基于多智體強(qiáng)化學(xué)習(xí)的高效率貨物列車運(yùn)行動(dòng)態(tài)調(diào)整方法
2023-09-11 03:11:34蔣靈明倪少權(quán)
鐵道學(xué)報(bào) 2023年8期
蔣靈明,倪少權(quán)
(1.西南交通大學(xué) 交通運(yùn)輸與物流學(xué)院,四川 成都 611756;2.北京全路通信信號(hào)研究設(shè)計(jì)院集團(tuán)有限公司,北京 100070)
鐵路作為高效、綠色的陸地交通方式,是中國(guó)、日本、韓國(guó)和歐洲等國(guó)家和地區(qū)的主要公共交通運(yùn)輸方式。根據(jù)國(guó)際鐵路聯(lián)盟(UIC)發(fā)布的數(shù)據(jù)[1-2]:2017年全球鐵路里程、客運(yùn)和貨運(yùn)分別達(dá)到801 357 km、2 783億人·km和8 991億t·km。鐵路特別適用于重型、散裝和長(zhǎng)途的大宗商品運(yùn)輸,例如貨運(yùn)鐵路分別占美國(guó)和中國(guó)總運(yùn)輸份額的55%和50%[1]。而且,與公路運(yùn)輸(例如卡車)相比,貨物列車平均減少了75%的溫室氣體排放與直接能耗[3]。
貨運(yùn)鐵路網(wǎng)絡(luò)的輸運(yùn)能力由速度、載重和運(yùn)營(yíng)效率決定。由于惡劣天氣、臨時(shí)限速、鐵路建設(shè)或維護(hù)、自然災(zāi)害甚至列車事故等原因,貨物列車的到達(dá)、出發(fā)和停留時(shí)間都會(huì)有所延誤。更嚴(yán)重的是,延誤會(huì)在一定范圍內(nèi)傳播,導(dǎo)致大面積列車延誤,降低運(yùn)營(yíng)效率[4]。本文重點(diǎn)關(guān)注原計(jì)劃列車時(shí)刻表面臨不同延誤干擾下貨物列車運(yùn)營(yíng)效率的提升,以實(shí)時(shí)或動(dòng)態(tài)方式重新調(diào)度列車,使得延誤或成本降至最低。因此,列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整具有重要理論意義和應(yīng)用價(jià)值,已成為研究熱點(diǎn)[5-6]。
列車運(yùn)行圖調(diào)整或運(yùn)行動(dòng)態(tài)調(diào)整是一個(gè)NP完全問題。如文獻(xiàn)[5-20]所述,列車運(yùn)行圖調(diào)整的恢復(fù)模型和算法涉及數(shù)學(xué)規(guī)劃、啟發(fā)式算法[7-8]、智能算法等。采用啟發(fā)式算法的替代圖模型或整數(shù)線性規(guī)劃模型能夠得到有效解[5,9-10],但在處理大規(guī)模調(diào)度問題時(shí)面臨嚴(yán)峻挑戰(zhàn)。與此同時(shí),遺傳算法、模擬退火法、粒子群優(yōu)化算法和神經(jīng)網(wǎng)絡(luò)等智能算法在優(yōu)化補(bǔ)償列車時(shí)刻表的延誤擾動(dòng)方面也展現(xiàn)非凡實(shí)力[8,14-18]。
近年,作為一種先進(jìn)智能算法——強(qiáng)化學(xué)習(xí)[21-22]被廣泛應(yīng)用于鐵路交通管理中,如信號(hào)控制、列車調(diào)度或運(yùn)行圖調(diào)整[23-29]。強(qiáng)化學(xué)習(xí)結(jié)合了動(dòng)態(tài)規(guī)劃和有監(jiān)督學(xué)習(xí),適用于難以精確建模甚至無法數(shù)學(xué)建模的復(fù)雜環(huán)境。因此,強(qiáng)化學(xué)習(xí)是一種典型的無模型方法,它在獲取優(yōu)化的參數(shù)后,可以應(yīng)用于不同環(huán)境[21],具有優(yōu)良的泛化性。因此,強(qiáng)化學(xué)習(xí)算法(Q-learning等)已經(jīng)在研究高速鐵路(以下簡(jiǎn)稱“高鐵”)、城際列車和地鐵的運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整中發(fā)揮了重要作用[30-43],包括來自斯洛文尼亞[31]、英國(guó)[32-33]、荷蘭[34-36]、印度[37-39]、韓國(guó)[40]和中國(guó)[41-43]的研究案例。
在上述研究工作的啟發(fā)下,本文首次提出基于多智能體強(qiáng)化學(xué)習(xí)(Multi-agent Reinforcement Learning, MARL)突破大規(guī)模貨物列車的運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整難題,具有開創(chuàng)性參考價(jià)值。一方面,貨物列車的規(guī)模(數(shù)量)遠(yuǎn)大于客運(yùn)列車,其運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整更為關(guān)鍵。然而,相較于高鐵和地鐵已經(jīng)引入了多種智能型動(dòng)態(tài)調(diào)整技術(shù)[30-43],貨物列車的動(dòng)態(tài)調(diào)整仍然以傳統(tǒng)方法為主[44-50],且動(dòng)態(tài)調(diào)整的效率具有一定局限性。另一方面,MARL在處理大規(guī)模貨物列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整問題上優(yōu)勢(shì)顯著,而傳統(tǒng)智能算法難以乃至不能實(shí)時(shí)或快速地處理。具體而言,貨物列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整將采用“多智能體”模式,而不是傳統(tǒng)的“單智能體”模式[51]。多智能體算法被廣泛應(yīng)用于AlphaGo、智能多機(jī)器人、道路交通信號(hào)控制和分布式系統(tǒng)控制[27-28,51],具有并行優(yōu)化和動(dòng)態(tài)策略選擇的優(yōu)越性能。從原理上分析,MARL采用馬爾可夫博弈(或隨機(jī)博弈),引入了智能體之間交互(協(xié)作、沖突或組合)這一新自由度進(jìn)行決策優(yōu)化,而不是傳統(tǒng)單智能體強(qiáng)化學(xué)習(xí)算法(Single-agent Reinforcement Learning, SARL)的馬爾可夫決策過程。對(duì)應(yīng)地,區(qū)段網(wǎng)內(nèi)的貨物列車可以組合成多個(gè)智能體,分別與環(huán)境進(jìn)行交互,構(gòu)建多智能體模式,而單智能體模式則是由所有列車組成的一個(gè)公共智能體與環(huán)境進(jìn)行交互。因此,與單智能體算法相比,所提出的MARL的算法復(fù)雜度和計(jì)算時(shí)間呈現(xiàn)指數(shù)函數(shù)趨勢(shì)下降。
本文首先闡述貨物列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整場(chǎng)景、基于MARL的運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整算法,以及動(dòng)態(tài)調(diào)整的實(shí)現(xiàn)過程;然后以包頭—神木貨運(yùn)鐵路為案列,進(jìn)行模擬實(shí)驗(yàn),驗(yàn)證運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整方法的性能與效率,并與傳統(tǒng)SARL進(jìn)行性能比較;最后進(jìn)行總結(jié)和討論。
1 面向貨物列車的多智體強(qiáng)化學(xué)習(xí)方法
1.1 場(chǎng)景描述
貨物列車運(yùn)行動(dòng)態(tài)調(diào)整的鐵路場(chǎng)景見圖1:由雙向運(yùn)行(上行和下行方向)的單線軌道和4個(gè)車站(S1、S2、S3和S4)組成。由于貨物列車整車較長(zhǎng),兩個(gè)相鄰站點(diǎn)之間設(shè)置為一個(gè)站間閉塞分區(qū),共計(jì)3個(gè)站間閉塞分區(qū)。車站和站間閉塞分區(qū)的軌道都被定義為位置資源(詳見2.2節(jié)),并按“1,2,3,…,14”進(jìn)行編號(hào)排序。大多數(shù)情況下,貨物列車(G1和G3下行列車,G2和G4上行列車)按照原計(jì)劃時(shí)刻表在車站和站間閉塞分區(qū)之間有序運(yùn)行。

圖1 貨物列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整的鐵路場(chǎng)景
為充分滿足鐵路運(yùn)營(yíng)的安全約束,對(duì)場(chǎng)景做以下近似理想合理約束:
(1)每列貨物列車被視為一個(gè)質(zhì)點(diǎn),其位于車站軌道或站間閉塞分區(qū),而不會(huì)同時(shí)占用站間閉塞分區(qū)和車站的軌道。
(2)每個(gè)車站由多條并行軌道(到發(fā)線)組成,可容納列車數(shù)不超過并行軌道(到發(fā)線)數(shù)目。
(3)車站軌道和站間閉塞分區(qū)都必須滿足唯一的資源占用約束,以確保列車運(yùn)行的安全性,即該資源在某時(shí)刻只能為空閑狀態(tài)或被一列列車占用。
(4)貨物列車在車站可提前一定時(shí)間發(fā)車,以有效補(bǔ)償延誤干擾,而客運(yùn)列車或地鐵不允許。
(5)所有貨物列車的運(yùn)行速度相同(例如,包頭—神木鐵路速度為80 km/h),不考慮速度差異。
1.2 基于MARL的列車運(yùn)行動(dòng)態(tài)調(diào)整的原理與步驟
與SARL的“單智能體”模式不同,MARL采用“多個(gè)智能體”。為此,設(shè)計(jì)并定義兩個(gè)不同的智能體,分別涵蓋下行和上行貨物列車,且這兩個(gè)智能體與鐵路環(huán)境交互,觀察多個(gè)貨物列車的狀態(tài)(位置資源)和基礎(chǔ)設(shè)施資源(車站、軌道和站間閉塞分區(qū))的可用性。兩個(gè)智能體(下行和上行列車)之間的相互作用以及與環(huán)境的交互見圖2,每個(gè)智能體包含3個(gè)核心因素:狀態(tài)、動(dòng)作和獎(jiǎng)勵(lì)。MARL利用當(dāng)前狀態(tài)下的獎(jiǎng)勵(lì)(貨物列車總延誤時(shí)間最小化)積累學(xué)習(xí)經(jīng)驗(yàn)完成Q-table更新,引導(dǎo)多智能體不斷試錯(cuò)學(xué)習(xí)并逐步收斂,在安全運(yùn)行條件下以最優(yōu)動(dòng)作(停止或前進(jìn))來最小化總延誤時(shí)間。
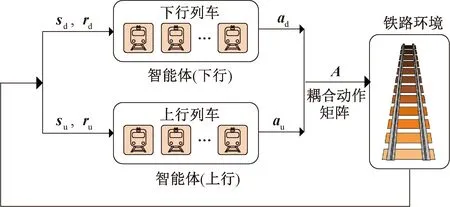
圖2 兩個(gè)智能體(下行和上行列車)之間的相互作用以及與環(huán)境的交互
在算法收斂和計(jì)算效率之間保持平衡的前提下,可以為特定場(chǎng)景設(shè)置更多智能體,而不僅局限于2個(gè)智能體。
圖2中:sd、su分別為所有下行、上行貨物列車的位置集;rd、ru分別為所有下行、上行貨物列車的獎(jiǎng)勵(lì)函數(shù)矩陣;ad、au分別為所有下行、上行貨物列車的動(dòng)作矩陣;A為耦合動(dòng)作矩陣。
在MARL方法中,智能體的狀態(tài)、行動(dòng)和獎(jiǎng)勵(lì)定義如下:
(1)狀態(tài)定義為貨物列車在每個(gè)時(shí)刻的位置資源及占用,即車站到發(fā)線或站間閉塞分區(qū)。圖2中所有位置資源都按“1,2,3,…,14”進(jìn)行編碼和排序,每個(gè)智能體的狀態(tài)由該智能體所包括的多個(gè)貨物列車的位置集組成。
(2)動(dòng)作定義為每列列車的兩個(gè)可用動(dòng)作(“停車”或“行駛”)。當(dāng)考慮N列貨物列車(N/2列下行列車和N/2列上行列車)時(shí),每個(gè)智能體都有2N/2個(gè)行動(dòng)集。假設(shè)任一列車(重車或空車)都可以在車站停車或行駛,但在站間閉塞分區(qū)必須行駛。
(3) 獎(jiǎng)勵(lì)定義為所有貨物列車延誤時(shí)間之和的倒數(shù)或者延誤時(shí)間平方之和的倒數(shù),即
( 1 )
或
( 2 )

由式( 1 )可知,每個(gè)智能體的獎(jiǎng)勵(lì)隨著總延遲時(shí)間的減少而增加。當(dāng)所有智能體到達(dá)最終狀態(tài)時(shí)(即所有下行和上行列車都到達(dá)終點(diǎn)站),可以獲得獎(jiǎng)勵(lì)。此外,還需設(shè)置一些懲罰機(jī)制,以促進(jìn)MARL算法的收斂。例如,當(dāng)?shù)鷷r(shí)間ti超過時(shí)間閾值而貨物列車未能全部到達(dá)終點(diǎn)站時(shí),訓(xùn)練過程中斷且獎(jiǎng)勵(lì)為負(fù)值。因此,獎(jiǎng)勵(lì)函數(shù)進(jìn)一步改寫為
( 3 )
Tthreshold=Tspan+Tdelay+Tset
式中:ri為列車的獎(jiǎng)勵(lì)函數(shù);β為放大常數(shù),用于調(diào)控算法收斂速度;Tthreshold為閾值;Tspan為第一列車出發(fā)時(shí)刻與最后一列車到達(dá)時(shí)刻之間的時(shí)間跨度;Tdelay為所有列車干擾延誤時(shí)間的總和;Tset為具體時(shí)間常數(shù)(設(shè)置為10 min)。另外,為避免局部最優(yōu)和縮短訓(xùn)練時(shí)間,將時(shí)間閾值設(shè)置為MARL算法每輪訓(xùn)練結(jié)束的標(biāo)志。
在場(chǎng)景描述和參數(shù)定義之后,進(jìn)一步闡述基于MARL的列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整的詳細(xì)過程。兩個(gè)智能體之間采用獨(dú)立學(xué)習(xí)和相互競(jìng)爭(zhēng)的混合策略,因此采用Q-learning方法來獲得多個(gè)貨物列車之間的最優(yōu)動(dòng)作(“停止”或“前進(jìn)”)策略。對(duì)應(yīng)于1.2小節(jié),定義的兩個(gè)智能體(下行和上行貨物列車)的3個(gè)關(guān)鍵因素(狀態(tài)、行為和獎(jiǎng)勵(lì))可以進(jìn)一步描述為
式中:S包括所有基礎(chǔ)設(shè)施資源(車站軌道和站間閉塞分區(qū)),按順序列為貨物列車的可執(zhí)行位置;A為由兩個(gè)智能體的2N/2+2N/2=2(1+N/2)個(gè)單獨(dú)操作所組成的動(dòng)作集,假設(shè)下行列車和下行列車的數(shù)量(N/2)相同。同樣場(chǎng)景下,單智體模式的SARL方法卻具有2N個(gè)獨(dú)立的動(dòng)作。
經(jīng)過對(duì)比,不難發(fā)現(xiàn):MARL方法的復(fù)雜度由O(2N)降到O[2(1+N/2)]。假設(shè)面向22列貨物列車(第3節(jié)),MARL的算法復(fù)雜性或計(jì)算時(shí)間降低為SARL計(jì)算時(shí)間的約1‰(即1/1 024)。因此,該MARL方法能夠高效、實(shí)時(shí)地完成貨物列車的運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整任務(wù),特別是大規(guī)模動(dòng)態(tài)調(diào)整。
此外,每個(gè)智能體的動(dòng)作通過ε貪婪策略進(jìn)行決策,以ε為探索率決定執(zhí)行動(dòng)作的概率,即
( 4 )
( 5 )
式中:μ(t,ai|si)表示第i個(gè)智能體(i=d或u)在時(shí)間t和狀態(tài)si下目標(biāo)動(dòng)作集合;A(t,si)為在時(shí)間t狀態(tài)si的所有可能動(dòng)作集;rand為標(biāo)準(zhǔn)正態(tài)分布;a*為與時(shí)刻t時(shí)狀態(tài)si中最大值Q對(duì)應(yīng)的動(dòng)作;其余參數(shù)見表1。
由式( 5 )可知:隨著訓(xùn)練片段的增加,ε逐漸減小并接近于零,即隨著訓(xùn)練代數(shù)增加,智能體傾向于使用學(xué)習(xí)經(jīng)驗(yàn),從而產(chǎn)生最優(yōu)動(dòng)作集。
Q-learning通常基于狀態(tài)和動(dòng)作來構(gòu)造Q-table的更新規(guī)則。在基于MARL的列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整過程中,狀態(tài)由列車數(shù)量(N)、車站數(shù)量(M)和時(shí)間跨度Tspan組成,所有狀態(tài)的數(shù)量達(dá)到MN×Tspan。因此,Q-table中元素?cái)?shù)量增加到MN×Tspan×2(1+N/2)。隨著列車規(guī)模增加,Q-table中的元素?cái)?shù)量呈現(xiàn)出爆炸性增長(zhǎng)。為降低復(fù)雜度,結(jié)合時(shí)間和動(dòng)作構(gòu)建Q-table,則第i個(gè)智能體的Q-table為
Qi(t+Δt,ai)=Qi(t,ai)+
α[ri-Qi(t,ai)+γgmaxQi(t,:)
( 6 )
式中:Δt為時(shí)間步長(zhǎng);ri為第i個(gè)智能體在狀態(tài)si執(zhí)行動(dòng)作ai而獲得的獎(jiǎng)勵(lì)。maxQi(t,:)為時(shí)刻t的最大Q值。表1和算法1詳細(xì)給出了的MARL的參數(shù)定義和算法步驟。
算法1基于MARL的列車運(yùn)行動(dòng)態(tài)調(diào)整算法
輸入:α,β,T_table,Q_table,max_episode,S_matrix,delay_time,delay_point;
輸出:opt_plan;
輸入(Train_environment,Q_table,episode)
1: forepisode=1:max_episode
2: 輸入(t,states,done)給上下行智能體;
3: while !done do
4: foragent_i:
5:state_i=states(i);
6: [action_i,res_i] =get_act_res(t,state_i);
7:actions= [train_i],ress= [res_i];
8:check_action_res(actions,ress);
9: [states_,rewards,done] =step(t,states,
actions,ress);
10: foragent_i:
11:Q(t,action_i,agent_i) =
12:Q(t,action_i,agent_i) +α[reward_i+γmaxQ(t,action_i,agent_i)];
13:t=t+ 1;
14:states=states_;
15: end
16:opt_plan=greedy(Q_table);
17:plot(opt_plan);
18: end
2 基于多智體強(qiáng)化學(xué)習(xí)的貨物列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整案例
2.1 包頭—神木鐵路中等規(guī)模的動(dòng)態(tài)調(diào)整
萬南場(chǎng)—東勝區(qū)段貨物列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整場(chǎng)景見圖3,這是包頭—神木煤炭貨運(yùn)鐵路主干部分。該區(qū)段由91.4 km的雙向單線軌道組成,設(shè)有9個(gè)車站和8個(gè)站間閉塞分區(qū)。對(duì)應(yīng)地,萬南場(chǎng)—東勝區(qū)段可構(gòu)建69個(gè)位置資源,由車站軌道(到發(fā)線)和站間閉塞分區(qū)組成;計(jì)劃期間共有22列貨物列車,上行和下行各為11列。
為比較MARL與SARL的性能,首先研究一個(gè)中等規(guī)模貨物列車的運(yùn)行動(dòng)態(tài)調(diào)整。中等規(guī)模貨物列車運(yùn)行動(dòng)態(tài)調(diào)整的3種算法(MARL、SARL和FIFO)性能比較見表2,如表2所示,選取1列或3列列車晚點(diǎn)場(chǎng)景下的5種延誤擾動(dòng)條件,并進(jìn)行動(dòng)態(tài)調(diào)整測(cè)試。本文聚焦延誤擾動(dòng)(表2)為決策者已知的場(chǎng)景下,利用MARL與SARL方法實(shí)現(xiàn)貨物列車的運(yùn)行動(dòng)態(tài)調(diào)整。

表2 中等規(guī)模貨物列車運(yùn)行動(dòng)態(tài)調(diào)整的3種算法性能比較
本文采用通用計(jì)算機(jī)(AMD Ryzen 7 5800X 8核3.79 GHz CPU和64GB RAM)完成貨物列車運(yùn)行動(dòng)態(tài)調(diào)整程序的測(cè)試。如表2所示,MARL方法的收斂迭代均為250次以內(nèi),且對(duì)所有擾動(dòng)條件下的優(yōu)化調(diào)整均收斂有效。進(jìn)一步選擇兩種擾動(dòng)情景進(jìn)行詳細(xì)分析,見表3。如圖4(a)和圖4(b)所示,在兩種擾動(dòng)條件下(一列和三列延誤),MARL方法收斂穩(wěn)定后的最佳總延誤時(shí)間分別為721 min和1 686 min。值得指出的是:圖4(a)和圖4(b)中迭代過程中產(chǎn)生了比最終收斂結(jié)果更小的延誤時(shí)間。這是因?yàn)閷r(shí)間閾值設(shè)置為MARL算法每輪訓(xùn)練結(jié)束的標(biāo)志,以避免局部最優(yōu)和縮短訓(xùn)練時(shí)間。在每輪訓(xùn)練中,當(dāng)訓(xùn)練時(shí)間超過時(shí)間閾值且存在列車未到達(dá)終點(diǎn)站時(shí),訓(xùn)練被強(qiáng)制停止而未到達(dá)終點(diǎn)站的列車不計(jì)算終點(diǎn)站的延誤時(shí)間,因此出現(xiàn)最終收斂結(jié)果的更小延誤時(shí)間,這些更小延誤時(shí)間不能作為動(dòng)態(tài)調(diào)整的有效解。

表3 中等規(guī)模貨物列車運(yùn)行動(dòng)態(tài)調(diào)整的延誤擾動(dòng)條件

圖4 中等規(guī)模貨物列車的MARL方法收斂結(jié)果和動(dòng)態(tài)調(diào)整前后的貨物列車運(yùn)行圖
圖4(c)和圖4(d)展示了兩種擾動(dòng)條件下經(jīng)過列車運(yùn)行動(dòng)態(tài)調(diào)整后的時(shí)間表。不難看出,兩種條件下動(dòng)態(tài)調(diào)整獲得的時(shí)間表均滿足唯一的資源占用約束。因此,實(shí)驗(yàn)結(jié)果表明MARL方法能夠有效處理大規(guī)模的運(yùn)行動(dòng)態(tài)調(diào)整。
為了驗(yàn)證MARL方法處理貨物列車運(yùn)行動(dòng)態(tài)調(diào)整的高效率,同時(shí)采用了SARL方法來處理表2中的延時(shí)擾動(dòng)問題。與圖4所示的擾動(dòng)情景(1列延誤列車和3列延誤列車)相同,SARL方法處理重新調(diào)度后的時(shí)刻表見圖5。顯然,對(duì)于不同的擾動(dòng)條件,MARL和SARL方法都可獲得相同總延誤時(shí)間。

圖5 中等規(guī)模下貨物列車的SARL方法收斂結(jié)果和動(dòng)態(tài)調(diào)整前后的貨物
更進(jìn)一步,表2提供了MARL和SARL方法之間的全面性能比較,例如計(jì)算時(shí)間、操作集和內(nèi)存需求。與MARL相比,SARL方法的動(dòng)作集增加了27倍,達(dá)到 65 536。 因而SARL計(jì)算時(shí)間高達(dá)675 min甚至更多,而MARL的計(jì)算時(shí)間大幅度減少到5~6 min,不到SARL的1%。顯然,MARL方法極大地提升了計(jì)算效率,這種優(yōu)勢(shì)對(duì)于3.2節(jié)中的大規(guī)模的動(dòng)態(tài)調(diào)整更為明顯。
此外,引入先進(jìn)先出(FIFO)算法以提供更加全面的性能比較,它對(duì)延誤列車采用整體平移策略,不能通過超車方式進(jìn)行調(diào)整。與FIFO算法相比,MARL方法的總延遲時(shí)間降低了44%~86%。
2.2 包頭—神木段大規(guī)模貨物列車運(yùn)行動(dòng)態(tài)調(diào)整
為了在更大范圍內(nèi)驗(yàn)證運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整能力,利用MARL方法對(duì)全部22列貨物列車進(jìn)行動(dòng)態(tài)調(diào)整,即下行和上行方向各11列貨物列車。
同樣,在上述鐵路環(huán)境下,選擇了1列和3列延誤列車的兩種擾動(dòng)條件。大規(guī)模貨物列車(22列)運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整的收斂結(jié)果如圖6(a)和6(b)所示。經(jīng)過250或300次訓(xùn)練后,最佳總延遲時(shí)間分別為721、 1 689 min,兩種干擾條件見表4。相應(yīng)地,圖6(c)和圖6(d)顯示了兩種延誤擾動(dòng)下經(jīng)動(dòng)態(tài)調(diào)整優(yōu)化后的列車時(shí)刻表。兩種擾動(dòng)條件下,受延誤影響的22列列車在計(jì)劃動(dòng)態(tài)調(diào)整后的時(shí)刻表仍滿足對(duì)資源占用的唯一約束。

表4 大規(guī)模動(dòng)態(tài)調(diào)整下(22列)延誤擾動(dòng)條件

圖6 大規(guī)模貨物列車(22列)的MARL方法收斂結(jié)果和動(dòng)態(tài)調(diào)整前后的貨物列車運(yùn)行圖
根據(jù)表5和圖6的統(tǒng)計(jì)與分析結(jié)果,MARL方法能夠有效解決延誤干擾下大規(guī)模貨物列車的運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整,并得到最小總延誤時(shí)間。然而,若采用SARL替換MARL來實(shí)施動(dòng)態(tài)調(diào)整,動(dòng)作集從4 096(即212)指數(shù)上升至4 294 967 296(即222),此時(shí)該通用計(jì)算機(jī)已經(jīng)無法在短時(shí)間內(nèi)完成優(yōu)化過程。根據(jù)表2和表5對(duì)此時(shí)SARL所需的計(jì)算時(shí)間和內(nèi)存進(jìn)行預(yù)測(cè):該通用計(jì)算機(jī)需要耗時(shí)3 469 d(即4 995 600 min),幾乎難以完成任務(wù)。這一結(jié)論與2.2節(jié)的理論分析是一致的:MARL使得算法復(fù)雜度從O(2N)到O[2(1+N/2)]成指數(shù)趨勢(shì)級(jí)降低,因而計(jì)算效率以2(N/2-1)倍顯著提高。

表5 大規(guī)模貨物列車(22列)運(yùn)行動(dòng)態(tài)調(diào)整的MARL與SARL性能比較
值得指出的是,若采用高性能計(jì)算服務(wù)器可以進(jìn)一步減少大規(guī)模列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整下的MARL計(jì)算時(shí)間(例如僅需幾分鐘),提供實(shí)時(shí)模式服務(wù)。然而,此時(shí)SARL方法仍需數(shù)十、數(shù)百小時(shí),依舊無法完成以實(shí)時(shí)或快速的大規(guī)模貨物列車運(yùn)行動(dòng)態(tài)調(diào)整任務(wù)。
3 結(jié)論
針對(duì)大規(guī)模貨物列車運(yùn)行動(dòng)態(tài)調(diào)整問題,本文提出了一種高計(jì)算效率的MARL方法。頗具創(chuàng)意的是,該MARL方法將上行和下行貨物列車設(shè)計(jì)為兩個(gè)不同的智能體,從而使其算法復(fù)雜度比單智能體算法大幅度。以包頭—神木貨運(yùn)鐵路為例,在處理22列貨物列車和9個(gè)車站的大規(guī)模動(dòng)態(tài)調(diào)整案例,該MARL方法能夠獲得穩(wěn)定收斂的最小總延誤時(shí)間和可行的列車運(yùn)行調(diào)整方案。但由于所需計(jì)算時(shí)間巨大,傳統(tǒng)SARL方法不可能在短時(shí)間內(nèi)完成大規(guī)模運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整任務(wù)。因此,本文提出的基于MARL方法的貨物列車運(yùn)行計(jì)劃動(dòng)態(tài)調(diào)整有望為大運(yùn)量、復(fù)雜網(wǎng)絡(luò)的鐵路貨物列車調(diào)度問題提供一種有效和有力的解決方案,從而顯著提高貨運(yùn)鐵路的運(yùn)營(yíng)效率。
猜你喜歡
表面工程與再制造(2019年6期)2019-08-24 06:40:04
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
