基于LDA和GBDT算法的對文學(xué)作品愛國主義特征的分類研究
2019-06-18 11:44:54毛頻對外經(jīng)濟貿(mào)易大學(xué)外語學(xué)院北京100029
文化創(chuàng)新比較研究 2019年13期
毛頻(對外經(jīng)濟貿(mào)易大學(xué)外語學(xué)院,北京 100029)
愛國主義是社會主義核心價值觀,自古至今,愛國主義一直是文學(xué)作品中最重要、最能引起讀者共鳴的主題之一,可謂日月高懸,激勵了一代又一代的仁人志士,為了國家和民族的利益,毅然承擔起歷史賦予的重任,赴湯蹈火在所不惜,在中國歷史上留下了濃墨重彩的一幕又一幕。弘揚愛國主義,傳遞正能量是毋庸置疑的,因此所有相關(guān)媒體、平臺在推介文學(xué)作品時,價值取向是首先要面對的問題,優(yōu)先推薦愛國主義題材的佳作,淘汰宣揚分裂、背叛國家等思潮的不符合社會主義價值觀的作品。膾炙人口的現(xiàn)當代愛國主義小說有《紅日》《紅巖》等。進入當代消費社會,文學(xué)的互聯(lián)網(wǎng)化越來越成為當代文學(xué)創(chuàng)作和閱讀的重要特征。文學(xué)創(chuàng)作活動異常活躍,閱文等互聯(lián)網(wǎng)文學(xué)企業(yè)不斷產(chǎn)生發(fā)展,政府意識形態(tài)主管部門把控價值取向時,不可能對所有文學(xué)作品進行分析和判斷,文學(xué)企業(yè)在評價某個文學(xué)作品的特征時,也需要掌握文學(xué)作品本身的特點以及讀者對這部作品的感受。現(xiàn)在已經(jīng)進入大數(shù)據(jù)時代,隨著互聯(lián)網(wǎng)海量數(shù)據(jù)的產(chǎn)生,以及自然語言處理算法的不斷革新,使得使用機器學(xué)習技術(shù)處理自然語言成為可能[1],我們認為,對文學(xué)作品本身的文本以及用戶閱讀文學(xué)作品后的反饋進行量化分析,判斷該作品對讀者產(chǎn)生了怎樣的價值取向,該文以讀者是否產(chǎn)生愛國主義情感為例,進行分析研究。
1 概述
該任務(wù)本質(zhì)上是機器學(xué)習中的分類問題。分類問題屬有監(jiān)督學(xué)習,在離線的模型訓(xùn)練階段需要有標注的樣本集,樣本集可被分割為訓(xùn)練集、測試集、驗證集。樣本由多個特征構(gòu)成,其中有個特殊的特征被稱為目標特征,對應(yīng)的是人工標注的文學(xué)作品類標簽(愛國主義作品、反面題材作品、中性作品)。類標簽可以從官方對文學(xué)作品的定性來獲取,值得一提的是,愛國主義與反面題材作品占到了全部文學(xué)作品的小部分,大部分是中性題材的,因此在控制樣本比例時需要考慮這一點。樣本數(shù)據(jù)的其他特征可以通過自然語言理解技術(shù)中的Topic Model(如PLSA、LDA等)來抽取作品的關(guān)鍵詞及其權(quán)重來構(gòu)造。國內(nèi)已有部分學(xué)者使用LDA方法用于歷史研究[2],還有的成功運用于對海量微博話題進行主題抽取。對于待分析的新作品(閱讀量大、傳播范圍廣的),則可以使用GBDT算法,基于從讀者評論中抽取的特征來進行分類。
2 邏輯與算法原理
2.1 處理流程概述
處理流程分兩類:離線處理和在線預(yù)測。離線處理包括數(shù)據(jù)預(yù)處理(特征提取,構(gòu)造樣本集)和模型。在線預(yù)測指的是利用分類模型對沒有標簽的數(shù)據(jù)的愛國主義傾向進行預(yù)測,可以發(fā)現(xiàn)主題的演化內(nèi)容,超越了Blei等人的動態(tài)主題模型[3]。關(guān)鍵步驟包括數(shù)據(jù)預(yù)處理、離線訓(xùn)練和在線預(yù)測三部分。在數(shù)據(jù)預(yù)處理時,如果處理的是樣本集,輸出結(jié)果中目標特征值為(0,1,2),如果處理的是待預(yù)測實例,則不包含目標特征值。離線預(yù)測的訓(xùn)練集、測試集和驗證集都同時包含了愛國主義評論、負面評論和中性評論。
2.2 關(guān)鍵技術(shù)
文學(xué)作品愛國主義影響力分類算法涉及兩類關(guān)鍵技術(shù),它們分別是數(shù)據(jù)預(yù)處理涉及的特征提取和分類算法。前者主要涉及自然語言理解中的Topic Model技術(shù),該方案選擇了前沿的LDA模型(隱性狄利克雷分布模型)。后者主要涉及分類算法的構(gòu)造,該方案選擇了主流的GBDT算法。
2.2.1 LDA模型
LDA模型一種TopicModel,TopicModel即主題模型,顧名思義就是諸如一篇文章、一段話、一個句子所表達的中心思想。不過從統(tǒng)計角度來說是用一個特定的詞頻分布來刻畫主題的,并認為一篇文章、一段話、一個句子是從概率模型生成的,每個實體可能由若干個主題合成,主題概率之和為1。LDA本質(zhì)上是一個多重貝葉斯模型。假設(shè)我們有M篇文檔,對應(yīng)第d篇文檔中有Nd個詞。
模型的目標是找到每篇文檔的主題分布和每個主題中詞的概率分布。首先需要確定合成文檔的主題個數(shù),記作K,所有的分布基于K個主題展開。
LDA假設(shè)文檔主題的先驗分布滿足Dirichlet分布,即對于任一文檔d,其主題分布滿足θd:θd=Dirichlet),其中α為分布的超參數(shù),是一個K維向量。
LDA假設(shè)主題中詞的先驗分布分布也是Dirichlet分布,即對任一主題k,其詞分布βk為:βk=Dirichlet),η為分布的超參數(shù),是一個V維向量。V代表詞匯表的大小。
對于任意一篇文檔d中的第n個詞,主題分布θd的后驗分布為:
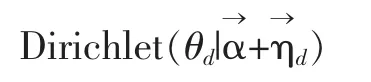
βk的后驗分布為:Dirichlet(βk)
由于主題詞產(chǎn)生不依賴具體某一個文檔,因此文檔主題分布和主題詞分布是獨立的。理解了上面這M+K組Dirichlet-multi共軛,就理解了LDA模型原理。
剩下的問題是,基于這個LDA模型如何求解我們想要的每一篇文檔的主題分布和每一個主題中詞的分布呢?一般有兩種方法,第一種是基于Gibbs采樣算法求解,第二種是基于變分推斷EM算法求解。
用我們的分類算法,可以將每部作品或該部作品的全部讀者評論看成一個文檔,主題數(shù)設(shè)置為1,那么就能抽取出該作品或讀者評論的主題詞及其權(quán)重。
2.2.2 GBDT算法
GBDT(Gradient Boosting Decision Tree)被稱為梯度提升決策樹,可用于回歸或分類。隨著深度學(xué)習的不斷發(fā)展,以其自動提取特征的優(yōu)勢被更多的應(yīng)用在關(guān)系抽取任務(wù)中。關(guān)系抽取可以看成是多分類問題,奠雨潔等人將GBDT用于微博立場檢測當中,通過對語料庫手動提取特征,完成文本分類[4]。
在GBDT的迭代中,假設(shè)前一輪迭代得到的強學(xué)習器是 ft-1(x),損失函數(shù)是 L(y,ft-1(x)),我們本輪迭代的目標是找到一個CART回歸樹模型的弱學(xué)習器ht(x),讓本輪的損失函數(shù) L(y,ft(x))=L(y,ft-1(x)+ht(x))最小。也就是說,本輪迭代找到?jīng)Q策樹,要讓樣本的損失盡量變得更小。
通過損失函數(shù)的負梯度來擬合,我們可以通過擬合損失誤差的辦法,這樣無論是分類問題還是回歸問題,都可以通過其損失函數(shù)的負梯度的擬合,就可以用GBDT來解決分類和回歸問題。區(qū)別僅僅在于損失函數(shù)不同導(dǎo)致的負梯度不同而已。
在我們的應(yīng)用中,實際上是多元(3個類標簽)GBDT分類算法,假設(shè)類別數(shù)為K=3,則此時對數(shù)似然損失函數(shù)為:
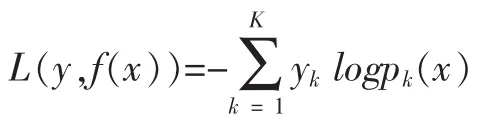
其中如果樣本輸出類別為k,則yk=1。第k類的概率 pk(x)的表達式為:
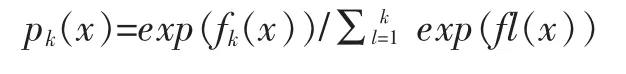
3 實證研究
《紅巖》這部小說以解放前夕“重慶中美合作所集中營”敵我斗爭為主線,展開了對當時國統(tǒng)區(qū)階級斗爭全貌的描寫。作品結(jié)構(gòu)錯綜復(fù)雜又富于變化,善于刻畫人物心理活動和烘托氣氛,語言樸實,筆調(diào)悲壯,被譽為革命的教科書。該書被中宣部、文化部、團中央命名為百部愛國主義教科書。該研究爬取了豆瓣網(wǎng)《紅巖》的讀者評論5199份,其中有文字的評論1480份,使用python3.6調(diào)用對LDA和GBDT算法編寫程序進行了測試。在運用LDA算法時,分別調(diào)用了NLTK,stop_words,gensim的python包,漢語分詞使用開源的中科院漢語詞法分析系統(tǒng)ICTCLAS,使用測試結(jié)果現(xiàn)實,對于讀者評論,刪除了停用詞、書名、人名、出版等與主題無關(guān)的詞。我們設(shè)定了愛國主義題材關(guān)鍵詞為六個,分別是:信仰,紅色,黨,革命,感動,英雄所占比例為46%。反面題材作品使用六個主題,關(guān)鍵詞分別為:洗腦、不真實、套路、文革、惡心、政治色彩,所占比例為12%,其余沒有這些關(guān)鍵詞的為中性評價,比例為42%。從讀者評論看,不少負面評論是閱讀結(jié)束以后,讀者感覺故事不真實而做出的評論,這表明讀者對同一作品在不同的時間閱讀,會有不同的感受,時間越長異樣的感受越明顯。
根據(jù)第一步LDA的主題模型計算結(jié)果,對每個讀者評論的每句話進行GBDT的三分類,有愛國主義題材關(guān)鍵詞的為句子賦值為1,有反面題材作品關(guān)鍵詞的句子賦值為-1,均沒有的賦值為0,仍然使用python語言,對數(shù)據(jù)進行GBDT分類,訓(xùn)練后的模型表達式為:pk(x)=exp(fk(x))/∑Kl=1exp(fl(x)),使用此式,隨機選擇100個的讀者評論句子進行了驗證,成功率為91%,說明可以判定大部分讀者的感受判定,基本實現(xiàn)了機器判定文學(xué)作品是否為愛國主義題材的目的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
創(chuàng)造(2020年6期)2020-11-20 05:58:40
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中國火炬(2014年7期)2014-07-24 14:21:22
