“后摩爾時代”下的異構計算
2024-10-22 00:00:00陳隆
信息化建設 2024年8期



“后摩爾時代”,足夠的“算力”是人類獲取更大發展的前提,摩爾定律失效后如何滿足算力需求指數級增長?“異構計算系統”將能夠較好地解決問題
在近半個世紀的時長里,以CPU為主的計算類芯片,算力提升一直遵循著摩爾定律在高速發展,即隨著制造工藝的進步,每間隔約兩年時間,算力翻倍。進入21世紀,這類發展開始減速,算力翻倍所需的時間越來越長且成本越來越高,意味著“摩爾定律失效”了。而與此同時,“萬物智能互聯世界”的算力需求呈指數級增長,進而對計算芯片提出了更大算力、更低功耗且成本可控等要求。算力供給瓶頸與算力需求爆發這對矛盾的產生,開啟了“后摩爾時代”。足夠的“算力”是人類獲取更大發展的前提,在“后摩爾時代”,摩爾定律失效后如何滿足算力需求指數級增長,其意義極為重大。比較成熟的技術路徑“異構計算系統”,將能夠較好地解決問題。
認識芯片制程工藝
要了解算力,先從了解芯片的制程工藝開始。集成電路或者說芯片主要由晶體管構成,圖1是晶體管簡化的模型圖,“柵極”加電壓后,電流從左邊“源極”流向右邊“漏極”。1965年的一塊芯片可以集成幾十個晶體管,而今天,同樣面積可以集成以億為單位數量的晶體管。
“XXnm制程”工藝或“XXnm節點”工藝,是對芯片制造工藝的命名方式,命名中的“XX”數值越小,一般意味著工藝越先進,也意味著該工藝下,單個晶體管開關越快、功耗越低,單位芯片面積晶體管數量越多。命名中“XX”大于20nm的制程工藝,被稱之為“成熟制程”;小于20nm的制程工藝,被稱之為“先進制程”。但“成熟制程”和“先進制程”的區分,也有取值“28nm”為分界點的方式。
如圖1所示,“溝道”從左到右的長度,意味著“柵極長度”,是芯片制造工藝命名中“XX”的參考數字。直至20世紀90年代末,命名為“XXnm制程”的工藝,都代表著所生產芯片晶體管的柵極長度大約為“XXnm”(參見表1)。如命名為“350nm制程”的工藝,每個晶體管柵極長度約350nm。但隨著技術進步,工藝命名中的“XX”與柵極長度之間不再具有類似的對應關系。2019年,臺積電研發負責人黃漢森提出,“現在描述工藝水平的‘XXnm’說法已經不科學,因為它與晶體管柵極已經不是絕對相關,制程節點(指工藝命名,筆者注)已經變成了一種營銷游戲,與科技本身的特性沒什么關系”。
特別是“先進制程”,如命名為7nm、5nm、3nm制程等工藝之下的柵極長度,基本穩定在固定數值10nm左右。之所以命名為如7nm制程工藝,是因為按照某個公式,該工藝下晶體管的相關指標,等同于實際柵極長度達到7nm的晶體管,于是就將該工藝命名為“7nm制程”。后文將會解釋,為何產業化的制造工藝止步于約10nm的實際柵極長度。
解析摩爾定律及其失效原因
那么,為什么芯片產業化的制造工藝會止步于10nm的實際柵極長度?要探究其原因,需要先從了解摩爾定律開始。
1965年,摩爾定律被提出,但并未形成統一的定義。筆者通過梳理眾多解析,發現摩爾定律存在兩大特征:
每隔一段時間(從一開始約18個月、到約兩年、再到后來21世紀初期約3年),一是單位芯片面積晶體管數量會翻倍;二是單個晶體管成本和功耗都會下降。
如前文所述,在近半個世紀的時長里,以CPU為主的計算類芯片,算力提升一直遵循著摩爾定律在高速發展。但進入21世紀,這類發展開始減速,算力翻倍所需的時間越來越長、成本也越來越高,即“摩爾定律失效”了。
這種現象可以從物理學和經濟學兩個視角透視其發展瓶頸。
從物理學角度來看,起初技術手段主要發力于不斷縮小柵極長度,但在實現約20nm實際柵極長度節點時,發生了“短溝道效應”,即晶體管無法關閉電流流動,最終通過晶體管從平面結構改為Finfet結構,解決了問題、延續了摩爾定律;當制程工藝發展到約10nm實際柵極長度,又出現了“量子隧穿效應”,即電子出現無規律運動,漏電率急劇上升,表現為功耗過大、溫度過高且性能提高很有限。
從經濟學角度來看,谷歌高級技術開發工程師Mudasir Ahmad在最近一次演講中說,“新工藝的開發成本正在上升”,“現在5nm芯片開發成本與10nm、7nm芯片開發成本加起來差不多”。在很長一段時間里,芯片開發成本不高,作為可變成本平攤到每塊芯片中,相比物料成本要小很多,所以“單位芯片面積晶體管數量翻倍”也帶來了單個晶體管成本顯著下降;但隨著工藝進步,芯片開發成本急速上升,生產的芯片必須出貨量非常大才能真正攤薄開發成本。因此,對于很多芯片設計公司來說,芯片開發風險急劇上升且會出現新工藝單個晶體管成本不降反升的情況(參見表2)。
破局“后摩爾時代”
“摩爾定律失效”的同時,“萬物智能互聯世界”的算力需求卻呈指數級增長。筆者將這對矛盾的產生定義為“后摩爾時代”的開始,而解決該矛盾的成熟技術路徑,就是“異構計算系統”。計算芯片大致分為CPU、GPU、FPGA、ASIC等;眾多處理各類專門問題的加速器,基本都是FPGA或ASIC,尤其以ASIC為主。而“異構計算系統”簡單來說,就是以CPU為主搭配其他計算芯片的計算系統。
“異構計算系統”主要有三個集成方式。一是PCB板系統,個人電腦或服務器的CPU與GPU是獨立插在PCB板插槽上的,服務器的AI加速卡也會以插槽方式集成在PCB板上。二是SOC系統(System on Chip,片上系統),以CPU為主的各類計算模塊,用同樣的制造工藝制作在一塊芯片上。這種集成方式的優點是各類計算模塊之間通信效率高、整體功耗更低,特別節約空間,尤其適合手機等強調低功耗與小空間的終端使用。三是Chiplet系統,也稱為小芯片系統。以CPU為主的多類計算芯片,用不同制造工藝,先獨立制作出芯片,然后再“集成于一塊硅片上”,相互間使用高速接口通信。優點是成本低、功能組合很靈活;相比SOC系統,缺點是功耗大、占用空間大。需要指出的是,集成方式沒有先進或落后之分,只是為了適應不同的應用場景,來獲取性能、功耗、空間、成本等的均衡配置。
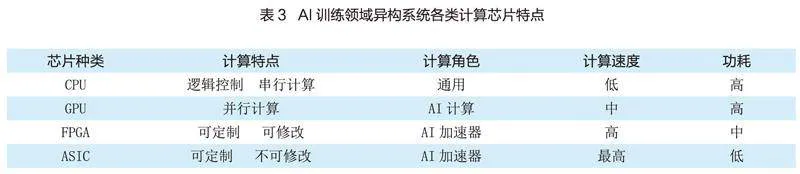
在“異構計算系統”中,各類加速器在各自擅長的計算領域,以更快的速度、更低的功耗和可控的成本,整體上很好填補了“算力不足”。主要計算芯片的比較分析,參見表3。
舉例來說,2023年上市的英特爾旗艦機CPU,Sapphire Rapids,使用異構計算技術,集成了許多加速器,將原本由CPU完成的許多計算,交給加速器處理。比如,DLB模塊能加速不同服務器之間的負載均衡,保證服務器的大規模部署分布式計算;DSA模塊加速CPU和存儲之間的數據交換和數據轉換;IAA模塊加速數據庫相關應用中的數據壓縮和解壓;QAT模塊加速網絡相關應用中的數據壓縮和加密運算;AMX模塊加速人工智能相關的矩陣運算。
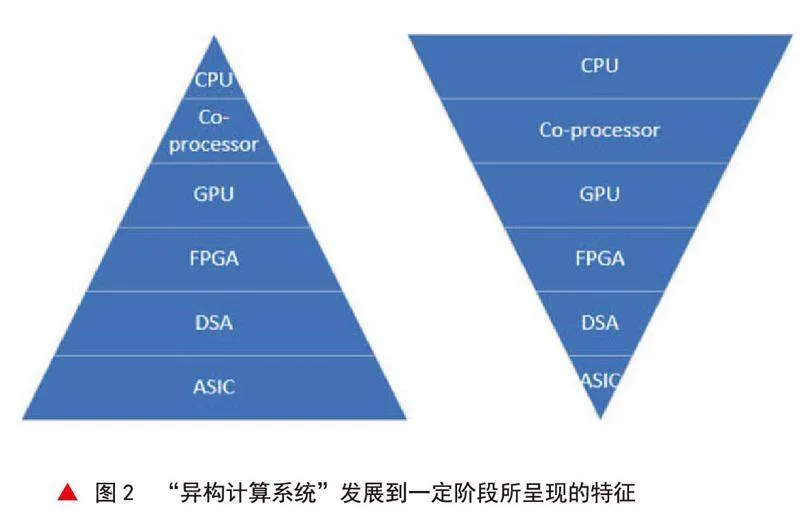
預計在較長時間里,“異構計算系統”將是解決后摩爾時代主要矛盾的最重要成熟技術路徑。這項結論可以從兩個視角去推演。“異構計算系統”發展到一定階段,將呈現出的金字塔和倒金字塔分層特征,如圖2所示。正金字塔圖的畫圖依據是,在一個完整“異構計算系統”中,各類計算芯片(或計算模塊,下文同)的數量;倒金字塔圖的畫圖依據是,在一個完整“異構計算系統”中,各類計算芯片覆蓋的計算領域的數量。
在可以預見的將來,在一個完整的“異構計算系統”中將會出現以下情況:CPU數量最少,但具有最好的靈活可編程性,可以用在任何計算領域,但性能相對最低。Co-Processor(協處理器)依附于CPU存在,可視作CPU的擴展功能模塊。GPU數量不多,具有較好的軟件編程能力,覆蓋計算領域較多,大多性能居中。FPGA數量較多,可編程靈活適用很多計算領域,性能高于CPU、GPU,但不如ASIC。DSA數量很多,具有一定程度上的可編程,覆蓋的計算領域比ASIC大,可視作介于FPGA與ASIC之間的一類計算芯片。ASIC數量眾多,各類ASIC整體覆蓋的計算領域不大,但這些計算領域往往是基礎性算法、很成熟,可將算法硬化在ASIC的電路中,所以計算速度最快、功耗最低、成本也很低(視具體ASIC芯片的出貨量而定)。
綜上所述,在“后摩爾時代”,從晶體管到“異構計算系統”,將突破制造工藝桎梏,用成熟可落地的技術手段,來不斷滿足“萬物智能互聯世界”呈指數級增長的算力需求。
(作者單位:浙江省無線電監測中心)
