(shè)計方案略占優(yōu)勢,文獻[18]池化核小于3 的最大池化略有優(yōu)勢;但本文采取數(shù)據(jù)全復用的方案設(shè)計,不僅支持所有池化類型,且在重疊池化中,較文獻[17]和文獻[18]有更明顯的加速效果。文獻[17]和文獻[18]中池化層設(shè)計思路僅適用LeNet-5 且無單獨實驗數(shù)據(jù),此處按其設(shè)計思路進行擴展制定相應的對比方案進行比對。其中文獻[18]嵌套for 實現(xiàn)核為13 的YOLOv4 與YOLOv5網(wǎng)絡(luò),以YOLOv4為例,for循環(huán)需要實現(xiàn)64通道、輸出圖像為13×13、核為13×13池化核、步長為1的數(shù)據(jù)賦值與比較。單loop的運行時間過長,導致無法進行進一步的聯(lián)合仿真,雖可降低單次池化的通道數(shù)實現(xiàn),但導致對照組參數(shù)不同,無比較意義,故做缺省處理。
實驗數(shù)據(jù)表明,使用本文的設(shè)計方案與CPU(AMD TR Pro 3995WX)相比,運行最大池化最高可實現(xiàn)536倍的加速效果;運行平均池化最高可實現(xiàn)11 248倍的加速效果。
當使用本文方案與文獻[17]的方案相比時,從LeNet-5和MobileNet 的實驗數(shù)據(jù)可以得出,不論最大池化還是平均池化,當步長等于池化核大小時,兩個方案的性能比接近1。這是由于非重疊池化本身就不存在數(shù)據(jù)復用,故本文方案在該方面沒有明顯的加速效果;從AlexNet、ZFNet、GoogleNet 和DenseNet 實驗數(shù)據(jù)可以得出,當步長小于但接近池化核時,因池化核滑行中存在數(shù)據(jù)重疊,本文方案的數(shù)據(jù)全復用的高性能處理有相對較好的表現(xiàn),相比于文獻[17]可以做到2倍的加速;從YOLOv4、YOLOv5 和YOLOv6 的實驗數(shù)據(jù)可以看出,當步長遠小于池化核時,池化核滑行重疊區(qū)域大,本文方案相較文獻[17]的性能比有較大的提升,且隨著池化核滑行中的重疊數(shù)據(jù)范圍增大而增大,其中YOLOv5可以達到27 倍的性能加速比。綜合來看,本文方案相對文獻[17]的平均加速效果為3.5倍。
當使用本文方案與文獻[18]方案相比時,從LeNet-5、Alexnet和ZFNet可以看出,針對valid模式的最大池化,本文方案取得加速效果的幾何平均值為4.7;從MobileNet和GoogleNet的實驗數(shù)據(jù)可以得出,含平均池化的網(wǎng)絡(luò),兩個方案的性能差距十分巨大,加速效果分別為213.7倍與554.8 倍,這是由于數(shù)字設(shè)計除法器得到的加速效果;從DenseNet 和YOLOv6 網(wǎng)絡(luò)實驗數(shù)據(jù)可以得出,same模式下,相較valid模式,本文方案的加速效果較文獻[18]將進一步提升,且根據(jù)DenseNet和YOLOv6網(wǎng)絡(luò)相互對比可以得出,當池化核越大且步長越小時,加速效果更明顯。綜合來看,本文方案相對文獻[18]的平均加速效果為148.4倍。
3.3 資源對比
本設(shè)計采取數(shù)據(jù)流高效復用的方式,在大型網(wǎng)絡(luò)中對緩存區(qū)域有較大的需求。但本設(shè)計可通過Verilog參數(shù)傳遞并取舍相應網(wǎng)絡(luò)所不需要的模塊以減少資源開銷。具體體現(xiàn)在:頂層結(jié)合左移行緩存器設(shè)計理念,池化核與輸入圖像的閾值對于硬件資源使用量影響較大,故僅需根據(jù)網(wǎng)絡(luò)需求傳遞相應參數(shù)閾值;根據(jù)網(wǎng)絡(luò)是否使用same 模式,池化方法僅使用單一最大池化還是多種方法混合,對設(shè)計中相應模塊功能進行取舍。故對于不同網(wǎng)絡(luò),設(shè)置不同閾值,合理規(guī)劃資源,本文dut 與文獻[17]和文獻[18]方案資源對比如表2所示,表中資源比使用LUT數(shù)據(jù)作為代表進行比較分析。
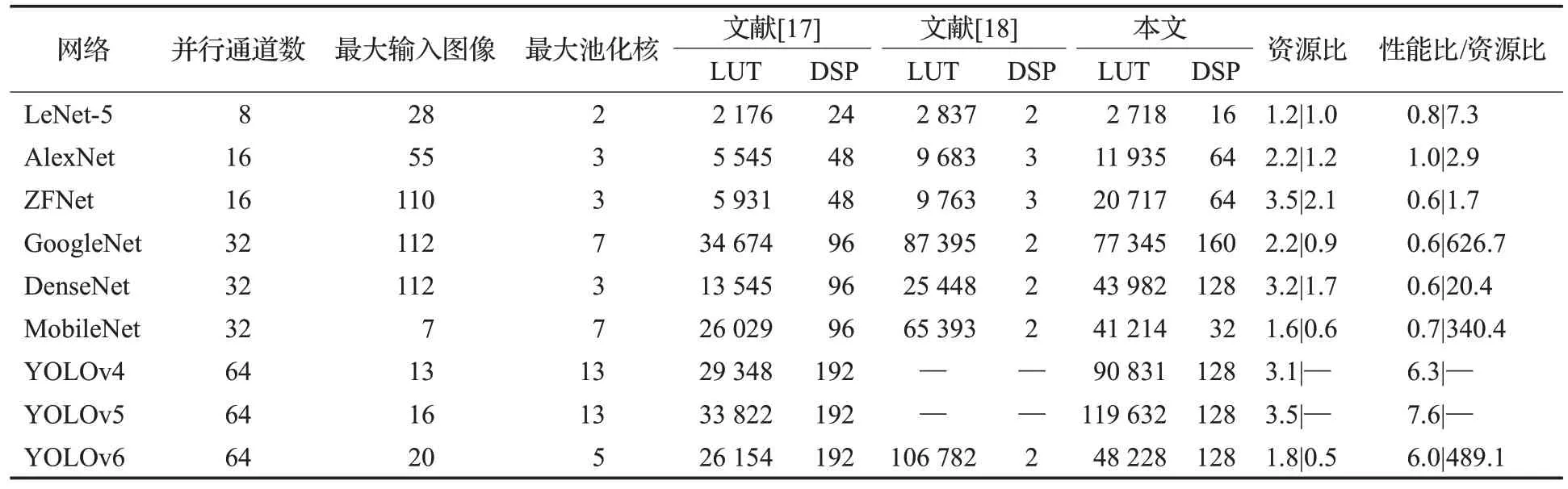
表2 不同參數(shù)下的資源對比Table 2 Comparison of resources under different parameters
從表2 實驗數(shù)據(jù)中可以得出,本文方案與文獻[17]的方案相比,資源的使用相對較多,本文方案在資源的對比上僅DSP 的使用量存在優(yōu)勢。其中DSP 資源主要作用于數(shù)據(jù)讀取時序的控制與數(shù)據(jù)處理的控制中所需的過程參數(shù)計算。過程參數(shù)是基于步長、核大小、圖像大小和模式選擇等,依據(jù)本文池化設(shè)計方案計算時序約束所需的參數(shù)。與文獻[17]的資源比的幾何平均值為2.3。再結(jié)合表1對比分析,從LeNet-5、AlexNet、ZFNet、GoogleNet、DenseNet 和MobileNet 的實驗數(shù)據(jù)可以得出,本文方案相較于文獻[17],資源使用量更大。這是由于本文方案存在數(shù)據(jù)緩存,而以上網(wǎng)絡(luò)無需數(shù)據(jù)復用或數(shù)據(jù)復用要求低;從YOLOv4、YOLOv5 和YOLOv6的實驗數(shù)據(jù)可以看出,網(wǎng)絡(luò)對數(shù)據(jù)復用要求高時,本文方案的優(yōu)勢將凸顯。其中以YOLOv5 網(wǎng)絡(luò)參數(shù)為例,3.5倍的資源使用量可獲得27倍的加速效果。綜上實驗數(shù)據(jù)分析總結(jié)可得,本文方案與文獻[17]方案相比,綜合的性能比/資源比的幾何平均值為1.5。
本文方案與文獻[18]相比,在池化核不超過3 的最大池化網(wǎng)絡(luò)中資源使用略高于文獻[18]的方案,但對于平均池化或池化核大于5的網(wǎng)絡(luò),本文方案的資源使用量低于文獻[18]。其中LeNet-5 的資源使用量兩者接近;從AlexNet、ZFNet和DenseNet這類最大池化且池化核不超過3 的網(wǎng)絡(luò)比較可以得出,文獻[18]比本文方案資源使用量更低,但比文獻[17]高,池化中計算輸出圖像大小需要用到除法,文獻[17]使用數(shù)字設(shè)計除法器,資源占優(yōu);但從GoogleNet、MobileNet、YOLOv6 這類平均池化或池化核較大的網(wǎng)絡(luò)比較可以得出,本文方案的資源使用量低,其根本原因也是HLS的除法資源使用量與大尺寸池化核需要額外嵌套for循環(huán)。其中以GoogleNet網(wǎng)絡(luò)參數(shù)為例,該網(wǎng)絡(luò)既需要核為7 的平均池化,又需要same模式重疊最大池化,兩者均需要大量資源,本文方案相較文獻[18]可以0.9 倍的資源使用量獲得555 倍的加速效果。綜上實驗數(shù)據(jù)分析可得,本文方案與文獻[18]方案相比,綜合的性能比/資源比的幾何平均值為212.6。
從表3可以得出,本文方案的數(shù)據(jù)全復用方法極度依賴數(shù)據(jù)緩存,行緩存器資源與輸入特征圖大小與池化核大小成一定比例關(guān)系,圖像與核越大且運行模式相同時,相較其余模塊資源,行緩存器資源占用量也越大。
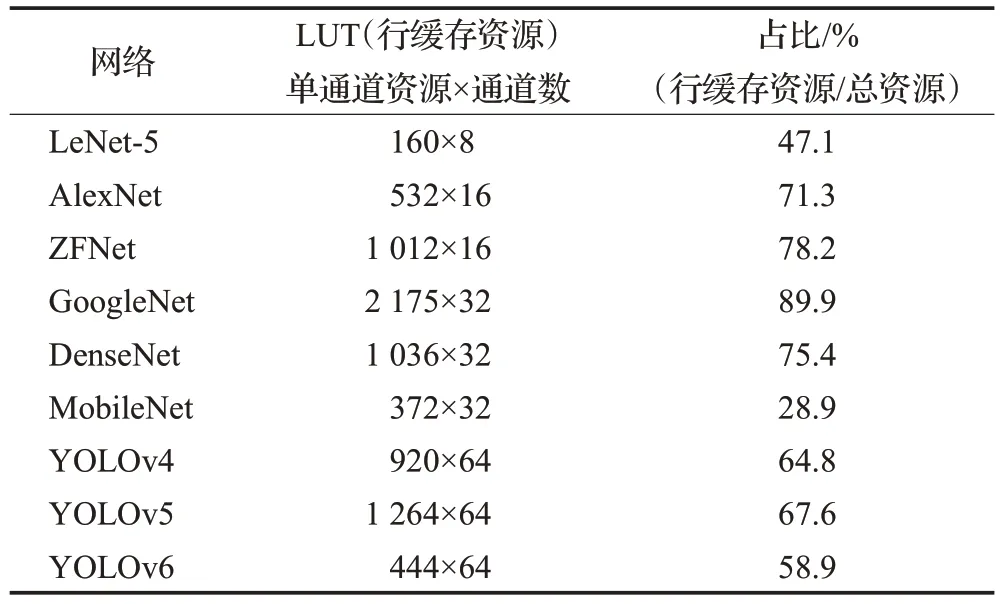
表3 不同網(wǎng)絡(luò)中行緩存資源占比Table 3 Proportion of row cache resources in different networks
從實驗結(jié)果可以看出,本文方案適用于所有類型的池化,在重疊池化中的優(yōu)勢更加明顯。在不考慮硬件資源的情況下,本文方案具備較高的性能;在考慮硬件資源的情況下,本文方案在類似YOLOv5 和GoogleNet 等網(wǎng)絡(luò)中的綜合表現(xiàn)突出。
4 結(jié)束語
本文通過Verilog 進行面向神經(jīng)網(wǎng)絡(luò)池化層的靈活高效硬件設(shè)計,并結(jié)合UVM 驗證環(huán)境對池化層功能進行多方位驗證,實驗證明其滿足LeNet-5、AlexNet、ZFNet、GoogleNet、DenseNet、MobileNet、YOLOv4、YOLOv5 和YOLOv6 等各類網(wǎng)絡(luò)應用需求,可移植性強,且在性能上表現(xiàn)十分優(yōu)異。以YOLOv5 為例,根據(jù)現(xiàn)有實驗數(shù)據(jù),與通用的數(shù)據(jù)不復用的方案相比,可實現(xiàn)以3.5倍資源取得27倍的加速;以GoogleNet為例,與HLS 設(shè)計方案相比,可實現(xiàn)僅用0.9 倍資源獲得555 倍的加速比。這對指導基于Verilog HDL 的CNN 硬件實現(xiàn)也具有重要意義。
猜你喜歡
江蘇安全生產(chǎn)(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
現(xiàn)代裝飾(2020年7期)2020-07-27 01:27:42
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
流行色(2020年1期)2020-04-28 11:16:38
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
資源再生(2017年3期)2017-06-01 12:20:59
