基于SVM和泛化模板協作的藏語人物屬性抽取
2015-06-09 23:45:58朱臻,孫媛
中文信息學報 2015年6期
關鍵詞:特征
朱 臻,孫 媛
(1. 中央民族大學 信息工程學院,北京 100081;2. 中央民族大學 國家語言資源監測與研究中心少數民族語言分中心,北京 100081)
?
基于SVM和泛化模板協作的藏語人物屬性抽取
朱 臻1,2,孫 媛1,2
(1. 中央民族大學 信息工程學院,北京 100081;2. 中央民族大學 國家語言資源監測與研究中心少數民族語言分中心,北京 100081)
該文提出了一種基于SVM和泛化模板協作的藏語人物屬性抽取方法。該方法首先構建了基于藏語語言規則的模板系統,收集了包括格助詞、特殊動詞等具有明顯語義信息的特征建設模板并泛化。針對規則方法的局限性,該文在模板的基礎上,采用SVM機器學習方法,設計了一種處理多分類問題的層次分類器結構,同時對多樣化的特征選取給予說明。最后,實驗結果表明,基于SVM和模板相結合的方式可以對人物屬性抽取的性能有較大提高。
人物屬性抽取;藏語語言處理;SVM;層次分類器
1 引言
隨著互聯網的快速普及,特別是發展中國家互聯網用戶的快速增加,網絡上非英語文本資源數量急速增長,其增長速度遠遠超過了十年前的速度,并且越來越多的網上信息以多語言的形式發布。
據中央民族大學國家語言資源監測與研究中心少數民族語言分中心調查,截止到2013年12月底,大陸少數民族語言文字的網站總量在1 250個左右,其中維吾爾文網站840個、藏文網站146個、蒙古文網站136個。“與全國網民增長速度相比,少數民族網民的增速較為突出,例如,藏族網民增幅達86%,遠遠高于全國平均增長速度”[1]。
Web內容的爆炸式增長,使得對Web的社會網絡研究已經不再局限于對Web結構的分析,而是轉向以Web內容為研究對象的分析[2],其中知識圖譜(Knowledge Graph)成為大數據時代自然語言處理領域的一個研究熱點。知識圖譜以結點代表實體或者概念,邊代表實體/概念之間的各種語義關系,其中實體知識的抽取是主要研究內容之一。
知識圖譜以全面、完整的知識體系為信息檢索、問答系統、知識庫構建等領域的研究提供了資源和支撐,而目前已有的Google(超過5.7億實體,18億關系),DBpedia(超過1 900萬實體,1億關系),Wiki-links(4 000萬排除歧義的關系),Wolframalpha(10萬億關系),Probase(超過265萬實體),百度知心,搜狗知立方等知識圖譜只提供英、漢、法等語言的相關知識[3],少數民族語言知識圖譜的構建才剛剛起步。
因此,本文針對藏語語言的特點,提出了一種基于SVM和泛化模板協作的藏語人物屬性抽取方法。藏語人物屬性抽取的研究,是藏語知識圖譜構建的基礎,為藏語知識問答、信息檢索、信息抽取等領域研究提供支撐,對提高少數民族地區的社會管理科學化水平、維護民族團結和國家統一、構建和諧社會具有重要意義。
2 國內外研究現狀及發展動態分析
人物屬性抽取是信息抽取領域的一個重要研究對象[4],該概念在2009年的國際TAC KBP會議開始引入[5]。人物屬性抽取是指自動從無結構或者半結構的文本語料中抽取特定的人物屬性,其中包括人物性別、出生年月、出生地、所屬機構等。但是人物屬性抽取一直面臨著兩大問題[6],即人物屬性識別問題和人物屬性關系判別問題。人物屬性一般為命名實體,例如,人名、地名和組織機構名。命名實體識別在自然語言處理領域仍是一件尚未完全解決的工作。因此,在人物屬性抽取工作前,需要準備高準確度命名實體標注語料[7]。
為了實現大規模數據的信息抽取,很多機器學習算法被引入到信息抽取領域。Freitag采用HMM結構進行信息抽取[8],Laffery使用條件隨機場抽取數據[9],Kambhatla把多種特征用于最大熵模型并取得了較好的抽取效果[10]。而應用最廣的是支持向量機方法[11-12]。作為信息抽取領域的一個分支,把統計的方法運用于人物屬性抽取,通常采用基于特征向量的方式[13]。其中,經典的基于特征向量的機器學習方法包括最大熵模型[14]和支持向量機[15]。另外,特征選取對于基于特征向量的方式至關重要。Miler構建了一種語義解析樹,樹中整合了概念間關系的多種語義信息,包括詞性標注,命名實體識別標記和其他一些語言上的強特征,這些特征給分類器提供了很好的依據[16]。Culotta根據依存樹構建了核函數,并將其用于機器學習算法[17]。Zelenko引入了一種樹核的方法[18]。
但是,目前針對藏語的實體知識抽取領域的研究較少,主要研究集中于藏語的命名實體識別方法[19-21],而對于實體關系抽取特別是人物屬性抽取的研究尚未有成熟的成果。歸納原因,藏語任務屬性抽取存在的困難如下: (1)訓練語料匱乏;(2)藏語在句子和篇章級的信息處理研究還處于起步階段,因此,英、漢實體關系抽取中的核函數方法無法被直接應用于藏語實體關系抽取中。
因此,本文針對藏語的特點,構建了一定規模的訓練語料,提出一種基于SVM和泛化模板的藏語人物屬性關系抽取方法。其中,模板構建重點選取包括藏語后置謂詞,相關的格信息等主要特征。此外,針對模板方式的局限性,本文采用SVM機器學習方法,設計了一種處理多分類問題的層次分類器進行屬性關系抽取。最后,本文分別采用模板、SVM以及模板和SVM結合的方法進行實驗,實驗結果表明,通過模板和SVM結合的方式有效提高了人物屬性抽取的正確性。
3 整體框架
通過可配置的爬蟲系統從多個藏文網站獲取語料,從中篩選出關于人物介紹的文章并對這些句子做預處理,包括分詞、詞性標注和命名實體識別。首先,根據訓練語料構建模板系統。此外,為了應對開放語料的多樣性問題,引入了SVM方法進行預測,而模板中的語言規則作為輔助工具。最終將處理完成的數據裝入人物-屬性庫中,具體過程如圖1所示。
4 模板構建
一定量的訓練語料標注之后,可以進入模板系統建設階段,本節將分別介紹藏語特征選擇,模板建設和泛化過程。
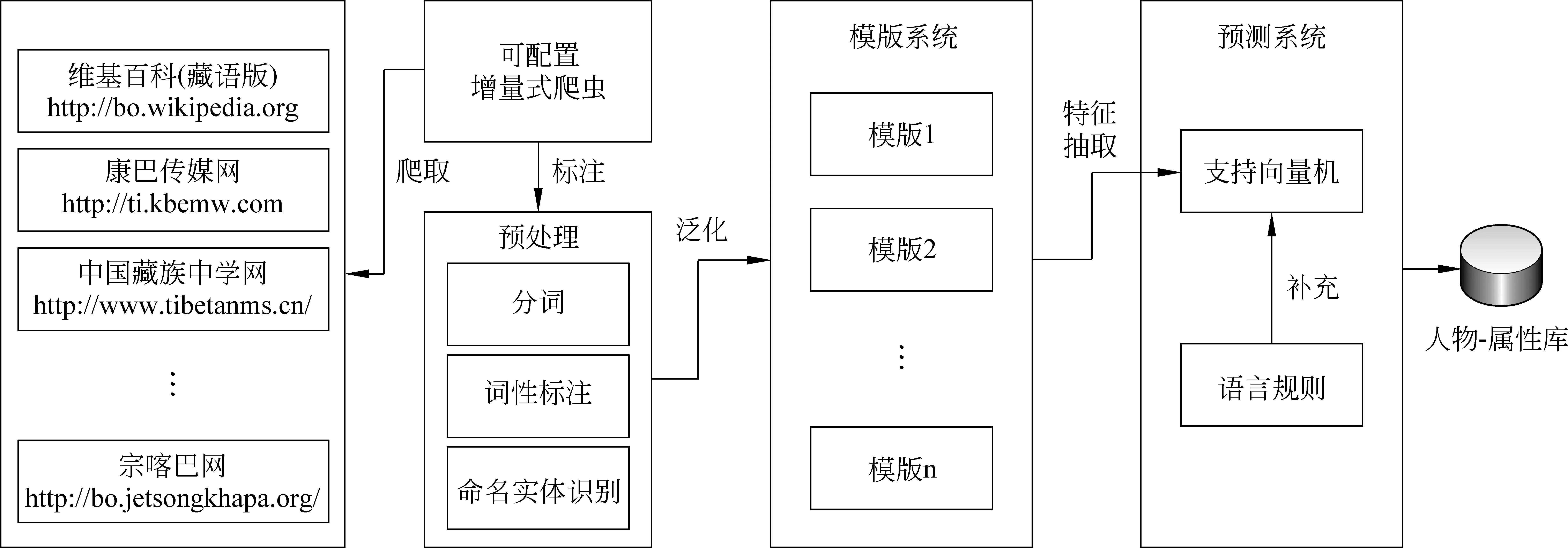
圖1 基于SVM和泛化模板相結合的藏語人物屬性關系抽取方法
4.1 主要藏語特征選擇
不同于漢語和英語,藏語是謂語后置型語言,動詞是句子的核心。動詞附近的格標記含有豐富的語義角色信息,格標記在一定程度上反映出句子中謂詞與主體詞之間的關系,而且這些格標記的出現存在一定的規律。因此,對格標記做了整理,這些格標記對藏文人物屬性抽取起到重要的作用,如表1所示。
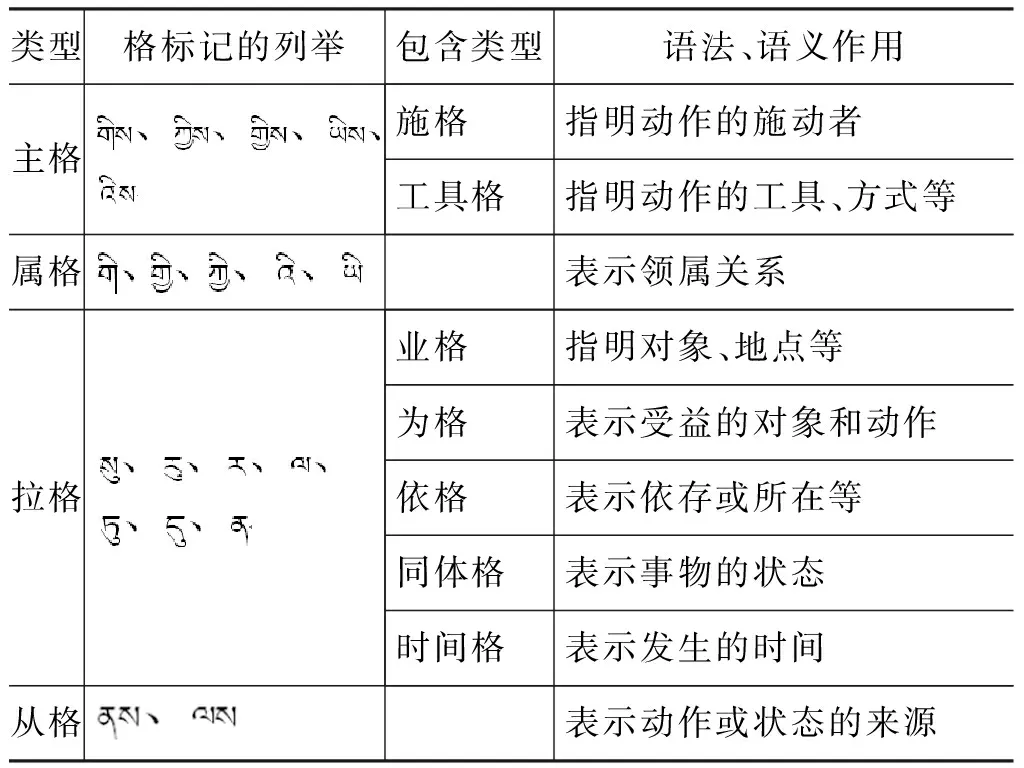
表1 藏語格標記的類型與作用
4.2 模板建設
與漢語和英語不同,模板建設中更加注重藏語特有的格標記和周圍的動詞,在語料標注的基礎上構建特征模板,如例1-4。
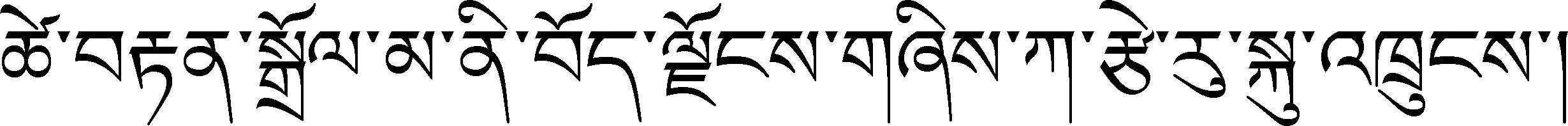




詞性標記采用“國家語言資源監測與研究中心少數民族語言分中心”的《信息處理用現代藏語詞類標記集規范》,其中,“/nh”表示人名、“/t”表示時間、“/ns”表示地名、“/k”表示格標記、“/v”表示動詞。
4.3 泛化
在語料模板建設完成后,發現眾多模板具有相似性,我們整合、修改并泛化模板使其能應用于更廣泛的語料。對于微小區別模板,例如,僅是動詞的差別,只需將不同的動詞添加的集合來合并模板。對于模板中不重要的修飾性成分,將其從模板中刪除,模板樣式如例5-8。
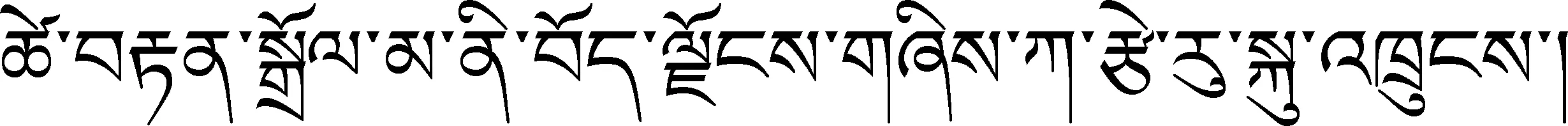
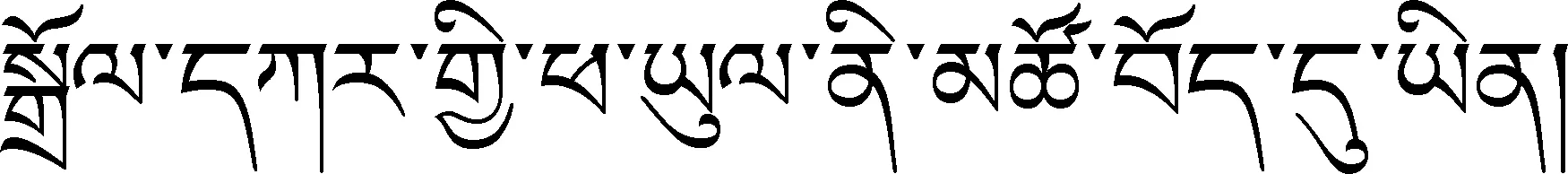


5 基于SVM的層次分類
雖然基于特征模板的方法在特定的測試語料中可以取得較高的準確度,但是它需要很多人工的介入,并且對于模板系統尚未覆蓋的內容無能為力。因此,對于不同的語料,準確率和召回率差別很大,特別是對于模板系統比較生疏的語料,基于模板的抽取系統召回率非常低。因此,本文引入了基于特征向量的SVM方法,并設計了層次分類器。
5.1 特征選取
特征選擇至關重要。一定程度上,特征的質量決定了分類效果。本文的特征向量主要選取關鍵詞特征、標注組合特征、實體詞周圍標記特征。
5.1.1 關鍵詞特征
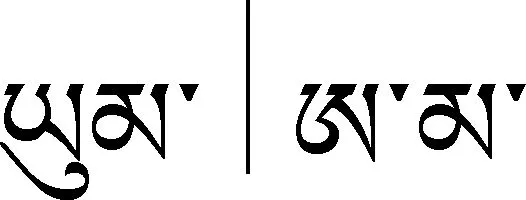
5.1.2 基于多種標記的組合特征

5.1.3 實體詞周圍標記特征
實體詞周圍標記特征是指在實體詞周圍的詞標記構成的特征,包括詞性標記和命名實體標記。本文認為離實體詞越近的標記越重要,而離實體詞距離越遠的標記則較不重要。因此,選取實體詞向前兩個詞距和向后一個詞距內的詞性標注標記和前后三個詞距內的命名實體標記。
5.2 構造層次分類器
SVM目前是信息抽取領域應用較為成功的分類器之一。SVM通過在高維空間上尋找最優超平面,從而達到分類目的。對于非線性可分的樣本集,一般是通過升維實現樣本空間映射,從而轉變成線性可分的問題。為了使問題可計算,即避免出現維度災難問題,引入了核函數的方法,從而達到把計算在低維空間完成的目的。對于人物屬性抽取問題,一個關鍵問題是構建高性能的SVM分類器。SVM最初被設計用來解決二分類問題,但是屬性抽取往往都是復雜的多分類問題。例如,人物屬性可以分為出生年月,出生地,性別等多個類別。那么,如何組織這些分類器則是多分類問題必須解決的問題。
目前主流的分類器組織形式分為兩種:
(1) 一對多的方式。假如一共有k個屬性類別,那么需要構建k個分類器,并且確實每個屬性平均需要進行k/2次預測,此方式分類效果欠佳。
(2) 一對一的方式。同樣如果存在k個屬性類別,那么需要構建k(k-1)/2個分類器,然后通過k(k-1)/2次預測,再計算累加權重,獲得累加值最大的類別則為所屬類別。這種方式比前者好,但是分類器數量過多,對于屬性抽取等類別數量較多的問題適用性較差。
因此,本文引入了一種層次分類器的構造方法。該方法結合兩種傳統方法的長處,同一層面采用一對一的方式,逐層向下。同時,利用模板系統中獲取的語言規律建設快速通道,從而進一步優化層次分類器的分類效果和分類速度。具體構造如圖2所示。
(1) 過濾器: 在進入層次分類器系統之前需要對語料做篩選,將沒有任何屬性實體存在的部分干擾句直接剔除,可以一定程度上減少層次分類器工作負荷從而提高效率。
(2) 逐層向下: 進入層次分類器系統后,標準的分類模式是從第一層分類器開始逐層向下直至類別葉節點,中間的分類器會將一些無關類別的數據剔除。這一步驟對于屬性抽取過程中大量負樣本的處理是非常重要的。
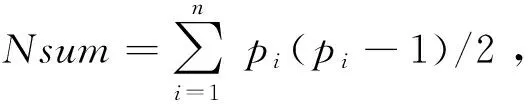
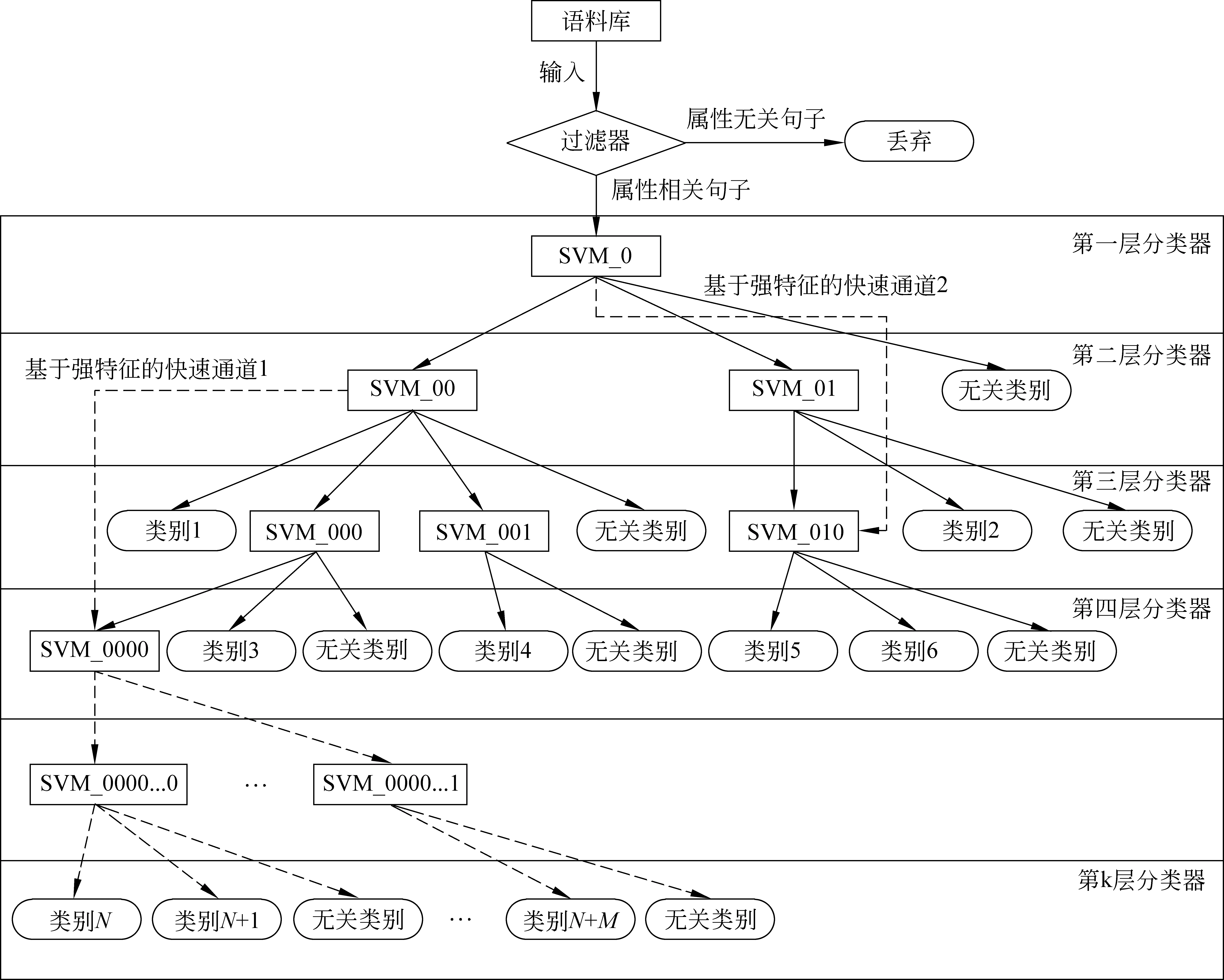
圖2 層次分類器的構造
(4) 快速通道: 本文設計了根據實體-屬性標注構造的快速通道,這些快速通道可以有效地提高層次分類器的分類效果和速度。因為在屬性抽取任務中,屬性實體本身往往帶有明顯的區分性。例如,當出現時間為第二個實體詞時,只可能出現出生年月屬性而不會是父親或出生地的屬性。因此可以通過快速通道直接跳至關于出生年月類別和無關類別的分類決策器。
6 實驗結果與分析
6.1 語料來源
6.1.1 數據爬取及篩選
本文語料來源于七家藏語網站,如表2所示。我們研究關注的人物屬性主要包括:
人名-出生日期 人名-出生地
人名-父親 人名-母親
我們從大量網頁文本中選取2 400句包含人物屬性的句子。其中,1 975句是包含上述四種人物屬性關系的句子,剩余425句為其他人物屬性關系的句子。我們將1 600句作為訓練語料,其余800句作為測試語料。
表2 語料來源
6.1.2 語料預處理
我們對選取的2 400句進行分詞、詞性、命名實體識別,并標注了實體之間的關系。
人物-出生地(e1,e2)
人物-出生年月(e1,e2)
6.2 實驗分析與評價
首先使用基于模板的方法在1 600句訓練語料集上做測試(共包含1 705個屬性),實驗結果如表3所示。
表3 基于模板的藏語人物屬性抽取在封閉訓練集上的結果
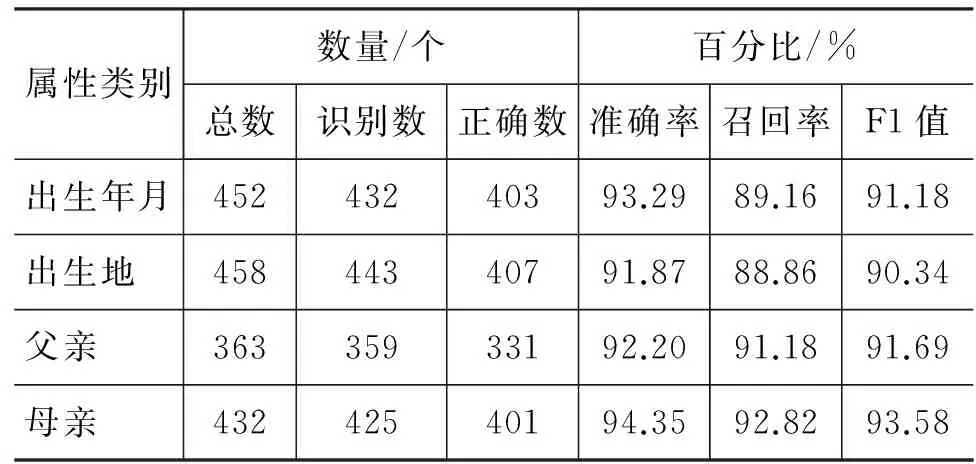
屬性類別數量/個百分比/%總數識別數正確數準確率召回率F1值出生年月45243240393.2989.1691.18出生地 45844340791.8788.8690.34父親 36335933192.2091.1891.69母親 43242540194.3592.8293.58
但是,把這些模板應用于800句測試語料集(共846個屬性)時,實驗結果如表4所示。
表4 基于模板的藏語人物屬性抽取在開放測試集上的結果
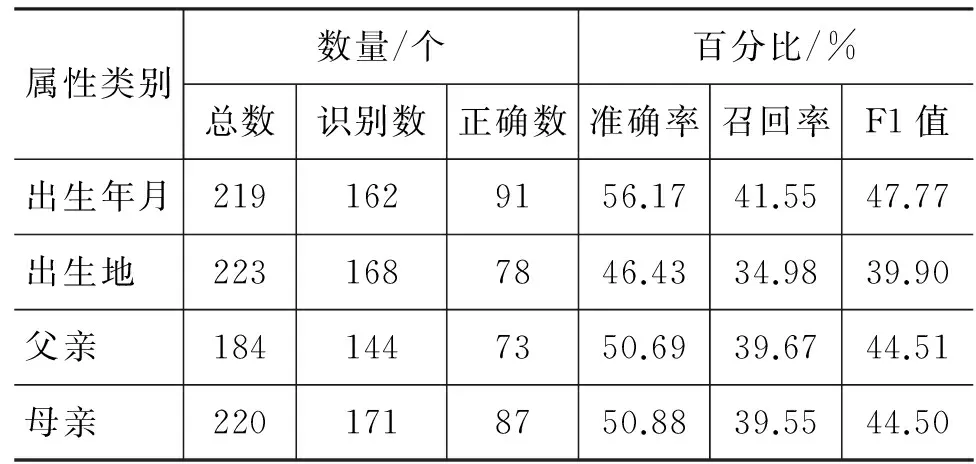
屬性類別數量/個百分比/%總數識別數正確數準確率召回率F1值出生年月2191629156.1741.5547.77出生地 2231687846.4334.9839.90父親 1841447350.6939.6744.51母親 2201718750.8839.5544.50
上述實驗結果表明,基于模板的方法應用在模板系統不熟悉的語料中性能下降明顯。主要原因在于,基于模板的方式缺少學習能力而必須通過一些人工參與構建,雖然通過不停的泛化和修正,性能會逐漸提升,但是過多的人工介入和較大的工作量成為該方法的瓶頸。此外,不同藏語地區或不同風格網站的語言會有一些區別,考慮語言的豐富性,難以通過基于模板的方式做到完備。
下面,我們采用基于SVM的層次分類器進行人物屬性抽取,本文采用層次分類器在分類速度上較之一對一的分類器有較大提升,而兩種方法的準確性相差不大。此外,通過語言規則構建的快速通道使分類性能更好。在實驗中,我們對比常見的核函數方法,最終選型為RBF(徑向基函數)并設置參數γ=1/k,k為類別個數。同時考慮到語料普遍存在不均衡性,負樣本大大多于正樣本,因此,對正負樣本分別設置了不同的懲罰因子C+和C-。其中,C-為3,正樣本滿足C+=(Num-/Num+)×C-。Num-為負樣本數,Num+為正樣本數,我們通過增大正樣本的懲罰因子,從而減少因為數據傾斜造成的影響。實驗結果如表5所示。
表5 基于SVM的藏語人物屬性抽取在開放測試集上的結果
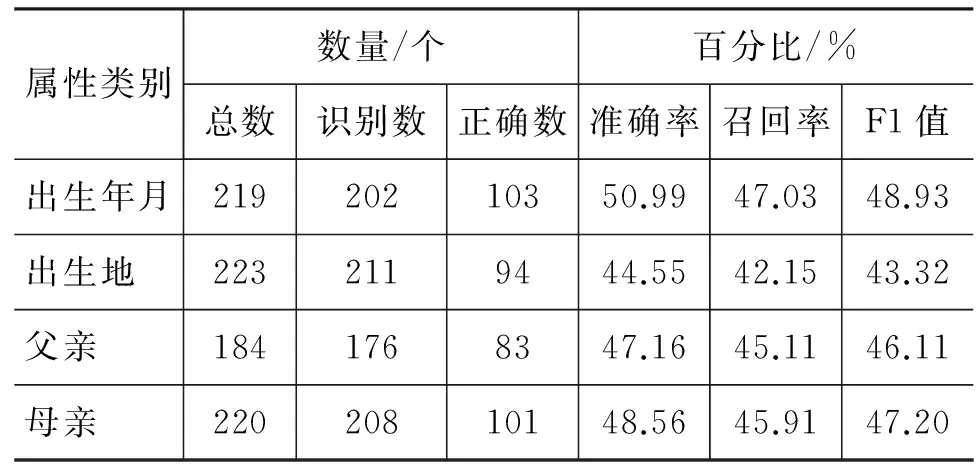
屬性類別數量/個百分比/%總數識別數正確數準確率召回率F1值出生年月21920210350.9947.0348.93出生地 2232119444.5542.1543.32父親 1841768347.1645.1146.11母親 22020810148.5645.9147.20
實驗結果表明,相比于模板的方法,SVM方法提高了人物屬性抽取的召回率,但是準確率并沒有提高。主要原因在于,SVM的結果在對于一些不明顯的分類,通過多樣化的特征向量反而可以取到較好的預測效果。但是對于一些非常明顯的分類問題卻判斷錯誤,我們認為,部分原因在于訓練語料不足和訓練語料不均勻造成的。
最后,本文采用基于模板和SVM相結合的方式進行實驗。實驗結果如表6所示。
表6 基于SVM和泛化模板協作的藏語人物屬性抽取在開放測試集上的結果
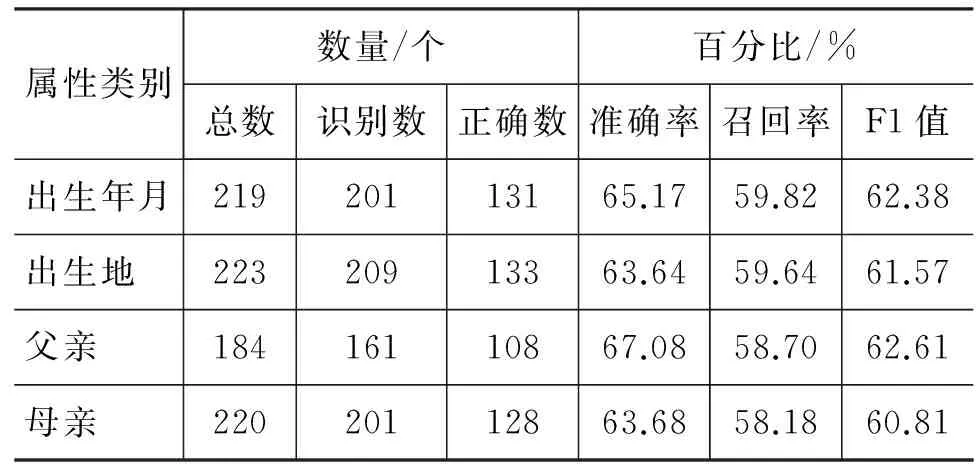
屬性類別數量/個百分比/%總數識別數正確數準確率召回率F1值出生年月21920113165.1759.8262.38出生地 22320913363.6459.6461.57父親 18416110867.0858.7062.61母親 22020112863.6858.1860.81
首先對前期建設的模板系統精心篩選,只保存在抽取實驗中準確率接近100%的這部分模板。雖然這樣會使召回率在模板系統部分急劇下降,但是,隨后我們就將所有模板沒有抽取出屬性所剩下的所有句子數據化并交給SVM預測。這樣,對于那些模板并未抽取的屬性可以通過SVM預測出,保護了一些原本特征明顯的屬性句子不被SVM誤判。所以在整體上并未影響召回率,同時還提高了抽取的效果。
由圖3可以看出,采用模板和SVM相結合的方式比只采用SVM的方式,性能上有較大的提高。
6.3 實驗結果的展示
通過SVM和模板結合的人物屬性抽取后的結果如表7所示。通過人物屬性抽取,把屬性放入人物-屬性庫中,為藏語人物收集、藏語知識圖譜建設等應用提供數據支撐。
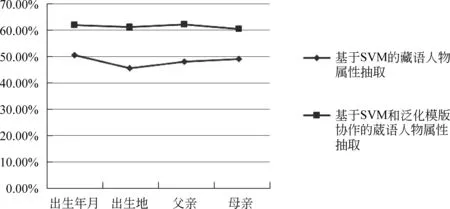
圖3 基于SVM和泛化模板協作和基于模板的藏語人物屬性抽取比較

表7 關于人物(松贊干布)的屬性抽取結果
7 結論
通過對上述實驗結果的分析,我們發現對于人物屬性關系抽取的問題采用SVM和模板相結合的方式,比僅采用SVM或者僅采用模板的方式性能更好。部分原因在于彼此對于不同情況的分類問題具有各自的優勢,通過整合兩者方法,讓它們協同工作,從而使實驗方法性能提高。通過該方法提取的屬性可以廣泛應用于專門數據庫的建設、知識圖譜構建和智能問答等領域。在將來的工作中,需要擴充語料庫并增加人物屬性的類別,從而提升成果的價值。
[1] 李光,鐘雅瓊.大陸研擬藏維文網絡輿情監測系統監控分裂風險[N].鳳凰周刊, 2012(18).
[2] Bizer C,Heath T,Berners-Lee T. Linked data-the story so far [J].International Journal on Semantic Web and Information Systems (IJSWIS),2009,5(3): 1-22.
[3] 張靜,唐杰.下一代搜索引擎的焦點: 知識圖譜[J].中國計算機學會通訊, 2012,9(4):64-68.
[4] Kong Fang, Zhou Guodong, Zhu Qiaoming. Survey on Coreference Resolution [J]. Computer Engineering, 2010, 36(8): 33-36.
[5] Bikel D, Castelli V, Florian R. Entity linking and slot filling through statistical processing and inference rules[C]//Proceedings of the TAC 2009 Workshop 2009.
[6] Burman A, Jayapal A, Kannan S.Entity linking, slot filling and temporal bounding[C]//Proceedings of the KBP,2011.
[7] Axel Bernal, Koby Crammer, Artemis Hatzigeorgiou. Global discriminative learning for higher-accuracy computational gene prediction[J]Computational Biology, 2007, 3(3):488-497.
[8] Freitag D, McCallum A. Information extraction with HMM structures learned by stochastic optimization[C]//Proceedings of the AAAI Press,2000: 584-589.
[9] Lafferty J, McCallum A, Pereira F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conf. on Machine Learning,2001: 282-289.
[10] Kambhatla N. Combining lexical, syntactic and semantic features with Maximum Entropy models for extracting relations[C]//Proceedings of 42th Annual Meeting of the Association for Computational Linguistic,2004: 21-26.
[11] Zhou G, Su J, Zhang J, Zhang M. Combining Various Knowledge in Relation Extraction[C]//Proceedings of the 43th Annual Meeting of the Association for Computational Linguistics,2005.
[12] Zelenko D, Aone C, Richardella. Kernel methods for relation extraction[J]. Journal of Machine Learning Research, 2003: 1083-1106.
[13] Nadia Ghamrawi, Andrew McCallum. Collective multi-label classification[C]//Proceedings of the Conference on Information and Knowledge Management (CIKM), 2005.
[14] Nanda Kambhatla. Combining lexical, syntactic and semantic features with Maximum Entropy models for extracting relations[C]//Proceedings of ACL, 2004: 178-181.
[15] Zhao S B, Grishman R. Extracting relations with integrated information using kernel methods[C]//Proceedings of ACL,2005: 419-426.
[16] Miller S, Fox H, Ramshaw L, et al. A novel use of statistical parsing to extract information from text [C]//Proceedings of 6th Applied Natural Language Processing Conference,2000.
[17] Culotta A, Sorensen J.Dependency tree kernels for relation extraction[C]//Proceedings of 42th Annual Meeting of the Association for Computational Linguistics,2004: 21-26.
[18] Zelenko D, Aone C, Richardella. Kernel methods for relation extraction[J]. Journal of Machine Learning Research, 2003: 1083-1106.
[19] 加羊吉,李亞超,宗成慶,等.最大熵和條件隨機場模型相融合的藏文人名識別方法 [J].中文信息學報,2014:28(1):107-112.
[20] 才智杰.藏文自動分詞系統中緊縮詞的識別 [J].中文信息學報,2009,23(1): 35-37.
[21] Sun Yuan, Zhao Xiaobing. Research on automatic recognition of Tibetan personal names based on multi-features[C]//Proceedings of International Conference on Natural Language Processing and Knowledge Engineering 2010.
Tibetan Person Attribute Extraction Based on SVM and Pattern
ZHU Zhen1,2, SUN Yuan1,2
(1. School of Information Engineering, Minzu University of China,Beijing 100081, China;2. Minority Languages Branch, National Language Resource and Monitoring Research Center, Minzu University of China, Beijing 100081, China)
This paper proposes an SVM and pattern based approach to Tibetan person attribute extraction. The pattern system is built with language rules on Tibetan language features with clear semantic information, such as case-auxiliary words, particular verb and etc. Then, a machine learning approach via SVM is introduced to build a a hierarchy classifier strategy. Experiment results indicate a significant improvement in person attributes extraction.
person attributes extraction; tibetan language processing; SVM; hierarchy classifier

朱臻(1988—),碩士研究生,主要研究領域為自然語言處理、信息檢索、數據挖掘。E-mail:18957736389@163.com孫媛(1979—),通信作者,副教授,主要研究領域為自然語言處理、信息抽取。E-mail:tracy.yuan.sun@gmail.com
1003-0077(2015)06-0220-08
2015-08-17 定稿日期: 2015-10-20
國家自然科學基金(61501529,61331013),北京青年英才資助計劃(YETP1291),國家語委項目(ZDI125-36,YB125-139),中央民族大學自主科研項目(2015MDQN11),中央民族大學國家語言資源監測與研究中心少數民族語言分中心項目(CML15B02)
TP391
A
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
