典型小生境遺傳算法原理與性能比較分析*
2014-08-08 09:19:44茹婷婷
通化師范學院學報 2014年4期
關鍵詞:機制
趙 越,茹婷婷
(1.吉林建筑大學計算機科學與工程學院,吉林長春130118;2.吉林建筑大學基礎科學部,吉林長春130118)
近年來,隨著智能計算領域各項研究的不斷深入,人們對于遺傳算法的認識也在不斷豐富和提升.與傳統意義上的優化算法相比,遺傳算法的通用性和魯棒性更強,故其在各個領域的應用很廣[1-2].盡管如此,基本遺傳算法本身也存在不盡如人意的地方,主要表現在兩個方面:一是問題的求解過程中可能會出現早熟或隨機漫游現象;二是遺傳算法不具備全局收斂性[3-4].對于這些不足,究其根本原因在于缺乏對種群多樣性的保護機制.針對各種優化問題而言,求解的目標往往更加全面,即需要全局最優解和局部最優解.在遺傳算法中引入小生境技術能夠很好地解決這個問題.
1 小生境技術與物種形成過程
在自然環境當中,“物以類聚,人以群分”是一種普遍的現象.這說明生物往往傾向于和其本身在性狀和特征等方面相似的同類在一起生活,并與其同類交配完成后代的增殖.生物的這種生存特點和增殖方式是有其積極意義的.在生物學上,小生境(niche)是指特定環境下一種組織的功能,我們也常常把具有共同特性的組織稱為物種(species).
為了說明小生境技術相對于基本遺傳算法的優勢所在,我們考察基本遺傳算法應用于多峰函數最大值點的求解與搜索過程.對于如(1)所示多峰函數,欲求其最大值點.
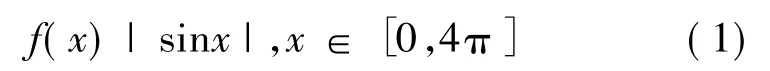
若選用基本遺傳算法,初始群體的產生常常是以均勻分布的方式隨機產生.在算法的初始階段,個體在函數的定義域內分布范圍相對較寬.伴隨著整個優化過程的不斷推進,群體將逐漸聚集到一個山峰上,我們得到的并非是全部的解.產生這種現象的根本原因是由于單一群體的規模有限,無法完成對于定義域內所有點的探測.而在實際應用中,常常也需要得到其他山峰的情況.于是我們考慮生物界中的真實情況,也就是說交叉操作并非完全隨機,它受物種類別、所在區域、性別等條件的限制.盡管加入某些限制會對算法的性能造成一定影響,但從另一個角度講它能夠以一定區域為限制保持種群的多樣性,這是有現實意義并被實驗研究證明為有效的方法.因而我們需要對現有具有代表性的小生境技術進行研究.
2 典型小生境技術研究
對于小生境機制的模擬方法,近年來已經出現多種.歸納起來主要有三類,具體如下.
2.1 基于預選擇機制的小生境技術
基于預選擇機制的小生境技術是由Cavicchio于1970年在已有遺傳算法理論基礎上首先提出的.該預選擇機制規定,只有新生成子串的適應度超過其父串的時候,子串才能完成對父串的替換.也就是說,這種機制僅允許子代替換與其本身性狀相似的個體(即父代個體),因而該方法能夠有效保持群體的多樣性.更進一步講,Cavicchio認為該方法可以在群體規模較小的條件下仍能保持群體的多樣性.基于預選擇機制算法的實現步驟如下.
step1 算法初始化.主要完成初始種群的建立,遺傳參數的設定等.
step2 完成種群中所有個體適應度的計算.
step3 執行遺傳操作,即選擇、交叉、變異.
step4 針對新生成子串和父串的適應度大小進行比較.若子串的適應度比父串的適應度高,則子串替換父串;否則保持父串不變.
step5 若滿足算法終止條件,則算法停止;否則返回step2.
2.2 基于擁擠機制的小生境技術
1975年,De Jong對Cavicchi的預選擇機制進行了改進,提出基于擁擠機制的小生境技術.在該排擠機制中,De Jong針對每代群體選擇代間覆蓋的機制,根據相似度來完成群體中一部分個體的替換.算法的具體實現步驟如下.
step1 算法初始化.主要完成初始種群的建立,遺傳參數的設定,排擠因子CF的確定等.
step2 完成種群中所有個體適應度的計算.
step3 執行遺傳操作,即選擇、交叉、變異.
step4 隨機確定當前群體中1/CF個個體作為排擠因子成員.
step5 完成新生成個體與排擠因子成員相似性的比較.
step6 新群體的生成.即使用新生成的個體選擇排擠因子成員中最相似的個體完成替換.
step7 若滿足算法終止條件,則算法停止;否則返回step2.
對于以上算法,執行的起始過程由于群體中個體的差別不大,故替換操作多數情況下為隨機選擇;隨著算法不斷執行,群體中個體將形成多個小生境并逐漸被分類.在這種情況下,該算法選擇與其自身性狀最相似的排擠因子進行替換,故能夠保持群體的多樣性.據De Jong稱,基于擁擠機制的小生境遺傳算法針對某些優化問題能夠獲得比較滿意的結果,如多峰函數求極值等.
2.3 基于共享機制的小生境技術
基于共享機制的小生境技術是Goldberg和Richardson于1987年提出的.在該機制中,使用共享函數來確定每個個體在整個群體中的共享度.一個個體共享度的計算方法為該個體與整個群體中所有其他個體之間共享函數值之和.共享函數能夠提供群體中兩個個體之間關系密切程度(根據基因或表現型的相似性確定)的度量.若共享函數值較大則表明兩個個體間的關系較密切;反之則表明兩個個體間關系的密切程度不大.
也可以用形式化的方式來表達這個問題.設dij表示兩個個體之間關系的密切程度(度量方式有多種,如海明距離等).若以S表示共享函數,Si表示個體i在群體中的共享度,則(其中m為群體中個體的數量減1).
在完成群體中所有個體共享度計算的基礎上,個體i的適應度f(i)調整為fs(i),其中fs(i) =f(i)/Si.據此可知,基于共享機制的小生境技術能夠限制種群中的某一個或特殊個體無限制的增殖.目標已有的測試數據表明,較基本遺傳算法而言,基于共享機制的小生境技術在解決多峰函數的優化問題時能夠體現出更好的搜索性能.基于共享機制的小生境遺傳算法的基本實現步驟如下.
step1 算法初始化.主要完成初始種群的建立,遺傳參數的設定等.
step2 完成種群中所有個體適應度的計算.
step3 執行遺傳操作,即選擇、交叉、變異.
step4 完成種群中所有個體共享度的計算.
step5 根據個體的共享度重新計算每個個體的適應度.
step6 對子代和父代個體的適應度大小進行比較.
step7 用子代個體替換父代個體,形成新一代群體.
step8 若滿足算法終止條件,則算法終止;否則返回step3.
2.4 隔離小生境技術
通過考察自然界中存在地理隔離方式,我們將遺傳算法中的初始群體以某種方式進行劃分,得到若干個子群體.子群體間的進化是彼此獨立的.而各個子群體由于其平均適應度不同,故子群體間的進化速度和群體自身規模通常是有差異的.由于隔離后的子群體的進化過程彼此獨立,故可以針對各子群體進行更為靈活的控制.據此,我國學者提出隔離小生境技術的概念.另外,自然界中的競爭不僅存在于種群中個體之間,種群與種群之間也存在相互競爭.也就是說,適者生存的機制不僅存在于個體之間,對于種群也同樣適用.在隔離小生境技術中,我們通過引入兩級競爭機制來實現競爭機制,以保證得到更優秀的個體.
3 幾種小生境技術性能比較分析
適應值共享算法的執行起始為選擇階段,該方法通過調整個體適應值的手段達到維持種群多樣性的目的.擁擠算法的執行起始為替換階段,新個體以某種方式與老個體競爭完成替換,目的同樣是維持種群多樣性.而遺傳算法的競爭機制為優勝劣汰,由于適應值共享算法能夠通過調整個體適應值完成搜索過程,故其對于解的搜索能力優于擁擠算法.
預選擇機制通過限定只有子串才能完成對父串的替換,故該方法能夠在一定程度上維持種群多樣性.但由于該方法較擁擠機制的靈活度差,故其收斂和搜索性能不及擁擠算法.
隔離小生境遺傳算法為兩級競爭機制,即子群體中個體之間的競爭和子群體之間的競爭.子群體個體間的競爭側重于局部搜索性能,而子群體間的競爭側重于全局搜索性能.故該算法能夠較好的平衡遺傳算法局部搜索與全局搜索間的矛盾.
[1]華潔,崔杜武.基于個體優化的自適應小生境遺傳算法[J].計算機工程,2010(1):200-202.
[2]陸青,梁昌勇,楊善林,張俊嶺.面向多模態函數優化的自適應小生境遺傳算法[J].模式識別與人工智能,2009(1):93-99.
[3]譚艷艷,許峰.自適應模糊聚類小生境遺傳算法[J].計算機工程與應用,2009(4):56-59.
[4]黃鵾,陳森發,孫燕,郜振華.一種小生境正交遺傳算法研究[J].東南大學學報(自然科學版),2004(1):135-137.
猜你喜歡
四川勞動保障(2021年9期)2022-01-18 05:11:08
文苑(2018年21期)2018-11-09 01:23:06
當代陜西(2018年9期)2018-08-29 01:21:00
當代陜西(2017年12期)2018-01-19 01:42:33
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:00
中國衛生(2016年9期)2016-11-12 13:28:08
中國衛生(2015年9期)2015-11-10 03:11:12
醫學研究雜志(2015年12期)2015-06-10 06:57:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
