基于AssiStudy的形成性評(píng)價(jià)系統(tǒng)及學(xué)生進(jìn)程監(jiān)測(cè)*
2015-06-04 06:38:04孟凡茂
現(xiàn)代教育技術(shù) 2015年5期
孟凡茂
(臨沂大學(xué) 外國(guó)語(yǔ)學(xué)院,山東臨沂 276005)
一 引言
在最近的計(jì)算機(jī)輔助評(píng)價(jià)(Computer-Assisted Assessment,CAA)系統(tǒng)中,評(píng)價(jià)策略是基于每道題的正確答案,該答案在學(xué)生答案(Students Answers,SAs)評(píng)價(jià)中被用作參考答案(Reference Answer,RA)。RA和SAs之間的相似性是根據(jù)詞的共現(xiàn),通過(guò)傳統(tǒng)的信息檢索(Information Retrieval,IR)技術(shù)來(lái)確定,尤其是處理較長(zhǎng)文本時(shí),這種方法通常很有效,這是因?yàn)橄嗨频拈L(zhǎng)文本往往同現(xiàn)詞的頻率高。然而,在較短的自由文本答案中,詞的同現(xiàn)可能很少或沒(méi)有,意思卻近似。同時(shí),RA不應(yīng)是唯一的,因?yàn)橐粋€(gè)問(wèn)題可能會(huì)有多個(gè)不同的答案[1]。其次,另外一個(gè)負(fù)面因素是沒(méi)有考慮到教師的評(píng)價(jià)標(biāo)準(zhǔn),僅僅考慮的是RA和SAs之間的相似度。
為此,我們研發(fā)了輔助學(xué)習(xí)(Assisted Study,AssiStudy)系統(tǒng)作為學(xué)生的形成性評(píng)價(jià)工具,該系統(tǒng)能幫助教師設(shè)計(jì)和評(píng)價(jià)考試并監(jiān)測(cè)學(xué)生的進(jìn)展情況。在自動(dòng)評(píng)價(jià)答案的過(guò)程中,該系統(tǒng)依據(jù)單詞及其POS標(biāo)簽,對(duì)每個(gè)問(wèn)題都自動(dòng)生成幾種RAs,這樣,學(xué)生所提交的答案就可以與幾種RAs進(jìn)行比對(duì),從而確保了更為準(zhǔn)確的判分;通過(guò)各種自然語(yǔ)言處理(Natural Language Processing,NLP)技術(shù),AssiStudy先將RA和SAs轉(zhuǎn)換成更易處理的規(guī)范形式,通過(guò)在RA中搜索SAs的近似詞,進(jìn)行單詞匹配運(yùn)算,并根據(jù)SA和RA之間的共有詞義,計(jì)算出近似得分,這種方法更適合于用來(lái)評(píng)估內(nèi)容相似而相同詞幾乎不共現(xiàn)的簡(jiǎn)短答案。
二 CAA的方法綜述
自20世紀(jì)60年代以來(lái),CAA就一直是一個(gè)不斷發(fā)展的開(kāi)發(fā)領(lǐng)域。CAA系統(tǒng)評(píng)估論述題答案的方式分為三類(lèi):形式、內(nèi)容或者二者兼有。目前CAA系統(tǒng)中最為重要的方法是統(tǒng)計(jì)法(Statistical)、潛在語(yǔ)義分析法(Latent Semantic Analysis,LSA)和自然語(yǔ)言處理法。最初的CAA系統(tǒng)的評(píng)價(jià)方法主要用來(lái)捕捉文本結(jié)構(gòu)的相似性;之后的CAA都基于LSA,超出了對(duì)簡(jiǎn)單共現(xiàn)詞的分析,采用兩種解決問(wèn)題的途徑,即基于語(yǔ)料庫(kù)技術(shù)和代數(shù)法來(lái)識(shí)別比較兩個(gè)措辭不同的文本之間的相似性;最近的CAA都是基于NLP技術(shù),能夠進(jìn)行智能分析,捕獲自由文本文檔的語(yǔ)義信息。但是,絕大多數(shù)CAA系統(tǒng)從兩個(gè)維度評(píng)分,而且,這些系統(tǒng)所采用的方法差別很大。最近,教育數(shù)據(jù)挖掘(Educational Data Mining,EDM)應(yīng)運(yùn)而生。EDM具備四項(xiàng)功能:學(xué)習(xí)建模、輔導(dǎo)、信息存儲(chǔ)和評(píng)價(jià)[2]。為了既支持評(píng)價(jià)也支持預(yù)備基架,通過(guò)結(jié)合文本回放標(biāo)記所研發(fā)的模型、環(huán)境對(duì)學(xué)生的探究技能做出推論,這種方法能夠?qū)W(xué)生日志文件和教育數(shù)據(jù)挖掘迅速地進(jìn)行人工編碼。
以上這些系統(tǒng)都不適于我們的用途,因?yàn)樗鼈冎荒芴幚碛⑽奈谋荆倚枰獙W(xué)習(xí)大量的文本。為此,我們創(chuàng)建了AssiStudy系統(tǒng),該系統(tǒng)通過(guò)廣泛應(yīng)用文本預(yù)處理技術(shù)和詞匯網(wǎng)路(WordNet)數(shù)據(jù)庫(kù),極力減弱對(duì)大型語(yǔ)料庫(kù)的需求,從而公平地評(píng)價(jià)內(nèi)容簡(jiǎn)短的文本答案。
三 AssiStudy系統(tǒng)架構(gòu)
鑒于服務(wù)導(dǎo)向式架構(gòu)(Service-Oriented Architectures,SOA)[3]的各種優(yōu)點(diǎn)(如:模塊化、互操作性和可擴(kuò)展性),我們研發(fā)了一個(gè)以SOA為基礎(chǔ)的系統(tǒng)進(jìn)行形成性評(píng)價(jià)和終結(jié)性評(píng)價(jià)。該AssiStudy體系結(jié)構(gòu)主要由以下四個(gè)層所組成:
客戶(hù)端應(yīng)用程序?qū)樱–lient Application):該層用來(lái)處理數(shù)據(jù)和流程的安全性和隱私;
業(yè)務(wù)層(Business):該層包含了AssiStudy的主要模塊,每一個(gè)模塊都包含一組可用的核心服務(wù),在不同層級(jí)中分離業(yè)務(wù)邏輯將會(huì)使得AssiStudy具有模塊化和靈活性;此外,該層能夠以一種簡(jiǎn)易且靈活的方式更新業(yè)務(wù)邏輯;
服務(wù)層(Service):在該層中,可通過(guò)服務(wù)注冊(cè)中心直接調(diào)用域名Web服務(wù);
資源層(Resource):該層包含了AssiStudy的基礎(chǔ)結(jié)構(gòu)資源,即數(shù)據(jù)庫(kù)以及與域相關(guān)的系統(tǒng)和工具,譬如:學(xué)校信息系統(tǒng)和協(xié)作學(xué)習(xí)工具,其中每個(gè)系統(tǒng)和資源都有一組Web服務(wù)。
AssiStudy作為通用而又靈活的系統(tǒng)得以開(kāi)發(fā)。說(shuō)它通用是因?yàn)樗軌驊?yīng)用于任何領(lǐng)域的研究,該系統(tǒng)的創(chuàng)建目的就是處理不同的知識(shí)領(lǐng)域;同時(shí),它又是靈活的,因?yàn)樗瓤梢宰鳛橐粋€(gè)獨(dú)立系統(tǒng),也可以通過(guò)Web服務(wù),增加新模塊或特殊種類(lèi)的應(yīng)用程序。圖1所描繪的就是該系統(tǒng)架構(gòu)的概貌。
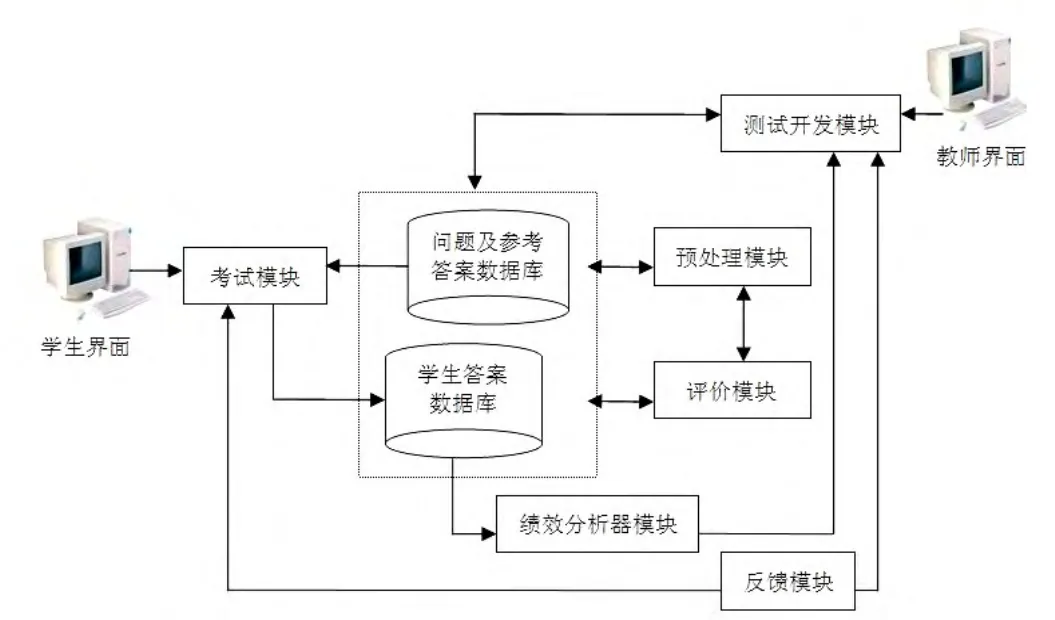
圖1 AssiStudy系統(tǒng)體系結(jié)構(gòu)
1 測(cè)試開(kāi)發(fā)模塊
通過(guò)該模塊,教師可以查詢(xún)?cè)谝郧暗目荚嚺蟹种猩婕澳骋粋€(gè)特定方面的所有問(wèn)題,這些問(wèn)題都被存儲(chǔ)在問(wèn)題及RA(Question&RA)數(shù)據(jù)庫(kù)中。此外,教師有可能查閱每道題目的難度級(jí)別,當(dāng)然,這種難易度的判別要基于之前的考試中學(xué)生的得分情況。再者,對(duì)于某個(gè)指定的題目,教師對(duì)學(xué)生所做的所有考題及得分都有訪(fǎng)問(wèn)權(quán)限,這樣教師在考前就能了解他們要評(píng)估的學(xué)生對(duì)于不同考題內(nèi)容的準(zhǔn)備情況,從而,就能更為恰當(dāng)?shù)卦u(píng)價(jià)每個(gè)班級(jí)的考試情況。
考試評(píng)估由AssiStudy完成,之后老師再進(jìn)行核查。一個(gè)班級(jí)的考試評(píng)判一旦完畢,其中的問(wèn)題以及與此相關(guān)的所有信息都會(huì)被存儲(chǔ)到問(wèn)題及參考答案(Question&RA)的數(shù)據(jù)庫(kù)中,在其后的訓(xùn)練考試時(shí)就可據(jù)此加以說(shuō)明。SAs都存儲(chǔ)在學(xué)生答案數(shù)據(jù)庫(kù)(Student Answer Repository)中;獲得滿(mǎn)分的論述題的SAs也存儲(chǔ)在Question&RA的數(shù)據(jù)庫(kù)中,以便在將來(lái)的評(píng)價(jià)程序中進(jìn)行應(yīng)用。Question&RA的數(shù)據(jù)庫(kù)非常重要,因?yàn)锳ssiStudy系統(tǒng)中幾乎所有模塊的成功與否在很大程度上取決于該數(shù)據(jù)庫(kù)的優(yōu)劣。
2 考試模塊
根據(jù)學(xué)生的狀況以及教師在先前的模塊中所限定的內(nèi)容,訓(xùn)練考試會(huì)從Question&RA庫(kù)中隨機(jī)選擇考試題目。假如大一新生在第一學(xué)期首次考試,該系統(tǒng)將根據(jù)學(xué)生的檔案信息,試題會(huì)依據(jù)前面所述的五個(gè)話(huà)題方面的內(nèi)容自動(dòng)生成,但其中每個(gè)話(huà)題的問(wèn)題數(shù)量和難度由AssiStudy界定。學(xué)生已做過(guò)的試題及得分都被記錄下來(lái),并計(jì)算出學(xué)生對(duì)每個(gè)話(huà)題的定性得分(低、中或高),這些信息都被存儲(chǔ)在Student Answer Repository中。另外,Question&RA的數(shù)據(jù)庫(kù)中儲(chǔ)存了很多試題,除了其他的屬性外,每一道題都被標(biāo)識(shí)出其內(nèi)容歸屬、難度和分?jǐn)?shù),根據(jù)這些信息和一定程度的隨機(jī)化,AssiStudy將會(huì)自動(dòng)從Questions&RA庫(kù)中挑選試題,為每位學(xué)生設(shè)計(jì)出訓(xùn)練試題。評(píng)估訓(xùn)練考試僅靠AssiStudy系統(tǒng)完成,糾錯(cuò)則需由反饋模塊中所設(shè)立的解釋來(lái)彌補(bǔ)。
3 預(yù)處理模塊
(1)檢測(cè)專(zhuān)有名詞:在英文文本情況下,檢測(cè)單詞開(kāi)頭首字母是否大寫(xiě);
(2)刪除標(biāo)點(diǎn)符號(hào):該項(xiàng)任務(wù)就是要?jiǎng)h除所有特殊字符并將所有字母轉(zhuǎn)換為小寫(xiě),除非是專(zhuān)有名詞。特殊字符是指不屬于單詞的一些符號(hào)(如:標(biāo)點(diǎn)符號(hào)),但單詞的重音符號(hào)予以保留,以免誤認(rèn)為是拼寫(xiě)錯(cuò)誤;
(3)校正單詞拼寫(xiě)錯(cuò)誤:用來(lái)檢查拼寫(xiě)錯(cuò)誤的校正器是Jspell[4];除了檢測(cè)錯(cuò)誤拼寫(xiě)外,Jspell會(huì)提示正確的單詞,拼寫(xiě)錯(cuò)誤的單詞會(huì)被正確的單詞替換;
(4)刪除無(wú)用詞:無(wú)用詞與內(nèi)容無(wú)關(guān),刪掉它不影響句子的語(yǔ)義;
(5)詞干提取:在這個(gè)階段,將個(gè)別單詞簡(jiǎn)化為其基本型或詞干,一個(gè)單詞的基本型即是其詞根或詞元;
(6)文本標(biāo)記:該項(xiàng)任務(wù)就是給單詞標(biāo)注詞性(Part of Speech,POS)標(biāo)簽,此項(xiàng)操作也是由Jspell[7]完成;這種分類(lèi)要求對(duì)標(biāo)注相同POS的單詞進(jìn)行對(duì)比;一個(gè)單詞可能會(huì)有多個(gè)POS標(biāo)簽,依照其出現(xiàn)的語(yǔ)境而定;正是由于各種不同的可能詞性,該Jspell形態(tài)分析器會(huì)給每個(gè)單詞標(biāo)注可能的POS標(biāo)簽;為了避免詞性標(biāo)注的模糊性,在編輯程序中將呈現(xiàn)規(guī)范標(biāo)準(zhǔn)的RAs,這樣,教師就可以正確地選擇每個(gè)單詞的POS標(biāo)簽,而其他標(biāo)簽會(huì)自動(dòng)刪除;
(7)同義詞:一個(gè)詞的同義詞列表取決于其POS標(biāo)簽,每一個(gè)單詞會(huì)有一個(gè)與其POS標(biāo)簽相關(guān)的同義詞列表,把涉及該單詞的所有同義詞以及它們的POS標(biāo)簽添加到RA中,從而完全相同的RA會(huì)產(chǎn)生幾種解釋?zhuān)灰粋€(gè)單詞與其每一個(gè)同義詞之間的匹配得分是通過(guò)WordNet.pt詞匯數(shù)據(jù)庫(kù)[5]分析它們之間的最短路徑得出,為了測(cè)量?jī)蓚€(gè)單詞之間的語(yǔ)義關(guān)聯(lián)度,前人已通過(guò)語(yǔ)義網(wǎng)絡(luò)信息研究出了多種測(cè)量方法。本研究中,鑒于在WordNet層次結(jié)構(gòu)方面相對(duì)較高的計(jì)算效率,我們選擇了Leacock&Chodorow(L&Ch)的測(cè)量方法,L&Ch相似度的計(jì)算公式為:
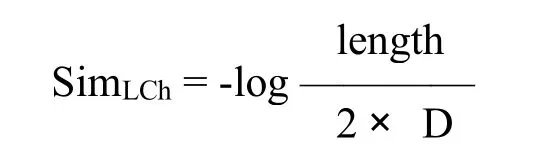
該公式中,length指通過(guò)計(jì)數(shù)節(jié)點(diǎn)所得的兩個(gè)概念之間最短路徑的長(zhǎng)度,D代表分類(lèi)的最大深度。
4 評(píng)價(jià)模塊
該模塊能夠自動(dòng)得出一個(gè)分?jǐn)?shù),并由此根據(jù)規(guī)范的RA和 SA的意義顯示出這兩者之間的相似性,從而勝過(guò)簡(jiǎn)單的詞匯匹配。這一目標(biāo)的實(shí)現(xiàn)是在計(jì)算出SA和 RA之間總的語(yǔ)義相似度之后,根據(jù)相應(yīng)的RA的語(yǔ)義相似度,構(gòu)建SA向量。根據(jù)SA向量和RA之間的距離,RA就是該單位向量,如圖2所示。
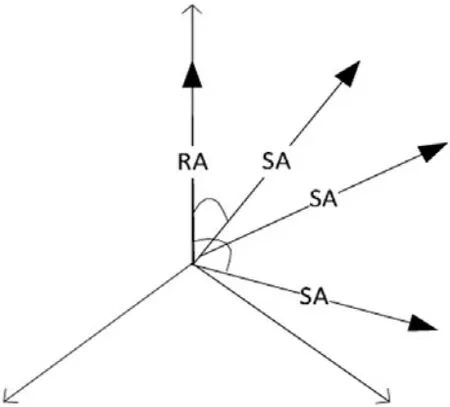
圖2 空間向量模型
SA向量和RA向量之間的相似度取決于歐幾里得(Euclidean)點(diǎn)積,公式如下:

5 反饋模塊
AssiStudy提供的反饋由學(xué)生得分和RA中所收集的答案信息構(gòu)成。為此,SA中遺漏或不完整的要點(diǎn)會(huì)在RA中得以搜索,而且相關(guān)的分?jǐn)?shù)以及詳細(xì)的解釋會(huì)得以呈現(xiàn)。AssiStudy自動(dòng)反饋的其中一大優(yōu)點(diǎn)就是學(xué)生獲知反饋迅捷,即測(cè)試提交完畢學(xué)生即可獲得反饋,如此能促進(jìn)學(xué)生更加深入的學(xué)習(xí);而教師能夠看到每位學(xué)生的答卷及評(píng)語(yǔ),了解學(xué)生的得分情況,同時(shí),也能知道全班遺漏的最為重要的知識(shí)點(diǎn),從而能夠迅速獲悉整個(gè)班級(jí)的學(xué)習(xí)情況。
6 表現(xiàn)分析器模塊
該模塊是基于統(tǒng)計(jì)和數(shù)據(jù)挖掘(Statistics and Data Mining)技術(shù)研發(fā),其設(shè)計(jì)目的是分析有關(guān)評(píng)判結(jié)果的數(shù)據(jù)。我們研發(fā)了幾種數(shù)據(jù)挖掘模式來(lái)洞察學(xué)生有關(guān)訓(xùn)練考試成功與否的情況。最為有用的模式通過(guò)k平均聚類(lèi)算法(Clustering Algorithm K-means)[6]獲取,這樣就能獲悉哪些問(wèn)題難哪些問(wèn)題易,并通過(guò)信息分析,修改問(wèn)題的難易度。而使用C4.5分類(lèi)算法(Classification Algorithm C4.5)[7],對(duì)學(xué)生訓(xùn)練考試進(jìn)行分析,就能推斷出學(xué)生或班級(jí)對(duì)于即將來(lái)臨的評(píng)價(jià)考試的準(zhǔn)備狀況。另外,通過(guò)關(guān)聯(lián)規(guī)則Apriori算法(Association Rule Algorithm Apriori)[8],就能發(fā)現(xiàn)訓(xùn)練試題與學(xué)生最終成績(jī)之間的關(guān)系,從而了解學(xué)生對(duì)哪些問(wèn)題準(zhǔn)備得更好。
四 評(píng)價(jià)與分析
為了檢查AssiStudy系統(tǒng)在提高過(guò)關(guān)率方面的有效性,我們進(jìn)行了一次測(cè)試。表1顯示:使用AssiStudy的學(xué)生平均過(guò)關(guān)率比不使用該系統(tǒng)的學(xué)生的過(guò)關(guān)率高(t=57.65,df=533,p<0.05),因此,通過(guò)AssiStudy能提高通過(guò)率。
同時(shí),我們也對(duì)考試自動(dòng)評(píng)價(jià)與教師評(píng)價(jià)進(jìn)行了對(duì)比。表2顯示了2012-2013學(xué)年4次考試中教師評(píng)分和系統(tǒng)評(píng)分情況。

表1 經(jīng)過(guò)AssiStudy訓(xùn)練和沒(méi)有經(jīng)過(guò)訓(xùn)練的過(guò)關(guān)學(xué)生數(shù)量對(duì)比
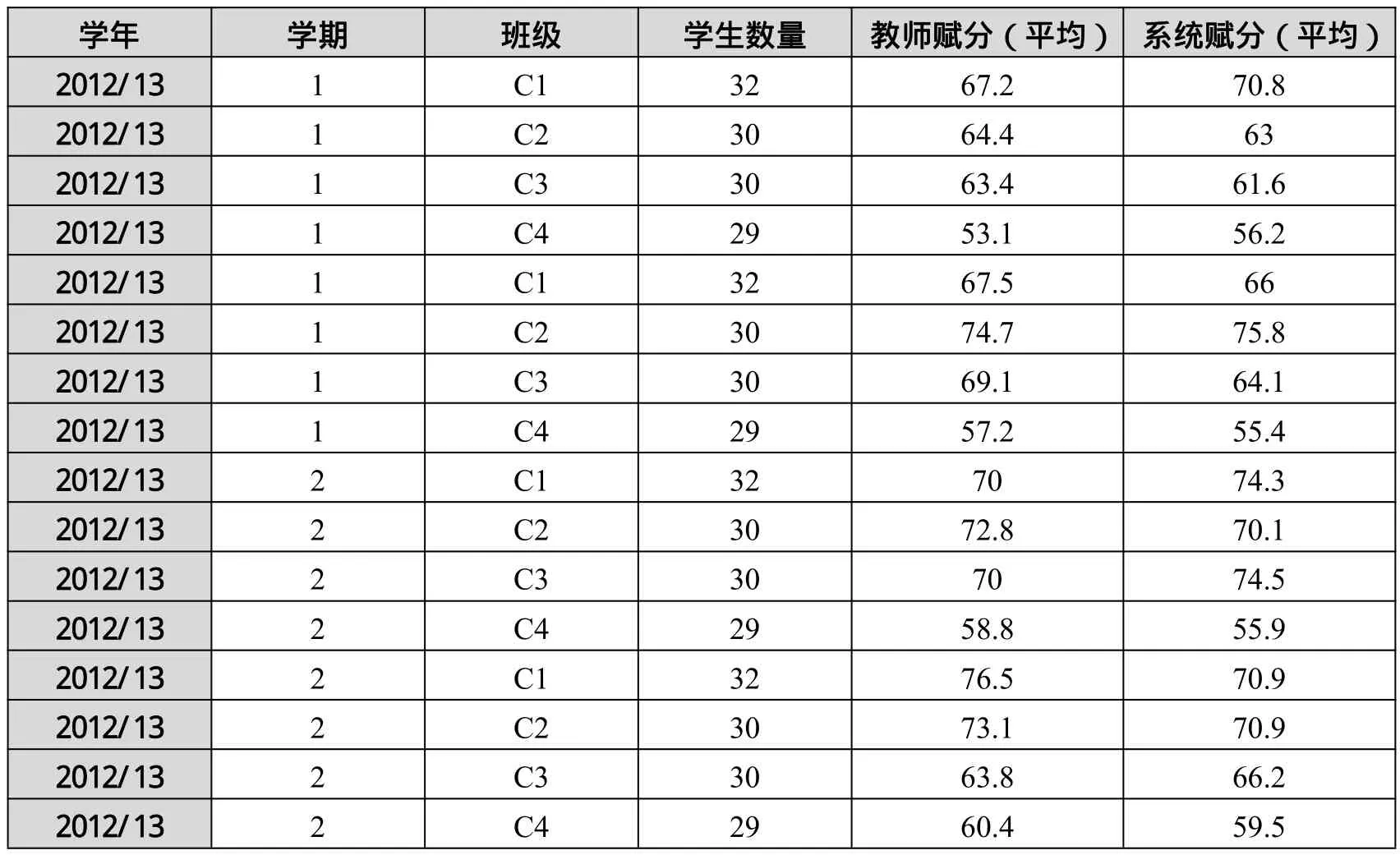
表2 2012-2013學(xué)年考試中的分值情況
結(jié)果顯示:對(duì)于不同的考試評(píng)分,教師判分與系統(tǒng)判分差別并不太大;教師評(píng)判與系統(tǒng)評(píng)判之間的皮爾遜相關(guān)系數(shù)(Pearson correlation)為0.88。
AssiStudy系統(tǒng)的誤差分析顯示,誤差分為兩類(lèi):漏判(False Negatives,F(xiàn)N)和誤判(False Positives,F(xiàn)P)。當(dāng)考試得分比應(yīng)得分?jǐn)?shù)低時(shí),就會(huì)發(fā)生FN;而FP是指判分過(guò)高。一般而言,如果系統(tǒng)與教師判分不匹配,通常是因?yàn)榻處熍蟹致愿撸@是因?yàn)镾A太抽象或比RA短少,而在這種情況下,AssiStudy系統(tǒng)判分會(huì)比預(yù)期的分?jǐn)?shù)低,這是因?yàn)橄到y(tǒng)的判分標(biāo)準(zhǔn)是基于詞的匹配,而且,有些SAs在RA中無(wú)匹配的格式所致,但是,教師卻能根據(jù)SAs推斷出學(xué)生對(duì)于所學(xué)的理解程度,從而,判分時(shí)給出較高的分?jǐn)?shù),這樣就增大了系統(tǒng)評(píng)價(jià)與教師評(píng)價(jià)之間的差異;而當(dāng)學(xué)生不知道問(wèn)題答案,碰巧又寫(xiě)出了一些與RA相匹配的單詞時(shí),系統(tǒng)判分最易發(fā)生FP。
五 結(jié)論
AssiStudy系統(tǒng)不僅可以作為對(duì)學(xué)生考試的形成性評(píng)價(jià)工具,也能幫助教師創(chuàng)建并評(píng)價(jià)考試,還可以監(jiān)控學(xué)生的學(xué)習(xí)進(jìn)展?fàn)顩r。實(shí)驗(yàn)證明,采用AssiStudy系統(tǒng)進(jìn)行訓(xùn)練的學(xué)生比不參與的學(xué)生會(huì)獲得更高的成績(jī),考試通過(guò)率大大提高;而對(duì)于教師而言,該系統(tǒng)的研發(fā)非常實(shí)用,因其能大大減輕教師閱卷的工作量。
[1]Noorbehbahani F,Kardan A A.The automatic assessment of free text answers using a modified BLEU algorithm[J].Computers&Education,2011,(2):337-345.
[2]Pe?a-Ayala A.Educational data mining:a survey and a data mining-based analysis of recent works[J].Expert Systems with Applications,2014,(4):1432-1462.
[3]Al-Smadi M,Gutl C.SOA-based architecture for a generic and flexible e-assessment system[A].In Education engineering(EDUCON),2010 IEEE[C].2010:493-500.
[4]Sim?es A M,Almeida J J.Jspell.pm–a morphological analysis module for natural language processing[A].In Actas do XVII Encontro daAssocia??o Portuguesa de Linguística[C].Lisbon,2001:485-495.
[5]Marrafa P,Amaro R,Chaves R P,et al.WordNet.PT new directions[A].In Proceedings of GWC.2006,(6):319-320.
[6]Hartigan J A,Wong M A.Algorithm AS 136:a k-means clustering algorithm[J].Journal of the Royal Statistical Society,Series C(Applied Statistics),1979,(1):100-108.
[7]Quinlan J R.C4.5:Programs for machine learning Morgan Kaufmann,1993,(1):235-240.
[8]Agrawal R,Imieli_nski T,Swami A.Mining association rules between sets of items in large databases[J].ACM SIGMOD Record,1993,(2):207-216.
猜你喜歡
閱讀(快樂(lè)英語(yǔ)高年級(jí))(2020年8期)2020-01-08 02:21:16
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
