一種面向產品模型管理的PLMM接口實現方法
2022-11-08 06:27:38岳繼光鄒鴻宇吳琛浩王萍劉軍
中國工程機械學報 2022年5期
岳繼光,鄒鴻宇,吳琛浩,王萍,劉軍
(1.同濟大學電子與信息工程學院,上海 201804;2.山東山大華天軟件有限公司,山東 濟南 250102)
為適應企業產品的網絡協同制造需求,一些公司研發了產品全生命周期管理(product lifecycle management,PLM)系統[1]。其友好的用戶界面、涵蓋的功能組件、豐富的基礎模塊,為企業內部和相關企業之間的產品協同研制提供了便利。
近年來,隨著產品高效研制要求的不斷提高,基于數據與文檔的PLM系統越來越難以滿足企業高質量敏捷制造的要求。現代制造業希望能夠在PLM系統基礎上,加大產品深層次協同力度,縮短研發周期,推演預測產品研制狀況,實現跨單位、跨部門、跨層次的產品高效管理。因此,將具有解釋內在屬性、描述內涵知識、反應研制流程的產品模型融入PLM系統[2],進而形成產品全生命周期模型管理(product lifecycle model management,PLMM)系統,對實現高層次的產品協同制造具有創新性。
PLMM系統是一種新的產品管理解決方案。在保留了PLM“前臺人機交互”方式的同時,還提供基于產品模型的“中臺”支持。PLM基于產品“文檔+數據交互”模式,提升到基于“模型”的產品屬性交互、模型協同、仿真推演乃至數字孿生的高層次聯動研制,是產品由“碎片化”數據管理轉型到“體系化”模型知識管理的有效途徑。
產品研制類的軟件系統管理的特點是文件交互。為將PLM系統高效地轉變為PLMM系統,其焦點是高效地處理涉及產品信息的文件。然而人工很難勝任非結構化的文件文本數據處理[3],自動化、智能技術手段的運用和應用文本數據的挖掘技術成為產品管理的關鍵部分之一[4]。本文提出一個基于“產品模型文件包”的“文本關鍵詞特征聯合預測算法”,實現面向協同研發的PLMM接口。
1 產品生命周期協同研發
產品的協同研發是先進制造技術中并行工程運行的核心[5-6]。將數據轉化為能夠影響產品性能的決策信息成為國內外工業管理的共識,Siemens的HD-PLM框架為大規模、分布廣泛、來源不同的數據賦予意義[7],Solid Works Enterprise基于全產品線搭建產品生命周期解決方案[8],如華天PLM、武漢開目、數碼大方、艾克斯特、上海思普等國內廠商,以產品數據為基礎,以知識庫為核心,建立工藝設計與管理的軟件數據信息集成平臺[9]。
在PLMM平臺上的協同研發,指通過PLMM完成產品的高質量、高效研發。要使產品利益攸關者高效的協同工作,需要建立準確、快速、高質量地信息交換和相互協同機制[10]。因此,構建面向協同研發的產品模型管理接口就顯得十分重要[11-12]。
2 PLMM系統上的模型管理接口
2.1 模型管理接口功能描述
面向協同研發的產品模型管理接口,應滿足產品利益攸關者分享相關的產品模型,通過模型來提高協同設計的效率[13]。模型管理包括產品的概念模型、三維設計模型、工程分析模型、過程模型和知識模型的管理。
當前國內產品模型管理體系,例如山東大學華天團隊的PLMM系統,如圖1所示。在“前臺人機交互”層面依然為文件方式,將產品模型涉及的“功能、結構、行為”等要素,表述為“文檔、圖紙、表單、實物圖”等文件類信息,進而“打包”為若干文件,形成“產品模型文件包”。PLMM系統后臺,產品模型文件包通過相互關聯組織,形成具有結構化、數字化意義的對象,在原型系統相關模型支持的軟件層中以模型為基本組成單位被調度和協同。
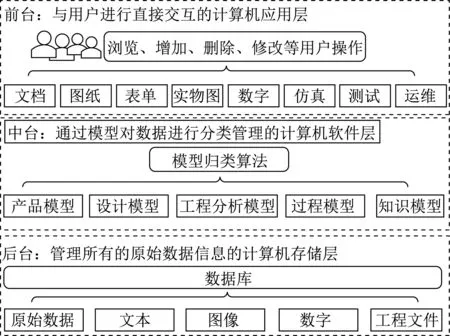
圖1 PLMM系統架構Fig.1 Framework of PLMM system
“產品模型文件包”是指與產品概念、設計、采購、生產、銷售和售后服務全生命周期6個階段相關的所有文件,可以通過PLMM平臺打開或互聯、互通,由產品制造企業及產品利益攸關者在不同時間、不同地點、不同人員、按照不同權限查閱、設計、協同、制造、購置以及運行維護。“產品模型文件包”中的文件名稱用規范的編碼表示,具體參考產品全生命周期管理平臺編碼規范,見表1。
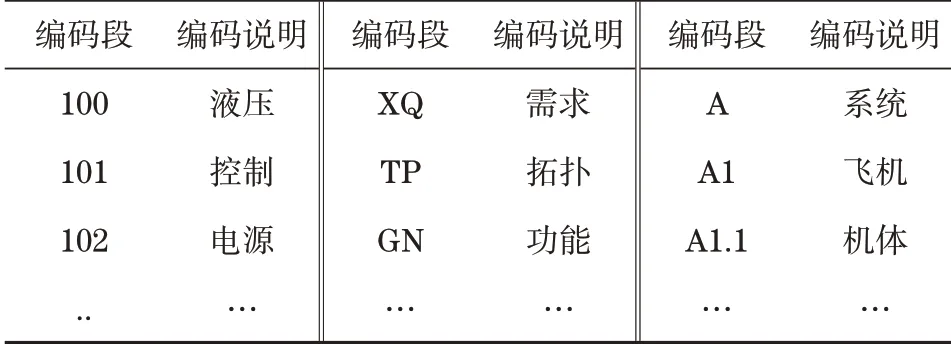
表1 基于模型的PLM平臺編碼規范Tab.1 Coding specification of PLM platform based on model
PLMM模型接口包括如下功能:①對來自不同領域、不同部門、不同來源、不同結構的“產品模型文件包”進行特征識別;②將產品的概念模型、三維設計模型、工程分析模型、過程模型以及知識模型等組成的“產品模型文件包”進行分類;③根據用戶需求意見推送結果;④繼續推送直到協同研發結束。
2.2 產品模型管理接口的實現
面向協同研發的PLMM模型管理接口的結構按照輸入-活動-輸出(input process output,IPO)三元組模式,如圖2所示。其輸入為“產品模型文件包”,其活動包括產品模型特征識別、提取、屬性分類以及協同推送,其輸出為產品利益攸關者。
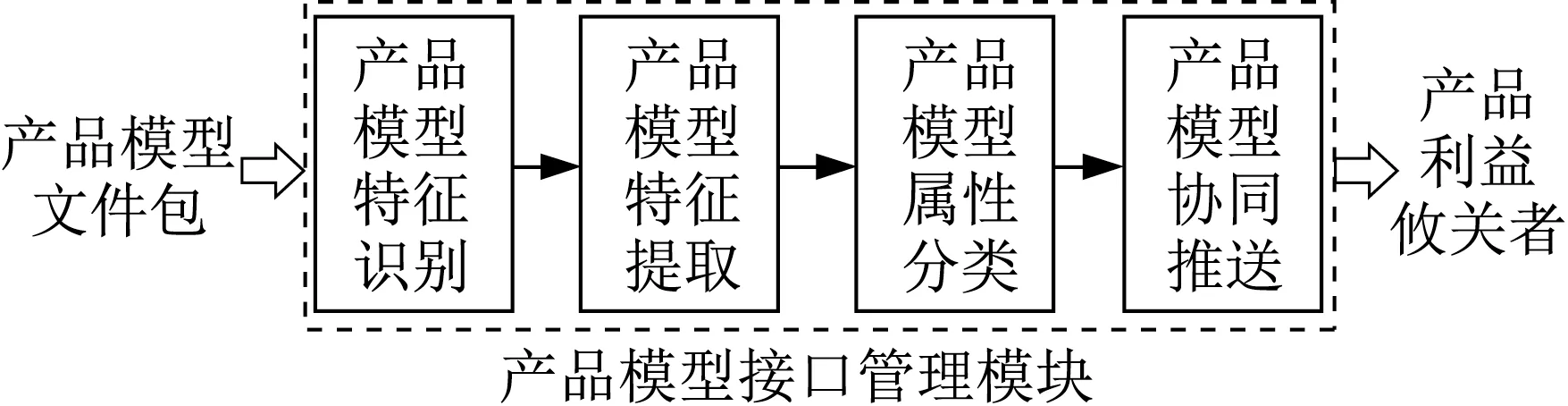
圖2 PLMM系統上的產品模型接口結構示意Fig.2 Schematic diagram of product model interface structure on PLMM system
面向協同研發的PLMM模型管理接口的核心是基于中文文本自然語言處理的智能化算法,輸入為產品文件包,及其包含文件的文本信息,輸出該產品的模型文件包對應的模型類別。其具體步驟如圖3所示。
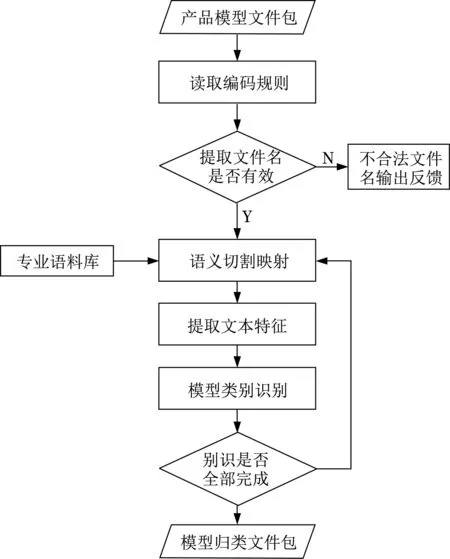
圖3 產品模型管理接口算法步驟Fig.3 The procedures of product model management interface algorithm
3 面向某軍機后機身平尾控制模擬系統的工程示例
后機身平尾控制系統是軍機典型復雜產品,由油源、伺服閥、液壓缸、控制電路、連接機構、平尾、傳感變送裝置以及供電電源等組成,核心是閥控液壓缸系統,其方框圖如圖4所示。
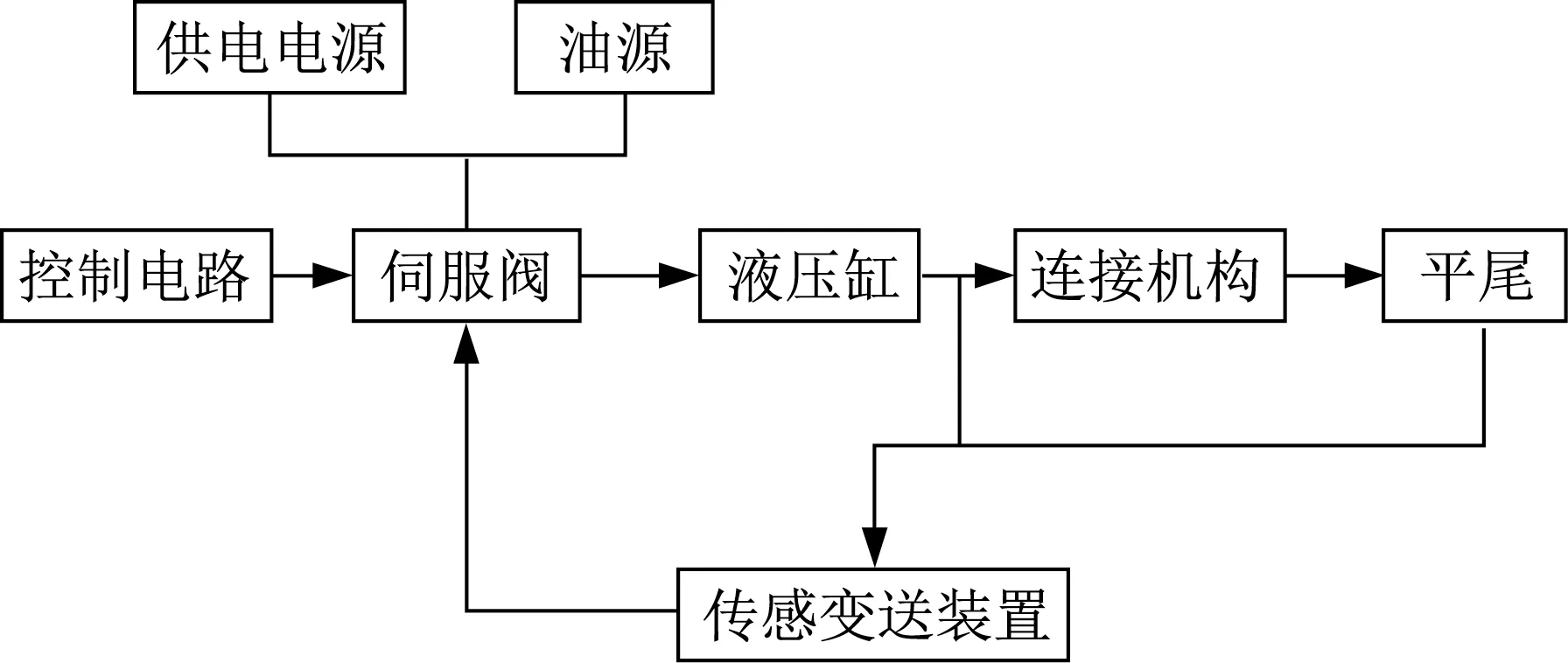
圖4 閥控液壓缸系統方框圖Fig.4 Block diagram of valve-controlled hydraulic cylinder system
其“產品模型文件包”涵蓋了如下文件:①基于SysML表達的閥控液壓缸系統設計需求、用例、功能、架構、參數約束以及其他文件;②閥控液壓缸系統配置、結構、公差和拓撲關系、裝配關系和各類BOM等模型文件;③閥控液壓缸系統所涉及的機械、電子電氣、流體傳動等不同學科的仿真模型間的耦合關聯關系等模型文件;④表示閥控液壓缸系統不同生命周期階段的模型動態關聯的過程模型文件;⑤表示閥控液壓缸系統知識獲取、知識表示、知識變換、知識重用等知識模型文件。
4 軍機后機身平尾控制模擬系統產品模型管理接口的應用
4.1 基于關鍵字的產品模型文件包管理
產品模型管理接口復雜產品模型,根據模型在管理系統中的組織架構與自身包含的信息,來提取出模型特征,并基于特征預測其產品模型類別。
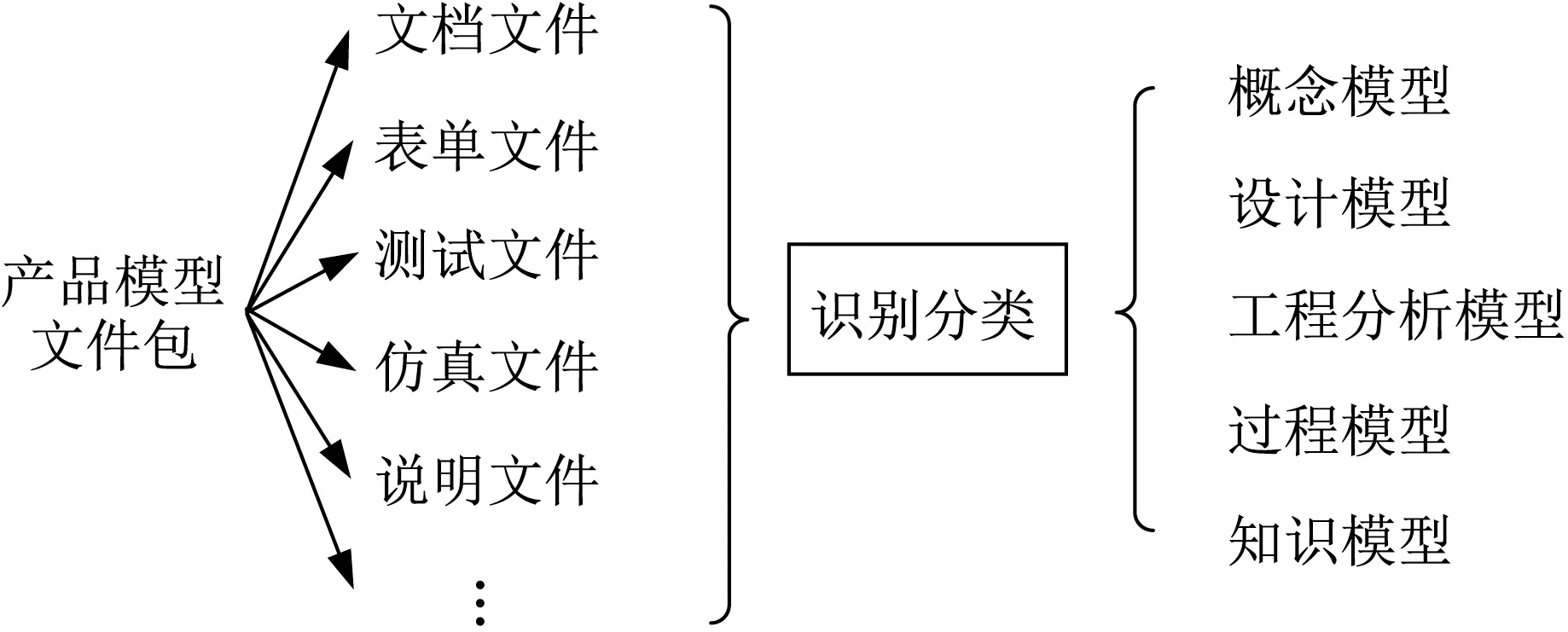
圖5 協同接口識別分類功能Fig.5 Identification and classification function of collaborative interface
產品的任意一個模型,在PLMM系統中以“產品模型文件包”的形式呈現給用戶,一個“模型文件包”的定義為
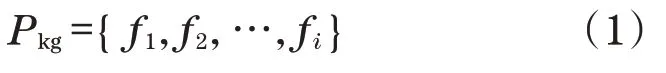
任意一個產品文件包Pkg,其內部包含的諸多文件fi,i的取值范圍為[0,∞)。對于任意一個產品模型,最低限度的文件特征是沒有文件,而文件數量不設上限,隨著產品的研發進行而不斷增加。
產品模型文件包的模型類別識別遵循以下步驟:
步驟1文本清洗與正則化匹配。
每個產品模型中的文件信息,使用文本清洗與正則化匹配,與標準編碼進行正則匹配,從而剔除不符合工業要求的目標。正則表達式Re為
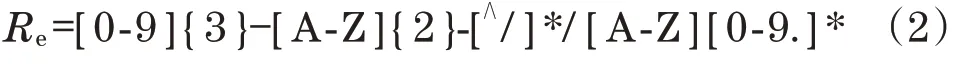
式中:0-9為任意有效阿拉伯數字;{3}為3位有效數字;A-Z為任意有效英文字母;{2}為2位有效字母;[∧/]*為任意多個非反斜杠符號字符的文本,故該正則表達式可匹配任意字段,單字母加數字結尾的編碼格式,不同的文件名匹配結果,如圖6所示。100-JG-CR32液壓缸設計圖紙/A1.1中,100匹配[0-9]{3},JG匹配[A-Z]{2},CR32液壓缸設計圖紙匹配[∧/]*,A匹配[A-Z],1.1匹配[0-9.]*。
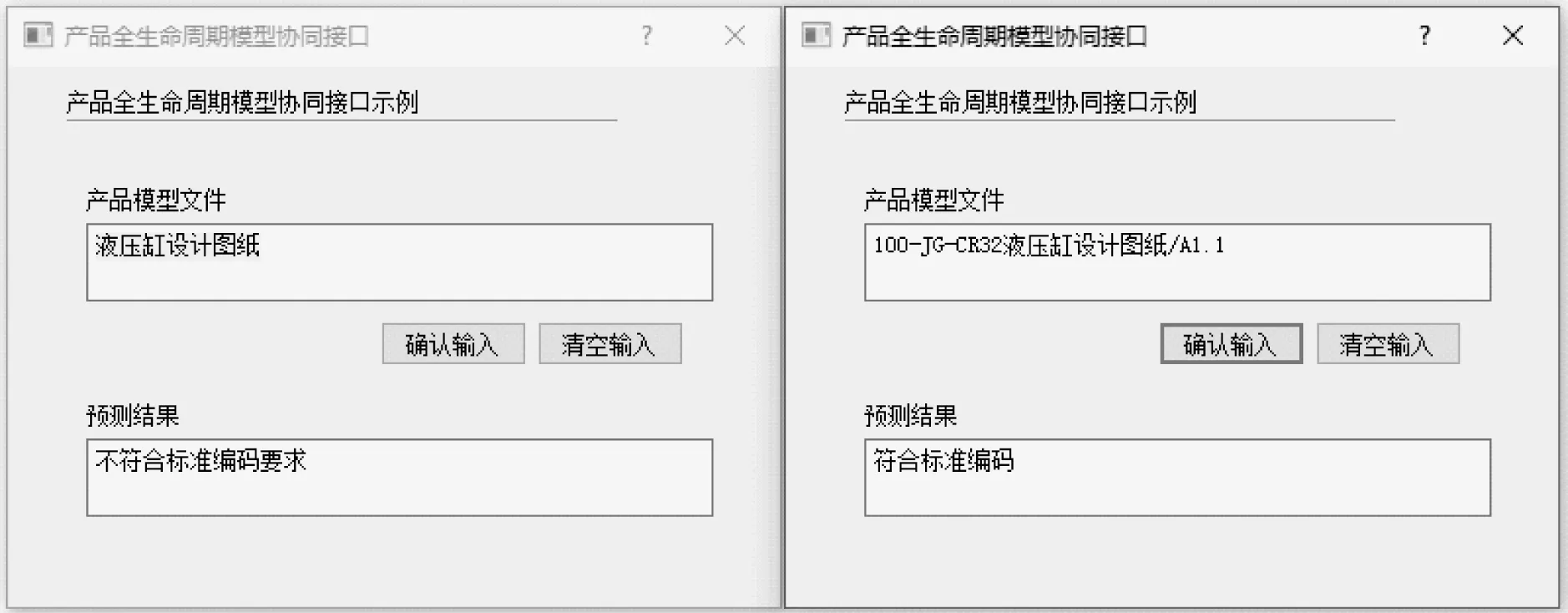
圖6 不同的文件名匹配結果Fig.6 The match results of different file names
步驟2特征提取與特征轉義。
通過冗余信息的清理和規則匹配來快速從文本中提取有效特征,對符合標準編碼格式的文件fi進行特征提取與解析。具體方法為:①載入語料庫C,獲取語料信息corpus;②讀取文件fi的名稱Ni;③將Ni與正則表達式Re進行匹配,得到標準編碼的結果,即編碼段Code、數字段Num、文字段Str;④分別訪問corpus中的code、corpus映射區段、num_corpus映射區段,并與Code、Num進行匹配,返回corpus中的映射結果,得到編碼特征;⑤遍歷Str中的字符,搜索corpus中相同的字符組合,存在復數搜索結果時按照字典序保留,得到文字特征。
對提取的特征屬性,使用精確率、召回率、F1-score等5項指標對其效果進行評估,實驗效果如圖7所示。
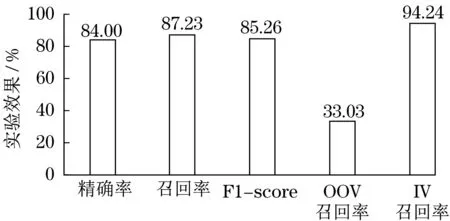
圖7 特征提取效果驗證Fig.7 Effect verification of feature extraction
通過對軍機后機身模擬控制系統中的文本內容的驗證,在精確率、召回率、F1-score分數以及已在語料庫中的數據(in vocabulary,IV)的召回率上均取得了較好的效果,但是對于未在語料庫中的數據(out of vocabulary,OOV),由于OOV的數據量過少,與IV數據的比例存在不平衡現象,所以分數相比于其他指標較低。
步驟3基于關鍵字的搜索匹配。
從“產品模型文件包”到模型體系需要進行模型類別預測,本文采用語義推理的方法,通過在產品全生命周期詞料庫wd中,使用不同的關鍵字組KG對提取的特征進行相似匹配,從而得到產品模型文件包中的模型類別。
預測方程如下:

式中:S()為歸一化方程,用于對產品模型文件的相似度向量vsim進行歸一化,并得出對應類別的預測分值。其中:
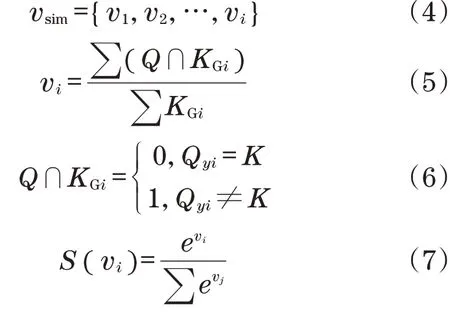
式中:vi為其中一條文件特征與關鍵字組KGi的查詢分值,由于不同的關鍵字庫的體積不一定保持一致,故需要∑KGi保證不同關鍵字庫的大小不會對結果造成影響;Q為其他一條文本的提取特征。
為加強產品模型的預測效果,實現對“產品模型文件包”中信息最大化的利用,在文件信息的基礎上,結合文件格式進行協同預測,通過對產品模型文件包的數字化格式信息與文本化語義信息進行訪問,對產品模型文件包所屬模型類別進行預測:
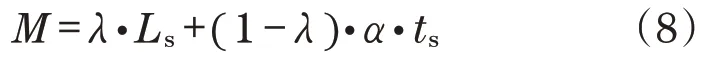
式中:M為產品模型文件包的預測結果與分值;ts為具體文件的文件類型預測分值;α為標準系數,用于保證Ls與ts在同一量級;λ為取值[0,1]的權重系數,用于均衡兩者在最終預測中的作用程度。通過對兩者的加權評估,使得最終的文件推送能夠更準確,如圖8所示,不同的λ對預測準確度的效果,如圖9所示。
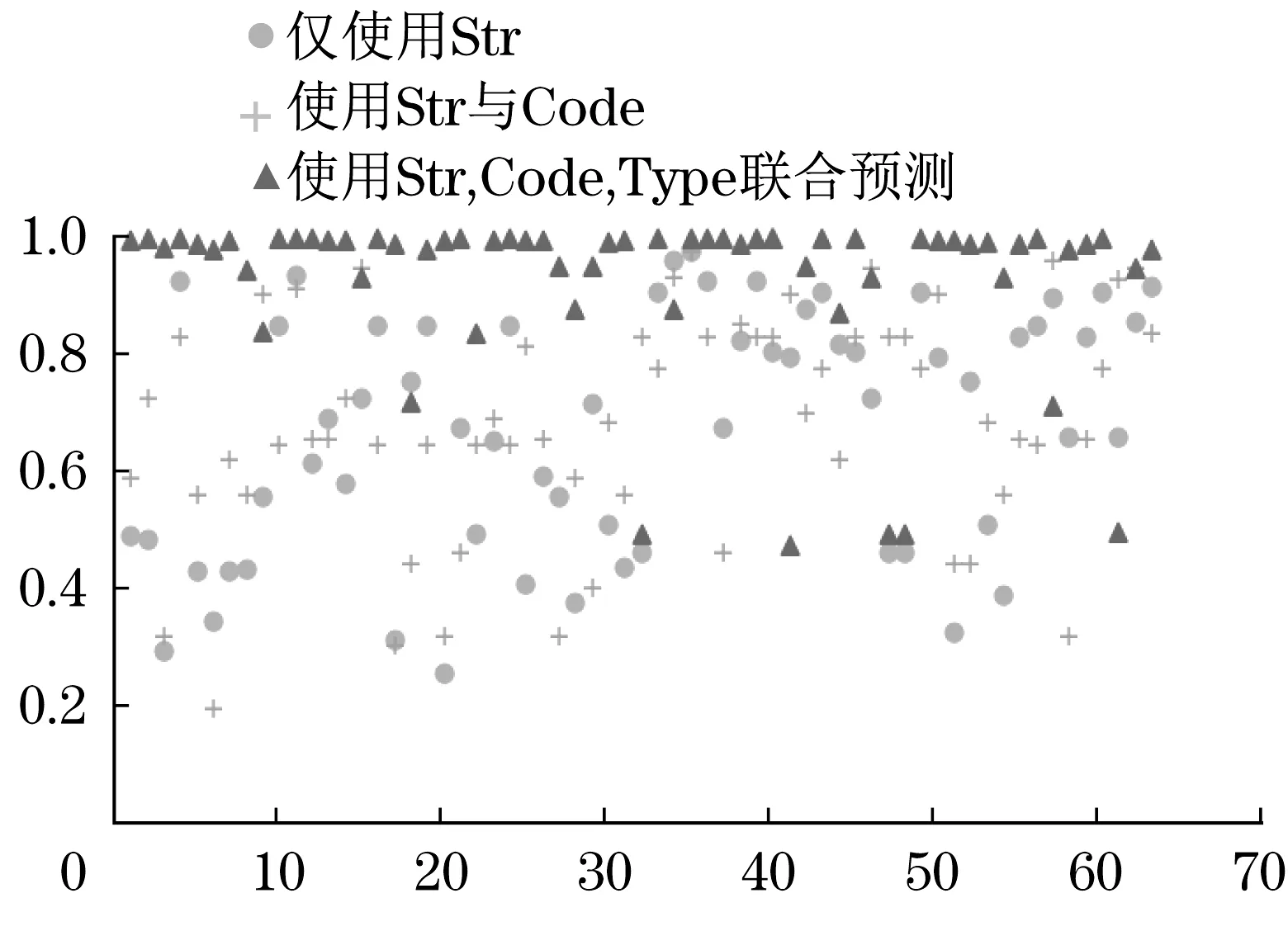
圖8 對模型類別的預測分值Fig.8 The forecast score for model category
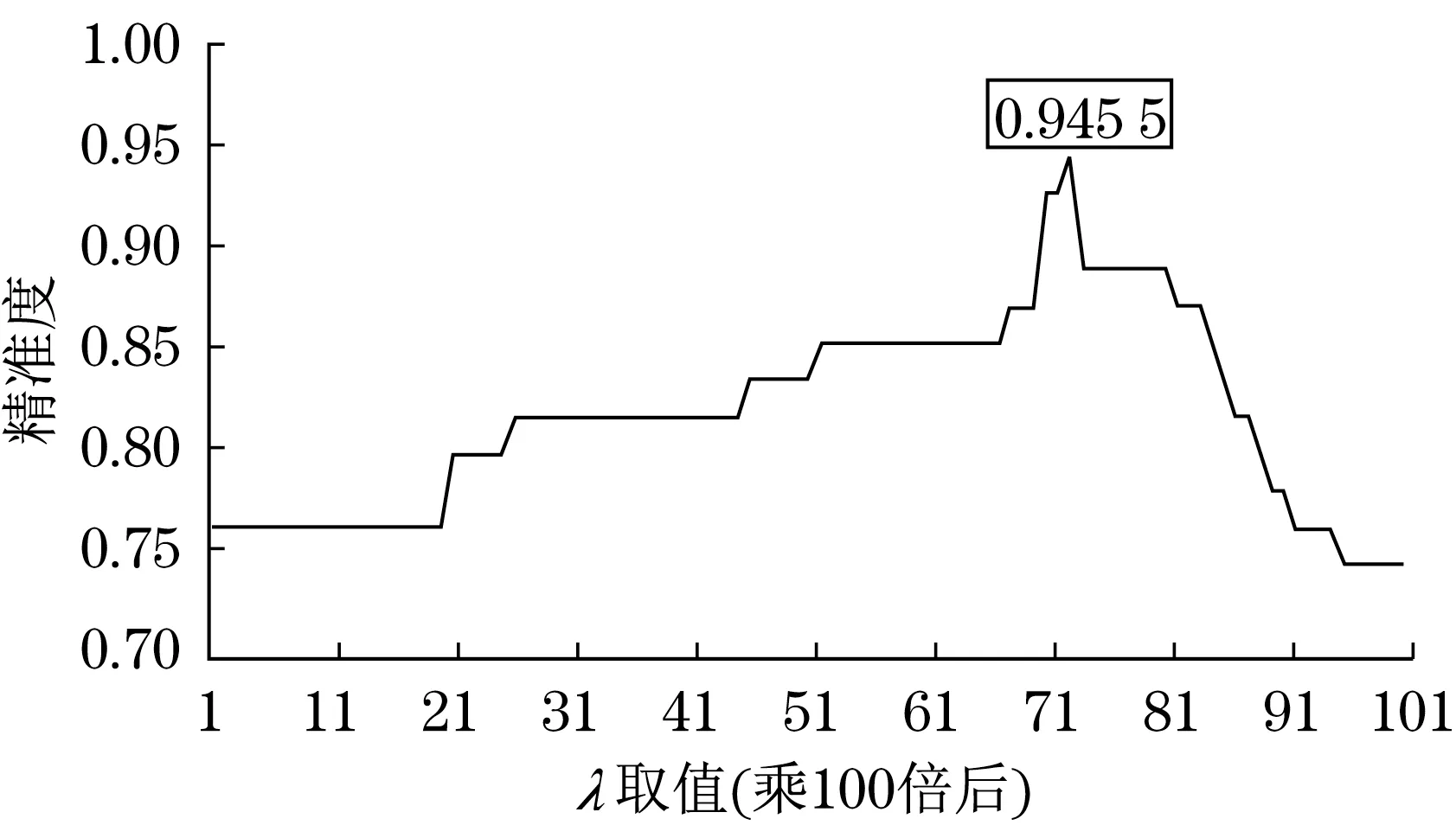
圖9 不同λ對預測準確度的影響Fig.9 The impact of different λ on prediction accuracy
通過對“文件包”中大量的異構信息的提取其有效特征的預測,在華天公司PLMM系統中,對圖10所示的文件系統進行模型類別預測,通過文本關鍵詞特征聯合預測算法的結果形成了圖11中按模型類別的分類視圖,從結果上來看,類似的內容會被歸類到其關聯的模型類別中,實現文檔到模型的接口功能之一。
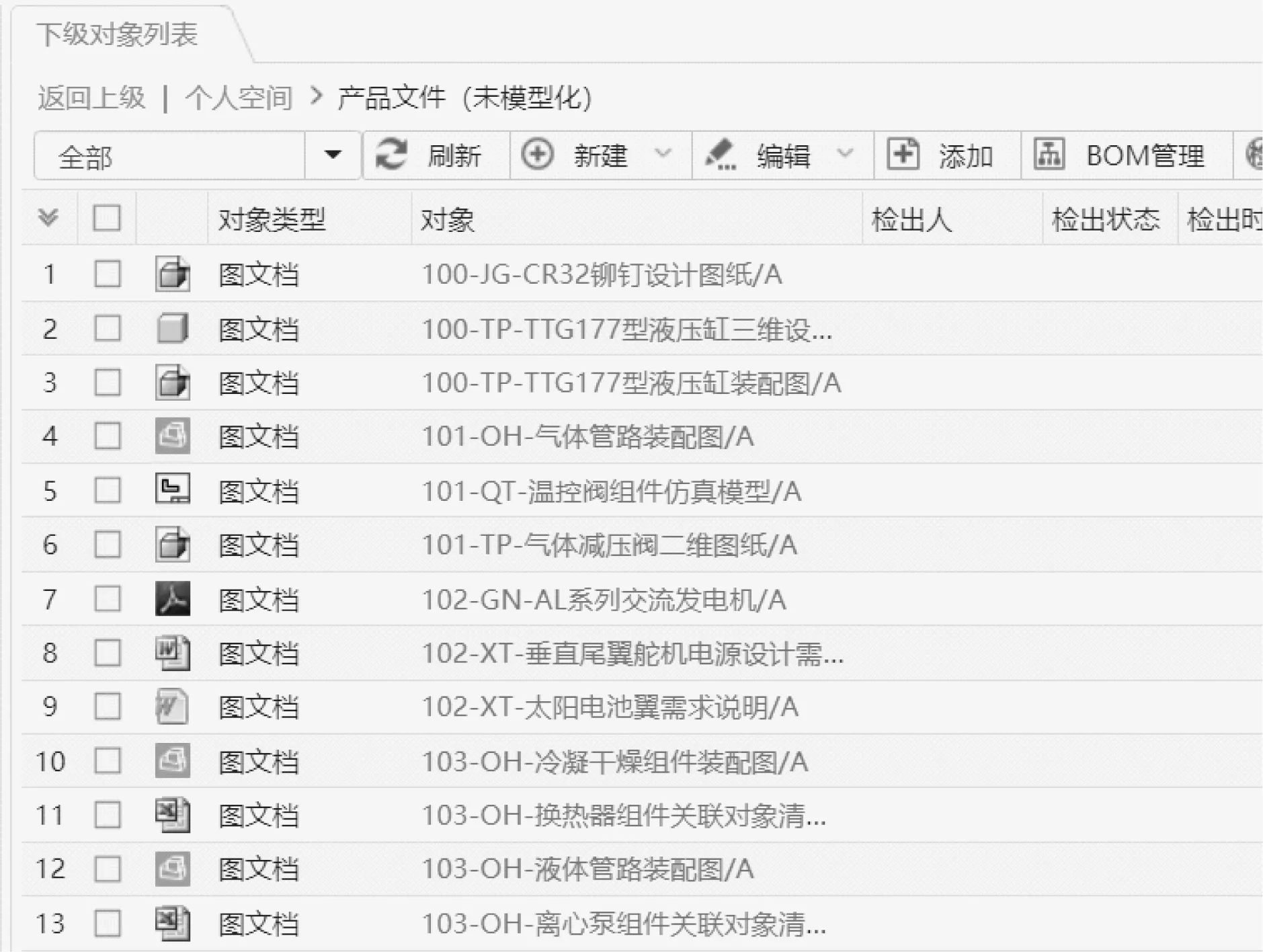
圖10 PLMM系統中的文件管理Fig.10 Documents management in PLMM

圖11 PLMM中按照模型類別管理Fig.11 Management method through model type in PLMM
4.2 基于用戶需求的協同資源管理
對于PLMM系統的用戶而言,協同管理接口需要解決模型與產品利益攸關者的索引難題。協同管理接口的用戶視角可以被視為如下的IPO結構,如圖12所示。其中,輸入為用戶/利益攸關者在產品研發過程中的工程需求信息,不遵循固定規范,多為自然語言或關鍵詞的組合。處理環節中協同管理接口識別需求,從產品模型文件包資源數據庫中快速搜索與需求相匹配的資源數據。輸出為工程師需要的資源。

圖12 協同接口需求分析功能IPO結構Fig.12 The IPO structure of collaborative interface
在對用戶輸入需求信息前,檢查產品模型數據庫是否建立了協同接口的索引,若未建立索引,則執行數據庫的搜索引擎初始化過程。
對每一個Pkg中的產品文件fi,使用中文分詞算法,將f劃分為多個獨立的中文詞語,建立索引對象dxi={title,context}。其中,title為協同推薦引擎推薦的標題,context為協同推薦引擎推薦的實際內容。對于每個產品模型,有
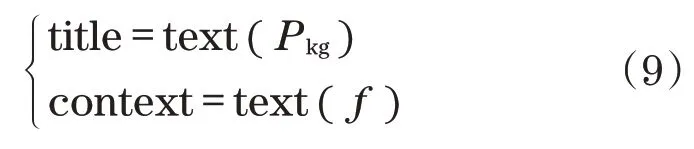
式中:text(x)為對象x的文本內容。通過遍歷所有產品模型文件包,可以得到當前搜索引擎的索引
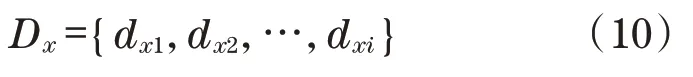
在已有數據庫索引的基礎上,對用戶的非結構化輸入In,使用特征提取算法,得到其關鍵需求詞匯wdi組成的需求組N。
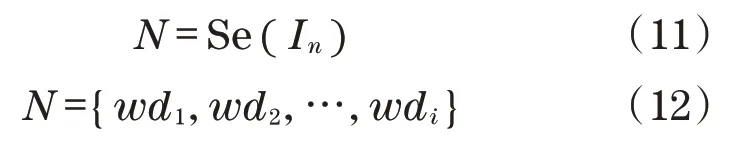
式中:Se為前文中的特征提取方法,通過對中文文本進行切分得到關鍵詞匯信息wdi。每一個關鍵詞匯會在搜索引擎中進行索引匹配,優先在title中獲取返回結果,其次對context進行二次訪問,得到推薦的資源和結果,在一定條目限制下,推薦的資源會被組合在一起,向提出需求的用戶展示。當用戶對推薦的資源進行一定了解后,如果產生新的需求,則可以再次通過搜索引擎輸入新的需求信息,來得到更準確、更符合用戶需求的推薦結果。根據用戶需求的資源推薦系統,如圖13所示。

圖13 根據用戶需求的資源推薦系統Fig.13 Resource recommendation system according to user needs
5 結語
本文提出了基于PLMM模型管理接口方案,為產品制造企業和產品利益攸關者網絡化協同智能化和高效化的提供了一種可行性;使用了基于關鍵字的模型類別預測方法,通過對輸入的文件文本進行清洗、切分、搜索匹配,計算其在各模型類別領域的權重,并通過歸一化給出其預測結果與對應分值,實現文件管理到模型管理的轉化技術,預測效果最高可達94.55%;實現了一種基于關鍵字的搜索引擎,能夠對用戶提出的需求進行分析,提取其中的關鍵文本,并在PLM海量的數據庫中為用戶提供最匹配的資源信息,為工業軟件管理系統提供一種快速查詢的方案。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:23:50
語文知識(2014年1期)2014-02-28 21:59:13
玩具(2009年10期)2009-11-04 02:33:14
