HITS算法在論文引用關系中的應用
2021-03-01 03:32:42黃印
內蒙古科技與經濟 2021年24期
關鍵詞:排序
黃 印
(南京大學 信息管理學院,江蘇 南京 210023)
目前,絕大部分傳統文獻數據庫檢索系統,對于檢索結果文獻的組織都是基于文獻的外部特征和內部特征,外部特征主要包括篇名、作者姓名、發表時間,內部特征包括關鍵詞、標題詞、敘詞等等。在互聯網化的學術平臺上,被引次數和下載次數作為重要的外部指標,也常常被使用。以CNKI為例,檢索結果可以按照“相關度”、“發表時間”、“被引”和“下載”等進行排序。
引用關系是論文間的重要關系。一篇論文被引用,證明了這篇論文的影響力。目前引用關系的常用量化指標是“被引次數”。但是這個指標存在一些問題,許多學者認為,被引次數只有當引用是真引用才是合適的[1]。除此之外,不同論文對文獻的引用也不應該視作等價。在現有的“被引次數”指標中,一篇領域內重要論文的引用和一篇普通論文的引用次數是相同的,體現的是引用關系的數量特征,掩蓋了引用關系的質量特征。
對于引用關系的質量特征的量化,目前并沒有廣泛應用的方法。但是論文之間的引用關系與網頁之間的鏈接關系具有很高的相似性,因此對于論文之間的引用關系的質量特征的量化一定程度上可以借鑒、參考搜索引擎中網頁的排序方法。
楊思洛按照排序技術進行分類,將搜索引擎分為三代,我們目前正處于第二代搜索引擎,即按照鏈接分析的方式進行排序,主要有PageRank算法[2],HillTop算法[2]。除此之外,頁面排序算法還有:HITS算法,主題敏感 PageRank算法 (TSPR)等[3]。
為了量化引用關系的質量特征,對“被引次數”指標進行補充,參考了搜索引擎鏈接分析的排序機制,提出了使用HITS算法對檢索結果進行計算,使用計算值來量化引用關系的質量特征,并實驗了HITS算法在量化引用關系的質量特征中的實際效果,進一步研究了HITS算法在不同數量級別下的可靠性。
1 相關研究
1998年,就職于Cornell University的克萊因伯格博士提出了HITS 算法(Hypertext-Induced Topic Search)[4]。HITS算法的原理基于這樣的假設:一個高質量的權威(Authority)頁面會被很多高質量的樞紐(Hub)頁面所指向,反之亦然。
在搜索領域,相對于PageRank算法,HITS算法存在一些缺點,沒有被目前主流的搜索引擎所采用。主要有兩點:①HITS算法是基于某一檢索主題的,而 PageRank 算法不受限制。②HITS算法是在得到結果集后進行計算,耗時較長。
將鏈接分析方法應用應用于文獻引用中,是因為兩者在本質上十分相似:兩者研究的都是一個網絡模型中兩個元素之間的影響關系及其形成過程,都具有高度的目的性和理性。也有學者做過類似的嘗試,比如李江等學者從算法角度對網頁評價和文獻評價進行了對比,將PageRank算法應用于論文中,提出了Paperank算法。該算法傾向于挑選出高被引的、被高質量且少出度的論文引用的論文,是對被引次數的一種修正。 筆者嘗試將HITS算法應用到檢索文獻的排序中,并初步評價其效果。
2 HITS算法
具體而言,應用于文獻中的HITS算法需要計算兩種值,即權威值(Authority Scores)和樞紐值(Hub Scores)。所有引用該文獻的文獻的樞紐值的和即權威值。該文獻所有引用的文獻的權威值的和即樞紐值。
HITS算法的數學計算步驟如下所示[6]:
①a(i)表示文獻i的權威值,h(i)表示文獻i的樞紐值,所有文獻的權威值和樞紐值初始設定為1。
②迭代計算,a(i)等于所有引用文獻i的文獻的樞紐值之和,即:a(i)=Σh(j)
j指所有指向文獻i的文獻。
③h(i)等于文獻i所有引用的文獻j的權威值之和,即:h(i)=Σa(j)
④將所有文獻的a(i),h(i)進行標準化,即都除以其最大值。
n是指所有文獻。
⑤計算上一輪迭代計算中的值和本輪迭代以后值的差異,在達到允許的誤差之前,不停地重復上述②③④步驟。只有當對于總體來說差異在允許的范圍內,證明數據已收斂時,才可以結束計算。
3 HITS算法實證分析
3.1 數據來源
由于CNKI中大批量的檢索結果難以快速直接地導出,為了方便收集、計算數據,筆者選取人工智能領域來源于2015年度中國計算機學會(CCF)于人工智能方面推薦的A、B、C三類共39個國際學術會議論文,作為數據集,作為使用某一檢索策略進行檢索,所得到檢索結果的模擬,具體會議如表1所示。

表1 CCF于人工智能方面推薦的國際學術會議
2016年,清華大學唐杰教授團隊建立了Aminer,該數據庫是計算機及相關領域的知名數據庫,收集了大量關于人工智能的學術論文成果。Aminer被設計為面向新一代的科技情報分析與挖掘,而且完全不依賴外國知識產權。筆者以Aminer中的Open Academic Graph(OAG)作為數據來源,下載了截止到2017年3月22日的所有論文題錄信息,共得到113 195篇文獻。
3.2 數據處理
數據中,存在文獻的“被引次數”和“引用的文獻”字段。由于本文的研究對象是113 195篇文獻,所以在“被引次數”之外,根據“引用文獻”計算“數據內被引次數”——數據內是指作為計量對象的113 195篇文獻。
將“被引次數”和“數據內被引次數”進行對比,發現存在一些文獻“被引次數”為0,但是“數據內被引次數”很高的情況。比如,其中3篇的“被引次數”是0,但是 “數據內被引次數”卻分別高達1 128、981和999次。經過查證,這3篇文獻的標題都是各類會議的總集文件。通過對比“被引次數”和“數據內被引次數”數據,再進行人工檢查,發現這類文獻共有526篇,去除這些文獻,剩余112 669篇。最后計算112 669篇文獻的權威值和樞紐值。
3.3 數據分析
112 669篇文獻的權威值和樞紐值按照權威值、樞紐值排序前20分別如表2、表3所示。

表2 權威值排序前20文獻情況

表3 樞紐值排序前20文獻情況
可以明顯地看出,權威值較高的文獻大都有著較高的“數據內被引次數”,樞紐值較高的文獻大都有著較多的“數據內引用文獻”。
為了探究指標之間的關系,對其進行相關性檢驗。使用SPSS工具對所有數據進行統計分析,結果顯示,所有指標都是非正態分布的。而斯皮爾曼相關系數法可以適用于非正態分布的數據,故采用次方法,結果如表4所示。
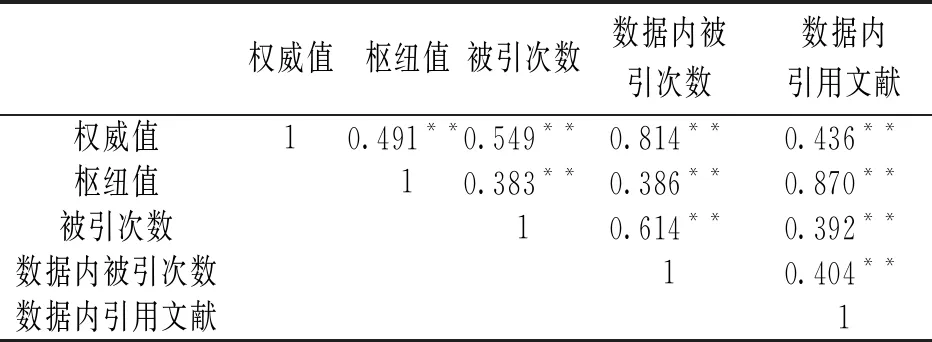
表4 相關性檢驗
從表4可以看出,“權威值”與“數據內被引次數”相關度很高,相關系數為0.814,屬于高度相關;“樞紐值”與“數據內引用文獻”相關度很高,相關系數為0.870,屬于高度相關。“權威值”與“被引次數”的相關性不如“數據內被引次數”,相關系數僅為0.549。
可以初步得到一個結論,“權威值”與“數據內被引次數”高度相關,可以揭示某個領域內的引用情況,而且與“數據內引用文獻”相關,兼顧了文獻引用的文獻的影響。
3.4 進一步研究
上文的研究基于的數據是112 699篇文獻,但是很多時候,檢索結果往往只有幾十篇,幾百篇。為了探究HITS算法在不同規模數據下的效果,筆者選擇在這112 699篇文獻中,以摘要中包含“AI”和“Artificial Intelligence”的1 046條數據為例,計算各指標之間的相關性。得到結果如表5所示。

表5 相關性檢驗(1 046篇)
可以看出,在數據量較少的情況下,各個指標之間的相關度明顯降低。為了找出HITS算法具有較好效果的數據集大小界限,選擇AAAI,CVPR兩個會議的11 932條記錄作為研究數據。得到結果如下表6。

表6 相關性檢驗(11 932篇)
3種數據量得到的結果的“權威值”與“數據內被引次數”的相關性進行對比,得到表7。

表7 3種數據量下“權威值”與“數據內被引次數”的相關性
可以看出,當數據量在一萬級以上時,HITS算法具有較高的可靠性;當數據量在一萬以下時,可靠性急劇下降。
4 總結與展望
綜上所述,“權威值”指標與“數據內被引次數”指標高度正相關,與“數據內引用文獻”也有一定的相關性。這表示,將“權威值”作為指標,與“被引次數”相比,有以下優點:①可以更好地反映一個主題內(或者一個檢索結果內)的文獻被引情況。②根據權威值和樞紐值的算法,“權威值”是引用文獻的樞紐值之和,“樞紐值”與“數據內引用文獻”高度相關,可以說權威值是綜合了“數據內被引次數”和“數據內引用文獻”兩個指標。相比于“被引次數”,權威值能夠選出既被廣泛引用地,也引用了高質量文獻的文獻。
“權威值”也存在以下缺點:①計算速度可能比較慢。②如果檢索結果數量少于一萬,會導致文獻間的引用關系數量不足,使得HITS算法的“權威值”不能很好地反映真實情況。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
名家名作(2021年9期)2021-10-08 01:31:36
名家名作(2021年4期)2021-05-12 09:40:02
名家名作(2021年3期)2021-04-07 06:42:16
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
新世紀智能(語文備考)(2019年12期)2020-01-13 06:04:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
名家名作(2017年2期)2017-08-30 01:34:24
