基于框架的漢語篇章結構生成和篇章關系識別
2015-06-09 23:45:58呂國英王智強柴清華
中文信息學報 2015年6期
呂國英,蘇 娜,李 茹,2,王智強,柴清華
(1. 山西大學 計算機與信息技術學院,山西 太原 030006;2. 山西大學 計算智能與中文信息處理教育部重點實驗室,山西 太原 030006;3. 山西大學 外國語學院,山西 太原 030006)
?
基于框架的漢語篇章結構生成和篇章關系識別
呂國英1,蘇 娜1,李 茹1,2,王智強1,柴清華3
(1. 山西大學 計算機與信息技術學院,山西 太原 030006;2. 山西大學 計算智能與中文信息處理教育部重點實驗室,山西 太原 030006;3. 山西大學 外國語學院,山西 太原 030006)
針對漢語篇章分析的三個任務: 篇章單元切割、篇章結構生成和篇章關系識別,該文提出引入框架語義進行分析研究。首先基于框架構建了漢語篇章連貫性描述體系以及相應語料庫;然后抽取句首、依存句法、短語結構、目標詞、框架等特征,分別訓練基于最大熵的篇章單元間有無關系分類器和篇章關系分類器;最后采用貪婪算法自下向上生成篇章結構樹。實驗證明,框架語義可以有效切割篇章單元,并且框架特征可以有效提升篇章結構以及篇章關系的識別效果。
篇章單元;篇章結構;篇章關系;貪婪算法
1 引言
篇章分析是自然語言處理領域的一項重要任務,它[1]是指對篇章結構以及結構中篇章單元之間的語義關系進行分析。篇章由一個以上的語段或句子構成,例如,給定一個由一個句子“中國夢只有被世人理解和接受,才能加快實現進程。”構成的簡單篇章,通過篇章分析后,得到如圖1所示的篇章關系結構樹。在結構樹中,“中國夢只有被世人理解和接受”和“才能加快實現進程”兩個篇章單元在條件關系基礎上構成了一個只有一個層次的篇章結構樹。該項研究對自然語言處理的許多領域起到了很大的作用,如問答系統[2]、文本連貫性[3]等。

圖1 簡單篇章分析示例
目前,針對篇章分析的研究主要面向英語,其中一個原因就是英文的相關理論體系和語料庫比較完善。Mann和Thompson提出的修辭結構理論(Rhetorical Structure Theory,RST)[1,4]認為所有好的篇章都是在篇章關系基礎上形成的篇章層次化結構。基于RST的篇章分析器自動構建過程主要有兩個子任務: (1)切割基本篇章單元; (2)根據RST確定篇章單元之間的語義關系,生成有層次的篇章結構樹。目前,已有許多研究者針對這兩個任務在修辭結構理論篇章樹庫(Rhetorical Structure Theory - Discourse TreeBank,RST-DT)[5]上展開了研究和實驗。在基本篇章單元分割任務上,Hernault[6]等人將該任務看作序列化標注問題,使用詞匯、句法等平面特征訓練CRF模型,已取得了94%的F值。在篇章結構生成任務上,Wei Feng[7]等人提出使用雙線性鏈條件隨機場模型和貪婪策略進行篇章分析的方法,得到了58.2%的正確率。
賓州篇章樹庫(Penn Discourse Treebank,PDTB)[8]主要標注與英語篇章連接詞相關的篇章關系。基于PDTB的篇章分析器自動構建過程主要有三個子任務: (1)判定篇章中的連接詞是否充當連接詞;(2)識別存在篇章關系的兩個論元(arg1,arg2);(3)篇章關系識別,在PDTB中,篇章關系細分為隱式關系(Implicit)、顯式關系(Explicit)、替代關系(AltLex)、實體關系(EntRel)、無關系(NoRel)五類。篇章關系識別方面,由于顯式篇章關系具有篇章連接詞,易于識別,Pilter[9]等人僅僅利用連接詞的統計特征已取得了93.09%的顯式篇章關系識別準確率。Ziheng Lin[10]等針對PDTB的第二層語義進行識別,提出了短語結構樹、依存句法樹、上下文、詞對等有效特征,取得了40.2%的隱式篇章關系識別準確率。
在漢語方面,孫靜[11]等人在自建的漢語語料庫(Chinese Discourse Treebank,CNDB)上進行了相關實驗。張牧宇[12-13]等人在從OntoNotes4.0中隨機篩選出1 096篇文本構成的語料庫上進行了相關研究與實驗。涂眉[14]等人在標有復句邏輯語義關系的清華漢語樹庫上,提出了基于最大熵的漢語篇章結構分析方法。但是,相對于英語篇章分析的快速發展,漢語的研究還很少,其中的主要原因是相關的理論體系與漢語篇章語料庫還不夠完善,且漢語在構建篇章上與英語有較大差異,使得英語的標注體系和分析方法不能完全應用到漢語上。因此,本文嘗試將框架語義學與漢語篇章分析相結合,構建了相應的理論體系以及篇章框架語料庫。
雖然面向篇章分析的理論以及語料庫不盡相同,但從他們的實驗中,可以看出句首、短語結構、依存句法等一些篇章淺層特征對篇章分析具有很大的作用。然而,篇章分析是一項艱巨的任務,僅依靠這些淺層特征還不能有效完成篇章分析任務。Ziheng Lin[10]等人曾指出識別篇章關系的難點在于歧義性、推理、上下文、世界面,篇章分析只有在分析了篇章上下文知識、理解了有聯系的篇章單元的語義、對篇章單元間的語義進行合理推理等的基礎上,才能分析出篇章單元之間的語義關系以及篇章的結構。Fillmore[15]的框架語義學是對世界知識和語言知識之間關系的描寫,用框架對篇章進行分析,既可以在一定程度上模擬篇章的語義內容,使其具有可計算性,而且為篇章連貫提供了新的描寫機制,從而有效改善篇章分析的性能。基于此,本文在框架語義基礎上構建了篇章連貫性描述體系以及相應語料庫,并展開了初步的句子級實驗,驗證了框架在漢語篇章單元切割、句子級篇章結構生成以及篇章關系識別上的作用,為進一步研究框架在篇章分析技術方面的作用奠定了基礎。本文的具體組織結構如下: 第2節介紹漢語篇章框架語料庫;第3節構建篇章分析器;第4節是實驗設置與結果分析;第5節為結語。
2 漢語篇章框架語料庫介紹
本文利用山西大學在Fillmore[15]提出的框架語義學理論基礎上構建的漢語框架網(Chinese Framenet,簡稱CFN)[16-17],建立了方便計算機實現的篇章框架連貫性描述體系。本體系將篇章看作是由裹挾在語言符號中的框架構成的框架集合,即框架可以構成篇章單元,并且這些框架依據篇章關系自底向上組合形成一棵意義上連續的語義結構樹,框架之間的篇章關系通過顯式或隱式的連接詞語連接起來。
2.1 框架
該體系認為篇章是由裹挾在句子等表層語言符號中的框架構成的框架集合。CFN中的框架提供了漢語詞語在語言中使用的背景和動因,是人類在理解語言時,儲存在人類認知經驗中的圖式化場景。框架語義學根據各框架對應的場景,將具有相同基本意義、支配相同類型語義角色的詞語歸入一個框架,例如,“包含”框架下的詞語有“包含”、“構成”、“涵蓋”等,描述的是部分包含在整體中。篇章中裹挾在句子中的目標詞(目標詞是指在一個具體的句子中能夠激起框架的詞)激起一個與句子情境相一致的框架,句子的其他成分充當該框架的語義角色,如:
例1 “典型的兩棲動物包括青蛙、蟾蜍、蠑螈和火蜥蜴。”進行框架語義分析后得:
2.2 切割篇章語義單元
針對漢語篇章由一系列句子構成,每個句子由系列小句構成的特點,本體系將一個篇章(Discourse,簡稱D)中的句子經“,”、“:”等分割的語義單元定義為初級篇章單元(Primary Discourse Unit,簡稱PDU);一些PDU沒有能激起框架的目標詞,即不能構成篇章的基本單元,因此將不具有框架的PDU與相鄰具有框架的PDU合并在一起,構成一級篇章單元(First Discourse Unit,簡稱FDU),其他含有框架的PDU直接向上構成FDU;句子定義為二級篇章單元(Second Discourse Unit,簡稱SDU)。這種切割方式與英語按照詞匯或句法標記來劃分篇章單元相比,不僅充分考慮了漢語篇章的特點,而且充分考慮了篇章單元的語義信息。
例2的篇章構成如圖2所示,例句中“()”內內容為初級篇章單元,“[]”內內容為一級篇章單元,“{}”內內容為二級篇章單元,黑體字為目標詞。
例2 {[(今天上午)PDU1,(張樂認真聽取發言)PDU2]FDU1,[(并與參加座談的同志探討交流)PDU3]FDU2}SDU1。{[(他強調)PDU1]FDU1,[(對各位專家學者提出的思想觀點、意見建議)PDU2]FDU2,[(要認真歸納、研究、吸收)PDU3]FDU3}SDU2。{[(他希望專家學者持續關注、參與教育實踐活動)PDU1]FDU1}SDU3。
如圖2所示,在PDU這一層級,從每個初級篇章單元中抽取出(目標詞-框架),其中第一個句子的PDU1沒有能激起框架的目標詞;在FDU這一層級,SDU1下的PDU1沒有框架,與PDU2合并為FDU1,包含自主感知框架,SDU1下的PDU3含有框架直接向上構成FDU2,包含研究、信息交流框架,篇章中其他篇章單元分析與此一致。

圖2 篇章語義單元構成
2.3 篇章框架結構
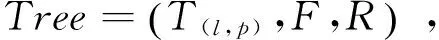
如2.2的例2形成的篇章框架結構樹如圖3所示,句子“{[(今天上午)PDU1,(張樂認真聽取發言)PDU2]FDU1,[(并與參加座談的同志探討交流)PDU3]FDU2}SDU1。”具有三個基本篇章單元PDU1、PDU2、PDU3,兩個一級篇章單元FDU1、FDU2,其中FDU1和FDU2是一般遞進關系,篇章中其他篇章單元分析與此一致。
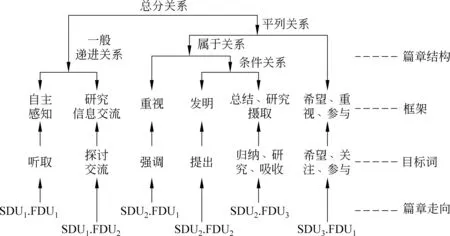
圖3 篇章框架結構樹
2.4 篇章關系
本文基于黃伯榮和廖序東的《現代漢語》中關于復句以及句群之間關系分類體系[18],建立了三層級篇章框架關系結構: 第一層級根據篇章單元間意義是否平等將篇章關系劃分為聯合關系和偏正關系兩大類別;在第二層級篇章關系中,在傳統的偏正關系中加入屬于關系這一類別(表1給出了細化至二層級的篇章關系),屬于關系表示篇章的意圖以及意圖的所有者的所屬關系;第三層級篇章關系,根據前后篇章單元的發展順序以及邏輯關系細分為24類。在該篇章關系層級結構中,如果無法區分篇章單元之間的關系,可以將其歸入承接關系的連貫關系中。
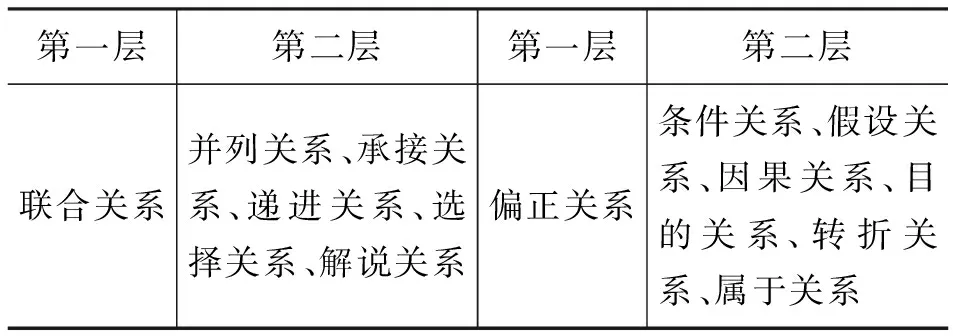
表1 篇章關系類型
2.5 篇章語料庫現狀
鑒于目前關于漢語篇章語料庫的缺乏以及標注體系的不同,我們在該理論體系下構建了一個包括496篇篇章的語料庫,每篇文章都由人工標注了框架、篇章結構以及篇章關系。這些篇章都來自于人民日報,最小的篇章包含一個句子,最大的篇章包含五個句子,從表2的句子級語料庫現狀中,可看出總共標注了1 915個篇章關系,其中并列關系、承接關系、因果關系和屬于關系所占比例較大,并列關系比例最大,達到了21.98%;選擇關系、假設關系和轉折關系所占比例較小,選擇關系實例數最少,只有四條,造成語料庫這種分布狀況的原因與語料體裁選取和關系本身使用頻率具有較大關系。此外,三名標注人員對其中160篇篇章進行了同時標注,在篇章結構上取得了大于0.9的kappa值,在篇章關系上取得了大于0.8的kappa值。

表2 句子級語料庫現狀
3 篇章分析器
針對篇章框架語料庫的篇章自動分析任務主要包括三個子任務: (1)根據篇章激起框架的情況,將篇章切割為一級篇章單元(FDUs)和二級篇章單元(SDUs);(2)篇章結構生成,即生成有層次的篇章結構樹;(3)篇章關系識別。為完成篇章分析的任務,本文設計了相應的篇章分析器,其具體流程如圖4所示。
1. 將進行框架分析后的篇章切割生成FDUs和SDUs,以及生成篇章對應的短語結構樹和依存句法樹,并根據篇章單元向上組合的跨度范圍與相應的短語結構樹和依存語法樹進行邊界對齊后,分別生成訓練數據集和測試數據集;
2. 抽取特征訓練篇章單元之間是否具有關系的最大熵分類器,對測試數據集的篇章單元對進行關系有無的預測,并利用最大熵分類模型給出的篇章單元間具有關系的概率值,采用貪婪算法生成篇章結構樹;
3. 抽取特征訓練篇章關系分類器,對生成的篇章結構樹中的篇章單元對進行關系類別預測;
4. 輸出標注了篇章關系的篇章框架結構樹。
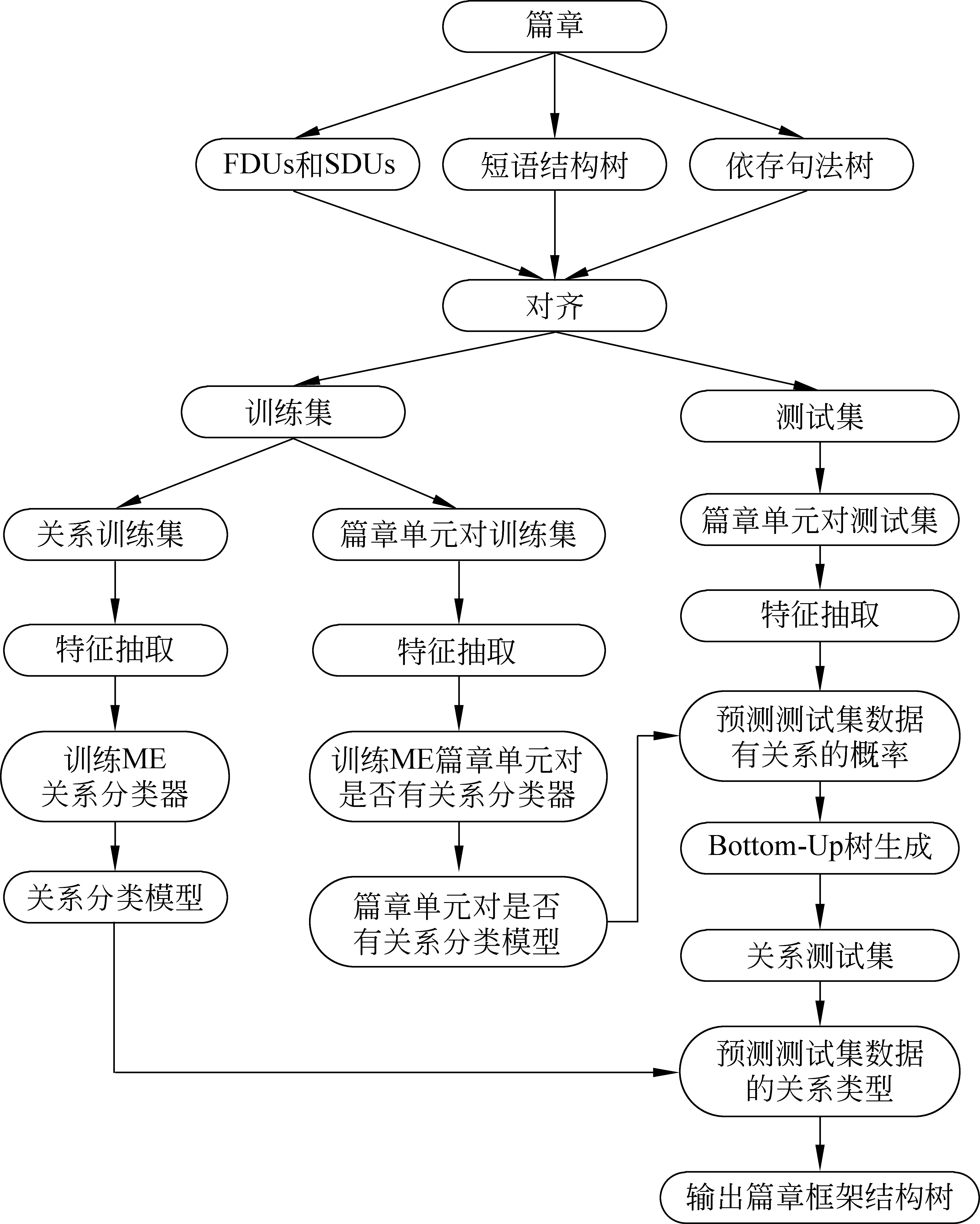
圖4 篇章分析器流程圖
在訓練分類器的時候,本文選用了五類特征: 句首特征、依存句法特征、短語結構特征、目標詞特征和框架特征。
3.1 特征
(1) 句首特征
在漢語中,每個篇章單元的句首通常起到承上啟下的作用,能夠起到指示篇章關系的作用。因此本文分別抽取篇章單元對的第一個篇章單元和第二個篇章單元的句首作為特征。
(2) 依存句法特征
依存句法分析使用依存句法樹來描述各個詞語之間的語義依存關系,這種依存關系描述了篇章單元的主要信息。本文使用Stanford Parser對句子進行依存句法分析,然后從篇章單元向上組合的跨度范圍對應的依存樹中獲得所有擁有被支配者的詞和依存類型。圖5顯示了“張樂認真聽取發言”對應的依存樹,從這棵樹上,收集到的依存句法特征是: 聽取 ← nsubj advmod dobj。每一個依存特征都表示為三個二元特征,來檢測該特征是出現在第一個篇章單元中、第二個篇章單元中或同時出現在兩者中。
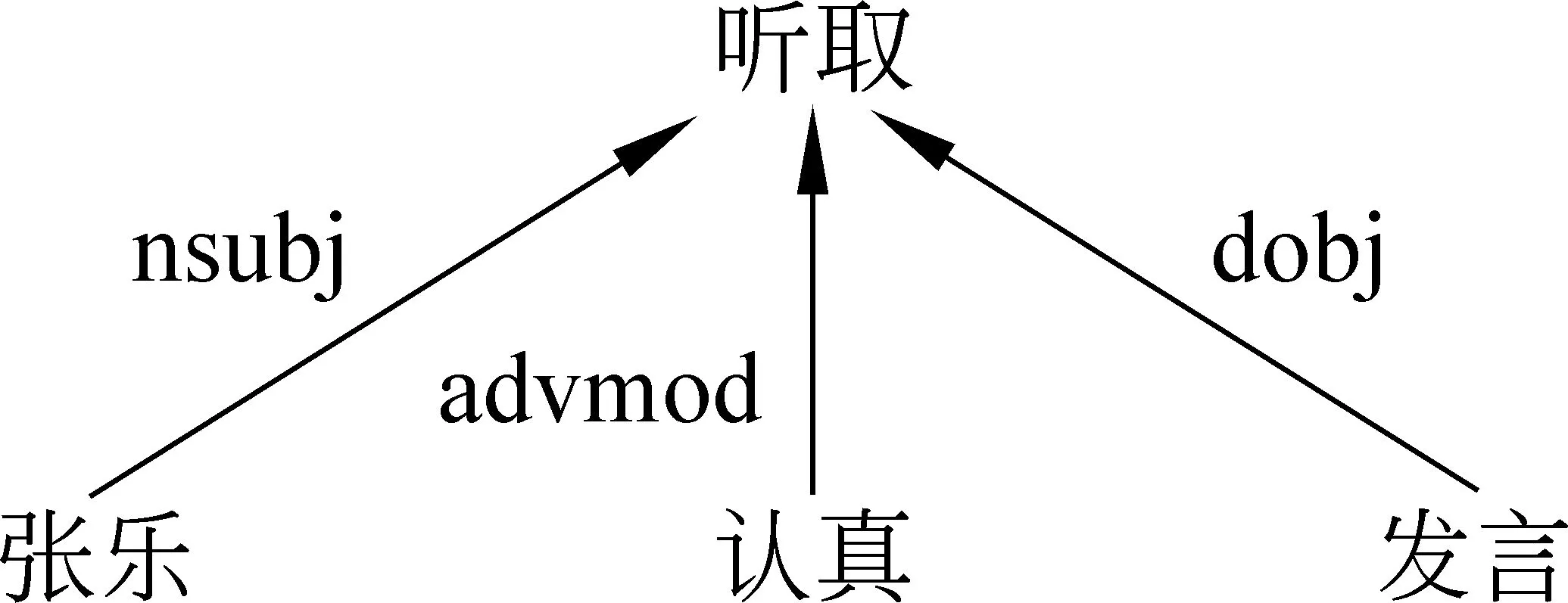
圖5 依存句法樹
(3) 短語結構特征
篇章單元的短語結構往往限制了篇章的結構以及篇章關系。本文使用Stanford Parser對每個篇章中的句子進行分析得到短語結構樹,然后從這些樹上提取相應篇章單元向上組合的跨度范圍的短語結構特征。圖6顯示了“張樂認真聽取發言”的部分短語結構樹,從這棵子樹上,收集到的短語結構特征是: IP→NP VP,NP→NR,VP→ADVP VP,NR→NN,ADVP→AD等。每一個短語結構特征都表示為三個二元特征,來檢測該特征是出現在第一個篇章單元中、第二個篇章單元中或同時出現在二者中。
(4) 目標詞特征
目標詞作為激起整個句子語境的詞匯,在語義表達中起著很大的作用,且它們之間的關系通常反映了篇章單元間的篇章關系。在CFN框架體系中,能承擔起框架的目標詞包括動詞、名詞和形容詞。
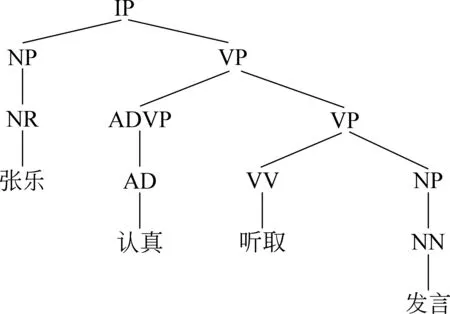
圖6 短語結構樹
如例3 [第一次被嚴重打擊,]FDU1[心情相當難過。]FDU2。
其中,FDU1的目標詞“打擊”和FDU2的目標詞“難過”代表了一種隱式的因果關系,同時也指示了FDU1和FDU2之間是因果關系。
(5) 框架特征
框架能夠表達文本的語義信息,選用框架作為特征不僅可以減少詞語的種類,而且可以有效挖掘出框架之間的語義關系,如圖7所示,由詞語“敲打”等詞語激起的框架“造成傷害”與“疼”等詞語激起的框架“身體感知”是因果關系,與“惶恐”等詞語激起的框架“心理刺激”同樣是因果關系,除此之外,“造成傷害”框架還會與其他框架具有其他種類關系。
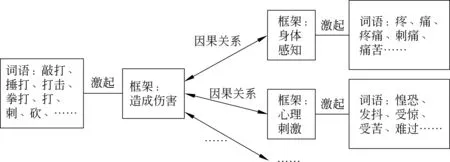
圖7 框架特征
3.2 篇章結構分析器

3.2.1 篇章單元對是否有關系分類模型
在相鄰篇章單元是否具有有關系的分類模型中,本文首先將篇章生成相應的篇章單元對訓練集和測試集。其具體流程如圖8所示。
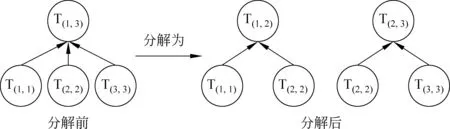
圖8 結構分解
1. 給定篇章集合D={D1,D2,…Dn};
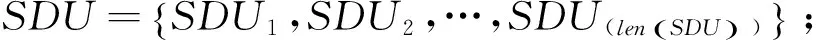
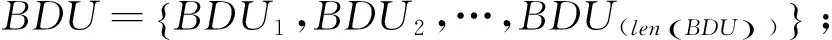
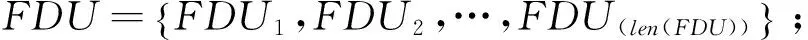
5. 生成篇章單元對,并根據標注真實情況,為每一對篇章單元對標注是否具有關系,生成篇章結構的訓練數據和測試數據。
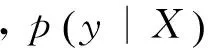
采用拉格朗日乘數法求解最大熵,計算公式為式(2)~(3)。
其中,fi表示每個特征,n代表特征總數,λi為特征的權重。
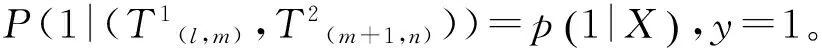
3.2.2 貪婪算法
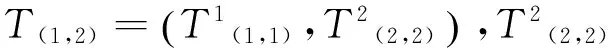
圖9 無重合

圖10 新節點的第一棵子樹與已有節點的最后一棵子樹相同

圖11 新節點的最后一棵子樹與已有節點的第一棵子樹相同

圖12 新節點的第一棵和最后一棵子樹與已有節點的最后一棵子樹和第一棵子樹相同
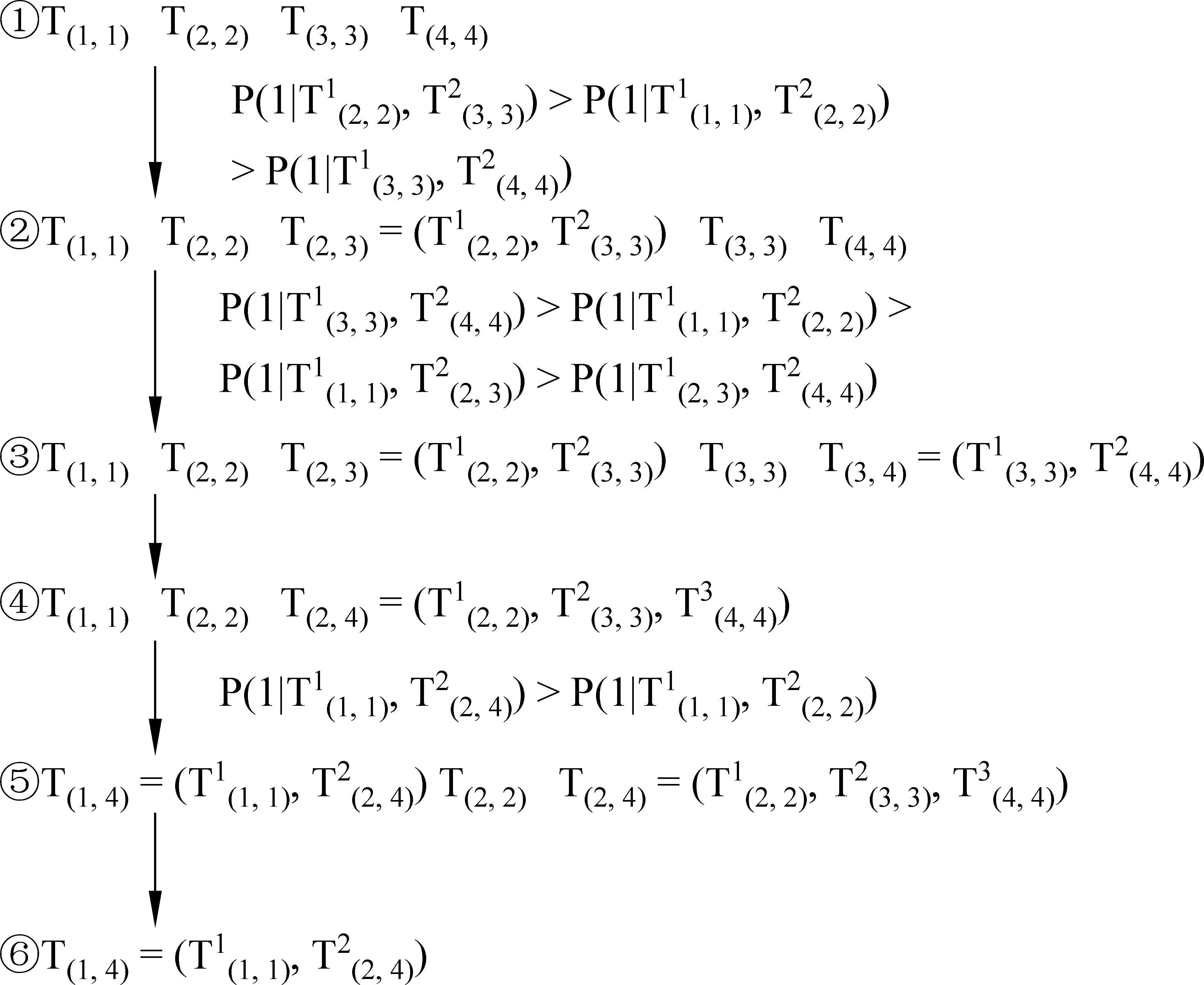
圖13 自下向上生成篇章結構樹
① 將四個一級篇章單元形成葉子節點T(1,1)、T(2,2)、T(3,3)、T(4,4);
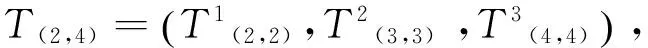
⑥ 因為⑤中的T(1,4)已包含所有篇章單元,因此停止比較,并刪除節點T(2,2)和T(2,4)。從T(1,4)開始從上向下輸出這四個一級篇章單元生成的篇章結構樹,如圖14所示。
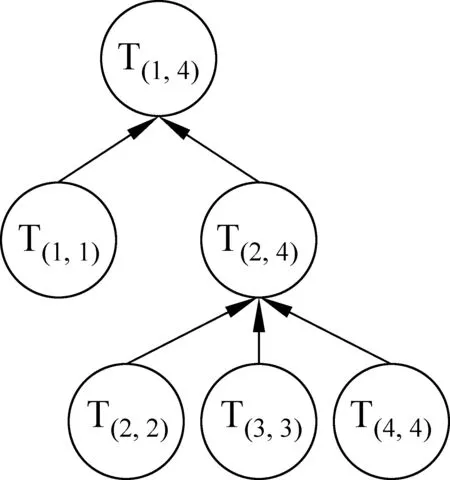
圖14 輸出篇章結構樹
3.3 篇章關系分類模型
4 實驗設置與結果分析
(1) 篇章框架標注情況
由于CFN框架本身覆蓋率的問題,導致篇章中的目標詞不能完全標注出所屬的框架,表3統計了篇章的框架標注情況。
從表3可以看出,總共標注了4 472次,其中3 679次標注了框架,所占比例為82.27%;涉及不同詞語909個,其中679個詞語具有框架,所占比例為74.70%,共涉及框架193個。
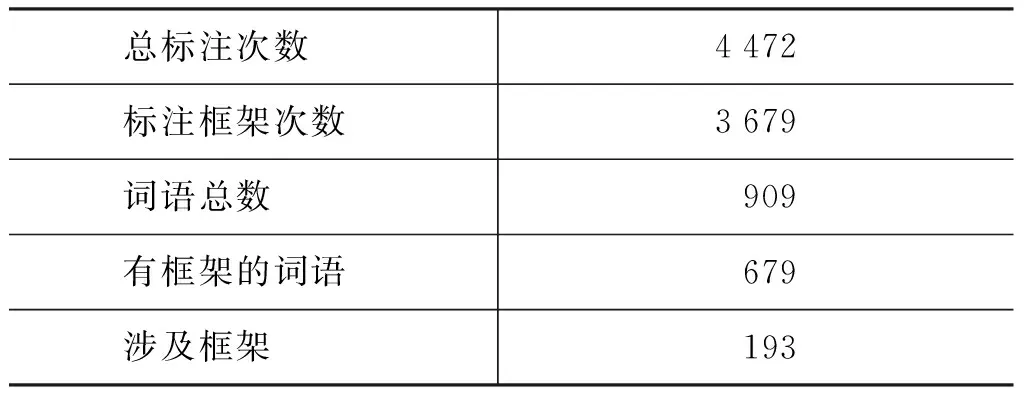
表3 框架標注情況
(2) 篇章單元間有無關系識別效果
本實驗采用框架特征、目標詞特征、短語結構特征和依存句法特征生成篇章結構對應的特征實例集5 585個篇章單元對,采用五折交叉驗證進行實驗,表4給出了每個類別特征的正確率。

表4 基于單個特征篇章單元之間有無關系實驗效果

表5 基于多個特征篇章單元之間有無關系實驗效果
通過表4可以看出每類特征對篇章結構分類效果的影響相繼是框架特征、目標詞特征、短語結構特征、依存句法特征,框架特征取得了最好的實驗效果,這表明框架特征包含了更多的語義信息,更有助于識別篇章單元之間是否存在關系。
為了驗證組合特征對篇章結構識別的影響,表5給出了特征組合對實驗結果的影響。在該實驗中,使用MI特征選擇方法,選擇400個短語結構特征、150個依存句法特征、全部框架特征、100個目標詞特征生成篇章結構對應的特征實例集,通過表5可以看出組合特征的實驗結果要優于單個特征,其中,框架、短語結構、依存句法和目標詞特征的組合識別效果最好,這表明特征組合時,篇章結構識別效果最好。
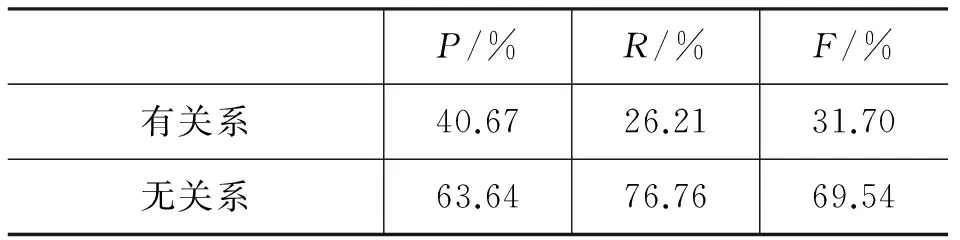
表6 篇章單元之間有無關系實驗總效果
表6給出了在所有特征組合下的篇章單元有無關系的P,R和F值。從表6中可以看出有關系的篇章單元對的識別效果較差,F值只有31.70%。
(3) 篇章關系實驗效果
本實驗采用頻數大于3的框架特征、目標詞特征、短語結構特征、句首特征和依存句法特征生成篇章關系對應的特征實例集2 110個,采用五折交叉驗證進行實驗。為了驗證各類特征在篇章關系識別上的作用,我們首先在正確標注篇章關系的數據上進行了實驗,表7給出了各類特征的實驗結果。將篇章關系中占據比例最大的并列類設置為基準系統,正確率為22.46%。
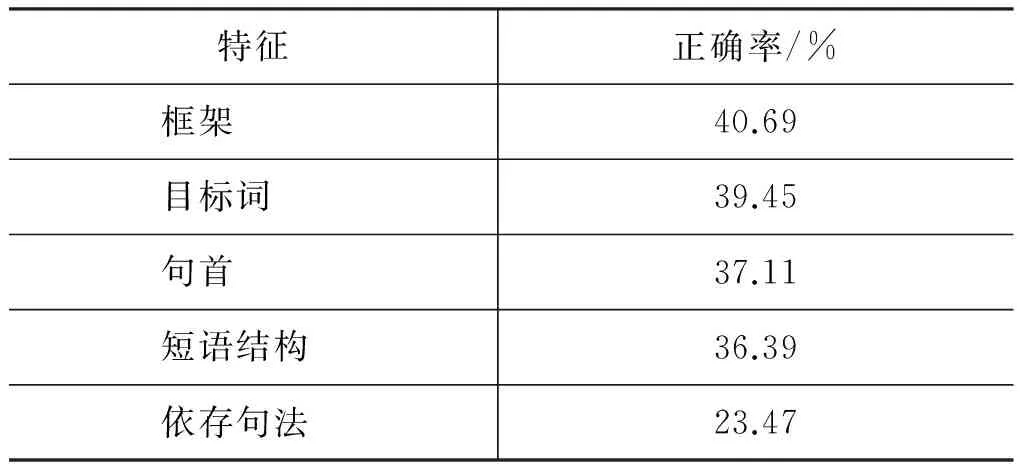
表7 基于單個特征篇章關系實驗效果

表8 基于多個特征篇章關系實驗效果
通過表7可以看出,本文選擇的幾組特征都是有效的,總正確率都超過了基準系統,每個特征對篇章關系分類效果的影響相繼是框架特征、目標詞特征、句首特征、短語結構特征和依存句法特征;框架特征的識別效果要優于目標詞特征、句首特征、短語結構特征和依存樹特征,達到了40.69%,這表明標注框架對于識別篇章關系是有效的。
為了驗證組合特征對實驗結果的影響,表8給出了特征組合對實驗結果的影響。通過表8可以看出,當所有特征組合時,實驗效果最好,達到了49.25%,比單個特征效果最好的框架提高了8.56%,這表明組合特征時,篇章關系識別效果要明顯優于單個特征。

表9 篇章關系總效果
表9分別給出了基于所有特征組合的每種篇章關系類別的P,R和F值。通過表9可以看出,選擇類與轉折類沒有識別出來,假設類識別準確率較低,這是由于數據稀疏引起的,在整個語料中,選擇類的實例僅有四個,假設類所占比重為2.61%,轉折類所占比重為2.66%。遞進類的識別效果較差,是由于遞進類與并列類的特征具有較大的相似性,如若沒有明顯的連接詞作指示,很難區分這兩個類別。屬于類的識別效果最好,是由于屬于類別的篇章關系,多是由“說”、“宣布”等一些表達篇章意圖的句首表達,這些詞語激起了“陳述”框架,特征明顯且屬于類的實例數較多,對于屬于類識別具有較強的針對性,因此屬于類識別效果最好。并列類、承接類、解說類、條件類、因果類、目的類的識別效果相當。
(4) 整體性能實驗效果
為檢驗篇章分析器的整體性能,即完全由篇章分析器完成篇章結構生成以及在結構樹上識別篇章關系,本實驗首先使用貪婪策略自下向上生成篇章結構樹,然后使用篇章關系分類模型對篇章結構分類模型輸出的有關系篇章單元對進行關系類型預測。本實驗使用397篇篇章作為訓練集,99篇篇章作為測試集,使用標準Parseval[19]中的指標P,R和F值作為測試標準,實驗結果如表10。
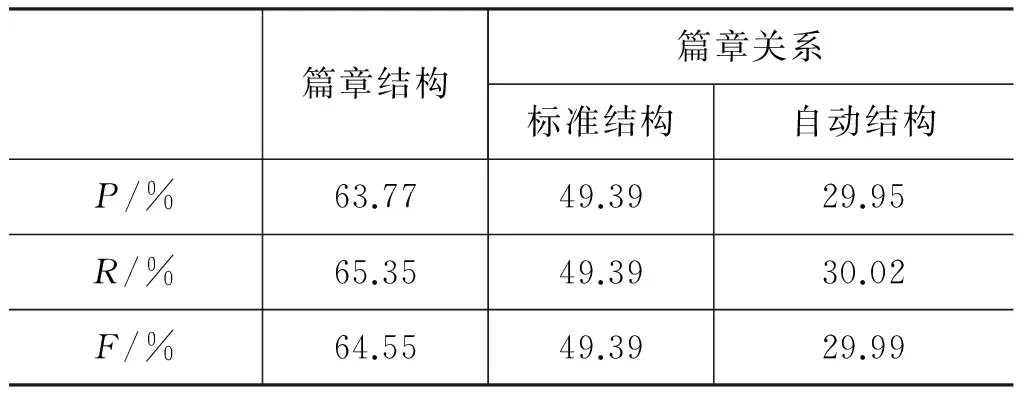
表10 整體實驗效果
通過表10可以看出,使用貪婪策略生成的篇章結構樹,F值可達到64.55%。在關系實驗中,使用自動生成篇章結構的F值29.99%比使用標準結構的F值49.39%有所下降,這是由于自動生成的篇章結構準確率較低且篇章關系分類器的準確率也較低,以至于在下一步的自動篇章關系識別上準確率有所下降。
5 結語
本文研究了如何運用框架語義切割漢語的篇章單元以及自動分析漢語篇章結構和篇章關系。在篇章自動分析過程中,我們提出了基于最大熵的分析方法,對篇章結構和篇章關系分別建模。在建模過程中使用到句首特征、依存句法特征、短語結構特征、目標詞特征、框架特征,實驗結果驗證了框架特征可以有效提高這兩個任務的準確率,為以后進一步的工作奠定了基礎。但是由于本文的框架覆蓋不全,造成實驗效果并未達到最優,因此在以后的工作中,我們將進一步進行框架的構建工作,同時有效地使用框架語義資源在漢語篇章分析方面的研究,如框架的語義角色、框架關系等,并擴大篇章單元的研究范圍。
[1]MannWC,ThompsonSA.Rhetoricalstructuretheory:Aframeworkfortheanalysisoftexts[J].IprapapersinPragmatics, 1987,1: 79-105.
[2]PrasadR,JoshiA.Adiscourse-basedapproachtogeneratingwhy-questionsfromtexts[C]//ProceedingsoftheWorkshopontheQuestionGenerationSharedTaskandEvaluationChallenge,Arlington,VA. 2008.
[3]LinZ,NgHT,KanMY.Automaticallyevaluatingtextcoherenceusingdiscourserelations[C]//Proceedingsofthe49thAnnualMeetingoftheAssociationforComputationalLinguistics:HumanLanguageTechnologies-Volume1.AssociationforComputationalLinguistics, 2011: 997-1006.
[4]MannWC,ThompsonSA.Rhetoricalstructuretheory:Towardafunctionaltheoryoftextorganization[J].Text, 1988,8(3): 243-281.
[5]CarlsonL,MarcuD,OkurowskiME.Buildingadiscourse-taggedcorpusintheframeworkofrhetoricalstructuretheory[J].CurrentandNewDirectionsDiscourseandDialogue, 2003: 85-112.
[6]HernaultH,BollegalaD,IshizukaM.Asequentialmodelfordiscoursesegmentation[C]//ProceedingsoftheComputationalLinguisticsandIntelligentTextProcessing.SpringerBerlinHeidelberg, 2010: 315-326.
[7]VanessaWeiFeng,GraemeHirst.Alinear-timebottom-updiscourseparserwithconstraintsandpost-editing[C]//Proceedingsofthe52ndAnnualMeetingoftheAssociationforComputationalLinguistics,Baltimore,Maryland,USA, 2014:511-521.
[8]PDTBResearchGroup.Thepenndiscoursetreebank2.0annotationmanual[R].Philadelphia:UniversityofPennsylvania, 2008.
[9]PitlerE,RaghupathyM,MehtaH,etal.Easilyidentifiablediscourserelations[C]//ProceedingsoftheInternationalConferenceonComputationalLinguistics. 2008:87-90.
[10]ZihengLin,Min-YenKan,HweeTouNg.Recognizingimplicitdiscourserelationsinthepenndiscoursetreebank[C]//Proceedingsofthe2009ConferenceonEmpiricalMethodsinNaturalLanguageProcessing.Morristown:AssociationforComputationalLinguistics, 2009: 343-351.
[11] 孫靜,李艷翠,周圍棟,等.漢語隱式篇章關系識別[J].北京大學學報(自然科學版),2014,(1):111-117.
[12] 張牧宇,宋原,秦兵,等.中文篇章級句間語義關系識別[J].中文信息學報,2014,27(6):51-57.
[13] 姬建輝,張牧宇,秦兵,等.中文篇章級句間關系自動分析[J].江西師范大學學報(自然科學報),2015,2(2):124-131.
[14] 涂眉,周玉,宗成慶.基于最大熵的漢語篇章結構自動分析方法[J].北京大學學報(自然科學版),2014,1(1):125-132.
[15]Fillmore,CharlesJ.Framesemantics[A].InLinguisticsintheMorningCalm,theLinguisticSocietyofKorea,Seoul:Hanshin,1982:111-137.
[16] 李茹.漢語句子框架語義結構分析技術研究[D].山西大學博士學位論文. 2012.
[17] 郝曉燕,劉偉,李茹等.漢語框架語義知識庫及軟件描述體系[J].中文信息學報, 2007, 21(5): 96-100.
[18] 黃伯榮,廖序東.現代漢語[M].北京: 高等教育出版社.2011.
[19]AbneyS,FlickingerD,GdaniecC,etal.ProcedureforquantitativelycomparingthesyntacticcoverageofEnglishgrammars[C]//ProceedingsoftheWorkshoponSpeech&NaturalLanguage, 1991:306-311.
Frame-Based Discourse Structure Modeling and Relation Recognition for Chinese Sentence
LV Guoying1,SU Na1,LI Ru1,2,WANG Zhiqiang1,CHAI Qinghua3
(1. School of Computer & Information Technology, Shanxi University, Taiyuan, Shanxi 030006, China;2. Key laboratory of Computation Intelligence and Chinese Information Processing of Ministry of Education, Shanxi University, Taiyuan, Shanxi 030006, China;3. School of Foreign Languages, Shanxi University, Taiyuan, Shanxi 030006, China)
Frame semantics is introduced to the research of Chinese discourse analysis which includes three subtasks: discourse segmentation, discourse structure modeling and discourse relation recognition. First, the Chinese discourse coherence framework and a corresponding corpus is built based on frame semantics. Then two kinds of maximum entropy classifiers are applied to recognize the relation between discourse units and the class of discourse relation based on lexical features, dependency parser features, syntactic parser features, target features and frame sematic features. Finally, we use probability of the relation existence between discourse units to generate the discourse structure by greedy bottom-up method. Experimental results show that frame sematic can segment discourse units effectively and frame sematic feature can improve the performance of discourse structure construction and discourse relation recognition.
Discourse units; Discourse Structure; Discourse Relation; Greedy Bottom-up Method

呂國英(1964—),通信作者,碩士,副教授,碩士生導師,主要研究領域為自然語言處理。E-mail:english@sxu.edu.cn蘇娜(1989—),碩士研究生,主要研究領域為中文信息處理。E-mail:cindysunas@163.com李茹(1965—),博士,教授,博士生導師,主要研究領域為自然語言處理。E-mail:liru@sxu.edu.cn
1003-0077(2015)06-0098-12
2015-07-10 定稿日期: 2015-10-10
國家自然科學基金(61373082);山西省科技基礎條件平臺建設項目(2014091004-0103);山西省回國留學人員科研資助項目(2013-015);國家863計劃項目(2015AA015407);中國民航大學信息安全測評中心開放課題基金項目(CACC-ISECCA-201402)
TP391
A
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代語文(2016年21期)2016-05-25 13:13:44
現代企業(2015年9期)2015-02-28 18:56:50
大連民族大學學報(2015年2期)2015-02-27 08:28:11
