大規模軌跡數據并行化地圖匹配算法
2019-09-20 07:35:46郭佳豪段宗濤
測控技術 2019年2期
康 軍,2, 郭佳豪, 段宗濤,2, 唐 蕾, 張 凡
(1.長安大學 信息工程學院,陜西 西安 710064; 2.陜西省道路交通智能檢測與裝備工程技術研究中心,陜西 西安 710064)
城市計算是一種利用大數據技術解決城市治理問題的新興領域,而軌跡數據是城市計算應用中最重要的數據源之一[1-2]。隨著相關問題的產生,以及計算性能的極大提升,對大規模軌跡數據的研究非常廣泛。如文獻[3],第一次利用軌跡數據進行實驗,分析出出租車司機普遍存在拒載現象,并且根據算法估計出北京市高收入出租車司機的拒載概率大約為8.25%。滴滴[4]每天有數百萬司機為上億用戶提供打車服務,針對訂單的分配問題就需要準確、實時的司機與乘客的位置信息。
為了更好地利用大規模軌跡數據,車輛導航定位等技術非常重要,而地圖匹配正是車輛導航技術中的核心技術之一。目前對于地圖匹配算法的研究非常廣泛,如文獻[5]提出一種加權幾何地圖匹配算法,該方法利用水平精度因子、行駛速度、行進距離來獲取動態加權系數,利用加權系數與幾何特征值的乘積來選取匹配道路。文獻[6]和文獻[7]是兩種基于隱馬爾可夫模型的高級地圖匹配算法,這種方法主要針對路網復雜,軌跡采樣頻率低等復雜場景下的地圖匹配。現有的研究主要針對地圖匹配的精度問題,而數據規模的增大,使得傳統的串行算法不再適用。文獻[8]提出了一種基于Hadoop的分布式地圖匹配算法,但實驗的最大數據量為20萬個軌跡點,數據規模并不是很大。針對此問題,提出一種基于大規模軌跡數據的并行化地圖匹配算法,并利用基于GeoHash編碼的網格化地圖對候選道路的選取進行了優化。實驗使用了大規模出租車軌跡數據,對比了該算法與文獻[8]的算法對同規模軌跡數據的運行時間,并參考文獻[9]采用的3種并行計算的性能比較方式對本算法進行測試。
1 問題分析
1.1 串行地圖匹配算法
地圖匹配算法主要有基于幾何的地圖匹配算法、基于拓撲的地圖匹配算法、高級地圖匹配算法等。在眾多的地圖匹配算法中,選取一種動態加權的地圖匹配算法[10]進行并行化實現。該算法準確率達到96.7%,并且算法的各個特征以及權值系數計算過程非常簡單、易于實現,非常適合用于解決軌跡數據規模大的地圖匹配問題。
該算法的主要步驟是取候選道路,計算待匹配點與候選道路的投影距離、航向夾角、軌跡夾角這3個特征值,再分別計算每個特征的權值系數,最后加權求和,選取得分最小的道路作為候選道路,待匹配點在該道路上的投影點為修正后的軌跡點。得分的計算公式如下:
(1)
式中,di為投影距離;Δθheadi為航向夾角;Δθtraji為軌跡夾角;Wi為投影距離的動態系數;Whead為航向夾角的動態系數;Wtraji為軌跡夾角的動態系數;N為候選路段個數。
1.2 網格化地圖
在地圖匹配過程中首先要選取候選路段,然后在候選路段中根據不同的匹配算法選取最為匹配的路段。文獻[10]中選取經緯度的L∞距離作為選取的距離度量,這種方法得到的范圍比歐式距離、曼哈頓距離得到的面積大,可以最大限度地選取候選路段。而此方法需要遍歷整個路網,由于真實路網的數據量很大,因此這種方法非常消耗時間。候選路段的選取問題可以抽象為一種空間索引問題。如文獻[11]采用了二級網格索引,可以將候選路段的搜索進行優化,但該方法需要將地圖數據劃分為兩個刻度不同的地圖數據,索引具體的網格也需要兩次完成。GeoHash[12]是一種有效的地理編碼方式,可以將經緯度利用二分法進行二進制編碼,再用Base32編碼進行壓縮。GeoHash將二維的經緯度坐標轉換為一維的字符串編號,每個編碼代表一個矩形區域,編碼的長度決定矩形區域的大小,這種編碼方式非常適合網格化地圖問題。
原始的西安市地圖是一個左下角坐標為(108.67,33.7)、右上角坐標為(109.81,34.75)的矩形區域。將經緯度分別按18位、17位進行GeoHash編碼,如表1所示,此時的經緯度誤差均為0.00136,可以將所有路網分割為邊長為0.00136°的矩形區域。這樣可以把這個區域分割為大約840×774個網格。每個網格是一個經度邊長為0.00136°、緯度邊長為0.00136°的矩形區域,且每個網格剛好可以用一個GeoHash編碼的字符串表示。
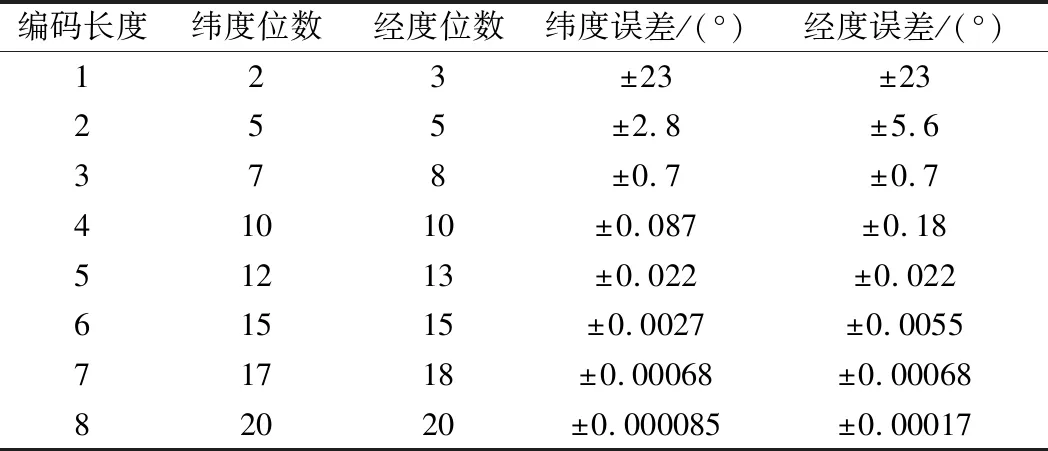
表1 GeoHash編碼精度表
網格編碼過程如下。
① 根據對角線上兩個坐標求平均值,可以得到網格中心點的坐標;
② 利用二分法將中心點的坐標轉為二進制碼;
③ 將經度放在奇數位,緯度在偶數位,這樣可將兩個二進制碼合并成一個二進制碼;
④ 最后進行Base32編碼,得到最終的網格編號。
如圖1所示,點C為中間網格的中心點,點C對應的編碼即為該網格的編碼,周圍的道路為Path1、Path2,其余的點為道路上的結點。

圖1 網格化地圖示意圖
1.3 軌跡數據預處理
原始軌跡數據主要包含車牌號、時間戳、經度、緯度、速度、航向夾角和車輛狀態等字段。實驗使用的數據為西安市出租車軌跡數據,采樣間隔為30 s,每輛車每天產生大約2880條軌跡數據。所有出租車每天大約產生2 GB左右的軌跡數據,最大實驗數據約為14.7 GB。
首先需要對數據進行數據清洗,原始的軌跡數據是無序、且含有異常數據的。數據清洗包括以下幾步:數據去重;去除漢字;去除異常軌跡點;按車牌、時間排序。
在式(1)中參數Δθtraji為航向夾角特征,在數據清洗過程中,需要利用連續兩個軌跡點的軌跡距離判斷是否為異常點,這時可以直接計算出軌跡夾角,減小后續匹配的計算量。
在計算軌跡夾角之后,對每個軌跡點計算其對應的GeoHash編碼,這個編碼就是該軌跡點所對應的地圖網格的編號,這樣可以增強軌跡數據的內聚性。編碼方式與網格化地圖的編碼方式一致。如軌跡點坐標為(108.945652,34.184875),編碼為wg27cbu,將該編碼也保留在原始數據中。
1.4 選取候選路段
當匹配一個待匹配點時,先用GoeHash編碼計算該點在地圖中的網格編號,根據網格編號可以查找該網格的路段數據,以及周圍的8個網格的路段數據,字典型的查詢時間復雜度為O(1)。在進行候選路段選取時,選擇待匹配點周圍9個網格中的數據進行遍歷。這樣就把地圖數據規模縮小至原始地圖面積的0.00138%,極大地降低了時間復雜度。如圖2所示,小圓圈表示待匹配點,字符串分別表示9個網格的網格編號,虛線的網格為最終的候選路段范圍。
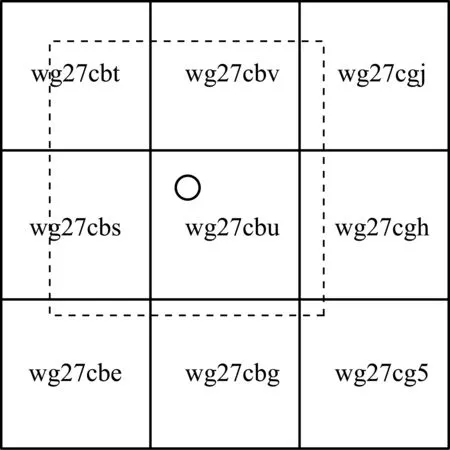
圖2 候選道路的選取
2 并行化地圖匹配算法
2.1 Spark介紹
隨著科技的發展,位置信息很容易被記錄下來,大規模的軌跡數據是城市計算的重要數據來源之一。而Spark等開源的大數據平臺的出現,使大規模數據的計算更加便捷。將動態加權的地圖匹配串行算法改為Spark RDD的編程模型,可以快速地完成大規模地圖數據的地圖匹配任務,為城市計算等應用提供了有力的保證。
2.2 分區方法
為了使并行計算更為有效,將網格化的地圖數據與帶有網格編號的軌跡數據利用HashPartitioner的方式進行分區。設軌跡點A的GeoHash編碼為grid,grid的數據類型為字串類型,則軌跡點A利用Spark的HashPartitioner分區器進行分區時,其分區編號key可表示為
key=String.hashcode(grid) modn
(2)
其中,String.hashcode()為字串類的hashcode函數;mod表示整數求余運算;n表示設定的分區數目。將網格地圖數據分配給各個分區時,首先使用如式(2)所示的方法計算各個網格所對應的分區編號;然后根據1.4節的候選路段選取辦法,確定當前網格的其他8個相鄰網格;最后將上述9個網格對應的網格-路段數據分發給選定分區。
2.3 算法介紹
如表2所示,并行化地圖匹配算法的輸入為地圖數據、預處理后的軌跡數據、分區數,輸出為匹配后的軌跡數據。

表2 并行化地圖匹配算法
首先將原始的地圖數據映射為網格編號為key的網格化地圖數據,再得到軌跡點的網格編號。然后分別對地圖數據和軌跡數據進行分區,將相同key的軌跡數據和地圖數據進行連接,得到該軌跡點對應的候選路段數據。并行計算每個點對應的每條候選道路的投影距離特征、航向夾角特征、軌跡夾角特征。計算最終得分,并對候選路段按得分進行升序排列,取出得分最低的候選路段作為最終的匹配路段。最后對數據進行重新合并,返回匹配后的軌跡數據。
3 實驗與分析
3.1 實驗數據及環境
實驗數據來源于西安市交通管理部門,為出租車1周產生的軌跡數據,數據量約2億條。軌跡數據的格式以及清洗過程如1.3節所示。電子地圖數據為西安市地圖數據,包含2.9萬條西安市城區道路。
實驗使用的Spark集群包含13個Worker節點,252個Core,每個節點32 GB內存,總內存416 GB。原始數據存儲在HDFS平臺上,運行的結果再保存到HDFS上。Spark的部署模式為Standalone模式,該模式具有容錯性,且支持分布式部署等優點,適用于真實場景下大規模數據的計算。
3.2 算法效率對比
在相同數據規模下,使用本方法與文獻[8]中的實驗結果進行對比,如表3所示。顯然新的方法在性能方面取得了很大的提升,特別是當數據量增大為20萬條時,新算法的運行時間為舊算法的44%,比數據量小時性能提升的效果更好。原始方法并沒有在足夠大的規模下進行試驗,將數據上升至接近3000萬條,新的算法仍然高效。提升至2億余條,仍然可以在短時間內完成匹配,最大數據規模是原始算法最大規模數據(20萬條)的1000倍以上,時間開銷僅用了其32倍。新的算法更加適合于大規模軌跡數據的地圖匹配問題。
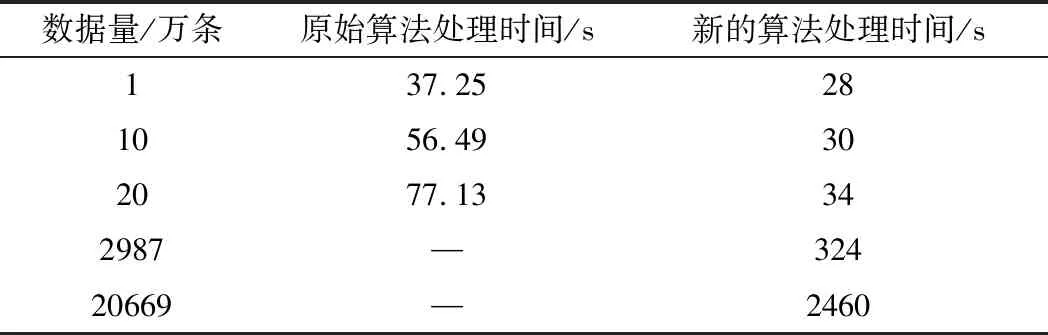
表3 新算法與原算法效率對比
3.3 并行度優化
在并行計算中,并行度對計算的效率有很大的影響,而Spark中分區數的選取決定并行度的大小。如果分區數過小,有的節點沒有分配到數據,會造成資源浪費。如果分區數目太大,計算過程中各分區之間的Shuffle很大,也會降低計算的效率。分區數由100到1000(步長為100),分別對同一天的軌跡數據進行地圖匹配,數據量大約為3000萬個軌跡點,占內存2 GB左右,實驗的運行時間測試結果如圖3所示。圖中橫軸代表分區數,縱軸代表運行時間。由圖中可以看到,當分區數為500時運行時間最短,運行時間為5.4 min,比最差的情況少用了38%的時間。由此可以看出分區的選取對于并行計算的效率影響很大,而不同數據規模最優分區數不同,在進行并行計算時可根據規模大小對分區數目做一些適當調整。
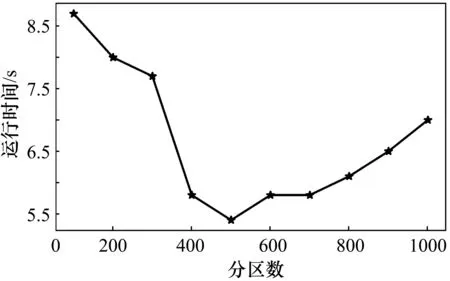
圖3 不同分區數的運行時間
3.4 規模增長性測試
隨著數據規模的增大,各個節點的負載會變大,而且節點之間的通信量也會變大,這時算法的性能會有所下降。因此,引入規模增長性這一指標,對規模增長引發的并行性能變化情況進行測試,如式(3)所示。
Sizeup(n)=Tn/T1
(3)
式中,T1為一天的數據量所需匹配時間;Tn為n天的數據所需匹配時間。
將1~7天規模的數據量分別測試運行時間,根據式(3)進行計算規模增長性,結果如圖4所示。顯然,隨著數據規模成倍的擴大,規模增長性接近線性增長,并行算法性能上并沒有太大的下降,穩定性比較高。
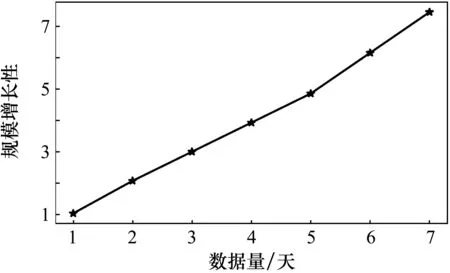
圖4 不同規模數據的運行時間
3.5 加速比測試
在并行計算中,加速比這一指標表示隨著節點數的增大,并行計算相對串行計算性能上的提高,如式(4)所示。
Speedup(p)=T1/Tp
(4)
式中,Speedup(p)為加速比;T1為單處理器下的運行時間;Tp為P臺處理器的運行時間。對不同節點數下,測試同一天軌跡數據的匹配時間。測試結果如圖5所示,橫軸代表使用節點數,左縱軸代表運行時間,右縱軸代表加速比。隨著節點的增加,運行時間下降,但下降的趨勢變慢;加速比在上升,但上升的趨勢趨于緩慢。這是由于節點數增加,節點之間的通信開銷增大。
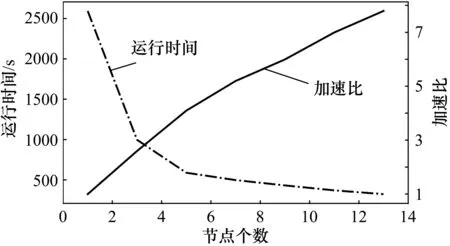
圖5 加速比測試
3.6 可擴展性測試
可擴展性由加速比產生,代表著算法性能隨著節點的增大而提高的能力,如式(5)所示。
Scaleup(p)=Speedup(p)/p
(5)
式中,Scaleup(p)為可擴展性;Scaleup(p)/p為節點數等于p時的加速比與節點數p的比值。測試結果如圖6所示。可見,隨著節點的增加,可擴展性在緩慢降低。
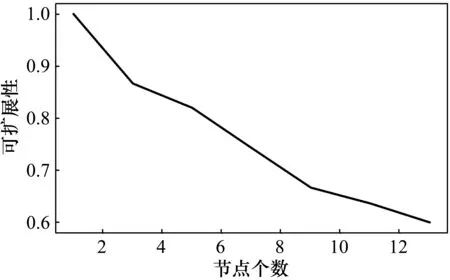
圖6 可擴展性測試
4 結束語
提出了一種基于大規模軌跡數據的并行化地圖匹配算法。在候選道路的選取中采用了一種基于GeoHash編碼的網格化地圖方法,將候選道路查詢的時間復雜度下降了一個量級。采用Spark平臺,實現了一種并行化的動態加權地圖匹配算法。經試驗測試,該算法可以短時間內完成大規模數據的地圖匹配任務,且穩定性高,具有良好的可擴展性。在很多真實應用場景下,地圖匹配需要具有實時性。因此,下一步的研究應該將批處理方式改進為流處理,使該算法得到更加廣泛的應用。
