增量文本軟聚類速度改善算法設計及仿真
2022-09-28 09:54:42劉艷,周斌,2
計算機仿真 2022年8期
劉 艷,周 斌,2
(1. 武漢工程科技學院信息工程學院,湖北 武漢 430200;2. 華中科技大學軟件學院,湖北 武漢 430200)
1 引言
相對于普通文本而言,增量文本包含的數據信息量較大,在以往的增量文本聚類算法中,通常在計算時會存在較高的時間復雜度,導致計算性能下降,且不適用于動態變化文本集聚類,同時,硬聚類方法只將一個文本劃分一個類別[1-3],無法全面展示文本信息,而軟聚類能夠依據主題的類別劃分信息,使相同類別的文本信息分配到同一處中[4,5]。
目前,有較多學者研究文本的聚類算法,例如馬武彬等[6],研究基于改進NSGA-Ⅲ的文本空間樹聚類算法,但該算法計算時間復雜度較高,會使聚類計算時的聚類時間延長。除此之外,還有學者研究基于語義簇的中文文本聚類算法,但該算法僅能夠處理中文文本,在對增量文本進行聚類時依然需要大量的時間。因此,本文研究基于群體智能的增量文本軟聚類算法,通過劃分語義序列特征,構建基于蟻群算法的增量軟文本聚類計算,并采用Python語言構建SCAST程序實現算法計算過程。
2 增量文本軟聚類算法
2.1 語義序列特征分析
由于增量文本存在一定數量的長文本,且具有多主題特性,因此,通過計算語義序列相似關系對序列集合的覆蓋度進行計算,并對得到的結果進行聚類能夠有效降低增量文本向量空間維數,縮短文本軟聚類的計算時間[7]。
在語義序列中并不存在文本集中的全部信息[8],僅存在文本自身信息,因此,有效分析語義序列,能夠得到增量文本中更加詳細的共同點。分析語義序列的基本概念:
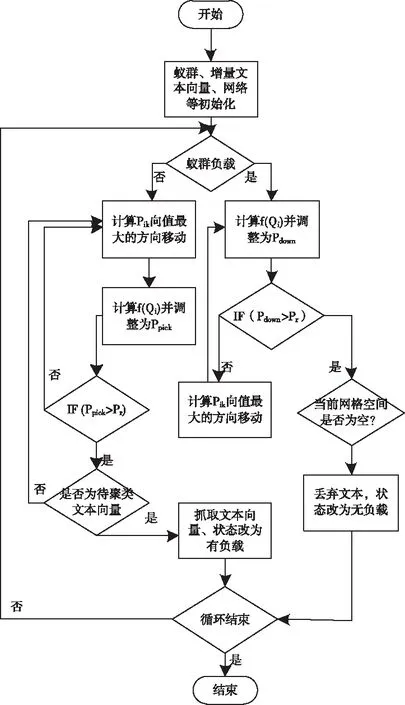
設需要聚類的增量文本集合為D={d1,…,dk,…,dn}(1≤k≤n),其中,dk表示每個文本,dk中的某個詞匯序列由s描述,即s=w1w2…wm,而s中e(1≤e≤m)區域內的詞匯由we描述。通過以下流程設定語義序列,使其能夠應用于增量文本集。
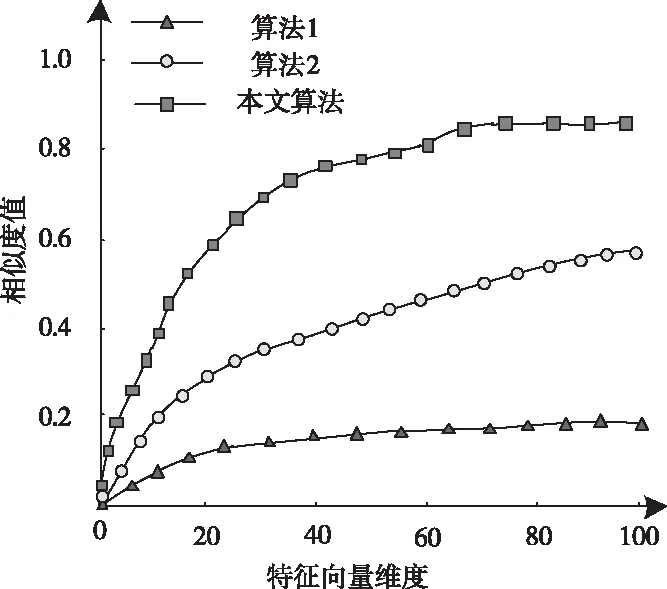
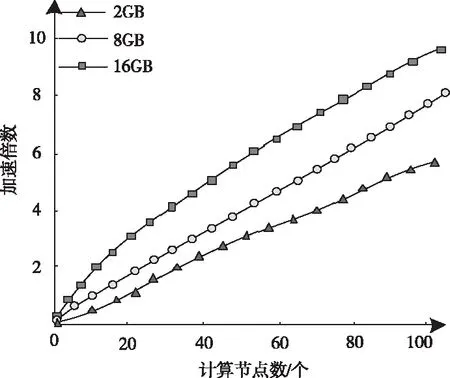
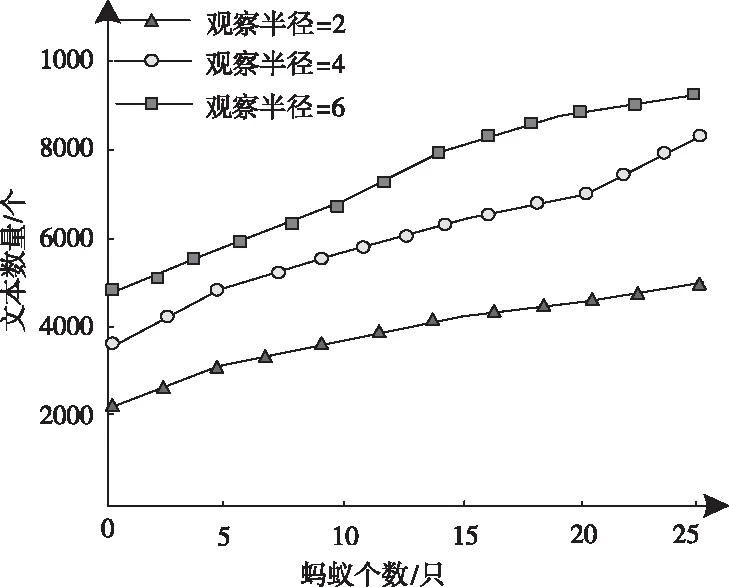
1)設定s內區域e中的詞匯距離σ(e)為詞匯we到詞匯wh之間的詞匯數量,設為σ(e)=e-h,詞匯we=wh,同時we≠wk(1≤h 2)設ρ(e)=1/σ(e),即s內區域e中的語義密度ρ(e)為此處詞匯距離的倒數。 在現實中,可將單個文本看作長度較長的詞匯序列,而詞匯序列s內區域e中的詞匯距離即為σ(e),若σ(e)較短,則可以表示文本中某段落內的詞匯we出現次數較多,即該詞匯we的密度很高,所以,由此可認定在局部區域中,密度較高的詞匯能夠描述出該區域內的局部語義特性[9,10]。 3)設語義序列為s[e]=we1we2…wer,該序列為s中的子序列,在該序列中,e=[e1,e2,…,er](1 |s[e]|>1 (1) 0 (2) ρ(ek)≥δ,1≤k≤r (3) (e1-ε≤eh (er (4) (?wek,wel∈s,ek≠el)→wek≠wel, 1≤k≤r,1≤l≤r (5) 上述公式中,δ、ε均表示閾值。 當剔除s中的低密度詞匯之后,留下的一個連續詞匯序列即為s[e],連續的含義為:s[e]內鄰近的兩個詞匯在初始文本s中的位置差應不高于已設定的閾值ε。已設定的條件為:s中的非空子序列構成s[e];在該語義序列中的詞匯間應存在連續性;s[e]內的詞匯均應為局部頻繁狀態;需保證s[e]前后距離存在一段低密度范圍,以保障s[e]不會出現無限擴展;確保s中不會出現重復詞匯。 4)熵重疊。熵重疊能夠描述出文本集合D的每個類Cq中的文本全部候選類中的劃分情況,可通過式(6)計算 (6) 式(6)中,當dk為某個指定聚類的概率時通過pk=1/fk描述,而dk中存在的語義序列數量由fk描述。文本集合D的聚類結果集合為C={C1,…,Cq,…,Ct}(1≤q≤t),其中,Cq表示每一個類。若Cq中的每個dk只能夠表明一個語義序列,則熵重疊為0,當fk逐漸增加,熵重疊也會上升,由此可知,熵重疊值越低,聚類純度越好,這是由于熵重疊主要衡量語義序列分辨文本的能力。依據該特征,構建文本軟聚類算法,實現增量文本聚類。 群體智能(Swarm Intelligence)是現階段應用較為廣泛的人工智能技術,隨著該技術的發展已逐漸應用于社會、經濟等各個領域[11]。群體智能算法中包含粒子群算法與蟻群算法等,本文選取蟻群算法實現增量文本軟聚類。在蟻群算法中,由于蟻群的移動存在一定的隨機性,因此,通過信息素操控螞蟻移動能夠加快算法的收斂,使聚類速度得到提升。在本文軟聚類算法中,依據上述分析得到的文本語義詞序特征,將其擺放在二維平面中,并為每個信息隨機分配初始區域,全部螞蟻均可通過隨機形式在網格中爬行,之后計算群體相似度,得到計算結果后,采用概率轉換函數繼續計算,將相似度調整為螞蟻抓取或丟棄的概率。通過大量螞蟻的爬行,可以使相同屬性的增量文本信息匯集在相同范圍內。 通過圖1表示基于蟻群算法的增量文本軟聚類過程。在圖1中,通過f(Oi)描述群體相似度;Ppick描述抓取的概率;Pdown描述丟棄的概率;Pr表示隨機函數。 圖1 增量聚類算法流程圖 某個待聚類文本與當前區域內全部其它文本的綜合相似性,即為群體相似度,通過式(7)計算該相似度 (7) 式(7)中,局部環境由Oj∈Neights×s(r)描述;通過b×b設定單元r的鄰域面積;而對象屬性空間內Oi、Oj的間距由u(Oi,Oj)描述;相似度因子為α,同時α表示群體相似系數,α能夠直接對聚類數量造成影響,因此,α為比較重要的參數,當α越大,則會導致群體相似度f(Oi)變大,使得并不存在相似性的對象歸類到同一處,以此降低聚類數量并提升收斂速度,若α取值越低,則會使收斂時間變長以及聚類數量增大。 與群體相似度f(Oi)存在關聯的函數,即為概率轉換系數,通過概率轉換,能夠使群體相似度調整為文本對象的抓取概率與丟棄概率。 其中,抓取操作是在螞蟻不存在負載的情況下,抓取螞蟻鄰域內的文本對象,確定該文本對象可以抓取的概率可通過式(8)計算 (8) 而丟棄操作是指在螞蟻負載文本情況下,若發現空閑網格,則螞蟻可丟棄該文本對象,確定丟棄的概率可通過式(9)計算 (9) 式中,可變動的參數為kd、kp,文本對象Oi與鄰近對象之間的平均相似度測量結果為f(Oi)。 本文通過Python語言構建SCAST程序,聚類算法的計算過程,具體設計如下: 初始化網格grid與螞蟻列表antList; for(迭代次數)i∈iterationdo{ for(eachant∈antList)do{ if((ant_tv==null)&&(xy_tv!=null)) {Computer f(Oi); P_pick←Computer Ppick(Oi); if(P_pick>r)then {抓取Oi;} } else if((ant_tv!=null)&&(xy_tv==null)){ Computer f(Oi); P_drop←Computer Pdrop(Oi); if(P_drop>r)then {丟棄Oi;} for(i=0;i C.add(cov(S[e])); for(k=i+1;k } } next_step_random(); } } 主要通過以下步驟實現該算法: 1)依據配置文件,對網格與螞蟻列表進行初始化。 2)設iteration為迭代次數,計算螞蟻迭代次數,依據現階段環境與螞蟻是否負載信息判定螞蟻抓取或丟棄增量文本。 3)通過Computer函數對文本相似度進行計算,將螞蟻所在位置是否存在增量文本向量采用xy_tv描述,螞蟻是否負載由ant_tv描述。若螞蟻所處位置存在增量文本向量且負載為空,則對抓取概率與群體相似度進行計算,若計算得到的抓取概率高于隨機值,則抓取增量文本。 4)計算S[e]的熵重疊值并存儲,同時選出最小熵重疊值的語義序列集,將該序列集與S[e]進行交換,之后再次計算熵重疊值并存儲。 5)將螞蟻ant隨機爬行至下一網格的函數通過next_step_random描述。分析該算法的復雜度,若現階段螞蟻總量為m,共進行n次迭代,則可計算得出時間復雜度O(m·n)。 通過VC6.0構建仿真環境進行實驗,在實驗環境中構建增量文本集,并選取基于改進NSGA-Ⅲ的文本空間樹聚類算法(算法1)和基于語義簇的中文文本聚類算法(算法2)進行對比實驗。 對比三種算法,分析不同文本向量空間維數下,語義序列的相似度計算能力,分析結果如圖2所示。 圖2 語義序列相似度分析 根據圖2可知,隨著特征向量維度的不斷增加,三種算法計算得到的語義序列相似度值也有所上升,其中,算法1的相似度值始終最低,算法2計算得到的相似度雖然有所上升,但依然低于本文算法,本文算法在特征向量維度為100時,相似度值達到了0.88,由此可知采用本文算法計算語義序列相似度值較高,相似度計算能力強。 從該增量文本庫中選取三類文本集,分析不同文本數量下,不同文本集的聚類召回率,分析結果如圖3所示。 圖3 聚類效果分析 由圖3可知,三類文本集在文本數量逐漸上升的情況下召回率均有所降低,其中,由于醫學類詞匯較為復雜,因此醫學類文本集的召回率在三種文本集中保持最低,而計算機類文本集召回率最高,在三種文本集的聚類過程中,召回率均保持在80%以上,說明本文算法聚類時具有較高的召回率。 分析本文算法在不同計算節點數下,計算2GB、8GB、以及16GB文本量情況下的計算加速倍數,分析結果如圖4所示。 圖4 不同文本量大小時聚類加速比分析 由圖4可知,當計算節點數不斷增長,加速比也隨之增加,其中16GB文本量的聚類加速倍數最高,而2GB文本量的加速倍數相對較低,說明數據量越大,在進行聚類時的加速倍數就越高,同時,三種大小的文本量最終加速倍數均保持在5以上,因此,本文算法聚類時的加速效果較好。 蟻群算法中螞蟻觀察半徑是影響聚類效果的關鍵因素,選取不同螞蟻個數,分析在不同螞蟻觀察半徑下,螞蟻觀察到的文本數量,分析結果如5所示。 圖5 觀察得到文本數量分析 根據圖5可知,由于螞蟻個數的不斷增多,不同觀察半徑下觀察到的文本數量也隨之增加,其中,觀察半徑為2時觀察到的文本數量較低,而觀察半徑為6時,觀察得到的文本數量最高在9000個以上,說明觀察半徑越大,觀察到的文本數量就越多,同時,采用本文算法觀察到的文本數量均在2000個以上,說明本文算法具有較高的文本觀察能力。 對比三種算法聚類時的算法性能,分析結果如表1所示。 表1 聚類效果分析 根據表1可知,三種聚類算法中,算法2的聚類時間較長,且對異常文本并不敏感,同時聚類時內存占比較大,算法1的聚類時間消耗過長,通過對比可知,采用本文算法能夠更好地實現聚類。 本文研究基于群體智能的增量文本軟聚類算法,通過語義序列特征分析得到增量文本特征,依據該特征,選取基于群體智能的蟻群算法,設計增量文本軟聚類算法,并通過Python語言構建SCAST程序,實現聚類算法的計算過程。同時采用仿真形式進行實驗,得出本文算法具備較低的聚類執行時間,能夠改善聚類效果。在未來研究階段,可依據現有聚類分析繼續優化,實現多種形式文本的聚類。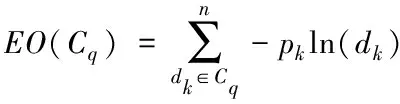
2.2 基于群體智能的增量文本軟聚類
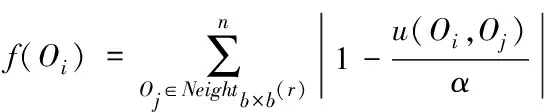
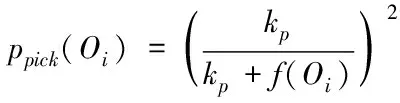
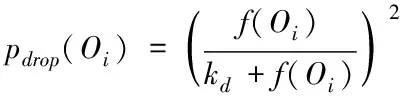
3 實驗分析


4 結論
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36山東醫藥(2020年34期)2020-12-09 01:22:24開放教育研究(2020年2期)2020-03-31 01:54:14制造技術與機床(2019年10期)2019-10-26 02:48:08中華胰腺病雜志(2019年4期)2019-08-29 08:52:20電子制作(2018年18期)2018-11-14 01:48:06現代語文(2016年21期)2016-05-25 13:13:44小學教學參考(2015年20期)2016-01-15 08:44:38大連民族大學學報(2015年2期)2015-02-27 08:28:11語文知識(2014年1期)2014-02-28 21:59:13
