基于R語言的亞麻種質資源農藝性狀相關及聚類分析
2020-02-26 15:43:01張麗麗耿立格孫娟王玉祥曲志華李世芳喬海明
農學學報 2020年1期
關鍵詞:相關性
張麗麗 耿立格 孫娟 王玉祥 曲志華 李世芳 喬海明
摘要:本研究旨在通過對河北省種質資源庫部分亞麻資源進行進一步的表型鑒定,以期探索亞麻種質資源的農藝性狀相關性和聚類研究,用于亞麻新品種選育研究工作。本試驗以499份亞麻種質資源為材料,應用R語言對亞麻主要農藝性狀進行相關性分析,得出各性狀間的相關系數,并進行聚類分析。研究結果顯示亞麻單株粒重與分莖數、主莖分枝數、單株有效果數存在顯著正相關,株高與工藝長顯著正相關。聚類分析將499份資源分成了3類,種群1更有利于亞麻高產育種,種群2有利于抗倒伏亞麻新品種的選育。
關鍵詞:亞麻;農藝性狀;相關性;聚類分析;R語言
中圖分類號:S563.2
文獻標志碼:A
論文編號:cjas20190700124
0引言
亞麻(Linum usitatissimum L.)是亞麻科亞麻屬一年或多年生草本植物[1],按用途可分為油用、纖用和油纖兼用3種類型[2]。河北省是全國六大油用亞麻產區之一,年種植面積在3.7萬hm2左右。亞麻籽富含α一亞麻酸、膳食纖維及木酚素等保健成分[3],能降低三高、抗腫瘤、抗衰老、預防老年癡呆、增加智力和保護視力等[4]。種質資源是農業科學研究尤其是育種研究不可缺少的重要物質基礎,通過對亞麻種質資源進行鑒定評價,可挖掘種質資源潛力,拓寬遺傳多樣性,有利于突破亞麻育種瓶頸[5]。
“河北省農業生物資源保存中心”始建于1983年,2005年初步建立河北省農作物種質資源特性評價鑒定信息系統[6]。擁有種子低溫保存長期庫、中期庫、短期庫以及試管苗庫、超低溫庫等保存設施,共收集、保存了57種作物45962份種質資源,開展了花生口[7]、大豆[8]、黑豆[9]、玉米[10]、小麥[11]等作物資源的相關研究。張家口市農業科學院在“八五”期間為該中心登記入庫亞麻種質資源1800多份[12]。這些資源在種子庫己保存了30年之久,當時國內的亞麻調查記載標準并不統一,本研究旨在將其中部分資源進行繁種更新,并根據《亞麻種質資源描述規范和數據標準》[13]對其進行更規范化的表型鑒定,以期通過探索亞麻種質資源的農藝性狀相關性和聚類分析研究,為亞麻新品種選育的親本選擇提供數據支持,用于輔助亞麻新品種選育研究工作。
隨著數據量級的不斷增大,大數據挖掘算法提出了新的需求與挑戰。本研究應用數據聚類的K-Means算法,結合R語言的實現,通過迭代方法實現了基于Map-Reduce函數的K-means優化算法,并用R程序得以實現[14-15];最后給出了程序的測試與應用,驗證算法的可行性。
1材料與方法
1.1試驗材料
“河北省農業生物資源保存中心”提供的500份亞麻種質資源(見表1),2018年在河北省張家口市農業科學院的壩上試驗基地繁種更新,每行長6.67m,行距0.25m,4行區種植。其中1份由于蒴果開裂,果實脫落未能及時收獲,共收獲499份材料。
1.2試驗方法
試驗于2018年在河北省張家口市農業科學院張北基地進行。每小區1mx6.67m,4行區種植,田間管理同一般大田。亞麻成熟收獲后,每小區隨機收獲10株用于考種,并測定小區產量,記載按照《亞麻種質資源描述規范和數據標準》[13]進行。
1.3數據分析
將499份亞麻資源的8個農藝性狀指標(株高、工藝長、分莖數、主莖分枝數、單株有效果數、單株無效果數、每果粒數和單株粒重)作為細分變量,基于該數據,采用k-means聚類分析方法,將具有相似屬性的亞麻品種聚為一類,使得同一類品種具有高度的相似性。采用excel計算各農藝性狀平均數,用R語言進行各農藝性狀的相關性分析(Pearson相關系數、Kendall相關系數、Spearman相關系數)和聚類分析。
2結果與分析
2.1亞麻種質資源各主要農藝性狀的相關性分析
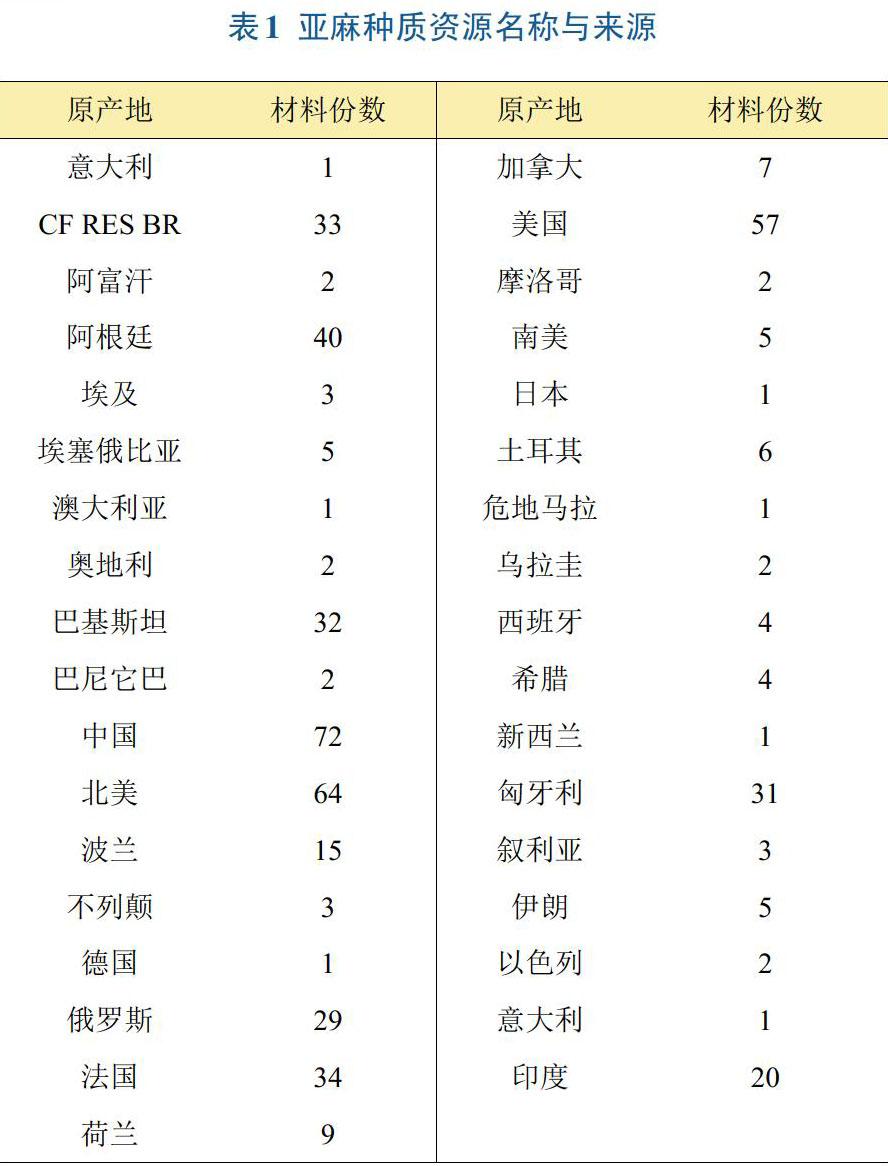
圖1為亞麻種質資源各主要農藝性狀指標的相關系數矩陣圖,主對角線為各指標直方圖;主對角線下方為各指標間的散點圖;主對角線上方從上到下依次為各指標間的Spearman相關系數、Kendall相關系數、Pearson相關系數以及Pearson相關系數的顯著性檢驗的P值[16],背景顏色越接近藍色,則相關系數越接近于1,背景顏色越接近紅色,則相關系數越接近于-1。由圖可看出,亞麻種質資源的主莖分枝數、單株粒重均與其他7個農藝性狀存在正相關關系,其他各農藝性狀間存在正相關也存在負相關。其中,株高與工藝長顯著正相關,Spearman相關系數最大,達到0.87,與主莖分枝數和單株無效果數存在弱相關關系;單株有效果數與單株粒重、主莖分枝數、分莖數顯著正相關,Spearman相關系數分別為0.73、0.5、0.52;主莖分枝數與單株粒重、單株有效果數均為顯著正相關,相關系數分別為0.54、0.50;單株有效果數與分莖數顯著正相關,相關系數0.52;主莖分枝數與各性狀均呈正相關,其中與分莖數和工藝長的相關性沒有達到顯著水平,與其他5個性狀均達到顯著水平,與單株粒重、單株有效果數的Spearman相關系數分別為0.54、0.50;單株無效果數除與單株粒重相關系數為0外,與其他各性狀相關顯著,其中與株高、工藝長和每果粒數顯著負相關,與分莖數、主莖分枝數和單株有效果數顯著正相關;每果粒數與單株粒重存在弱相關關系。Pearson相關系數的顯著性檢驗的P值可用于比較不同類別數值時的聚類結果,從而找出最優聚類結果,該值越大表明組內差距越小,組間差距越大,聚類效果越好。
2.2亞麻種質資源的K-means聚類分析
應用R語言通過計算不同K值下簇集中各對象的輪廓系數確定最優聚類數[17];然后通過凝聚層次聚類的方法獲得數據集的分布,確定不同類別的中心坐標點;最后利用k-means方法完成聚類,將這499份資源聚成3類。
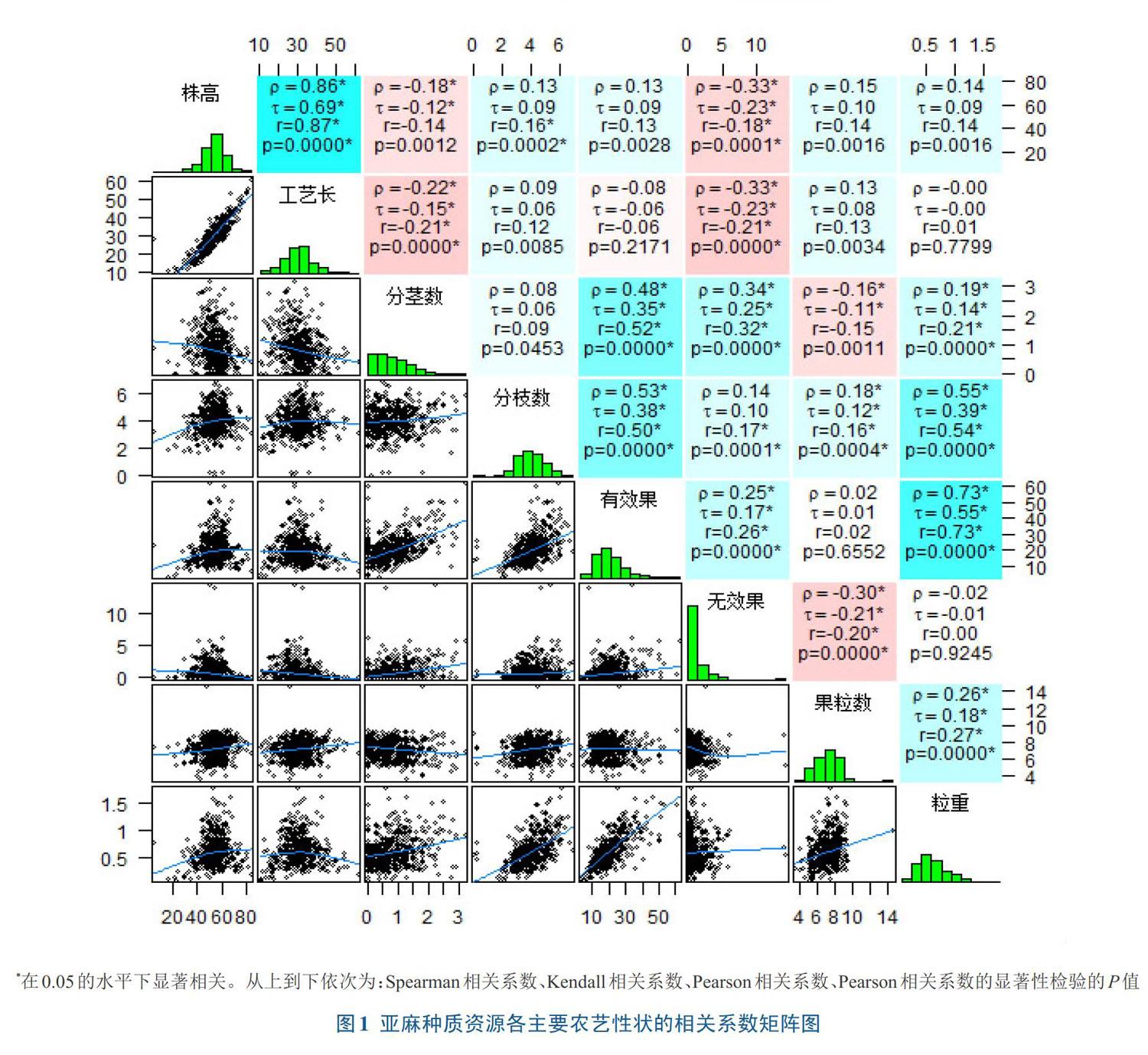
2.2.1輪廓系數輪廓系數是聚類效果好壞的一種評價方式,可以更好實現對于聚類效果的判斷[18]。將各指標數據進行標準化處理后,根據輪廓系數圖(圖2)可以看到,在聚類數為3時輪廓系數達到了峰值,所以最佳聚類數為3。
2.2.2各類別的中心點坐標中心坐標點是用于比較不同類別數值時的聚類結果,從而找出最優聚類結果,該值越大表明組內差距越小,組間差距越大,聚類效果越好。由表2可見,3個分群所包含的樣本量分別為141、215、143;各分群的組內平方和分別為15353.26、20657.56、15937.71,分群3最高;另外組間平方和占總平方和的53.2%。
2.2.3各分群的概率函數由各亞麻種質資源分群的概率密度函數圖進行分群特點分析如下,詳情見圖3,圖4,圖5。
分群1的特點:株高主要分布在50-60cm之間,工藝長主要分布在25-35cm之間,分莖數主要集中在0.5-1.5個之間,主莖分枝數主要集中在4-6個之間,單株有效果數主要在25-35個之間,單株無效果數在0-2個之間,每果粒數在6-9個之間,單株粒重在0.8-1.3g之間。
分群2的特點:株高主要分布在35-50cm之間,工藝長主要分布在18-30cm之間,分莖數主要集中在0.5-1.5個之間,主莖分枝數主要集中在2.5-5個之間,單株有效果數在10-25個之間,單株無效果數在0-2個之間,每果粒數在5-9個之間,單株粒重在0.3-0.8g之間。
分群3的特點:株高主要分布在55-65cm之間,工藝長主要分布在30-45cm之間,分莖數主要集中在0-1.5個之間,主莖分枝數主要集中在2.5-5個之間,單株有效果數在10-25個之間,單株無效果數在0-1個之間,每果粒數在5-9個之間,單株粒重在0.3-0.8g之間。
3結論與討論
人們對農作物種質資源尤其亞麻種質資源的研究結果分析采用的都是SPSS、DPS或者SAS等軟件[2,19]。目前,R語言分析方法被越來越多的農業科研人員接受。溫嵐等[20]應用R語言對長蒴黃麻5個產量性狀進行回歸與相關分析;肖海霞等[21]采用R語言對吐魯番驢、疆岳驢及和田青驢的體重和體尺性狀進行了相關和回歸分析;張禎勇等[22]使用R語言對”3414”肥料效應試驗結果擬合了二元二次、三元二次肥料效應方程;盛坤等[23]用R語言計算冬小麥品種品質性狀的安全指數;郭敏杰等[24]用R語言對花生區試進行品種的適應性、豐產性和穩產性,試點環境的相關性、區分力和代表性分析。
本研究通過對499份亞麻種質資源的8個主要農藝性狀指標按照標準進行了規范化鑒定,并應用R語言分析方法進行相關性分析,得出亞麻種質資源的主莖分枝數、單株粒重均與其他7個農藝性狀存在正相關關系,其他6個農藝性狀間存在正相關也存在負相關,其中單株粒重和分莖數、主莖分枝數、單株有效果數顯著正相關,株高和工藝長顯著正相關。從主要農藝性狀的相關性及相關系數分析結果看,分莖數和主莖分枝數指標會對單株有效果數指標產生顯著影響,而單株有效果數和主莖分枝數指標會對單株粒重指標產生顯著影響。因此,在亞麻育種親本選擇時,注重對單株有效果數和單株粒重的選擇,從而能提高分莖數、主莖分枝數,提高單株生產力及種子產量,從而達到高產育種的目的,這為亞麻新品種選育工作的親本選擇提供了新的理論依據。
應用R語言將這499份資源聚成了3類,對比3個種群聚類分析結果發現,種群1在單株有效果數、單株粒重等性狀上表現更為優良,株高、工藝長等性狀表現較差,容易發生倒伏。種群2在株高、工藝長等性狀上表現較好,不易發生倒伏,其他性狀表現一般。種群3在株高、工藝長等性狀上表現較差,容易發生倒伏,其他性狀表現和種群2相似。整體上,種群1各農藝性狀表現更為優良,更有利于亞麻高產育種,種群2有利于抗倒伏亞麻新品種的選育。此結論為亞麻新品種選育提供了新的目標親本材料。
參考文獻
[1]米君.亞麻(胡麻)高產栽培技術[M].北京:金盾出版社,2006.
[2]崔翠,周清元,王利鵑,等.亞麻種質主要農藝性狀主成分分析與綜合評價[J].西南大學學報:自然科學版,2016,38(12):10-18.
[3]黨占海,趙瑋.胡麻產業技術體系[M].蘭州:蘭州大學出版社,2015
[4]郭永利,范麗娟.亞麻籽的保健功效和藥用價值[J].中國麻業科學,2007,29(3):147-149.
[5]黨占海,趙瑋中國現代農業產業可持續發展戰略研究胡麻分冊[M].北京:中國農業出版社,2016.
[6]耿立格,李靈芝,王麗娜,等.河北省農作物種質資源特性評價鑒定信息系統的建立[J].河北農業科學,2005,9(02):70-72.
[7]劉立峰,耿立格,王靜華,等.河北省花生地方品種農藝性狀和品質性狀的遺傳分化[J].植物遺傳資源學報,2008,9(02):190-194.
[8]耿立格,宋春風,王麗娜,等.近紅外光譜無損測定大豆種子生活力方法研究[J].植物遺傳資源學報,2013,14(06):1208-1212.
[9]耿立格,王麗娜,張磊,等.河北省綠子葉黑豆種質資源表現型和ISSR標記遺傳多樣性分析[J].植物遺傳資源學報,2010.11(03):266-270.
[10]張磊,耿立格,王麗娜,等.不同玉米自交系萌芽期的抗旱性研究[J].玉米科學,2010,18(04):77-81.
[11]許紅星,許云峰,耿立格,等.我國小麥農家品種和近緣種對白粉病的苗期抗性[J].中國生態農業學報,2011,19(05):1210-1214.
[12]米君.河北省胡麻生產調研報告[J].現代農村科技,2009(20):49-50.
[13]王玉富,粟建光.亞麻種質資源描述規范和數據標準[M].中國農業出版社.2006.
[14]郭顯娥.K-Means優化算法的R語言實現[J].山西大同大學學報:自然科學版,2018,34(2):27-29,33.
[15]李曉瑜,俞麗穎,雷航,等.一種K-means改進算法的并行化實現與應用[J].電子科技大學學報,2017,43(1):61-68.
[16]金林,李研.幾種相關系數辨析及其在R語言中的實現[J].統計與信息論壇,2019,34(4):3-11.
[17]夏士雄,李文超,周勇,等.一種改進的k-means聚類算法(英文)[J].Joumal of Southeast University (English Edition),2007(03):435-438.
[18]朱連江,馬炳先,趙學泉.基于輪廓系數的聚類有效性分析[J].計算機應用,2010,30(S2):139-141,198.
[19]張麗麗,劉晶晶,喬海明,等.從俄羅斯引進亞麻種質資源的農藝性狀評價[J].中國油料作物學報,2017,39(05):698-703.
[20]溫嵐,陳基權,戴志剛,等.長蒴黃麻產葉量的多元回歸與偏相關的R語言分析[J].作物雜志,2013(01):49-53.
[21]肖海霞,托乎提·阿及德,石國慶,等.基于R語言的吐魯番驢體尺和體質量相關分析[J].河南農業科學,2012,41(10):153-157.
[22]張禎勇,高明文,肖啟銀,等.基于R語言的“3414”肥效試驗的統計分析[J].中國農學通報,2011,27(27): 127-134.
[23]盛坤,李曉航,王映紅,等.用R語言計算冬小麥品種品質性狀的安傘指數[J].中國農學通報,2017,33(25):8-12.
[24]郭敏杰,鄧麗,任麗,等基于R語言的AMMI和GGE雙標圖在花生區試中的應用[J].花生學報,2017,46(02):24-31.
[25]張麗麗,米君,李世芳.胡麻種間雜交種主要農藝性狀與產量的關系研究[J]。河北農業科學,2014,18(03): 76-78,88.
基金項目:現代農業產業技術體系建設專項資金資助項目“胡麻抗逆育種崗位”(CARS-14-1-08);國家科技資源共享服務平臺“國家農作物種質資源共享服務平臺”(NICGR2018-23);河北省現代農業產業技術體系油料產業創新團隊“特色油料崗位”(HBCT2018090204)。
第一作者簡介:張麗麗,女,1983年出生,河北保定人,副研究員,碩士研究生,主要從事胡麻新品種選育及栽培技術研究。通信地址:075000張家口市經開區惠通街張家口市農業科學院,Tel:0313-7155779,E-mail:zhanglili57@126.com。
通訊作者:喬海明,男,1965年出生,張北人,研究員,本科,主要從事胡麻新品種選育及栽培技術研究。通信地址:075000張家口市經開區惠通街張家口市農業科學院,Tel: 0313-7155774,E-mail:qhm1965@163.com。
收稿日期:2019-07-16,修回日期:2019-08-30。
猜你喜歡
商情(2016年42期)2016-12-23 14:25:52
商情(2016年42期)2016-12-23 13:35:35
東方教育(2016年4期)2016-12-14 22:15:13
財經界·學術版(2016年19期)2016-11-16 16:28:33
科技視界(2016年21期)2016-10-17 17:37:34
中國實用醫藥(2016年24期)2016-10-17 04:31:12
中國實用醫藥(2016年24期)2016-10-17 03:37:40
中國實用醫藥(2016年24期)2016-10-17 03:35:06
科學與財富(2016年28期)2016-10-14 21:58:50
