分層教學中決策樹歸納分類及應用
2022-08-24 09:48:06劉楊
淮北職業技術學院學報 2022年4期
劉 楊
(安徽水利水電職業技術學院 質量管理辦公室,安徽 合肥 231603)
0 引言
正如不能用一把尺子去衡量萬物,也不能用一個標準去衡量每一個學生。由于學生家庭因素、成長經歷、個人努力程度的不同,他們在知識現狀、知識學習能力、思維品質、思維能力等方面都會存在或多或少的差異。近年來,人們對個人在教育中的主體地位和個性在人的發展中的影響逐漸重視,這使班級授課制統一進度與個體差異之間的矛盾日益突出,如何做到因材施教、關注學生的個性差異成為教學發展的應然訴求,實施分層教學是解決這一問題的有效方案。
分層教學模式承認學生差異,注重因材施教和個性化培養,是我國教育教學研究中的熱點之一。[1]分層教學是指根據教學內容,綜合考慮學習者生理、心理特點及學習能力,尊重學習者存在的差異性,將水平相近的學生分為一組,便于采用個性化和具有針對性的教學方法,提升學生整體水平。盡管這種教學策略的有效性得到了廣泛認可,但其有效性建立在對學生合理分組上,這一問題一直是制約分層教學大規模推廣的阻礙之一。
傳統的分層策略通常由一組教師團隊或教學規劃團隊基于教學實施經驗分析得出,但這種分組方式受團隊自身環境的主觀性影響較大,這使得對分層規劃人員的要求相對較高。不具備較多教學經驗的規劃人員往往會引入不合理的分層設計。此外,在需要規劃的學生規模較大或者教學環境發生較大變化時,傳統的分層經驗的可靠性會受到一定程度的損失,并會耗費較多的分析時間。
那么,如何科學合理地對學習者進行層次劃分則成為分層教學的關鍵問題。分層教學的層次劃分涉及學習者的學習情況、心理素質、情誼特征、認知風格和性格傾向等,需要的信息數量巨大,形式多樣,采用先進的科學手段才能快速有效地實現分析過程。數據挖掘可使用戶從海量數據中獲取需要和感興趣信息,含有多種分類方法,決策樹歸納是其中的一種。[2]決策樹歸納分類所需的訓練數據少,便于理解和解釋,可視性強,分類規則形成簡便。故將決策樹歸納應用于分層教學研究中,可以為分層教學的層次劃分提供科學的指導和理論依據。本文就決策樹歸納技術進行研究,分析其在分層教學中的應用。
1 決策樹歸納分類
分類是根據已知類別的數據集構建分類模型,然后,對未知類別數據進行分類的過程。大量的數據對象構成一個數據集,每一個數據對象都具有多個屬性。在分層教學中,每個學生就是一個數據對象,他們的姓名、學號、年級、專業、獲得的學分、專業排名、獎懲情況、心理健康、性格特點等就是屬性。所謂分類就是要給數據對象賦予一個類標號。分類一般分兩步完成,如圖1所示。第一步,建立一個模型,通過對已有類標號的數據集(也稱為“訓練集”)進行學習,構建分類器;第二步,利用分類器,對未分類的數據(也稱為“測試集”)分類。分類的核心就在于使用某種算法,通過大量的訓練集,構造出分類器。之后,通過分類器,對新的未分類的數據做分類。

圖1 數據分類過程
決策樹是樹形結構的分類模型,如圖2所示,由根節點、中間節點、樹葉節點和分枝組成。根節點和中間節點代表一個屬性,根據屬性節點可以對數據對象進行劃分,每一個劃分就是一個分枝,葉節點則代表一個類別。
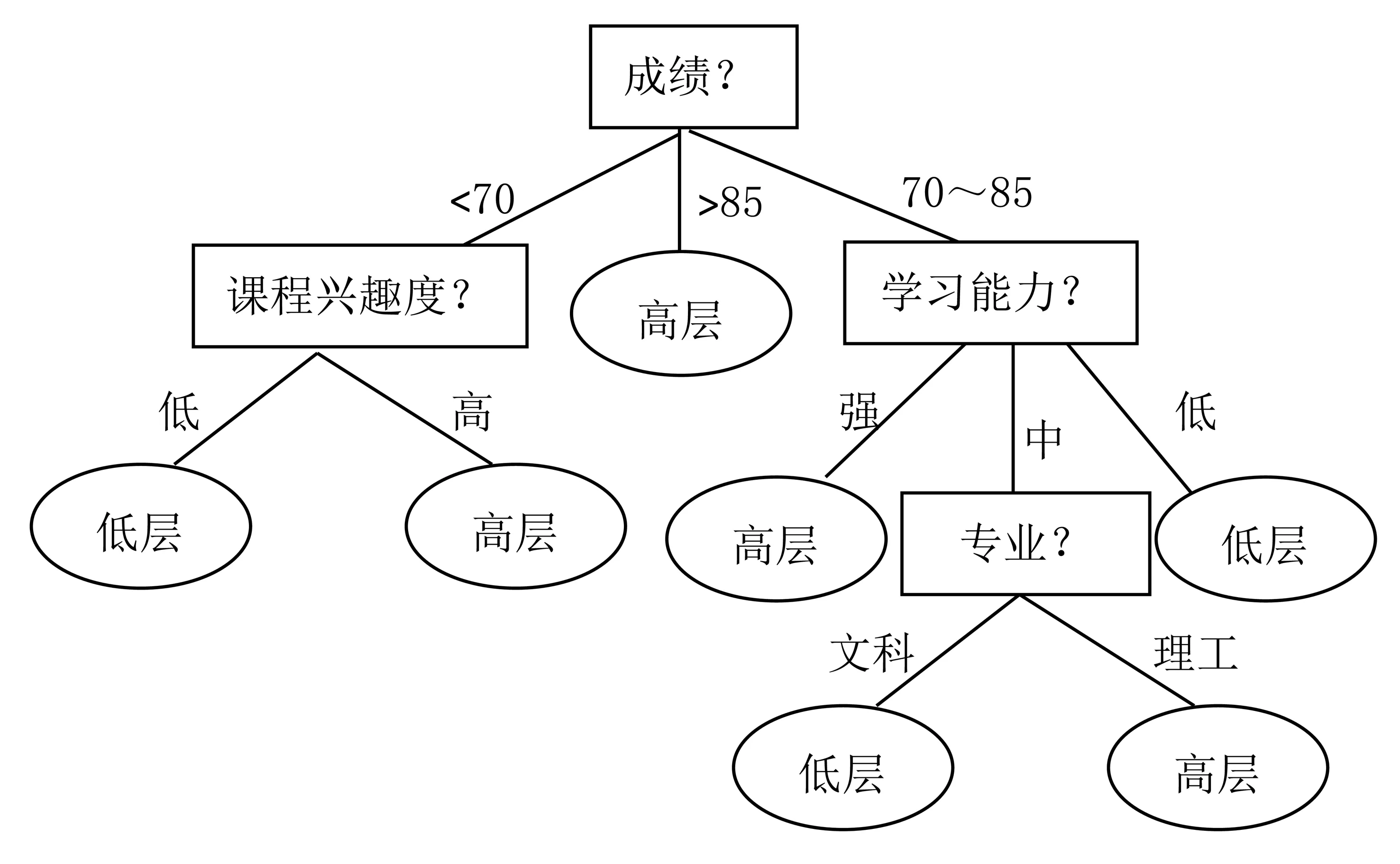
圖2 決策樹結構
決策樹的構建采用自頂向下遞歸算法。[3]樹節點從根節點開始,采用基于熵的信息增益來對數據對象的每一個屬性進行度量,從而選擇出能夠進行最好分類的屬性作為節點,對數據對象進行劃分,創建分枝,然后,根據剩余屬性的信息增益再次選擇節點,依次往下,直到分枝下的數據對象都在同一類,則標記類標號,是為樹葉節點。
設數據樣本有s個,構成集合S,可以分成m個類別,記為Ci(i=1,2,…,m)。設Ci類中數據樣本有si個,則對該樣本分類所需的期望信息為:
(1)
其中:pi是概率,表示樣本屬于類Ci的概率,用si/s表示。
假設屬性A具有v個不同值{a1,a2,…,av},將數據樣本集劃分為v個子集{S1,S2,…,Sv}。設sij是子集sj中類Ci的樣本數,則由屬性A劃分子集的信息熵為:
(2)
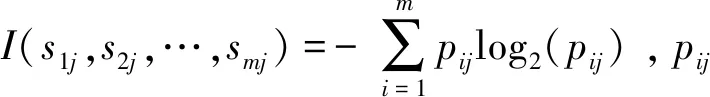
則屬性A的信息增益是:
Gain(A)=I(s1,s2,…,sm)-E(A)
(3)
信息增益最大的屬性可作為決策樹根節點的測試屬性。
2 決策樹歸納分類應用舉例
以某高校思想政治類課程分層教學[4]為例,說明決策樹歸納分類方法的應用。判定樹算法的基本策略如下:
步驟一:樹以代表訓練樣本的單個節點開始;
步驟二:如果所有樣本都在同一個類,則該節點成為樹葉,并用該類標記;
步驟三:如果所有樣本不都在同一個類,則基于信息增益選擇能夠最好地將樣本分類的屬性,該屬性成為該節點的測試屬性;
步驟四:對測試屬性的每個已知的值,創建一個分枝,并據此劃分樣本;
步驟五:使用同樣的過程,遞歸地形成每個劃分上的樣本判定樹。一旦一個屬性出現在一個節點上,就不必考慮該節點的任何后代上。
當下列條件有一條成立時,以上的遞歸劃分步驟停止:
(1)給定節點的所有樣本屬于同一類;
(2)沒有剩余屬性可以用來進一步劃分樣本,用樣本集中的多數所在的類標記它;
(3)分枝中沒有樣本,以訓練樣本中的多數類創建一個樹葉。
表1給出了學生數據訓練集,類標號有兩個值:高層用C1表示;底層用C2表示。C1類有9個樣本,C2類有5個樣本。訓練樣本集用于生成決策樹,訓練樣本量不能少于10,決策樹多生長一層,對訓練樣本量的需求會增加一倍。如果往屆教學已有過分層教學,則可以從往屆分好層的學生集中選取具有代表性的學生樣本,由于其測試屬性和類標號都是已知的,直接即可作為訓練樣本集。如果沒有進行過分層教學,缺少現成分好類的學生樣本,則需要授課教師構建出訓練樣本集。授課教師需要選取部分學生樣本,根據學生的實際情況,再結合自身的經驗,對選取的學生樣本進行類標號的賦值。學習能力和課程興趣度則可以根據學習專注力、學習成就感、自信心、思維靈活度、獨立性和反思力、課堂表現、課堂參與度等進行度量。初次構建出的訓練樣本集可能會出現數量較少、部分學生分類不合理等問題,但這些問題通過大量測試樣本的測試和學習是可以得到糾正的。
首先,計算該樣本分類所需的期望信息如下:
=0.940

表1 某高校學生數據訓練樣本集
其次,計算每個屬性劃分樣本的信息增益。以成績為例,計算過程如下:
對于成績=“<70”:s11=2,s21=3,I(s11,s21)=0.971
對于成績=“70~85”:s12=3,s22=2,I(s12,s22)=0.971
對于成績=“>85”:s13=4,s23=0,I(s13,s23)=0
根據公式(2),按照成績劃分子集的熵信息為:
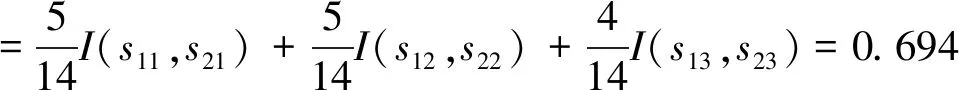
根據公式(3),屬性成績的信息增益是:
Gain(成績)=I(s1,s2)-E(成績)=0.246
按照上述同樣的過程,依次可以計算出其他屬性的信息增益,為Gain(學習能力)=0.048,Gain(課程興趣度)=0.151和Gain(專業)=0.021。由此,屬性成績具有最高的信息增益,被選為測試屬性,作為根節點,并對每一個屬性值,引出分枝,樣本集據此進行劃分。其中:落在成績=“>85”的樣本為同一類,該分枝的端點創建一個葉節點,用高層表示。在分枝成績=“<70”和成績=“70~85”內,重復上述過程,再次計算剩余屬性的信息增益,直到所有的劃分都屬于同一類為止。最終形成的決策樹如圖2所示。
沿著決策樹的根節點到葉節點的路徑,可以得到IF—THEN分類規則,例如:
分類規則1:IF成績=“>85”,
THEN學生類別=“高層”
分類規則2:IF成績=“70~85”AND學習能力=“強”
THEN 學生類別=“高層”
分類規則3:IF成績=“<70”AND課程興趣度=“弱”
THEN 學生類別=“低層”
例如:有一測試樣本,數據為:成績為“80”,學習能力“強”, 課程興趣度“高”,專業“理科”,則根據分類規則2,可以將其分類為=“高層”。這樣根據決策樹提取的分類規則,就可以對思想政治類學生進行分層劃分。當判定樹創建時,由于訓練樣本集可能存在錯誤分類或者奇異點數據等問題,樹結構的分枝反映的異常數據,導致在分類過程中,出現不符合分類規則的數據,此時,可以對決策樹采用剪枝處理,重新對決策樹進行修正。因此,基于決策樹歸納分類進行分層具有有效性和可行性。
3 結語
決策樹歸納是數據挖掘中的一種非常有效的分類方法。初始只需要較少數量的訓練樣本即可生成決策樹;然后,基于決策樹,歸納提取出IF-THEN分類規則;基于分類規則,則可以對測試樣本進行分類。在分類過程中,還可以對決策樹進行剪枝、加強等修正工作,使決策樹歸納分類越來越科學,越來越合理,越來越符合實際情況。將決策樹歸納用于某高校思想政治類課程分層教學中,詳細說明了訓練樣本集的構建、決策樹的生成和分類規則的提取,因此,基于決策樹歸納分類進行分層具有有效性和可行性,為分層教學提供了新的思路和途徑。
教育教學中,沒有哪一種教學方法和教學模式最好,只有根據學生實際情況,采用具有針對性的教學方法,才能調動學生學習的積極性和主動性,取得好的教學效果。分層教學能夠針對學生個體差異,尋求最合理的教學形式和方法,實現教學效果的最優化。[5]采用決策樹歸納分類方法可以綜合考慮學生的各個方面,科學地將學生進行分層,讓學有余力的學生接受更多更大挑戰,同時,也不要破壞稍微落后學生的自信心和意志力,盡可能做到宋代著名教育家朱熹在《四書集注》中所說的“圣賢施教,各因其材。小以小成,大以大成,無棄人也”[6]。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
甘肅教育(2020年14期)2020-09-11 07:57:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
東方教育(2017年19期)2017-12-05 15:14:48
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
唐山文學(2016年2期)2017-01-15 14:03:59
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
