基于深度學習的評分預測社交推薦
2022-09-28 09:17:38劉藝璇孫英娟李婉樺楊丹陽
東北師大學報(自然科學版) 2022年3期
劉藝璇,孫英娟,李婉樺,楊丹陽,劉 乾
(長春師范大學計算機科學與技術學院,吉林 長春 130032)
0 引言
推薦算法研究的目的就是針對海量數據進行數據挖掘,獲取用戶感興趣的數據,把它們推薦給相關的用戶[1].而隨著數據規(guī)模增大和互聯網不斷發(fā)展,傳統的推薦算法模型已經不能滿足人們的日常生活,研究者們想到把多種傳統的推薦算法結合起來,或者在深度學習的基礎上進行研究,這些研究都取得了一些不錯的效果.
國內外的一些研究者們對基于深度學習推薦算法做了一些深層次的研究,Lin等[2]提出了GNN-DSR模型,該模型分別對用戶興趣和項目吸引力的短期動態(tài)和長期靜態(tài)交互表示進行建模,使用從多個角度獲取的特征來進行評分預測;He等[3]提出的NeuMF模型,它采用了一種基于神經網絡的矩陣分解模型,其初始實現是根據推薦排序的任務,將其損失調整為一個平均損失值來進行評分;Wu等[4]通過將社交推薦重構為具有社交網絡和興趣網絡的異質圖來建模用戶影響擴散和興趣擴散;Cui等[5]所提出的LT算法,在模型中增加了使用者的信任信息,并將使用者的標簽信息納入到模型中,以此為基礎,通過對用戶的標記進行分析,對用戶間的信任度進行了評估,并將兩者相結合,進行了預測.基于卷積神經網絡(CNN)的推薦模型[6-8],利用卷積神經網絡研究了歌曲信息,獲得歌曲的潛在特征,并計算用戶潛在向量和歌曲潛在向量之間的相似性,從而緩解了新歌曲的冷啟動問題.Gu等[9]將項目圖嵌入和情境社會建模納入推薦任務中,提高了推薦算法的性能.
雖然結合深度學習的融合算法很常見,但利用圖神經網絡(Graph Neural Network,GNN)獲得用戶和物品之間的關聯,得到用戶和物品的潛在特征,再用AFM(Attention Factorization Machine)將這兩者結合起來,預測用戶對物品的評分,并將這些模型融合起來的方法卻很少,因此本文提出混合模型REC_AFM.
1 本文算法
1.1 相關模型
社交推薦算法中的數據可以表示為圖數據.如圖1所示,左邊表示用戶之間的關系社交圖,連線代表彼此之間存在一定聯系,有時也會用數字標注用戶之間的聯系緊密程度.右邊表示用戶和物品之間存在購買行為和評分的用戶物品圖,如圖1中某用戶對音頻產品評分為1,對筆記本電腦的評分為3,對書籍的評分為5.
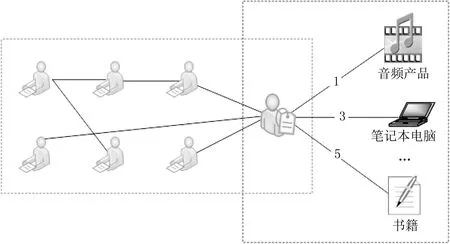
圖1 社交推薦中的圖表數據圖
本文提出基于深度學習和AFM算法的混合模型REC_AFM,算法模型如圖2所示.該模型由三個部分組成:用戶建模模塊、物品建模模塊和評級預測模塊.第一部分是用戶建模(User Model),利用圖神經網絡從用戶物品圖和用戶社交圖獲得用戶的潛在特征;第二部分是物品建模(Item Model),本模塊將用戶與物品的購買行為及打分結合起來,以了解物品的潛在特征;第三部分是評級預測模塊(Rating Prediction),通過AFM將用戶和物品的潛在特征聯系起來,預測用戶對物品的評分.
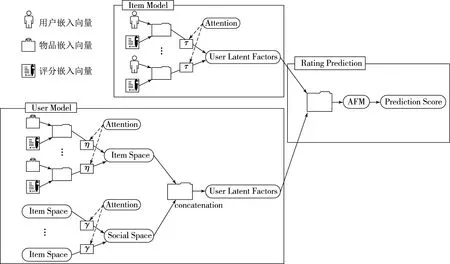
圖2 REC_AFM算法模型
1.2 用戶建模模塊
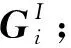
1.2.1 物品聚合
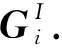
(1)
其中:f為非線性激活函數;W表示權重;b表示偏差;Aggi是物品item的聚合函數;Oia表示用戶ui與物品Ij之間的評分感知交互的向量;C(i)是用戶物品圖(user-item)中用戶ui的鄰居.通過多層感知器(MLP)將評分感知交互進行建模.bv可以表示為將交互信息與意見信息融合在一起.物品嵌入pa及其評分嵌入gr的串聯作為MLP輸入,MLP的輸出是Oia,它表示物品和評分之間交互,所以Oia可以用數學公式表示為
Oia=bv([pa?gr]).
(2)
Aggi是一種聚合函數,也叫作均值運算符,在其中取向量元素的均值{Oia,?A∈C(i)}.所以,公式(1)可以化簡為
(3)
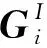
(4)
(5)
(6)
1.2.2 社交聚合
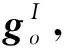
(7)
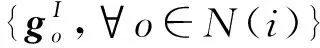
(8)

(9)
(10)
(11)
1.2.3 學習用戶潛在特征
(12)
d2=f·[W2·d1+b2];
(13)
…
Gi=f·[Wl·dl-1+bl].
(14)
1.3 物品建模模塊
物品建模的目的是用來學習用戶聚合得到物品Ij的潛在特征,表示為Mj.本文使用了一種通過用戶聚合來學習空間物品潛在特征的方法.對于每個物品Ij,需要從與物品Ij交互的用戶集合中聚合信息,表示為B(j).引入一種用戶對物品的評分意見表示為Yjt,hu是通過MLP從基本用戶和評分embedding(qi,gr)得到的,hu用來融合交互信息和評分信息,Yjt可以定義為
Yjt=hu([gr?qi]).
(15)
為了學習物品潛在特征Mj,在B(j)中為物品Ij聚合用戶的評分意見交互表示.用戶聚合函數表示為Aggu,用于聚合用戶的評分交互,Mj表示為
Mj=f(W·Aggu({Yjt,?t∈B(j)})+b).
(16)
引入了一種注意力機制,以Yjt和物品信息的嵌入pa為輸入,通過兩層神經注意網絡區(qū)分用戶的重要性權重τjt,物品潛在特征Mj可以用函數表示為:
(17)
(18)
(19)
1.4 評分預測模塊
使用AFM將用戶潛在特征Gi和物品潛在特征Mj結合起來,用來預測某用戶對未評分物品的評分.AFM的結構劃分為5個部分:Sparse Input(輸入層)、Embedding Layer(嵌入層)、Pair-wise Interaction Layer(雙向交互層)、Attention-based Pooling(注意力聚合層)、Prediction Score(評分預測).AFM的Sparse Input和Embedding Layer都與FM相同,對輸入的特征用稀疏矩陣來表示.
Pair-wise Interaction Layer采用的是對Embedding向量進行各個元素對應相乘(element-wise product)交互,用函數表示為
fPI(ε)={(Gi⊙Mj)xixj}(i,j)∈Rx.
(20)
其中:⊙表示元素對應相乘;Rx={(i,j)}i∈X,j∈x,j>i,這里的X是非零特征經過embedding層之后得到的embedding集合;Gi∈Rk表示的是用戶潛在特征的嵌入向量;Mj∈Rk表示的是物品潛在特征的嵌入向量,k表示嵌入向量的大小.最終的預測值可以定義為
(21)
其中p∈Rk,b∈R分別表示預測層的權值和偏差.Attention-based Pooling Layer根據對預測結果的影響程度給其加上不同權重,允許它們做出不同的貢獻.因此,提出采用特征交互的注意力機制,對交互向量進行加權求和,用函數表示為
(22)
其中:aij表示為特征Gi⊙Mj的注意力分數,表示該交互特征對于預測評分的重要性程度.為了解決泛化問題,本文使用了將注意力得分引入多層次感知器(MLP)參數化的方法,即注意力網絡.用數學形式表示為:
(23)
(24)
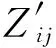
(25)
1.5 模型訓練
要對REC_AFM進行模型參數的估算,必須要有一個可以進行優(yōu)化的目標函數.因為是評分預測,所以目標函數公式為
(26)
其中:|O|是觀察評分的數量,Zij是由物品j的使用者u指定的基本真實評分.為了優(yōu)化目標函數,在實驗中采用RMSprop(Root Mean Square Prop,一種加快梯度下降算法)作為優(yōu)化器.模型中有3種嵌入,分別是物品嵌入pa、用戶嵌入qi和意見嵌入gr,在訓練時隨機初始化開始學習.意見嵌入矩陣e取決于系統的評分范圍.為了緩解過擬合問題,將dropout正則化方法用于該模型,即在訓練過程中,將某些神經元隨意丟棄.
通過MAE、RMSE來評估本文模型.為了評估推薦算法性能的好壞,使用了兩個常用的評估指標,即:平均絕對誤差(MAE)和均方根誤差(RMSE),隨著 MAE、RMSE的降低,其預測準確率也相應地提高.MAE與RMSE的公式為(其中Rtest為測試集的評分矩陣):
(27)
(28)
2 實驗結果分析
2.1 數據集
本文采用的數據集是Ciao.它擁有7 317個用戶,104 975個物品,111 781個社交關系.它是一個在線消費者購物網站,記錄用戶對帶有時間戳商品的評分,用戶還可以將其他人添加到好友列表中,并建立社交關系.因此,它們提供了大量的評分信息和社交信息.我們根據從1—5的評分,使用對應的嵌入向量,來初始化數據集的評分embedding.該數據集如表1所示.

表1 采用的數據集
2.2 模型參數與模型性能對比
在本文的模型REC_AFM中,研究的數據集劃分為:訓練數據集占80%,用于擬合本文模型;驗證數據集占10%,用于調整超參數以避免過擬合;測試數據集占10%,用于評估模型在訓練過程中對看不見數據的表現.
如圖3所示,所提出的模型在Ciao數據集上的嵌入大小對推薦效果有影響.當嵌入大小為256時,RMSE和MAE較大.然而,如果嵌入的長度太大,模型的復雜性也顯著增加.當嵌入大小從8增加到64時,RMSE和MAE最小,因此嵌入大小為64最合適.其他設置的參數值如表2所示.
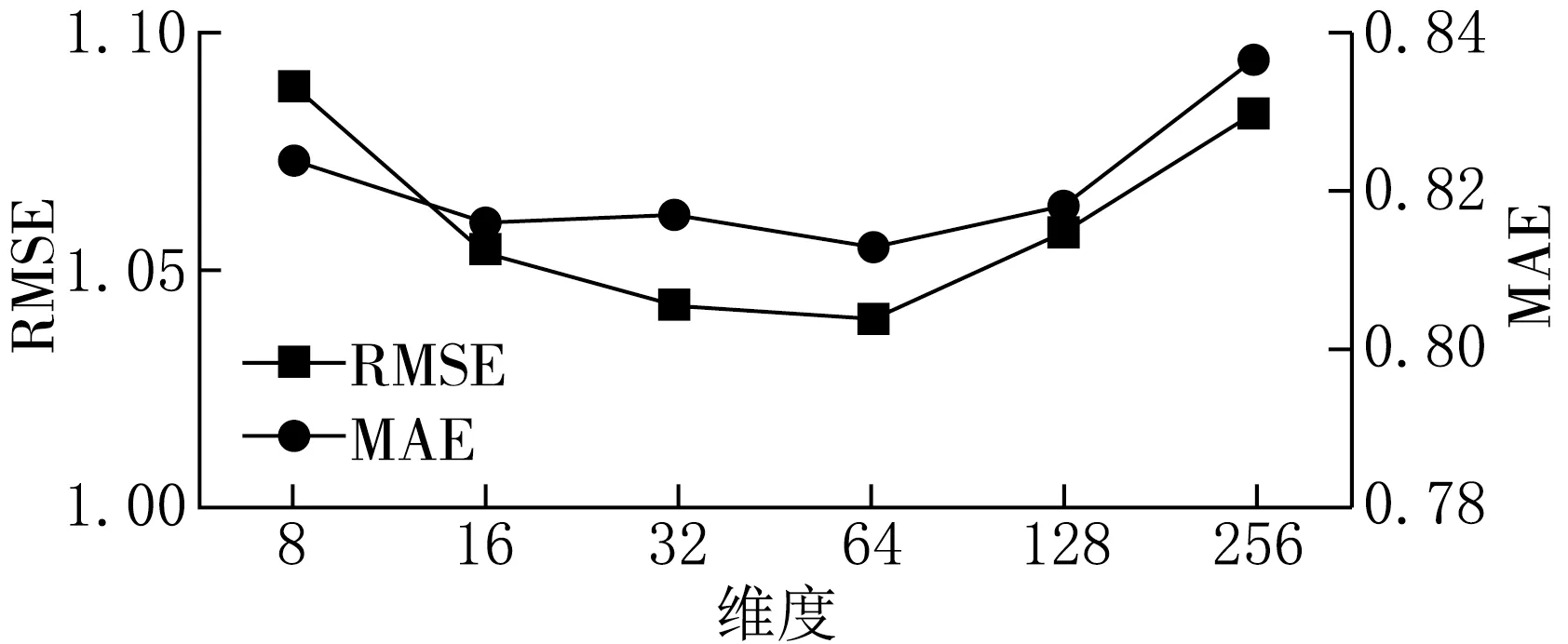
圖3 嵌入大小與RMSE、MAE的關系
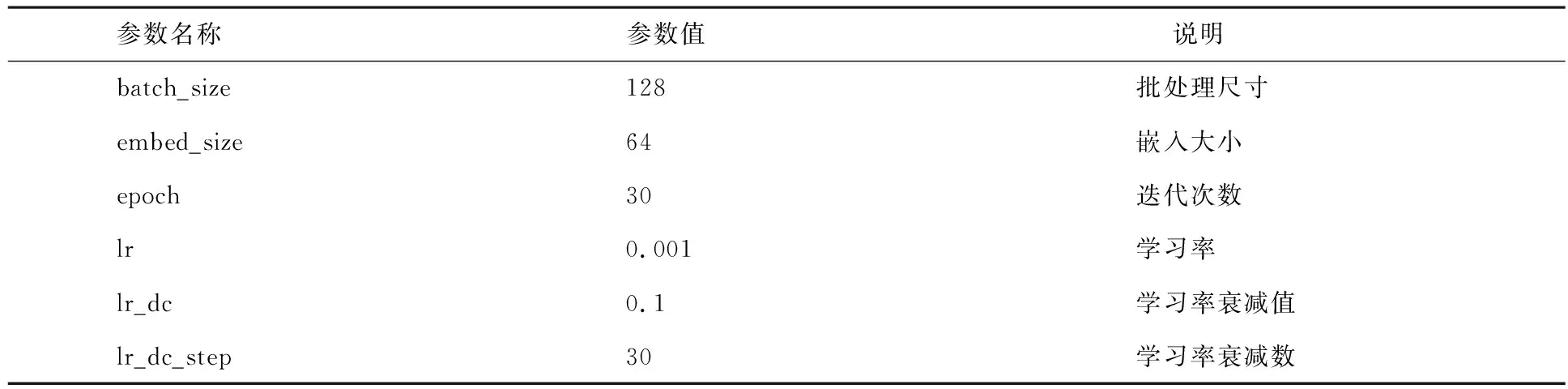
表2 參數設置
將本文方法REC_AFM與PMF、SoReg、SocialMF、NeuMF方法進行比較,結果如表3所示.PFM[11]:是一個基于概率矩陣分解的算法,該方法僅使用了用戶物品的評分矩陣,并運用了高斯分布的方法來獲得用戶和物品的潛在特征.SoReg[12]:社交規(guī)則信息將社交網絡信息建模為正則化項,屬于一個約束矩陣分解的框架.SocialMF[13]:在推薦系統矩陣分解模型中,引入了信任信息,并討論了其傳播問題.NeuMF[3]:一種新的基于神經網絡的矩陣分解模型,該算法首先考慮了推薦排序的問題,最后將其損失調整為平方損失進行評分預測.

表3 不同推薦算法的性能比較
PMF是不包含社交網絡信息的純協同過濾模型,用于評分預測,其他模型均為社會推薦.SocialMF、SoReg的表現優(yōu)于PMF,SocialMF是利用評分和社交網絡信息進行預測,SoReg將社交網絡信息建模為正則化項,而PMF只使用評分信息,這說明社交網絡信息是評分預測推薦算法中的一個較為重要因素.NeuMF在性能上略優(yōu)于PMF,兩個算法都僅采用了評分的信息,然而NeuMF是一種基于神經網絡的推薦算法,這說明神經網絡在推薦算法中能讓推薦性能更優(yōu)秀.綜上所述,對比結果表明:(1)社交網絡信息使推薦算法更準確;(2)加入神經網絡模型能提高推薦算法性能.
從表3可以看出,本文研究的結果比PMF、SoReg、SocialMF和NeuMF算法都要好.因為MAE和RMSE值越小,表示預測準確率越高,在表3中可以看出本文提出的模型與其他4種算法模型相比,MAE和RMSE都是最低的,MAE為0.803 6,RMSE為1.054 4.意味著推薦效果更好,預測的評分更準確,本文方法REC_AFM優(yōu)于所有的對比算法.
3 結語
REC_AFM是用于評分預測推薦的一種方法,它是一種以深度學習為基礎的融合算法,該算法利用GNN,首先從用戶物品圖和用戶社交圖中學習用戶的潛在特征,再通過用戶聚合來獲得物品空間中物品的潛在特征,最后利用AFM算法將得到的兩個特征相結合,來預測用戶對未評分物品的評分,獲得了較好的推薦結果.通過對Ciao公共數據集的仿真試驗,證明了該方法在一定程度上能有效提高推薦算法的性能.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
