基于粒子群優化算法的中小企業競爭情報搜集系統模型
2021-12-17 11:03:30王洪林
科技管理研究 2021年21期
王洪林,劉 偉
(山東科技大學計算機科學與工程學院,山東青島 266590)
我國中小企業一般指從業人員在1 000 人以下的企業,具體分為中型、小型、微型三種類型。據中國產業調研網公布數據顯示,目前我國中小企業數量接近5 000 萬個,占我國企業總數的99.7%,同時對我國國內生產總值增長貢獻率達67.7%,稅收貢獻率超過50%。值得注意的是,據天眼查公布數據顯示,“十三五”期間(2016—2020 年)我國新注冊的企業中,中小企業占比近60%[1]。由此可見,中小企業在我國企業經濟中占有并將持續占有極其重要的地位。伴隨著全球經濟一體化的市場格局、知識經濟和全面進入大數據信息化時代,競爭情報已成為企業的“第四核心競爭力”[2]。我國中小企業面臨著愈加復雜的市場環境,企業對信息的搜集,處理能力直接關系到對市場的應變速度及決策部署,關乎企業發展的生死存亡,因此中小企業情報及決策部門對競爭情報搜集系統存在迫切需求。
有學者指出企業所需的競爭情報80%分布于公開信息源中,而網絡技術的發展,使得幾乎所有公開信息都能在網絡中檢索得到[3]。目前,大型企業逐步構建自己的競爭情報系統,建立屬于本企業的情報網[4]。在許多大型跨國企業中,應用最為廣泛的是競爭情報作戰室系統,如Microsoft(微軟),Ford(福特),Amazon(亞馬遜)等企業的競爭情報作戰室,Walmart(沃爾瑪)的危機公關作戰室,GE(通用電器)的戰略規劃作戰室等[5];在我國,競爭情報系統(Competitive Intelligence System,CIS)同樣被建立在如中國石油、中國移動等大型國有企業;而大型民營企業由于資金和技術的限制,通常采用企業的CIS 同一些競爭情報的信息咨詢公司合作的方式[6]。
相比競爭情報系統發展較早且完善的大型企業而言,我國中小企業對競爭情報搜集分析并提供企業戰略決策的相對較少,這并不利于我國中小企業在信息環境下的發展。近些年國內外學者均嘗試通過不同研究視域對中小企業競爭情報工作開展研究。Choo[7]認為中小企業的信息收集及情報分析是與企業經營者持續互動的合作過程。Ram[8]發現中小企業缺乏企業競爭情報相關服務的現狀,Savioz[9]為使競爭情報工作更好地為中小企業決策提供支持,設計了用于搜集、分析、傳播和利用信息的技術情報系統。Nenzhelele[10]研究發現,中小企業依然存在簡單通過即時通訊、搜索引擎、競爭對手網站等進行信息搜集,競爭情報搜集效果并不明顯。黃曉斌等[11-12]結合大數據和云計算相關技術的應用對企業競爭情報工作變化進行分析,構建了中小企業競爭情報系統;之后提出由數據采集、策管、分析、服務和協調控制5 個子系統構成的企業競爭情報系統。韓穎[13]通過對中小企業競爭情報狀況分析發現,競爭情報工作在我國中小企業無法高效開展的主要原因包括企業管理層缺乏大數據環境下競爭情報的戰略意識、缺乏競爭情報領域的高素質人才、獲取和分析信息的方式和技術單一落后導致大量有效情報浪費、沒有完善的競爭情報工作體系、沒有專項企業競爭情報資金投入等諸多因素。我國在中小企業競爭情報理論模型構建方面的研究還較為欠缺[14]。為優化競爭情報工作中的情報搜集過程,以粒子群優化算法原理類比,采取跨學科分析法和仿真實驗檢驗法,嘗試從競爭情報獲取方面建立質量高、速率快、易組織管理的競爭情報搜集系統,以支持我國中小企業戰略決策規劃。
1 粒子群優化算法
1.1 起源與發展
粒子群優化算法(Particle Swarm Optimization,簡稱PSO 算法),最初是由Kennedy 等[15]、Eberhart等[16]在1995 年通過模擬鳥群覓食過程中聚集和遷徙行為所使用的智能行為提出的一種依托群體智能的演化計算技術,本質上是一種集群智能優化算法。PSO 算法簡單易行,目前已成功應用于求解各種復雜問題[17-18],主要在函數優化、圖像處理、數據挖掘與分類、離散組合優化神經網絡設計、模式識別等應用領域取得重大成效[19]。PSO 算法的機理并非類似遺傳算法對鳥群中的個體進行選擇、變異和交叉,而是以在N 維搜索空間中沒有體積和質量的粒子(點)更新聚集模擬鳥群中的各個個體的協同覓食行為,目的是尋找當前解空間中的最優解,這與競爭情報中通過協同行為尋找某項目情報信息最集中的信息源有相同之處。
1.2 算法原理
設想以下場景:一塊未知區域食物隨機分布,有一小部分區域食物最集中,即單位面積包含食物量最多,一群鳥在這片區域隨機搜索食物,鳥群間通過分享當前位置和食物量信息更改飛行方向和距離,最終使得所有鳥均到達食物最多區域。粒子群優化算法求解優化問題時,問題的解對應搜索空間中食物源的位置,食物最多的區域對應問題的最優解,搜索空間中的鳥被視為“粒子”(particle)或“主體”(agent),每個粒子都有一個適應值來衡量其所在位置的優劣程度,粒子所在區域食物越多其適應值越高。每個粒子均受到粒子原有速度屬性、個體歷史最優位置、全局最優位置三個方面的影響,不斷更新飛行方向和速度,進而更新粒子的適應值尋找全局最優解。PSO 算法步驟如下:
(1)初始化:對于一個D維向量優化問題,PSO 算法首先通過隨機產生一定規模的粒子作為問題搜索空間的有效解,即m個初始解(m代表初始粒子數),每個解Xi(i=1,2,……,m)是一個D維向量,為每個粒子隨機初始化速度、位置及飛行速度并計算其適應值fiti。為防止粒子偏離搜索空間,粒子的每一維速度v都需在[-Vdmax,+Vdmax]之間[20],粒子最大速度Vmax為粒子的范圍寬度。位置信息設為整個搜索空間,將每個粒子自身的歷史最優解(pBest)設為當前位置,所有粒子中pBest 最優的個體作為當前的全局最優解(gBest)。
(2)迭代:初始化種群后進行迭代,迭代次數記作iter(iter=1,2,……,itermax),itermax為最大迭代次數。迭代過程中,各粒子更新方式如下:
在每次迭代中,各粒子性能的優劣程度通過跟蹤兩個“極值”對自身位置和速度進行更新[21]:這兩個極值分別為粒子本身當前所找到的歷史最優解(pBest)和粒子群中當前所找到的全局最優解(gBest),每個粒子均受到粒子原速度向量、個體歷史最優位置向量與粒子位置向量的差向量、全局最優位置向量與粒子位置向量的差向量三個方面的影響更新粒子速度和位置。以粒子群在D維目標搜索空間中的粒子為例,粒子i的信息均可以通過向量表示,速度表示為Vi=(vi1,vi2,…2viD)T,位置表示為Xi=(xi1,xi2,…,viD)T,其他向量類似。對每個粒子i在D維空間中的速度及位置更新公式為:
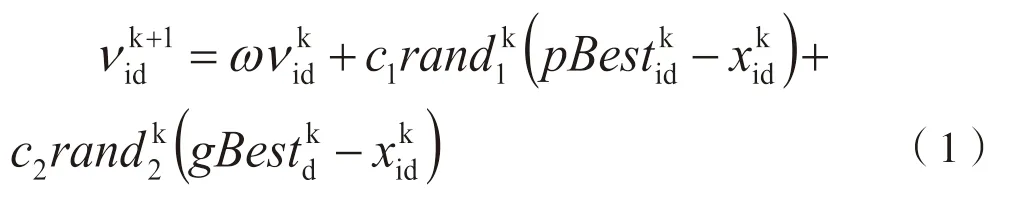

其中,令慣性權重ω為0.9,并隨著迭代的線性地減小ω的值進行自適應調整直到0.4[22];通過仿真獲得φ的經驗值,當φ=4.0(c1=2.0,c2=2.0)時具有最好的收斂效果且不易陷入局部最優,因此加速因子c1和c2均為2.0[13];rand1和rand2是[0,1]之間的隨機數;表示粒子i在第k次迭代中第d維的當前位置;pBestid是粒子i當前在第d維的個體最優解位置;gBestid是整個粒子群當前在第d維的全局最優解位置。每種維度的迭代方法均相同。
根據貪婪策略,如果某一粒子迭代過程中當前位置的適應值函數比其個體歷史最優解好,則該粒子個體歷史最優解將會被當前位置替代,否則保留原個體最優解[23];同理,如果全局最優解被某一粒子的個體歷史最優解替代,說明其適應值函數比原全局最優解好,否則將保留原有全局最優解。每次迭代中每個粒子的更新方法均相同,且每次更新后都要檢查更新后的粒子位置是都在解空間中,否則必須通過重新隨機設定或限定在邊界進行修正[24]。
(3)結束:當步驟(2)操作完成itermax 次迭代(或已得到全局最優解)后,PSO 算法結束,輸出全局最優解。
1.3 用于企業競爭情報的數學模型
假設現有一規模為30 人的中小企業A 需要對B項目搜集情報,導入粒子群優化算法作為類比構建多維空間坐標轉換模型,并將信息源映射在該模型中的對應位置作為有效解:
(1)屬性劃分。項目B 所需的所有可能包含有效情報的信息源類型分布在解空間中,企業競爭情報收集團隊為該企業除分析決策層外的全體員工,該團隊成員總數為全集U(即隨機產生的粒子數)。情報搜集人員在解空間中隨機開展搜索工作,每個情報人員在搜索過程中均具有搜索速度和搜索信息源位置兩種屬性,當前搜索信息源位置的情報數量越大則其適應值越高,表明該位置在解空間中局部最優。情報人員更新搜索信息源位置的因素有三種,分別為WI、WB 和IB,其中WI 表示自身個體認知和正在進行的情報搜索經驗帶來的搜索慣性,相當于粒子原有速度;IB 表示某一情報人員當前已發現的最優信息源位置,相當于當前個體歷史最優解;WB 表示通過情報人員間信息共享并對每名情報人員的IB 比較后得出的當前情報搜索空間中已被發現的最優信息源位置,相當于當前全局最優解。每個解Xi(i=1,2,…,m)是一個D維向量,D是收集工作的優化參數,Xi確定后,每個Xi所指示當前信息源位置的預估情報量稱為Xi的適應值fiti。
(2)情報搜集。設置代表情報搜集工作的開展次數為iter(iter=1,2,…,itermax),itermax為進行搜索次數的最大值。當情報搜集工作已完成itermax次或各情報搜集人員均已在情報最多的信息源及附近位置進行搜索時,尋找最優信息源工作結束,輸出全局最優解,各情報人員對該類型及相近信息源進行重點情報收集。否則情報人員循環進行如下工作:
任意情報搜集人員i 在搜索空間中進行搜索速度和信息源搜索位置更新。這類更新受到WI 向量、IB 與當前搜索信息源的關聯向量VO(由當前搜索類別指向IB)、WB 與當前搜索信息源的關聯向量VW(由當前搜索類別指向WB)三種向量共同影響進行仿射變換,通過公式(1)生成新的搜索速度,并通過公式(2)確定新的搜索信息源位置。確定后,在和之間的fiti通過貪婪策略進行選擇并選取具有更高fiti的Xi為i的IB,并在交流區與其他m-1 名情報搜集人員分享本輪工作結束后的所在信息源及其情報量情況,將與的情報量依次比較,選擇情報量更多的X為WB。
迭代過程中將慣性權重ω由0.9 線性減至0.4,這能使各搜集人員先依據自身情報搜索經驗探索新的信息源,使其有拓展搜索空間的趨勢,再趨向全局最優信息源,加速收斂效果。這樣可以最大限度探索搜索空間,并快速將搜索力集中在情報量最多的信息源。
2 構建競爭情報搜集系統模型
2.1 構建原理
本文根據我國中小企業競爭情報團隊在對項目進行競爭情報搜集時各信息源在搜索空間中的關聯規則,將包含與該項目相關情報的信息源按一定規則映射在解空間中對應位置,并將每一名情報人員比作一個粒子。每個情報人員在搜索空間中更新當前搜索情報源位置時,搜索慣性就是粒子自身運動慣性,某一情報人員當前已發現的最優情報源就是該粒子當前個體歷史最優解,所有員工當前已發現的最優信息源就是粒子群當前全局最優解。但與PSO 算法不同的是,信息源類別存在于一個泛化的環境中,因此它的數量并不確定,需要情報人員根據個人及全局搜索經驗在這個環境中探索。同時信息源對應位置也不能按照PSO 算法機械化確定,需要結合社會公認的各信息源間的聯系來確定不同信息源的跨度,并映射在搜索空間中的對應位置。搜索過程中應注意各類信息源適應值的記錄,在搜索結束確定全局最優解后對各信息源的適應值由大至小排序,采用擇優的選擇策略對排名前n位的信息源依次開展情報搜集工作。至此,該競爭情報搜集系統將PSO 算法數學模型轉為信息源類型轉換模型,可以稱其為競爭情報搜集系統粒子搜索模型。
2.2 構建要素
(1)解所在位置——信息源。各類信息源如競爭對手內部狀況、競爭產品情況、宏觀市場走向等具有情報搜集價值的信息都分布在如年報、財務數據、政策信息、匯率趨勢、競品優勢、宣傳內容、人際關系、供應商等信息源中。類似PSO 算法中解所在位置,有效信息源是中小企業開展競爭情報搜集的基礎,沒有可靠的信息源,競爭情報的搜集及后續分析等工作就無法開展。分析不同的企業和競爭對手需要不同情報,其對應的信息源也存在差異,因此針對粒子搜索模型中參與者的業務素質,需要有一定搜索經驗并對各種項目有普遍適應性—強調認知廣泛,弱化專業性。尤其是泛在與Web3.0 環境中的競爭情報要格外留意。相較于Web2.0 環境信息含量大、更新速度快但體積小的特點,Web3.0 在此基礎上提供基于用戶需求的智能過濾器和多元化需求滿足平臺,該環境中信息交互和整合更便捷[25]。這就打破了情報人員信息搜集的信息壁壘,弱化數字鴻溝,如附著在微博、社交平臺等信息平臺的各類數據在高效、智慧化處理后被有效信息利用[26]。在企業全員參與源于Web3.0 的競爭情報的開發過程中,人工分布式情報挖掘理念被廣泛運用,這種搜索方式將在Web4.0 環境的大規模同步智慧網絡中智慧生成多種情報搜索策略供情報人員結合需求選擇[27],使信息搜集更快速高效且個性化。
(2)運動慣性——搜索慣性。在基于PSO 算法的中小企業競爭情報粒子搜索模型中,情報人員在搜索時對搜索狀態的信任類比粒子對運動狀態的信任,主要負責新信息源的發現和探索。通過適當的培訓和氛圍培養,使每個員工都具有競爭情報嗅覺,將要搜索的信息源位置向經驗方向偏移。
(3)個體最優粒子經驗——個體最優信息源位置。某情報人員當前已發現的最優信息源就是單個粒子經過的最優位置,即對已搜索信息源預估情報量的記憶功能。這會使情報人員對當前情報源類型進行評估思考,并為下次迭代時信息源更新劃定范圍。
(4)群體最優粒子經驗——全局最優信息源位置。情報人員當前已經發現的最優信息源類比當前已發現的最優粒子位置,當ω減小使系統開始收斂時,情報人員的搜索方向就開始向該領域靠攏,若在搜索過程中發現更優秀的信息源則將其替代。因此搜索工作迭代越后期,該位置的社會影響越明顯,越有利于快速將最終搜索目標集中在最可能是全局最優的信息源。
(5)媒介——通訊機制。如同粒子群優化算法的自然界原理中,鳥群經過一輪搜索后通過信息交流的方式比較種群找到的最好位置。為保障通訊過程的安全性、穩定性和可靠性,競爭情報搜集系統內同樣需要可靠的通訊機制。因此,在此模型中通訊可以使用企業內部通訊軟件(如騰訊使用釘釘,字節跳動使用飛書,360 使用藍信,百度使用百度hi 等),也可以使用短信、郵箱等工具,甚至是舉行會議面對面交流。
2.3 保障機制
PSO 算法本質上是一種計算機仿生的集群智能優化算法,競爭情報搜集系統粒子搜索模型中更多的是人的行為,而無論是人的哪種行為均需要一定的保障制度,這能確保系統的正常運行。
結合中小企業特征和內外信息環境,本文認為其保障機制主要有以下幾點:
(1)協作共享機制。在情報人員進行信息源搜索的過程中,相互合作并及時實現信息共享是情報工作在本模型開展的重要特征。在當今復雜多變的信息環境中,生成信息的數據每秒都在以PB 級單位增長,單純依靠地毯式的信息源搜索已經不能適應要求。信息共享作為每次搜索工作的關鍵也在搜索過程中起到承前啟后的作用,同時協作共享機制可增強全員溝通合作及信息共享效果,更有助于最優信息源的確定及其重要度排序。
(2)保密機制。情報具有保密性,尤其是有關于企業機密的情報,一旦外泄對企業后期的影響將不可估量。在情報搜集階段和后續情報分析階段,需要建立完備的保密機制才能保證企業競爭情報不會落到競爭對手手中,以免對企業造成直接或間接威脅。
(3)激勵機制。如粒子群優化算法的自然原型鳥群捕食行為,是出于生存的本能。而在企業中除信息資源和情報戰略等部門外,其他員工沒有義務進行競爭情報搜集,因此建立能調動積極性的激勵機制是必要的。
(4)責任機制。面對信息爆炸式增長的大數據時代,情報搜集人員需要在泛濫的信息中初步甄別其真實性、時效性和可用性,對公司的情報、戰略部門和管理層負責。這些部門的負責人要對情報搜集過程跟蹤監督并進行質量把控,以此形成雙向負責制。
2.4 模型構建
2.4.1 情報搜集流程
本文將信息源搜索過程分為初始化、迭代和記錄排序三個步驟,見圖1。每名情報搜集人員均執行相同的操作。
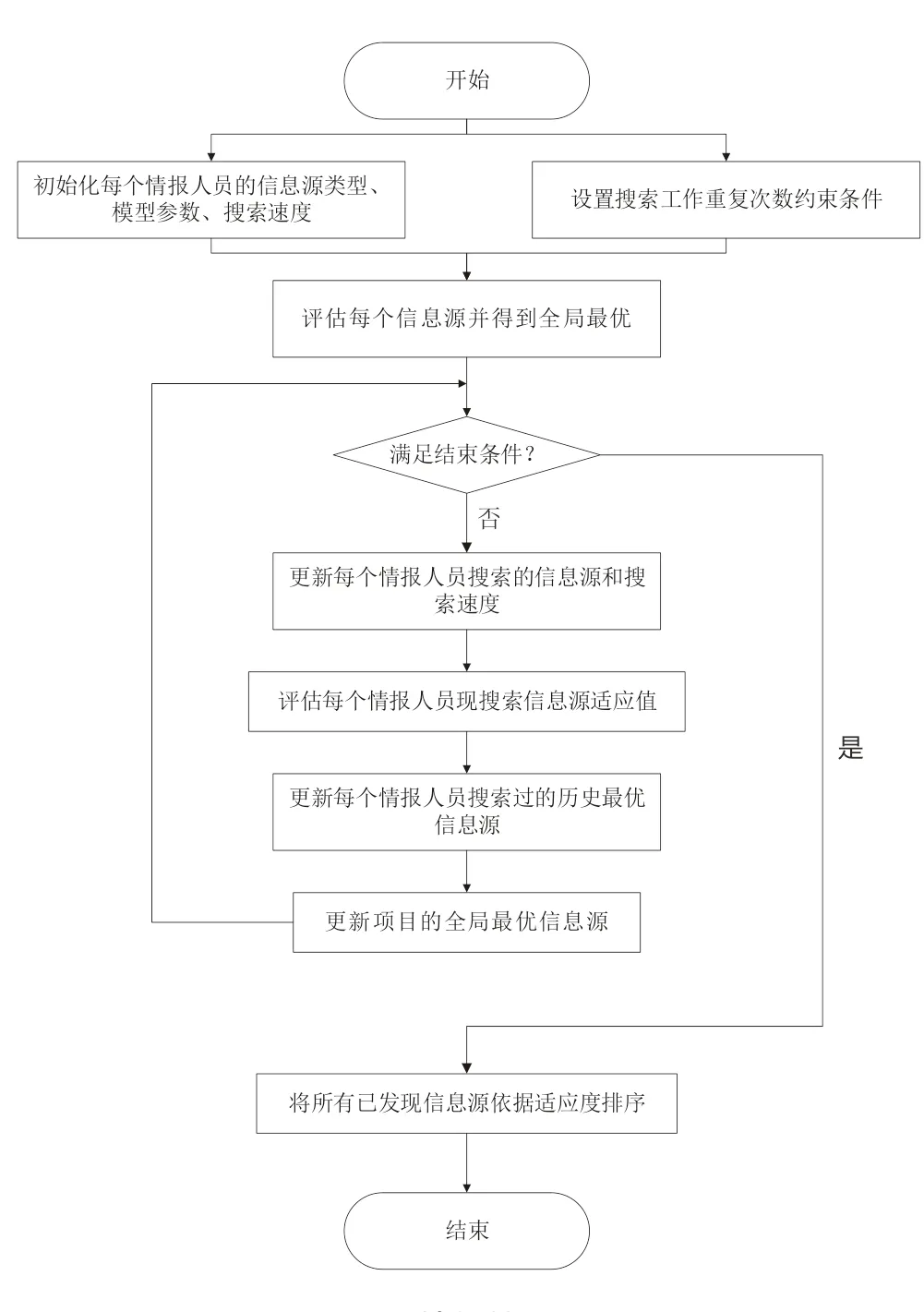
圖1 情報搜集流程
2.4.2 單次迭代每名情報人員搜索情報源對應位置更新
如圖2 所示,每輪搜索工作中,情報人員在解空間中進行當前信息源更新,原信息源受到搜索速度、目前個人最優解和目前全局最優解三者共同影響確定更新后的信息源。

圖2 基于PSO 算法的單次信息源對應位置更新示意圖
2.4.3 競爭情報搜集系統粒子搜索模型
如圖3 所示,本文將該模型分為情報搜索層,控制層和決策分析層。在情報搜索層中,S1-SN 表示企業中有N 名情報人員進行信息源搜索工作,矩形邊界表示解空間(即搜索空間),其中包含多種信息源類型。不同情報人員隨機在解空間中初始化調查的信息源位置,在迭代中將其依據圖2 所示進行更新(圖3 中僅顯示情報人員搜索的信息源位置更新情況)并記錄每次更新后信息源的情報含量作為適應值。所有情報人員搜索的位置在itermax 次迭代后收斂至適應值最高的全局最優位置,將搜索到的信息源依據適應值從高到低排序后逐級進行情報搜集。
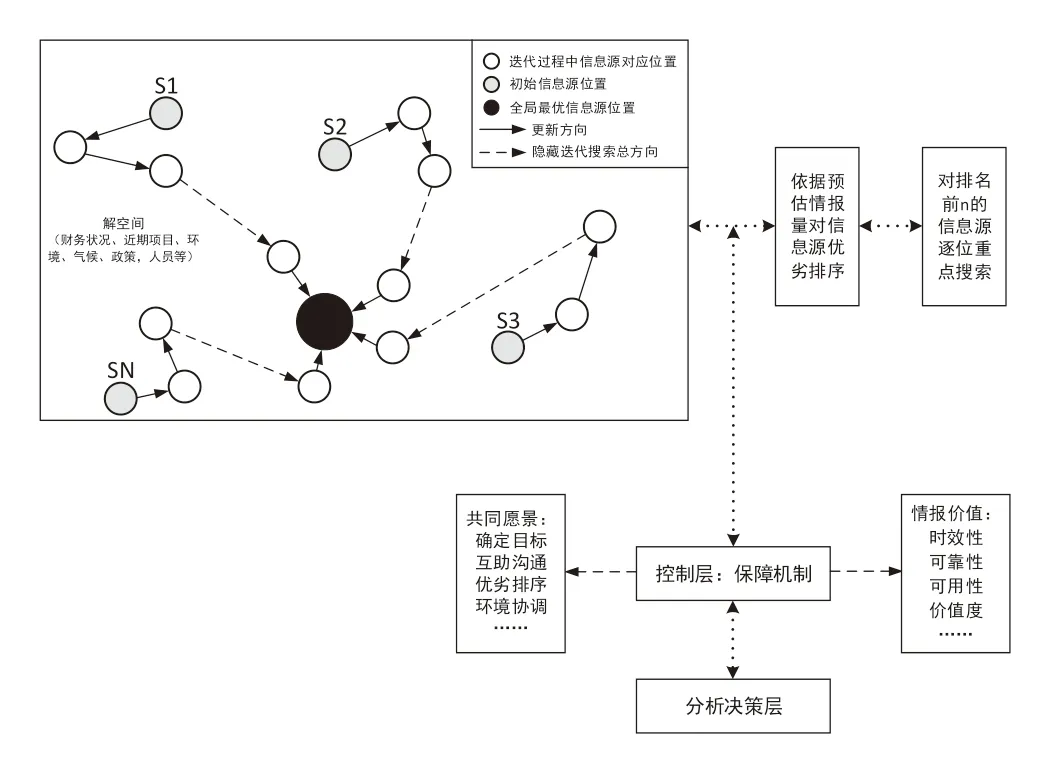
圖3 基于PSO 算法的競爭情報搜集系統粒子搜索模型
控制層主要起到控制情報采集的價值,效率、安全和激勵的作用。同時公司應該指定明確的情報價值判定標準,用于評測情報對企業的效用價值。為達到搜索效率最大化,應結合管理學中激勵、組織、控制理論,適當激勵員工對其搜索工作提供原動力。
分析決策層由企業高級管理層或信息戰略部門充當。在員工從各個領域搜集回海量信息后,該層人員應具備挖掘分析可用情報的能力,并結合情報分析做出報表為企業戰略決策提供參考和支持。
3 仿真實驗結果分析
本文的仿真實驗工具為Python 3.8.2,數據集來自某公司某項目調查信息源及其預估情報量。為了驗證粒子群優化算法對優化情報搜集過程的有效性,基于競爭情報搜集系統粒子搜索模型,模擬30 名情報人員對374個信息源映射在二維空間的對應位置,迭代400 次尋找全局最優(即預估情報量最大)信息源的搜索過程。
通過圖4 對比可得,情報人員在初始化時搜索的信息源位置隨機分布在搜索空間中,在第150 次時已完成收斂,所有情報人員集中在(-9,17)對應的信息源位置,該位置對應信息源適應度(即預估情報量)為74。
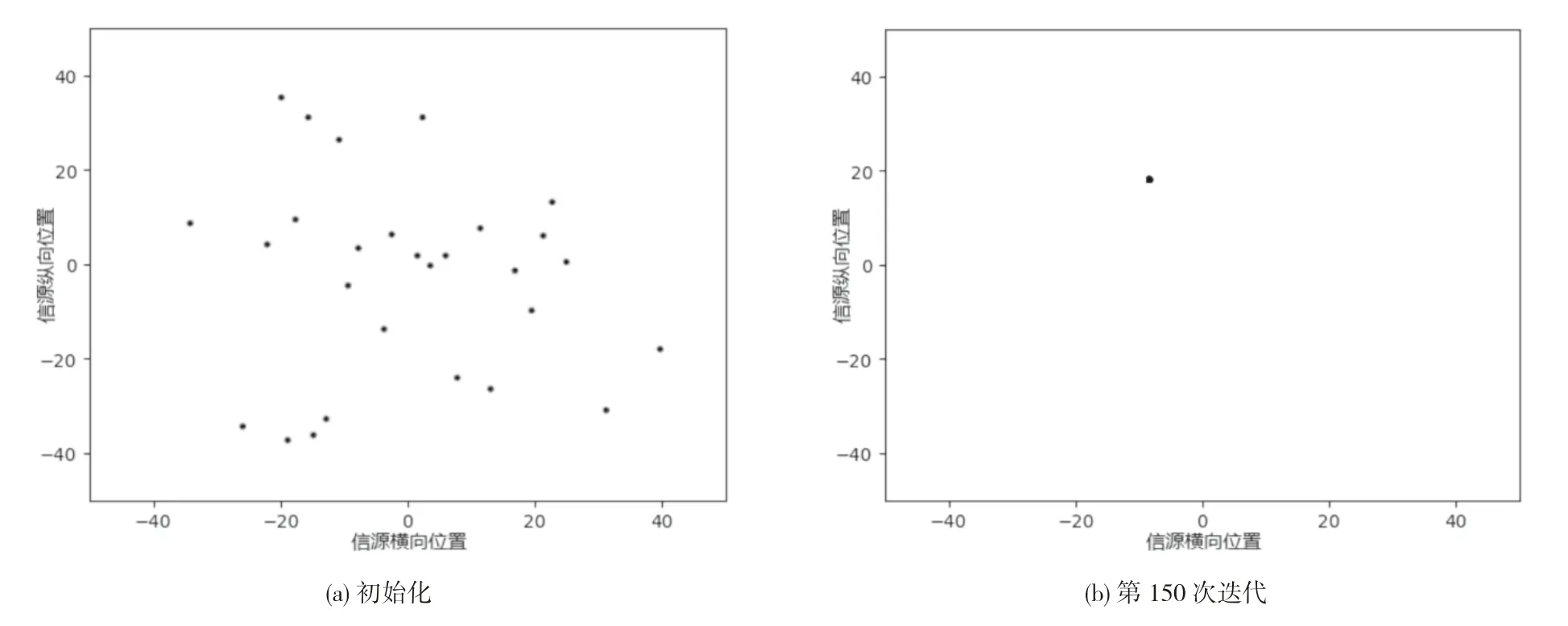
圖4 情報人員搜索信息源位置對比
如圖5 所示,反映的是模型中粒子群優化算法在模擬上述搜索過程中的粒子迭代進化過程,橫軸和縱軸分布表示搜索工作迭代次數和相應的適應度函數值。從模型算法迭代圖中可以得出:受到慣性權重ω 線性遞減的影響,算法迭代初期搜索速度快,情報人員具有較強的尋優和拓展搜索空間的能力,能夠較快確定最優解位置;當算法迭代一定次數后,搜索速度減慢,適應度值隨迭代次數變化趨于平緩,但情報人員并未失去仍具有一定的尋優能力,能夠使該模型算法有跳出局部最優解,最終得到全局最優解。結合圖4 結論可知,150 次迭代時已完成尋優工作,全局最優解為適應度值為74 且映射空間位置為(-9,17)的信息源。由此可得,粒子群優化算法在求解一定空間內信息源尋優問題時具有較好的搜索效率,可以快速搜得全局最優解對應的信息源并有一定能力跳出使算法早熟的局部最優問題。
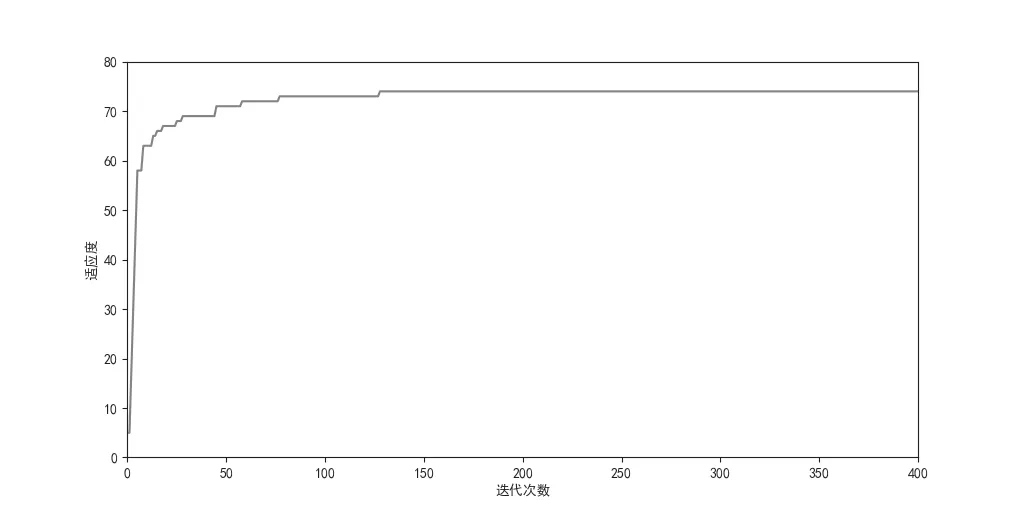
圖5 模型算法迭代
信息源搜索工作結束后,將各個信息源按搜索過程中得到的預估情報量從多到少排序,情報人員后續可依據信息源優劣排序對前n 位逐次重點搜集分析。至此,仿真實驗結束,基于競爭情報搜集系統粒子搜索模型在實際應用中具有較好的尋優效果,且一定程度上防止算法陷入局部最優解,具有較強實用價值。
4 應用實例
廣州科盟電子有限公司是一家民營中小型企業,現有64 名員工,包括中高級管理人員12 人,主要從事專業電聲產品研發、制造、銷售與服務工作。通過調研發現,為對標國內先進市場,該企業引入國內先進生產技術并先后投入200 萬元設計制造新型DJG CL 系列音箱,使其產品產量和質量均達到國內行業先進水平。然而,受產品上市時間較短、缺乏統一的信息源評估體系和信息共享平臺、沒有適應本企業的情報搜集方法、對該產品針對性的市場策略研究不足等因素的影響,該系列音箱銷量一直無法提高,給新產品的研發帶來很大困難。
為提高產品銷量給新產品研發提供充足資金保障,促進公司可持續性發展以提高行業競爭力,2021 年2 月1 日,該公司嘗試采用全員參與并建立企業內部競爭情報粒子搜索模型的方式進行情報搜集,以達到企業內競爭情報服務“更精、更準、更快”,情報質量更高成本更低的目標,提升情報價值。
公司除銷售部,產品研發設計部,市場信息部等7 個部門的分析決策層7 人和董事會5 人外全員參與競爭情報搜集,其主要搜集流程如下:
(1)短期全員信息素養培訓,縮小組織內信息源選擇質量的差異。
(2)搭建企業內部統一的信息共享平臺,制定統一的信息計量評估標準。
(3)總經理確立當前決策需求,經各部門分析后制定情報需求。
(4)調動部門員工從各個可能產生情報的維度如政策、年報、供應商來源和用戶偏好等搜索信息源,通過信息計量等方法對各信息源情報量進行評估并上傳至信息共享平臺。
(5)每個搜集周期結束時通過信息共享平臺對當前已知的所有信息源價值進行整理反饋。
(6)循環(4)和(5),并根據情報需求緊急程度設置發散到保守型思維收集策略的過渡節點。
(7)依據預估情報量對所有已知信息源排序。
(8)選擇前20 個信息源重點進行競爭情報挖掘,匯總上報最終決策層。
為提高員工情報搜集參與度和積極性,公司承諾給予價值情報每個獎勵500 至1 000 元,高價值情報3 000 至5 000 元。
截至2021 年5 月18 日,廣州科盟電子有限公司以3 萬余元的現金獎勵采集到競爭情報327 條,其中包括箱體設計專利技術、小箱體高靈敏度高保真大聲壓市場需求、高新技術中小企業扶持政策等價值情報43 條。這些情報為決策層調整產品在市場中的策略布局等方面提供了有效的支持,市場拓展、營銷投資比例優化等策略使DJG CL 系列音箱銷量提升約55%,產品利潤得到大幅提升,新產品研發資金壓力得到有效緩解,公司在促進內部情報生態良性發展的同時提升了企業及產品競爭力。
5 競爭情報搜集系統粒子搜索模型的特點
5.1 主觀影響偏重
與傳統情報搜集不同,該模型強調個人認知與社會影響這類心理學理論的結合。鼓勵員工在搜索過程中充分發揮自身經驗和搜集習慣,使得項目與情報之間的結點更多、更全面,再與群體經驗結合尋找最優搜索路徑和信息源類型。也就是說,員工在搜索路徑決策的過程中使用兩種重要信息:一是自身經驗,二是其他人的經驗。
5.2 情報質量高
在該模型中,偏重經驗意味著需要更多具有情報搜索知識和經驗的專業人員,情報人員不需要進行傳統的全局搜索即可得出搜索空間中各類信息源的優劣程度。通過運用檢索工具和分析思路擇優重點進行情報搜集、分析,最大限度地開發和利用情報,深度挖掘高價值信息源中符合企業戰略發展的高質量情報。
5.3 情報時效性強
在信息爆炸時代,及時有效的情報對企業保持競爭力有極其重要的作用。中小企業若因決策失誤產生危機,會使企業完全喪失市場競爭力,但如果采用模型及時偵測相關情報并為決策提供支持,就可以迅速采取有效措施應對或規避危機。同時模型在一定程度上減小搜索范圍,提高搜索效率,更利于企業尋找到強時效性情報。
5.4 模型的缺點
金無足赤,在該模型中也存在諸多問題未能有效解決。一是搜索過程不易控制,缺乏自適應調節,較易陷入局部最優,導致在搜索過程后期出現收斂精度不高的問題。二是該模型對參數要求較高,對不同企業需要選擇合適的參數來達到最優效果,這需要企業在實踐中不斷積累經驗,形成適用于本企業的模型參數。三是企業在較大解空間中搜集情報時需要其他員工協助,而這部分員工缺乏經驗及專業素養,需要專業情報人員依據模型流程進行前期培訓。
6 結束語
在數據信息大發展和新經濟時代的大背景下,各行業企業間競爭增強,信息化在企業中的地位日益提升。我國中小企業數量龐大,但信息化程度普遍不高,這直接導致了競爭情報意識不強、獲取和分析的方式和技術單一落后的現狀。而競爭情報在戰略決策部署、產品策略研究等方面直接影響企業,對中小企業的重要性逐漸增強。至今已有大批情報學者為解決這一矛盾進行大量研究,探索優化方法。
本文將粒子群優化算法原理與我國中小企業競爭情報搜集過程的現狀相結合,構建了一個競爭情報搜集系統,該系統引入全局及個體“經驗”和對搜索狀態的信任,以期指導我國中小企業發動除分析決策層外全員參與情報搜集和重要性排序,分析決策層的高管及負責人進行情報分析及決策制定,最大限度開發高質量信息源,獲得與企業息息相通的競爭情報,以應對我國中小企業情報獲取效率不高、資金和人才匱乏的現狀,建立高效率、易管理且行業適用范圍較廣的中小企業個性化競爭情報搜集系統。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
云南畫報(2020年9期)2020-10-27 02:03:26
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
