基于連接強度的動態蛋白質網絡構建算法研究?
2020-12-23 11:49:50羅愛靜許家祺顏湘茹
計算機與數字工程 2020年11期
李 鵬 閔 慧 羅愛靜 許家祺 顏湘茹 伊 娜 劉 杰
(1.湖南中醫藥大學信息科學與工程學院 長沙 410208)(2.中南大學湘雅三醫院 長沙 410006)(3.醫學信息研究湖南省普通高等學校重點實驗室(中南大學) 長沙 410006)(4.湖南信息職業技術學院軟件學院 長沙 410200)
1 引言
自從人類基因測序工程完成后,生命科學研究的重點已經從基因組學轉到了蛋白組學[1]。同時隨著計算機硬件的發展以及智能信息處理技術的進步,采用計算機相關技術對蛋白組學中的諸多問題展開分析和研究是目前的熱點。其中,關于蛋白質相互作用網絡(Protein-Protein Interaction Network,PPIN)[2~3]的研究是一項基礎性的工作。
眾所周知,生物體內蛋白質之間的相互作用總是動態變化的[4],這種變化體現著生命進化與發展的一種自然趨勢和必然結果。然而,動態變化的蛋白質網絡給基于計算機技術的蛋白組學研究帶來巨大的挑戰,如何準確地對動態蛋白質網絡進行建模和分析已經成為制約該領域中很多問題研究的瓶頸。為此,國內外相關學者對蛋白質網絡的建模問題進行了大量的研究,提出了一系列有代表性的建模方案,例如,文獻[7]從多維角度出發綜述了構建蛋白質網絡的常見方法,并展望了動態蛋白質網絡研究的發展趨勢。文獻[8]根據蛋白質的基因表達變化情況將蛋白質分為動態和靜態兩類,進而提出了一種動態-靜態蛋白質混合的時序網絡構建新方法。然而該方法缺少對噪音的系統化分析,網絡構建結果容易受到假陽性和假陰性數據的干擾。文獻[9]利用概率統計中常見的3-σ 法則來判斷蛋白質的活性,進而提出了基于活性周期的蛋白質網絡構建方法。但是這種方法經常會過濾掉一些一直有較高表達信息的蛋白質,造成數據的丟失。胡塞等[10]分析了蛋白質相互作用數據和基因表達數據對于網絡構建的作用,建立了一種改進的動態蛋白質網絡D-PIN(Dynamic Protein Interaction Networks)。然而該文對于采樣周期的選擇主要通過實驗設定,不具有普適性。針對以上方法的不足,本文對動態蛋白質網絡的構建問題進行了研究,提出了一種基于連接強度的動態蛋白質網絡構建算法。并最后通過仿真實驗驗證了所提算法的有效性。
2 構建動態蛋白質網絡
本文借鑒進化圖[11]在描述復雜動態網絡方面的優勢,采用進化圖來完成動態蛋白質網絡建模過程。為了便于理解,下面給出一些相關的定義:
定義1 進化圖假設有一動態圖G=(V,E),V是G 的頂點,E 是G 的邊。它的子圖包含:GS={},有。設TS=t1,t2,…,tT表示所有子圖存續時間,則稱Θ=(G,GS,TSi)是進化圖,其中i=1,2,…,T 。
定義2 活性蛋白質設Pr 表示某一生物體內的一個蛋白質,PrAGE表示Pr 的基因表達均值,如果在某一時間段T 內,都存在關系:PrAGE≥ε,其中ε 是閾值因子。則稱Pr 是活性蛋白質,并記Ac(Pr)為Pr 的活性周期。
2.1 網絡構建細節
緊接著上述定義,我們分為如下的三個階段來構建動態蛋白質網絡:1)基于基因表達均值計算來判斷各個蛋白質的活性,確定各自的活性周期;2)對各個活性蛋白質劃分時間片,具有相同活性周期的蛋白質擁有同一時間。對于同一時間的所有活性蛋白質,依據后續定義的連接強度來構建蛋白質子網;3)采用進化圖理論對各個蛋白質子網進行建模,從而構建得到動態蛋白質網絡。
2.1.1 計算蛋白質的活性周期
蛋白質活性周期的計算是構建動態蛋白質網絡的第一步。假設,蛋白質Pr 在時刻i 的基因表達值為,1 ≤i ≤n。Pr 的基因表達值的標準差為(Pr)。則有如下的計算公式:
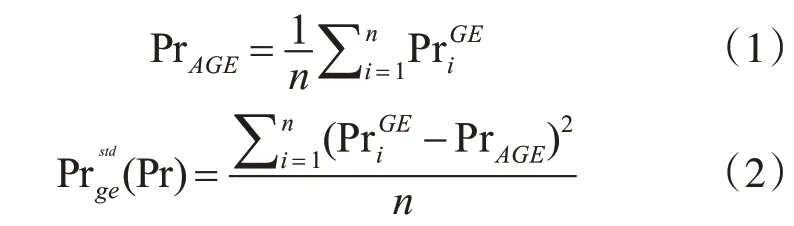
根據式(1)和式(2),文中定義了函數V(Pr)表示蛋白質Pr 的基因表達情況的變化:

一般而言,0 ≤V(Pr)≤1。緊接著,我們利用經典的3-sigma 準則[9]來確定活性閾值ε ,其計算公式為

對于任意給定的一個時間片,若有PrAGE(Pr1,Pr2,…,Prk)>ε(ε 為活性閾值),則認為這k 個蛋白質具有相同的活性,用它們來構建同一個蛋白質子網。對于生物體內的所有蛋白質而言,利用蛋白質活性計算可以統計得到具有不同活性周期的蛋白質集合S_Pr={T1,T2,…,Tk}。最后我們根據S_Pr 中元素的個數來決定劃分出多少個蛋白質子網。
2.1.2 構建子網
計算得到所有蛋白質的不同活性之后,可以構建出不同的蛋白質子網。下面僅以其中的任意一個子網為例來闡述其構建過程。假設{Pr1,Pr2,…,Prl}表示具有相同活性的l 個蛋白質,現在對它們構建子網。要準確地構建出蛋白質子網的關鍵在于發現這l 個蛋白質的相互作用關系。文中通過定義連接強度這一個概念來對蛋白質之間是否具有相互作用來進行評價。具體而言,文中從兩個方面考慮蛋白質與蛋白質之間的連接強度:1)公共鄰居數量。如果兩個蛋白質之間存在越多的公共鄰居,這表明它們之間具有更為緊密的相互作用關系;2)邊和度的比例。如果某兩個蛋白質之間的鄰接邊越多,并且度越小。則它們之間具有更緊密的相互作用關系。綜上所述,可以采用下面的公式計算連接強度:
定義3 連接強度

其中,CS(Pri,Prj)表示任意兩個蛋白質Pri和Prj之間的連接強度;表示Pri和Prj之間存在的鄰接邊個數;nn(Pri)表示Pri的鄰居節點;di表示Pri的度;式(5)中的是一個Sigmoid 函數[12],使用該函數的好處在于:它可以將影響蛋白質之間相互作用強弱的諸多因素(鄰接邊個數、節點的度等)最終轉為一個概率值,能夠較好地刻畫不同蛋白質之間的連接關系。
2.2 動態蛋白質網絡構建算法描述
相對于靜態蛋白質網絡而言,動態蛋白質網絡的拓撲結構會隨著蛋白質合成或降解、生物環境等因素的變化而動態變化。對蛋白質網絡準確建模的關鍵是采用合適的模型來表示這個動態變化因素。考慮到網絡中大多數蛋白質的基因表達具有時間周期特性,并不是完全隨機的,因此文中從時間維度出發對動態蛋白質網絡進行建模,首先基于時間片的概念對整個網絡進行劃分,定義出每個時間片內的網絡連通性,然后基于進化圖理論將多個時間片內的子網構建成動態蛋白質網絡模型,具體細節見算法1。
算法1 動態蛋白質網絡構建算法(DPPN-CC)
輸入:基本表達值數據,PPI數據,閾值th
輸出:動態蛋白質網絡模型Θ=(G,GS,TSi)
步驟1. 根據所有蛋白質的基因表達值數據,采用式(1~3)計算生物體內所有蛋白質的活性周期Ac(Pr),并采用列表對其結果進行存儲,可得:
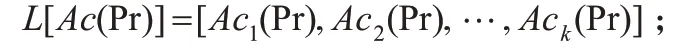
步驟2.根據蛋白質的活性周期來構造子網:
For Aci(Pr),i=1,2,…,k in L[Ac(Pr)]:
在Aci(Pr)中計算CS(Pri,Prj);
If CS(Pri,Prj)≥th,則在Pri和Prj之間增加邊<Pri,Prj>,并記錄<Pri,Prj>所在的時間片TSi;
步驟3.如果L[Ac(Pr)]不為空,則重復執行步驟2;否則算法終止。
3 實驗結果與分析
下面以蛋白質復合物的識別作為測試應用,在經 典 的DIP 數 據 集[13]和CYC2008 數 據 集[14]上 對DPNC-CC 算法的性能進行了評價。其中,算法的實現采用Python語言;評價指標采用:查全率、查準率和F-measure。仿真實驗環境為:64 位的Windows10操作系統+anaconda平臺。
3.1 參數敏感性分析
從算法1中的描述可知,參數th 的取值大小直接影響著構建出來的動態蛋白質網絡的拓撲結構,因此為了衡量DPNC-CC 算法的可靠性,有必要對該算法的參數敏感性做出詳細的分析。我們以CYC2008數據集為測試數據集,在構建出來的網絡上依次運行MPC-TPW[15]和DPC-NADPIN[16]等兩種復合物識別算法,采用F-measure 指標來評價DPNC-CC 算法的性能。實驗結果見圖1。仔細觀察圖1 可以發現,隨著th 取值的增大,兩種識別算法的識別性能也在逐步上升,但當th 取值超過0.7之后,兩種識別算法的F-measure 值基本不再波動,這表明通過DPNC-CC 算法構建的動態蛋白質網絡不具有參數敏感性,可以推廣到蛋白組學的眾多應用問題中去。
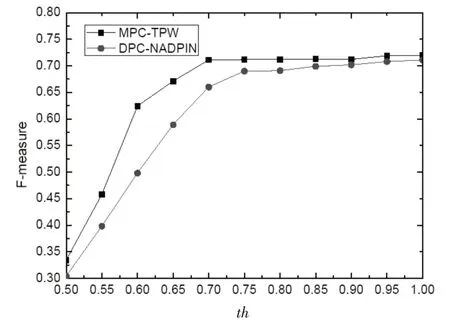
圖1 DPNC-CC算法的參數敏感性分析
3.2 DPNC-CC算法與其他算法的比較
以DIP 數據集為實驗對象,下面以DPNC-CC算法與文獻[4~6]中的算法構建得到的動態蛋白質網絡上運行MPC-TPW 算法進行復合物識別,來測試不同的網絡構建算法的有效性。文中采用K 折交叉驗證(K=10)來進行仿真實驗,取10 次實驗結果的均值作為各個算法在DIP 數據集的復合物識別結果,見表1。
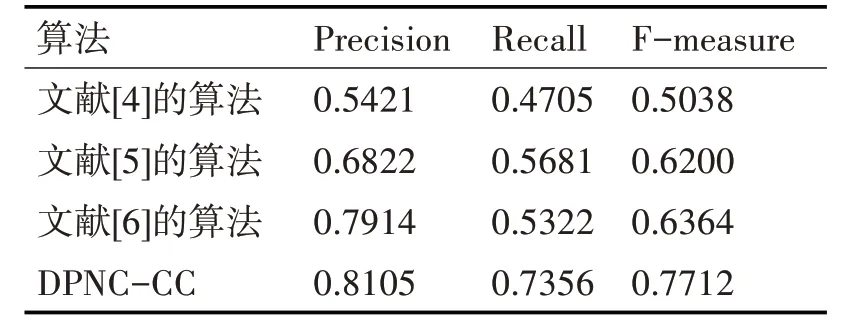
表1 MPC-TPW算法在各個網絡上的性能比較
從表1 可以看到,MPC-TPW 算法在本文構建的動態蛋白質網絡(DPNC-CC)上進行復合物識別的查全率和查準率都要優于另外的四種算法。F-measure 值要比文獻[4]的算法、文獻[5]的算法和文獻[6]的算法分別高約53%、24%和21%。這主要是因為:本文算法在構建動態蛋白質網絡時,不僅從物理上考慮了蛋白質與蛋白質之間的距離、拓撲結構等信息對網絡構建的影響,還利用了蛋白質的活性周期這一生物信息來衡量蛋白質之間的相互作用關系,較為全面地規避了蛋白質網絡中可能存在的虛假信息,從而能夠更好地識別蛋白質復合物。這也從側面印證了DPNC-CC算法構建的動態蛋白質網絡更優。
3.3 魯棒性分析
下面進一步對DPNC-CC 算法在包含噪聲(假陽性和假陰性)的蛋白質相互數據集上的性能表現進行實驗分析。首先,我們通過在已經構建好的蛋白質網絡上隨機增加一定比例的邊數來模擬數據的假陽性。邊數每次增加20%,增加的尺度從20%上升到100%,可以得到五組包含假陽性的蛋白質相互作用數據,然后采用DPNC-CC 算法對這五組數據進行復合物的識別,識別結果的查準率和查全率如圖2 所示。從圖2 可以明顯觀察到,數據假陽性的增加,只會輕微降低DPNC-CC算法的查準率,對于DPNC-CC算法的查全率基本沒有影響。

圖2 數據包含假陽性時的DPNC-CC算法性能
最后,我們再次在已經構建好的蛋白質網絡上隨機刪除一定比例的邊數來模擬數據的假陰性。刪除的邊數每次增加20%,增加的尺度從20%上升到100%,可以得到五組包含假陰性的蛋白質相互作用數據,然后采用DPNC-CC 算法對這五組數據進行復合物的識別,識別結果的查準率和查全率如圖3 所示。從圖3 可以明顯觀察到,隨著數據假陰性的增加,DPNC-CC 算法在前期的查全率和查準率基本保持不變,但當刪除的邊的比例超過45%之后,DPNC-CC 算法的識別質量則呈現著明顯下降的趨勢,這主要是由于隨著邊的刪除將會使得蛋白質相互作用數據中大量真實存在的相互作用被刪除,從而導致算法的識別結果大大地降低。總的來看,本文算法在包含噪聲的蛋白質相互作用數據集中的表現是可信的,算法能夠對數據的動態變化做出正確響應,具有較好的魯棒性。
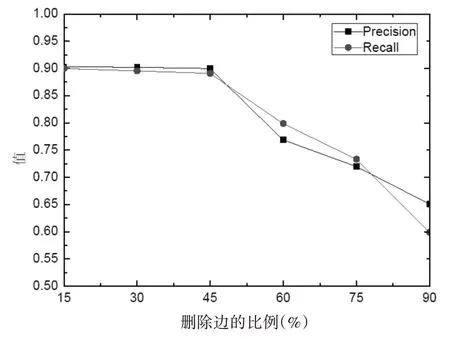
圖3 數據包含假陰性時的DPNC-CC算法性能
4 結語
蛋白質網絡的構建是蛋白組學中眾多問題研究的基礎,文中針對現有構建算法存在的不足,提出了一種基于連接強度的動態蛋白質網絡構建算法,并通過仿真實驗驗證了該方法在蛋白質復合物識別上的有效性。下一步,我們將在本文的基礎上進一步對動態蛋白質網絡中的復合物挖掘問題展開研究,力爭為生物學家或醫學家的工作提供更多的技術支撐。
