基于遺傳算法與BP_Adaboost的故障檢測方法
2022-09-28 09:28:34付樂天
計算機仿真 2022年8期
付樂天,李 鵬*,高 蓮,沈 鑫
(1.云南大學信息學院,云南昆明650091;2.云南電網有限責任公司,云南昆明650011)
1 引言
當前,隨著社會經濟技術的發展,工業過程的技術和產品不斷發生著更新,化工過程越來越復雜,化工過程的安全性和可靠性以及產品的質量需要得到保障,所以及時有效的故障檢測方法具有重要意義[1-2]。
故障檢測是一門目標明確、針對性強、應用范圍廣的交叉型技術學科,其目前主要分為三種類型[3]:基于解析模型的方法[4]、基于數據驅動的方法[5]、基于知識的方法[6]。其中,基于數據驅動方法因為不需要先驗知識且現代化工過程復雜很難精確地建立數學機理模型,因此受到廣泛地關注。在眾多基于數據驅動的方法中,又以基于多元統計分析以及基于機器學習的方法應用廣泛。文獻[7]采用PCA對電潛泵實時數據進行分析,根據數據的線性組合進行特征提取,降低數據維度,創造新的主元空間。實驗結果表明PCA可以有效監測ESP的健康狀況。文獻[8]提出了一種基于BP神經網絡與小波函數的軸承故障檢測模型。該模型首先利用小波函數對振動信號進行分解,然后構造特征向量作為BP網絡的輸入元素。實驗表明,該模型能夠準確地半段故障的類型。文獻[9]提出基于BP_Adaboost的電子式電能表故障診斷模型。該模型把單一BP網絡作為弱分類器,并利用Adaboost算法組合訓練得到強分類器,然后應用電子式電能表的典型故障診斷中。仿真結果表明BP_Adaboost模型相較與單一BP網絡能提高精度,顯著減小誤差。文獻[10]利用NPE將原始空間劃分為不相關的特征空間和數據殘差空間,針對兩個空間分別構造T2與SPE統計量,對環網柜進行故障檢測。實驗表明該模型改善了環網柜故障檢測的效果。
上述研究方法雖然為故障檢測提供了很好的思路,但將其應用于化工過程的故障檢測中仍有不足。因為化工過程故障的影響因素種類眾多,導致其模型建立復雜,檢測精度不夠。因此,本文提出了采用遺傳算法對自變量進行降維并優化網絡參數,再結合BP_Adaboost方法建立模型,并對TE過程進行故障檢測。首先,采用遺傳算法降維,能夠極大提取數據間的特征關系,降低數據的輸入維度,減小模型的復雜性,同時利用遺傳算法對BP網絡的權值和閾值進行參數優化能夠提高網絡的精度。然后,建立BP_Adaboost模型能進一步強化BP網絡的精度,增強對故障的檢測能力。最后,通過TE實驗仿真,表明本文方法模型精度良好,能準確地對化工過程進行故障檢測。
2 基本理論
2.1 遺傳算法
遺傳算法是1962年由Holland教授提出的一種模擬自然界遺傳機制和生物進化論而形成的智能優化算法[11]。其原理主要依據大自然的‘優勝劣汰,適者生存’的競爭機制。算法首先需要將優化的參數引入到個體的基因編碼中,然后根據適應度函數對編碼的個體進行選擇、交叉和變異操作。其中,保留適應度值高的個體,淘汰適應度值低的個體,不斷地反復迭代優化,直至篩選出最優個體。其基本操作分為:
1)選擇操作
選擇操作是指以一定的概率將個體從舊群體選擇到新群體中,適應度高的個體其選中的概率越大。
2)交叉操作
交叉操作是指從群體從選擇兩個個體,通過兩個染色體的交叉組合產生新的優秀個體。其染色體的交叉方式可分為單點交叉和多點交叉。
3)變異操作
變異操作是指從群體中任意挑選一個個體,對其染色體中的一點進行變異,以產生更加優秀的個體。
2.2 Adaboost算法
Adaboost是一種迭代算法,本身是通過改變數據分布來實現的,它根據每次訓練集之中每個樣本的分類是否正確,以及上次的總體分類的準確率,來確定每個樣本的權值。其核心思想是針對同一個訓練集訓練不同的分類器,然后把這些分類器集合起來,構成一個更強的最終分類器[12]。其算法本身是通過改變數據分布來實現的,它根據每次訓練集之中每個樣本的分類是否正確,以及上次的總體分類的準確率,來確定每個樣本的權值。將修改過權值的新數據集送給下層分類器進行訓練,最后將每次訓練得到的分類器最后融合起來,作為最后的決策分類準則。
3 基于遺傳算法自變量降維與BP_Adaboost的優化模型
遺傳算法自變量降維與BP_Adaboost優化模型(本文稱為GADR-BP_Adaboost模型)如圖1和圖2所示,模型包括2個部分:BP_Adaboost模型部分和遺傳算法自變量降維與優化部分。BP_Adaboost模型主要是將單一的BP網絡作為弱學習器,然后根據集成學習的思想把n個BP網絡結合起來建立一個強學習器。其流程主要為先對數據進行預處理,再將預處理后的數據輸入到單個的BP網絡弱學習器中,然后根據弱學習器的輸出來調整各個樣本的權值,最后得到整個模型的輸出。為了提高BP網絡的精度,采用遺傳算法先對自變量維度進行基因編碼,然后根據遺傳算法的全局迭代優化提取出最終參與建模的維度重新進行數據的組合,最后利用組合后的數據對BP網絡進行權值和閾值的優化,從而建立BP網絡。本部分通過降維以及權值和閾值的優化來提高單個的BP網絡的精度,從而有效地提高了BP_Adaboost模型的精度。

圖1 BP_Adaboost模型網絡結構圖
3.1 BP_Adaboost
模型依據Adaboost集成學習思想,將BP網絡作為弱學習器從而建立一個更加強大的集成學習器,其主要步驟如下:
Step1:由樣本數量確定初始分布權值為:
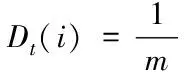
(1)
式中,Dt(i)表示第t輪第i個樣本的分布權值,m表示樣本數量。
Step2: 訓練第t組弱學習器時,用訓練數據訓練神經網絡并且預測訓練數據的輸出,根據輸出得到神經網絡的預測誤差和為
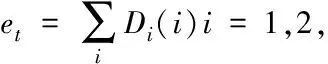
(2)
式中,g(t)為預測輸出;y為期望輸出。
Step3: 根據預測誤差和計算序列權重
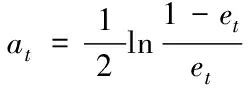
(3)

圖2 遺傳算法自變量降維與優化流程圖
Step4: 根據序列權重計算下一輪訓練樣本權重
(4)
式中,Bt是歸一化因子。
Step5: 由弱學習器得到的函數計算得到強學習器函數
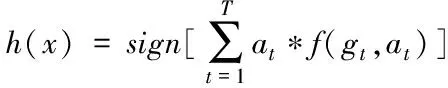
(5)
式中,f(gt,at)為弱學習器訓練得到的函數。
3.2 遺傳算法自變量降維與優化模型
遺傳算法自變量降維與優化模型是基于遺傳算法能將解空間映射到編碼空間,使每個編碼對應于一個問題的解,其算法步驟如下:
Step1:輸入數據,建立BP模型,使染色體編碼的每一位對應于一個輸入自變量維度。每一位只能取0、1兩種情況。
Step2:對每一個個體計算個體適應度值,提取并紀錄最優個體適應度值。
Step3:計算種群中所有個體的適應度和
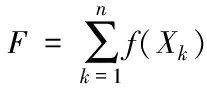
(6)
式中,f(Xk)是個體適應度。
計算種群中個體的相對適應度,并以此作為遺傳概率
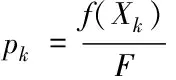
(7)
Step4: 對染色體進行選擇和交叉操作,然后進行網絡的迭代優化,提取輸出種群中染色體值為1的所對應的自變量維度,即篩選出最具代表的自變量維度。
Step5: 依據提取的自變量維度對輸入數據進行重新組合,將組合后的數據作為網絡的輸入進行權值和閾值的優化。根據優化后的權值和閾值以及經過降維后的數據進行創建網絡。
4 GADR-BP_Adaboost模型應用于故障檢測
本文將提出的遺傳算法自變量降維與優化BP_Adaboost(GADR-BP_Adaboost)模型應用于故障檢測中,其建模流程圖如圖2所示,主要分為以下幾個部分:
1)數據預處理;
2)遺傳算法模型參數選取;
3)建立GADR-BP_Adaboost的故障檢測模型;
4.1 數據預處理
為了使不同量綱的數據具有可比性,本文對數據進行歸一化處理,將數據歸一化到[-1,1]之間,以提高模型的精度
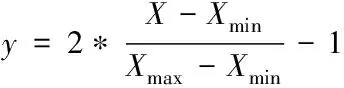
(8)
式中,y為歸一化后的數據;Xmin為樣本數據最小值;Xmax為樣本數據最大值。
4.2 遺傳算法模型參數選擇
為了提高模型建立的精度,本文采用遺傳算法對輸入的自變量進行降維和對網絡的權值閾值進行優化。遺傳算法相關參數設置如表1所示。

表1 模型參數設置
其中,選取測試集數據誤差平方和的倒數作為適應度函數
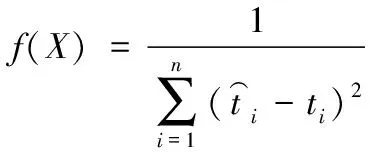
(9)
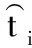
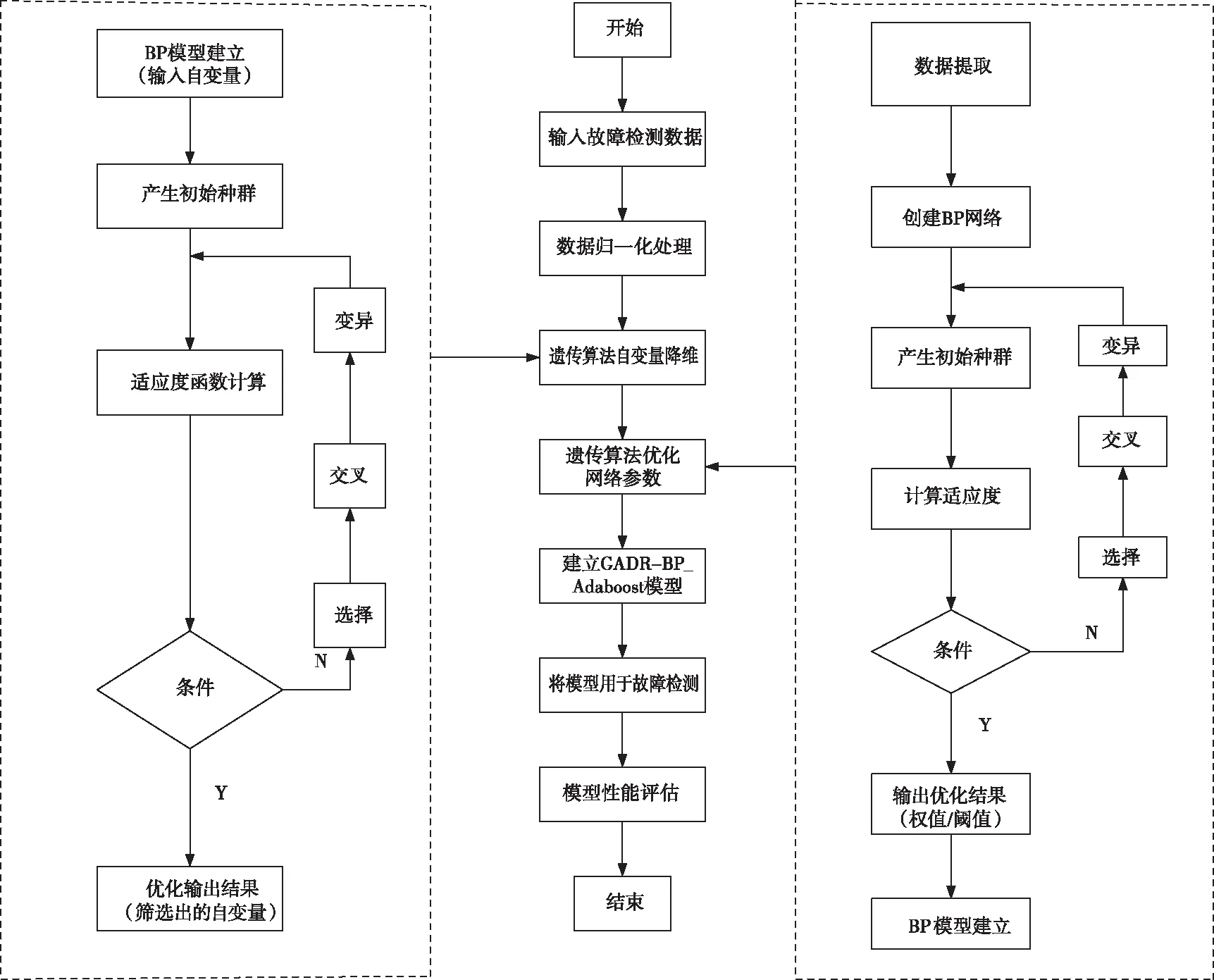
圖3 基于GADR-BP_Adaboost模型的故障檢測流程圖
4.3 建立GADR-BP_Adaboost的故障檢測模型
本文建立基于遺傳算法自變量降維與優化BP_Adaboost的故障檢測模型具體步驟如下:
Step1:對故障檢測輸入數據進行數據歸一化處理,將處理好的數據作為模型的輸入。對輸入數據的自變量維度進行基因編碼,使用遺傳算法對自變量進行降維。
Step2:提取經過遺傳算法進行降維后維度,然后重新組合新的故障檢測輸入數據。以新的輸入數據作為模型的輸入,利用遺傳算法優化BP網絡的權值閾值。
Step3:利用優化好的權值和閾值以及新的故障檢測輸入數據,創建BP網絡模型。將創建的BP網絡作為弱學習器,根據Adaboost集成思想,建立BP_Adaboost強學習器。最后,將建立好的模型應用于故障檢測。
5 算例分析
5.1 數據來源
本文數據采用的是TE化工過程數據,其是由J. J. Downs和E. F. Vogel[13]根據伊士曼化學公司的實際化學過程開發的標準測試平臺。
TE過程數據包括41個過程測量變量和12個過程控制變量[14]。由于最后一個控制變量保持不變,本文選取前52個變量作為輸入自變量。TE過程的故障共有21種,其中已知故障種類16個,為故障1-15、21;未知故障種類5個,為故障16-20。
TE過程數據分為21組數據,每組數據的樣本數量為960個,數據維度為52維。其中,每組前160個數據為正常數據,后800個數據為故障數據。本文將在每組數據的前后各添加480個正常樣本數據,以模擬系統故障被修復后的運動狀態。因此,本文采用的每組數據長度為1920個,取前1280個數據作為訓練集,后640個數據作為測試集。其中,訓練集中前640個正常樣本數據,后640個為故障樣本數據;測試集中故障數據為160個,正常數據為480個。
5.2 評價指標
本文采取的模型性能評價指標為檢測率FDR和誤報率FAR,其公式如下:
5.3 效果分析
在對于化工過程的故障檢測采用本文方法,能夠有效地提高模型的精度,相較于單一的BP網絡模型、單一的BP_Adaboost模型和NPE模型,本文方法不論是在檢測率,還是在誤報率方面都具有良好的表現,其具體見表2所示。其中,經過多次實驗,網絡隱藏層節點數為15。
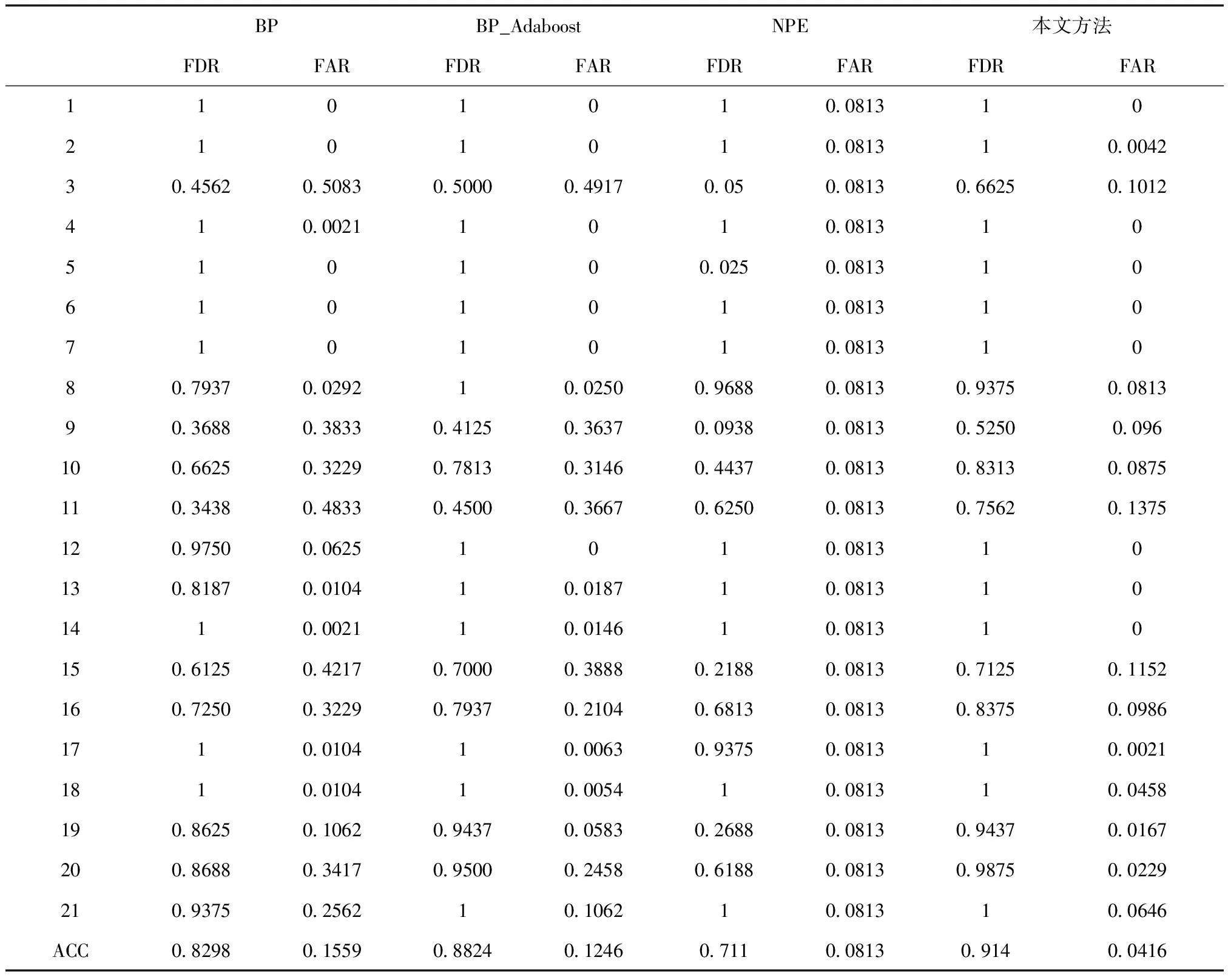
表2 4種模型性能指標對比
其中,ACC表示的是21種故障的平均值,其公式如下

(10)
式中,Xi為21種故障情況所對應的各個指標的值。用來衡量模型對化工過程中故障檢測的整體性能。
由表2可以看出,BP_Adaboost模型因為依據Adabooost思想將BP作為弱學習器從而構建強學習器,有效地提高了模型的精度。在故障檢測率方面,相對于BP整體平均提高了6%,在故障誤報率方面,平均降低了3%,尤其是對于故障種類為17、18、21的表現要比BP網絡更加突出。但是,對于故障類型為3、9、10、11、15、16、20進行故障檢測時,檢測率和誤報率表現均有欠缺,還需要提高。而本文模型在4種模型的比較中表現最好。其因為在BP_Adabooost模型的基礎上采用遺傳算法對自變量進行降維處理并對網絡參數進行優化,提高了模型的精度,相較于BP_Adaboost模型,檢測率整體提高了4%,誤報率降低了8%。同時在單獨針對于某一種故障類型時,其也在4種模型中表現最好。而本文方法與NPE進行比較時,其模型的表現也均好過NPE方法。
本文模型在BP_Adaboost模型基礎上采取遺傳算法對自變量進行降維,降低了計算的時間耗費,其時間計算公式如下:
T=T訓練+T測試
(11)
式中,T為總的計算時間耗費;T訓練為訓練模型所需時間;T測試為模型測試所需時間。
其時間耗費如表3所示。

表3 模型時間耗費
由表3可知,本文模型對于21種故障類型的平均計算時間耗費比BP_Adaboost模型少40多秒,并且每種故障類型的時間耗費都要低。因為采用了遺傳算法對自變量進行降維,其不僅提高了建模的精度,同時還降低了模型計算的時間耗費,能有效地對化工過程進行故障檢測。
6 總結
本文針對化工過程中故障檢測模型精度不夠,提出了一種基于遺傳算法自變量降維與優化BP_Adaboost的故障檢測方法,有效地提高了模型的建模精度,能準確地對化工故障進行檢測。經過TE過程的驗證,其結論如下:
1)采用遺傳算法進行自變量降維不僅提高了模型的精度,同時還降低了計算的時間耗費,能有效對化工過程進行故障檢測。
2)基于遺傳算法對BP網絡的權值和閾值進行參數的優化,可以避免網絡陷入局部最小值,提高模型的精度。
3)建立基于Adaboost集成學習思想的BP_Adaboost強學習器能夠有效的提高模型的精度。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
海峽科技與產業(2016年3期)2016-05-17 04:32:12
