基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界防護(hù)技術(shù)研究*
2016-08-10 03:43:00姜洪海王婷婷
計算機(jī)與數(shù)字工程 2016年7期
關(guān)鍵詞:挖掘
姜洪海 王婷婷 左 進(jìn)
(1.海軍北海艦隊司令部機(jī)要處 青島 266000)(2.海軍工程大學(xué)信息安全系 武漢 430033)
?
基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界防護(hù)技術(shù)研究*
姜洪海1王婷婷1左進(jìn)2
(1.海軍北海艦隊司令部機(jī)要處青島266000)(2.海軍工程大學(xué)信息安全系武漢430033)
摘要針對網(wǎng)絡(luò)邊界安全檢測與防護(hù)問題,提出了基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界防護(hù)模型。該模型從數(shù)據(jù)流的角度出發(fā),首先對網(wǎng)絡(luò)數(shù)據(jù)進(jìn)行抽樣并預(yù)處理,然后應(yīng)用數(shù)據(jù)流挖掘技術(shù)進(jìn)行規(guī)則挖掘,最后根據(jù)挖掘結(jié)果對網(wǎng)絡(luò)進(jìn)行分析和控制。仿真實驗表明,在網(wǎng)絡(luò)安全檢測中,數(shù)據(jù)流挖掘方法比傳統(tǒng)的模式匹配方法更具有優(yōu)勢。
關(guān)鍵詞網(wǎng)絡(luò)邊界; 防護(hù); 數(shù)據(jù)流; 挖掘
Class NumberTP393
1引言
網(wǎng)絡(luò)安全問題一直是互聯(lián)網(wǎng)技術(shù)領(lǐng)域熱點問題之一,尤其是不同網(wǎng)絡(luò)之間的邊界安全,其所受到的安全威脅來源呈日益增長態(tài)勢。近年來,隨著網(wǎng)絡(luò)技術(shù)的發(fā)展,部分網(wǎng)絡(luò)出口流量就達(dá)到百G甚至更高,在超大規(guī)模網(wǎng)絡(luò)之間交換的數(shù)據(jù)量則更高,甚至達(dá)到千G[1]。如何維護(hù)高速網(wǎng)絡(luò)邊界安全己成為一個現(xiàn)實問題。現(xiàn)有網(wǎng)絡(luò)之間交換的數(shù)據(jù)往往呈流式狀態(tài),針對如此大規(guī)模的數(shù)據(jù)流安全檢測問題,傳統(tǒng)的邊界安全檢測與防護(hù)手段存在諸多問題:需要多次訪問數(shù)據(jù),無法處理潛在無限的數(shù)據(jù)流;計算復(fù)雜度太高,難以一次性處理所有數(shù)據(jù)流;空間復(fù)雜度太大,有限內(nèi)存難以計算[2]。
為了從大量冗余的信息中提取出潛在有價值的信息,衍生出了一個全新的領(lǐng)域—數(shù)據(jù)挖掘。數(shù)據(jù)挖掘就是從海量的、模糊信息中獲取有效的、潛在有用的信息和知識的過程[3~4]。而數(shù)據(jù)流挖掘就是在流式數(shù)據(jù)上提取有效的、有價值的信息和知識的過程。數(shù)據(jù)流挖掘技術(shù)能夠在大規(guī)模流式數(shù)據(jù)中發(fā)現(xiàn)特征或規(guī)則。在網(wǎng)絡(luò)異常行為分析和入侵檢測領(lǐng)域,利用數(shù)據(jù)流挖掘技術(shù)可以從大量的審計數(shù)據(jù)中找出正常或入侵性質(zhì)的行為模式,從而構(gòu)建自動檢測模型。基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)安全檢測方法具有自適應(yīng)強(qiáng)、無監(jiān)督和檢測效率高等優(yōu)點。本文從數(shù)據(jù)流挖掘的角度出發(fā),研究基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界行為檢測和防護(hù)技術(shù)。
2網(wǎng)絡(luò)邊界防護(hù)難點
網(wǎng)絡(luò)邊界是指具有不同安全策略的網(wǎng)絡(luò)連接處或者是邏輯隔離的不同網(wǎng)絡(luò)之間分界線。網(wǎng)絡(luò)邊界內(nèi)涵豐富,不僅包含傳統(tǒng)的物理邊界,還包括網(wǎng)絡(luò)之間的邏輯邊界。網(wǎng)絡(luò)邊界的復(fù)雜性與廣泛性決定了其所受的安全威脅來源多樣,如網(wǎng)絡(luò)內(nèi)外部的信息泄露、針對網(wǎng)絡(luò)邊界設(shè)備或系統(tǒng)服務(wù)器的網(wǎng)絡(luò)攻擊、內(nèi)嵌在軟件中的網(wǎng)絡(luò)病毒、盜用網(wǎng)絡(luò)信息的木馬入侵等。目前針對網(wǎng)絡(luò)邊界的防護(hù)主要是配備邊界路由器、邊界防火墻、邊界防病毒設(shè)備、邊界流量監(jiān)控等。如此多的邊界防護(hù)軟硬件容易產(chǎn)生安全信息過載現(xiàn)象,造成管理的混亂。網(wǎng)絡(luò)邊界的防護(hù)關(guān)鍵是能夠?qū)Ω鞣N網(wǎng)絡(luò)安全威脅進(jìn)行快速有效的檢測,對檢測到的威脅進(jìn)行及時隔離與處理,從而才能夠確保網(wǎng)絡(luò)安全。
3數(shù)據(jù)流挖掘在網(wǎng)絡(luò)行為分析中的優(yōu)勢
網(wǎng)絡(luò)中的程序或用戶在網(wǎng)絡(luò)中的各種行為,往往可以通過其產(chǎn)生的網(wǎng)絡(luò)行為數(shù)據(jù)來反映。從捕獲的網(wǎng)絡(luò)行為數(shù)據(jù)中,選擇合適的有代表性的行為屬性進(jìn)行模式挖掘處理,構(gòu)建網(wǎng)絡(luò)的正常行為特征庫,通過實時比較網(wǎng)絡(luò)的當(dāng)前行為和行為特征庫,可以實現(xiàn)對網(wǎng)絡(luò)異常的檢測和分析,維護(hù)網(wǎng)絡(luò)的安全。
數(shù)據(jù)流挖掘就是從大量流式數(shù)據(jù)中挖掘出潛在的有價值的信息知識過程。數(shù)據(jù)流挖掘包括對數(shù)據(jù)流的頻繁模式挖掘、分類挖掘、聚類挖掘和關(guān)聯(lián)規(guī)則挖掘[5~7]。該技術(shù)主要根據(jù)流式數(shù)據(jù)本身的固有屬性進(jìn)行挖掘分析,從數(shù)據(jù)之間的差異發(fā)現(xiàn)價值信息,挖掘模型不依賴專家系統(tǒng),不需要過多的人工參與。將數(shù)據(jù)流挖掘技術(shù)應(yīng)用到網(wǎng)絡(luò)異常行為分析和網(wǎng)絡(luò)防護(hù),具有智能性好、自動化程度高、檢測效率高、自適應(yīng)性強(qiáng)和誤報率低等優(yōu)點。
4基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界防護(hù)模型
圖1為基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界防護(hù)模型,主要分為三個模塊:數(shù)據(jù)流抽樣與預(yù)處理模塊、數(shù)據(jù)流挖掘與規(guī)則輸出模塊、網(wǎng)絡(luò)邊界安全控制模塊。下面對其進(jìn)行詳細(xì)介紹。
4.1數(shù)據(jù)流抽樣與預(yù)處理模塊
網(wǎng)絡(luò)數(shù)據(jù)流的抽樣是對大量、高速、時變的網(wǎng)絡(luò)數(shù)據(jù)包按一定比例進(jìn)行約減抽取。通過對網(wǎng)絡(luò)數(shù)據(jù)流的抽樣,可以降低網(wǎng)絡(luò)分析與測量的實現(xiàn)代價,從而實現(xiàn)對網(wǎng)絡(luò)的安全檢測和性能監(jiān)控等目的。對網(wǎng)絡(luò)數(shù)據(jù)流的抽樣,最重要的是利用樣本能夠恢復(fù)出原有數(shù)據(jù)的特性即保真,但同時也需要追求抽樣方案的簡單性與可行性以提高效率[8]。
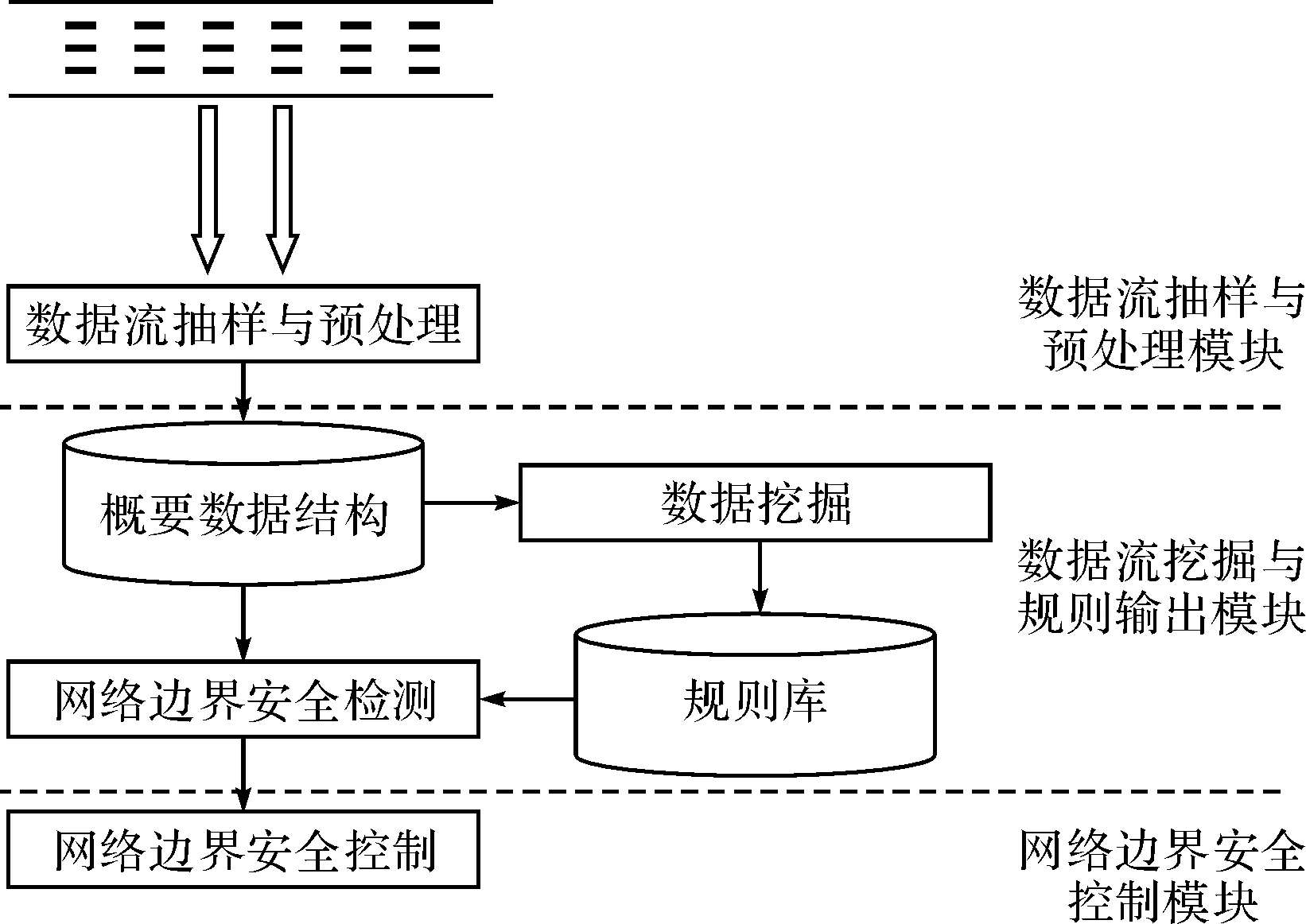
圖1 基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界防護(hù)模型
網(wǎng)絡(luò)數(shù)據(jù)流的抽樣樣本為網(wǎng)絡(luò)數(shù)據(jù)包,將數(shù)據(jù)包統(tǒng)計為網(wǎng)絡(luò)連接記錄,仍然不能直接用于數(shù)據(jù)挖掘,需要對其進(jìn)行預(yù)處理。預(yù)處理過程主要包括特征屬性項的選取、屬性值的數(shù)值化和屬性值的標(biāo)準(zhǔn)化。
4.1.1特征屬性項的選取
鑒別并選取關(guān)鍵屬性項作為數(shù)據(jù)流挖掘算法的輸入,對于數(shù)據(jù)分析來說意義重大。不僅可以降低算法的復(fù)雜度和所需存儲空間,而且可以提高算法的準(zhǔn)確率。以KDD99數(shù)據(jù)集為例,對于數(shù)據(jù)集中每一條網(wǎng)絡(luò)連接記錄的41個特征屬性,文獻(xiàn)[9]根據(jù)PFRM算法(基于效能等級的重要特征排序算法)篩選出了對應(yīng)于不同網(wǎng)絡(luò)攻擊行為的重要特征屬性子集,如表1所示。表中數(shù)字對應(yīng)KDD99數(shù)據(jù)集中各特征屬性項編號,即1~41個特征屬性項。
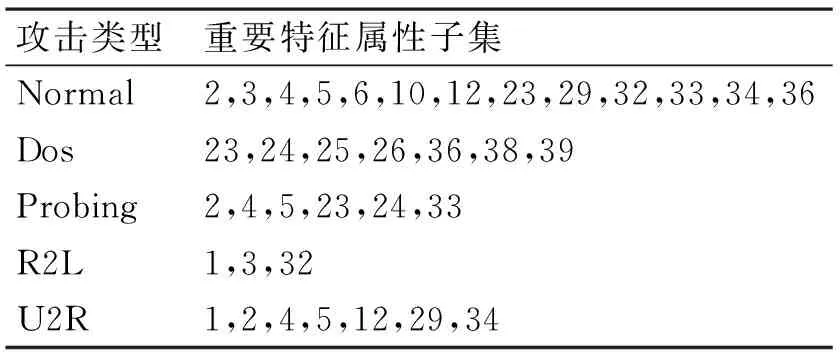
表1 PFRM算法重要特征屬性子集列表
綜合得出PFRM算法可選擇的特征屬性項個數(shù)為19個,即特征屬性項集F1={1,2,3,4,5,6,10,12,23,24,25,26,29,32,33,34,36,38,39}。文獻(xiàn)[10~11]利用RS粗糙集理論對數(shù)據(jù)集的屬性進(jìn)行約簡,并和SVDF、LGP、MARS算法進(jìn)行比較,選出了六個最為重要的特征屬性項。各算法選擇的重要特征屬性項如表2所示。

表2 RS、SVDF、LGP、MARS算法重要特征屬性子集列表
考慮到RS選擇的特征屬性子集能夠很好地判斷入侵,且特征屬性項的個數(shù)較小,容易實現(xiàn),本文采用的是RS算法對數(shù)據(jù)集屬性約簡篩選出的特征屬性項子集F3={3,4,5,24,32,33}。
4.1.2屬性值的數(shù)值化
在網(wǎng)絡(luò)連接記錄中的所有特征屬性中,還包含一些非數(shù)值數(shù)據(jù),如flag、service、Protocol_type等屬性值是字符串類型。為了能夠?qū)ζ溥\算,需要將這些字符串變?yōu)閿?shù)值型。連接正常或錯誤的狀態(tài)—flag屬性,取值有S0,S1、S2、S3、SF、SH、OTH、REJ、RSTO、RSTOSO、RSTR,一共11個,可分別將其轉(zhuǎn)換對應(yīng)為整數(shù)1~11;協(xié)議類型—Protocol_type屬性的取值有icmp、tcp、udp可對應(yīng)為整數(shù)1~3,其他協(xié)議類型一律對應(yīng)為4;對于目標(biāo)主機(jī)的網(wǎng)絡(luò)服務(wù)類型—service一共有70種取值,可分別對應(yīng)于整數(shù)1~70。
4.1.3屬性值的標(biāo)準(zhǔn)化
大多數(shù)的數(shù)據(jù)流挖掘算法是根據(jù)相似度對算法的輸入即特征屬性項進(jìn)行挖掘分析的,將相似度小的數(shù)據(jù)聚為一類,相似度大的數(shù)據(jù)分開。而相似度對特征屬性項的值域范圍是非常敏感的。例如,相似度采用歐式距離進(jìn)行運算時,對如下兩組數(shù)據(jù)進(jìn)行相似度的判斷:
第一組:{(1,1,2,3),(2,2,3,2)};
第二組:{(180,340,320,120),(280,240,420,220)};
第一組中兩個數(shù)據(jù)的相似度:
第二組中兩個數(shù)據(jù)的相似度;
=200
如果算法以數(shù)值3為相似度的度量標(biāo)準(zhǔn),則根據(jù)得到的結(jié)果,第一組應(yīng)該歸為一類,第二組應(yīng)該被劃分開。但事實上,第二組兩個數(shù)據(jù)之間的距離與第一組兩個數(shù)據(jù)之間的相對距離等同。直接用特征屬性的值進(jìn)行計算勢必造成很大誤差,必須對數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化。
對于包含m個特征屬性項的L個數(shù)據(jù)的數(shù)據(jù)集DS,由式(1)~式(3)將其轉(zhuǎn)換到新的標(biāo)準(zhǔn)化空間NEW_DS。mean_vector[i]和std_vector[i]分別是數(shù)據(jù)集DS中第i個特征屬性項的均值和標(biāo)準(zhǔn)方差。
(j∈(1,2,…,L),i∈(1,2,…,m))
(1)
(2)
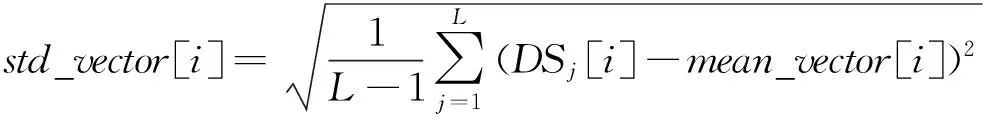
(3)
這樣,通過式(1)~式(3)后,可將數(shù)據(jù)集中不同特征屬性項由其初始空間轉(zhuǎn)換到標(biāo)準(zhǔn)空間,消除不同值域范圍對挖掘算法的影響。
4.2數(shù)據(jù)流挖掘分析與規(guī)則輸出模塊
將抽樣數(shù)據(jù)流進(jìn)行預(yù)處理之后,待挖掘數(shù)據(jù)的真實性、數(shù)據(jù)量以及數(shù)據(jù)質(zhì)量已經(jīng)可以得到保障,接下來就可以對處理過的數(shù)據(jù)進(jìn)行深層次的分析和挖掘了。這部分工作主要是從待挖掘的數(shù)據(jù)中找到異常數(shù)據(jù),挖掘出隱藏在數(shù)據(jù)中的重要價值信息,并且以規(guī)則這種可接收、可理解可應(yīng)用的形式展示出來。
如圖2所示,為數(shù)據(jù)流挖掘與規(guī)則輸出的整個流程。首先需要選擇合適的挖掘算法對數(shù)據(jù)進(jìn)行挖掘分析,同時將分析的結(jié)果以圖表或文本規(guī)則的形式進(jìn)行總結(jié),最后輸出。

圖2數(shù)據(jù)流挖掘與規(guī)則輸出過程
4.2.1數(shù)據(jù)流挖掘算法
對數(shù)據(jù)進(jìn)行挖掘應(yīng)用最為廣泛的是J.B.MacQueen提出的k-means算法即K均值算法。由于該算法簡單、高效、適用于大規(guī)模數(shù)據(jù)集的處理,自提出后就被廣泛應(yīng)用于各種領(lǐng)域。經(jīng)典的K均值算法屬于劃分聚類方法,目標(biāo)是最小化平方誤差和函數(shù)。算法經(jīng)過多次迭代,將Rd空間上的數(shù)據(jù)集X={x1,…,xi,…,xn}劃分聚類到K個不同類簇當(dāng)中,使得類簇間相似度盡可能小,類簇內(nèi)相似度盡可能大。K均值算法首先隨機(jī)指派K個數(shù)據(jù)點作為算法的初始聚類中心,然后采用歐式距離計算所有點到達(dá)各個中心的距離,把各個點劃分到離其最近的中心點所屬類簇。對調(diào)整后的類簇重新計算其簇中心,再次更新所有點的所屬簇,如此反復(fù)迭代,直至聚類準(zhǔn)則函數(shù)收斂或達(dá)到迭代次數(shù),算法結(jié)束。具體聚類過程如圖3所示。
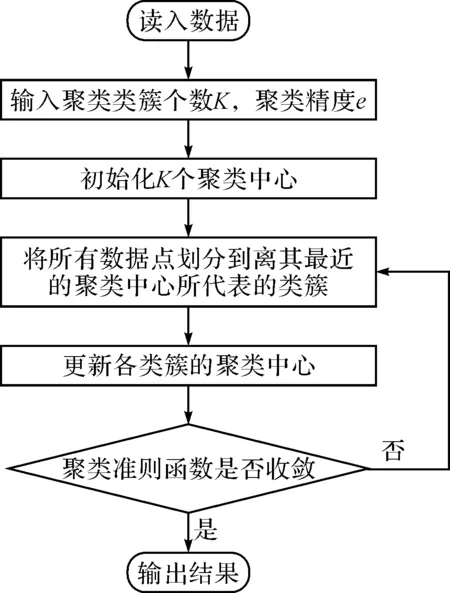
圖3 K均值算法聚類過程
4.2.2挖掘結(jié)果判斷
對于網(wǎng)絡(luò)邊界數(shù)據(jù)流來說,挖掘的結(jié)果主要是找出其中具有潛在威脅的信息即異常信息。異常,從某種意義上說是一種模式,這種模式中的數(shù)據(jù)并不滿足我們熟知或者預(yù)定義的正常數(shù)據(jù)范圍,在整個數(shù)據(jù)流中找出符合這種模式的數(shù)據(jù)稱之為異常檢測。而在聚類中,對異常的挖掘是基于數(shù)據(jù)對象與大眾數(shù)據(jù)的偏離程度。所有數(shù)據(jù)通過無監(jiān)督的聚類算法按照相似度差異進(jìn)行聚類劃分之后,被分成不同的類簇。對異常的判斷基于以下兩個原則:在同一個類簇中,正常的數(shù)據(jù)對象離類簇中心距離較近,而異常數(shù)據(jù)對象離類簇中心距離較遠(yuǎn);在不同的類簇之間,正常的數(shù)據(jù)對象屬于規(guī)模較大、數(shù)據(jù)密集的類簇,而異常數(shù)據(jù)對象屬于嬌小的、數(shù)據(jù)稀疏的類簇。如圖4所示,在一個二維數(shù)據(jù)集中,所有數(shù)據(jù)被聚類劃分為三類。數(shù)據(jù)集中的大部分?jǐn)?shù)據(jù)都聚集在類簇C1和C2中,對于較為稀疏的類簇C3和離類簇中心距離較遠(yuǎn)的數(shù)據(jù)點d1和d2都可以被判斷為異常數(shù)據(jù)點。
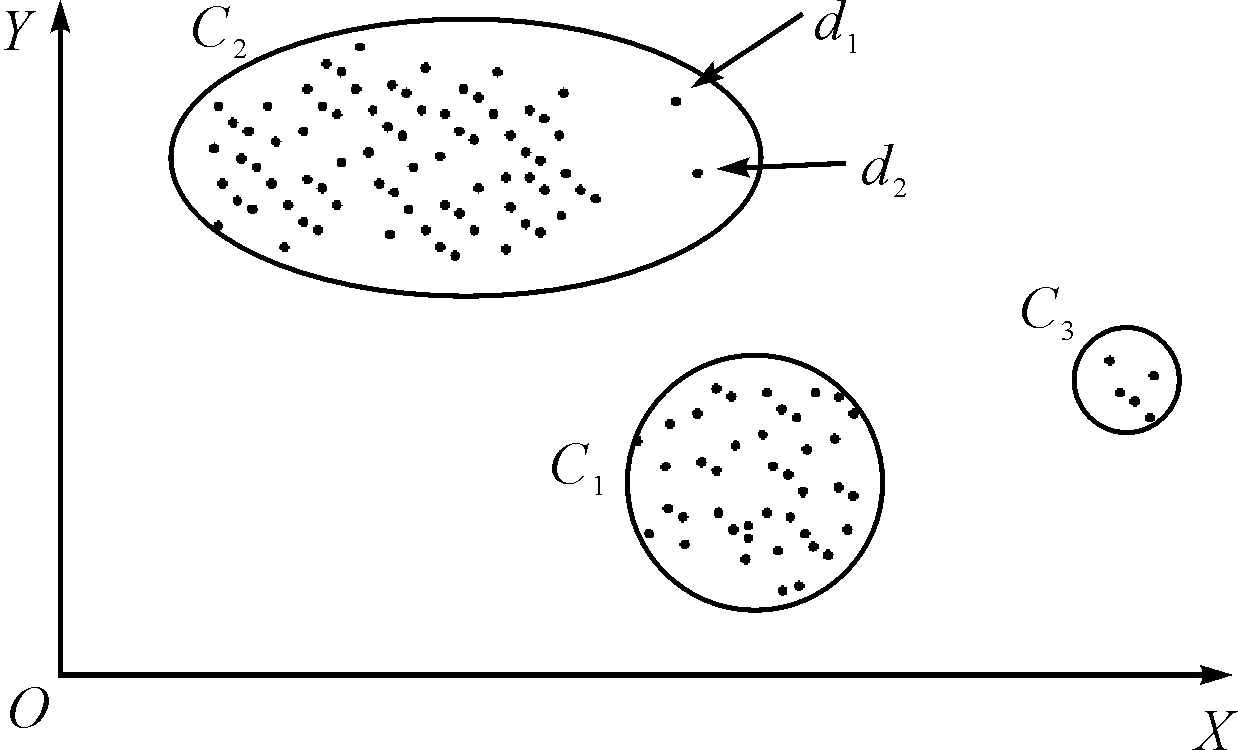
圖4 數(shù)據(jù)挖掘結(jié)果判斷
4.3網(wǎng)絡(luò)邊界安全控制模塊
當(dāng)利用數(shù)據(jù)流挖掘技術(shù)發(fā)現(xiàn)異常數(shù)據(jù)流之后,需要對該數(shù)據(jù)流所代表的網(wǎng)絡(luò)行為進(jìn)行監(jiān)控或及時阻斷,此功能主要由網(wǎng)絡(luò)邊界安全控制模塊來完成。作為網(wǎng)絡(luò)邊界安全控制中心,通過允許、拒絕網(wǎng)絡(luò)之間流通的數(shù)據(jù)流,網(wǎng)絡(luò)邊界安全控制模塊實現(xiàn)對出入網(wǎng)絡(luò)的服務(wù)、訪問進(jìn)行審計和控制,對用戶的行為進(jìn)行監(jiān)控,對具有不安全傾向行為早發(fā)現(xiàn)早預(yù)防,削弱、減少網(wǎng)絡(luò)中的脆弱點,達(dá)到網(wǎng)絡(luò)防護(hù)的目的。具體措施包括斷開連接或關(guān)閉訪問資源、根據(jù)相應(yīng)的安全策略進(jìn)行響應(yīng)、向用戶告警等。
5仿真分析
在網(wǎng)絡(luò)邊界防護(hù)過程中,對網(wǎng)絡(luò)入侵或者攻擊行為的識別是關(guān)鍵,為了分析數(shù)據(jù)流挖掘在網(wǎng)絡(luò)行為判斷中的優(yōu)勢,本文對數(shù)據(jù)流挖掘方法和傳統(tǒng)入侵檢測系統(tǒng)的模式匹配方法進(jìn)行了仿真對比,主要分析兩種方法對網(wǎng)絡(luò)攻擊數(shù)據(jù)的檢測率、誤檢率和檢測時間。
實驗配置:Win 7,VC++6.0,Matlab7.1,CPU 2.4 GHz,2.0 GB內(nèi)存。實驗數(shù)據(jù)來源于UCI機(jī)器學(xué)習(xí)數(shù)據(jù)庫[12]的KDD數(shù)據(jù)集。其中,KDD數(shù)據(jù)集有四大類攻擊數(shù)據(jù)即異常數(shù)據(jù):Dos(拒絕服務(wù)攻擊)、Probing(監(jiān)視與探測)、R2L(遠(yuǎn)程非法訪問)、U2R(普通用戶對本地超級用戶的非法訪問)。該數(shù)據(jù)集中的每一個連接記錄可提供一個完整的網(wǎng)絡(luò)會話。表3是摘自KDD99數(shù)據(jù)集的三條網(wǎng)絡(luò)連接記錄,以CSV格式呈現(xiàn)。
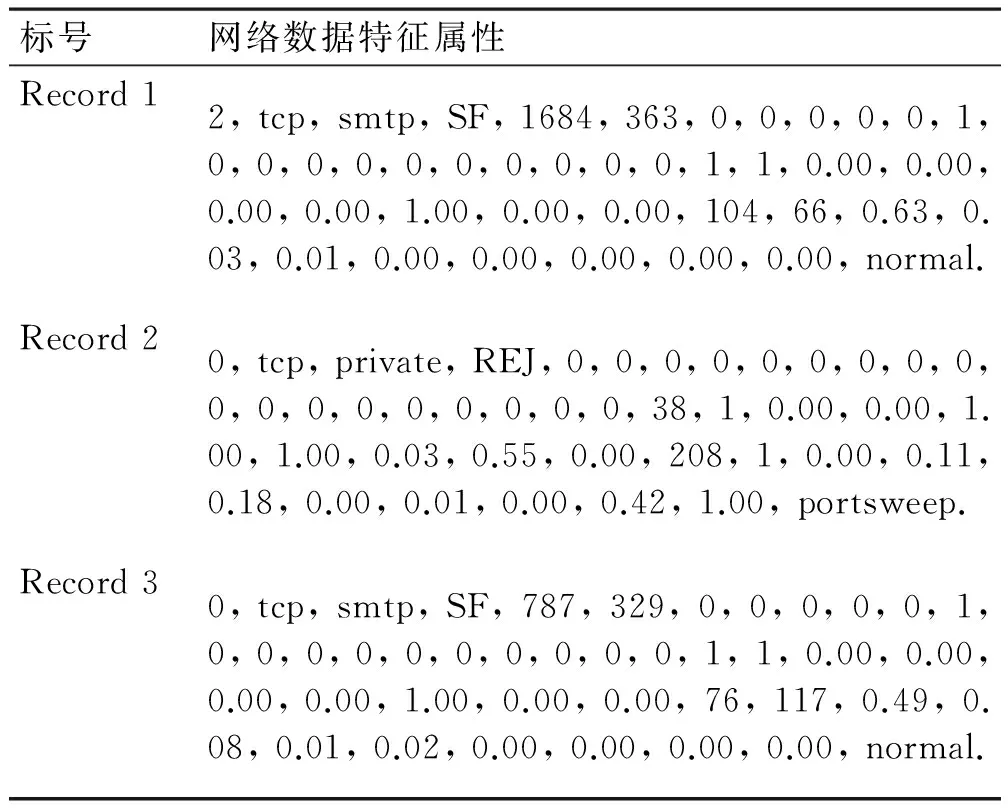
表3 KDD99數(shù)據(jù)集
結(jié)果如表4所示。對于前三種攻擊數(shù)據(jù),檢測率方面,數(shù)據(jù)流挖掘檢測方法平均比傳統(tǒng)模式匹配檢測方法提高了4%,用時方面平均少了1468ms。這是因為數(shù)據(jù)流挖掘技術(shù)主要根據(jù)數(shù)據(jù)本身的固有屬性進(jìn)行挖掘分析,效率較高。但是在誤檢率方面,傳統(tǒng)模式匹配檢測方法根據(jù)原有的攻擊行為模型進(jìn)行一一吻合檢測,誤檢率較低。綜合來看,在整體數(shù)據(jù)集的檢測中,數(shù)據(jù)流挖掘檢測方法除了在誤檢率方面稍微落后一些,在檢測率和檢測時間方面,優(yōu)于傳統(tǒng)的模式匹配檢測方法。
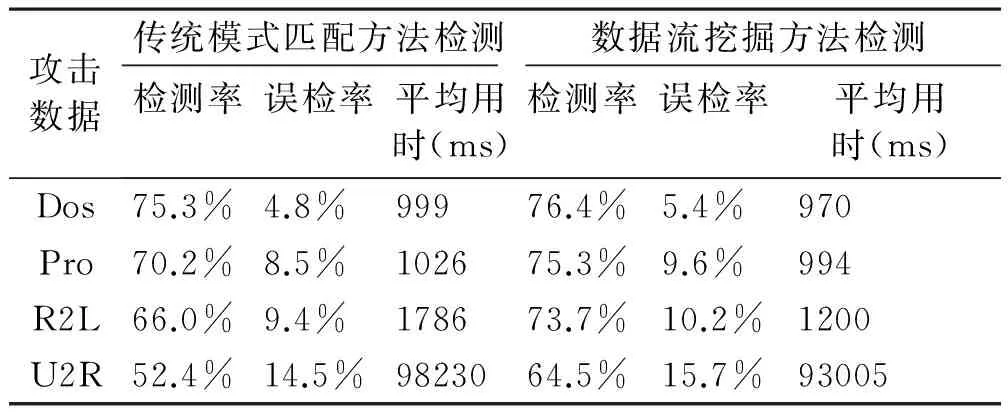
表4 兩種方法對攻擊數(shù)據(jù)的檢測效果比較
6結(jié)語
本文主要研究了基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界防護(hù)技術(shù)。提出了基于數(shù)據(jù)流挖掘的網(wǎng)絡(luò)邊界防護(hù)模型,主要包括數(shù)據(jù)流抽樣與預(yù)處理模塊、數(shù)據(jù)流挖掘與規(guī)則輸出模塊、網(wǎng)絡(luò)邊界安全控制模塊。并對防護(hù)模型中涉及到的關(guān)鍵技術(shù)和環(huán)節(jié)進(jìn)行了重點介紹。最后利用編程仿真,分析了數(shù)據(jù)流挖掘技術(shù)在網(wǎng)絡(luò)行為分析中的優(yōu)勢。將數(shù)據(jù)流挖掘技術(shù)應(yīng)用到網(wǎng)絡(luò)異常行為分析和網(wǎng)絡(luò)防護(hù),具有智能性好、檢測效率高等優(yōu)點,如何在真實網(wǎng)絡(luò)環(huán)境中搭建平臺與實踐應(yīng)用,將是本文下一步研究方向。
參 考 文 獻(xiàn)
[1] 白生江.主動型軍用網(wǎng)絡(luò)邊界防護(hù)系統(tǒng)研究[D].西安:西安電子科技大學(xué),2010.
BAI Shengjiang. Study of Proactive Military Network Security Border Protection System[D]. Xi’an: Xi’an Electronic and Science University,2010.
[2] 劉本倉.基于采樣數(shù)據(jù)流挖掘的網(wǎng)絡(luò)行為分析研究[D].西安:西安電子科技大學(xué),2009.
LIU Bencang. Research On Network Behavior Analysis Based on Sampling Stream Data Mining[D]. Xi’an: Xi’an Electronic and Science University,2009.
[3] 李賀玲.數(shù)據(jù)挖掘在網(wǎng)絡(luò)入侵檢測中的應(yīng)用研究[D].長春:吉林大學(xué),2013.
LI Heling. Study on Application of data mining in network intrusion detection[D]. Changchun: Jilin University,2013.
[4] 譚林.基于NMHS4C和M-Apriori的Snort入侵檢測研究[D].武漢:武漢科技大學(xué),2015.
TAN Lin. Research on Intrusion Detection Based on Snort NMHS4C and M-Apriori[D]. Wuhan: Wuhan University of Science and Technology,2015.
[5] Shie B E, Yu P S, Tseng V S. Efficient algorithms for mining maximal high utility itemsets from data streams with different models[J]. Expert Systems with Applications,2012,39(17):12947-12960.
[6] Li H F. MHUI-max: An efficient algorithm for discovering high-utility itemsets from data streams[J]. Journal of Information Science,2011,37(5):532-545.
[7] Song W, Liu Y, Li J. Mining high utility itemsets by dynamically pruning the tree structure[J]. Applied Intelligence,2014,40(1):29-43.
[8] InMon. sFlow accuracy and billing[EB/OL]. http://www.inmon.com/PDF/sFlowBilling.pdf,2015-10-10.
[9] 田俊鋒,王惠然,劉玉玲.基于屬性排序的入侵特征縮減方法研究[J].計算機(jī)研究與發(fā)展,2006,43(Suppl):565-569.
TIAN Junfeng, WANG Huiran, LIU Yuling. Research on Reduction Method of Intrusion Features Based on Ordering Features[J]. Journal of Computer Research and Development,2006,43(Suppl):565-569)
[10] Ivan Bruha. Pre-and Post-Processing in Machine Learning and Data Mining[J]. Machine Learning and Its Applications,2010,18(3):258-266.
[11] 陳才杰.粗糙集理論在知識發(fā)現(xiàn)數(shù)據(jù)預(yù)處理中的研究與應(yīng)用[D].武漢:武漢理工大學(xué),2014.
CHEN Caijie. Research and Application of Rough Set on Data Preprocessing of Knowledge Discovery[D]. Wuhan: Wuhan University of Technology,2014.
[12] Asuncion A, Newman D. UCI Machine Learning Respository[EB/OL].[2015-12-1].http://archive.ics.uci.edu/ml/datasets.html.
收稿日期:2016年1月6日,修回日期:2016年2月14日
作者簡介:姜洪海,男,工程師,研究方向:信息安全。王婷婷,女,碩士,工程師,研究方向:網(wǎng)絡(luò)安全。左進(jìn),男,碩士,研究方向:信息安全。
中圖分類號TP393
DOI:10.3969/j.issn.1672-9722.2016.07.023
Network Boundary Protection Technology Based on Data Stream Mining
JIANG Honghai1WANG Tingting1ZUO Jin2
(1. Confidential Room, Navy North Sea Fleet Headquarters, Qingdao266000)(2. Information Security Department, Naval University of Engineering, Wuhan430033)
AbstractIn view of the problem of network boundary security detection and protection, a network boundary protection model based on data stream mining is proposed. From the view of data flow, the network data is sampled and processed first, then the data stream mining technology is applied to rule mining. Finally, the network is analyzed and controlled according to the mining results. Simulation experiments show that, in the network security detection, the data stream mining method has more advantages than the traditional pattern matching method.
Key Wordsnetwork boundary, protection, data flow, mining
猜你喜歡
都市家教·上半月(2016年12期)2016-12-29 09:44:12
新一代(2016年17期)2016-12-22 12:24:37
東方教育(2016年4期)2016-12-14 08:19:03
新教育時代·教師版(2016年35期)2016-12-07 20:36:36
新課程·中學(xué)(2016年9期)2016-12-01 14:04:58
新課程·中旬(2016年9期)2016-12-01 08:50:37
都市家教·下半月(2016年10期)2016-11-30 00:22:22
散文百家·下旬刊(2016年9期)2016-11-23 22:52:23
教師博覽·科研版(2016年9期)2016-11-23 08:50:22
資治文摘(2016年7期)2016-11-23 00:37:46
