基于邏輯回歸算法的乳腺癌診斷數據分類研究
2018-03-28 06:03:14劉蕾
軟件工程
2018年2期
劉蕾
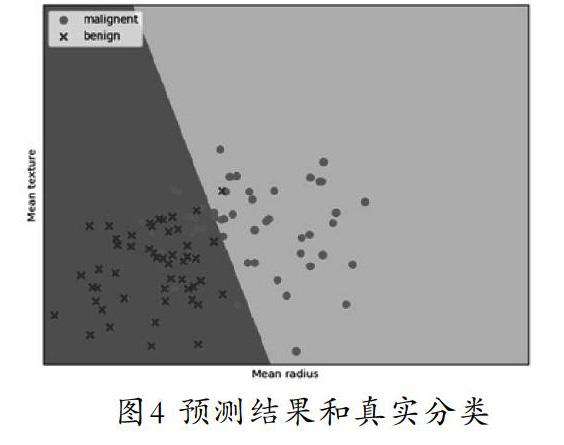
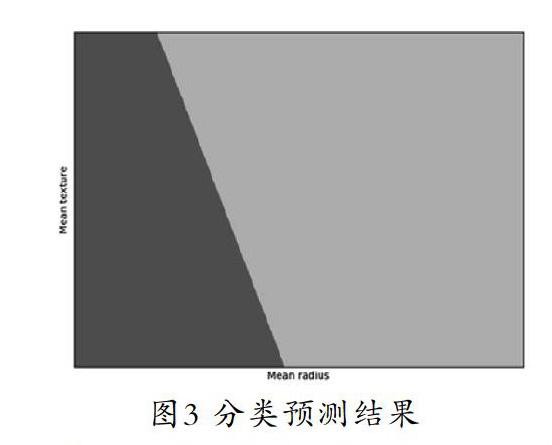
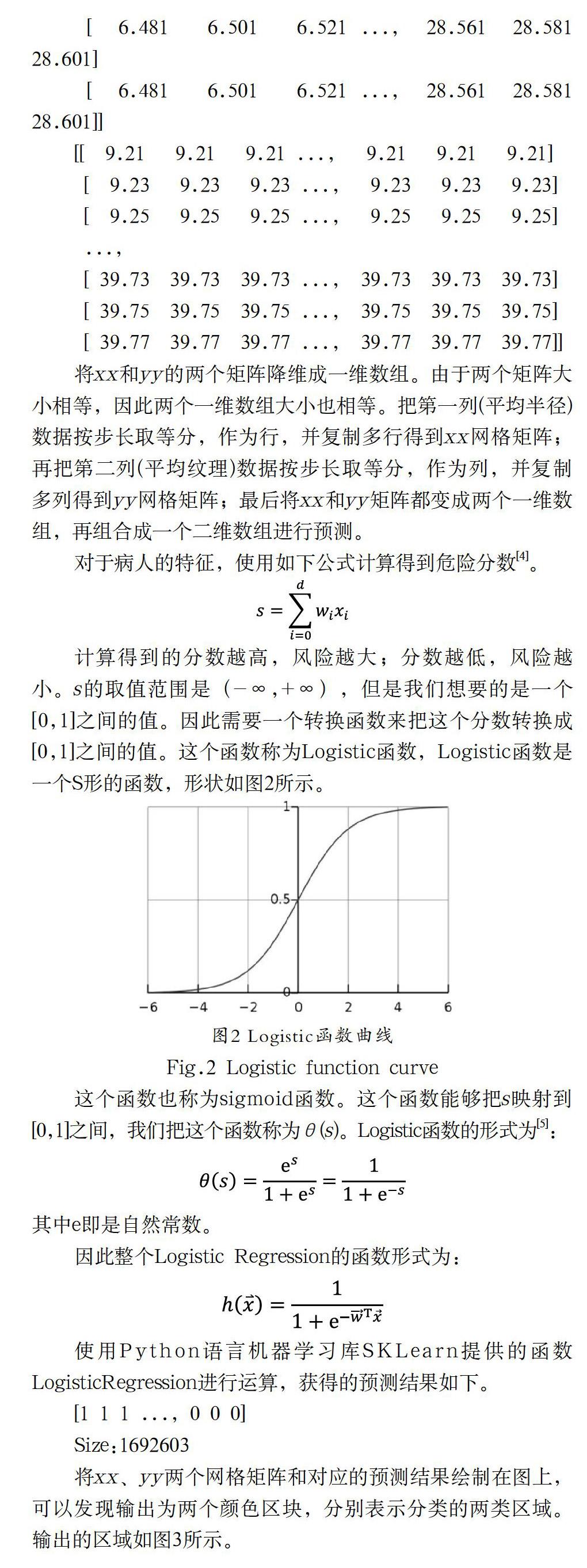
摘 要:乳腺癌是世界范圍內婦女死亡的主要原因之一,準確的診斷是乳腺癌治療中最重要的步驟之一。本文詳細講解了邏輯回歸模型的原理知識,結合Sklearn機器學習庫的LogisticRegression算法對乳腺癌威斯康辛(診斷)數據集進行了數據分類。由于該數據集分類標簽劃分為兩類(惡性、良性),能夠很好地適用于邏輯回歸模型。用基于兩個特征的邏輯回歸模型得到的分類結果表明,當選取平均半徑和最大周長兩個特征時,分類精度最高(95.72%)。與以往的方法相比,該方法在性能上有所提高。
關鍵詞:乳腺癌數據集;邏輯回歸分類算法;預測
中圖分類號:TP393 文獻標識碼:A
Abstract:Breast cancer is one of the major causes of death for women worldwide,and accurate diagnosis is one of the most important steps in the treatment of breast cancer.This paper explains the knowledge of the logistic regression model in detail,and classifies the data set of breast cancer by using the Logistic Regression algorithm of Sklearn machine learning library.The classification label of the data set is divided into 2 classes (malignant and benign),which is appropriate for the logistic regression model.The classification results based on the logistic regression model with two features show that the classification accuracy is the highest (95.72%) when the two characteristics of the mean radius and the largest perimeter are selected.In comparison to previous methods,the performance has been improved to some extent.
Keywords:breast cancer data set;logistic regression classification algorithm;prediction
1 引言(Introduction)
乳腺癌的早期診斷與治療有著重要的作用,已有多種分類方法應用于此種診斷,如C4.5決策樹算法、樸素貝葉斯算法、支持向量機、KNN等。基于乳腺癌數據,運用上述分類方法進行模型構建,分析比較各模型性能,其中支持向量機性能較優。支持向量機可有效調節算法復雜度與泛化能力之間的矛盾,其在小樣本學習領域中有著優于傳統模式識別方法的推廣能力。然而在處理較大規模數據集時,往往需要較長的訓練時間。KNN方法是一種基于實例的學習,可生成任意形狀的決策邊界,無需建立模型,但其分類中開銷很大,需逐個計算相似度,此外,當k取值較小時,對噪聲也很敏感[1]。針對上述不足,國內外研究者們也已做出相應的改進,但尚未有一個能同時實現訓練時間短、預測能力強、規則提取簡易且適應性強的分類方法[2]。……
登錄APP查看全文
