基于半監督學習模型的協同過濾推薦算法
2022-09-28 09:17:34崔瑩瑩王紅霞
東北師大學報(自然科學版) 2022年3期
崔瑩瑩,陳 卓,王紅霞
(青島科技大學信息科學技術學院,山東 青島 266061)
0 引言
隨著信息技術以及互聯網的快速發展,推薦系統已成為一個領域中不可或缺的關鍵要素之一,其主要目的是在“信息過載”的大環境下,為用戶精準推薦其感興趣的事物,減少“選擇困難”,提高選擇效率,因此被廣泛應用于各領域,例如淘寶、音樂軟件、論壇等.推薦算法是推薦系統的核心關鍵,其根據用戶行為和特征以及物品特征等信息來進行推薦.推薦算法又分為協同過濾推薦算法、基于內容的推薦算法、基于物品的推薦算法等,其中協同過濾推薦算法近年來被廣泛應用在各大領域,該算法不依賴于物品內容,僅依靠評分來表示用戶對項目的喜好程度,但用戶與項目之間的交互矩陣常常較為稀疏,數據大多由有標簽數據和無標簽數據組成,且存在數據不均衡問題,嚴重影響推薦效率,也造成了不必要的資源浪費.隨著各領域規模的擴大以及用戶量的不斷增長,解決用戶與項目之間的稀疏性成為推薦系統中亟待解決的核心問題.
為了解決上述問題,本文提出基于半監督學習模型的協同過濾推薦算法,并通過對比實驗驗證了所提出算法的有效性.
1 相關工作
推薦系統被用來將信息元素(電影、書籍等)推薦給可能對其感興趣的社會元素(人、組織等).
推薦算法可以通過挖掘用戶偏好來幫助用戶篩選信息,較為傳統的推薦算法是結合協同過濾的思想,該思想根據用戶的歷史行為找到與目標用戶興趣愛好相似的一組用戶集合,進而對目標用戶推薦這組用戶集合所喜好的項目[1].
Sedhain等[2]提出結合自編碼器的協同過濾算法,預測出丟失的評分,提高了物品之間相似度計算的準確性;在此基礎之上,霍歡等[3]提出棧式降噪自編碼器的標簽協同過濾推薦算法,進一步解決了數據的稀疏性問題,但該模型的算法復雜度較高,性能不佳;王根生等[4]通過計算不同元路徑下的用戶相似度,得出用戶相似度矩陣,然后將其融合到矩陣分解推薦算法的目標函數中;JAMALI等[5]提出的SocialMF模型將信任傳播機制引入到矩陣分解中;HE等[6]提出的NeuMF模型將多層感知機與傳統矩陣分解相結合,可以同時抽取低維和高維的特征;羅達雄等[7]提出了一種基于隱性行為的問題解決者推薦算法,通過計算基于標簽的隱性行為變量,解決問題的傾向性變量,并結合能力變量使用貝葉斯多變量回歸得到開發者得分,排序后進行推薦.
上述算法通常較依賴用戶與項目之間的交互信息以產生推薦結果,當數據稀疏性問題加劇時,算法準確率會受到較大影響.
對于推薦系統來說,不僅要依靠現有的用戶/項目交互評分,學習到用戶點擊行為背后的隱性特征向量也十分關鍵.而深度學習具備充分挖掘數據隱含信息的能力,近年來被廣泛應用于自然語言處理、計算機視覺等領域,并通過實踐證明,深度學習方法能夠顯著提高模型性能.鑒于深度學習此前取得的成功,研究人員也逐漸嘗試將深度學習融入推薦系統中,這些方法從特征出發,從不同層次和角度使用相應的深度學習方法完成推薦任務.
馮興杰等[8]提出在利用圖神經網絡提取關聯關系的同時,利用深度學習提取評論的優勢提取用戶和商品的一般偏好,并進行特征融合來提升推薦效果;Cheng等[9]提出Wide&Deep模型,該模型融合深層Deep模型和淺層Wide模型進行聯合訓練,綜合利用深層模型的泛化能力和淺層模型的記憶能力,兼顧了單模型對推薦系統的準確性和擴展性.針對Wide&Deep的淺層特征和深層特征不能交互共享的問題,Huifeng等[10]提出DeepFM模型,該模型在處理稀疏特征時,將稀疏的特征先進行向量化,得到高維稀疏特征,再將其轉化為低維稠密向量,然后將數據共同輸入深度神經網絡與FM[11]相結合的模型中,其中使用FM做特征間低階組合,使用深度神經網絡Deep部分做特征間高階組合,通過并行的方式組合兩個部分.
由于在用戶與項目交互過程中,用戶幾乎不能對每個項目都進行評分,這造成數據中既包含有標簽數據,又存在無標簽數據[12].半監督學習能夠在此種僅存在部分有標簽數據的情況下,使學習模型具有較高的正確率.
在半監督學習的自訓練算法中,為了解決偽標記數據選擇問題,Tanha等[13]使用基于距離的局部度量來確定實例之間的置信度等級,其性能有所提升;Dong等[14]提出的弱標簽的半監督學習算法SSWL,通過考慮實例和標簽相似度來彌補缺失標簽;為了提升分類機器學習模型性能和泛化性,毛銘澤等[15]提出了一種基于權值多樣性的半監督分類學習算法,從基于學習器的不同角度擴展模型的多樣性,提升了模型分類性能.在大多數半監督學習研究中,主要通過集成學習方法來拓展模型或者數據的多樣性,從而提高偽標簽的準確性以提升模型性能.
在推薦系統的研究中,雖然有不少算法在嘗試解決數據稀疏性問題,但由于大多數數據本身較為稀疏的特點,難以訓練出泛化能力強的模型,因而,稀疏性問題依舊是目前推薦系統的研究難點.
2 基于半監督學習模型的協同過濾推薦算法(CFSS)
2.1 CFSS模型
針對目前推薦算法中現存的有評分的用戶/項目交互數據較為稀疏,且尚有部分無評分的用戶/項目交互數據的問題.本文借鑒半監督學習的思想,將有評分的用戶/項目交互數據視為有標簽數據,無評分的用戶/項目交互數據視為無標簽數據,提出一種CFSS模型.算法模型如圖1所示.
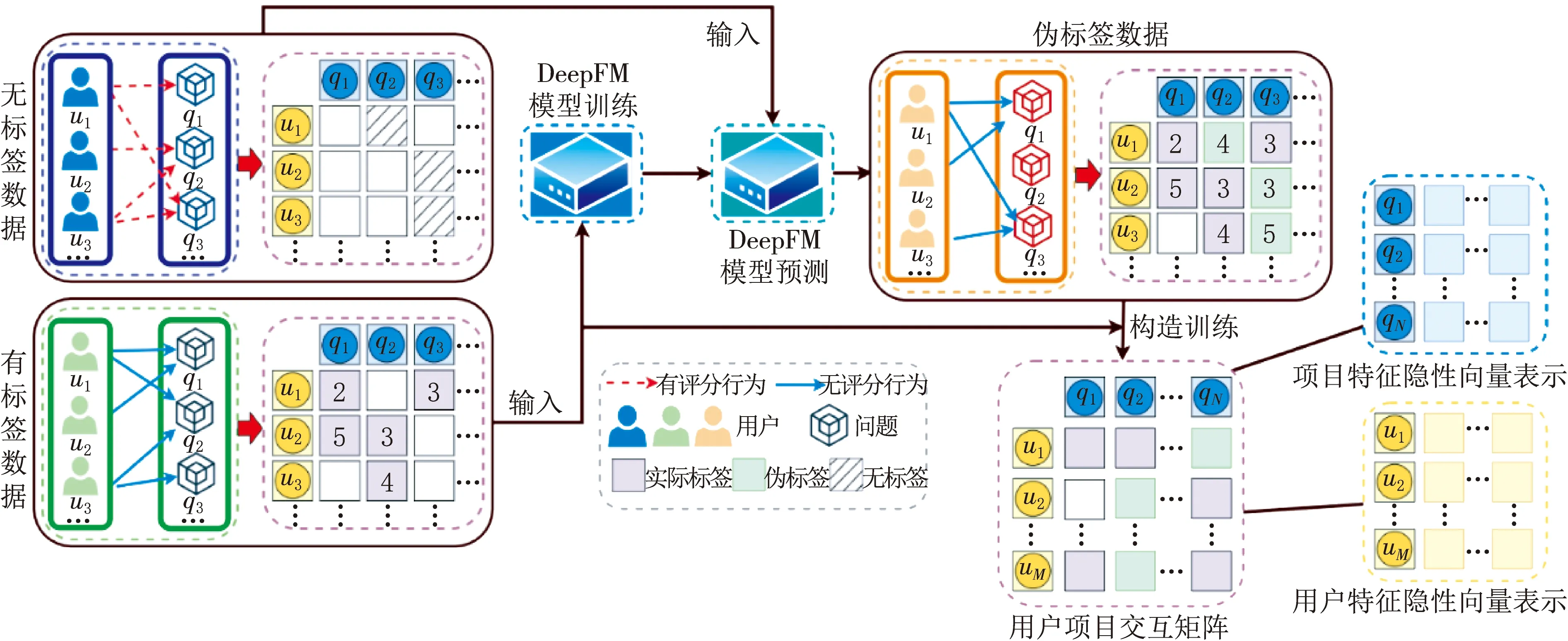
圖1 CFSS模型
CFSS模型算法首先利用有標簽的用戶/項目交互數據和DeepFM模型算法,訓練得到一個評分預測模型,再用該模型預測無標簽數據的評分,得到偽標簽.之后采用原始有標簽數據和偽標簽數據共同構造用戶/項目交互矩陣,并利用交替最小二乘法(alternating least squares,ALS)分解該交互矩陣,從而得到用戶向量表示和項目向量表示,以此來預測空白項的評分.
2.2 評分預測
評分預測部分使用帶評分的用戶/項目交互數據訓練DeepFM模型,并將訓練用的稀疏的交互矩陣中的用戶特征向量和項目特征向量進行拼接后,放入DeepFM模型網絡中作為輸入進行訓練.
為了對用戶特征進行向量表示,將用戶的離散特征經過One-hot編碼轉換后,原來的低維用戶特征轉換為高維的稀疏向量.但為了降低向量維度、增加稠密度提升訓練效果,本文對用戶特征進行自編碼,將高維稀疏向量轉化為低維稠密向量后,再輸入網絡進行訓練.
連續特征內各個數值可能存在差異較大或者其單位(尺度)不同的情況,例如某用戶的在線時間和好友數,因此使用公式對其歸一化處理,避免出現模型訓練速度降低等問題.具體公式為
(1)
其中:x表示實際特征值,μ表示同一特征下的平均特征值,xmax表示最大特征值,xmin表示最小特征值.經過處理,原本差異懸殊的連續特征,都介于0到1之間.
將用戶特征向量和項目特征向量作為DeepFM模型的輸入.DeepFM算法模型如圖2所示.
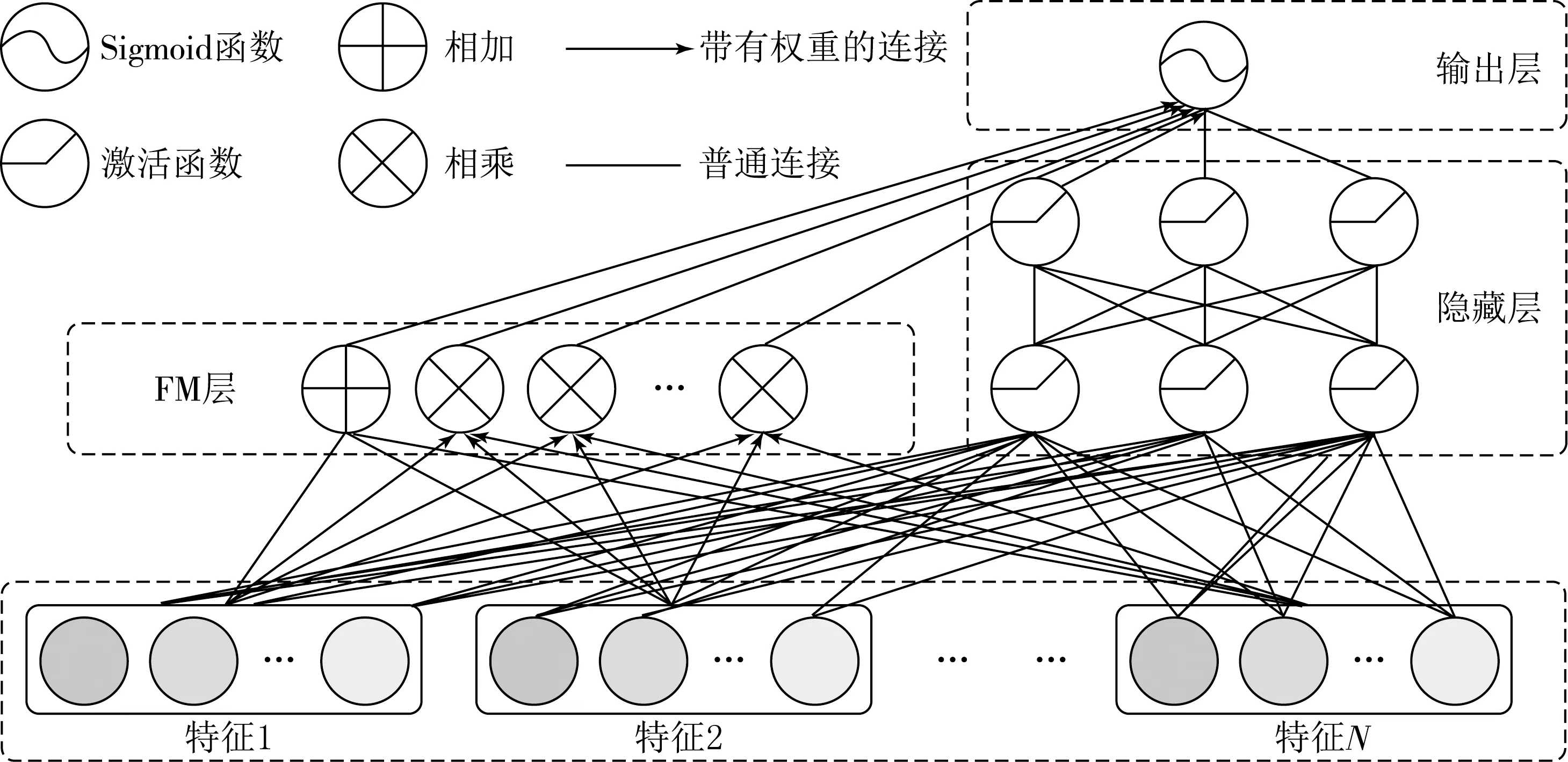
圖2 DeepFM算法模型
模型左側為FM模塊,其具有線性時間復雜度的優越性,能適用基于上下文或基于相關性的推薦.不僅可對一階特征進行建模,還能通過隱性向量點積來獲取二階特征表示,有效解決高維數據的稀疏問題,降低稀疏性對預測結果的影響,將輸入的特征連接為向量x進行輸入,FM模塊計算公式為
(2)
其中:b0表示偏置,wi表示第i個特征的權重,〈vi,vj〉表示第i個特征與第j個特征的相互作用.
模型右側部分是Deep模塊,是一個用于學習高階特征交互的前向神經網絡,可以將稀疏的表示特征映射為稠密的特征向量.其中輸入層和FM模塊共享,中間隱藏層第一層公式為
A(1)=W(0)x+b(0).
(3)
其中:W(0)為初始權重項,b(0)為初始偏置項.
Deep模塊最終的輸出計算公式為
yDNN=WH+1aH+bH+1.
(4)
其中:H表示隱藏層的層數.得到FM模塊和Deep模塊的輸出后,便可以得到最終的預測結果為
(5)
本文用有標簽數據訓練DeepFM算法,得到評分預測模型.然后用該模型為所有無標簽數據預測出偽標簽.
2.3 用戶隱性向量生成
傳統的矩陣分解算法,利用評分信息作為推薦依據,當評分數據稀疏時,不能準確獲取隱式反饋,影響推薦準確性[16].本文使用上一節中有標簽和預測得出的偽標簽兩種用戶/項目交互數據,構建新的用戶/項目交互矩陣之后使用ALS進行矩陣分解.
在推薦系統中矩陣分解(Matrix Factoriza-tion,MF)[17]算法是一種常用的協同過濾推薦方法,它將評分矩陣分解為兩個矩陣,目的是從所有已知評分數據中學習用戶的隱性偏好和項目隱性特征,然后利用用戶和項目的隱性向量的乘積來預測用戶/項目評分矩陣中的未知項,以便更好地為用戶推薦[18].常見的矩陣分解算法有奇異值分解(Singular Value Decomposition,SVD)、ALS[19]等.相比于SVD及其他矩陣分解算法,ALS更加適合于分解交互數據較為稀疏的矩陣,因此本文使用ALS對用戶/項目交互數據進行矩陣分解,以產生用戶和項目的隱性向量表示.形式如圖3所示.
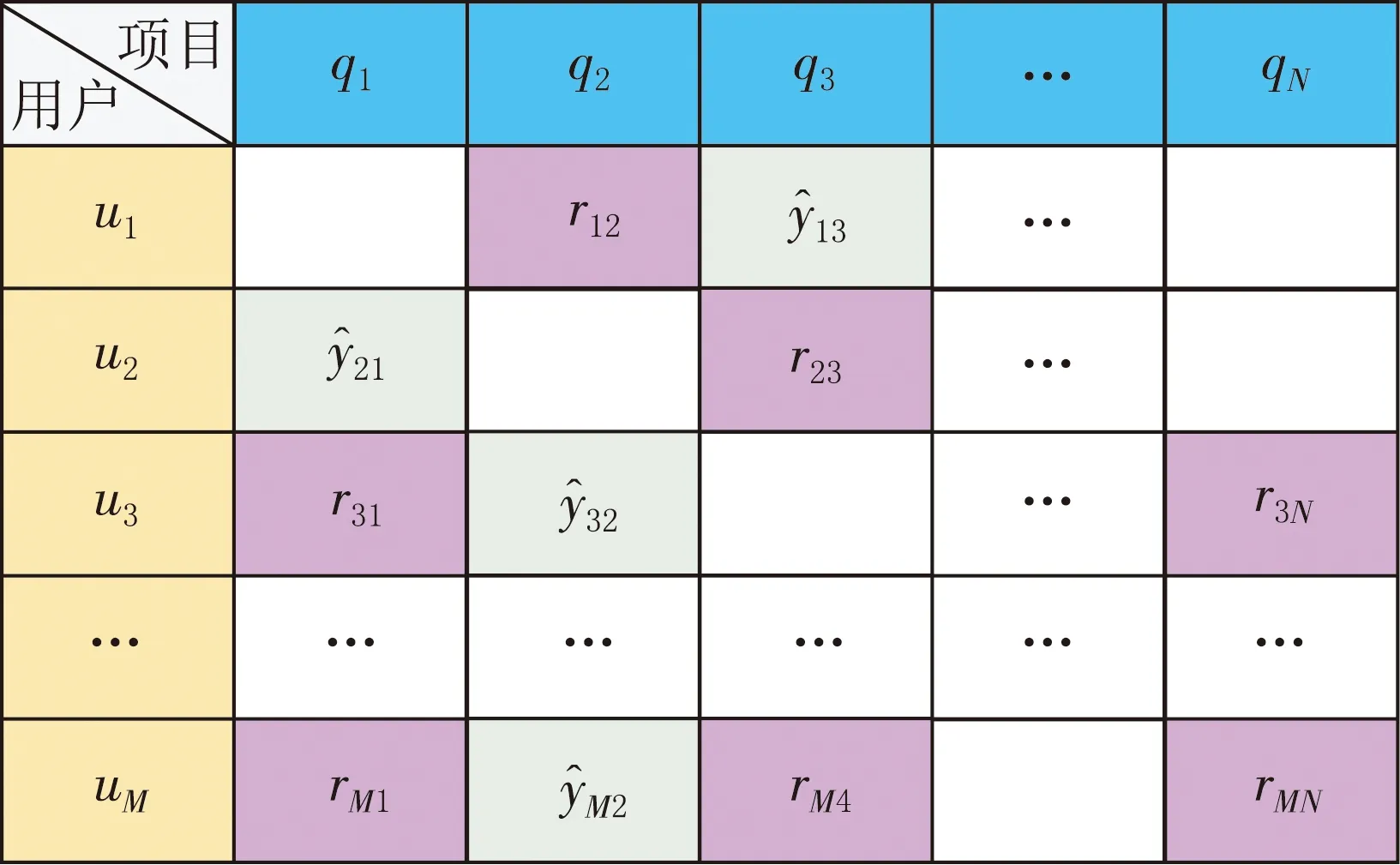
圖3 用戶/項目交互矩陣

在CFSS模型中,使用ALS將用戶/項目評分矩陣RM×N分解為M×K的用戶隱性向量矩陣和K×N的項目隱性向量矩陣,其中超參數K為潛在因子空間,K越大越精準,計算時間也越長.
在ALS中,用戶/項目交互矩陣可以表示為用戶矩陣與項目矩陣的乘積,以此來近似用戶/項目評分矩陣,公式為
RM×N=PM×KDK×N.
(6)
其中:PM×K表示用戶隱性向量矩陣,DK×N表示項目隱性向量矩陣.
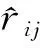
(7)
其中:pi表示用戶隱性向量,dj表示項目隱性向量.在計算PM×K與DK×N的乘積與原始矩陣的誤差時,損失函數的計算公式為
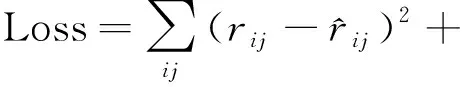
(8)
其中λ表示正則化系數.為了優化損失函數,使用交替固定P和Q對損失函數求偏導,降低損失函數.
3 實驗結果與分析
本節通過對比實驗以及K折交叉驗證檢驗了本文提出的CFSS模型的有效性.
3.1 數據集
為了驗證本文提出的基于半監督學習的協同過濾推薦算法的泛化性能,選取了公共數據集Movielens 100K和公共數據集Book-Crossings來進行實驗.分別隨機抽取兩個公共數據集中的25%的數據設置為待填充數據,再從剩下75%的數據中隨機抽取20%的數據設置為測試集,80%設置為訓練集.
3.1.1 Movielens 100K數據集
該數據集中包含10萬個用戶對電影的評分數據,也包含電影特征信息以及用戶特征信息,用戶使用1~5之間的評分來表示用戶對電影的喜好程度,分值越高則表示該用戶對該電影越感興趣.數據隨機劃分結果見表1.

表1 Movielens 100K數據集
在輸入DeepFM進行訓練時,將Movielens 100K數據集中用戶的性別、年齡和職業作為用戶特征進行輸入;將Movielens 100K數據集中電影的發行日期以及電影類型作為項目特征進行輸入.
3.1.2 Book-Crossings數據集
該數據集中包含110萬個用戶對圖書的評分,表達了9萬個用戶對27萬本書的喜好程度,用評分1~10來表示.數據來自于一個擁有數百萬人的規模龐大的圖書館網站,特點是用戶/圖書評分矩陣較為稀疏.數據隨機劃分結果見表2.

表2 Book Crossings 數據集
在輸入DeepFM進行訓練時,將Book-Crossings數據集中用戶的年齡、所在地作為用戶特征進行輸入;將Book-Crossings數據集中書籍的名稱、作者作為項目特征進行輸入.
3.2 評價指標
本文采用均方根誤差(Root mean squared error,RMSE)和平均絕對誤差(mean absolute error,MAE)兩個指標來評價算法的評分預測誤差.
(9)
(10)
其中:X表示測試集中用戶與項目交互的次數;yij表示模型用戶i對項目j的預測評分值;Rij表示用戶i對項目j的實際評分值.
3.3 參數選擇
首先對評分預測時所使用的DeepFM模型中的迭代次數進行優化選擇,對迭代次數進行分組實驗,結果見表3.
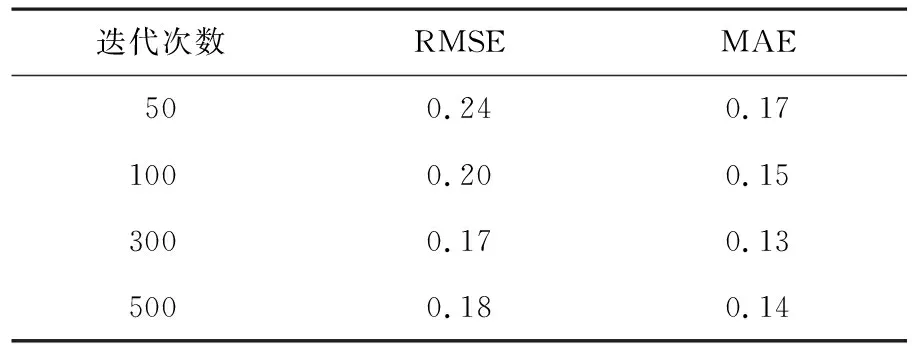
表3 DeepFM迭代次數分組實驗結果
由表3可知,當DeepFM模型的迭代次數為300時,對測試集預測的結果與實際的誤差不再繼續增大,因此本文選擇300為DeepFM模型的迭代次數.
對ALS的隱性向量長度進行分組實驗,結果見表4.
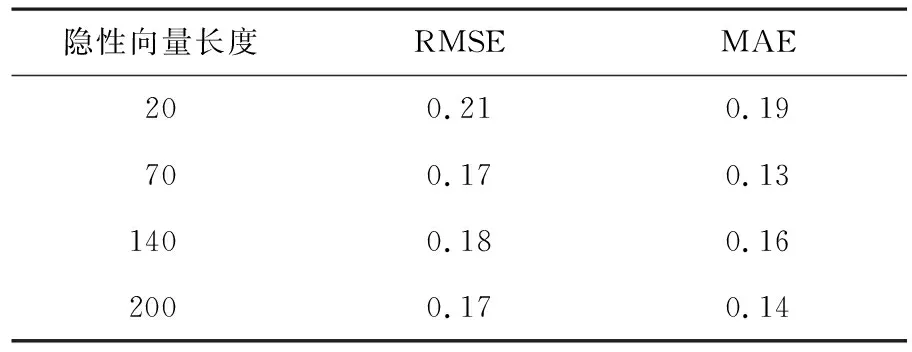
表4 ALS不同隱性向量長度分組實驗結果
從表4可知,隱性向量長度為70時,RMSE和MAE最小.因此在使用ALS分析用戶歷史回答數據,對用戶和項目隱性向量進行表示時,將其設置為70.
3.4 K折交叉驗證
算法模型在僅訓練一次的情況下無法代表模型的平均性能,因此本文采用K折交叉驗證,可以大致反映本文算法模型的平均水平.K折交叉驗證圖如圖4所示.
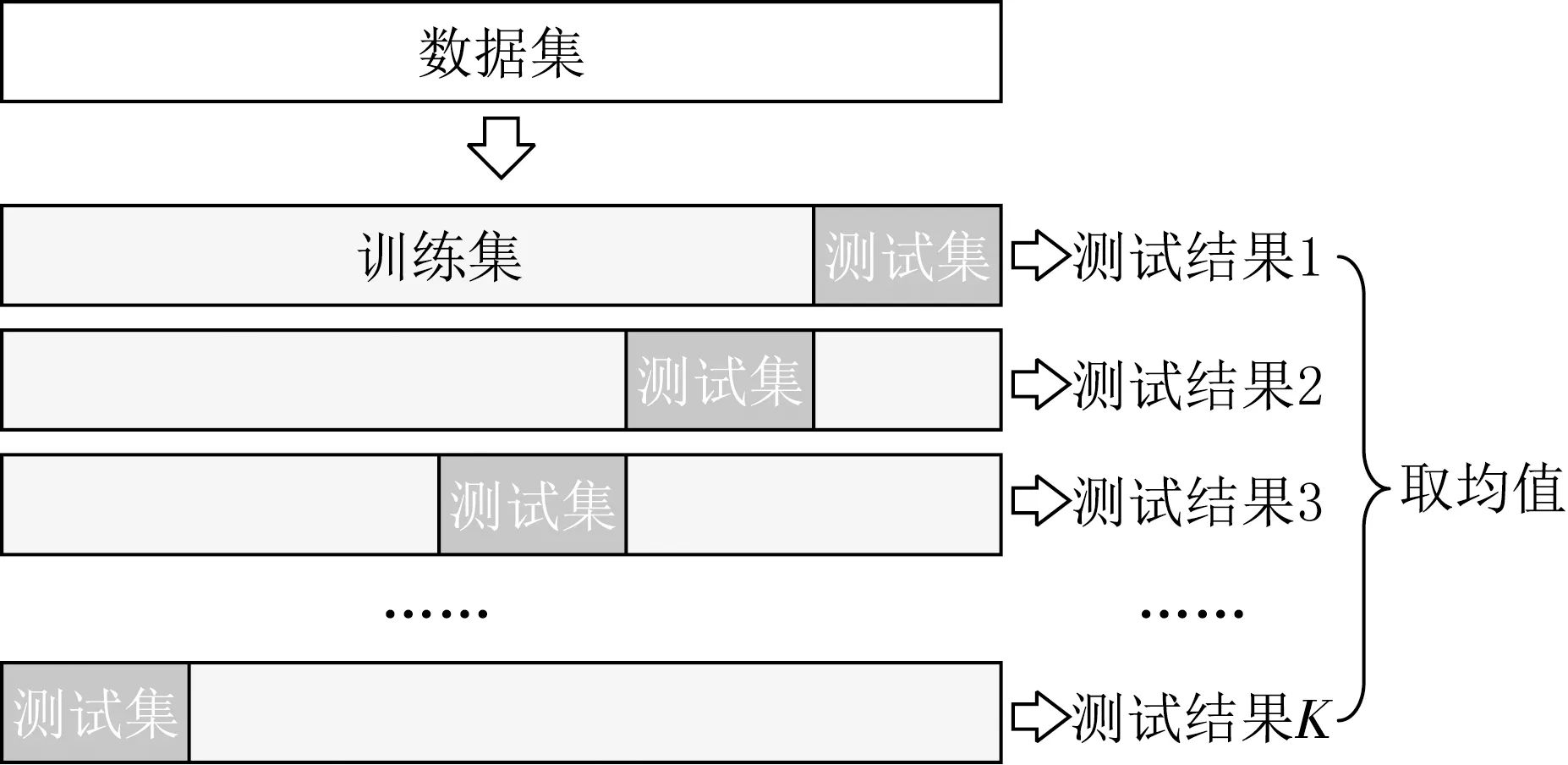
圖4 K折交叉驗證圖
K折交叉驗證使用了無重復抽樣技術,具體實現步驟:首先將訓練集數據隨機劃分為K份,將其中的K-1份數據作為訓練集,剩余的1份作為測試集;之后將迭代K次的訓練結果取平均值作為模型的性能指標.
K取值越大,模型訓練結果越可靠,但所消耗時間也隨之線性增長.考慮到數據集大小與模型性能,本文選取K=5,對模型進行5折交叉驗證,訓練結果如圖5所示.
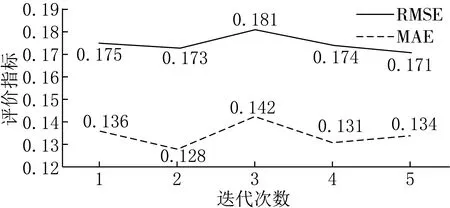
圖5 5折交叉驗證訓練結果
將交叉驗證結果取平均值作為模型的評估結果,得RMSE=0.174 8,MAE=0.134 2.
3.5 對比實驗
為了驗證評分預測效果以及填充用戶矩陣的有效性與必要性,本文對有無DeepFM算法評分預測進行了消融實驗,并加入了不同矩陣分解的算法以及其他推薦模型進行對比,對比實驗結果如表5所示.
從表5可知,在使用ALS算法表示用戶隱性向量之前,由于使用DeepFM方法進行矩陣填充降低了矩陣的稀疏度,使ALS算法的誤差更低,因此能夠更加準確地表示出用戶隱性向量,從而證明了本文提出算法的評分預測的有效性與必要性.
同時為了驗證本文提出的CFSS算法在稀疏性數據集上的推薦效果以及其泛化性能,本文進行了稀疏性對比實驗.對公共數據集Movielens 100K和Book-Crossings分別進行稀疏化處理.通過不斷增加數據集稀疏性,使用不同算法進行多組對比實驗來驗證本文算法的推薦效果,如表6所示.

表6 數據稀疏化后不同算法之間的RMSE和MAE對比
由上述稀疏性對比實驗可以看出,在數據稀疏性逐漸增大的情況下,本文提出的基于半監督學習模型的協同過濾推薦算法的RMSE和MAE均低于其他對比算法,表明本文方法的推薦效果較好.
4 總結與展望
隨著用戶規模的不斷擴大,解決推薦系統中的稀疏性問題變得尤為關鍵.傳統推薦學習從較為稀疏的矩陣中難以訓練出有效的推薦模型.本文提出基于半監督學習模型的協同過濾推薦算法,基于半監督思想,用有標簽數據訓練DeepFM算法,得到評分預測模型,然后用該模型為所有無標簽數據預測出偽標簽,以此填充用戶/項目交互矩陣,使得數據由稀疏變得更加稠密.將原始有標簽數據與預測出的偽標簽數據作為ALS矩陣分解的輸入,對用戶/項目交互矩陣數據進行矩陣分解,以此產生用戶和項目的隱性向量表示,來預測空白項的評分.通過在兩個公共數據集的實驗對比,驗證了本文提出的CFSS模型的有效性,并且通過訓練不斷稀疏化數據集,CFSS模型的推薦誤差明顯小于傳統推薦模型.
在今后的工作中,我們希望能有效利用用戶特征中的職業、年齡等多個維度的特征表示以及項目特征中的文本內容信息來更準確地表示用戶的偏好.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
