基于領域詞典和機器學習的影評情感分析
2019-11-03 14:07:16徐善山
電腦知識與技術 2019年23期
關鍵詞:機器學習
徐善山
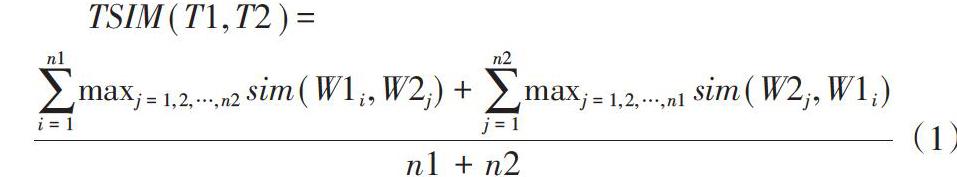


摘要:針對影評文本情感分析準確性不高的問題,本文提出一種基于影評領域詞典結合機器學習的情感分析方法。首先,構建完備的影評領域相關詞典,如程度副詞詞典、否定詞詞典和網絡用詞詞典。然后,利用文本相似度的方法(TSIM)對訓練數據集進行去重處理,并提出三類特征:詞性、句法、依存進行選擇。最后,利用NB和SVM相結合的分類方法對影評進行情感分類。實現結果表明,該方法相對于僅僅基于傳統的機器學習的方法,具有更準確的分類精度。
關鍵詞:情感分析;領域詞典;機器學習;數據去重;特征選擇
中圖分類號:TP18? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2019)23-0222-02
開放科學(資源服務)標識碼(OSID):
1 引言
交互性網絡技術的不斷發展,使得越來越多的人通過豆瓣、微博影評等電影網站發表自己對電影的觀點和看法,這些影評包含著很多用戶對于電影及其相關內容的評價。因此,對于這些影評文本信息進行情感分析具有重要的商業價值。但是目前,影評領域情感分析的準確性不是很高,主要是因為影評領域相關情感詞典的不完備性、機器學習方法需要完備的語料庫和精確的特征選擇。針對上述問題本文提出一種基于影評領域詞典和機器學習相結合的情感分析方法。本文的主要工作為:1)構建完備的影評領域相關的詞典;2)對訓練數據集進行去重處理,并進行特征選擇;3)利用NB和SVM相結合的分類方法對影評文本進行情感分類。
2 相關工作
文本情感分析技術主要分為情感詞典和機器學習的方法。在情感詞典方面:栗雨晴等人[1]提出一種基于雙語詞典的多類情感分析方法,通過構建雙語多類情感詞典對微博文本進行多分類語義傾向性分析。肖江等人[2]提出一種基于領域情感詞典的中文微博情感分析策略,能夠有效分析出微博中的情感傾向。孔偉俊等人[3]提出基于領域詞典的商品評論分析策略,能夠有效分析出網絡商品評論的情感傾向。在機器學習方面:朱軍等人[4]提出了一種改進的機器學習方法和情感詞典結合的集成學習情感極性分類方法。針對旅游網絡評價使用的旅游情感詞匯量不多的特點,王新宇[5]提出一種基于旅游情感詞典和機器學習相結合的方法。針對中文微博內容較短、口語化嚴重、主題分散等特點,孫建旺等人[6]提出了基于詞典和機器學習相結合的方法。
3 影評情感分析
3.1 情感詞典的構建
目前,影評領域情感分析方面尚未有一部通用和完備的情感詞典,使得影評領域的情感分析一直不夠準確。因此,本文為了使影評領域的情感分析具有更好的識別效果,將目前較好的并廣泛應用的3個情感詞典(知網的HowNet、臺灣大學的NTUSD和大連理工大學的情感詞典)進行優化和整合,構建成了一部綜合基礎情感詞典。
此外,本文還構建了程度副詞詞典、否定詞詞典和網絡用詞情感詞典。程度副詞詞典主要是采用知網的程度級別詞典,共219個詞,如:極其、非常、不少、半點等。本文整理構建了否定詞典,共31個詞,如:不、沒、無、非等。網絡用詞情感詞典主要是將“常用網絡用詞情感詞典”和“2019網絡用詞”進行優化和整合,從而構建了數量為254的網絡用詞情感詞典,如:盤它、開掛、前方高能、實錘等。
3.2 數據集去重
如果機器學習中訓練數據集的相似影評文本的樣本數量很多,將嚴重影響機器學習模型預測結果的分布和情感分析的性能。由此,本文采用文本相似度的方法,將相似度最高的影評文本進行合并,達到對訓練數據集去重的目。
定義1:文本相似度(Text similarity,[TSIM] )用來計算兩個文本的語義相似度,計算公式如下:
[TSIM(T1,T2)=i=1n1maxj=1,2,…,n2sim(W1i,W2j)+j=1n2maxj=1,2,…,n1sim(W2j,W1i)n1+n2]? (1)
在公式(1)中,[W1i]和[W2j]分別為影評文本[T1]和[T2]中的詞元素,[n1]和[n2]分別為影評文本[T1]和[T2]中詞元素總的數量,[sim(W1i,W2j)]是基于知網詞語的語義相似度計算公式。首先遍歷訓練集中的所有語句,然后將相似度最高的兩條語句進行合并,達到減少機器學習中訓練數據集的相似評論文本的樣本數量、增加低頻文本權重的目的,從而提高機器學習模型預測結果的分布和情感分析的性能。此方法能夠有效降低影評文本中因某些用戶的惡意評論或水軍的虛假言論,導致機器學習模型預測結果的不準確。
3.3 特征選擇
文本的特征提取是機器學習的關鍵步驟,可以說情感分類的準確性和效率很大程度上取決于特征值的選取。本文選擇三類特征:詞性、句法、依存關系。詞性在影評文本情感分析中起很大的作用,因為一個影評文本是由多個不同詞性的詞構成的。句法特征是給出句子的組成部分、排列順序、詞性標注的特征。依存關系特征是從依存關系樹中給出的依存關系和詞性搭配的特征,其對影評文本情感分析起著決定性作用。在選擇特征時,每類特征維度的具體含義如表1所示。
本文以“這部電影真心不錯,我非常喜歡。”為例進行特征選擇。
①使用中科院ICTCLAS分詞技術進行處理,可以獲得例句的詞性特征、句法特征如下:
這部/r電影/n真心/d不錯/a,/wd我/rr非常/d喜歡/vi。/wj
其中,/r表示代詞、/n表示名詞、/d表示副詞、/a表示形容詞、/wd表示標點符號、/vi表示動詞。
②在ICTCLAS分詞的基礎上,使用哈工大語言技術平臺(LTP)處理工具,獲得例句的依存關系和詞性搭配特征如下:
從圖2中可以得到例句的5種依存關系:HED(核心)、ATT(定中關系)、SBV(主謂關系)、ADV(狀中關系)、COO(并列關系)。通過上述2個步驟可以得到機器學習方法的三種基本特征模板,并作歸一化處理,從而為其訓練分類器。
3.4 NB結合SVM的分類方法
選擇三類特征并作歸一化處理,將其擴展到機器學習的特征模板中后,本文采用NB結合SVM對整個數據集進行訓練得到分類器。
樸素貝葉斯(NB)分類算法具有簡單、穩定的分類效果,但是條件是每個變量是相互獨立的。判斷一條影評的情感傾向時,若影評中有情感詞出現在情感詞典中,則采用NB分類方法,因為將情感詞作為NB分類方法的特征時,統計特征更加合理和明顯,并且可以利用NB分類方法從事先計算好的情感詞的條件概率分布得到分類的結果。
支持向量機(SVM)是一種二類分類模型,利用SVM分類方法進行分類,是因為NB分類方法僅僅簡單地統計影評中的詞語得到概率分布,忽略了詞語之間的依存關系,而SVM考慮到了影評詞語之間的依存關系和句子之間的語義關系。所以本文將兩種方法相結合進行互補,達到對分類結果更加準確的目的。
如圖2是基于NB和SVM的情感分類流程圖。第一步,對影評數據進行綜合處理:首先將數據集分為正向和負向,然后對數據集進行去重處理,最后提取特征并作歸一化處理;第二步,判斷特征值是否在情感詞典中,若在情感詞典中則使用NB分類方法,反之則使用SVM分類方法。
4 實驗分析
本文利用網絡爬蟲技術從豆瓣平臺和微博影評中抓取5000條影評數據集,并對這些影評數據集進行人工情感標注。本次實驗以準確率P、召回率R和F1值作為評價指標。
為了驗證本文提出的基于領域詞典和機器學習的情感分析的準確性,本文通過下表對測試數據進行了實驗,并對結果進行分析和評價。
由上表可以得出,基于領域詞典和機器學習的情感分析方法在準確率上面比基于傳統的SVM和NB分類方法都要高。因此,該實驗證明了基于領域詞典和機器學習的情感分析方法在整體上是優于基于傳統的SVM和NB分類方法,并驗證了本文方法具有更高的準確性。
5 結論
實驗結果表明,基于領域詞典和機器學習的情感分析方法對于影評領域的情感分類具有更高的準確性,能夠更加適應于影評領域的情感分析,從而解決了傳統機器學習方法對影評領域情感分析不準確的問題。
參考文獻:
[1] 栗雨晴,禮欣,韓煦,等.基于雙語詞典的微博多類情感分析方法[J].電子學報,2016,44(9):2069-2073.
[2] 肖江,丁星,何榮杰.基于領域情感詞典的中文微博情感分析[J].電子設計工程,2015,23(12):18-21.
[3] 孔偉俊,胡廣朋.基于領域詞典的網絡商品評論情感分析[J].計算機與數字工程,2018,45(1):155-159.
[4] 朱軍,劉嘉勇,張騰飛,等.基于情感詞典和集成學習的情感極性分類方法[J].計算機應用,2018,38(S1):95-98.
[5] 王新宇.基于情感詞典與機器學習的旅游網絡評價情感分析研究[J].計算機與數字工程,2016,44(4):578-582.
[6] 孫建旺,呂學強,張雷瀚.基于詞典與機器學習的中文微博情感分析研究[J].計算機應用與軟件,2014,31(7):177-181.
【通聯編輯:唐一東】
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
