油氣上游領域智能化發展方向探析
2019-02-27 16:13:44鹿牛志杰石國偉李嗣旭林道壽
石油科技論壇 2019年6期
關鍵詞:智能化
賈 鹿牛志杰石國偉李嗣旭林道壽
(1.中國石油新疆油田公司數據公司信息研究所;2.中國石油新疆油田公司勘探開發研究院勘探所;3.中國石油新疆油田公司數據公司;4.北京嘉和無限科技有限公司)
1 國內外油田智能化應用現狀
國際石油公司在大數據分析與智能化應用方面做了許多探索性工作,但資料顯示,主要在下游領域應用比較多,在油氣勘探與生產上游領域應用相對較少。上游領域主要用在一些自動化采集比較完善的油田生產領域,如抽油機診斷及維護、少數生產智能井等,再有就是油田技術服務領域,如鉆井、測井等,而在一些綜合性研究領域還少有先例。這是因為上游領域專業多,不同專業數據類型不同、數據量級差別大,且缺乏關聯性,因而難以實現綜合分析。比如,地震數據和鉆井數據就無法做關聯分析,因為二者的數據類型和性質完全不同,前者是非結構化數據,后者是結構化數據[1-3]。
近年,國內石油公司在大數據分析與智能化應用方面做了一些探索,主要也是在下游領域(如智能工廠、智能加油站等方面)。從2010年開始,IBM先后為中國石油天然氣集團有限公司(簡稱中國石油)和中國石油化工集團有限公司(簡稱中國石化)做了智能油田總體規劃設計,但實質性進展并不大。阿里巴巴也曾與中國石油開展過合作,在智能加油站方面做了一些嘗試,由于缺乏相關專業人才,無法取得突破,最終退出石油行業大數據分析與智能化應用市場。
究其原因,IBM、阿里巴巴缺乏精通石油上游業務知識的AI 專家,在給中國石油和中國石化做的智能油田總體規劃設計中,只是從綜合業務角度著手,而不能從專業角度進行設計。正確理解油氣大數據分析與油田智能化應用,首先要從油氣大數據構成分析入手,這是油氣大數據分析與油田智能化應用的方向。
2 油氣大數據構成分析
人工智能的本質是統計學,要研究油氣智能化應用方向,應該從其大數據構成分析入手,這是油氣領域智能化應用的基礎和前提。下面從3個角度分析油氣大數據的構成。
2.1 業務角度
從業務角度看數據,根據油氣勘探開發價值鏈理論,可把油氣勘探開發劃分為幾大業務:油氣勘探、油藏評價、油氣開發、油氣生產、油氣儲運(圖1)。但是這種分類范圍太大,而且每個業務中都包含相同的專業內容,如油氣勘探、油藏評價與油氣開發業務都包含物探、鉆井、測井等數據。所以,這種業務劃分標準不能作為數據的劃分標準,但不同業務中的共同專業內容,則是實現業務組件服務化軟件工程開發的基礎,也是人工智能綜合應用的大方向[4-6]。
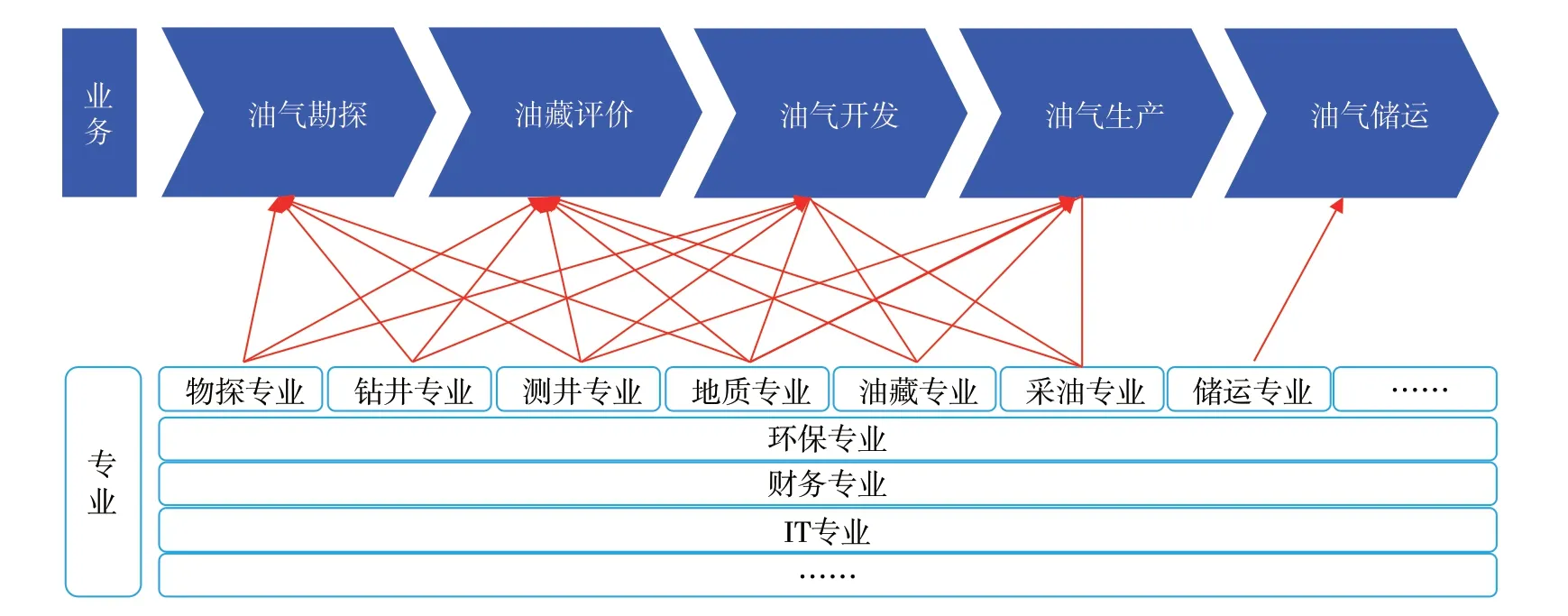
圖1石油業務與石油專業區別與關系
2.2 專業角度

圖2按專業的石油數據分類
如上所述,一項業務包含多個專業,從專業角度劃分數據類型應是數據分類的基礎。根據石油專業類型和大數據特征,可以把油氣大數據劃分為9大類(圖2)。其中,隨鉆錄井數據、地震數據、測井數據、生產井史數據、實時生產數據(包括實時地面工程數據)符合典型大數據特征,比較容易實現大數據分析和人工智能應用。因此,這幾個專業領域是智能化發展的重點方向。
2.3 數據類型角度
按照結構化數據和非結構化數據、重復型數據和非重復型數據分類方法,油氣大數據可以劃分為業務相關大數據、潛在相關大數據、業務不相關大數據。業務相關大數據是分析重點,潛在相關大數據是關注的對象,業務不相關大數據基本不用管它。這樣就避免了大數據分析的盲目性(圖3)。從狹義上講,非結構化數據屬于大數據范疇;廣義上,結構化數據多了就是大數據,因符合大數據量大這個第一特征[7-9]。
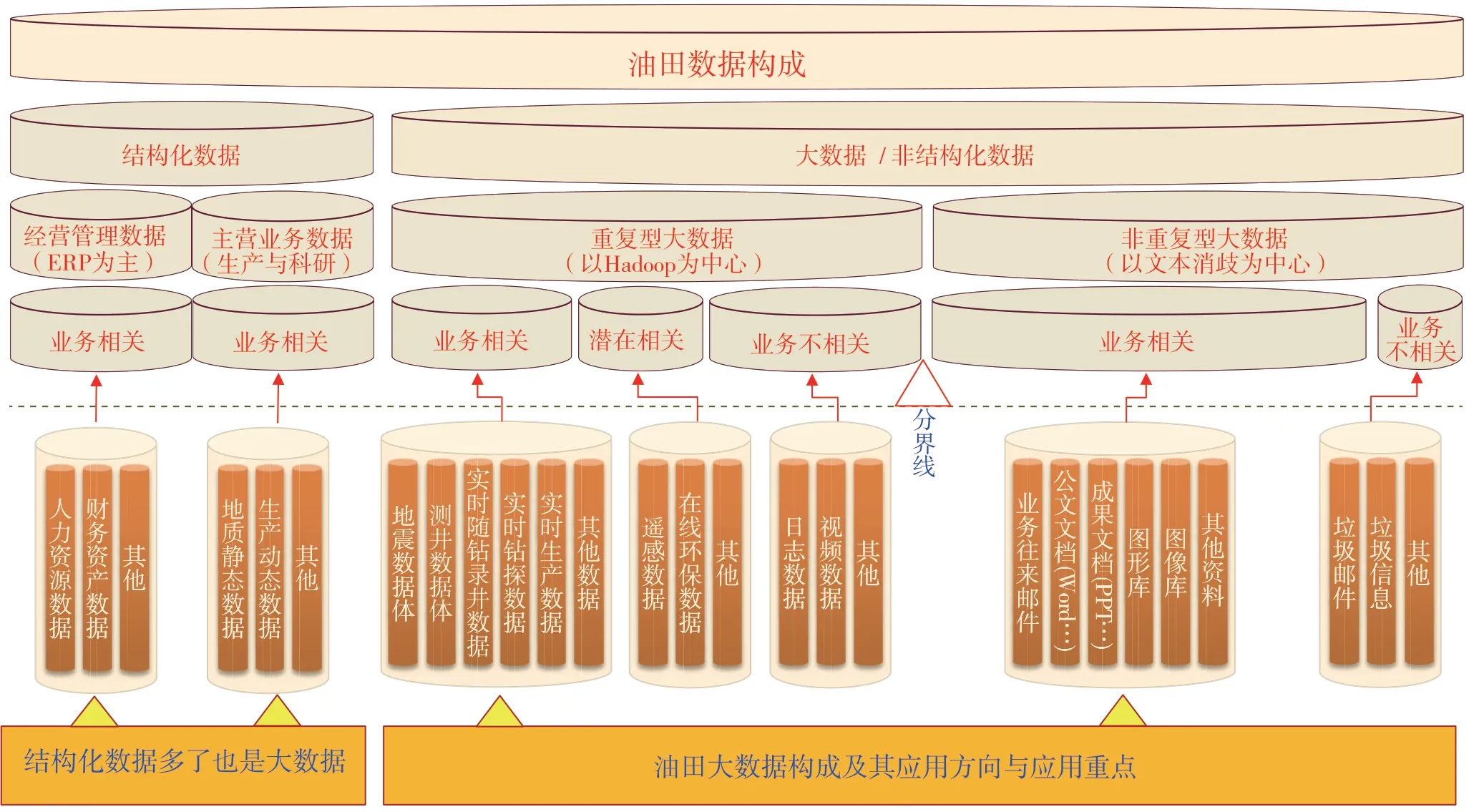
圖3 按數據類型的石油大數據構成分類
當然,業務相關或不相關不是絕對的。比如視頻數據,從油氣專業來看,屬于業務不相關,但從安全管理角度來說,又屬于業務相關。業務相關的重復型大數據主要有:地震數據、測井數據、實時鉆錄井數據、實時生產數據等。這些領域的數據也是大數據分析與智能化應用比較容易實現的領域。
3 油氣上游不同專業領域智能化應用發 展方向
石油各專業是產生數據的來源,既是大數據構成的基礎,也是智能化應用的方向。因此,油氣大數據分析與智能化(AI)應用的方向應該從專業領域去尋找;不要企圖在整個業務系統實現智能化,而應該衡量AI
在其中的貢獻率。根據大數據構成分析,油氣領域智能化發展方向主要包括以下5個領域。
3.1 物探專業
地震數據是油田重要的數據資產之一,地震數據體(文件形式存在)是典型的重復型大數據,資料比較完整,比較適合做大數據分析和人工智能應用。
從地震工作的三大步驟來看,地震資料解釋、地質反演與儲層預測是地震專業的智能化應用重點方向(圖4);地震資料應用大數據技術進行處理,可以提高數據的處理效率;地震數據采集的視頻資料可以進行智能化分析,如基于深度神經網絡的圖像資料識別,來判斷地震數據采集過程的規范化和正確性[10]。

圖4物探專業工作流程
3.2 測井專業
測井資料也是油田重要的數據資產之一,資料最為完整齊全,主要包括測井數據體(文件形式)和測井解釋成果數據。測井數據體是典型的重復型大數據,測井解釋成果數據是結構化的數據(圖5)。測井解釋是智能化應用的重點方向,因為測井解釋的四性關系本身就是依據統計學原理。其中,巖性解釋、物性解釋、含油氣性解釋,都有現成數據,不需要進行人工標注,最容易開展人工智能應用。

圖5測井專業工作流程
3.3 鉆錄井專業
鉆井工程數據采集主要來自隨鉆錄井。從錄井工作流程分析看(圖6),錄井資料解釋比較適合開展智能化應用,特別是隨著物聯網技術的普及應用,實時隨鉆錄井成為鉆井工程智能化應用的一個主要方向。
錄井數據的智能化應用方向主要有兩方面:一是常規錄井資料地球化學解釋、綜合解釋的智能化應用;二是實時隨鉆錄井資料的實時智能化解釋與預測預警,如實時隨鉆氣測數據的實時智能解釋、實時隨鉆工程錄井數據的實時展示與實時智能預警。

3.4 油氣生產領域
油氣生產領域智能化應用的方向是油田地質與采油工程一體化智能分析。在油氣生產領域,存在油田地質與采油工程專業各自為政的現象,兩類數據未能共享。而把油田地質數據與采油工程數據進行關聯建模,挖掘地下、地面數據之間可能存在的規律,是油氣生產智能化應用的最大潛力。
近年來隨著物聯網應用的逐步普及,中國石油、中國石化、中國海油普遍實施了實時生產數據的智能化采集,為實時生產數據的大數據分析和智能化應用創造了條件。根據實時工程數據、實時測試數據、實時計量數據表,可以進行關聯分析與建模的智能化應用,建立井底實時動液面(或井底流壓)數據、實時產液量數據和實時工程數據的關系模型(表1、圖7)。

表1油田實時油氣生產大數據分析與預測關聯數據表
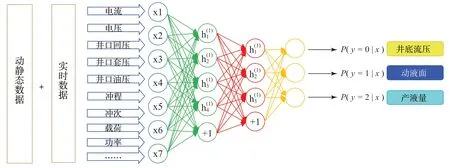
圖7基于深度學習算法建立油田地質數據與采油工程數據關系模型
3.5 油藏模擬領域
油藏模擬是油田開發和油氣生產動態分析的常用手段。常規油藏模擬軟件基于工程數學算法(如滲流力學算法),這些算法普遍存在局限性,為了提高油藏模擬的準確性,采用人工智能算法是一個重要的突破方向。
油田生產井史數據是油田的重要資產數據之一。數據比較全面完整,還是結構化數據,比較適合于進行大數據分析和智能化應用。基于井史數據的油藏歷史擬合與預測是一個可行的智能化應用方向。
4 油氣綜合研究領域智能化應用探索
前文所述,智能化應用在單一個體或專業領域比較容易做到,在綜合研究領域則很難實現,因為綜合研究領域涉及各種專業數據,數據間缺乏關聯性,數量級差別巨大,很難進行關聯分析和建模。
針對綜合研究領域的智能化應用,我們通過“基于大數據的勘探有利目標區優選新方法研究”,獨創了一套多專業、多學科的綜合業務智能化分析方法,克服了多專業數據無法進行關聯分析和建模的難題,對未來多學科領域智能化研究具有先導意義;獨創了一套勘探有利目標區的標注規則和自動標注方法,解決了目標變量需人工標注時工作量巨大的難題,實現了有利目標區的自動分級、可視化展示、查詢等功能。這項研究提供了一種新的勘探有利目標區優選輔助手段,可大幅提高勘探研究人員工作效率,并可能提高勘探準確率。
4.1 建模思路
按各專業數據分別建模,然后相互驗證。由于多專業數據組合無法建模,本研究采取各專業數據單獨建模方式,即錄井、測井、試油、化驗4個專業的數據表單獨建模,然后再用這4 種建模結果互相驗證,準確率均超過90%,取得了綜合業務智能化分析的良好效果(圖8)。
根據這種設計思想,即使只有一種數據,也可以初步得出勘探有利目標區的優選模型。在資料不完整的情況下,就可以利用個別種類的建模結果初步做出預測,4種資料齊全,就可以對4 種建模結果相互驗證。
4.2 算法選擇
對機器學習算法進行宏觀分類(圖9),然后根據不同的業務需求,選擇不同類別的算法(如回歸算法、分類算法、聚類算法)。本研究通過多種回歸算法和分類算法的大量計算對比,發現分類算法比回歸算法更適合有利目標區優選分析,因此選擇采用5種分類算法(圖9中綠色框部分)作為有利目標區優選的分析算法,再從5種算法中推薦準確率最高的一種算法作為最終建模算法。

圖9機器學習算法分類
根據實際模型訓練結果,以上5種分類算法模型訓練結果的準確率比較接近,都達到90%以上,邏輯回歸算法準確率相對最高(超96%)。這里僅對邏輯回歸算法(LR)做簡要介紹,其他算法不再逐一介紹。
邏輯回歸是經典的二分類算法,也可用于多分類算法。邏輯回歸本質上是線性回歸,只是邏輯回歸使用一個函數來歸一化y值,使y的取值在區間(0,1)內。這個函數稱為邏輯函數、S型函數。邏輯回歸常用于疾病自動診斷、經濟預測等領域。
4.3 技術架構
WEB后端由數據庫、大數據框架、WEB服務器和Java 框架組合。大數據開發基于Spark MLBase的機器學習系統;Java 開發基于IBM Websphere 8.5集成開發平臺,WEB服務器可配置成Tomcat;JPS框架采用Spring、mybatis、ehcache、shiro組合框架。WEB前端采用Jquery +Bootstrap +Echarts組合框架,前后端分離部署與開發,WEB前后端總體技術架構見圖10。

圖10勘探有利選區優選分析系統WEB前后端總體技術架構
4.4 最終成果
根據以上設計,研發的基于大數據分析平臺的“勘探有利目標區優選智能分析系統”,可以實現報表方式查詢、分級方式查詢、垂直剖面查詢、平面展布查詢及新數據預測等功能(圖11)。系統使用方便直觀,大幅提高了用戶工作效率,如老井復查可以提高效率幾十倍甚至上百倍。
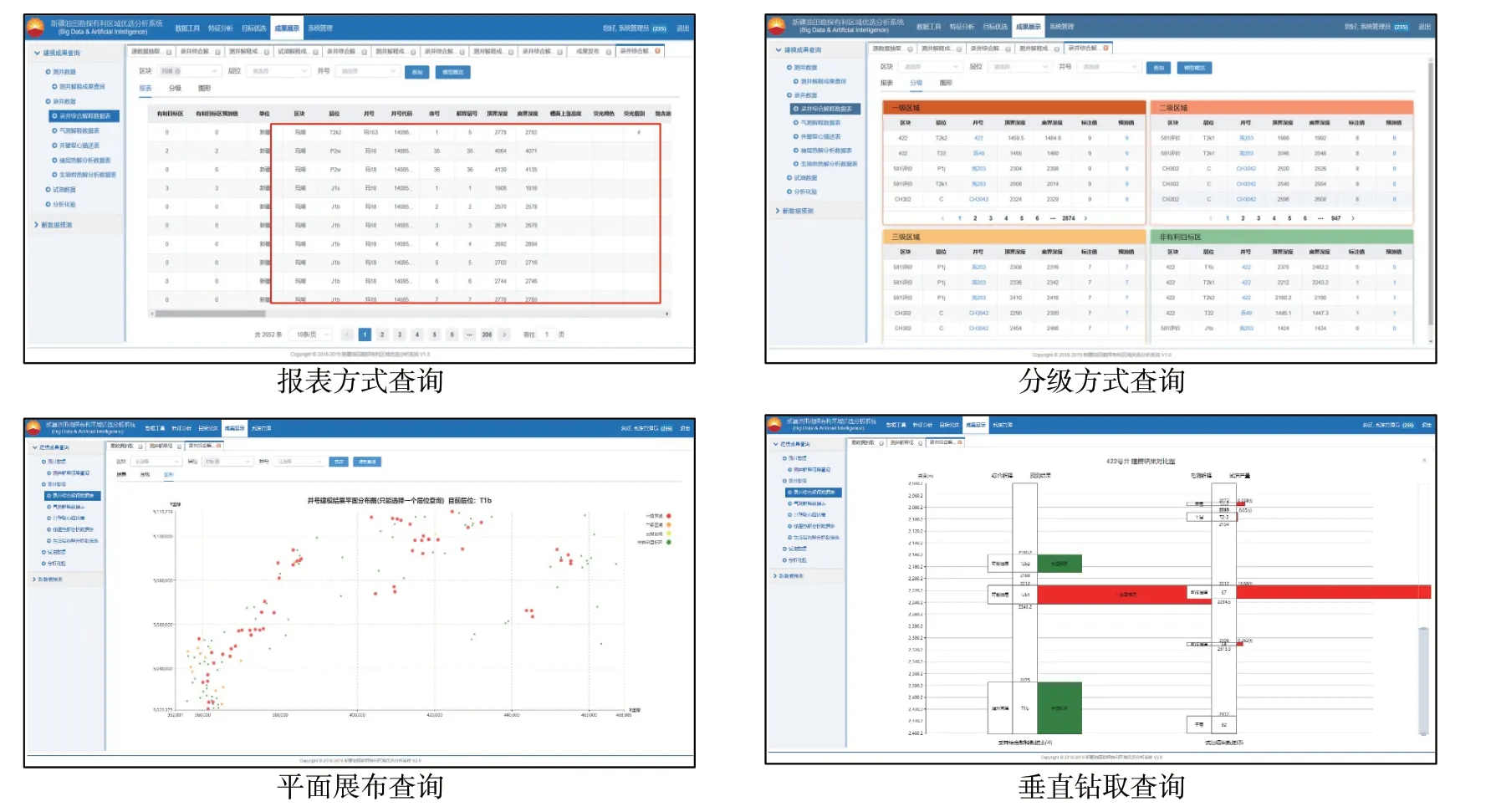
圖11勘探有利目標區優選智能分析系統成果
4.5 系統優勢與創新點
勘探有利目標區優選智能分析系統為全流程閉環設計,自動形成了數據準備—特征分析—模型訓練—成果查詢—新數據預測的反復循環(圖12)。通常地質研究工作有1/3甚至1/2 時間要花在準備數據上,該
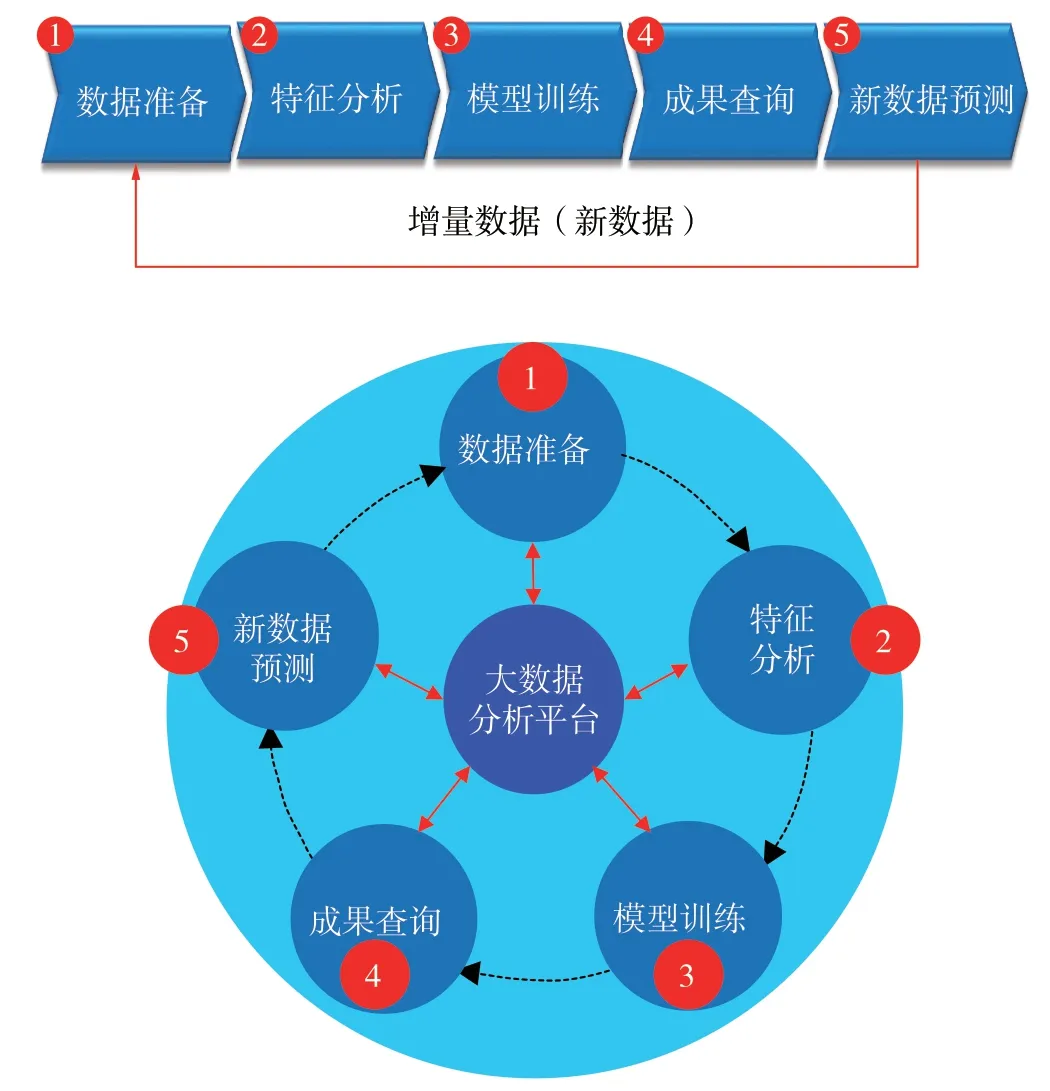
圖12系統全流程閉環設計
系統可大量節省用戶的數據準備時間,而且數據可做到增量疊加循環建模,有助于不斷提高模型的準確率。
有利目標區標注是該系統的難點之一,也是創新點所在。發明設計的有利目標區(YLMBQ)標注規則和自動標注方法,解決了人工標注工作量巨大的難題,為將來無目標變量字段的大數據項目積累了一定經驗(圖13)。目前,該發明正在申請專利中。
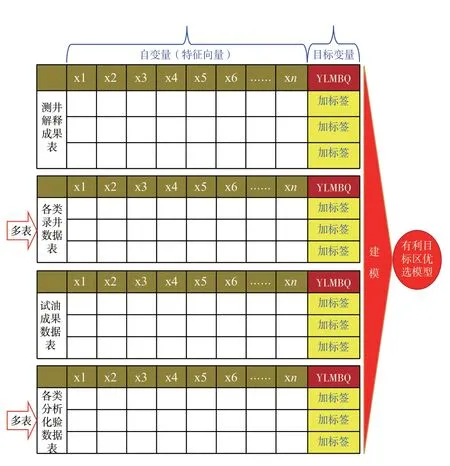
圖13有利目標區優選目標變量標注
5 結束語
從“企業信息化”到“信息化企業”的演進,是衡量IT 在企業中的應用程度;從“信息化企業”到“智能化企業”的演進,是衡量AI在信息化中的貢獻率。“智能化”是點上的應用,“信息化”屬于整體應用。人工智能在單一個體或專業領域比較容易實現,但在綜合分析領域如管理咨詢、綜合地質研究則很難實現。油氣大數據分析與智能化的應用方向應從專業領域去尋找,不要企圖整個業務系統實現智能化,應衡量AI在其中的貢獻率。
大數據是人工智能的基石,做好數據標準化工作,是人工智能應用的前提。不要被數據湖、大數據、人工智能、機器學習、深度學習等一些表面的技術術語所迷惑,不要對人工智能抱有過高的期望,要深刻領會人工智能的本質是統計學。對人工智能的本質認識及其在行業應用的方向性探析非常重要!
猜你喜歡
軍事文摘(2022年19期)2022-10-18 02:41:14
建材發展導向(2021年13期)2021-07-28 07:14:34
建材發展導向(2021年10期)2021-07-16 07:13:24
印刷工業(2020年4期)2020-10-27 02:46:02
印刷工業(2020年4期)2020-10-27 02:45:52
中國儲運(2019年5期)2019-05-15 09:37:40
能源(2018年10期)2018-12-08 08:02:52
汽車觀察(2018年10期)2018-11-06 07:05:08
中國交通信息化(2017年4期)2017-06-06 07:21:52
中國公路(2017年12期)2017-02-06 03:07:25
