基于哈肯模型的我國大數據產業演化機制研究
2020-02-28 10:37:52李橋興胡雨晴
工業技術經濟 2020年3期
李橋興 胡雨晴
1 (貴州大學管理學院, 貴陽 550025)
2 (貴州大學喀斯特地區發展戰略研究中心, 貴陽 550025)
引 言
與IT 領域緊密關聯的大數據將帶來一場新的重大技術變革[1]。 不論是信息科技領域, 還是國家治理領域, 大數據研究與應用的相關產業發展已成為公眾關注的焦點[2,3], 也因此再一次掀起新的產業革命浪潮。
產業演化能夠清晰把握某單一產業的動態發展規律。 產業演化研究多集中于演化過程和演化機制兩方面。 演化過程研究主要依據產業生命周期理論, 研究產業動態發展階段及其特征[4], 其定量分析一般采用G-K 模型[5]、 A-U 模型[6]、 NW 模型[7]、 基于主體的仿真模型[8]等多種產業動態模型及計量經濟模型[9], 如孫曉華等基于ABM框架動態模擬電動汽車業的演化過程[10]。 在演化機制研究方面, 創新通常被認為是產業演化的內在動力, 如Schumpeter 最早闡述創新在產業演變中的核心作用[11]。 除此之外, 需求異質性、 政策、學習等因素也能對產業演化產生影響[12-14]。 自組織理論的哈肯模型常用于產業演化機制研究, 從系統內部視角分析演化過程。 如朱永達等、 郭莉等基于哈肯模型研究區域產業系統演化, 并識別出相應的序參量[15,16]。 鑒于大數據產業研究還處在不斷完善其基礎理論階段, 目前研究多集中于發展特征和產業結構等方向, 并主要采用定性分析方法。 如朝樂門等指出我國大數據產業正處于起步階段[17]; Shari S C 等提出大數據產業系統包含數據、 應用程序、 技術和開放API 平臺4 個方面[18], 以及部分學者探討了大數據產業的服務模式[19]等, 但還未有學者涉及大數據產業系統的演化機制研究。 因此, 定量分析我國大數據產業系統的演化機制, 對預判和提升我國大數據產業發展具有重要的實踐意義。 本文基于自組織理論的哈肯模型構建我國大數據產業系統的演化方程,并以已上市的17 家大數據相關企業為樣本, 選取2017~2018 年的數據進行實證研究。 通過深入分析大數據產業系統的演化機制, 以期為探究我國大數據產業系統的發展規律提供理論參考。
1 大數據產業演化的自組織特征
大數據產業作為一個新興產業, 其大多數企業是基于大數據思維模式并通過傳統技術的升級改造而完成躍升, 表現為系統內各種因素的競爭與協同作用驅動該產業的演化過程。 大數據產業系統是一個復雜的動態演化系統, 其內部涉及多個子部門且各發展階段和水平有所差異, 總體表現為非均勻、 不單一、 非平衡態的趨勢, 即遠離平衡態。 其演化雖然受到外部多方面因素的共同影響, 但其演化的主要方向在很大程度上還是取決于系統內部。 自組織理論從內部視角來探討系統演化機制, 其思路為: 在外部控制參量達到某個閾值時, 伴隨著隨機漲落因素, 一個開放的、非線性的、 遠離平衡態的系統可以突變形成更有序、 更高級的新結構[20]。 基于這一核心思想以及其他相關文獻, 本文總結得出系統自組織演化需滿足開放性、 遠離平衡態和非線性等基本條件,還包括自我適應性、 涌現性、 突變性、 漲落等特征[21-23]。 由于目前尚未有學者采用自組織理論研究分析大數據產業的系統演化, 并且大數據產業系統與其他產業系統一樣均從屬于更高級的社會經濟系統, 因此本文根據系統自組織理論盡可能全面地分析大數據產業系統的自組織演化特征。限于篇幅, 本文將從以下兩方面展開探討:
(1) 開放性與自我適應性。 開放性是大數據產業系統演化的基本特性。 開放性意味著大數據產業系統并非完全封閉, 系統內部和外部能夠隨時進行交互作用。 系統內部會受到經濟、 文化、政治等來自系統外部因素的影響, 并且外部環境可以為系統提供物質、 信息、 人才、 政策等生存要素; 另外, 系統內部通過對來自系統外部的信息、 物質等要素的整合, 可以向外輸出適應外部環境的產品、 服務和技術等, 同時這些輸出又能夠反作用于外部環境, 使得外部環境發生新的變化以及這種新的變化又能夠為系統發展創造更有利的外部環境。 這兩個方面正是大數據產業系統演化的自我適應性的體現。 如在國家大數據戰略等一系列有利于大數據產業發展的政策扶持下,人才、 資金和技術等重要的生產要素正源源不斷地輸送至大數據產業系統, 并且系統內部也可以對各資源要素進行優化配置, 從而以產品的方式向社會、 政府提供更高級的技術和服務, 促使外部環境對大數據產業系統有了新的要求并輸送相應的新資源, 從而促進大數據產業系統的更進一步發展。
(2) 非線性作用與涌現性。 非線性作用是大數據產業系統演化的內在動因, 指在大數據產業系統演化過程中, 系統中各因素之間呈現非線性的相互作用, 即“非加和性”。 系統中各個部分并不是簡單相加, 而是通過復雜的競爭和協同作用,推動系統在宏觀上的演化。 這種非線性作用能夠推動系統在整體上呈現出復雜性和多樣性, 促進新功能的涌現, 即涌現性。 如在大數據產業系統中, 研發部門、 生產部門等各子部門間存在著非線性的反饋和協同機制, 當系統的狀態變量發生變化時, 這種反饋和協同機制又會發生新的非線性的正負變化, 從而導致新功能的涌現。
因此, 大數據產業系統的演化過程是從初始的混沌無序向清晰有序、 從舊式結構向新式結構不斷演變的自組織過程, 其系統內部各組成要素對系統產生差異性和不平衡性的影響。 當系統控制變量的變化將系統推過線性失穩臨界點時, 差異性和不平衡性隨之顯露, 從而區分出快變量和慢變量。 快變量的行為受慢變量支配, 慢變量主導系統演化進程并成為系統演化新狀態的序參量[20]。基于大數據產業系統自組織演化特征, 采用哈肯模型對各變量間相互作用及結構演化進行分析,可以揭示大數據產業系統的演化機制。
2 哈肯模型的構建
協同學理論的哈肯模型采用數學模型對在一定外部條件下由系統內部各因素的相互作用促使系統演化的過程進行表述[24]。 哈肯模型中將影響系統演化的因素分為快、 慢兩種變量, 其中起主導作用的慢變量往往只有1 個或幾個, 是整個復雜系統演化的關鍵因素[25]。 通過計算并消去系統的快變量, 找出系統序參量, 得到其演化方程。
大數據產業系統雖然涉及多個子部門, 但哈肯模型主要涉及兩個變量。 因此, 選取大數據產業系統的兩個狀態變量q1和q2并建立兩者的模型關系為:

其中λ1、 λ2為阻尼系數, a 和b 為兩個狀態變量的相互作用強度系數。
顯然, 由以上模型可得到系統的一個定態解為q1=q2=0。 當λ2?λ1且λ2>0 時, 滿足“絕熱近似原理”, 表明q2為迅速衰減的快變量。 因此,采用絕熱消去法, 令q′2=0, 由式(2) 可得:

將式(3) 代入式(1), 得到序參量方程,即系統的演化方程為:

從式(4) 中解出q1后, 再代入式(3) 解出q2。 由此可見, q1決定了q2, 即q2隨q1的變化而變化。 因此, q1為系統的序參量, 主導著系統的演化。
對式(4) 的相反數積分解出勢函數為:

存在兩種情況: 當λ1>0 時, 方程(4)有唯一穩定解, 即q1=0; 當λ1<0 時, 方程(4)有3 個解,即由于q11是不穩定解, 現實分析中一般不予考慮。但q12、 q13是穩定解, 表明系統可通過突變進入新的穩定態。 實際應用中可將哈肯模型離散化為:
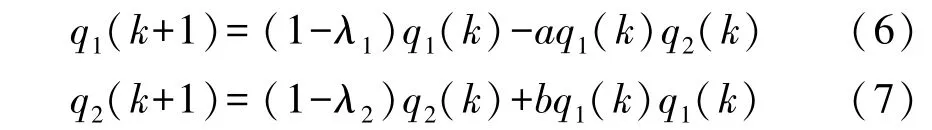
3 基于哈肯模型的大數據產業演化
3.1 變量選取
作為一個正處于發展中的新興產業, 大數據產業的演化發展受到多方面因素的影響, 但目前還未有學者關注大數據產業的演化機制研究。 鑒于運用哈肯模型在研究其他產業的演化發展中已有較成功的案例[15,16], 本文擬采用哈肯模型并選取研發投入、 勞動生產率和資本投入3 個狀態變量作為演化序參量的備選集具體分析大數據產業。
(1) 研發投入IR, 用研發費用表示。 研發投入反映了創新和技術的投入, 代表大數據產業系統中的知識和技術部門。 大數據產業中大數據是一類具有重要潛在應用價值的信息資源。 就管理視角而言, 大數據具有復雜性和高速增長性, 其潛在價值能夠被重復挖掘并對決策起重要作用,但由于其價值稀疏, 也導致挖掘難度的增加[26]。不同于傳統產業, 大數據產業更需尋求更優化的算法和處理模式來打破傳統技術的瓶頸, 也才能夠適應并充分利用復雜的大數據資源。 針對這一問題, 技術的進步和創新對于大數據產業發展來說至關重要。 研發投入促使創新成果的產出和技術的進步, 可以推動系統從原有的平衡態發展為不平衡態, 并最終達到新的更高層次的有序結構。由此可看出, 研發投入是系統遠離平衡態的重要契機, 可以直接反映創新和技術的投入狀況。 沒有創新和技術進化引起的產品質量、 管理效率等的變化, 系統也就不可能打破舊的平衡態而躍升到新的穩定態。 因此, 研發投入變量IR可為哈肯模型備選變量。
(2) 勞動生產率PR, 即人均生產價值轉化,用年收入與員工的比值表示, 代表大數據產業系統中的勞力部門。 勞動生產率涉及年收入和員工數兩個指標, 其中年收入可以反映大數據產業的經濟規模, 也可以體現生產部門的實際發展狀況。當產業系統從穩定態轉為不穩定態時, 由于系統環境的復雜性以及隨機漲落的觸發, 在形成新的有序結構過程中能夠依然發展并持續壯大的企業往往都是競爭能力強、 創新進步快的企業。 顯然,創新不僅包括產品工藝創新, 還包括經營管理創新、 員工素質提高等方面, 而這些創新和提高又集中體現在勞動生產率的增長[15]。 PR可反映人均生產價值的轉化程度, 以及科技成果轉向現實生產力的效率, 包括在組織、 管理、 經營等方面的科技創新。 因此, 勞動生產率也是系統自組織演化中需重點關注的變量, 可作為哈肯模型的備選變量。
(3) 資本投入RS, 反映了大數據產業系統的資本投入情況, 代表著大數據產業系統的資金投入部門, 用投資額表示。 企業的進步往往離不開資本的投入, 不僅僅是對于企業而言, 也可以上升至產業乃至政府層面。 在大數據產業演化過程中, 大數據企業通過對技術、 制度、 設備、 勞動者素質等的資本投入來獲得收益和實現增值, 從而在系統演化中贏得競爭優勢。 資本投入對大數據企業在大數據產業系統的演化中起著重要的推動作用。 因此, 資本投入也是系統演化應該關注的重要變量。 需要注意的是, 在技術進步、 設備更新等方面的投資既可以是資本投入的一部分,也可以是研發投入的一部分。 如設備更新費用可以作為資本投入中的固定資產投資, 也可作為研發投入中的硬件設備費用。 因此, 資本投入也包含了一部分研發方面的投入。 在大數據產業演化中, 研發投入往往是最直觀考慮的因素, 但由于系統環境的復雜性, 演化過程往往受到多因素共同作用。 在具體分析時, 還需要將其他非研發投入因素考慮進來。 鑒于此, 本文將資本投入RS作為哈肯模型的備選變量之一。
綜上所述, 研發投入、 勞動生產率和資本投入都是大數據產業演化發展中的重要因素, 基本能夠反映大數據產業系統的本質特征。 由于研發投入與資本投入有重合部分, 為避免數據的重復性, 將對研發投入與生產率、 資本投入與生產率進行兩兩比較, 找出符合哈肯模型變量要求的一組變量, 再識別出推動大數據產業發展的序參量。
3.2 數據來源與測算
由于我國大數據產業目前還在起步階段, 相關數據的統計工作還沒有完善且統計口徑不一致,導致缺乏完整、 準確的產值數據。 大數據產業又是由各個大數據企業等微觀個體所組成, 企業的發展狀況也能在一定程度上反映到產業上。 因此,考慮到數據的合理性和可獲取性, 本文選取2018年《中國大數據企業排行榜》 中17 家大數據相關上市企業作為樣本來代表我國大數據產業的現狀, 其數據來源于滬深證券市場披露的2017 ~2018 年上市公司報告。 表1 和表2 為2017 ~2018年17 家上市公司的研發費用、 勞動生產率和投資額的測算結果。
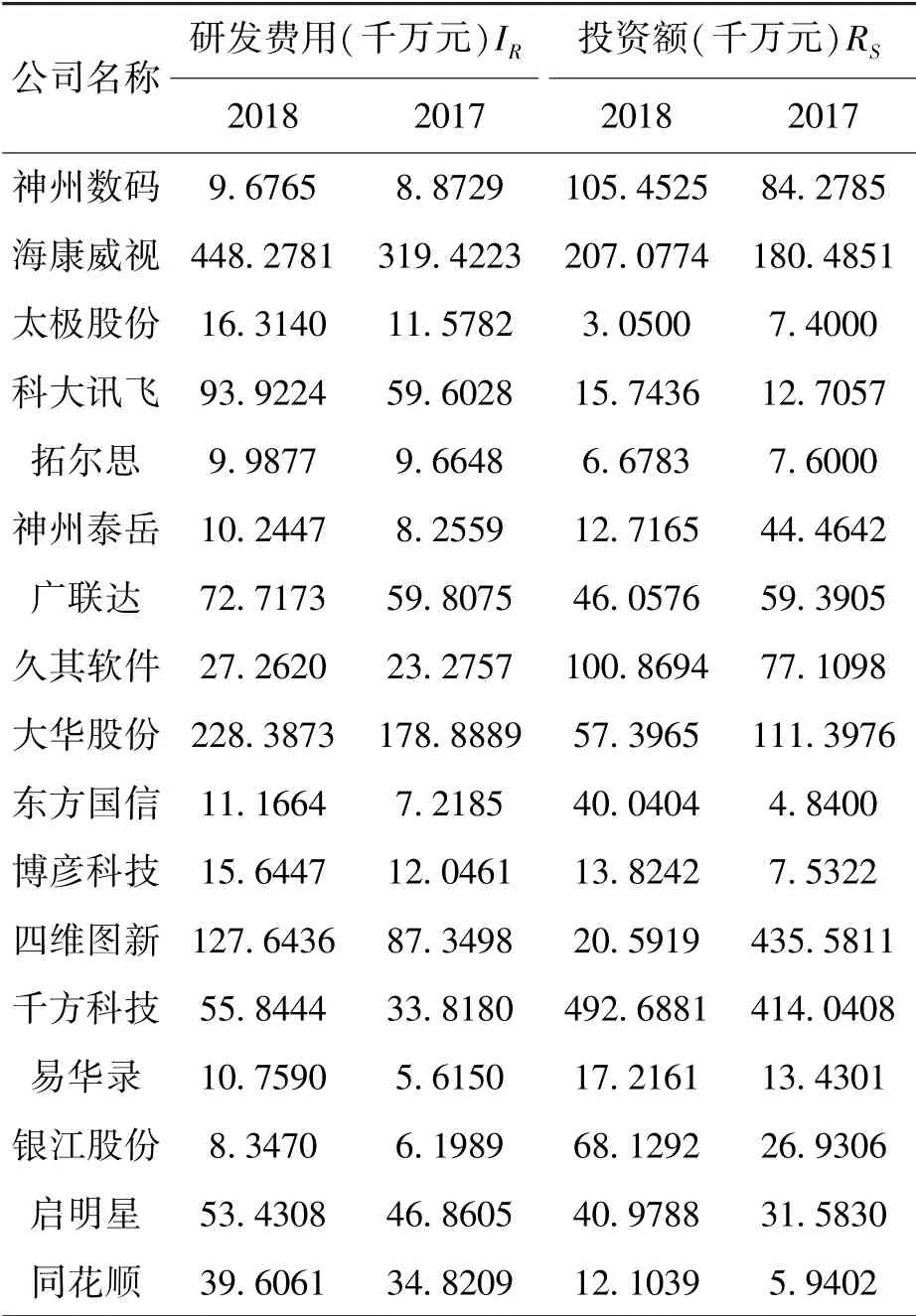
表1 大數據相關上市企業數據(一)
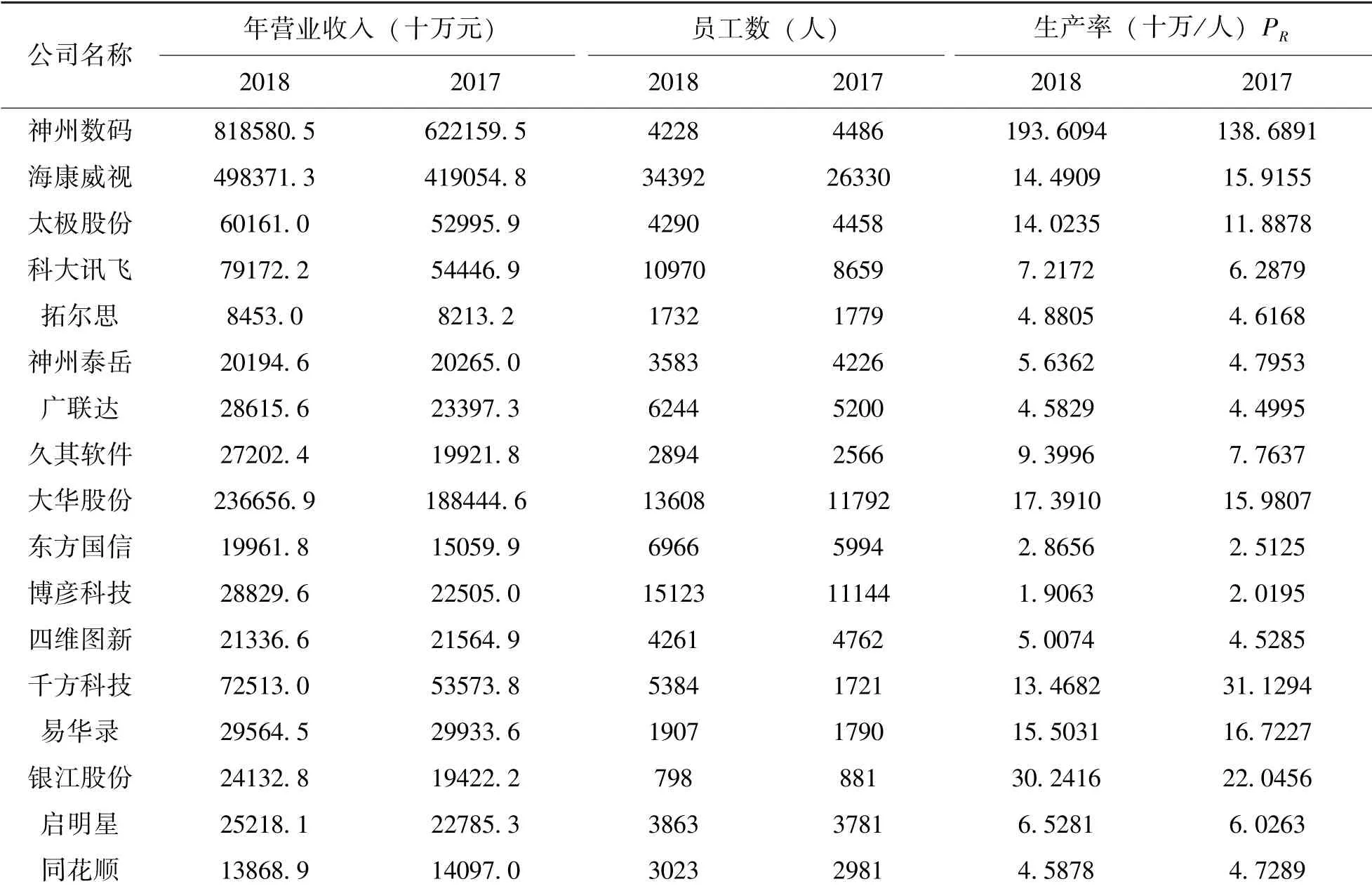
表2 大數據相關上市企業數據(二)
4 大數據產業系統的演化機制分析
4.1 序參量的識別
本文選取研發投入IR、 勞動生產率PR、 資本投入RS3 個備選變量, 而哈肯模型的變量要求為兩個, 因此需要對3 個變量進行組合再分析。 其步驟為: (1) 假設其中一個為慢變量, 即模型假設; (2) 建立相應的演化方程, 判斷其是否成立; (3) 對方程參數進行求解, 判別是否滿足絕熱近似條件; (4) 對模型假設進行判別, 求出序參量[27]。 結合上文可知, 只需對IR與PR、 RS與PR這兩組變量進行分析, 獲得4 組計算結果如表3 所示。 模型方程均利用SPSS 23.0 軟件對表1 數據進行回歸求得。 由表3 可知, IR與PR的組合不能滿足絕熱近似原理, 也就是說研發投入目前還不能夠作為哈肯模型的狀態變量, 這一點體現了大數據產業與相關聯的物聯網產業、 高新技術產業的不同之處。 RS與PR的組合滿足絕熱近似原理, 其中PR(勞動生產率) 為序參量, 其分析結果可以揭示大數據產業系統演化的一般特性。

表3 變量兩兩分析結果
4.2 勢函數求解
根據表3 結果, 獲得大數據產業系統的演化方程為:
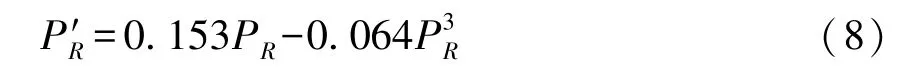
以及該系統的勢函數為:

令P′R=0 得到勢函數的3 個定態解: PR1=0,PR2=-1.546, PR3=1.546。
同時, 勢函數v 的二階導數為:
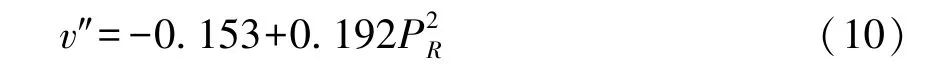
將定態解PR1代入式(10) 得v″=-0.153<0,表示勢函數式(9) 有極大值, 即vmax=0, PR1=0為穩定解。 將PR2、 PR3代入式(10) 時, v 有極小值, 即vmin=-0.09144, 表明PR2、 PR3為不穩定解, 此時勢函數的形狀如圖1。 其結構特性能夠揭示大數據產業的演化機制, 即系統勢函數會隨著狀態變量(λ1,λ2)和控制參數(a,b)的改變而改變, 系統狀態由原有的穩定轉向不穩定。 由圖1可見, 當控制變量取適當值時, 大數據產業系統內部的資本投入和勞動生產率會產生非零作用,形成新的穩定的定態解PR=±1.546。 也就是說,在這兩處, 系統的新有序結構出現。 而從式(7)可知, 此時支配大數據產業系統演化的序參量是勞動生產率。
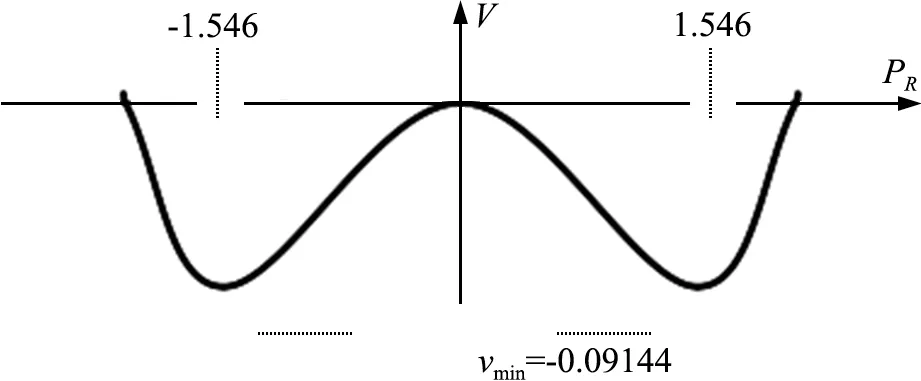
圖1 大數據產業系統勢函數圖形
4.3 結果分析
通過以上計算結果, 可以清晰地揭示出大數據產業系統的演化機制。
4.3.1 勞動生產率是大數據產業系統演化的序參量
大數據產業系統演化方程式(7) 揭示了其演化特征: 在大數據產業系統演化(即科技成果轉向大數據產業生產系統) 的臨界點上, 支配系統演化的序參量為勞動生產率。 目前, 我國大部分的大數據企業已經達到這個臨界狀態, 表明我國大數據產業從發展到目前至少已經歷過一次突變, 現在正處于一種新的有序結構的形成過程,并且在突變過程中勞動生產率起著重要的主導作用。 因此, 加速大數據產業向另一更高級、 更有序新結構演化的進程, 也同樣需要重視人均生產價值的轉化程度, 提高科技成果轉向現實生產力的效率。
4.3.2 控制變量反映大數據產業系統演化行為
系統演化行為也能由哈肯模型中各控制參數體現出來。
(1) 控制參數a 為正值, 反映資本投入抑制勞動生產率的增長。 此時, 企業加大資本投入不能較大地刺激勞動者的積極性, 說明目前我國大數據產業中加大資本投入與提高勞動生產率之間還未具有協同效應。
(2) 控制參數b 為正值, 反映勞動生產率促進投資的增長。 在國家大數據戰略支持下, 我國大數據產業得到充分發展。 無論是硬件設施建設、還是產品工藝等的改進都需要投入大量資金。 勞動生產率的提高能夠推動技術、 設備等的更新,從而刺激投資的增長, 這也說明了投資的重要性。
(3) 方程參數λ1為負值, 表明系統內部已建立勞動生產率不斷增長的正反饋機制。 勞動生產率的增長與λ1的絕對值呈正相關關系。 但此時λ1的絕對值并不大, 說明大數據產業系統的有序度還不是很高, 有進一步提升的空間。
(4) 方程參數λ2為正值, 表明大數據產業系統內部已形成資本投入遞減的負反饋機制。 當大數據產業發展初期所需的基礎設施、 設備等的投入逐漸趨于穩定狀態時, 其產業日常運行所需的資本投入也會隨之趨于穩定, 形成產業內部資本投入與生產經營之間的良性循環。 此時, 大數據產業的資本投入額度也會相應降低, 同時隨著先進技術的持續進步以及大數據產業發展的逐漸穩固, 資本投入額也將呈下降趨勢。 因此, 加強科技創新不僅有利于資本投入額的下降, 同時也能夠提高大數據產業的投入產出效率。
5 結 論
大數據產業系統具有開放性、 自我適應性、 非線性作用與涌現性4 個自組織演化特征。 應用哈肯模型分析我國大數據產業相關上市公司, 建立大數據產業系統演化方程, 推導出反映人均生產價值轉化的勞動生產率為大數據產業演化的序參量, 是大數據產業系統演化的決定因素。 大數據產業系統的演化在很大程度上取決于勞動生產率,當勞動生產率發生大幅變動時, 將役使資本投入等其他參量發生變動, 從而推動系統從一個有序結構向另一個更優的有序結構演進。 在大數據產業系統內部, 資本投入與勞動生產率的協同成為大數據產業快速發展的關鍵。 因此, 要利用開放條件的優勢, 加強系統各要素之間的配合, 使兩者之間實現良好的協同循環。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
