用于單音音樂音高估計的密集擴張卷積殘差網絡
2022-09-28 09:17:38馬文芳王天軍謝永勝
東北師大學報(自然科學版) 2022年3期
馬文芳,胡 英,王天軍,謝永勝
(1.新疆大學信息科學與工程學院,新疆 烏魯木齊 830046;2.新疆大學信息檢測和處理重點實驗室,新疆 烏魯木齊 830046;3.國網新疆電力有限公司,新疆 烏魯木齊 830092)
0 引言
音高估計或基音頻率估計對于音樂信息檢索和語音分析研究領域中許多任務而言,是不可或缺的重要一步.如在音樂信號處理中,音高跟蹤可用于多音軌數據集生成音高注釋的方法[1],也是旋律提取系統的核心步驟[2-3].傳統的基頻(F0)估計器采用基于參數的信號處理方法,有基于時域處理的算法[4-5]、有基于頻域處理的算法[6],或者兩者兼而有之[7-8],然后使用后處理算法平滑基頻軌跡,取得了較好的性能.然而,面對各類待處理音頻并非總是如此有效地提取出基頻,即使是像pYIN[5]這樣性能較好的算法,對于具有挑戰性的音頻記錄(如不常見的樂器聲或波動非常快的音高曲線),也會產生嘈雜的結果.近幾年,出現了各種基于神經網絡的基頻/音高估計方法.例如,RNN-BLSTM[9]使用PEFAC算法[10]提取男女兩種混合語音信號的頻域特征作為輸入并建模兩種音高輪廓.采用多種神經網絡的數據驅動方法用于單音音高估計[11-13]和多音音高估計[14-15].Xu等[16]提出了一種基于神經網絡的端到端回歸模型,其中語音檢測器和提出的F0估計器共同工作以突出音高軌跡.Ardaillon等[17]提出了一種用于語音音高估計的全卷積網絡(Fully Convolutional Network,FCN)模型,該模型可以減少計算量,使其更適合于實時估計的目的.Dong等[18]提出了一種用于復調音樂中唱聲基頻提取的深度卷積殘差網絡.Gfeller等[19]提出了一種以自監督的方式進行訓練的音高估計方法(SPICE).
為了解決梯度消失問題,He等[20]提出了一種具有恒等連接的殘差神經網絡(Residual Neural Network,ResNet).ResNet可以大大提高訓練效率,減少由于跳躍連接和殘差映射造成的模型退化.Huang等[21]提出密集連接卷積網絡(Densely connected convolutional Network,DenseNet),為了保證網絡模型中各個網絡層之間的最大信息流動,將網絡中所有層(特征圖大小相同)進行拼接.與ResNet不同,在特征映射被傳遞到某一層之前,不是通過求和來融合特征;相反,是通過拼接來組合特征.Yu等[22]提出了一種擴張卷積網絡模型,能夠聚合多尺度的上下文信息,并且不損失分辨率.Singh等[23]提出了基于擴張因果時間卷積網絡(Temporal Convolutional Network,TCN)單基頻估計的DeepF0模型.擠壓和激勵網絡(Squeeze-and-Excitation Networks,SENets)最早是由Hu等[24]提出來的,關注通道特征之間的關系.Dauphin等[25]在2017年首次提出了語言模型的門控機制.
受到DenseNet、ResNet的啟發,本文提出一種基于CRN-Raw[18]結構的密集擴張卷積殘差網絡(DDCRN)單音音樂音高估計模型,其中殘差模塊中權重層采用卷積門控線性單元,每個殘差模塊的輸出都送入通道注意力模塊.
1 密集擴張卷積殘差網絡單音音樂音高估計模型
1.1 密集擴張卷積殘差網絡
圖1是提出的用于單音音樂音高估計的DDCRN.該網絡包括密集擴張卷積模塊、3個殘差模塊和3個通道注意力模塊.DDCRN直接對原始時域波形按幀為單位進行處理,獲得每幀的估計音高.該網絡的輸入是1 024個時域音頻采樣點(幀長).將每一幀的樣本歸一化為零均值和單一方差后再送入DDCRN來獲得一個360維的輸出向量.圖1中最下方F框表示密集擴張卷積(Dense Dilated Convolution,DDC)模塊,擴張卷積的擴張因子d分別為1,2,4,8.將不同層的輸出特征均按通道維度進行拼接.C和E框表示殘差模塊(Residual Module),這里采用卷積門控線性單元(Convolutional Gated Linear Unit,ConvGLU)替代單一標準卷積來提取特征.B和D框表示通道注意力模塊(Channel-wise Attention Module),關注通道特征之間的相關性.最上方的A框表示全連接層.網絡中不同模塊數據計算公式為:
xDDC=fDDC(x0);
(1)
x1=f1(xDDC)+f2(f1(xDDC)),
xCA1=fCA(x1);
(2)
x2=f3(xCA1)+f4(f3(xCA1)),
xCA2=fCA(x2);
(3)
x3=f5(xCA2)+f6(f5(xCA2)),
xCA3=fCA(x3).
(4)
式中:x0是DDCRN的時域輸入;xDDC是密集擴張卷積模塊的輸出;xi,i∈{1,2,3}是網絡中3個殘差模塊的輸出,其中i是網絡中不同殘差模塊和通道注意力模塊的索引,網絡中3個通道注意力模塊的輸出進一步送入下一個殘差模塊;fCA表示網絡中通道注意力操作,f1,f2,…,f6分別表示網絡中6個ConvGLUs操作.xCA3是網絡最終的輸出.
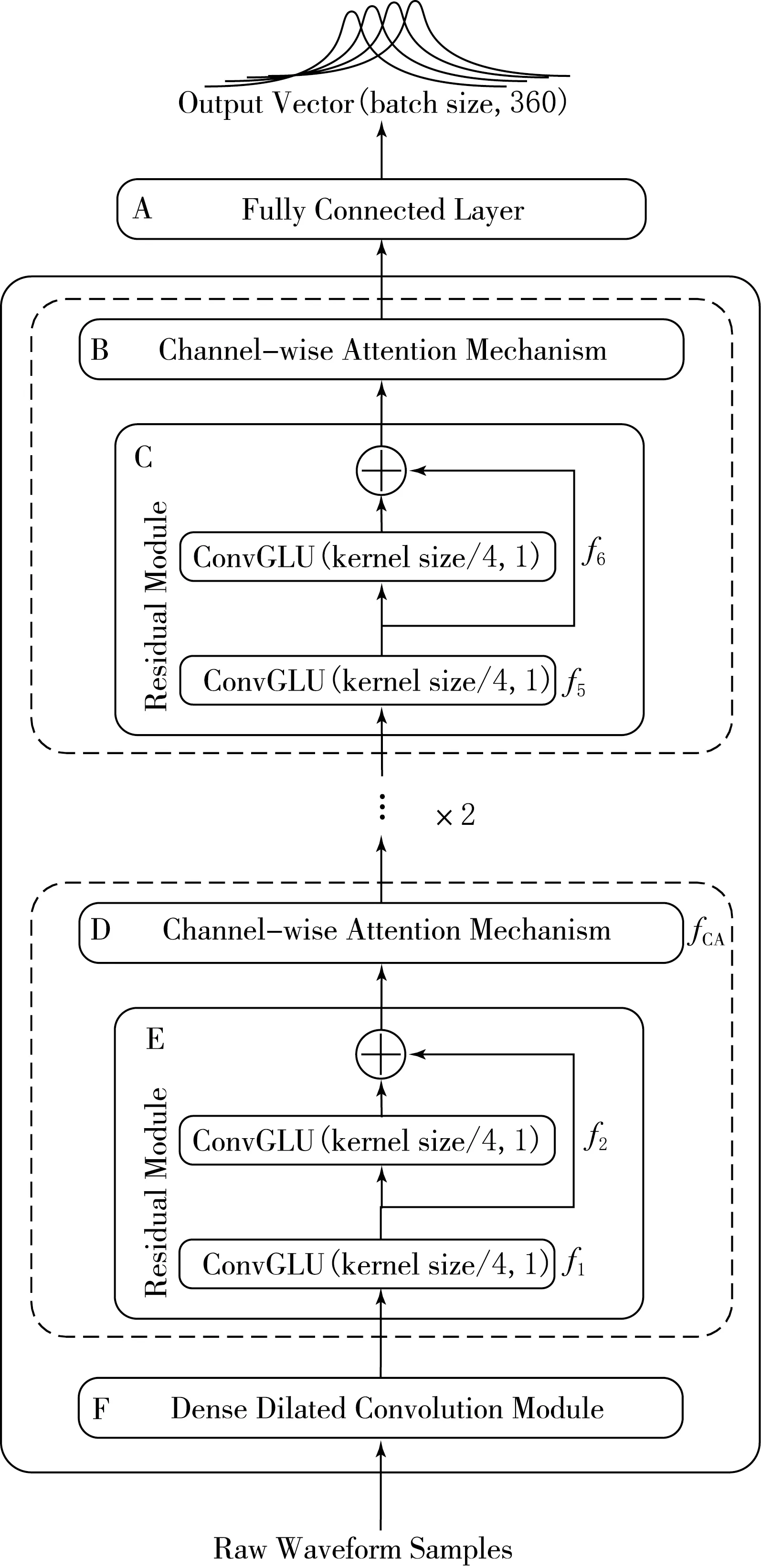
圖1 密集擴張卷積殘差網絡
1.2 密集擴張卷積模塊
對圖1中DDC模塊的詳細框圖如圖2所示.在DDC模塊中,所有以前的卷積層的輸出特征均送入當前卷積層,而當前卷積層輸出的特征又會送入后續的卷積層.這種將所有特征圖相互拼接的連接方式可以在一定程度上緩解梯度消失問題,并且能夠加強特征映射的傳遞,還可以重用這些特征.而擴張卷積則可以在不增加計算量和不丟失特征的前提下,增加卷積計算的感受野并系統地聚合多尺度上下文信息.圖2中左上角的框表示整個網絡的輸入,即時域音頻信號采樣點.該圖中前4個框分別表示擴張因子d為1,2,4,8,卷積核為64的一維卷積神經網絡層(Conv1d),第5個框表示卷積核為1的標準一維卷積神經網絡(Conv1d).第1個擴張卷積層的輸出與其輸入按通道維度進行拼接后作為第2個擴張卷積層的輸入,以此類推.最后將4個擴張卷積層的輸出特征與網絡的初始輸入進行拼接,再經過卷積核為1的標準一維卷積層來整合不同通道的特征.最后,將DDC模塊的輸出通過一個大小為4×1的平均池化層,對輸出特征按照時間維度進行降維操作.DDC中第l層的輸出xl接收了前面所有層的特征圖,表示為
(5)
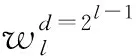
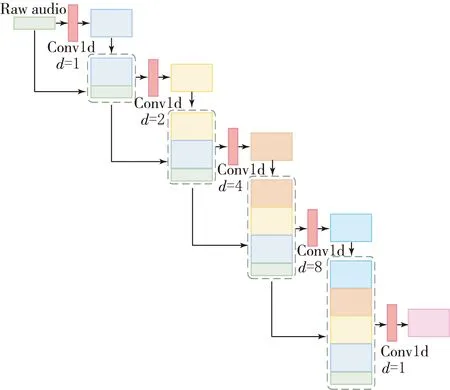
圖2 密集擴張卷積模塊
1.3 殘差模塊和通道注意力模塊
圖1中包含2個卷積門控線性單元和殘差跳躍連接的殘差模塊(Residual Module),其框圖如圖3所示,其中ConvGLU是卷積門控線性單元.ConvGLU中有2個CNN,它們的卷積核大小(kernel size)、步長(stride)和池化大小(pooling size)都設置為相同的數值.ConvGLU下半部分的卷積學習特征圖中每一個重要的特征元素并通過乘法操作重新加權每一個特征元素.圖3中第一個ConvGLU(w,4)表示2個卷積操作的卷積核大小設為w、步長設為4,該ConvGLU不僅用于學習輸入的特征,還用于對時域特征進行降維操作.第2個ConvGLU(w/4,1)表示包含的2個卷積操作中卷積核大小設為w/4(即為前一個卷積核大小的四分之一)、步長設置為1,因此該ConvGLU只用于學習特征而不改變輸入數據的尺寸.將后一個ConvGLU模塊的輸入與其輸出相加,構成殘差跳躍連接.在跳躍連接中,信息可以直接從當前層向后傳遞到下一層,通過加法進行融合.跳躍連接可以避免梯度消失以提高訓練的有效性.
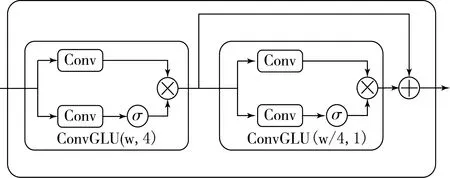
圖3 殘差模塊
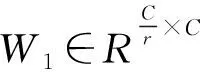
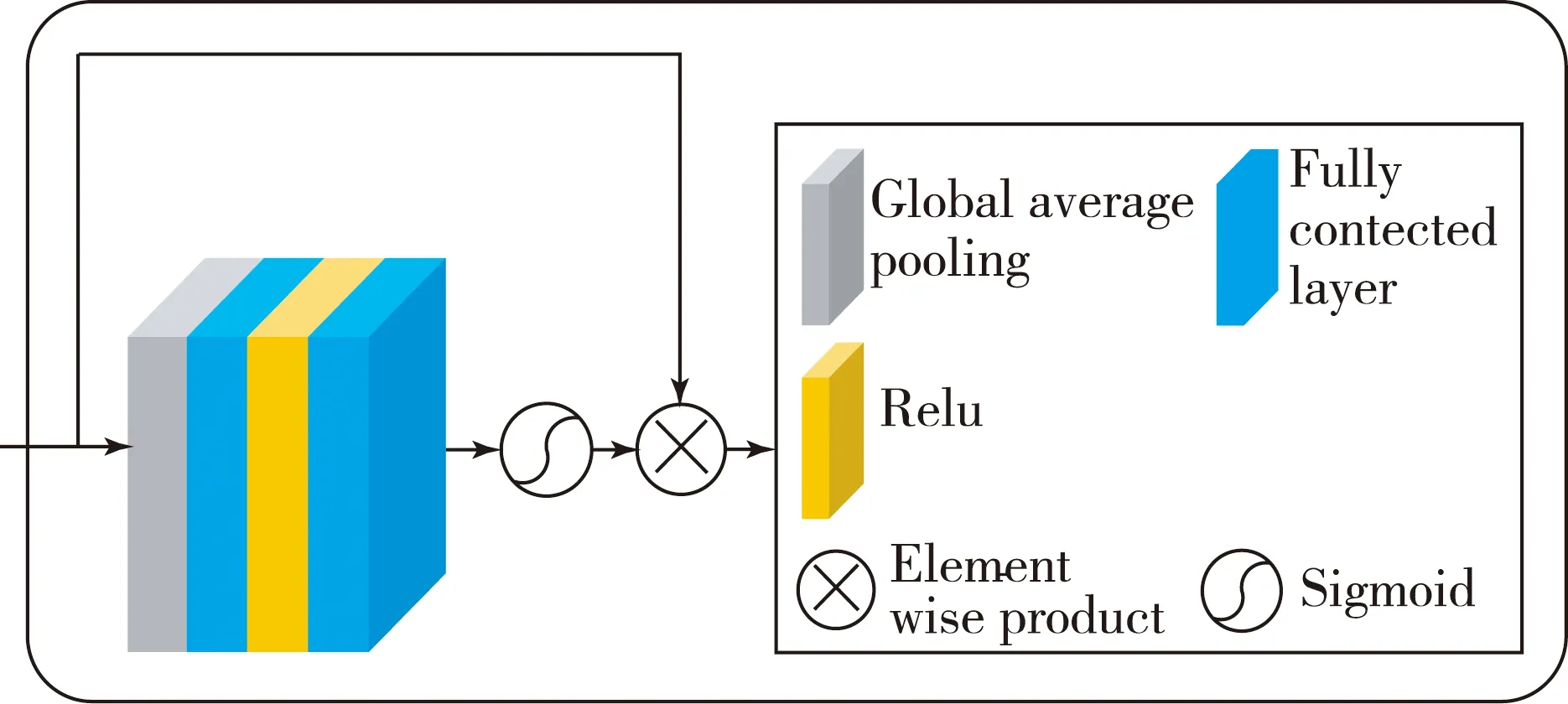
圖4 通道注意力模塊
2 實驗數據和網絡參數
本文提出的密集擴張卷積殘差網絡的單音音樂音高估計模型,分別在iKala[26]、MDB-stem-synth[27]和MIR-1K[28]3個數據集上進行訓練.iKala數據集包含252個歌曲片段,每一條音樂的長度都是30 s,采樣頻率為44 100 Hz.音樂伴奏和歌唱聲音分別在左右聲道錄制.MDB-stem-synth是來自MedleyDB的230個單音音頻片段的集合,它使用分析/合成方法[27]生成合成音頻,并提供完美的F0注釋,以保持原始音頻的音色和動態跟蹤.該數據集包含230個曲目,25個樂器,總時長為15.56 h.MIR-1K數據集是中文流行歌曲數據集,包含1 000首歌曲剪輯,分別在左聲道和右聲道錄制音樂伴奏和唱聲,總長度為133 min.本文僅用iKala和MIR-1K的唱聲為樣本進行訓練.對3個數據集進行了相同的處理.首先,原始音頻樣本被重新采樣到16 kHz.音高估計網絡的輸入是1 024個采樣點(幀長).對數據集做分幀處理,采用的幀移(hop size)分別為160(MDB-stem-synth、MIR-1K)和512(iKala).其次,所有幀樣本都被歸一化為零均值和單一方差后再送入網絡中.
本文采用二進制交叉熵損失函數,ADAM[29]優化器,初始學習率設為0.000 1.每個卷積層之后進行ReLU激活和批規一化(BN),批大小(batch size)為512.DDCRN的輸入是原始時域波形,輸出屬于每個可能音高類的基頻概率向量.輸出的360個點對應一個特定的音高值,以音分定義.音分是相對于參考音高fref(Hz)的音程單位,定義頻率f(Hz)的函數為
(6)
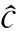
(7)
(8)
按照文獻[14]中的設置,為了減輕對接近正確預測的懲罰,目標在頻率上是高斯模糊的,以標準差為25音分圍繞真實頻率能量衰減為
(9)
這樣,360維的輸出中,高的激活表明輸入信號的音高可能接近與高激活節點相關聯的音高.
3 實驗結果及分析
本文提出一種用于單音音樂音高估計的密集擴張卷積殘差網絡.同時在iKala、MDB-stem-synth和MIR-1K 3個數據集上驗證了殘差網絡、注意力殘差網絡、注意力門控殘差網絡和密集擴張卷積殘差網絡的評價指標.還探討了前3種模塊中通道數的設置對網絡參數量及其性能的影響.根據實驗評價指標可知,密集擴張卷積殘差網絡性能最佳.
3.1 兩種通道數設置的各種殘差網絡性能對比
在iKala、MDB-stem-synth和MIR-1K數據集上分別訓練兩種通道數設置的不同殘差網絡.RN表示只包含4個標準卷積殘差模塊的殘差網絡,卷積殘差模塊是由兩個一維卷積和一個殘差跳躍連接構成,前一個CNN層在學習特征的同時還用于對時間維度特征進行降采樣,后一個CNN層則只學習特征并保持數據維度不變,將兩個CNN層的輸出相加后送入下一個卷積殘差模塊.+SE表示RN中4個卷積殘差模塊的輸出分別送入4個相同的通道注意力模塊的注意力殘差網絡.+SE+GLU表示在+SE網絡的基礎上,應用卷積門控線性單元(ConvGLU)替代殘差模塊中標準卷積的注意力門控殘差網絡.+SE+GLU+DDC代表的是用DDC模塊替代+SE+GLU中的第一個殘差模塊和第一個通道注意力模塊的密集擴張卷積殘差網絡(DDCRN).這4種網絡的輸入均是歸一化為零均值和單一方差后的幀級時域波形.注意力門控殘差網絡(+SE+GLU)中包含8個ConvGLU層,每一個ConvGLU層中的卷積核大小、步長以及神經元的個數均如表1所示,表1列出了兩種通道數設置:輸出_s和輸出_t,s和t分別是small和tiny的縮寫.本文探討這兩種不同的通道數設置思想來源于CREPE_s、CREPE_t[13].
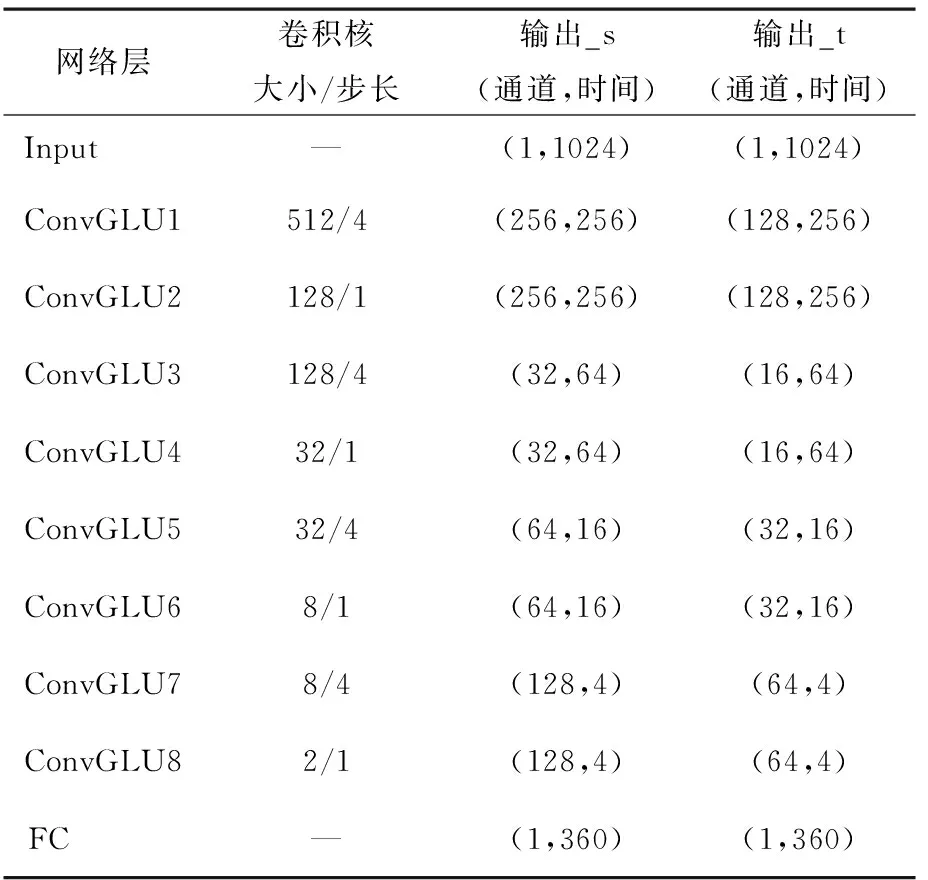
表1 注意力門控殘差網絡中的參數
原始音高準確率(Raw Pitch Accuracy,RPA)指估計的音高值在真實標簽的±1/4音調(50音分)以內的濁音幀所占的比例.原始色度準確率(Raw Chroma Accuracy,RCA)是指估計的音高值和真實標簽均映射到同一個八度音后,估計音高值在真實標簽的50音分以內的濁音幀所占的比例.它給出了忽略倍頻程誤差的情況下測量音高準確率的方法.表2列出iKala數據集上不同殘差網絡的音高估計評價指標.表3顯示MDB-stem-synth數據集上不同殘差網絡的評價指標.表4顯示的是表2和3中所有這些網絡在MIIR-1K數據集上的評價指標.
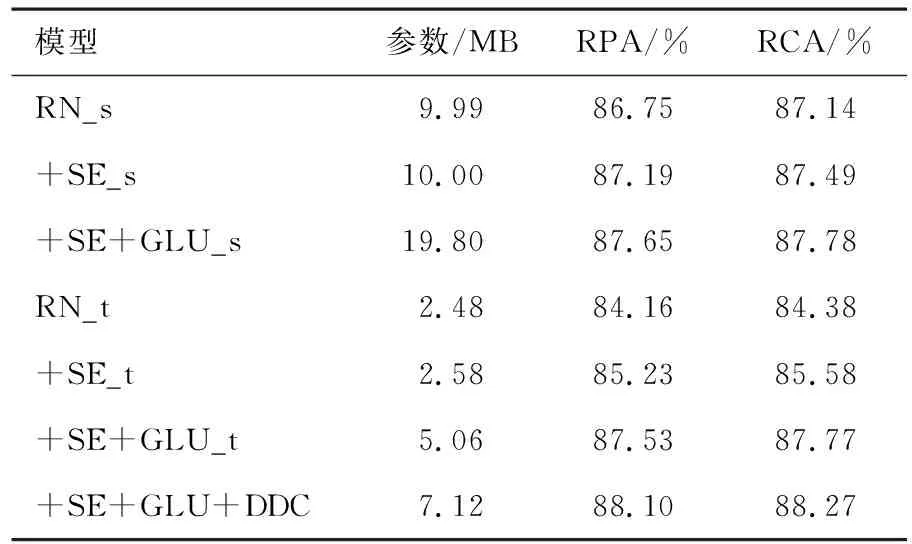
表2 iKala數據集上不同殘差網絡的評價指標
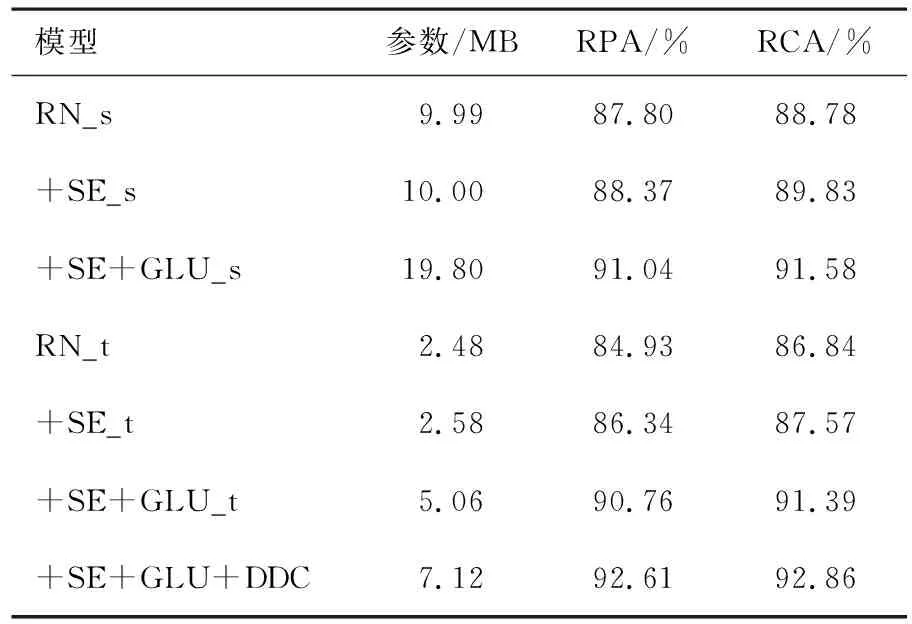
表3 MDB-stem-synth數據集上不同殘差網絡的評價指標
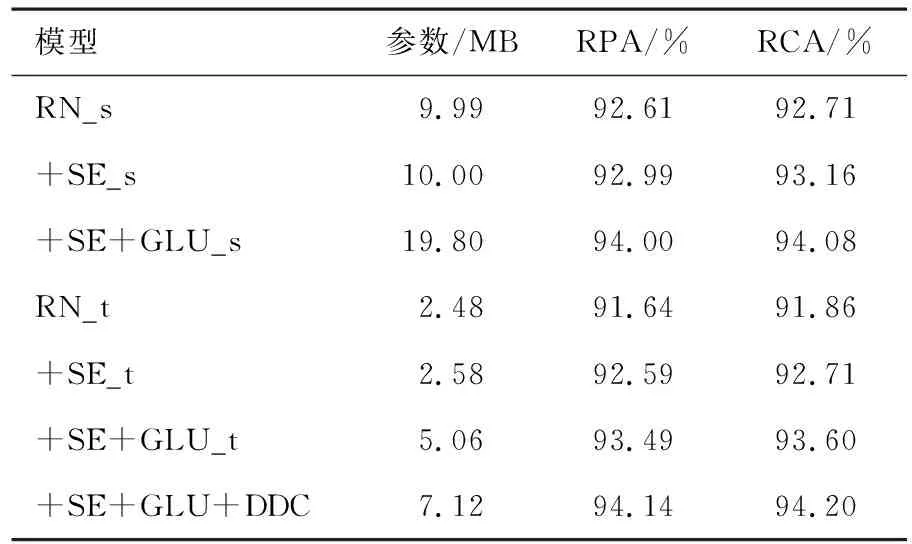
表4 MIR-1K數據集上不同殘差網絡的評價指標
從表2-4中的消融實驗結果可以看出,在3個不同的數據集上不同網絡的評價指標不同.在這3個數據集以及兩組不同的通道數設置下,+SE、+SE+GLU的評價指標均高于RN.由上述3個表中的評價指標可以看出,RN_s、RN_t的評價指標依次降低,參數也依次降低.本文探究音高估計性能較好的情況下,降低模型的參數.從表2—4中還可以看出RN_s、+SE_s和+SE+GLU_s的參數大約是RN_t、+SE_t和+SE+GLU_t參數的4倍,但性能相差不大.從表2—4中還可以看出,RN、+SE、+SE+GLU、+SE+GLU+DDC的性能逐漸增加.在3個數據集上,+SE+GLU+DDC的參數較小且性能最佳.
在iKala數據集上,可以看出通道注意力模塊會少量增加網絡的參數,但提升了網絡的性能.+SE+GLU_t比+SE_t和RN_t分別高2.30%,3.37%(RPA)和2.19%,3.39%(RCA).+SE+GLU+DDC的結果比RN_t、+SE_t和+SE+GLU_t分別高3.94%,2.87%,0.57%(RPA)和3.89%,2.69%,0.50%(RCA).在MDB-stem-synth數據集上,+SE_s的性能優于RN_s,而+SE+GLU_s比+SE_s和RN_s分別高2.67%,3.24%(RPA)和1.75%,2.80%(RCA).+SE+GLU+DDC的結果比RN_t、+SE_t和+SE+GLU_t分別高7.68%,6.27%,1.85%(RPA)和6.02%,5.29%,1.47%(RCA).在MIR-1K數據集上,可以看出+SE+GLU_s的評價指標比+SE_s、RN_s分別高1.01%,1.39%(RPA)和0.92%,1.37%(RCA).+SE+GLU+DDC的結果比RN_t、+SE_t和+SE+GLU_t分別高2.50%,1.55%,0.65%(RPA)和2.34%,1.49%,0.60%(RCA),由此可知在3種數據集上,密集擴張卷積殘差網絡參數較小并且性能最佳.
3.2 與其他算法對比
實驗中,提出的DDCRN模型還與pYIN[5]、SWIPE[6]、CREPE[13]和SPICE[19]算法進行了對比.pYIN和SWIPE是經典的傳統音高估計算法,CREPE是深度卷積神經網絡音高估計算法,SPICE是基于自監督訓練的神經網絡音高估計算法.MIR-1K數據集上不同方法的評價指標見表5.SWIPE的結果來自文獻[23].CREPE的結果是將該網絡只在MIR-1K數據集上進行訓練并測試得到的結果.在文獻[19]中,只報道了RPA的值,而沒有RCA的值.根據實驗結果可知,DDCRN在RPA上的平均得分分別比SWIPE、CREPE和SPICE高5.41%,1.10%和3.54%,在RCA上的值比SWIPE和CREPE高4.96%和1.03%.
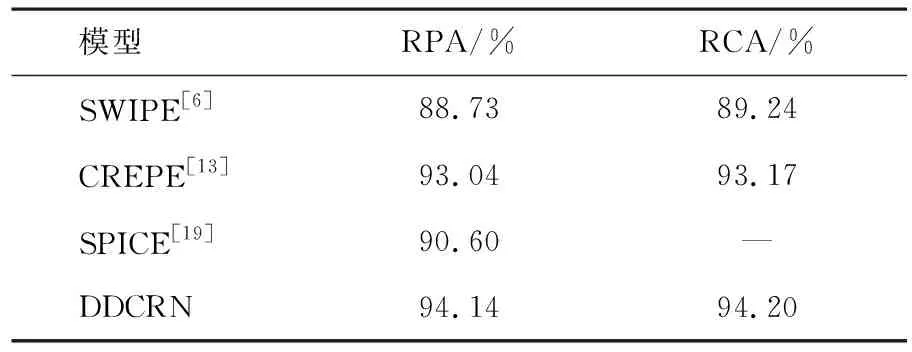
表5 MIR-1K數據集上不同方法的評價指標
MDB-stem-synth數據集上不同方法的評價指標見表6.pYIN和SWIPE的結果來自于文獻[13].CREPE的評價指標是在MDB-stem-synth數據集上重新訓練和測試得到的.在文獻[19]中,只報道了MDB-stem-synth數據集上的RPA的值,而沒有RCA的值.根據不同方法的評價指標,可以看到DDCRN在RPA上的值比pYIN、SWIPE、CREPE和SPICE高0.71%,0.11%,5.06%和3.51%,在RCA上的值比CREPE高3.33%.

表6 MDB-stem-synth數據集上不同方法的評價指標
分別繪制了DDCRN模型對iKala和MIR-1K數據集中的一個片段估計的音高輪廓及其對數頻譜,并將它們與標簽進行對比.iKala數據集的音高標簽是以半音為單位,任選iKala數據集中的一條語音45422_verse.wav,繪制其中10 s的語音波形,頻譜及標簽和估計的音高如圖5所示.
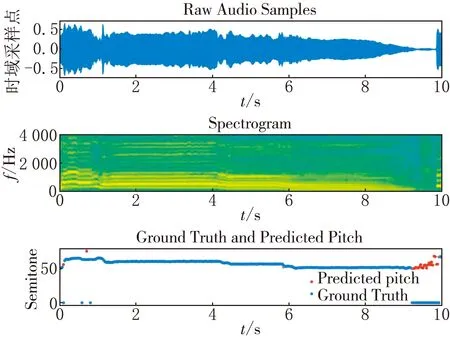
圖5 iKala數據集中音樂片段的時域波形、 頻譜以及標簽和預測音高的對比
DDCRN估計的MIR-1K數據集中的一個片段的音高輪廓及其對數頻譜見圖6,并將它們與標簽進行了對比.
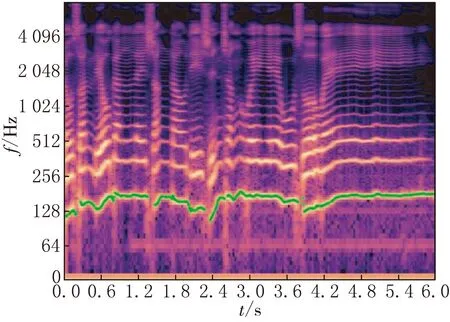
(a)在對數頻率譜上繪制真實音高輪廓
4 結束語
本文提出了一種用于單音音樂音高估計的DDCRN,直接對幀級時域波形進行處理.探討了殘差網絡(RN)、注意力殘差網絡(+SE)和注意力門控殘差網絡(+SE+GLU)在兩種不同的通道數設置下的模型大小和評價指標.分別在iKala、MIR-1K和MDB-stem-synth數據集上訓練上述殘差網絡,并且將DDCRN與RN、+SE、+SE+GLU進行了對比,可知DDCRN在3個數據集上的性能最好.然后將DDCRN與已報道的4種算法進行對比.根據實驗結果,可以得出以下結論:(1)tiny通道數設置的網絡參數量是small通道數設置參數量的1/4,且音高估計性能相差不大.(2)在3個數據集上,DDCRN的性能均優于RN、+SE、+SE+GLU.(3)DDCRN與現有算法進行對比,可以看到在MDB-stem-synth數據集上,本文提出的DDCRN的評價指標優于pYIN、SWIPE、CREPE和SPICE.在MIR-1K數據集上,DDCRN的評價指標優于SWIPE和SPICE.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
河南科技(2014年23期)2014-02-27 14:19:15
