基于兩階段學(xué)習(xí)的半監(jiān)督SVM故障檢測方法
2012-09-15 10:24:34陶新民曹盼東宋少宇付丹丹
振動與沖擊 2012年23期
陶新民,曹盼東,宋少宇,付丹丹
(哈爾濱工程大學(xué) 信息與通信工程學(xué)院,哈爾濱 150001)
故障檢測就是對測取的含有故障信息的信號利用信號處理和分析技術(shù),找出和故障有關(guān)的特征參數(shù)并利用這些特征參數(shù)對設(shè)備的實時技術(shù)狀態(tài)進行判別。這里涉及到兩個方面的問題,一是利用信號處理技術(shù)進行特征提取;二是利用模式識別技術(shù)進行故障檢測。在信號特征提取方面,主要分為:信號的時域特征,如信號的均值、均方值、峰值、峭度和歪度等;信號頻域特征,如能量譜、AR功率譜等;以及信號的時頻特征,如小波分析,Hilbert變換和短時傅里葉變換等[1]。
在模式識別方法方面,支持向量機算法(SVM)因其良好的非線性區(qū)分能力,已廣泛應(yīng)用到故障檢測領(lǐng)域[2-5]。支持向量機主要思想是建立一個最優(yōu)決策超平面,使得該平面和最近的兩類樣本(即支持向量)之間的距離最大化,從而避免以往神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)出現(xiàn)的過擬合、易陷入局部極值和維數(shù)災(zāi)難等諸多問題。但是,傳統(tǒng)基于支持向量機的故障檢測方法[3-6]只能使用樣本集中的已標識樣本進行學(xué)習(xí),而在軸承故障檢測領(lǐng)域,人工標識樣本的代價太大,因此只有少數(shù)樣本是標識過的,大量的是未標識的樣本。而傳統(tǒng)的SVM方法作為一種監(jiān)督檢測算法,需要一定數(shù)量且屬于不同類別的標識樣本進行訓(xùn)練才能獲得較好的故障檢測能力。如今,一種聯(lián)合標識樣本和未標識樣本的半監(jiān)督學(xué)習(xí)方法吸引了眾多科學(xué)工作者的目光,并逐漸成為當前機器學(xué)習(xí)領(lǐng)域的研究熱點[7-9]。
半監(jiān)督學(xué)習(xí)是將已標識樣本和未標識樣本提供的聚類信息結(jié)合起來,進而提高算法的分類精度。因此,可以說,半監(jiān)督學(xué)習(xí)方法較傳統(tǒng)分類算法更有助于解決實際問題。目前,結(jié)合未標識樣本信息來提高SVM算法的性能也有一些文獻提出,如 Joachims在文獻[10]中提出了直推式支持向量機(TSVM),加入了未標識樣本形成的規(guī)劃項,引導(dǎo)分類超平面通過低密度區(qū),減小錯分的概率,但同時帶來了非凸優(yōu)化的問題;Mikhail等[11]提出了LapSVM算法,考慮了樣本集的內(nèi)部結(jié)構(gòu),但由于半正定優(yōu)化問題同樣導(dǎo)致該算法易陷入局部解。為了能更好地利用未標識樣本信息來提高SVM算法性能,本文提出一種基于兩階段學(xué)習(xí)的SVM算法并將其應(yīng)用到故障檢測領(lǐng)域。該算法首先在利用基于圖的半監(jiān)督模型給未標識樣本加以偽標識;隨后將這些偽標識樣本與標識樣本作為整個訓(xùn)練樣本集,輸入到SVM算法中進行訓(xùn)練學(xué)習(xí),使得SVM算法在訓(xùn)練時能充分考慮未標識樣本帶來的結(jié)構(gòu)信息,進而提高算法的分類精度。考慮到偽標識生成過程中可能會有噪聲,在SVM訓(xùn)練前根據(jù)k近鄰圖,對比樣本標識值識別噪聲樣本并刪除,針對剩下的每個樣本根據(jù)其所屬類別的概率設(shè)置不同的懲罰因子,來增強SVM算法的魯棒性和抗干擾能力。實驗部分將本文提出的基于兩階段學(xué)習(xí)的半監(jiān)督SVM算法應(yīng)用到故障檢測領(lǐng)域同其他SVM算法進行對比,結(jié)果說明本文算法在只有少量標識樣本的情況下故障檢測精度較其他算法有較大幅度提高。
1 傳統(tǒng)的支持向量機分類算法
支持向量機算法是建立在統(tǒng)計學(xué)習(xí)理論中結(jié)構(gòu)風險最小化原理基礎(chǔ)上,根據(jù)有限的樣本信息,在模型復(fù)雜度和學(xué)習(xí)能力之間尋求最佳匹配,以期獲得最好的泛化能力。它通過核函數(shù)將原始特征空間中的非線性分類界面映射到更高維的特征空間中,使得分類界面在高維特征空間中變得線性可分,使分類效果更好。
其過程可表述為,對于n個樣本的二分類問題,假設(shè){(x1,y1),(x2,y2),…,(xn,yn)}為給定的訓(xùn)練樣本和其期望輸出,尋找最優(yōu)權(quán)值向量w和閾值b,使下面的代價函數(shù)最小化[12]。
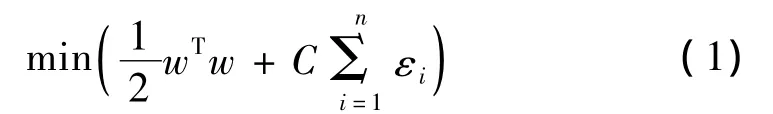
約束條件:
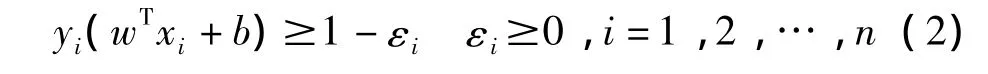
式中:C>0是懲罰因子,表示對錯分樣本的懲罰程度,εi為松弛變量,表示對訓(xùn)練樣本的錯分程度。可以利用拉格朗日乘子法求解該問題的最優(yōu)解,從而確定最優(yōu)分類。
為了測試較少標識樣本對SVM分類器性能的影響,選用月牙形樣本集,該樣本集共200個:類1有104個;類2有96個。SVM算法的參數(shù)設(shè)置為:高斯核函數(shù),核寬度0.35,懲罰因子C=1 000,已標識的訓(xùn)練樣本數(shù)為10個,類別比例定為6∶4,分別用菱形和實心圓表示,未標識樣本為190個,用正方形虛框表示,訓(xùn)練后得到的SVM最優(yōu)分類界面如圖1所示。
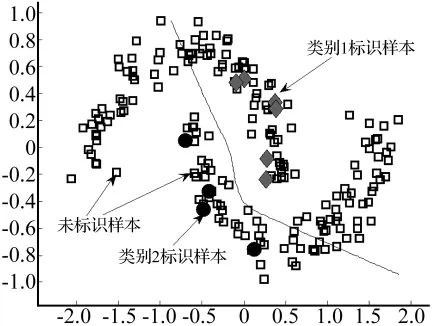
圖1 傳統(tǒng)SVM分類器得出的分類界面Fig.1 The classification interface after using the traditional classifier
從圖1可以看出,由于訓(xùn)練樣本中標識樣本太少,提供的樣本集信息太少,無法準確代表整個樣本集合的樣本分布信息,只依靠這些標識樣本,訓(xùn)練出的SVM分類器泛化性能并不理想。因此傳統(tǒng)SVM分類算法在標識樣本較少時得到的分類器泛化性能較差,而這種缺乏樣本標識的情況在現(xiàn)實中是普遍存在的,因此如何提高標識樣本較少情況下的SVM分類器泛化性能是值得深入研究的。
2 基于兩階段學(xué)習(xí)的半監(jiān)督SVM算法
為了能將未標識樣本的聚類信息[13]納入到訓(xùn)練過程,進而提高SVM算法的分類精度,本文提出一種基于兩階段學(xué)習(xí)的半監(jiān)督SVM分類算法。算法首先利用基于圖的半監(jiān)督模型給未標識樣本以偽標識,然后將這些偽標識樣本和標識樣本共同輸入到SVM算法中,使得SVM算法在訓(xùn)練階段能得到更全面的樣本集合信息,進而提升算法的分類性能。
2.1 算法中的偽標識生成
偽標識的生成主要分為兩步:構(gòu)建圖模型,根據(jù)某種距離度量計算相似度矩陣;依據(jù)概率轉(zhuǎn)移矩陣生成偽標識[14]。
2.1.1 確定相似度矩陣
假設(shè)訓(xùn)練樣本特征x為d維向量,y為樣本x的標識值,樣本總數(shù)為n:n=l+u。其中前l(fā)個為已標識樣本,樣本特征和對應(yīng)標識值構(gòu)成的樣本集合為L:L={(x1,y1),(x2,y2),…,(xl,yl)};后 u 個為未標識樣本,樣本特征和對應(yīng)標識值構(gòu)成的樣本集合為U:U={(xl+1,yl+1),(xl+2,yl+2),…,(xl+u,yl+u)},則整體訓(xùn)練樣本集合為S:S=L∪U。
利用基于歐氏距離的高斯函數(shù)構(gòu)建相似度矩陣W。為方便矩陣運算,將矩陣W分割成四個子矩陣,如式(3)所示,其中Wll為已標識樣本間的相似度矩陣,Wlu為已標識樣本和未標識樣本間的相似度矩陣,Wul為未標識樣本和已標識樣本間的相似度矩陣,Wuu為未標識樣本間的相似度矩陣。
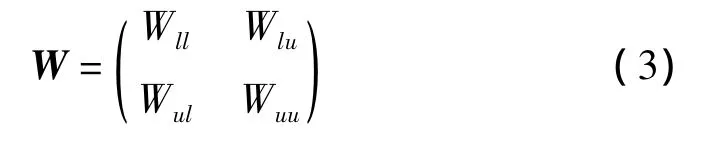
2.1.2 依據(jù)轉(zhuǎn)移概率確定偽標識
定義標識轉(zhuǎn)移概率Tij,表示標識從第j個樣本轉(zhuǎn)移到第i個樣本的概率。其具體表示形式見式(4)。

其中:wij表示相似度矩陣W中第i個樣本和第j個樣本間?的相似度表示第j個樣本和其他所有樣本間的相似度總和。
同時定義標識矩陣Y∈R(l+u)*N,N代表總類別數(shù),Y的每行代表樣本點xi屬于每一類的概率,其中未標識樣本屬于每一類的初始概率定為1/N,表示其所屬類別待確定。
偽標識生成基本步驟為:傳遞標識Y←YT;行單位化Y;固定標識樣本,重復(fù)執(zhí)行傳遞,直到Y(jié)收斂。為方便計算,將矩陣分割為:
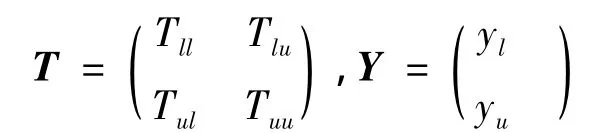
可導(dǎo)出未標識樣本的偽標識矩陣為:
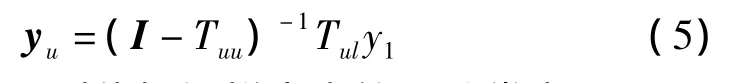
式中I為單位陣。則偽標識樣本點的預(yù)分類為:

式中:ciu為偽標識樣本集中第i個樣本所屬的類別,yuij為偽標識樣本中第i個樣本屬于第j類的概率,此處i=l+1,l=2,…,l+u,j=1,2,…,N。
圖2為偽標識生成后,利用本文算法訓(xùn)練得出的分類界面,其中加號表示類別1偽標識樣本,菱形框表示類別2偽標識樣本。
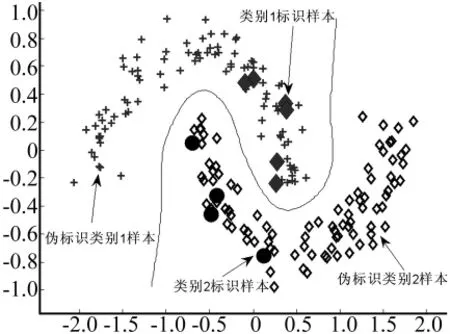
圖2 偽標識生成情況和分類界面Fig.2 The classification interface and the of producing circumstance pseudo labels
由圖2可以看出本文提出的兩階段學(xué)習(xí)模型,能充分發(fā)掘整體樣本集的分布信息,利用已有的標識樣本信息對未標識樣本進行偽標識,從而得到更多的訓(xùn)練樣本,這樣使得SVM分類器在訓(xùn)練時能兼顧全局聚類信息,而不會陷入局部最優(yōu)解,得出的分類器反映了整體樣本集的分布結(jié)構(gòu),最終提高了SVM分類器的泛化性能。同時本文算法還需能對邊界噪聲樣本進行處理,以避免標識穿越低密度區(qū)導(dǎo)致錯傳的情況,最大程度地保證SVM分類器在訓(xùn)練時能得到更多更準確的樣本集信息。
2.2 算法中核寬度的確定
在偽標識生成過程中,相似度矩陣W中的核寬度δ以往都是通過反復(fù)實驗得出的,增加了其計算時間和復(fù)雜度,為此本文采用自適應(yīng)調(diào)節(jié)的方法。

2.3 對偽標識樣本進行去噪處理
生成的偽標識樣本中可能存在邊界噪聲樣本,將導(dǎo)致SVM算法得到的信息有偏差,致使最終訓(xùn)練出的SVM算法分類能力被削弱,因此需要對偽標識樣本進行去噪處理。本文采取兩種方法,第一種通過對比標識值,識別并刪除噪聲樣本,第二種根據(jù)樣本所屬類別的信任度設(shè)置不同的懲罰因子。
將相似度矩陣W轉(zhuǎn)換成k近鄰圖相似矩陣W*,以表征樣本間的聚類結(jié)構(gòu)信息。根據(jù)k近鄰圖稀疏矩陣,對比樣本點和其近鄰點的標識,如果某樣本點的標識值和其近鄰點的偽標識值不相同,需判斷該樣本是否為噪聲樣本。令下式:

其中:yu是未標識樣本點的偽標識矩陣。W*是k近鄰圖相似矩陣,則偽標識樣本點的預(yù)分類變?yōu)?


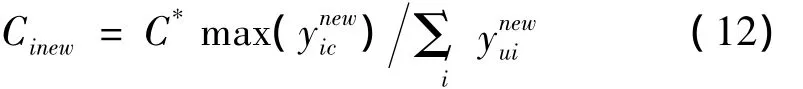
2.4 基于兩階段學(xué)習(xí)半監(jiān)督SVM故障檢測算法流程
本文將上述基于兩階段學(xué)習(xí)的半監(jiān)督SVM算法應(yīng)用到故障檢測中,具體步驟如下:
(1)首先根據(jù)相應(yīng)的故障特征提取方法計算出特征向量,將標識樣本和未標識樣本組合成樣本集合;
(2)計算樣本集的相似度矩陣W并變換成k近鄰圖相似矩陣W*,相似度計算時采用高斯核參數(shù),其參數(shù)選擇采用的是平均7近鄰距離法;
(3)確定標識轉(zhuǎn)移概率矩陣T,計算未標識樣本的偽標識矩陣yu;
(4)利用公式(10)和(11)去除噪聲樣本,得到新的樣本標識矩陣
(5)用公式(12)計算每個樣本的懲罰因子Cinew,將處理后的樣本集(xi)及參數(shù)Cinew代入到SVM的優(yōu)化函數(shù)(1)中,K(xi,xj)選用高斯核函數(shù),核參數(shù)與相似度矩陣W的參數(shù)取值相同;
(7)對于新的采樣信號,計算其特征值,然后輸入到?jīng)Q策函數(shù)進行故障檢測判斷。
3 試驗分析
3.1 特征提取
本文采用的試驗樣本來自美國Case Western Reserve University電氣工程實驗室[15]。振動信號的收集來自安裝在感應(yīng)電機輸出軸支撐軸承上端機殼上的振動加速度傳感器。實驗?zāi)M了滾動軸承的4種運行狀態(tài):①正常運行狀態(tài);②外圈故障;③內(nèi)圈故障;④滾動體故障。
本文采用基于相空間重構(gòu)(RPS)模式的特征提取方法,其中相空間重構(gòu)的參數(shù)包括嵌入維數(shù)m和延遲時間間隔τ。選用訓(xùn)練樣本易得的正常樣本相空間的投影系數(shù)作為故障特征,即首先確定正常樣本相空間的參數(shù),然后取其他類型的樣本在該空間的投影系數(shù)作為故障檢測的特征[2],具體描述如下:
若軸承振動信號時間序列為:
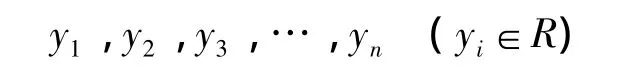
當正常樣本相空間的嵌入維數(shù)為m,延遲時間間隔為τ,則采用時間延遲技術(shù)重構(gòu)相空間為:
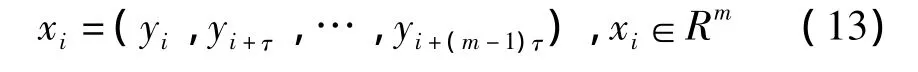
式中:xi為信號在重構(gòu)相空間的投影系數(shù),其中相空間的參數(shù)利用互信息函數(shù)指標來確定,嵌入維度選擇文獻[2]提供的方法。試驗確定的正常樣本相空間的延遲間隔τ等于2,嵌入維度m等于5,因此故障檢測的特征為5維矢量。最終形成正常樣本、內(nèi)圈故障樣本、外圈故障樣本和滾動體故障樣本四種5維矢量作為故障檢測特征。
3.2 故障檢測試驗對比
選擇前面生成的1 000個正常樣本、1 000個內(nèi)圈故障樣本、1 000個外圈故障樣本和1 000個滾動體故障樣本組成訓(xùn)練集合,同樣分別選擇1 000個樣本組成測試樣本集合。有標識樣本集大小從100到500,間隔為50進行變化。將本文的基于兩階段學(xué)習(xí)的半監(jiān)督支持向量機算法(TSLSVM)同支持向量機算法(SVM),模糊支持向量機算法(FSVM),直推式支持向量機算法(TSVM),拉普拉斯支持向量機算法(LapSVM)進行比較學(xué)習(xí)。
實驗迭代次數(shù)為20次,取20次的平均值作為最終的結(jié)果。SVM中核函數(shù)為高斯函數(shù),采用10次交叉驗證法選擇最佳的核寬度為0.35,懲罰因子為 C=1 000,拉格朗日因子λ=10-7;本文算法中k近鄰圖的近鄰數(shù)選為7;TSVM中懲罰函數(shù)C=1/2λ,核函數(shù)為徑向基函數(shù),核寬度為0.35;FSVM算法的模糊度計算中,近鄰數(shù)K值為9,模糊度為1;LapSVM中RKHS(再生核希爾伯特空間)規(guī)劃因子γA=10-5,流行規(guī)劃因子γI=1,近鄰數(shù) NN=7。
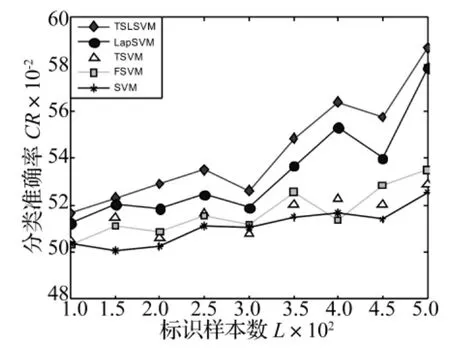
圖3 不同標識樣本數(shù)目下的內(nèi)圈故障檢測率Fig.3 Plot of inner fault detection rate under labeled samples with different sizes
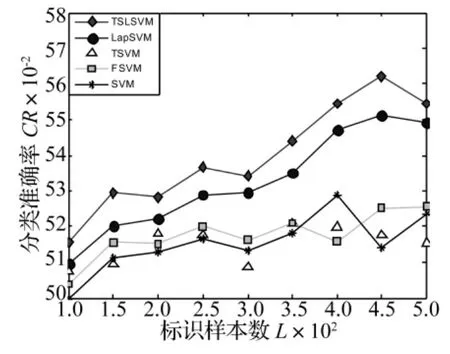
圖4 不同標識樣本數(shù)目下的外圈故障檢測率Fig.4 Plot of outer fault detection rate under labeled samples with different sizes
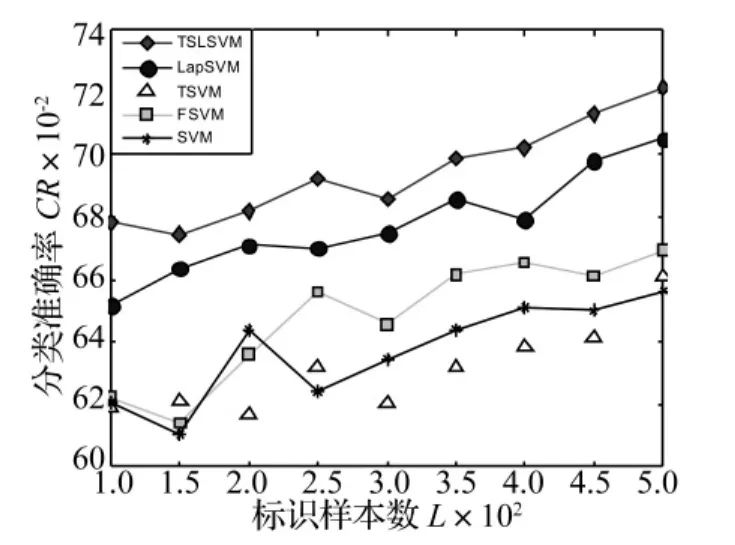
圖5 不同標識樣本數(shù)目下的滾動體故障檢測率Fig.5 Plot of ball fault detection rate under labeled samples with different sizes
試驗結(jié)果如圖3~5所示,其中圖3為內(nèi)圈故障的檢測結(jié)果,圖4為外圈故障檢測結(jié)果,圖5為滾動體故障檢測結(jié)果。從這些實驗結(jié)果可以看出,隨著標識樣本數(shù)目的增多,各種算法的檢測性能也隨之增強,另外本文算法在不同數(shù)目的標識樣本集合下檢測性能都好于其他算法,這是由于本文算法是一個半監(jiān)督算法,它充分考慮到了未標識樣本集合提供的聚類結(jié)構(gòu)信息,因此檢測性能大大提高。LapSVM因其本身的半正定優(yōu)化問題,使算法易陷入局部解,導(dǎo)致檢測效果不理想。TSVM由于在引入未標識樣本的信息時產(chǎn)生了非凸優(yōu)化問題,使算法易陷入局部極小解,最終的檢測結(jié)果不如人意。FSVM算法對邊緣噪聲過于敏感,檢測精度受到了很大的影響。
3.3 含和不含測試樣本的本文半監(jiān)督檢測算法性能的比較試驗
為了驗證本文方法在考慮測試樣本信息下的故障檢測性能,將測試樣本集合加入到本文的訓(xùn)練方法中,作為未標識樣本集共同參與分類器的訓(xùn)練學(xué)習(xí),其他參數(shù)設(shè)置同上,同不含測試樣本的本文故障檢測方法進行比較,結(jié)果如圖6~8所示。
從實驗結(jié)果可看出,對于不同類型故障檢測性能,相同情況下,增加未標識樣本的數(shù)目使檢測精度平均提高了1%~2%。這是由于將大量的測試樣本加到未標識樣本集合中,使得半監(jiān)督學(xué)習(xí)算法能更加充分地利用它們提供的樣本空間聚類信息,盡可能發(fā)掘樣本集內(nèi)在的分布信息,使得SVM在訓(xùn)練學(xué)習(xí)時能提取到更多的樣本特征信息,計算出來的流行結(jié)構(gòu)更加精確,更能準確模擬出樣本間的結(jié)構(gòu),使得最終訓(xùn)練出的分類界面更加精確,因此檢測性能會大大提高。
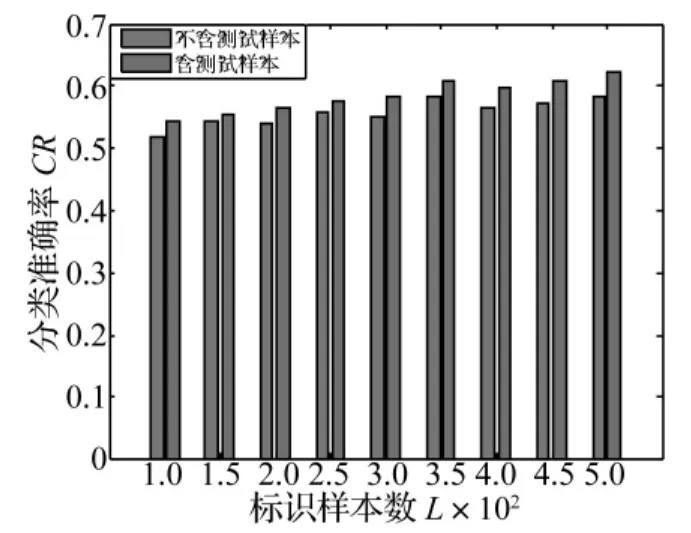
圖6 含和不含測試樣本對內(nèi)圈故障檢測結(jié)果對比Fig.6 Comparison of inner fault detection of the proposed method with test data and without test data
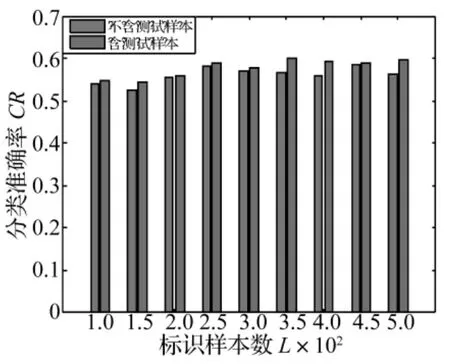
圖7 含和不含測試樣本對外圈故障檢測結(jié)果對比Fig.7 Comparison of outer fault detection of the proposed method with test data and without test data
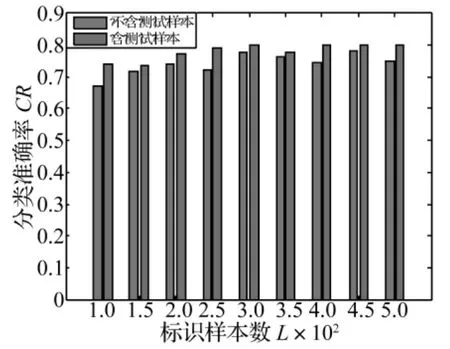
圖8 含和不含測試樣本對滾動體故障檢測結(jié)果對比Fig.8 Comparison of ball fault detection of the proposed method with test data and without test data
3.4 k值對本文算法的影響
為了測試k近鄰圖相似矩陣中不同近鄰數(shù)k值對本文算法性能的影響,將 k 值取為 2,4,6,8,10,12,14。標識樣本數(shù)目選擇100∶500,間隔為50,取不同數(shù)目標識樣本集訓(xùn)練后的平均結(jié)果,針對三種不同故障檢測類型進行實驗對比,其他參數(shù)同上,結(jié)果如圖9所示。
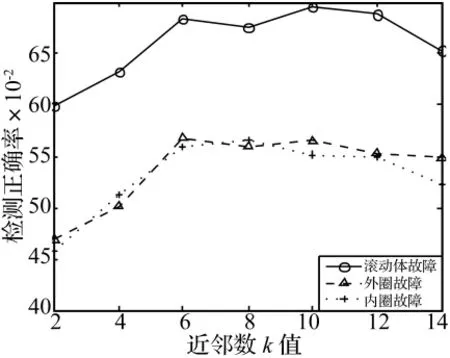
圖9 不同k值對檢測性能的影響Fig.9 The effect of different k value on performance
由實驗結(jié)果可以看出k設(shè)置在6~11處即可,分類精度在此區(qū)間時比較好而且較穩(wěn)定。k選取太小就成了最近鄰法,如果樣本集合分散度高的話,得出的參數(shù)不能很好的代表相似樣本間的相似信息;k值過大時有可能將類別外的樣本納入其中,帶來了類間的相互干擾,導(dǎo)致最終分類精度呈下降趨勢。
4 結(jié)論
本文提出了一種基于兩階段學(xué)習(xí)的半監(jiān)督SVM故障檢測方法。該算法首先利用基于圖的半監(jiān)督模型,預(yù)先給未標識樣本進行偽標識,接著利用k近鄰圖將其中的噪聲樣本識別并刪除,然后將處理后的樣本集當成已標識樣本集交由SVM處理,使SVM算法充分考慮整個樣本的分布信息,最終提高故障檢測率。仿真試驗結(jié)果表明本文方法在不同比例的標識樣本集合情況下,故障檢測性能優(yōu)于其他算法。另外,本文對含有測試樣本和不含測試樣本的情況進行了比較,結(jié)果表明含有測試樣本學(xué)習(xí)的檢測性能較不含測試樣本好。由于未標識樣本在故障檢測領(lǐng)域很容易得到,因此本文方法具有很好的現(xiàn)實應(yīng)用價值。需要說明的是,本文算法并未對未標識樣本集中存在的不均衡樣本分布情況進行分析,這也是本課題下一階段深入研究的重點。
[1]陶新民,徐 晶.基于緊密度FSVM新算法及在故障檢測中的應(yīng)用[J].振動工程學(xué)報,2009,22(4):418 -424.
[2]陶新民,劉福榮.不均衡樣本下基于SVM的故障檢測新算法[J].振動與沖擊,2010,29(12):8-12.
[3]明 陽,陳 進.基于譜相關(guān)密度切片分析和SVM的滾動軸承故障診斷[J].振動與沖擊,2010,29(1):197-201.
[4]黃紅梅,袁慎芳.基于光纖Bragg光柵和支持向量機的沖擊損傷識別研究[J].振動與沖擊,2010,29(10):54-59.
[5]張 超,陳建軍.基于EMD能量熵和支持向量機的齒輪故障診斷方法[J].振動與沖擊,2010,29(10):217-221.
[6]Lin C F,Wan S D.Fuzzy support vector machines[J].IEEE Trans.on Neural Networks,2002,13(2):464 -471.
[7]Zhu X.Semi-supervised learning litertures survey[D].Technical Report 1530,Computer Science,University of Wiscinsin-Madison,2005:18-25.
[8]Bai S H.Semi-supervised learning of language model using unsupervised topic model[C].IEEE International Conference on Acoustics, Speech and Signal Processing-Proceedings,2010:5386-5389.
[9]Mehdizadeh M,MacNish C.Semi-supervised neighborhood preserving discriminant embedding:a semi-supervised subspace learning algorithm[J].Computer Science,2011,6494:199-212.
[10]Joachims T.Transductive inference for text classification using support vector machines[C].Proc.16th International Conf.on Machine Learning,1999:200 -209.
[11]Belkin M,Niyogi P.Manifold regularization[J].Machine Learning Research,2006,7(8):31-42.
[12]Cortes C,Vapnik V.Support vector networks[J].Machine Learning,1995,7(3):273 -297.
[13]Zhu X, GhahramaniZ. Semi-supervised Learningwith Gaussian fields and harmonic functions[C]//Proceedings of the Twentieth International Conference on Machine Learning.Washington DC,USA,2005:5-12.
[14]Zhu X,Ghahramani Z.Learning from labeled and unlabeled data with label propagation[D].Technical Report CMUCALD-02-107,Carnegie Mellon University,2002:1-7.
[15]These data comes from Case Western Reserve University Bearing Data Center Website[OL].http://www.eecs.cwru.edu/laboratory/bearings/.lobal information of the whole samples can be considered by SVM to enhancet
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
汽車維護與修理(2016年10期)2016-07-10 08:17:41
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
