基于CNN-GRU模型的道岔故障診斷算法研究
2020-07-30 09:34:36楊菊花于苡健陳光武司涌波邢東峰
鐵道學報 2020年7期
楊菊花,于苡健,陳光武,司涌波,邢東峰
(1. 蘭州交通大學 交通運輸學院,甘肅 蘭州 730070; 2. 蘭州交通大學 自動控制研究所, 甘肅 蘭州 730070;3. 甘肅省高原交通信息工程及控制重點實驗室, 甘肅 蘭州 730070)
隨著中國鐵路的快速發展,對鐵路信號設備的運營維護也提出了更高要求。大數據分析、機器學習和人工智能技術也將逐漸應用在鐵路信號系統中。道岔是鐵路信號系統中的基礎設備之一,通過轉轍機完成列車不同進路之間的轉換,是保障列車安全運行的重要節點。在鐵路信號設備中,道岔是出現故障較高的設備,根據鐵路用戶的統計,信號設備發生的故障中,道岔故障約占信號故障總數的39%。基于狀態的維護(Condition Based Maintenance,CBM)在機械故障診斷領域應用廣泛[1-3]。本文將在道岔故障診斷中應用CBM技術,通過信號集中監測系統掌握道岔實時狀態,應用人工智能技術,實現道岔故障類型定位,以改變現有的鐵路現場維護方式,提高維護人員故障處理效率。
目前,國內外學者針對道岔故障進行了許多研究,在應用方法上也是各具特色。文獻[4]通過人工對S700K轉轍機的動作電流曲線進行故障特征提取,建立故障特征矩陣,最后作為BP神經網絡的輸入,進行故障識別。文獻[5]通過對ZD6轉轍機的電流曲線進行特征提取,最后使用BP神經網絡實現道岔的故障診斷。文獻[6]通過信號集中監測系統中記錄的故障文本信息,進行特征提取,建立故障文本數據庫。文獻[7]通過增加道岔設備的中間故障狀態,將道岔狀態細分,在功率曲線的時域和值域提取故障特征,建立隱馬爾科夫模型實現道岔故障診斷。另外還有應用Bayesian Network、SVM、灰關聯和專家系統等方法進行道岔故障診斷的研究[8-13]。
以上研究主要是針對電流曲線或功率曲線進行特征提取。然而,道岔動作電流曲線可以反映道岔轉換時的電氣特性、時間特性和機械特性,可以發現道岔動作過程的不良現象;道岔的動作功率曲線更能反映道岔在動作過程的阻力情況和機械性能。所以,本文提出將道岔的動作電流曲線和功率曲線結合起來,進行特征提取。先通過哈爾小波變換,建立特征矩陣,再通過卷積神經網絡(CNN)自動進行特征提取,最后應用GRU對道岔進行故障診斷。
1 道岔采集原理和動作曲線分析
1.1 道岔采集原理
在信號集中監測系統中,交流轉轍機的監測通過道岔采集單元實現。監測內容包括電流、電壓、道岔一啟動繼電器(1DQJ)狀態、定位反位表示狀態[14]等。三相交流轉轍機的采集原理見圖1。
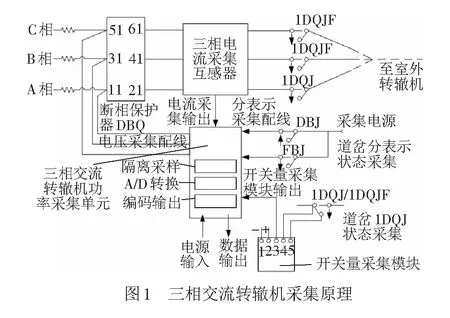
采集單元放置在組合架附近,通常一個采集單元采集一組轉轍機的三相電流、三相電壓、1DQJ和定位反位表示開關量。而只有在道岔轉動時,1DQJ吸起,采集點與外線接通,進行數據采集。
電流采集點位于斷相保護器(DBQ)輸出與1DQJ之間;電壓采集點在DBQ前級端子11、31、51點上;1DQJ采集點接入1DQJ繼電器的空接點上;道岔定位和反位表示的采集點分別為定表繼電器(DBJ)和反表繼電器(FBJ)上的空接點。
1DQJ動作時,產生開關量的變化,同時啟動互感器采集電機動作時的電流和電壓值,每40 ms計算一次有功功率,并記錄下來。同時電流和電壓的實時值、1DQJ、DBJ和FBJ的狀態將通過通信總線傳輸給站機進行顯示處理。
1.2 道岔動作曲線分析
本文以S700K型轉轍機為研究對象,其道岔在轉換過程中正常動作的電流和功率曲線見圖2。
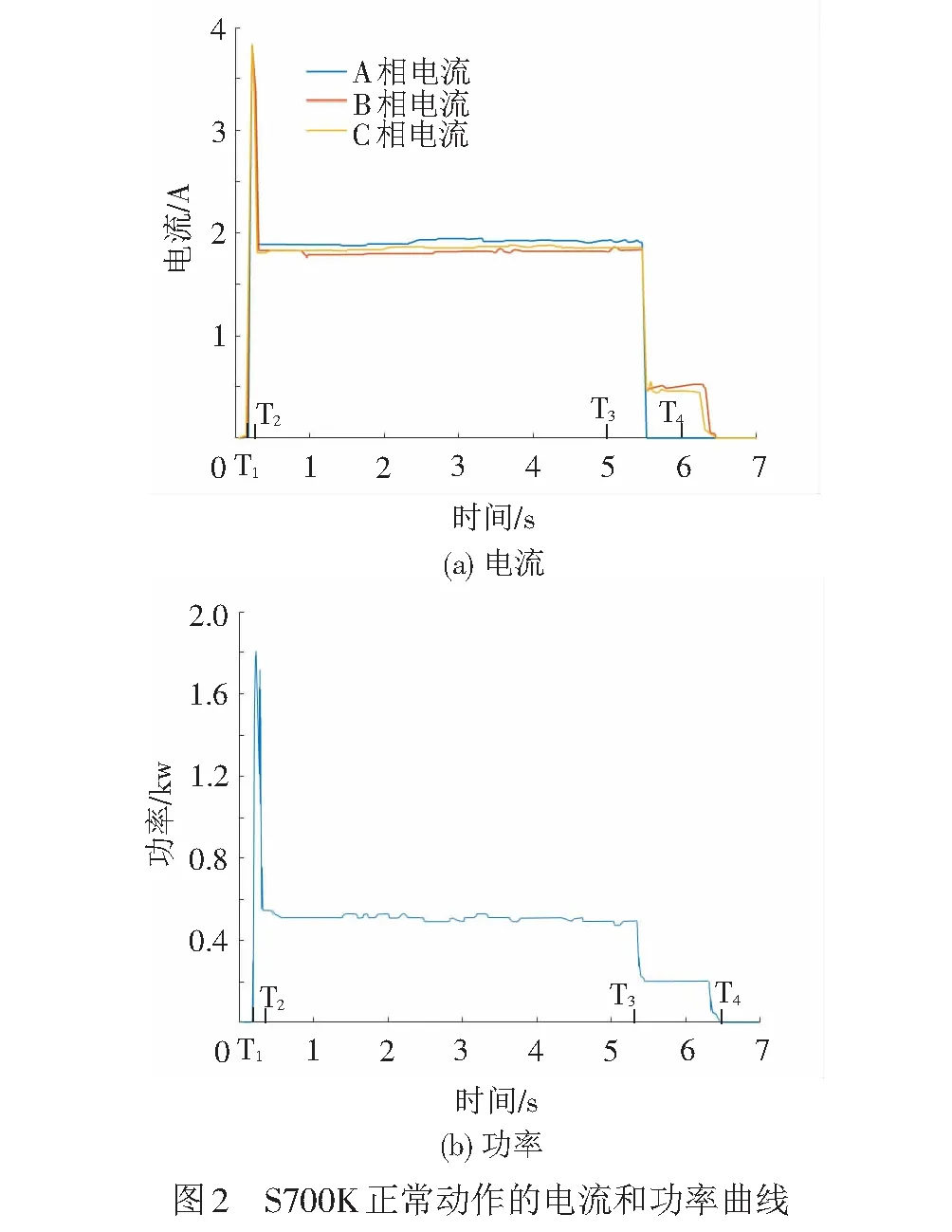
S700K交流轉轍機的動作過程主要有以下5個階段[15]。
0—T1階段:1DQJ吸起,道岔動作曲線開始記錄。
T1—T2階段:2DQJ轉極,動作電流曲線出現一個尖峰,說明道岔啟動電路接通,道岔動作開始。
T2—T3階段:此階段為道岔動作過程,正常情況下其電流曲線應平滑,動作電流大小應與參考曲線大體相同。
T3—T4階段:道岔轉換完畢,自動開閉器節點轉換,同時斷開啟動電路,表示電路接通,DBQ無電流通過使BHJ落下,但是1DQJ具有緩放功能,電路切斷后會進入緩放狀態,在緩放時,啟動電路仍有兩相電流存在。
T4時間點:1DQJ落下,停止記錄道岔動作曲線。
1.3 道岔常見故障現象及原因
S700K型轉轍機單動道岔常見故障見表1。

表1 S700K道岔常見故障現象和原因
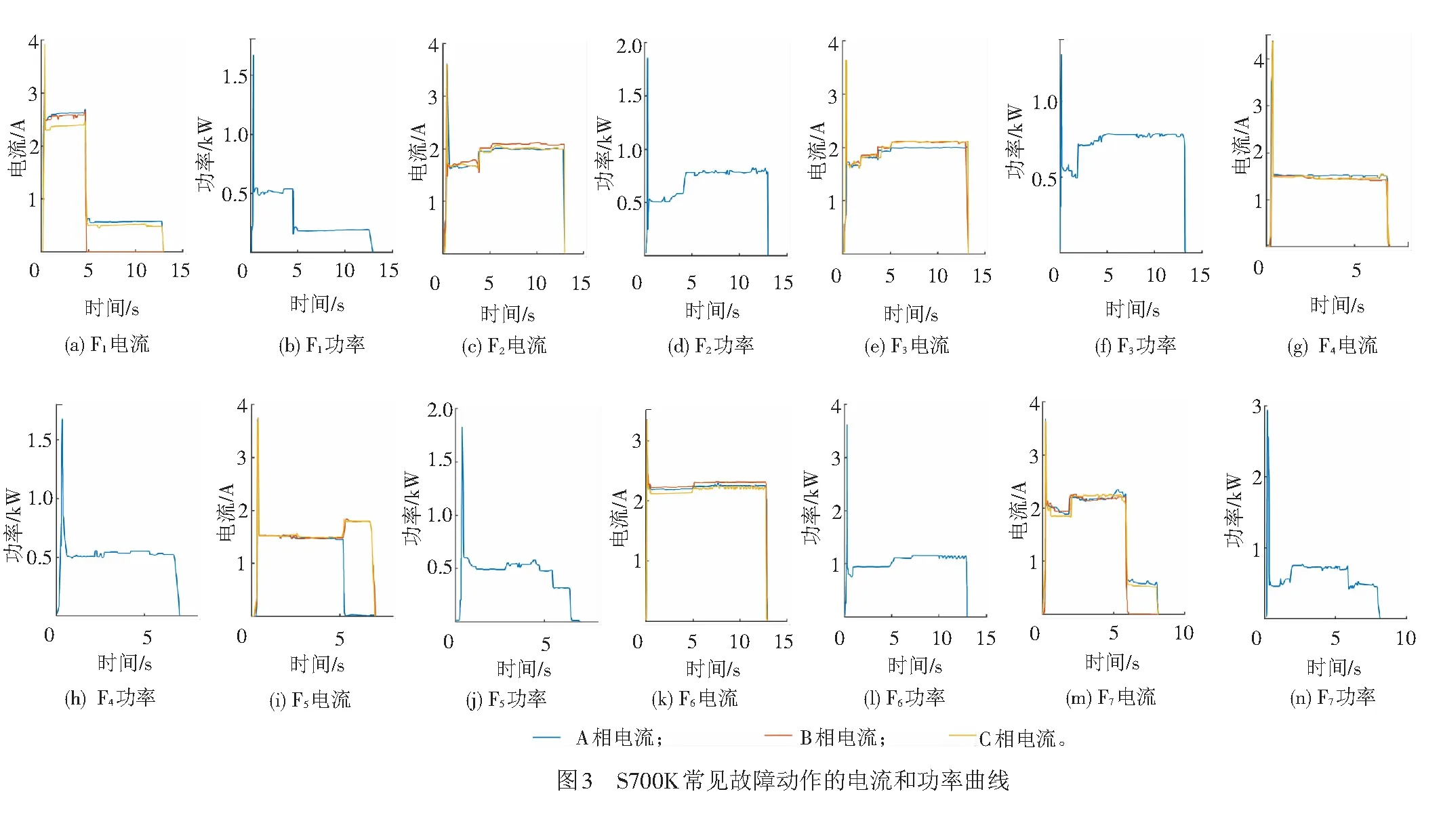
常見故障的三相電流和功率曲線見圖3。
根據鐵路運營用戶的統計,道岔出現的故障中,卡缺口和道岔夾異物約占40%,是道岔故障中出現次數最多的;道岔轉換阻力大和鎖鉤缺油兩種故障大約占20%;而其他故障則出現頻率較低。
2 基于GRU的道岔故障診斷算法
2.1 基于GRU的道岔故障診斷算法結構
道岔故障診斷的算法結構見圖4。
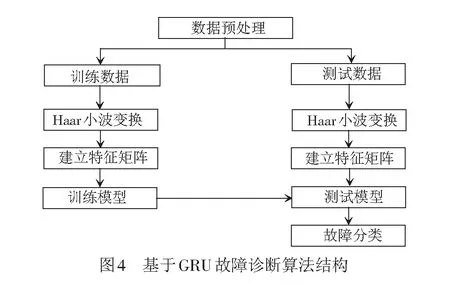
首先數據預處理,從信號集中監測系統中得到道岔的電流和功率數據,分為訓練數據和測試數據,分別經過哈爾小波變換,將變換后的數據與原始數據結合,建立特征矩陣,作為CNN-GRU模型的輸入。然后在模型中,經過CNN卷積層的自動提取特征,把高維數據矩陣自動降維,得到低維矩陣,作為GRU網絡層的輸入,得到訓練后的模型,再用測試數據測試模型準確率,實現道岔故障診斷。
2.2 電流和功率數據哈爾小波變換
對數據進行特征提取前,先對電流和功率數據進行哈爾小波變換。對道岔故障診斷的特征提取,常見的是在動作電流或功率的各個動作階段進行特征提取,這樣會忽略在動作曲線上各數據點之間的信息,而哈爾小波變換可以提取到相鄰數據點間的信息。
哈爾基函數是由一組常值分段函數組成的函數集,常用于圖像壓縮,可以將圖像以少于原始圖像像素點進行保存,而不失去圖像原始信息[16-17]。在經過哈爾小波變換后,得到相鄰數據點之間的信息,作為道岔故障診斷的特征參數。
哈爾小波的小波函數表示為
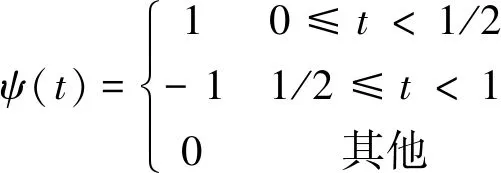
( 1 )
對應的尺度函數為
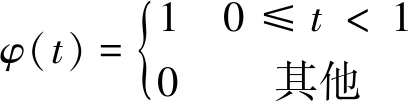
( 2 )
小波變換的基本思想是用一組小波函數或者基函數表示一個函數或者信號。將三相電流和功率曲線中的數據點抽取成一維矩陣,分別計算各自的哈爾小波變換系數
( 3 )
( 4 )
( 5 )
( 6 )
式中:IAi、IBi、ICi為三相電流曲線上數據點;Pi為功率曲線上的數據點。
哈爾小波變換系數求取如下:
(1) 求平均值,計算相鄰數據對的平均值,得到短的矩陣,新的矩陣長度是原來的1/2。
(2) 求差值,經過求平均值,矩陣已經丟失部分信息,為還原原始矩陣,需要存儲矩陣的細節信息,以方便找回丟失信息。所以,用數據對的第一個數據減去數據對的平均值。
將這些平均值和差值存儲下來,得到變換后的系數,組成新的矩陣,作為道岔故障診斷的特征參數。變換后各曲線哈爾小波變換系數矩陣為
( 7 )
( 8 )
( 9 )
(10)
式中:AIAi、AIBi、AICi和APi分別為三相電流和功率曲線上數據點經過哈爾小波變換后的平均值;而DIAi、DIBi、DICi和DPi則為哈爾小波變換后的差值。
最后組成特征候選矩陣
(11)
2.3 電流和功率數據特征提取
在經過哈爾小波變換后,得到更多的曲線信息,而這些信息中還會包含多余的細節,需要對矩陣做進一步的處理,從而得到低維矩陣而不失曲線原本信息。
多數道岔故障研究的特征提取,經過各種變換后,會由人工進行,而隨著人工智能技術的發展,可以采用神經網絡方法自動完成特征提取工作。
卷積神經網絡是一種更適合圖像和語音識別的神經網絡結構,可以出色地完成特征提取工作,而且訓練簡單[18]。
卷積神經網絡中激活函數往往選擇Relu函數,它的定義為
f(x)=max(0,x)
(12)
Relu函數相比sigmoid函數,計算速度快,意味著在訓練模型時,迭代速度快,可以減輕梯度消失的問題。對比sigmoid函數,在使用反向傳播算法進行神經元之間的梯度計算時,Relu函數的導數為1,不會出現梯度減小的問題。Relu函數會將小于0的映射為0,減少神經元之間的依賴,使網絡變稀疏,避免過擬合。所以在模型中使用Relu函數可以訓練更深,速度更快,并且能夠得到更稀疏的網絡模型。
若干個卷積層和池化層是一個卷積神經網絡的主要部分。在卷積層,卷積運算見圖5。
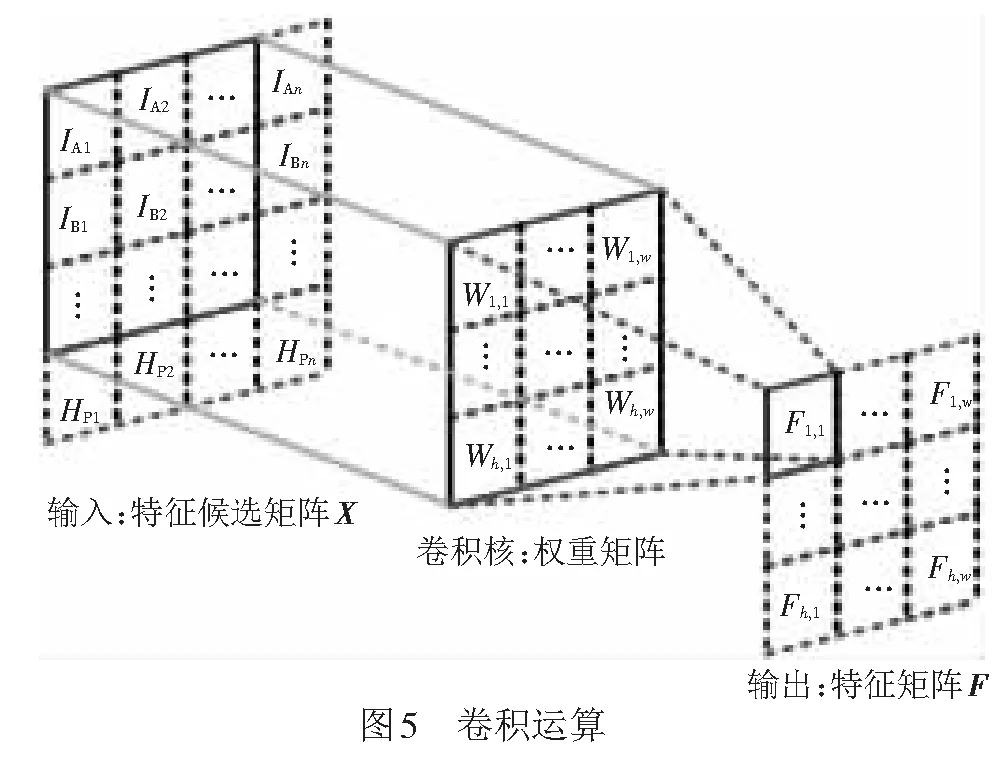
特征候選矩陣X作為輸入,卷積核對輸入從左到右掃描,和輸入的對應元素相乘后累加,得到輸出的特征矩陣第一個元素。設置步長可以控制每次滑動格數,掃描結束得到特征矩陣Fh,w。圖5中Wh,w的h和w分別為卷積核權重矩陣的高度和寬度,可以在搭建模型時提前設置;輸出特征矩陣的高度和寬度分別為
wF=(wX-wW+2wP)/wS+1
(13)
hF=(hX-hW+2hP)/hS+1
(14)
式中:wF為卷積后特征矩陣F的寬度;wX為特征候選矩陣X的寬度;wW為filter的寬度;wP為在原始矩陣周圍補零的列數;wS為窗口橫向滑動時的步幅;hF為卷積后特征矩陣F的高度;hX為特征候選矩陣的高度。hW為filter的高度;hP為在原始矩陣周圍補零的行數;hS為窗口縱向滑動時的步幅。式(13)和式(14)計算原理相同。
池化層在卷積層之后,其目的是繼續降低特征矩陣的維度,提高運算速度。池化運算選取MaxPooling,池化窗口對特征矩陣Fh,w從左到右掃描,設置步長控制滑動格數,同時選取池化窗口中最大值作為該位置輸出,最后得到維數更小的特征矩陣Fh,w。
2.4 GRU算法
GRU是長短時記憶網絡(LSTM)的一種變體。相比LSTM有3個門,GRU只有2個門,而且沒有細胞狀態,簡化了LSTM結構[19]。所以GRU有更少的參數,相對容易訓練且不容易出現過擬合問題[20-21]。GRU的網絡結構見圖6。圖6中,“+”為向量加運算;“σ”為sigmoid函數運算;“⊙”為哈達馬乘積,矩陣對應元素相乘;“tanh”為“tanh”函數運算。
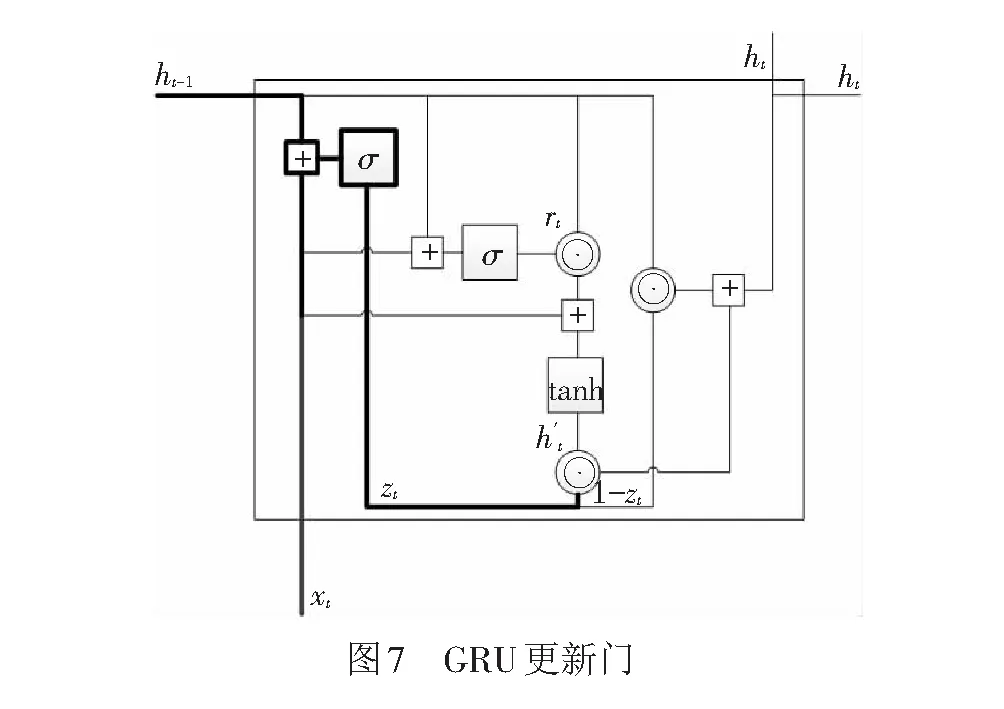
在GRU網絡結構中,更新門見圖7,輸出為
zj=σ([Wzx]j+[Uzh(t-1)]j)
(15)
輸入xt和上一時刻隱藏層h(t-1)分別與權重矩陣Wz、Uz相乘,再將結果輸入sigmoid函數中,將結果控制在0~1之間。更新門主要是決定上一層隱藏狀態下有多少信息傳遞給當前隱藏層ht。zj接近0,說明第j個信息被遺忘;接近1,說明信息繼續保留。
GRU的重置門和更新門的運算操作類似,區別在于權重矩陣不同。重置門的運算結構見圖8,輸出為
rj=σ([Wrx]j+[Urh(t-1)]j)
(16)
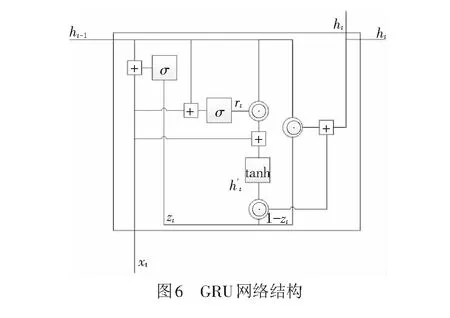
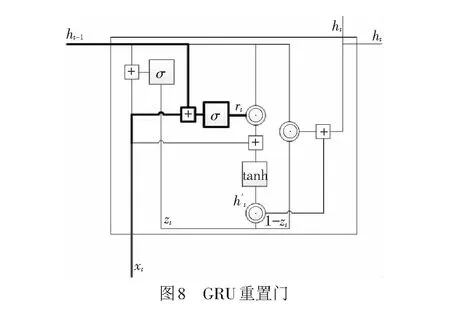
它決定上一時刻隱藏狀態中的信息有多少是需要被遺忘的。更新門和重置門的作用對象是不同的,更新門決定上一時刻隱藏狀態和記憶內容,而重置門決定當前的記憶內容。
確定當前記憶內容的結構見圖9,輸出為
(17)
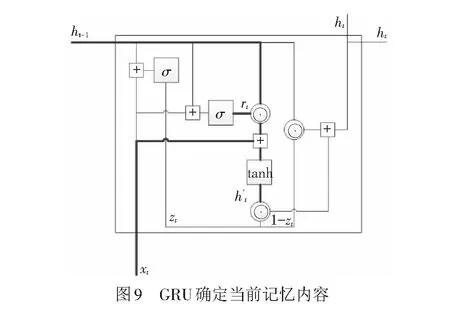
重置門rt和ht-1進行哈達馬乘積,決定在當前記憶內容中要遺忘部分上一時刻隱藏狀態的內容,再將部分信息經過tanh激活函數,把結果控制在-1到1之間。
上一時刻的重要信息和當前時刻輸入的重要信息組成GRU當前時刻的記憶內容,這是它記錄到的所有重要信息。
最后確定當前時刻隱藏層保留的信息,運算結構見圖10,輸出為
(18)
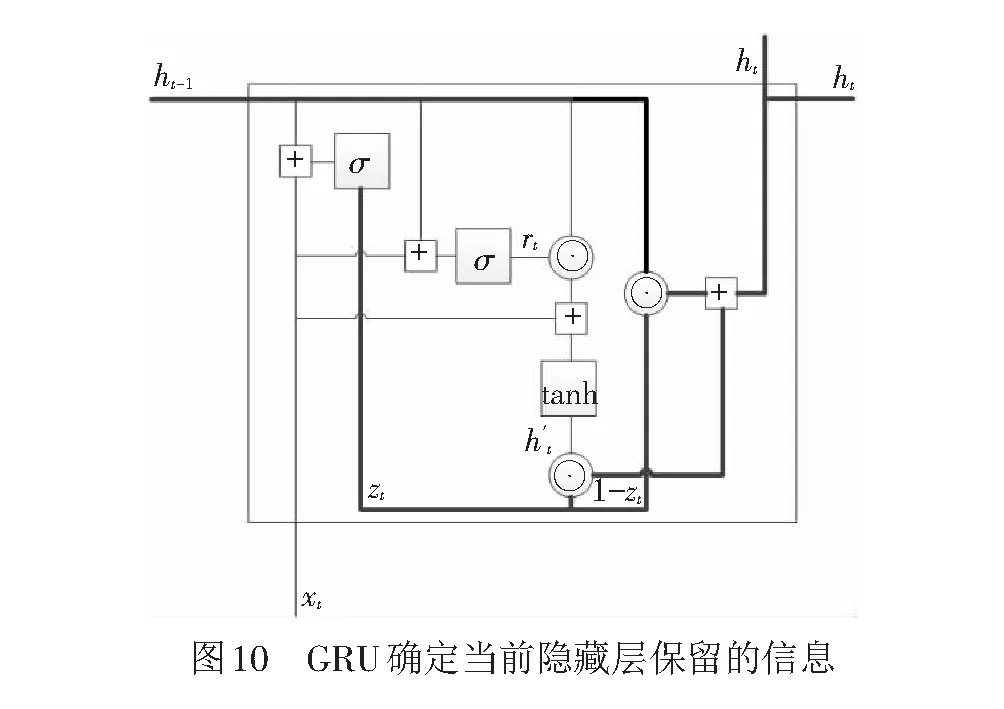
式(18)中的第一項決定了上一時刻部分信息需要保留在當前時刻隱藏單元ht,第二項(1-zj)決定需要遺忘的信息。當前記憶內容是當前時刻保留的所有信息,而當前時刻需要的信息在隱藏層中。
特征矩陣Fh,w作為GRU的輸入,經過全連接層Dense,激活函數采用softmax,輸出分類概率,模型經過優化和訓練后,實現道岔故障診斷。
3 實驗仿真分析
3.1 建立CNN-GRU模型
CNN-GRU模型使用python編譯平臺,在Keras框架下搭建,模型中包括二維卷積層,二維池化層,GRU層和全連接層,整體模型見圖11。
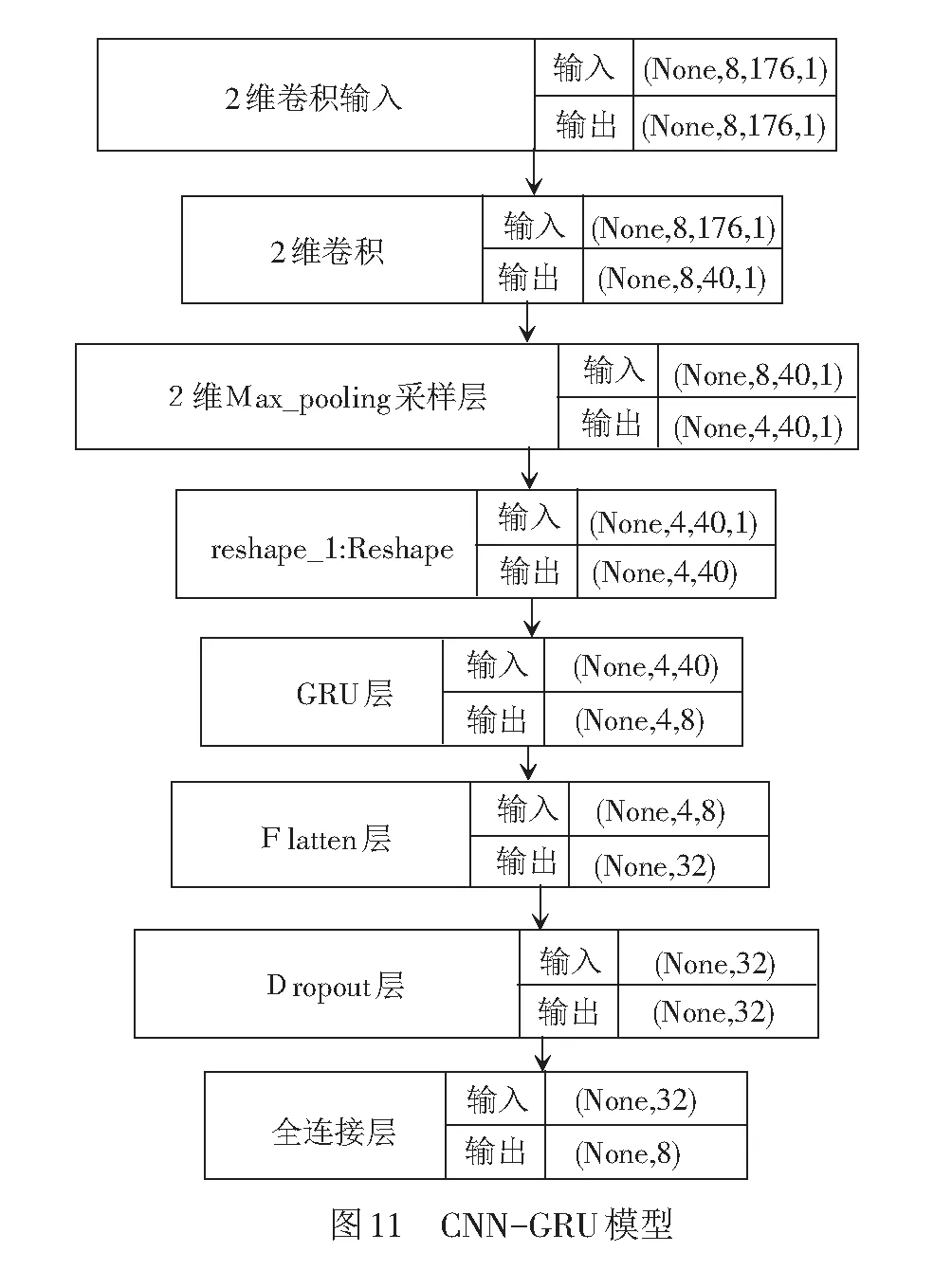
輸入矩陣尺寸為8×176,176是樣本曲線數據點長度,每40 ms采集一組數據,并截取7 s的曲線。如正常動作時間在6.5 s左右,在曲線數據點后補零;如果故障動作時間超過7 s,則取曲線前7 s數據。最終每個曲線采集175個數據點,三相電流和功率經過哈爾小波變換后,樣本長度變成176,將原始數據第一列加上動作時間,組成8×176的特征候選矩陣。
最后輸出8個節點,是正常情況和7種故障所對應的概率,判定概率最高值所對應的故障類別為故障診斷結果。
3.2 結果分析
以S700K型道岔為研究對象,正常動作情況和每種故障各取20組樣本,隨機排序后,取其中120組數據做訓練,其余40組樣本做測試,驗證道岔診斷模型準確率。測試在迭代75次和100次時,不同維數的特征矩陣F,仿真結果對比見圖12。
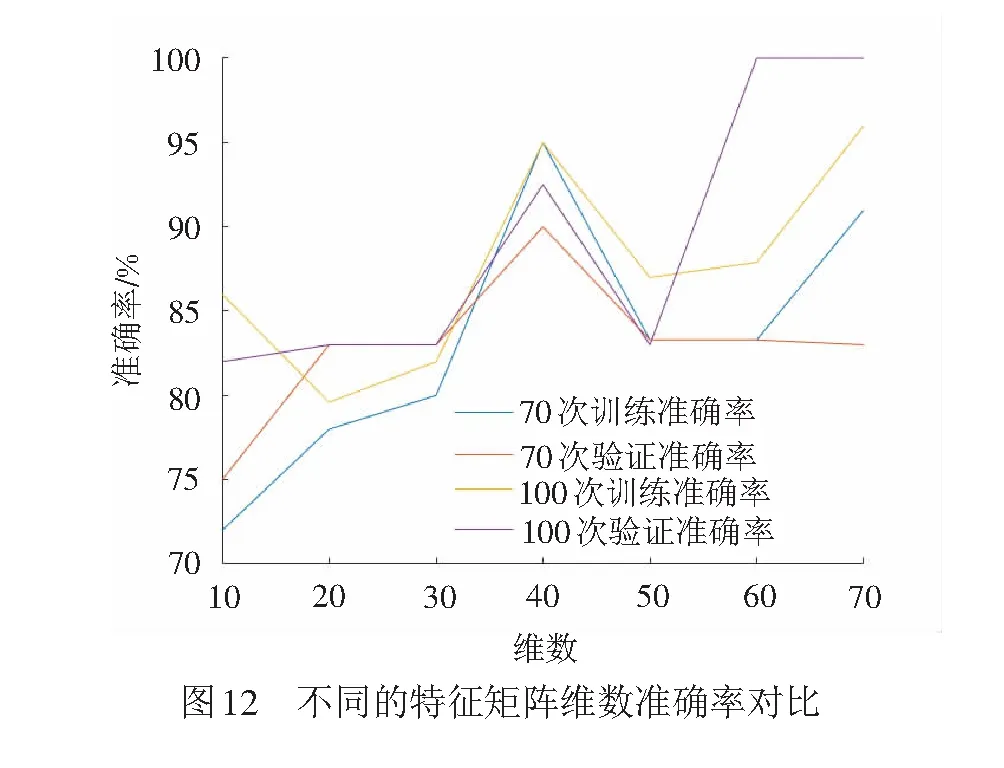
由圖12可以發現,在特征矩陣F維數為40時,迭代70次和100次,有較好的訓練準確率和驗證準確率。所以模型選取特征矩陣F維數為40。
確定特征矩陣維數后,改變迭代次數,仿真結果準確率見圖13(a),損失函數值見圖13(b),訓練時間見圖13(c)。
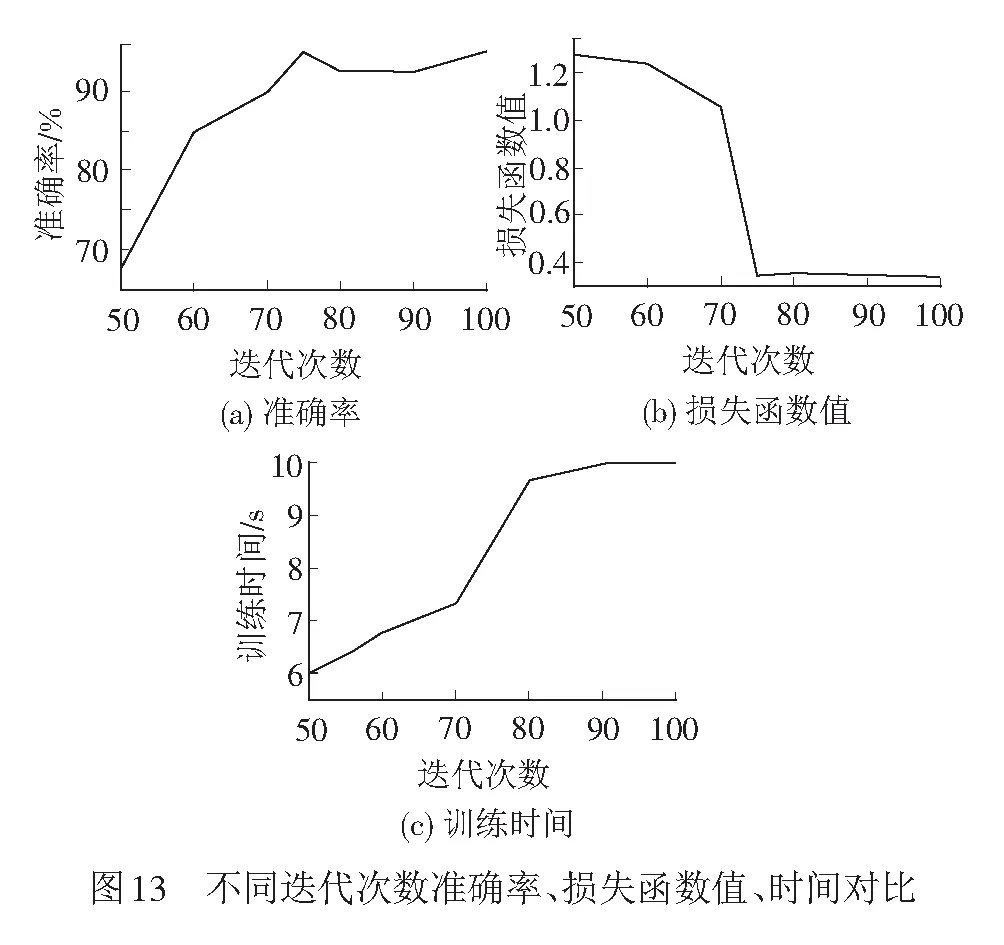
由仿真結果可以發現,綜合模型準確率、損失函數值和時間,迭代75次時,模型有滿意的結果,準確率為95%,損失函數值為0.344,訓練時間為8.49 s,而超過75次時,模型準確率和損失函數值變化幅度小,所以選取迭代75次可以滿足現場維護要求。
最終確定模型特征矩陣選取40維,迭代次數選75次。最終測試結果見圖14。
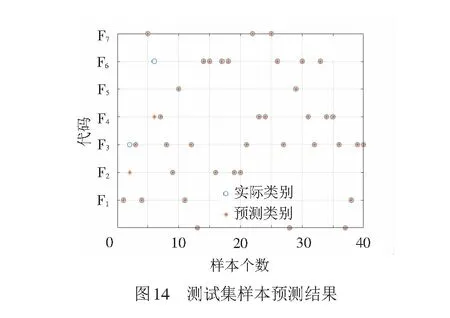
測試預測結果中:一個樣本故障3(道岔夾異物)被識別為故障2(卡缺口),由故障曲線可以發現,故障2和故障3曲線整體相似,是導致模型識別錯誤的主要原因;另一個故障6(鎖鉤缺油)被識別為故障4(室外表示電路開路),雖然兩種故障曲線不相似,但是經過哈爾小波變換后,曲線上數據點之間的平均值和差值整體相近,導致模型出現錯誤判斷。
診斷準確率和訓練時間分別見表2、表3。

表2 診斷準確率

表3 訓練時間
由表2和表3可知,經過與PCA-HMM和 PCA-GA-SVM方法對比,本文方法的準確率優于PCA-HMM方法的準確率,在訓練時間上優于PCA-GA-SVM方法。而且CNN-GRU模型在經過調試后,可以保存為.h5文件,再次調用后,可以直接使用,不需要再次訓練優化,如果無法滿足要求,可以繼續訓練優化,重復使用率高于其他方法。
4 結束語
通過提取信號集中監測系統中的道岔電流和功率故障曲線,經過哈爾小波變換后,與原始數據組成高維的特征候選矩陣,作為CNN的輸入,經過卷積網絡對特征候選矩陣的自動提取,得到低維特征矩陣,再經過GRU網絡的判斷,輸出每種故障狀態的概率,實現故障診斷。通過仿真實驗及對比其他方法,CNN-GRU道岔故障診斷模型準確率達95%,在訓練時間上也優于其他方法,能夠滿足鐵路現場維護需求。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
