基于改進譜聚類的提升機故障診斷算法
2015-12-20 06:54:48陳少達夏士雄王志曉
計算機工程與設計 2015年12期
陳少達,夏士雄,王志曉
(中國礦業大學 計算機學院,江蘇 徐州221116)
0 引 言
國內外對礦井提升機的故障診斷技術方法[1,2]主要分為3類,分別是基于解析模型、基于信號處理和基于智能技術與知識[3]。譜聚類[4]是這些方法中的一個重要分支,其通過分析一個與故障數據集相關的矩陣的特征向量和特征值來得到故障診斷結果。譜聚類方法具有很多優點,如,僅與數據點的數目有關,而與數據對象的維數無關,可以避免由于特征向量的過高維數所造成的奇異性問題。另外,譜聚類不對數據的全局結構作假設,可以避免“局部最優”的問題[5]。
傳統譜聚類存在一些缺陷與不足,比如,需要人為確定聚類數目,對初始聚類中心敏感和魯棒性較差等。譜聚類采用的節點矩陣主要有兩大類,分別是Laplace矩陣和Normal矩陣。在基于Laplace矩陣進行故障診斷時,無法知道故障數據能劃分為多少類,需要事先人為設置k 值和初始聚類中心點。Normal矩陣在一定程度上解決了該問題:Normal矩陣是半正定矩陣,存在k-1個與其最大特征值1相近的非平凡特征值 (非平凡特征值是值不為1的特征值),且這k-1個特征值所對應的特征向量的元素呈現階梯分布,為故障診斷提供了數目依據,階梯數即為故障種類數t。但是,當提升機故障分類不明顯時,Normal矩陣的這k-1個特征向量就不會呈現十分明顯的階梯狀,而是接近一條連續曲線[6],此時無法通過階梯數目判斷該故障種類數k。
數據場模型[7]作為一種描述數據對象間的非接觸相互作用的數學模型,能夠很好地揭示數據對象的聚類特性。提升機故障數據間并不孤立,而是存在相互的作用與聯系。本文將數據場模型引入到譜聚類方法中,利用數據場模型剔除孤立數據點,并借助數據場模型判斷譜聚類算法的k值和初始聚類中心點,最后利用K-means聚類算法進行聚類劃分。對UCI數據集和提升機軸承故障數據的實驗結果表明,將譜聚類與數據場結合能夠有效提高提升機故障診斷的性能。
1 數據場模型
場作為物體非接觸相互作用所需的介質最早由英國物理學家法拉第在電磁學研究中提出。場可以描述物體在空間中的分布狀況,通過量化物體間的空間分布和變化規律,得到物體間的作用關系。同樣在數據挖掘研究中,大量的數據之間存在著非直接的聯系,可以通過將數據抽象成數域空間,從而建立關于數據的場,應用物理學中場理論和研究方法,對場中的數據進行科學分析與研究,這種建立起來的關于數據的場就叫做數據場[8]。大量的數據場的研究與實驗結果表明數據場理論在處理數據之間的相互聯系上有著非常好的效果,目前數據場被應用于大量的數據挖掘學科研究中,比如人臉識別[9]、層次聚類、傳感器網絡路由[10]等領域。
提升機故障數據間并不孤立,而是存在相互的作用與聯系。數據場模型作為一種描述數據對象間的非接觸相互作用的數學模型,能夠很好地揭示提升機故障數據對象間的聚類特性。因此,本文將數據場模型引入到提升機故障數據中,利用數據場模型刻畫故障數據間的相互作用與聯系。可以從勢、梯度和場強等多個角度描述數據場。
定義 已知空間Ω 中包含數據集D ={x1,x2,…,xn}及其產生的數據場,其中n為數據集D 的個數,令數據對象的位置矢量為x1,x2,…,xn,則任一場點x點處的勢值可表示為
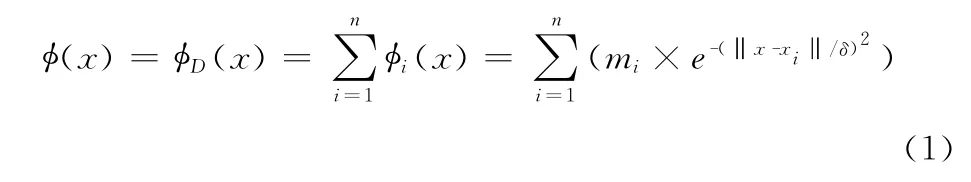

影響因子對于任一場點的勢值有著直接的影響。在式(1)中若δ值很小時,那么e的指數就會非常的小,從而每一個點的勢值都會很小,得到的勢值和就會很小。反之,若δ值很大,那么e的指數就會相對較大,得到的勢值也會較大。因此,需要選擇合適的影響因子δ,使數據場的勢值分布真正體現語義的內在分布。影響因子優選勢熵法[11]。
2 基于改進譜聚類的提升機故障診斷
針對譜聚類算法存在的問題與不足,本文將數據場模型引入到譜聚類方法中,利用數據場模型剔除孤立數據點,并借助數據場模型判斷譜聚類算法的k 值和初始聚類中心點,最后利用K-means聚類算法進行聚類劃分。
2.1 孤立點檢測
孤立點指數據集中與其它數據對象有較大不同的對象,或是那些顯著偏離其它數據的對象。本文給定一個閾值(經過多次實驗得出),孤立點可定義為在給定閾值范圍內勢值最小的數據點。孤立點檢測的具體過程就是計算每個數據點的勢,并選擇最小勢的數據點,如果該數據點滿足孤立點條件,將其作為一個孤立點,標記剔除。具體算法如下:
輸入:數據集Xm=(x1,x2,…,xm)
輸出:孤立點集合
步驟:
(1)依據數據集Xm=(x1,x2,…,xm)構建數據場;
(2)根據式 (1)計算數據場內各點勢值;
(3)找出勢值最小的數據點,將它從數據集Xm=(x1,x2,…,xm)中剔除,存入孤立點集合;
(4)重復上述步驟直至找出所有孤立點。
2.2 聚類數目及初始聚類中心確定
數據場能夠合理、客觀地展示數據對象間相互影響和相互作用,勢值是空間中所有數據對象作用力的疊加,全面體現了數據對象在整個數據空間的重要程度,其勢心更好地表達了數據對象的重心位置,通常稱勢心為 “準數據中心”。通過計算出故障數據的勢心,即可得出聚類個數k及初始聚類中心,從而自動確定了聚類分組數。在剔除孤立點之后,在剩下的數據集中確定聚類個數k 及初始聚類中心,其算法流程如下:
輸入:剔除孤立點后的數據集Xn=(x1,x2,…,xn)
輸出:聚類個數k及初始聚類中心集合
步驟:
(1)依據數據集Xn=(x1,x2,…,xn)構建數據場;
(2)根據式 (1)計算出每個數據對象的勢值,存入勢值矩陣F;
(3)利用Hesse矩陣的特征值確定局部極大值,確定聚類個數k及初始聚類中心。
2.3 故障診斷
基于改進譜聚類的提升機故障診斷算法主要步驟如下:
(1)對 數 據 集Xn=(x1,x2,…,xn)構 建 相 似 度 矩 陣W ∈Rn×n,其中Wij=exp(-d(xi,xj/2δ2)),i≠j;
(2)構造Laplacian矩陣L=D-1/2WD-1/2,其中Dij=Wij,D 為對角矩陣;
(3)根據2.2節給定的算法計算出聚類數目k 及初始聚類中心集合C =(c1,c2,…,ck);
(4)分別計算出Laplacian 矩陣L 的特征值和特征向量,選取特征值中最大的k個值對應的特征向量z1,z2,…,zn,構造矩陣Z =[z1,z2,…,zk]∈Rn×k;

(6)將矩陣Y 中的每一行視為Rn×k中的一個樣本,使用步驟 (3)得出的初始聚類中心集合C=(c1,c2,…,ck)賦予K-means算法的初始聚類,然后對其進行聚類,將其劃分為k類;
(7)將初始樣本點xi劃分為第j 類,當且僅當矩陣Y的第i行被劃分到聚類j 中。
3 仿真實驗
為驗證改進算法的有效性,本文選取UCI數據和提升機軸承故障數據進行測試。本文利用上述數據集對比了3種算法的性能,這3種算法分別是:經典的K-means算法、傳統譜聚類算法 (NJW)和本文提出的改進譜聚類算法(NJW-Fields)進行測試比較。本文實驗環境為:處理器2.94GHz,內存3GB,硬盤320GB,操作系統Windows 7,編譯環境為matlab7.0,所得出的實驗結果為每個算法運行30次取得的平均值。本文以F-measure作為評價指標。
3.1 UCI數據集
Iris數據集可劃分為3個類,每類50個數據,每個類別代表一種類型鳶尾花,150 個樣本在3 個類簇中分布均勻。Wine數據集具有良好的聚類結構,包含178 個樣本,13個數值型特征,可聚為3 個類,每一類樣本數量不同。Zoo數據集共有101個樣本數據,可劃分為7類。
圖1為3種算法在Iris數據集上的每個聚類結果的Fscore曲線圖,可以看出在Iris數據集上,傳統NJW 算法在第二類聚類結果比K-means算法好,但是其第三類聚類結果比K-means算法稍差,然而本文提出的NJW-Fields算法在3個聚類結果都好于或等于其它兩個算法的聚類結果。

圖1 Iris數據集聚類F-score值
圖2為3種算法在Wine數據集上的每個聚類結果的F-score曲線圖,可以看出在Iris數據集上,傳統NJW 算法每一個聚類結果均比K-means算法結果好,本文提出的算法的聚類結果好于傳統NJW 算法聚類結果,說明本文提出的NJW-Fields算法在具有良好聚類結構的數據集上聚類結果的效果明顯。

圖2 Wine數據集聚類F-score值
圖3為3種算法在Zoo數據集上的每個聚類結果的Fscore曲線圖。可以看出,由于Zoo數據集元素線性不可分的關系,K-means算法聚類結果在第3 類和第7 類聚類結果效果都比較差,NJW 算法也在第3 類聚類結果表現較差,兩種算法在其它聚類上的效果也不明顯。相反,本文提出的NJW-Fields算法在各類別的聚類效果較為均勻,總體聚類結果的效果也較為明顯。

圖3 Zoo數據集聚類F-score值
表1為K-means算法、NJW 算法和本文提出的NJWFields算法的MacroF1 值,可以看出本文的算法由于事先為最終的聚類算法自動指定了k 值和k 個聚類中心,在3種數據集上的聚類結果都好于其它兩種算法的聚類結果。
表2為K-means算法、NJW 算法和本文提出的NJWFields算法在多次運行過程中,取得的平均運行時間的比較,可以看出在聚類過程中K-means算法消耗的時間最多,而NJW 算法由于構建了Laplace矩陣,并且取前k 個向量作為聚類數據集,從而加快了算法的運行速度,其運行時間較短。本文的NJW-Fields算法由于事先將初始聚類中心點給予了聚類算法,使得本算法在運行時間大大縮短,明顯快于前兩種算法的程序運行時間。

表1 3種算法在3種數據集MacroF1比較

表2 3種算法在3種數據集上運行的時間比較
3.2 提升機軸承故障數據集
本文搜集了部分提升機軸承故障樣本,樣本數據經過一定預處理,選取其中的典型數據建立故障樣本數據集。每類故障有1630個樣本數據,每個樣本數據含10個信號特征,共有5類故障。部分故障數據見表3。
將提升機故障信號數據分別導入K-means算法、NJW算法、NJW-Fields算法所實現的程序中,得出3種算法的運行時間和MacroF1值對比表格,見表4、表5。

表4 3種算法運行時間對比

表5 3種算法MacroF1值對比
表4為提升機軸承故障數據集分別在K-means算法、NJW 算法、NJW-Fields算法程序上運行統計的時間,可以看出,K-means 算法速度最慢,NJW 算法其次,本文NJW-Fields算法在3種算法中運行時間最短。
表5為提升機軸承故障數據集分別在K-means算法、NJW 算法、NJW-Fields算法得出的F-measure綜合值,可以看出,K-means算法得分最低,為0.5728,NJW 算法其次,得分為0.6183,本文NJW-Fields算法在3種算法中得分最高,為0.6571,根據F-measure得分越高,算法的效果越好的特性,可得出本文提出的NJW-Fields算法較其它兩種算法效果都較好。
4 結束語
礦井提升機一旦發生故障,便會造成巨大的人力和財力損失。礦井提升機故障診斷對煤礦安全生產至關重要。提升機故障診斷方法有很多,譜聚類是一種典型方法。傳統譜聚類需要人為地確定聚類數目,對初始聚類中心敏感,且魯棒性較差。
本文將數據場模型引入到譜聚類方法中,借助數據場模型的優點改善譜聚類算法存在的缺陷與不足,提高故障診斷的性能。改進的譜聚類算法利用數據場模型剔除孤立數據點,并借助數據場模型判斷譜聚類算法的k 值和初始聚類中心點,最后利用K-means聚類算法進行聚類劃分。對UCI數據集和提升機軸承故障數據的實驗結果表明,將譜聚類與數據場結合能夠有效提高提升機故障診斷的性能。
[1]WANG Zhiping.Fault diagnosis and repair technology of coal mining machinery and equipment[J].Coal Technology,2013,32(8):246-247(in Chinese).[王智萍.煤礦機械設備的故障診斷及維修技術探析[J].煤炭技術,2013,32 (8):246-247.]
[2]ZHOU Decai,XIA Shixiong,WANG Zhixiao.Improved fault diagnosis based on the mean C [J].Microelectronics & Computer,2012,29 (11):120-122 (in Chinese). [周德財,夏士雄,王志曉.基于改進C均值的故障診斷 [J].微電子學與計算機,2012,29 (11):120-122].
[3]NIU Qiang.Fault diagnosis of mine hoist semantic environment[D].Xuzhou:China University of Mining,2010 (in Chinese).[牛強.語義環境下的礦井提升機故障診斷研究 [D].徐州:中國礦業大學,2010].
[4]ZHANG Yan,TANG Baoping,DENG Lei.Mechanical fault diagnosis spectral clustering initialization based NMF [J].Journal of Scientific Instrument,2013,34 (12):2806-2811(in Chinese).[張炎,湯寶平,鄧蕾.基于譜聚類初始化非負矩陣分解的機械故障診斷 [J].儀器儀表學報,2013,34(12):2806-2811.]
[5]WANG Na,DU Haifeng,ZHUANG Jian,et al.For troubleshooting network segmentation spectral clustering method [J].Mechanical Engineering,2008,44 (10):228-233 (in Chinese).[王娜,杜海峰,莊健,等.用于故障診斷的網絡分割譜聚類方法 [J].機械工程學報,2008,44 (10):228-233].
[6]FU Chuanyi,XING Jieqing,CHEN Huandong.Spectral clustering and its research progress [C]//Seventh International Conference on Computational Intelligence and Security,2011.
[7]GAN Wenyan,HE Nan,LI Deyi,et al.Based topology discovery potential of online communities [J].Journal of Software,2009,20 (8):258-262 (in Chinese).[淦文燕,赫南,李德毅,等.一種基于拓撲勢的網絡社區發現方法 [J].軟件學報,2009,20 (8):258-262.]
[8]LI Deyi.The era of artificial intelligence research and development network [J].Intelligent Systems,2009,4 (1):1-6(in Chinese).[李德毅.網絡時代人工智能研究與發展 [J].智能系統學報,2009,4 (1):1-6.]
[9]WANG Shuliang,ZOU Shanshan.Face recognition method utilizing expression data field[J].Wuhan University(Information Science Edition),2010,35 (6):738-742 (in Chinese). [王樹良,鄒珊珊.利用數據場的表情臉識別方法 [J].武漢大學學報(信息科學版),2010,35 (6):738-742.]
[10]GUO Liang,ZHU Yi’an,CHI Wenming.Wireless sensor network routing hops protocol based on data field [J].Intelligent Instrumentation and Sensors,2010,18 (5):1214-1216(in Chinese).[郭亮,朱怡安,遲文明.基于跳數數據場的無線傳感器網絡路由協議研究 [J].智能儀表與傳感器,2010,18 (5):1214-1216.]
[11]LI Deyi.Uncertainty artificial intelligence[M].Beijing:Defense Industry Press,2005 (in Chinese). [李德毅.不確定性人工智能 [M].北京:國防工業出版社,2005].
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
