基于Python的招聘數據爬蟲設計與實現
2019-02-07 05:32:15常逢佳李宗花文靜常逢錦
軟件導刊 2019年12期
關鍵詞:數據分析
常逢佳 李宗花 文靜 常逢錦

摘要:隨著就業壓力日漸增加,準確全面地獲取數據可以幫助高校學生規避就業風險、正確認識自身價值,具有相當重要的研究價值。基于Python的網絡動態招聘數據抓取方案利用requests庫抓取Ajax異步請求多頁數據源,抓取的內容更為全面;對抓取到的招聘數據進行統計分析,對多線程效率進行對比分析,顯示爬蟲具有良好的適應性。該方案抓取的網絡資訊在科研、求職等方面具有一定實用價值。
關鍵詞:網絡爬蟲;招聘;Python;數據分析
DOI:10.11907/rjd k.191156
中圖分類號:TP312 文獻標識碼:A 文章編號:1672-7800(2019)012-0130-04
0引言
據北大青鳥統計,2019年高校應屆畢業生人數高達834萬,再加上中專技校、往屆畢業生、海外留學人員等,預計超過1500萬人求職,形成了巨大的就業壓力,畢業生就業問題成為社會關注焦點。
同時,隨著海量信息的涌現和信息技術的不斷進步,網絡招聘廣泛出現在各種網絡信息中,但大量招聘網站真假難辨,高校畢業生難以在眾多職位信息中作出正確選擇。目前,互聯網上存在許多同類招聘網站,表1列出目前比較規范的求職網站。但是現有招聘網站大部分是各類企業面向整個社會在互聯網上發布職位信息,其數量龐大,信息結構復雜,求職者很難在大量職位中找到適合自己的職位,導致有時企業招不到人才,而求職者無法找到合適崗位。
黃貴斌等介紹了幾種采用聚類算法將學生、企業進行分類的方法,但是在職位推薦功能中,沒有采用實際招聘職位,并且數據量小,分析學生和企業真實歷史數據的可行性較低。因此,對于就業推薦系統,招聘數據時效性和真實性十分關鍵。若能準確抓取招聘數據并深入分析與挖掘,可實現對大學生就業方向的有效預測與引導。
因此,本文通過分析拉鉤網招聘信息的存儲方式進行關鍵數據的獲取研究,以Python為技術基礎進行開發,綜合運用多個Python網絡函數庫,從中獲取公司名稱、地區、職位名稱、工作年限、工資、公司資質、公司規模、福利等信息,最后將數據保存到Excel電子表格中,以便統計分析和為后期就業推薦系統開發提供數據。
1爬蟲技術概述
目前,獲取招聘信息最主要途徑是通過搜索引擎,其最核心構件是網絡爬蟲,若無該技術后繼工作將無法開展。網絡爬蟲又稱網頁蜘蛛、網絡機器人,是一種按照一定規則,自動抓取萬維網數據信息的程序。如果把萬維網比作一張大網,則爬蟲技術就是網上的蜘蛛,若將網絡節點比作網頁,這個“蜘蛛”爬到何處就等于訪問了哪個網頁,獲得了相應信息;而后可順著這些節點繼續爬到下一個節點,這樣整個網的所有節點便被這個“小蜘蛛”全部爬到。而搜索引擎就是將“小蜘蛛”爬取到的數據以一定策略進行處理,并為用戶提供服務,從而達到信息檢索的目的。
1.1Python爬蟲
Python是一款開源的、可以運行在任何主流操作系統中的解釋性高級程序設計語言。選擇Python作為實現招聘信息爬蟲的語言主要考慮如下:
(1)開發效率高。因為爬蟲的具體代碼需要根據不同的網站進行修改,Python方便、簡單的語法可以高效地節省開發時間及成本。
(2)Python爬取網頁文檔的接口更簡潔。Python為爬蟲開發提供了如urllib、urllib2等豐富的第三方庫。爬蟲程序可以模擬瀏覽器訪問網站的流程,得到網站所有HTML數據,比其它語言(c、c++、Java)更方便、快捷。
(3)網頁爬取后的數據可以是結構化數據,如XML和JSON等;也可以是非結構化的數據,如辦公文檔、文本、HTML、圖像等。Python支持一些解析技術,包括正則表達式、Xpath、Beautiful Soup等,如果返回的是HTML格式的數據,則可使用lxml庫解析網頁,通過節點提取等一些常規方法,提取出真正需要的數據。如果返回的是JSON格式的數據,則可通過JSON解析獲取數據。
1.2通用爬蟲流程
通常可以按照不同的維度對網絡爬蟲進行分類,例如,按照使用場景,可將爬蟲分為通用爬蟲和聚焦爬蟲;按照爬取形式,可分為累計式爬蟲和增量式爬蟲;按照爬取數據的存取方式,可分為表層爬蟲和深層爬蟲。在實際應用中,網絡爬蟲系統通常由幾種爬蟲技術結合實現。
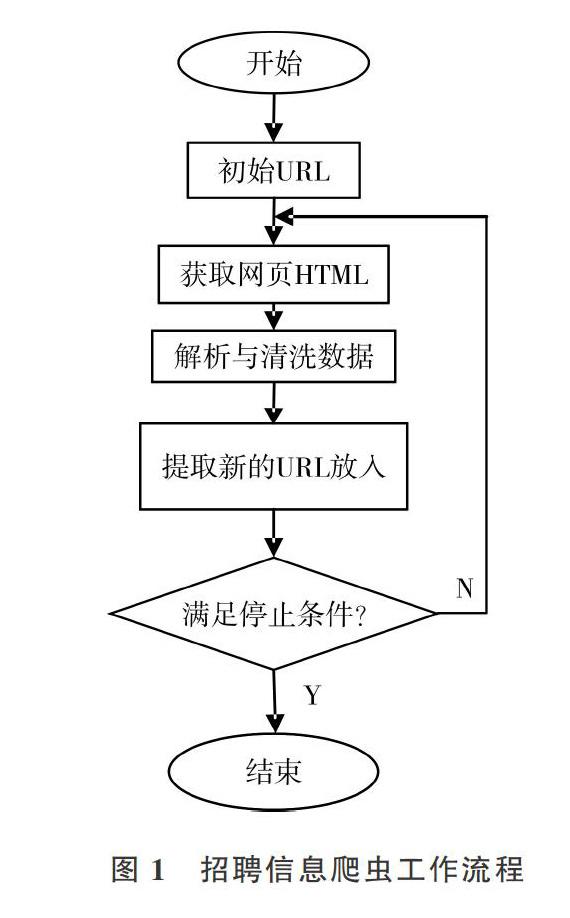
招聘信息爬蟲是一個自動提取網頁的程序,基本工作流程包括:①選取一個或若干個初始網頁的URL;②由網頁下載模塊獲取URL對應網頁的HTML,傳遞給數據解析模塊之后,將URL放進已爬取URL隊列;③數據解析模塊解析收到的HTML,查找標簽,提取出標簽所需數據,傳遞至數據清洗模塊,經提取后將URL傳遞至URL調度模塊;④調度模塊收到解析模塊傳遞過來的URL后,將其和已抓取的URL隊列對比,進行去重處理,篩選出未爬取的URL再放人待爬取URL隊列;⑤網絡爬蟲系統在第②一④步循環,直到待爬取隊列中的URL全部爬取完畢,或者用戶終止進程;⑥數據清洗模塊發現并糾正數據文件中可識別的錯誤,最終將數據存人數據庫或Excel表格中。但是,上述爬取行為需要遵循如標注為nofollow的鏈接或Robots協議等內容。
2網絡爬蟲案例實現
拉鉤網是國內著名的招聘網站,求職者可以通過官方網站提供的信息了解公司概況、崗位需求信息等。為了能夠準確地從海量招聘信息中獲取想要的數據,本文針對拉鉤網招聘信息特征設計爬蟲案例,使用爬蟲工具專門爬取招聘數據,供后期數據分析。
2.1數據分析
首先利用Chrome瀏覽器打開拉鉤網主頁(https://www.1agou.com),在搜索框中輸入職位關鍵字,例如“java開發工程師”,所有與職位相關的信息即被列出,這些信息是待爬取的數據。
右擊招聘職位空白處,選擇“檢查”選項,進入源代碼調試窗口,并定位到其對應的標簽位置,在
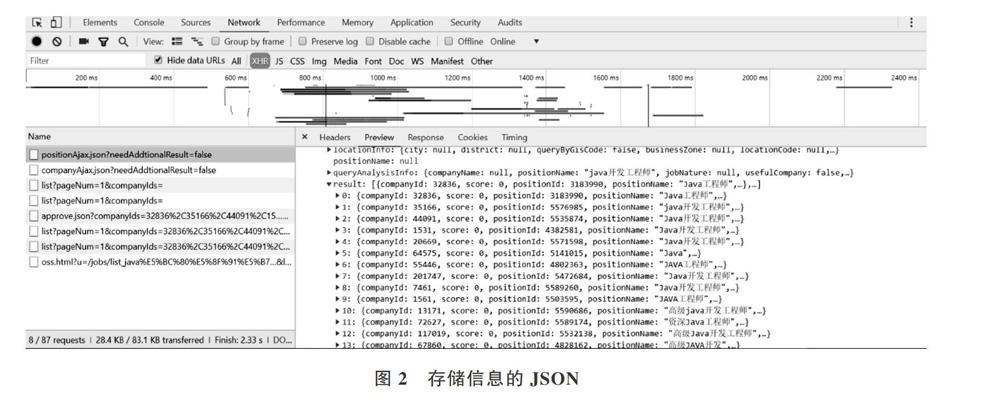
- 標簽中保留一條完整的職位信息。通過data-index屬性表明每一頁最多可顯示15條檢索的職位信息。利用network選項卡中XHR(ajax異步請求顯示結果)查看positionAjax.json條目,存取的每一頁中15條職位詳細信息如圖2所示。觀察JSON數據,該處選取鍵值名稱分別為companyFullName、district、positionN ame、work Y ear、salary、iinanceStage、compa-nySize、industryField、companyLabelList,分別對應公司名稱、地區、職位名稱、工作年限、工資、公司資質、公司規模、所屬類別、福利等含義。經過上述觀察分析,這些鍵值是待爬取數據。
在開發庫選取中,Python中的第三方庫requests庫是基于Python開發的http庫,它在Urllib庫基礎上進行了高度封裝,不僅可重復讀取返回的數據,還可自動確定相應內容的編碼,減少大量工作且使用方便。
2.2爬取流程
爬取的數據主要以JSON格式進行存取,因此爬取流程主要分為如下步驟完成。
(1)利用requests庫中的request(‘GET,url,headers=headers).ison()獲得response對象。
一些請求如果不是從瀏覽器發出,則無法獲得相應內容,所以爬蟲程序需要偽裝成一個從瀏覽器發出的請求。即在發送Request請求時,加入特定的headers,在爬取拉勾網招聘信息時,傳遞url同時,必須傳遞偽裝瀏覽器發送請求的headers頭。
Referer字段也被用作防盜鏈,即下載時,判斷來源地址是不是在網站域名之內,否則無法下載或顯示。拉鉤網在header中必須攜帶Referer字段。同時,由于請求以get方式發送,當傳遞的URL中包含中文或者其它特殊字符(例如,空格或‘/等)時,需要利用urllib.parse.urlencode()方法將中文參數進行編碼。它可以將key:value這樣的鍵值對轉換成“key=value”的形式。為了增加爬取程序的通用性,利用input接收用戶輸入需要爬取的職位名稱,并利用split(‘=)[1]進行切割。完成上述功能后定義get_page(url,headers)函數,返回response對象。
(2)將response對象返回的數據進行分頁爬取。在獲取的response對象中包含每一頁最多15個招牌信息,如圖3所示。
2.3相關問題
在測試過程中,為盡量使程序面對各種問題時仍能正常運行,本文對爬蟲細節進行如下設置。
(1)為了防止因頻繁訪問而被網站封鎖,本文爬蟲設置了隨機時間間隔。根據實驗結果,將間隔設置為0.5~2s。
(2)設計了斷點記錄功能。在獲取職位列表和詳細資訊內容的同時,將正在爬取的地址和其在職位列表中的位置保存起來。爬蟲重新啟動時,根據斷點位置繼續運行,無需從頭開始,該功能可節省大量時間。
(3)采用多線程爬取數據技術,效率可大幅提高。
(4)拉鉤網采取反爬取技術,若同一個IP反復爬取同一個網頁,很可能被封,因此設置代理IP池。
3結果分析
在爬蟲效率測試中,分別使用不同的線程數量進行測試,測試數據如表2所示。為了節省爬取時間,將爬取搜索職位頁面設置為3頁。
從測試結果可以看出,線程數量從1分別變化為2、3時,爬取速度均有明顯提升。線程數量上升到4時,系統為了維護各個線程需要分配出一定資源;同時考慮到網絡帶寬等因素,增加線程對爬蟲速度已無明顯影響。因此,多線程技術的使用需要考慮機器性能、網絡帶寬等各種因素。
4結語
本文以爬取拉鉤網招聘數據為例,介紹了一種爬取招聘數據的爬蟲程序設計。面對復雜的網絡,本文爬蟲設計方法仍存在一些問題,有進一步優化的空間。例如:爬取數據較多時,速度較慢,可以通過緩存與多進程技術再次提升爬蟲效率,建立分布式爬蟲應對海量數據。本文爬蟲工具的實現為后續研究工作奠定了一定基礎。
猜你喜歡
體育時空(2016年8期)2016-10-25 18:02:39
現代經濟信息(2016年19期)2016-10-20 17:46:29
中國科技博覽(2016年18期)2016-10-19 10:30:11
中國市場(2016年36期)2016-10-19 04:31:23
商場現代化(2016年22期)2016-10-18 19:11:00
科技視界(2016年22期)2016-10-18 14:37:36
