基于對抗自編碼模型的高速泵異常檢測
2022-09-17 08:06:38王樹宇袁嫣紅張建義
機床與液壓 2022年7期
王樹宇,袁嫣紅,張建義
(浙江理工大學機械與自動控制學院,浙江杭州 310018)
0 前言
旋轉機械是一種主要依靠旋轉動作來實現特定功能的機械設備。典型的旋轉機械包括汽輪機、燃氣輪機、離心壓縮機和高速離心泵等。這些機器廣泛應用于電力、石化、冶金、航天等行業。石油化工等流程工業的生產過程都是連續化大生產,大功率高速流程離心泵作為流體輸送的關鍵動力設備,除了具備優越的動力性能指標,更重要的是在運行過程中必須具有很好的可靠性。由于大功率設備智能化水平普遍不高,在實際運行過程中經常出現故障,嚴重影響連續化大生產,造成巨大的經濟損失。因此,及時發現設備的故障具有重要意義。
目前在工業生產過程中主要依靠定期巡查來評估旋轉機械的運行狀態。這種方法無法及時發現設備的故障,同時非常依賴評估員的實踐經驗,因此需要一套針對旋轉機械設備的有效在線故障診斷方法。目前,主要借助支持向量機(SVM)、小波包樣本熵和HHT等算法對設備進行故障診斷。但這些算法是有監督機器學習方法,需要大量已知的樣本標簽,然而實際工況下缺少大量故障樣本,故限制了這些方法的廣泛應用。基于此,無監督機器學習方法更具有實際應用價值。
2006年HINTON等發表的關于深度學習的文章中也提到了無監督方法,其中著名的有受限玻爾茲曼機、自編碼網絡、對抗生成網絡。
HINTON等提出了受限玻爾茲曼機,堆疊形成深度信念網絡,其主要用于特征提取和預訓練。自編碼模型更是廣泛應用于圖像分類、模式識別、視頻異常檢測。生成對抗網絡是由GOODFELLOW等在2014 年提出的一種新型網絡結構,是一種基于博弈場景的半監督特征學習算法,隨后更是廣泛應用于圖像生成。
2019年,Google Brain和OpenAI合作的文章Adversarial Autoencoders(AAE)中提出了一種對抗自編碼的方法,該架構中訓練一個新網絡來有區分地預測樣本是自編碼的隱藏代碼還是來自用戶確定的先驗分布。本文作者基于對抗自編碼模型,通過優化網絡機構建立故障檢測模型。將一臺高速泵作為研究對象,并與傳統方法作對比,驗證所提方法在機械系統異常檢測中的優越性。
1 理論基礎
1.1 GAN網絡
GAN網絡分為兩部分:生成器和鑒別器,本質上為兩個多層感知機網絡。生成器可以生成偽造的圖像,通過訓練鑒別器將生成器生成的虛假圖像與數據集區分開。最初因為權重是隨機的,生成器會產生一些隨機噪聲,通過訓練可使鑒別器能分辨出這種隨機噪聲和真實圖像,鑒別器能力提高后,通過權值反向傳遞促使生成器生成虛假圖像的能力提高,使它生成更好的偽圖像,生成器產生圖像效果的提高又繼續反作用于判別器,繼續執行此過程,直到生成器能夠很好地生成偽圖像為止,從而使鑒別器不再能夠分辨偽圖像中的真實圖像。最終訓練好的生成器,在生成隨機數字集作為輸入的情況下,該生成器可以生成看起來真實的偽圖像,GAN就是這樣一個博弈的過程。
1.2 自編碼網絡
在深度學習中,自動編碼器(Autoencoder,AE)是一種無監督的神經網絡模型,它可以學習到輸入數據的隱含特征,這一結構稱為編碼(Encoder),同時用學習到的新特征可以重構出原始輸入數據,這一結構稱之為解碼(Decoder)。直觀上看,自動編碼器可以用于特征降維,類似主成分分析PCA,但是它比PCA性能更強,這是因為神經網絡模型可以提取更有效的新特征。除了進行特征降維,自編碼模型學習到的新特征可以送入有監督學習模型中,所以自動編碼器可以起到特征提取器的作用。旋轉機械的振動信號中往往包含著很多復雜的成分,有效的特征夾雜在復雜的成分中,但早期故障的振動成分往往比較微弱,人工提取難度較大,而采用自編碼模型可使神經網絡自動提取振動特征,有利于更好地進行故障判斷。
2 故障檢測模型
針對實際機械故障診斷工作中難以獲取故障狀態下數據樣本的問題,基于異常檢測的實際情況,提出一種故障檢測方法。
2.1 故障檢測模型結構
本文作者所采用的對抗自編碼模型如圖1所示。編碼器和解碼器組成了自編碼器結構,將大量正常的機械設備振動信息送入編碼器進行特征學習,生成被壓縮后的特征向量,然后通過解碼器將壓縮后的特征重新解碼重建振動圖像。然而,單一的自編碼模型生成的壓縮特征分布不均,不利于后續數據重建。因而,引入對抗生成網絡模型,編碼器作為對抗生成網絡的一部分,因本身能夠產生和輸入數據相關的特征數據,編碼器作為生成器不再如傳統GAN網絡那樣最初產生的是隨機數據,可以減少訓練難度,同時也使模型更容易被理解;模型中添加了新的網絡結構作為鑒別器,鑒別器最終通過Softmax層直接判斷數據的真實性。
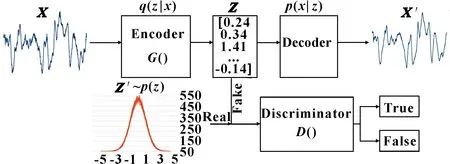
圖1 對抗自編碼模型
2.2 模型訓練
本文作者將同時訓練編碼器和解碼器,以最大程度地減少重建損失。在編碼階段,給定輸入數據,編碼器將輸入變換為特征向量:
()=[()]=[x()+]
(1)
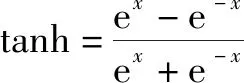
(2)
式中:()為每一個輸入()經過編碼器得到的隱藏層的特征表達;=(,)為網絡參數,為輸入層到隱藏層之前的權值矩陣,為隱藏層神經元的偏置量;()為激活函數,文中選用式(2)為激活函數:
′()=[()]=[′()+′]
(3)
式中:′()為隱藏層經過解碼后得到的重構表達;=(′,′)為網絡參數,′為隱藏層到輸出層的權值矩陣,′為輸出層神經元的偏置量。
將輸入傳遞給編碼器,該編碼器將提供輸入特征的潛在特征,將這個潛在特征傳遞給解碼器以獲取輸入數據曲線。通過反向調整編碼器和解碼器的權重,減少重建損失。AE的學習目標是最小化重構誤差,使得輸入與輸出盡可能接近,損失函數選擇式(4)所示的均方差損失函數:
=(-′)
(4)
進入訓練的第二部分,訓練鑒別器對編碼器輸出和一些隨機輸入′(實驗中采用標準正態分布)進行分類。因此,如果傳入具有期望分布的隨機輸入,則判別器輸出True;當傳入編碼器輸出時,輸出為False。直觀地,編碼器的輸出和鑒別器的隨機輸入都應具有相同的大小。
將編碼器輸出作為輸入連接到鑒別器,目的是迫使編碼器輸出具有給定先驗分布的值。使用編碼器(|)作為生成器,使用鑒別器來判斷樣本是來自先驗分布()還是來自編碼器(|),解碼器(|)返回原始輸入圖像。
生成器訓練時應保持鑒別器的權重固定為當前的權重,并在鑒別器的輸出端將目標固定。之后將圖像傳遞到編碼器,并找到鑒別器輸出,然后將它用于查找損耗(交叉熵代價函數)。僅通過編碼器權重進行反向傳播,會使編碼器學習所需的分布并產生具有該分布的輸出(將鑒別器目標固定為1會導致編碼器通過查看鑒別器權重來學習所需的分布)。
判別器在這里是一種分類器,用于區分樣本的真偽,因此常使用交叉熵(Cross Entropy)判別分布的相似性。交叉熵公式;
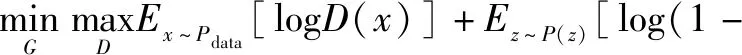
(()))]
(5)
鑒別器訓練時保持生成器權重不變,盡可能地讓鑒別器能夠最大化地判別出樣本來自于真實數據還是生成的數據。
輸入的振動信息不僅含有單純的機械振動信息,還包含大量的無用振動,為能夠讓網絡更好地學習振動數據的特征以及加快網絡學習效率,該模型在編碼器部分以及鑒別器部分加入了Dropout層,通過在每次訓練時,隨機讓每層小部分神經元停止工作,每次輸入網絡的有效數據只是部分數據,以此達到去噪聲的目的,以提高網絡的泛化能力。
3 實驗驗證
3.1 實驗平臺
本文作者選用的實驗設備是某熱電廠運行的型號為HTD250-160X10的多級離心泵,為工藝上的給水泵,基本工作參數:10級離心泵,額定流量為250 m/h,額定揚程為1 500 m,額度轉速為2 950 r/min,額定功率為1 273 kW。實際設備如圖2所示。自制的數據采集器,采樣頻率為50 kHz,單次采樣個數是1 000點;選用的傳感器為電渦流振動位移傳感器,通過電渦流效應,對泵的振動信息進行無接觸、連續的采集。數據采集完成后通過4G網絡上傳到自建的云平臺系統,采集器24 h在線運行。
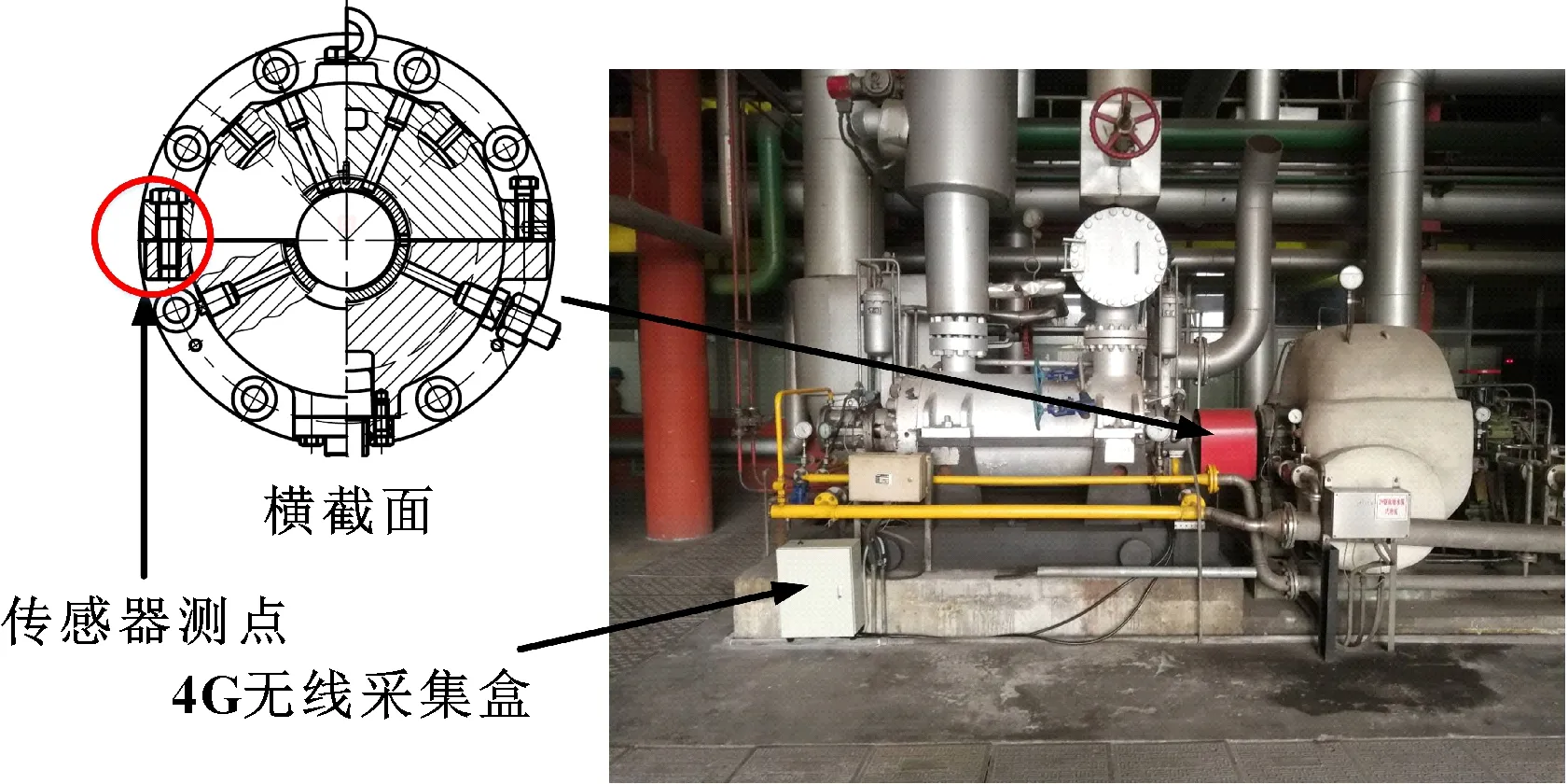
圖2 實驗設備
3.2 訓練
在云平臺中隨機抽取1 024組數據作為訓練樣本,每組數據有1 000個振動數據作為特征。訓練batch size取64,自編碼learning rate為0.001,對抗生成網絡learning rate設置為0.000 5,epoch取2 000。每次迭代將(64,1 000)的振動數據輸入構造的對抗自編碼模型中進行訓練。對抗自編碼模型在原有模型的基礎上加入了dropout層,神經元丟棄率為0.2,在損失函數中加入交叉熵,進一步約束、指導神經網絡進行特征學習。最后,將梯度信息反向傳播并更新梯度,以最小化損失函數。圖3所示為損失函數曲線。
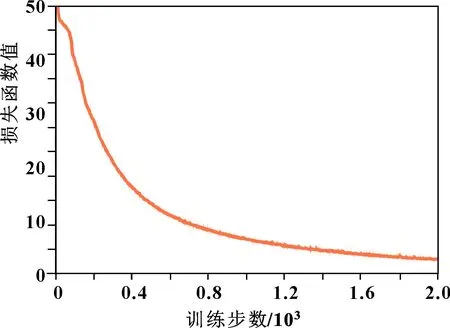
圖3 損失函數曲線
在對抗部分中,模型輸入了正態分布的數據指導自編碼部分的隱藏層學習其分布。圖4顯示了從最初到訓練結束過程中隱藏層數據分布的變化,直觀地表示出數據從最初分布極為不均到最后分布接近標準正態分布的過程。
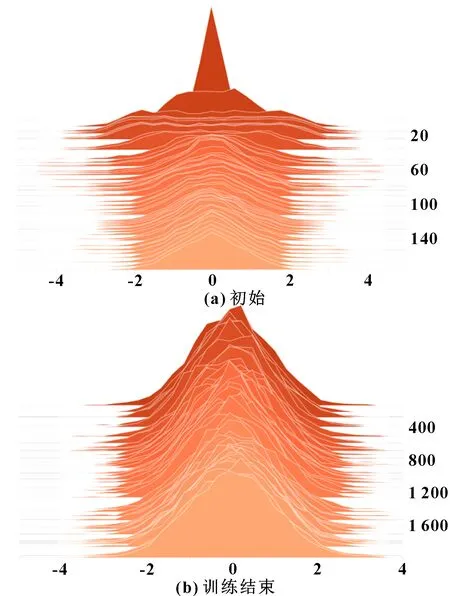
圖4 隱藏層數據分布
將云平臺下載的數據分別輸入對抗編碼模型,實際輸入的振動圖像信息與編碼解碼后重建振動圖像的對比如圖5所示。可知:重建圖像很好地學習了輸入信息的特征并加以復現。
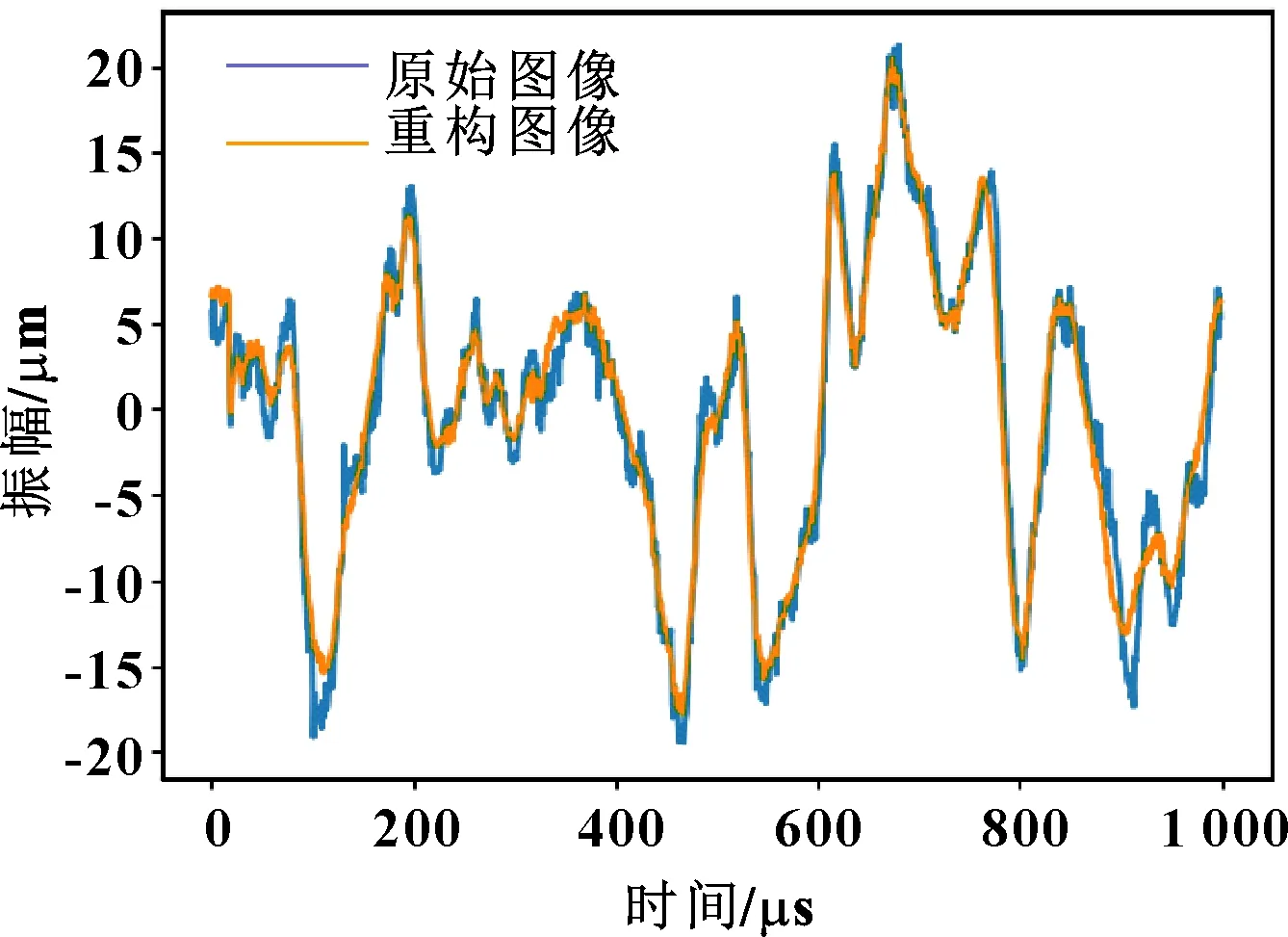
圖5 數據重建
3.3 誤差檢測
為檢驗模型訓練后的實際效果,同時選取未曾訓練過某一時刻泵的振動數據作為模型的輸入,由兩種數據重構情況的不同鑒別泵的運行狀態。選取未曾訓練過的數據點,其中包含200個正常數據點和20個異常數據點,以此測試訓練好的模型。數據點輸入模型后,將重構數據點與原數據進行對比,通過二者的誤差區別數據的狀態,同時選用傳統自編碼網絡模型進行對比,結果如圖6所示。可知:傳統自編碼器模型雖然能夠重建部分圖像,但是并不能將異常數據和正常數據進行明確的區分;對抗自編碼模型通過在隱藏層生成的均勻數據分布大大提高了模型的自適應性,即使是未曾訓練過的數據點,通過對比也可以看出,異常數據點分布于圖像上方,正常值數據點位于圖像的下側。可通過設定閾值來進行實際工況下泵的健康狀態評判。
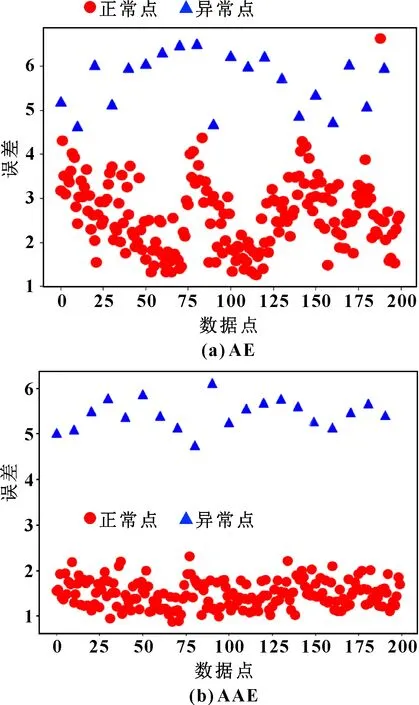
圖6 誤差對比
為直觀評價模型效果,引入混淆矩陣。混淆矩陣是二分類問題的多維衡量指標體系,在樣本不平衡時極其有用。在混淆矩陣中,將少數類認為是正例,多數類認為是負例。
TP(True Positive)為在預測正樣本中,預測正確的數目;FP(False Positive)為在預測正樣本中,預測錯誤的數目;TN(True Negative)為在預測負樣本中,預測正確的數目;FN(False Negative)為在預測負樣本中,預測錯誤的數目。準確率是所有預測正確的樣本除以總樣本的值,越接近1越好。精準率又叫查準率,表示所有被預測為少數類的樣本中,真正的少數類所占的比例。假正率表示模型將多數類判斷錯誤的能力。
取不同閾值,模型對泵異常檢測的準確率、精準率、假正率如表1所示。
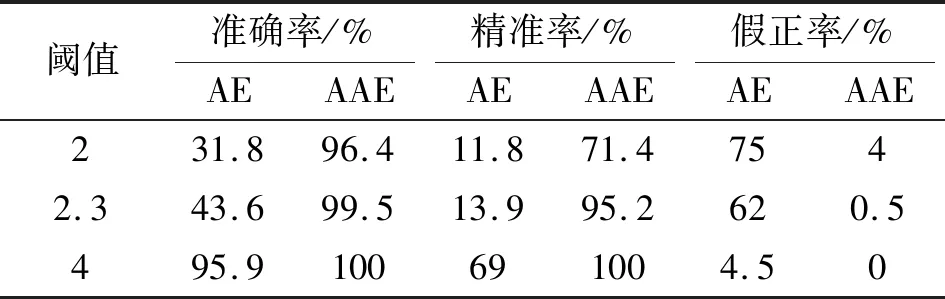
表1 不同閾值下模型效果對比
4 結束語
本文作者將基于自編碼器的神經網絡模型應用于高速泵故障檢測領域,通過優化對抗自編碼的網絡結構使模型在故障檢測中具有更好的適用性;提出了一種誤差閾值的故障檢測方法,該方法利用機械振動信號的高維特征參數,通過自編碼網絡自動提取特征并學習,依據模型輸出的變化,實現故障預警。結果表明:基于AAE模型的誤差閾值檢測方法在特定閾值下準確率可達100%,明顯優于傳統自編碼模型,具有一定的研究價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
