自然語言處理技術在中高職課程銜接中的應用
2015-11-26 03:35:15申玫徐寧趙曉玲
職業教育研究 2015年11期
關鍵詞:課程設置
申玫+徐寧+趙曉玲
摘要:在中高職課程銜接的實際中,存在著中高職專業設置不對口、專業課程內容重復等問題。為了選擇對口專業及查找重復課程,采用人工手段對教育教學文件進行分析研究,效率低、精確性差。而使用計算機自然語言處理技術對中高職教學文件中的文本數據進行分析,可以快速獲得中高職相關專業之間的相似度及專業課程內容之間的重復度,為課程設置提供科學依據。將自然語言處理技術用于青島遠洋船員職業學院“船舶工程技術”專業中高職課程銜接問題上,對相關文件進行分析,得到合理的結論。
關鍵詞:中高職銜接;自然語言處理技術;課程設置
中圖分類號:G712 ? ? ?文獻標識碼:A ? ?文章編號:1672-5727(2015)11-0060-04
中高職教育課程銜接主要存在兩個方面的難題:其一,中高職教育沒有實行專業歸類對口招生報考制度,造成中高職專業設置的對應關系不明確,各院校自行選擇對接專業,造成很多中職專業在升高職時不對口。其二,中高職專業課程內容重復,使中職畢業生升入高職時重復學習相同的課程內容。
在我國,中高職課程銜接仍然依賴于專家經驗。對口專業的判斷及重復課程的篩選是通過對“人才培養方案”和“課程標準”等文本文件的內容進行人工分析。面對多個專業,每個專業數十門課程,采用人工分析,工作效率低,專業的對口程度和課程重復程度難以精確的衡量。為了科學高效地進行中高職課程銜接,不能僅僅依賴經驗和人工分析,而應該運用計算機技術,對各院校多年積累的課程數據文件進行深入分析研究,使中高職課程銜接方法具備精確性和實用性。如何讓計算機對“人才培養方案”和“課程標準”等文本文件進行自動識別分析是科學高效進行中高職課程銜接的關鍵。
自然語言處理(Natural Language Processing,簡稱NLP)就是用計算機來處理、理解以及運用人類語言(如中文、英文等),它屬于人工智能的一個分支,是計算機科學與語言學的交叉學科,又常被稱為計算語言學,是計算機科學領域與人工智能領域中的一個重要方向。 自然語言處理技術可以實現文本分類聚類、文本自動摘要、機器翻譯、檢索系統、問答系統、人機交互等諸多功能,其中重要的一項任務就是文本相似度分析。文本相似度分析最為著名的應用案例之一是搜索引擎,如谷歌、百度等,人們能通過輸入文字來查找相關的新聞等網絡資源,另外,在檢測學術論文是否抄襲方面文本相似度也有其關鍵技術的應用。所謂文本相似度計算是指利用計算機自動計算文本間的相似程度,文本相似度是表示兩個或多個文本之間相似程度的一個度量參數,相似度大,說明文件相似程度高,反之文件相似程度就低。
本文運用自然語言處理中的文本相似度算法對中高職課程相關的文本數據進行分析,能夠快速地找出中高職對口專業,指導課程銜接方案的合理設置。
一、 自然語言處理中的文本相似度算法
文本相似度度量任務就是衡量兩個文本之間語義相似的程度,是自然語言處理中一個非常重要的任務。常規的文本相似度度量方法是將文本轉化詞匯的集合,分析每個詞在單個文本中出現的次數以及在整個語料庫中出現的次數,進而利用每個文本的詞頻信息構建為一個向量,并利用向量間的余弦相似度或Jaccard相似度等方法計算文本之間的相似度。圖1顯示了文本相似度算法的主要流程。
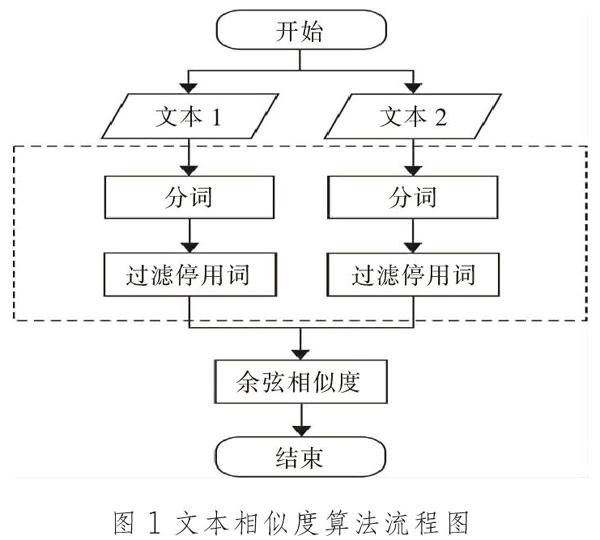
(一)預處理
計算機可以快速地計算出兩列數組之間的相似度,也可以分析出兩個矩陣之間的相似度,但對于兩篇文本來說,相似度的計算要相對復雜。因為,文本是非結構化的數據,數據挖掘的算法要應用到文本對象之上,就必須對文本進行預處理,使其結構化,即將文本轉化為數組或向量。對于中文文本的預處理技術主要包括中文分詞和停用詞過濾兩個方面。
1.中文分詞技術
中文文本與英文文本不同,詞與詞之間沒有空格,讀者閱讀時要根據經驗和語言知識來自行分詞。因而,計算機對于中文的處理相對于以英文為代表的西文處理存在更大的難度。現有的分詞方法主要有:基于字符串匹配的分詞方法、基于理解的分詞方法和基于統計的分詞方法。對于分析者來說,自行開發中文分詞算法難度較大,目前有很多開源的軟件和在線工具都可以完成分詞工作,如Jieba、SCWS、中科院張華平開發的ICTCLAS 、武漢大學沈陽開發的ROST-CM等。
2.停用詞過濾
在文本處理中,有一些詞出現頻繁但意義不大,為了提高文本的分析速度和精度,須將這些詞忽略。比如,“的”、“在”、“是”等幾乎是中文文本中出現頻率最高的詞,這類詞對文本相似度的計算會產生不良的干擾。對于這類問題的解決,可以利用現有的“中文停用詞表”將這些詞進行過濾刪除。但是較為精確的方法是計算文本中每個詞的TF-IDF值,將TF-IDF值為0的詞刪除。
TF-IDF是用來評估某一詞匯對于一個文件集或一個語料庫中的其中一份文件的重要程度的統計方法。詞匯的重要性隨著它在文件中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。比如,“船體的認識”被分詞后變成“船體”、“的”、“認識”,其中“的”是停用詞,而“船體”和“認識”這兩個詞在計算文本相似度中的重要程度是不同的。“船體”這個詞較為專業,“認識”這個詞較為普通,在中高職院校的教學文件中幾乎每篇都會出現“認識”這個詞。當某個詞在所有文本中都會出現,那么,它對文本相似性也就沒有貢獻了。
(二)基于余弦相似度的文本相似度算法
經過預處理之后,兩篇文本被轉換為兩份詞匯表數據,分別用向量D1(n)和D2(m)來表示,其中n和m表示兩表中詞匯的數目。文本相似度工作就是計算分析D1(n)和D2(m)的相似度。具體步驟如下:
(1)將兩份詞匯表中重復多次的詞合并,并將兩份詞匯表匯總成一個總詞匯表,用向量A(p)表示,其中p表示詞匯的數目,p≤m+n。
(2)計算A(p)中的詞在D1(n)和D2(m)中出現的次數,分別用向量B1(p)和B2(p)表示。

根據余弦公式計算cos茲=,即計算B1(p)和B2(p)這兩個向量的夾角余弦,當夾角為0時,余弦值為1,意味著兩個向量重合,即兩文本相同。也就是說余弦值越接近1,兩文本越相似。
二、中高職課程銜接文本數據來源
近年來,中高職教育銜接是我國教育領域的研究熱點,各級教育部門頒發了一系列文件,如《教育部關于推進中等和高等職業教育協調發展的指導意見》、《國家中長期教育改革和發展規劃綱要(2010—2020年)》、《山東省中等職業學校教學指導方案》等。在進行文本相似度分析時,要合理選擇相關文本進行研究。本文所選的數據來源有以下兩個方面:
判斷對口專業的文本文件主要有:地方教育部門或行業指導委員會制定的各專業教育教學指導性文件,如《山東省中等職業學校教學指導方案》或各中高職院校制定的《人才培養方案》。中等職業學校專業教學指導方案是中等職業學校專業建設和專業教學的基本指導文件,內容包括教學計劃和各門課程的課程標準。人才培養方案是人才培養的總體設計,反映著一個學院人才培養的指導思想和整體思路,關系著學院人才培養的內容、途徑和質量。
衡量專業課程內容重復情況的文本文件主要有:地方教育部門、行業指導委員會或院校制定的人才培養方案和課程標準。其中課程標準是指規定某一學科的課程性質、課程目標、內容目標、實施建議的教學指導性文件,是衡量課程內容重復度的主要依據。
三、實例分析
青島遠洋船員職業學院是一所高職院校,其船舶工程技術專業,在面對機械制造技術、焊接技術應用、電氣運行與控制等多個中職專業的畢業生時,如何能對口接收并進行合理的課程設置,是學院開展中高職教育銜接的關鍵。
(一)選擇對口專業
根據教育部頒發的《中等職業學校專業目錄》(2010年修訂),將山東省教育廳開發的6個中職專業(船舶建造與維修、焊接技術應用、機械制造技術、機電技術應用、電氣運行與控制、旅游服務與管理)的教學指導方案與青島遠洋船員職業學院“船舶工程技術專業”人才培養方案進行文本相似度分析,得到數據結果,如圖2所示。
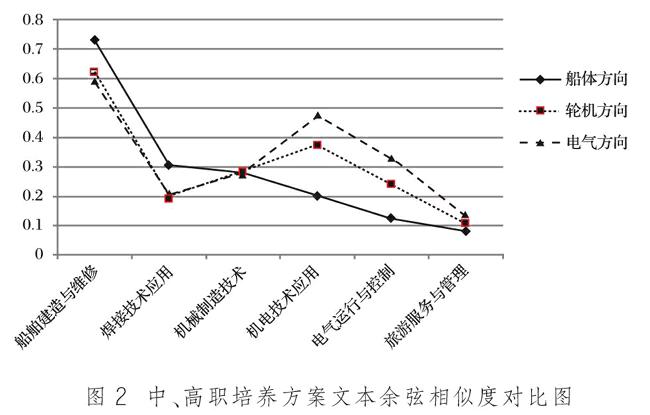
通過對人才培養方案進行文本相似度分析,可以看出,高職“船舶工程技術”專業的三個方向“船體”、“輪機”和“電氣”,與6個中職專業的相似程度各不相同:與“船體方向”對口的中職專業,按相似度依次為“船舶建造與維修”、“焊接技術應用”、“機械制造技術”;與“輪機方向”對口的中職專業,按相似度依次為“船舶建造與維修”、“機電技術應用”、“機械制造技術”;與“電氣方向”對口的中職專業,按相似度依次為“船舶建造與維修”、“機電技術應用”、“機械制造技術”、“電氣運行與控制”。
本文選擇“旅游服務與管理”作為與其他專業對比的參考專業,與船舶工程技術三個方向均不對口,相似度極低,與生活常識相符合。
(二) 判斷重復課程
中高職對口專業經常會出現課程內容重復的問題,專業對口程度越高,其課程重復的可能性就越大。通過分析課程標準的文本相似度,可能得到課程內容的重復程度,從而指導課程安排和課時分配,避免中職學生升入高職后重復學習。
圖3以中職“船舶制造與修理”專業與高職“船舶工程技術”專業船體方向為例,將4門高職課程分別與9門中職課程進行了文本相似度分析。為了直觀判斷出中職課程與高職課程之間的相關度,將高職的任一課程與所有中職課程對比繪制成折線圖,如圖2所示。將高職機械設計、電工基礎、結構制圖、修造工藝這4門課與中職9門課程進行比較,可以得出以下結論。
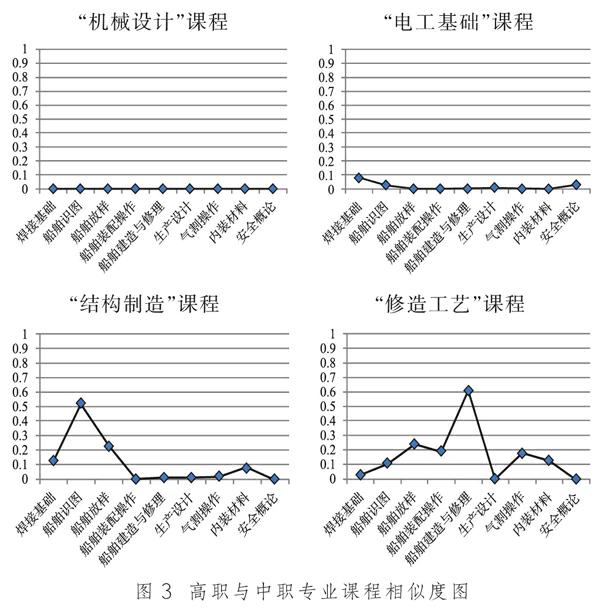
第一,高職機械設計課程與中職各課程相似度均不高,說明課程內容沒有重復;第二,高職電工基礎課程與中職各課程相似度均不高,說明課程內容沒有重復;第三,高職結構制圖課與中職船舶識圖課的相似度非常高,說明課程內容重復;第四,高職修造工藝課與中職船舶建造與修理課的相似度非常高,說明課程內容重復。
通過對每門課程的“課程標準”的文本相似度進行分析,可以準確快速地得出各門課程重復程度,對與中職課程重復程度高的高職課程,如“結構制圖”和“修造工藝”等應考慮免修或適當減免學時。
運用自然語言處理技術,分析文本文檔、為課程設置提供可靠依據,在中高職教育課程銜接領域是全新的嘗試。本文通過使用自然語言處理技術,對中高職銜接相關教育教學文件進行文本相似度分析。通過青島遠洋船員職業學院的實驗驗證,這種方法可以定
量地對中高職教育銜接時對口專業進行篩選,以及對重復課程進行判斷,取得了良好的分析效果,具有較強的科學性和應用性。
將自然語言處理引入中高職教育銜接領域,可以充分利用現有的教學文件數據,提高各項教育教學決策的速度和準確性,促進了職業教育水平的整體提高。隨著自然語言處理技術的不斷發展,通過計算機可以高速地對海量數據進行分析,這些數據不僅包括院校原有的教育教學文檔,還包括行業發展趨勢、社會人才需求等文本數據,并自動生成適應社會發展情況的“人才培養方案”、“課程標準”等教育教學文檔,從而實現教育決策的“人工智能”。
猜你喜歡
科教導刊·電子版(2016年26期)2016-11-21 08:59:37
科教導刊(2016年26期)2016-11-15 19:03:17
考試周刊(2016年84期)2016-11-11 23:16:10
人間(2016年28期)2016-11-10 23:10:28
戲劇之家(2016年20期)2016-11-09 23:45:20
戲劇之家(2016年20期)2016-11-09 23:43:53
科技視界(2016年18期)2016-11-03 20:28:57
現代經濟信息(2016年19期)2016-10-20 19:35:55
現代經濟信息(2016年19期)2016-10-20 19:33:01
科學與財富(2016年28期)2016-10-14 00:11:42
