淺談數據挖掘在高職院校學生成績預警中的應用
2018-08-11 11:01:46朱敏朱珍元張林靜
課程教育研究·學法教法研究 2018年13期
關鍵詞:數據挖掘
朱敏 朱珍元 張林靜

【摘要】隨著大數據技術的發展及對此認識的提高,愈來愈多的人開始利用大數據來獲取有價值的信息。我國高職院校的不斷擴招使得高職院校教育系統中的數據規模愈來愈龐大,教師想要從其中獲取自己需要的信息愈來愈困難。鑒于這種情況,利用大數據挖掘中的Apriori 算法,通過對高職院校學生成績信息的收集、分析以及處理,根據預設支持度與置信度找出數據庫中具有聯系和不同可信度的課程成績作為關聯規則,將關聯規則應用到學生成績預警中去,從而形成對成績處于危險狀態的學生進行預警的反饋機制。
【關鍵詞】數據挖掘 關聯規則 Apriori算法 學生成績 預警
【基金項目】安徽省2017年度高校自然科學研究項目重點項目(項目編號KJ2017A639);安徽省2016年度高校自然科學研究項目重點項目(項目編號KJ2016A167)
【中圖分類號】G712 【文獻標識碼】A 【文章編號】2095-3089(2018)13-0047-02
本文將通過收集計算機網絡專業學生主干課程的考試成績,然后對這些數據實施統計、分析以及處理。通過這一過程學校會對某一些不及格課程科目數比較多、可能無法按時畢業或者無法取得畢業證的學生進行預警,以便于督促這一部分學生更加努力地進行學習。我們都知道,相同的專業不同課程間肯定具備著一定的關系,本文就是在基于使用數據挖掘技術對高職院校學生得考試成績進行統計、分析以及處理的基礎上,深度發現不同科目成績間的關聯性,探索出他們之間的邏輯關系,進一步掌握學生學習狀態,更好的對學習成績處于危險狀態的學生進行預警,督促學生更好的進行學習,提升他們的及格率以及畢業率。
一、數據挖掘技術與常見算法
數據挖掘(Data Mining)就是有組織性和目的性地搜尋數據,通過對這些數據進行分析使之成為信息,從而尋找潛在規律以形成發現有價值的非同尋常的新信息和知識的過程,數據挖掘填補了數據和信息之間的鴻溝。
數據挖掘是一個在大數據上進行的自然行為,數據挖掘算法是大數據分析的核心部分,要科學表現大數據的特點就需要針對這些數據的類型及格式制定相應的算法。這些算法可以說是基于統計學的統計方法,也只有這樣,挖掘出來的數據才具有相應的價值,同時算法在處理數據速度方面起到了關鍵的作用,若一個算法需要很長時間才能獲得結論,那么大數據的價值也就無從談起。數據挖掘的主體沒有限制,主要是將現有數據通過數據挖掘算法進行預測性分析,進行一些高級別的數據分析,可利用Mahout工具實現。下文列舉一些比較常用的數據挖掘方法。
MBR(Memory-Based Reasoning),這是一種基于歷史的分析方法,利用已知的case(案例)來預測未來case的一些attribute(屬性),即先根據知識和經驗尋找相類似的情況,然后將這些情況的信息應用于現在的例子中。具體MBR首先尋找和新記錄情況相類似的鄰居,然后利用這些鄰居對新數據進行分類和估值。使用MBR有三個亟待解決的主要問題,尋找確定的歷史數據;決定表示歷史數據的最有效的方法;決定距離函數、聯合函數和鄰居的數量。
Decision Tree(決策樹),此算法主要是對未知數據進行分類或預測,它以法則的方式即一連串的問題來表達,再通過不斷詢問最終導出所需要的結果。典型的生成決策樹的方法是采用自頂向下的方式在部門搜索空間中搜索解決方案。它著眼于從一組無次序的、無規則的事例中推導出,該技術主要是用于預測和決策,在商業、科研、工業等領域具有廣泛的應用。
Cluster Detection(聚類分析),又稱為群分析,古人云:“物以類聚,人以群分”,描述的正是這類算法。它是一種廣泛應用于研究分類問題的數據挖掘方法,主要是在沒有給定具體劃分類即未知類的情況下,找出數據當中以前未知的相似群體。經常被用來提供不同類對象特征的報告。目前已經在許多領域 中有廣泛地應用,包括模式識別、圖像處理、模式分析以及市場研究。
除上述方法外還有購物籃分析、遺傳算法、OLAP分析、連接分析、神經網絡、判別分析等等,在此不做一一介紹。
二、數據挖掘技術在相關領域的應用
數據挖掘的最中目的是要實現數據的價值,而商業智能是在企業中實現數據價值的最佳方式之一。數據挖掘能力將成為一個企業未來的核心競爭力,并且挖掘能力將成為一個衡量企業業務水平高低的重要指標,通過數據挖掘以及數據分析抓住用戶特點,只有這樣才能實現大數據的真正價值,實現商業價值。它的蓬勃發展正是由于它在各個領域的廣泛應用,一般較常見的應用案例發生在營銷領域的零售業、直效行銷界、制造業、財務金融保險、通信業、醫療服務業以及各種政府機關等。
在眾多的應用案例中,數據挖掘在營銷領域的應用應該是最為廣泛的。數據挖掘可以從銷售的各項數據中發掘消費者的消費習慣,即通過交易記錄找出顧客偏好的產品組合,以進行交叉銷售(Cross-selling)、向上銷售(Up-selling)。找出流失顧客的特征和新產品的時機點等也都是數據挖掘在零售業中常見的應用。
數據挖掘在金融業中也有著充分的應用。例如,股票交易商可以利用數據挖掘來分析時長動向,并預測個被公司的營運狀況以及估價走向等;又例如,采用數據挖掘中的關聯規則挖掘技術,我們結業成功預測銀行中不同客戶的需求,一旦獲得了這些信息,銀行就可以改善對不同客戶的服務項目。
三、數據挖掘技術在學生成績預警中的實踐分析
(一)關聯規則算法:Apriori 算法
1.關聯規則
設 I{I1,I2,…I}為所有項目的集合,設與任務相關的數據庫DB是數據庫事務的集合,其中每一個事務T是項的集合,使得TI。每一個事務都關聯一個標識符,稱作TID。假設A是一個由項目組成的集合,稱為一個項集,事務T包含項集A,當且僅當AT。如果項集A由k個項目組成,稱為k項集。項集A在與任務相關的數據庫DB中出現的次數占DB中總任務量的百分比叫做項集A的支持度。如果項集的支持度超過用戶給定的最小支持度閾值,就稱該項集是頻繁項集。關聯規則是XY的邏輯蘊含式,其中XI,YI,且XY=φ。如果數據庫DB中有s%的事務包含X∪Y,則稱關聯規則XY的支持度為s%,若項集X的支持度記為support(X),規則的置信度為support(X∪Y)/support(X)。由此可見,支持度表示模式在規則中出現的概率,置信度表示規則的可信性,置信度越高表明規則越有價值。通常人們只研究支持度高的關聯規則,具有高置信度和強支持度的規則成為強規則。即support(X∪Y)=P(X∪Y),confidence(X∪Y)=P(Y|X),同時滿足最小支持度閾值(min_support)和最小置信閾值(min_confidence)的規則稱作強規則。關聯規則數據挖掘的基本任務是發現大型數據庫中的強規則。
2.Apriori 算法
Apriori算法作為關聯規則的標準方法,具體挖掘程序如下:
(1)提前設定好系統的最小支持度閾值,然后選擇使用迭代的方式來對數據庫中涉及到的項目集進行快速檢索,從而發掘出位于此范圍之內的數據庫相關項目組,即找出所有頻繁項集(Large Itemsets)。頻繁項集的意思是指某一項目組出現的頻率相對于其他項目組而言,必須達到某一水平。
(2)系統地分析由上一步驟頻繁項集產生的所有關聯規則,并選擇置信度大于用戶給定閾值的關聯規則作為強關聯規則,即這些規則必須同時滿足以上兩個條件最小支持度和最小置信度。
(二)Apriori 算法在學生成績分析中的應用
1.數據的預處理
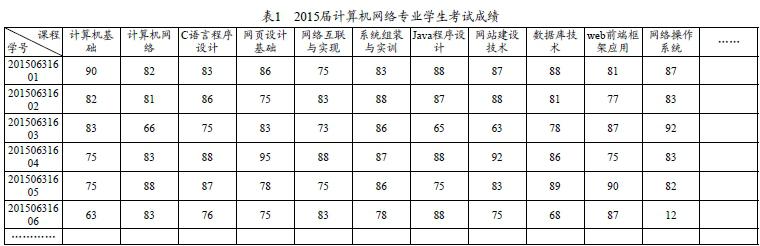
本文以某高職院校2015屆計算機網絡專業學生的考試成績來作為對象進行研究,工作人員獲取學生的成績單之后,采用關聯規則算法對學生的卷面考試成績以及不同科目之間的關系進行深度挖掘。學生的成績如下表1所示,其中包含2015屆計算機網絡專業學生全部專業課程與選修課程的成績。
(1)科目的選擇
通常來講,高職院校學生在公共選修課的選擇上具有非常大的自由度,有可能一個班級僅僅有一兩名同學選擇某一門課程,也就是說數據集中會出現獨立的一個事務涵蓋這一項目,這種狀況是與關聯規則的相關需求相沖突的。從2015屆計算機網絡專業學生的考試成績中我們可以得知,在同一個班級中多數同學共同選修一門選修課的狀況幾乎不存在,因此不把該專業學生的選修課成績劃入數據來源中,也不會對這一部分成績進行挖掘分析。所以,我們主要是針對學生的必修課與專業選修課成績范疇的數據庫進行研究。
(2)成績的離散化處理
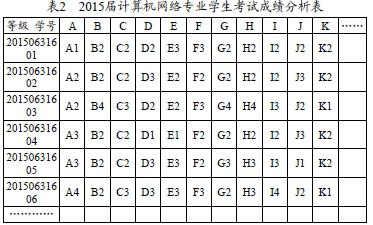
2015屆計算機網絡專業學生成績表中的成績體現為百分制,所以在進行數據處理時應該對其開展統一化處理。本文中將學生的成績劃定為四個范圍,分別為1/2/3/4。成績高于或者等于90分的學生,劃入范圍1;成績低于90分且高于或者等于80分的學生,劃入范圍2;成績低于80分且高于或者等于60分的學生,劃入范圍3;其他劃入范圍4。本文選擇該專業的15門課程來開展分析,這些課程用大寫英文字母來表示,依次為A、B、C……O。
2.數據的處理
(1)數據的轉化
按照數據預處理程序中設定的方式對2015屆計算機網絡專業學生考試成績進行轉化,結果如下表2所示:
(2)數據的統計
由于部分學生會進行補考或者申請延后考試,所以從教務處中獲取的學生成績單會不可避免的存在重復或者空缺問題。在數據統計過程中,對于出現重復的成績,在統計時選擇第一次考試成績;對于空缺的問題,將其成績統計為0。統計離散化后的成績如下表3所示:
通過表3的統計結果我們能夠得知,該班級學生部分課程成績會在某一個范圍進行集中,比如,2015屆計算機網絡專業1班中共有學生總人數為22,但是有16名學生的“網絡操作系統”這一課程成績處于范圍4之中,其他范圍的學生人數為6人,占比為6/22,即關聯規則的最小支持度不到三分之一。設定關聯規則的最小支持度為0.33,當某門課程等級的學生達不到6名時,將他們排除在候選數據挖掘數據庫中。通過統上述計,得到下表中以0.33作為最小支持度篩選的數據。
3.算法實現
對所有數據處理完成后,選擇使用關聯規則典型算法Apriori對它們進行挖掘。本文的所有挖掘算法操作均是在Windows 7系統及MAT-LAB2015a環境下進行的,設置的最小支持度為0.33,最小置信度為0.5,得到347個頻繁項集,562條關聯規則。對部分結果進行分析可知課程A(計算機基礎)、課程E(網絡互聯與實現)、課程F(系統組裝與實訓)存在著兩兩相關、相互制約的關系,學生的成績普遍較低,課程C(C語言程序設計)與課程G(Java程序設計)、課程D(網頁設計基礎)與課程H(網站建設技術)也存在著兩兩相關、互相影響的關系。通過對數據庫的檢索,可以找出符合這些關聯規則的學生名單,由輔導員負責對這部分學生發出預警通告。
四、結語
總而言之,數據挖掘應用于高職院校學生成績預警工作中,能夠有效的提升學校對學生成績的管理,同步對那些成績處于危險狀態的學生進行預警反饋,督促他們盡快調整學習態度以完成相關學業要求,對于提升學校的教學水平和學生的畢業率具有重要意義。
參考文獻:
[1]陳苗,馬燕. 數據挖掘在高職院校學生成績預警中的應用研究[J]. 電腦知識與技術,2017,13(2):204-206.
作者簡介:
朱敏(1989-),女,安徽合肥人,安徽警官職業學院教師,研究方向:數據挖掘、大數據分析;朱珍元(1985—),女,湖北黃岡人,安徽警官職業學院教師,研究方向:語義Web、數據挖掘、移動互聯網;張林靜(1988—),女,安徽合肥人,安徽警官職業學院教師,研究方向:計算機應用。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
