改進哈希編碼加權排序的圖像檢索算法*
2018-09-11 02:12:38郭呈呈于鳳芹
傳感器與微系統 2018年9期
關鍵詞:排序
郭呈呈, 于鳳芹, 陳 瑩
(江南大學 物聯網工程學院,江蘇 無錫 214122)
0 引 言
為了提高局部敏感哈希[1,2](locality sensitive Hashing,LSH)編碼效率,提出了許多生成緊湊哈希編碼的方法[3~7],但由于哈希編碼是離散的且受編碼長度的限制,因此,在檢索時查詢圖像與許多圖像數據間的漢明距離是相同的,難以根據距離排序來判斷這些圖像與查詢圖像間的相似性。為了解決該問題,可以對各個哈希比特位進行加權處理,Zhang X等人[8]沒有將查詢數據壓縮到二值哈希編碼,從而減少了信息的損失。Jiang Y G等人[9]根據預定義的類別標簽,為不同類別圖像學習不同的比特位權重,但算法受類別標簽數量限制,適用性較差。Zhang L等人[10]提出了加權漢明距離排序(weighted Hamming distance ranking, WHRank)算法,但該方法十分依賴數據分布假設。Liu X L等人[11,12]提出了哈希編碼加權排序(query-adaptive Hash code ranking,QRank)算法,克服了上述加權方法適用性差的問題,然而由于QRank在計算比特位權重時利用隨機采樣的方法選取采樣子集,導致數據分布特性丟失,權重分配不符合實際情況,檢索精度下降。
針對上述問題,本文提出了一種改進的哈希編碼加權排序圖像檢索算法,與現有的比特位加權算法相比,本文主要有兩點改進:1)利用數據依賴差異[13]的思想對圖像數據集采樣,得到一個保留數據分布特性的采樣子集,利用該采樣子集計算各個比特位權重,提高檢索精度;2)提出了一種由粗到細的圖像最近鄰檢索策略:采用哈希方法將圖像特征映射成二值哈希編碼;計算哈希比特位權重,對哈希編碼進行加權漢明距離排序,返回一個查詢圖像的候選最近鄰集合;對候選最近鄰集合中的圖像數據進行主成分分析(principal component analysis,PCA)映射,計算每幅候選圖像的排序得分,根據得分重新排序來進一步提高檢索精度,完成查詢圖像的最近鄰檢索。
1 改進哈希編碼排序圖像檢索的基本原理
1.1 數據依賴差異的基本原理
基本思想是兩個數據在樣本密集區域的差異性較大,在樣本稀疏區域的差異性較小,也就是數據依賴差異與數據的分布有關。定義一個能同時覆蓋樣本數據x和y的最小區域
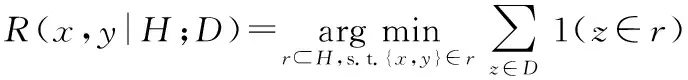
(1)
式中 1(·)為指示函數,D為樣本數據,H∈H(D)為一個分割模型,將空間分割成若干個不重疊且非空的區域。
1)構造一個包含t個隨機樹的隨機森林作為分割結構R,每個隨機樹都根據數據集D的一個子集構建得到,通過遍歷樹的方式記錄數據的分布信息;
2)找到包含數據x,y的所有t個分割R(x,y|Hi),計算數據依賴差異
(2)
3)利用數據依賴差異代替基本的歐氏距離度量對數據集進行聚類,根據每個類別數據的數量占總數的比重,對其進行采樣,共取ns個數據作為采樣子集。
1.2 由粗到細的圖像最近鄰檢索算法
1.2.1 生成短哈希編碼
采用哈希方法生成較短的哈希碼,假設給定一個包含n個d維數據點的數據集X={xi∈Rd,i=1,…,n)和m個哈希函數H(·)={h1(·),…,hm(·)},每個樣本數據xi均被第k個哈希函數編碼成哈希比特yik=hk(xi)∈{-1,1},其中哈希編碼函數定義為
hk(x)=thr(wkx)
(3)
式中wk為超平面參數的列向量。二值編碼通過符號函數y(x)=sgn(f)(如果f>0,那么y=1;否則,y=-1)獲得,數據的編碼過程為Y=sgn(WX)。
1.2.2 改進的加權漢明距離排序方法
對于一個查詢數據q,若一個哈希函數可以較好的保存其最近鄰集NN(q),則該函數對應的哈希比特位在加權漢明距離中應體現出更重要的作用,應賦予其更大的權重。基于哈希函數的近鄰保存能力,可以根據譜嵌入損失[4]定義權重
(4)
1)找到查詢的最近鄰集NN(q)。針對文獻[12]利用隨機采樣的方法,獲取的數據不穩定,不能保留數據的分布特性,本文利用數據依賴差異的思想來獲取符合數據分布特性的采樣子集。
2)計算相似性s(p,q)。為了度量查詢與數據集間的全局相似性,采用錨圖[14]的方法來近似數據的鄰居結構,利用K-means對數據進行聚類,取c個聚類中心作為錨點,基于數據和錨點間的近鄰關系,可以用區分力更強的非線性特征z(x)表示樣本數據x,最終兩個數據間的相似性為
s(p,q)=exp(-‖z(p)-z(q)‖2/σ2)
(5)
式中σ為z(p)和z(q)間的最大距離。
此外,通過計算兩個哈希函數的互信息判斷獨立性。
綜合考慮以上兩點,計算哈希比特位權重需要同時最大化哈希函數的近鄰保存能力和獨立性,這個問題可以看作一個二次規劃問題求解。
1.2.3 計算排序得分
計算排序得分時將查詢數據的近鄰半徑ε和原始特征作為輸入,在哈希編碼空間對查詢的ε近鄰進行統計特性的建模分,并利用PCA對候選最近鄰集數據進行降維壓縮,利用PCA方法一方面可以將數據特征信息盡可能的壓縮,減少編碼長度,提高計算效率,另一方面PCA映射是正交的且能夠保存L2距離,因此,查詢數據的ε近鄰在經過PCA映射后仍保留其近鄰關系。
為了計算方便,可以將排序得分近似為
(6)
式中q為查詢圖像,h為哈希編碼,k為編碼長度,ωj為排序得分的單個比特輸出
(7)
式中yj為pj(yj)生成的隨機數。本文假設pj(yi)為均勻分布。式中只要有任意一個ωj(qj,hj,ε)為0,最終的排序得分即為0,哈希編碼為h的數據則不會返回,可大幅提高計算效率。
2 算法流程
本文算法流程如圖1所示。
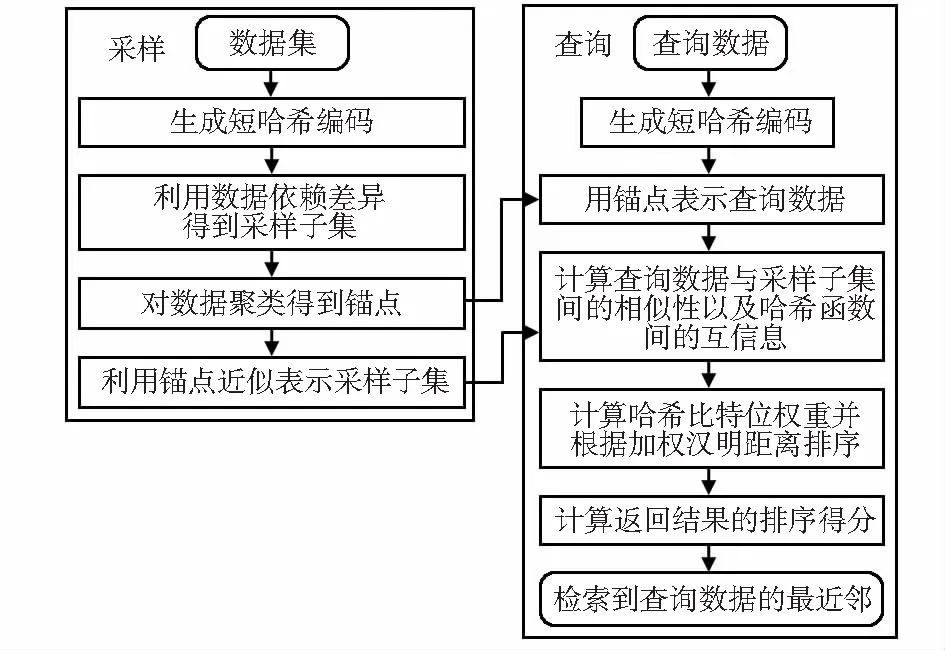
圖1 改進哈希編碼加權排序的圖像檢索算法流程
3 仿真實驗與結果分析
3.1 實驗環境與參數設置
仿真實驗采用圖像哈希檢索常用的手寫數字數據庫MNIST[15]和自然圖像數據庫CIFAR—10,本文隨機選取數據庫中的1 000幅作為測試用的查詢圖像,其余的作為數據集輸入。實驗硬件環境為Intel Core i5—6200U處理器、8 GB內存,軟件環境為Windows10,編程環境采用MATLAB R2016a。
為了驗證所提算法的有效性,選擇文獻[2]提出的基本的哈希編碼方法,即LSH,以及兩種哈希編碼加權排序方法,文獻[10]的WhRank算法和文獻[12]的QRank算法進行對比實驗,同時為了驗證本文算法的適用性,對比了文獻[3]PCA哈希(PCAH)和文獻[5]遞歸量化哈希(ITQ),共進行了3組仿真實驗,并對結果進行比較分析。本文采用精度(precision),召回率(recall)和平均準確率(mean average precision,MAP)作為算法的評價指標。精度為返回的前K個結果中最近鄰所占的比率;召回率為前K個結果中最近鄰占所有最近鄰的比率,K值相同的條件下精度和召回率越高,檢索性能越好;平均準確率的大小對應著precision-recall曲線下區域面積的大小,MAP值越大,檢索性能越好。由于查詢圖像是隨機選取的,因此每個實驗重復3次,每次選取5 000幅圖像作為訓練數據,1 000幅圖像作為測試數據,取結果的平均值作為最終結果。數據庫中與查詢圖像標簽相同的圖像即為查詢圖像的真實近鄰。
3.2 結果分析
圖2為CIFAR—10數據庫上查詢圖像返回的部分檢索結果,根據圖2(a)可以看出,經過加權排序粗檢索后得到的候選最近鄰集合中雖然大部分檢索結果是正確的,但仍有錯誤的匹配,影響檢索質量,經過圖2(b)計算排序得分的細檢索后,去除了大部分的錯誤匹配,提高了檢索精度。

圖2 飛機查詢圖像的部分檢索結果
表1中具體列出了MNIST數據庫中編碼長度分別為48 bit和96 bit時幾種算法的MAP,相比于基本的LSH圖像檢索算法,本文算法在檢索精度上有明顯的提升,并且本文算法的MAP也優于WHRank和QRank兩種哈希比特位加權排序算法,在編碼長度為96 bit時,本文算法的MAP分別提高11.61 %,8.42 %和1.86 %。
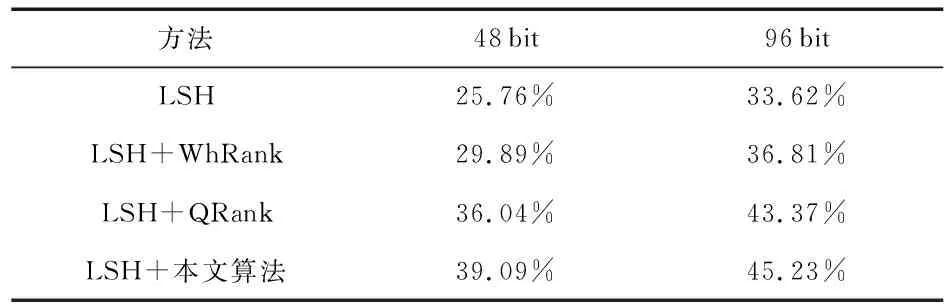
表1 MNIST數據庫上二種編碼長度下各算法的MAP
圖3為MNIST數據庫上各算法的性能對比,圖3(c)給出了編碼長度為48 bit時的檢索精度曲線,可以看出,通過對哈希編碼進行加權排序,提升了基本哈希方法的搜索性能,對于每種哈希方法,使用本文的加權排序算法后檢索精度平均提升了約14 %,對于LSH算法,精度提升的更多(約19 %)。圖3(d)給出了增加編碼長度的檢索精度曲線,可以看出,本文算法提升了基本哈希方法的檢索精度,與其他加權排序方法相比,檢索精度更高。對比圖3(c)、圖3(d)可以發現,LSH和PCAH哈希算法在編碼長度為96 bit時的檢索精度仍然要低于編碼長度為48 bit時使用本文排序算法的檢索精度,說明了本文算法能夠用更短的哈希編碼達到更高的檢索精度,有效提升編碼效率,節省存儲空間。圖3(a)、圖3(b)給出了在數據集MNIST上編碼長度分別為48 bit和96 bit的召回率曲線,可以發現,本文算法有效地提升了召回率,且在性能上優于其他2種排序算法,較QRank算法在召回率上提升了約7.47 %。

圖3 MNIST數據庫上二種編碼長度下各算法的性能對比
4 結 論
提出了一種由粗到細的檢索策略查找查詢圖像的最近鄰,仿真實驗結果表明:本文算法的檢索性能優于其他算法,但在計算排序得分時依賴基于PCA的哈希編碼技術,因此,編碼長度不能超過輸入特征的維數,對此,需要進一步研究更優的量化方案。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
名家名作(2021年9期)2021-10-08 01:31:36
名家名作(2021年4期)2021-05-12 09:40:02
名家名作(2021年3期)2021-04-07 06:42:16
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
新世紀智能(語文備考)(2019年12期)2020-01-13 06:04:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
名家名作(2017年2期)2017-08-30 01:34:24
