文言信息的自動抽取:基于統計和規則的嘗試
2015-04-12 11:30:52虞寧翌饒高琦1荀恩東
中文信息學報 2015年6期
虞寧翌,饒高琦1,,荀恩東
(1.北京語言大學語言科學院,北京100083;2.北京語言大學信息科學學院,北京100083)
1 引言
中國語言由古代文言文到現代白話文經過了近三千年的發展演變。排除字形的變化,語言本身在詞匯、語法和篇章層面都產生了巨大變化,但卻不失其連續性。這一特點使得在大時間跨度上研究漢語特征變化成為重要課題。對書面語進行文言/白話標注有助于對語言進行歷時性的描寫,分析語言風格,了解漢語書面語的發展情況。同時也方便對文言、白話混雜語料的分類和加工。
傳統的語言學自省的方法有其固有的主觀、高成本和緩慢的局限性。在文言、白話分類標注這一問題中引入自然語言處理的成熟方法和模型,結合專家自省知識,則有助于克服以上問題。本文研究中發現的特征和方法反過來又可以深化對漢語演變作為一個連續統的認識,因而具有一定的理論價值。本文的研究在一定程度上驗證了王力先生提出的觀點,即文言與白話的分野不在詞匯與句式,而是虛詞系統[1]。
在語料庫構建的實踐中,我們遭遇了文言文語料和白話文語料混合的情況,這給語料庫的科學平衡構建帶來了一定困難。在語言生活的調研工作中,社會大眾的文言使用情況是重要的調查目標。在現代書面語寫作中文言、白話夾雜的現象也比比皆是,這給句法語義分析帶來很大困擾。因而在大規模語料中通過計算手段自動標注文言文/白話文也具有重要的實踐和工程價值。本文研究發現使用基于字的統計特征可以實現對文言文較為精確的標注。
文章的組織結構如下:第2節簡述了現有相關研究;第3節描述了語料和測試集的構建;第4節描述了基于規則的方法;第5節描述基于統計的方法;第6節是結論與展望。
2 研究現狀
經過調研,與本文研究方向相同的研究工作并不多,相關的研究方向有漢語年代劃分、用字特征、語言風格、中文文本分類等方向。語言的發展是一個有序、緩慢、逐步演變的過程。社會語言學的理論揭示:語言是在穩態中變化,在變化中保持穩態。穩態不同于靜態。自然語言處理通常關注共時語料,也即一個時間切片上的語言數據。大規模語料庫亦少對時間信息進行標注。而實際上,語言是不斷發展變化的。語料數據亦有其時效性。這不僅表現在詞匯短語的分布上,也表現在語義乃至語言風格上[2-3]。
石毓智對漢語發展的雙音化趨勢和動補結構進行了探究。漢語的雙音化并非一蹴而就,是自漢代以來逐漸發展的[4]。胡裕樹在1981年對雙音化情況進行過統計,不計詞類區別,在3 000個最常用的詞中,75%是雙音節詞,還有大量未列入的雙音節常用詞。總體上說,雙音詞占漢語詞匯的80%以上[5]。呂叔湘在1961年提出,在很多情況下,單音節詞只有加上一個音節(詞綴)才能獨立成詞或作為句子成分[6]。
2012年和2013年,Mihalcea等和Popescu等[7-8]提出了時代消歧和時代檢測兩個任務及其基線。前者使用多種Welch測試、Run測試、最小二乘、Ratio、斯皮爾曼和Kendall測試等統計方法來判斷重要詞語(尤其是政治相關詞語)在近兩百年的Google N-gram Corpus的分布,以判斷其是否隨機,由此來進行歷史時期分割。Mihalcea等提出的時代消歧任務是在詞語中挑選出具有時代區分力的詞語。
在歷時語料的建設方面,北京語言大學建立的現代漢語詞匯歷時檢索系統,使用了《貴州日報》《福建日報》和《人民日報》共計8億字、4.7億詞,并提供在線檢索①http://nlp.blcu.edu.cn/historical20%computing。時間跨度為1949—2013年[9]。北語漢語語料庫BCC的文學頻道則收集了時間跨度約為100年的文學語料24億字,并提供在線檢索[10]②http://bcc.blcu.edu.cn/index.php?corpus=1。
3 測試集與統計基線
3.1 單句測試集
單句測試集包括1 372句文言文和1 538句白話文,共有2 900句,文言文和白話文的數量大致平衡。文言文部分選用了《論語》中的單句。《論語》形成于我國春秋時期,是最早的語錄體文集,記錄了孔子及其弟子的言行。《論語》作為儒家經典文學,有悠久的歷史,其中沒有白話文成分,是典型的文言作品。《論語》有較為成熟的句讀,易于程序切分為單句,方便使用,白話文部分采集自《人民日報》。《人民日報》是我國第一大報,使用了典范的現代漢語白話文,用字用詞十分規范。
測試集的句子長度保持在5—100字之間。若句長小于5個字,句子中可判斷特征不明顯,實際可判斷力過差,會降低測試結果的有效性。考慮單句的實際情況,句長超過100字的現象并不常見。古漢語的平均句長通常小于現代漢語的平均句長。若采用大量特殊的過長現代漢語作為測試集,可能影響標注,再則缺乏效力。
測試集樣例:
文言文:<文> 有朋自遠方來,不亦樂乎?
<文> 孝弟也者,其為仁之本與!
白話文:<白> 那么,增收的原因何在?
<白> 移風易俗,提倡健康文明的生活習慣!
3.2 段落測試集
段落測試集包括1 050段古漢語和1 050段現代漢語,共2 100段,古漢語和現代漢語的數量持平。文言文部分選用了《古文觀止》和《全唐文》的段落。《古文觀止》是歷代文言散文的精選集,清康熙年間編纂;《全唐文》是唐代及五代十國的文言散文,清嘉慶年間編纂。兩者均為清代中期前編纂,選文于上古和中古漢語,是典范的文言文作品,不包含白話文,而且其段落長度適中,適宜被選作段落測試集。
白話文部分選用了《人民日報》和《王朔文集》的段落。《人民日報》的段落中包含較多阿拉伯數字和字母,在文言文中沒有阿拉伯數字和字母,因而不宜在測試集中使用,在尋找純漢字段落之外,我們還引入了《王朔文集》。王朔從20世紀80年代開始寫作,作品內容為典型的當代白話文。《現代漢語》等教材亦多使用其內容做例句、例文。
測試集中,段落長度基本保持在100—300字之間。段落測試集格式與單句測試集相同。段落測試集僅用于對單句測試集結果的補充驗證。
3.3 報章體測試集
報章體測試集包括1 000段梁啟超的作品。梁啟超是報章體文學的代表人物,他的作品文白相間,在近代中國具有很大的影響力。測試集被同時標為文言文和白話文兩種形式,用于測試。段落長度基本保持在100—300字之間。該測試集并不用于測試方法性能,僅用于研究報章體文學的用字特性。
測試集舉例如下所示。
<白>|<文> 四曰厲國恥。務使吾國民知我國在世界上之位置,知東西列強待我國之政策,鑒觀既往,熟察現在,以圖將來。內其國而外諸邦,一以天演學物競天擇、優勝劣敗之公例,疾呼而棒喝之,以冀同胞之一悟。
3.4 評測標準
測試集中每個單句或段落之前有文言文和白話文的區別標注。將測試集中的一個條目通過文言文和白話文的判別模型,將測試語句標注為古漢語或現代漢語,然后和原語句標注情況進行比較,分別獲得白話文和文言文的正確率P、召回率R和F值。
正確率P=提取出的正確信息條數/提取出的信息條數
召回率R=提取出的正確信息條數/樣本中的信息條數
F值=正確率*召回率*2/(正確率+召回率)
3.5 基線0
將測試集的結果全部判斷為文言文或白話文。當全部判斷為白話文時,白話文的正確率約為0.529,召回率為1,F值約為0.692;當全部判斷為文言文時,文言文的正確率約為0.471,召回率為1,F值約為0.641。
在以下的實驗中,測試集與訓練語料均沒有交疊。
4 基于規則的方法
4.1 用字特征
漢語在漫長的演變歷史中存在雙音化現象,也即越古老的文本中,越多的詞語為單音節詞,而越現代的則越多使用多音節詞(雙音為主)。在大多數情況下,古代的單音節詞在現代漢語的譯文中都以雙音節詞的形式出現。所以,在通常情況下,現代漢語的句長長于古漢語。以論語為例,原文總字數為21 475字,某譯文總字數為29 725。原文總字數約占譯文總字數的72.2%。
隨著語言的演變,常見字集的內容出現了明顯的轉移。例如,文言文中常見的指示代詞“斯”、“彼”等,在白話文中逐漸被“這”、“那”等所取代;文言文中常用的人稱代詞“爾”、“其”等,在白話文中表示為“你”、“他”等。常見字的出現情況對古漢語、現代漢語的區分可以起到一定的參考作用[1]。
通常認為,實詞往往具有鮮明的時代特征。但是在本文任務中,實詞需要謹慎對待。很多實詞,如“經濟”、“民主”、“國家”等,看似可以成為白話文的特征詞,實則其歷史可追溯到中古乃至上古,只是其含義與今日不同罷了[11]。因而實詞反而不適合作為判別特征來使用。
4.2 句式分析
在文言文中,特殊句式主要有四種,分別為:判斷句、被動句、倒裝句、省略句。有些句式可以用結句式直接表示出來,例如,判斷句“……者,……也”、“……也”等,被動句“……見……于”、“為……所”等。還有一些無法用結句式直接表示出來,例如,倒裝句、省略句。
在現代漢語中,特殊句式有六種,分別為:把字句、被字句、連動句、兼語句、判斷句,存現句。其中,把字句、被字句可以直接由“把”字、“被”字判斷,其他句式的判斷很難形式化。但是,由于白話文中“把”字、“被”字不僅僅是介詞,還會出現在其他詞語里,所以僅憑“把”字、“被”字很難確定是否是把字句、被字句。文言文的特殊句式對文言文、白話文的區分可以具有的參考價值相對較大[12-13]。因此本文在基于規則的方法中使用文言句式來進行分析。
4.3 基于規則的實驗
選取常見的古漢語24個虛詞:之、乎、者、也、耶、矣、哉、於、吾、汝、爾、而、何、乃、其、且、若、所、為、焉、以、因、于、則。但是我們注意到,許多現代漢語的詞中也包含有這些虛詞。考慮到測試集本身不做分詞處理,我們從現代漢語詞典中匹配含有該虛詞的現漢詞語,形成一個排歧詞表。對于測試集句子,匹配到該虛詞,且又不是排歧詞表中的詞語,則虛詞數加1。匹配結束后,返回該句虛詞總數。
構造句式函數,將測試句輸入。匹配測試句中是否出現下列句式:以“也”作為結尾,“……者,……也”,“為……所”,“無乃……于”。若出現一次句式,則句式數加1。匹配結束后,返回該句句式總數。
將測試集中的句子輸入虛詞函數和句式函數,若其中一個函數的返回結果大于0,則輸出句子為文言文,反之,輸出句子為白話文。
經過測評,白話文的判斷正確率約為0.821,召回率約為0.458,F值約為0.588;文言文判斷的正確率約為0.594,召回率約為0.888,F值約為0.712。
由測評結果可知,通過虛詞和句式規則測評后,白話文判斷的正確率較高,但是召回率不足,文言文判斷的正確率不足,但是召回率較高。出現這種現象的原因主要有:1.文言文中的常用虛詞在白話文中仍有大量運用,且還是作為虛詞運用;2.文言文中的實詞在白話文中仍有運用;3.文言文中存在不包含虛詞的單句。
這從一個側面上反映了現代漢語和古漢語之間沒有明確分界的事實。
4.4 基于規則的優化實驗
在基于規則的實驗中,我們進行兩方面的擴充:1.虛詞。2.句式。
在虛詞的擴充情況中,不僅僅考慮虛詞是否存在,而是將虛詞出現的次數與句長聯系起來。虛詞集的內容與4.3中相同,虛詞出現次數通過虛詞出現的次數減去含虛詞的白話文詞語(排歧詞表內容)出現的個數得到,然后除以句子長度。
在句式的擴充情況中,將原來的四種句式擴充為26種句式,包括:句首的“夫”、“若夫”、“且夫”、“今夫”、“孰”、“吾”;標點前的“也”、“矣”、“焉”、“乎”、“諸”、“邪”、“哉”、“之”、“耶”、“曰”;以及固定搭配“如……何”、“若……何”、“奈……何”、“何以……為”、“何……之有”、“……者,……也”、“為……所”、“問于”、“之以”、“無乃……于”。對測試集語句進行匹配以考察其是否滿足句式。
在測試中,若滿足句式或者虛詞頻率大于閾值t,就判斷句子為文言文,否則,為白話文。本文對虛詞頻率的閾值t進行了對比實驗。
圖1是文言文正確率和F值在虛詞頻率的閾值t改變情況下的變化情況。橫坐標為虛詞頻率的閾值,主縱坐標為文言文F值,次縱坐標為正確率。由圖可知,文言文正確率隨t值減小,F值在t=0.08的情況下達到0.941。
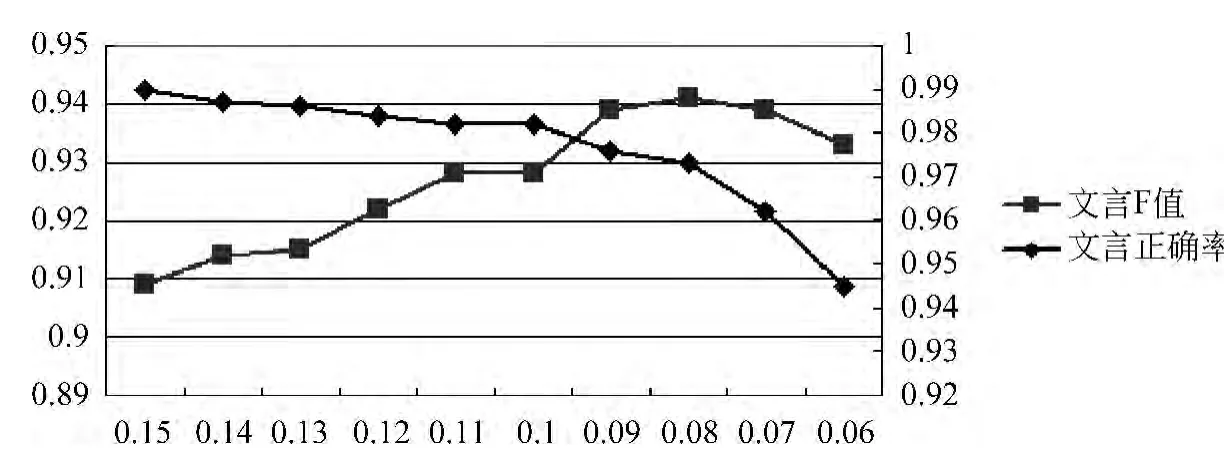
圖1 文言文正確率和F值對比圖
圖2是白話文正確率和F值在虛詞頻率的閾值t改變情況下的對比圖。橫坐標為虛詞頻率的閾值,主縱坐標為白話文F值,次縱坐標為白話文正確率。由圖2可知,白話文正確率隨t值減小而增大。白話文的F值在t=0.08的情況下最高達到0.95。
綜上所述,當虛詞頻率的閾值t為0.08時,優化規則模型最優。由4.3節可知,虛詞本身的存在對現代漢語的影響比較大,但是白話文的句長普遍長于文言文,且白話文虛詞數少于文言文的虛詞數。所以,虛詞數除以句長得到的虛詞頻率在白話文中會遠遠小于文言文,因此t值可以發揮其分類作用。圖3為兩種規則方法和基線0的F值比較。
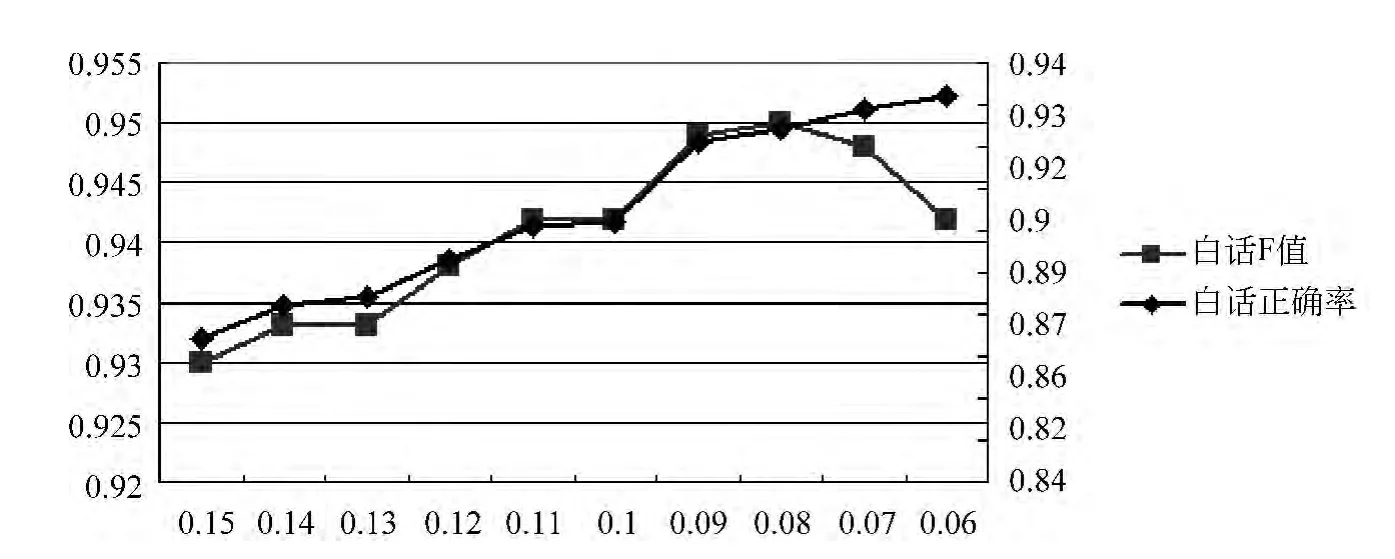
圖2 現代漢語正確率和F值對比圖

圖3 基線0、規則和優化規則的F值
5 基于統計的方法
5.1 N-gram語言模型
本文在BCC語料庫古漢語頻道選取清代中期以前的文言文語料1.5億字(gbk編碼下約300M)和2000年前后的《人民日報》語料1.5億字(gbk編碼下約300M)。我們使用Cambridge-CMU language toolkit實現了語言模型[14]。
選用單句測試集,在測試的過程中,將測試語句在一元、二元、三元狀況下頻率的log值相加作為分數。將在文言模型和白話模型中得到的分數對比。將句子標記為得分較高的模型。例如,
有朋自遠方來,不亦樂乎?
白話分值:-36.470 589
文言分值:-33.058 824
文言分值高于白話分值,則標記為文言。
將標記結果與測試語句人工標注結果對比,得到模型的正確率、召回率和F值。從中選取F值最高,且大小適中的模型為最優模型。本文認為F值越大,模型測試的結果越好。
圖4是三元與二元語言模型的訓練語料規模大小對標注F值的影響。

圖4 三元與二元模型對比圖
在三元模型中,白話模型測試結果的F值隨模型語料的增大呈振蕩下降趨勢。在模型為50M時,F值最大,約為0.785;在模型為100M時,F值降為約0.590;當模型為150M—300M時,F值保持在0.3—0.2左右。
文言模型測試結果的F值當模型為100M時最大,約為0.751;當模型為50M時,F值最小,約為0.557;當模型為150M—300M時,F值保持在0.67左右。
在二元模型中,現漢模型測試結果的F值隨模型語料的增大所呈現的趨勢與三元模型相仿。文言模型測試結果的F值當模型為100M時最大,最大值約為0.749;當模型為50M時,F值最小,約為0.491;當模型為150M—300M時,F值保持在0.67左右。
而一元語言模型的表現則呈現了巨大差異,白話模型測試結果的F值在模型為50M時為0,測試集沒有判斷為白話的結果,也即在較小的訓練集上,文言文和白話文的用字差異無法得到體現;當模型為100M時,F值最大,約為0.985;當模型為150M—300M時,F值基本不變,保持在0.98左右。圖6為文言、白話在三元、二元、一元模型下最好F值的對比。
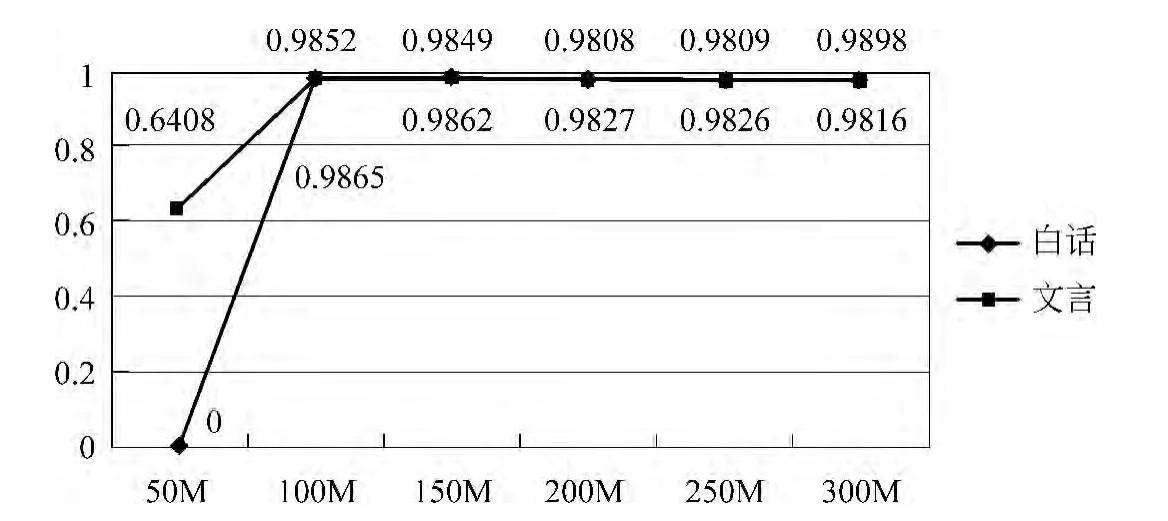
圖5 一元模型對比圖
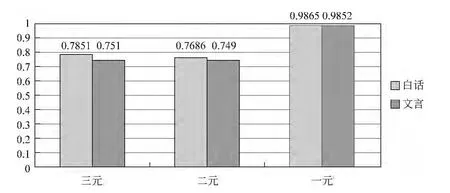
圖6 語言模型元數對標注F值的影響
其中,50M的白話模型在三元、二元情況下最優,其余情況下,均為100M的古漢、現漢模型最優。三元模型最好的F值,文言約為0.751,白話約為0.785。二元模型最好的F值,古漢約為0.749,現漢約為0.769。一元模型最好的F值,古漢約為0.985,白話約為0.986。
經對比,在各模型不同元數下的標注結果中,一元狀況下100M古漢現漢對比模型的標注結果最優。在接下來的實驗中,主要針對100M模型進行測試、標注和優化。
5.2 段落測試實驗
用段落測試集測試100M語言模型,以檢測單句測試集中句子長度對于模型標注的偏差是否具有有限性。
圖7為100M文白對比模型通過段落測試集后,在一元、二元、三元情況下的測試結果。

圖7 段落測試集測試結果圖
100M模型經過段落測試集測試,測試結果大致與在單句測試集中相似。在一元模型中,文言、白話識別的F值大于0.999,測試結果略優于單句測試集。由此可見,100M一元模型情況下測試結果優秀不是偶然情況。
用報章體測試集測試100M語言模型,以檢測報章體文學的用字特征。
圖8為100M文白對比模型通過報章體測試集后,在一元、二元、三元模型中的測試結果。
若報章體測試集被標記為文言文,在100M模型中被標注后,在一元、二元、三元模型中,F值均在0.9以上;若報章體測試集被標記為現代漢語,F值最小為0.01,最大值為0.239。由此可知,報章體大多會被模型識別為文言文。
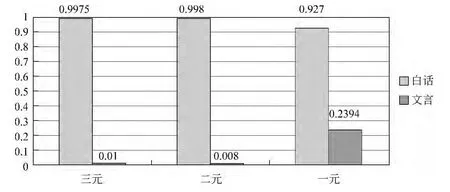
圖8 報章體測試集測試結果圖
據分析,報章體的主要句式基本與白話文相同,語法也與白話文類似。由于選用測試模型是基于字的統計模型,所以可以推測,報章體被判斷為文言文的主要原因是大量使用文言文的基本用詞。
5.3 基于機器學習的方法
本文還使用樸素貝葉斯、最大熵和決策樹(ID3算法)三種統計機器學習模型①本部分的機器學習模型使用麻省大學的MALLET工具包實現[14]進行了標注實驗。我們選取10M古漢語單句語料和10M現代漢語單句語料。使用特征為標注、行號與字符串(基于字)。其中最大熵模型表現最好,F值達到了0.967和0.968。
圖10是本文所使用諸方法的測試結果。其中N-gram為使用一元模型時的結果。基線0和基線1的結果相差不太大。基線1在文言的標注中優于基線0,在白話文的標注中弱于基線0,這與規則的使用情況有關,因為基線1使用的規則主要是針對文言文特征的,而不考慮其對白話文特征的影響,所以對文言文的標注較為有利。由優化規則實驗可以判斷出,規則方法對本任務確有意義,但是規則本身的尋找和優化過程存在一定難度,需要進行大量實驗,得到較為完善的規則庫。
基于統計的模型標注效果明顯優于基線0和基線1,由此可以確定基于統計的實驗有其研究的意義,且可以得到了一個相對較好的結果。Unigram模型的F值最高,達到0.98以上,是實驗過程中構建的最優模型,且相較于樸素貝葉斯、最大熵和決策樹三個機器學習模型,計算成本和時間成本都很低。

圖9 樸素貝葉斯、最大熵、決策樹結果對比圖
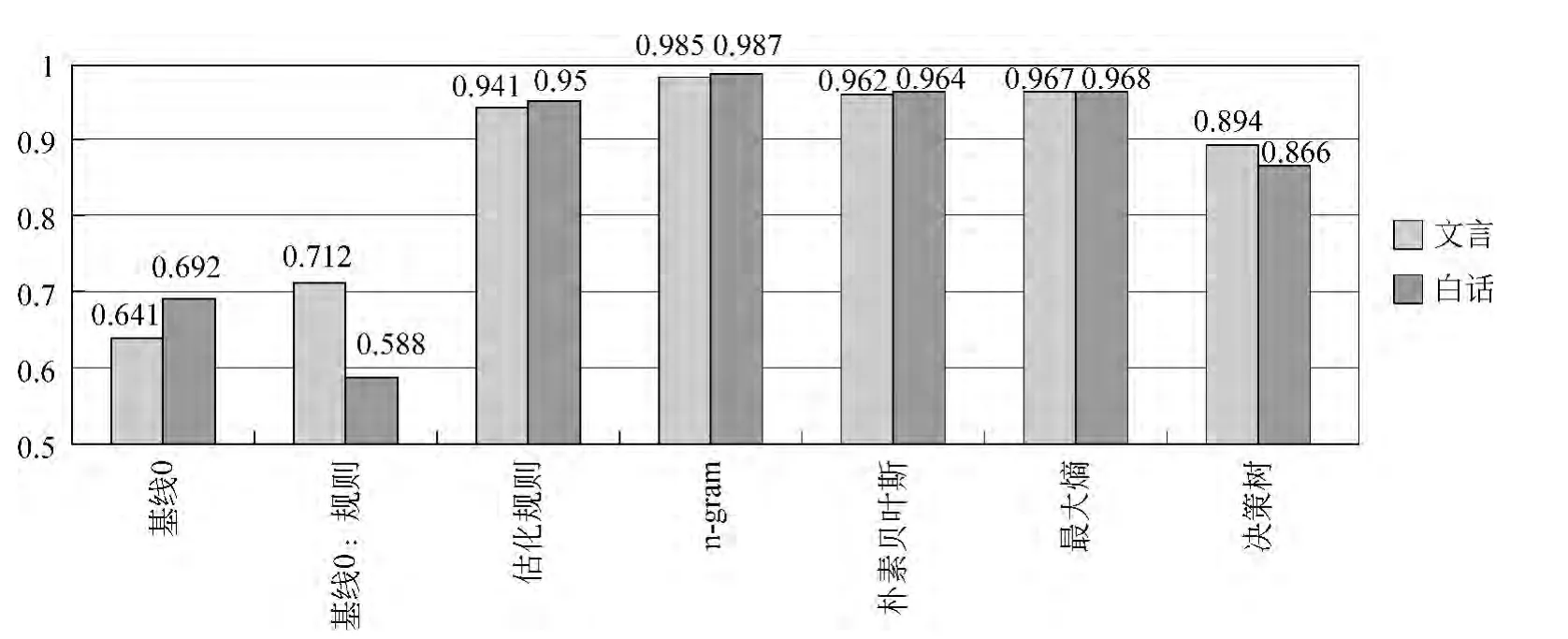
圖10 分類方法結果分析圖
6 結論和展望
本文將文言文和白話文標注問題視作文本分類任務,通過基于規則和基于統計的方法進行標注。使用26種文言句式和24個文言虛詞構成規則集,經由白話文詞表進行消歧,取得了一定的效果。在統計方中,本文使用了N-gram、樸素貝葉斯、決策樹、最大熵算法等幾種模型。實驗發現基于統計的模型的標注效果明顯優于基線,且F值普遍較高。其中一元語言模型取得了0.98的F值。
本文的結論支持了語言學家一直以來的直覺判斷:即文言文的虛詞使用是使之區分于白話文的主要標志,而非語法(或語序)。在語言演變過程中,最活躍的部分就是詞匯[16],而語法變化則相對緩慢。本文的工作也以計量的方式實證地證實了由文言文和白話文的分野主要集中在詞匯層面這一判斷。在這一現象中起主要作用的是虛詞并少量動詞(如“曰”)為代表的特征詞匯。從一個側面來說,我們的工作實際描述了古代文言文到現代白話文作為一個連續統的存在性。
從本文標注任務的結果來看,民國時期的報章體更適合被視作文言文。
未來計劃將規則方法和統計方法進行融合,并對更多時間段不同語體(如詩歌)進行測試,期待對這一問題給出更圓滿的解決方案。
[1] 王力著.中國語言學史[M].上海:復旦大學出版社,2007.
[2] 張普.論語言的穩態[J].鄭州大學學報(哲學社會科學版),2008,(02):105-109.
[3] 張普.論語言的動態[J].長江學術,2008,(01):1-9.
[4] 石毓智.漢語發展史上的雙音化趨勢和動補結構的誕生——語音變化對語法發展的影響[J].語言研究,2002,(02):1-4.
[5] 胡裕樹主編.現代漢語[M].上海:上海教育出版社,1981.
[6] 呂淑湘.現代漢語單雙音節問題初探[J].中國語文,1963,1:10-22.
[7] Mihalcea R,Nastase V.Word epoch disambiguation:Finding how words change over time[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics:Short Papers-Volume 2.Association for Computational Linguistics,2012:259-263.
[8] Popescu O,Strapparava C.Behind the Times:Detecting Epoch Changes using Large Corpora[C]//Proceedings of International Joint Conference on Natural Language Processing.2013:347-355.
[9] 荀恩東,饒高琦,謝佳莉,等.現代漢語詞匯歷時檢索系統的建設與應用[J].中文信息學報,2015,29(3):169-176.
[10] 饒高琦,臧嬌嬌,荀恩東.大數據視角下的語言實證工具:北語漢語語料庫系統BCC——以因果關系表達的語言模式研究為例[R].北京:北京市語言學年會,2014.
[11] 金觀濤,劉青峰.觀念史研究[M].北京:法律出版社,2009.
[12] 王力著.古代漢語[M].北京:中華書局,1964.
[13] 王力著.漢語史稿[M].北京:中華書局,1980.
[14] Clarkson P.Rosenfeld R.Statistical Language Modeling Using The Cmu-Cambridge Toolkit[C]//Proceedings of Eurospeech.2000:2707-2710.
[15] McCallum,Andrew Kachites.“MALLET:A Machine Learning for Language Toolkit.”[OL].http://mallet.cs.umass.edu.2002.
[16] 徐通鏘,葉蜚聲.語言學概論[M].北京:北京大學出版社,1981.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
中學時代(2020年6期)2020-11-11 14:49:53
數學物理學報(2020年2期)2020-06-02 11:29:24
紅樓夢學刊(2019年6期)2019-04-13 00:44:34
光學精密工程(2016年6期)2016-11-07 09:07:19
老年教育(老年大學)(2016年9期)2016-10-20 08:43:13
黨員文摘(2016年3期)2016-03-12 21:58:22
核科學與工程(2015年4期)2015-09-26 11:59:03
做人與處世(2015年4期)2015-09-10 07:22:44
