生成式AI的“三元競爭”和競爭問題
2024-06-07 07:03:35陳永偉
競爭政策研究 2024年2期
關鍵詞:模型
陳永偉
摘要:作為一種新的技術,生成式AI的興起既帶來了很多全新的機遇,也帶來了很多全新的問題。具體到競爭領域,生成式AI不僅會帶來新的市場力量來源,還會催生出很多新的壟斷行為,為了應對這些問題,就必須對生成式AI市場的競爭規律有充分的了解。本文首先對生成式AI的競爭本質進行了歸納,指出這個市場的競爭其實是圍繞著模型、數據和算力展開的“三元競爭”。在此基礎上,本文進一步分析了這三方面因素究竟如何為企業帶來了市場力量,又可能帶來哪些競爭問題。最后,本文還對如何應對生成式AI造成的問題提出了一些可行的思路。
關鍵詞:生成式AI;模型;數據;算力
2022年11月末,OpenAI發布了大型語言模型ChatGPT。這款AI模型不僅可以十分流暢地回答用戶的各種提問,還可以完成諸如資料整理、文本寫作,甚至程序編寫等工作。因而,ChatGPT發布之后,就廣受用戶好評,上線僅五天用戶量就突破了百萬,上線不到兩個月用戶就實現了破億。在此后的數月中,ChatGPT迅速實現了多次升級和迭代,不僅將其背后的模型從GPT-3.5升級為了GPT-4,還加入了多模態能力和插件功能。憑借著ChatGPT的優越表現,OpenAI的估值一舉突破了千億美元,成為全球估值第三的創業公司。
ChatGPT及其背后的基礎模型GPT僅僅是過去一年中涌現的無數“生成式AI”模型(Generative AI)的代表。不同于更早的“分析型AI”模型,生成式AI模型不僅可以幫助人們分析數據、預測趨勢,還可以生成新的文字、圖片、音頻和視頻信息。得益于這一特點,這類模型被廣泛地應用于各行各業,成為新一代的“通用目的技術”(General Purpose Technology)。
不過,生成式AI在帶給人們諸多便利的同時,也引發了很多新的問題。其中,生成式AI模型對科技巨頭市場力量的強化,以及對市場競爭秩序的破壞,就是受關注程度較高的一類問題。目前,已有不少國家和地區的監管部門對生成式AI領域存在的競爭問題表示了關切。例如,在2023年7月,美國聯邦貿易委員會(Federal Trade Commission,以下簡稱FTC)就對OpenAI損害消費者權益等問題展開了調查;2024年1月,FTC又對谷歌、OpenAI等企業的投資狀況、與合作者的關系,以及它們對市場競爭的影響問題發起了調查;最近,歐盟委員會也對生成式AI可能產生的競爭問題表達了關切。
值得注意的是,盡管生成式AI對于競爭的影響是十分現實的,然而當前關于這些問題的理論探討還非常有限。究竟在現實中,生成式AI的開發企業之間的競爭是怎樣展開的?在競爭過程中又會產生哪些競爭問題?對于這些問題,又該如何應對?關于這些問題,我們依然所知甚少。因而,在制定相關的法律和政策時,也就存在著很多的困難。
在本文中,我們將對生成式AI的競爭特征、競爭模式進行探討,并對競爭過程中可能存在的問題進行揭示。在此基礎上,還將對這些問題的規制提出一些可供參考的思路。
一、生成式AI競爭的三要素
對于生成式AI公司而言,其市場優勢來自三個方面:模型、數據和算力。某種意義上,生成式AI市場上的競爭其實是圍繞著這三方面展開的“三元競爭”(Triple competition)。在本節中,我們將對這三類關鍵要素分別進行介紹。
1.模型
生成式AI依賴基于大數據集訓練的深度學習模型來創建新內容,因而從競爭角度看,模型對生成式AI公司來說是最為重要的。
在現有的技術條件下,模型的性能在很大程度上取決于其參數的數量。一般來說,模型的參數量越大,其學習的能力也會更強,但與此同時,它們對算力和電力投入的需求也會更大,因而開發的成本也會更高。為了克服大模型的上述問題,很多企業試圖通過低秩自適應、知識蒸餾等技術來推進模型的小型化。現在,已經有一些參數量較小的模型實現了不錯的性能。
根據模型的開放程度,生成式AI模型可以分為兩大類——“閉源模型”(closed-source model)和“開源模型”(open-source model)。其中,閉源模型的源代碼和技術細節完全被其提供商控制,不對外進行公開,也不允許用戶對這些模型本身進行更改。例如,OpenAI的GPT、谷歌的Gemini、百度的文心一言等,都屬于閉源模型。開源模型的提供商則會將模型的源代碼和技術細節公開,并允許其用戶根據其自身需要對模型進行任意的使用和修改。例如,Meta的LLaMA、Stability AI的Stable Diffusion等,就屬于開源模型的代表。
需要指出的是,在現實中,閉源模型和開源模型之間也未必涇渭分明,模型的提供商會根據具體情況對模型的開放程度進行調整。一些模型的初期版本曾是開源的,但后續版本則進行了閉源。比如,GPT在3.0版本之前都會通過論文公開其具體的技術細節,但在3.5版本之后,則不再公開這一切。又如,阿里云的通義千問、智譜AI的GLM等,在早期是閉源模型,但隨后則逐漸進行了開源。與之相對的,另一些模型早期則是開源模型,但隨后則逐漸進行了閉源。比如,百川智能的Baichuan-7B、Baichuan-13B等模型在初期就是開源的,但后來提供商則對其采取了閉源。
在模型的性能方面,閉源模型和開源模型各有利弊。閉源模型通常由專業的團隊加以研發,其開發和維護的進度更為穩定,因而模型也會更為穩定和優質。不過,由于閉源模型對其關鍵技術的保密性更強,其包含的新技術的擴散性會較弱。相比之下,開源模型則主要是社區維護,未必可以很好確保對其開發和維護的支持,因而模型的穩定性和質量會略微遜色。但是,開源模型會大幅度降低模型的可得門檻,它們會比閉源模型更容易推廣和擴散。并且,隨著模型使用人數的增加,它會更容易發展出相關的使用生態,也會更容易實現模型的技術迭代。
在盈利模式上,開源模型和閉源模型存在著很大的差別。一般來說,閉源模型主要通過向用戶提供使用許可、訂閱服務,以及云服務等方式來獲取收入。以GPT為例:個人用戶可以按月向OpenAI支付訂閱費以獲得使用權;企業用戶則可以向OpenAI申請API,并按照使用量向其支付費用。除此之外,微軟的Office 365,以及Azure云也都搭載了GPT模型,用戶也可以通過購買云服務來使用該模型。相比之下,開源模型并不直接向用戶售賣或收費,而是通過提供服務或支持、雙授權(即同時授權模型的開源版本和閉源版本)等間接的方式來獲取收入。以Stable Diffusion為例:Stability AI主要通過向用戶提供咨詢,以及為用戶提供定制版的Stable Diffusion來獲取收益。
從競爭的角度看,AI模型的提供商需要考慮的問題將包括如下幾個方面:一是模型的開放性和兼容性,即應該讓模型保持閉源還是將其開源;二是模型的質量,即應該投入多大的資源,將模型的性能改善到怎樣的程度;三是模型的定價方式及價格,即模型應該用怎樣的方式來獲取收入,以及究竟應該將價格定在怎樣的位置。
2.數據
無論是在模型的訓練階段,還是在隨后的微調過程中,都會涉及數據的使用。只有投入的數據量足夠大、質量足夠高,最終得到的模型性質才能夠讓人滿意。在這種情況下,對數據集的占有就成為企業在生成式AI競爭中取得優勢的關鍵因素之一。在對數據的競爭中,企業需要綜合考慮數據的規模、質量,以及及時性等因素。
首先是數據的規模。有研究表明,相比于模型本身的結構,數據規模對模型表現的影響有時可能會更大。因而,要訓練優質的模型,投入的數據規模就必須足夠大。在實踐中,企業用于模型訓練的數據既包括公有數據,也包括私有數據。其中,公有數據包括報刊、書籍上的文字信息,以及網絡上的各種新聞信息、社區對話材料等。例如,在ChatGPT的訓練中,就大量使用了《紐約時報》等媒體的材料,以及維基百科等網站的信息。私有數據則包括企業自行構建的數據集,以及來自其旗下應用軟件的數據等。比如,DeepMind為了訓練數據就專門構建了MassiveText數據集。
其次是數據的質量。對AI模型的訓練而言,數據的質量至少和數據的規模具有同樣的重要性。研究表明,當投入的數據質量更高時,不僅可以減少對訓練數據規模和算力投入的要求,還可以有效改進模型質量。基于以上原因,目前數據競爭的重心已經逐漸從對“量”的爭奪轉移到了對“質”的爭奪上。
再次是數據的及時性。對于很多任務而言,數據的時效性是極為關鍵的。例如,當人們與AI就一些時事話題進行交互時,只有最新的數據才能保證AI回復的準確性。在實踐中,AI公司為了保證數據的時效性,都投入了很大的努力。例如,包括微軟、谷歌、OpenAI在內的很多機構都會通過爬蟲抓取最新的數據,然后讓自己的模型用這些數據進行訓練。
3.算力
無論是訓練還是運行生成式AI模型,都需要大量的算力資源作為支持。因而,在生成式AI的市場競爭中,對算力資源的獲取和掌握起著至關重要的作用。
現實中,不同的AI服務提供商會根據自身的特點來選擇究竟是使用自有的算力資源,或是租用云端的算力資源。一般來說,那些資金和技術實力較為雄厚的企業會更愿意選擇自行配置算力資源。例如,微軟及其商業盟友OpenAI、谷歌及其旗下的DeepMind,以及Meta等企業不僅會購置大量的GPU,甚至還會自行開發TPU、超級計算機等新型的算力技術,用以支持AI模型的訓練和運行。相比之下,一些實力較弱的企業出于節省固定投資的考慮,則會更傾向于租用云端的資源。
二、生成式AI的市場力量來源
在生成式AI的競爭中,企業要獲得市場力量,就必須在模型、數據、算力這三要素中的至少一種上確立其優勢。在本節中,我們將逐一分析每一種要素將會如何為企業貢獻市場力量。
1.模型與市場力量
模型帶給AI公司的市場力量主要是通過其規模經濟和網絡效應實現的。
先看規模經濟。這主要是由生成式AI的成本特征決定的。眾所周知,對生成式AI模型進行開發和訓練是一項成本非常高的工作。它不僅需要大量的人力和設備,更需要投入海量的算力資源作為支持,由此會產生巨大的固定成本。以GPT-4的開發為例:其訓練一次所需要的計算量約為2.1×1025FLOPS,大約需要在25000個A100型GPU上訓練90—100天,所產生的成本約為6300萬美元。當模型開發成功之后,它則可以以相對較低的邊際成本被調用。這樣,隨著用戶量的增長,前期產生的固定成本就可以不斷被攤銷,其平均成本就會越來越低。因而,相比于新開發的模型,那些擁有龐大用戶的在位AI公司將會擁有更低的平均成本,進而在定價方面有更大的空間。
再看網絡效應。和其他的網絡產品一樣,AI模型也具有十分顯著的網絡效應,即隨著模型用戶數量的增加,新用戶對其的評價將會更高。從本質上講,AI模型的網絡效應是由其技術特征決定的。AI模型只有不斷地與用戶交互、接受他們的反饋,才可能及時發現其自身存在的各種不足,從而及時對這些缺陷進行修正。與此同時,模型還需要與用戶持續交互來發現用戶的使用習慣,從而為其提供個性化的服務。在這種情況下,那些面世更早、用戶量更大、迭代時間更久的模型將會比新的模型更容易改進自己的性能,從而讓自己變得更有吸引力。反過來,這又會進一步讓模型獲得更多的用戶,從而讓其獲得更多交互和反饋的機會。
在規模經濟和網絡效應的作用之下,在位的AI公司就可能比新進入市場的競爭者具有更大的優勢。由此,它們就可能確立自己的市場力量。
需要說明的是,技術和行業環境的變化可能會對AI模型的規模經濟和網絡效應產生很大的影響。例如,目前的模型小型化趨勢將會大幅度降低研發和訓練模型的成本,這就可能在相當程度上削弱在位模型的規模經濟。又如,更為活躍的開源社群可以讓更多優秀的人才投入到對開源模型的改進和維護中來,并允許在社群內部更好地分享技術進步的成果,由此讓開源模型的迭代速度更快。這就可以在一定程度上抵消掉網絡效應帶給某些在位AI企業的優勢。
2.數據與市場力量
由于對AI模型而言,優質的數據是重要的投入品,因而對數據的掌握將有助于市場參與者確立其地位。
很多企業會通過購買數據源,或者與數據源簽訂獨家使用協議等方式來確保自己對于數據的獨占。比如,生成式AI要訓練其編程能力,就需要從一些代碼托管平臺大量抓取和學習優質的代碼。然而,在近幾年,一些科技巨頭已經著手對代碼托管平臺進行收購。例如微軟就在2018年收購了全球最大的代碼托管平臺GitHub,并在隨后允許其盟友OpenAI將GitHub上的大量代碼應用于GPT模型的訓練。雖然目前微軟并沒有排斥其他的開發者使用GitHub的代碼,但從理論上講,它確實具有這樣的能力。很顯然,如果這樣的情況發生,那么其競爭對手研發AI模型的效率將會受到很大的損害。
另外,在生成式AI的市場參與者中,有一部分本身就是優質的數據所有者。例如谷歌、Meta等本身就有天然的數據優勢。尤其需要指出的是,在移動互聯時代,有很多的應用都構建了相對封閉的生態,利用外部的爬蟲技術很難對這些封閉的應用進行數據抓取。在這種情況下,這些生態中的數據就事實上成為這些應用開發者的“私有”資源。因而,當這些應用的開發者開發AI模型時,就會先天擁有更多的優質數據,這會讓它們更容易獲取市場力量。
3.算力與市場力量
要實現AI的訓練,海量的算力投入是必不可少的。盡管從理論上講所有的市場參與者都擁有平等地獲取算力的機會,但在現實中,那些實力更為雄厚的參與者顯然會更容易獲取這種稀缺的資源。例如,現在的AI模型訓練非常依賴于高質量的GPU,因而英偉達的H100、A100等型號的GPU存在著嚴重的供不應求。在這種市場格局之下,英偉達出于維護客戶資源的關系,就會優先考慮微軟、谷歌等大客戶,讓自己的GPU優先保證它們的供應。這樣,優先獲取GPU就可以擁有更多的算力資源,從而在市場上獲得更大的優勢。
另外值得一提的是,很多AI市場的參與者本身還運營云平臺,它們本身就是其他一些AI市場參與者的算力提供者。作為平臺運營者,它們具有企業和市場管理者的兩重角色,因而對其用戶具有很強的控制能力。比如,亞馬遜、微軟、谷歌等企業都在云服務市場上擁有顯著的市場力量。因而,它們事實上就在一定程度上掌握了為其潛在的對手分配算力的能力,這無疑會有助于鞏固其在AI市場上的地位。
三、生成式AI的潛在競爭問題
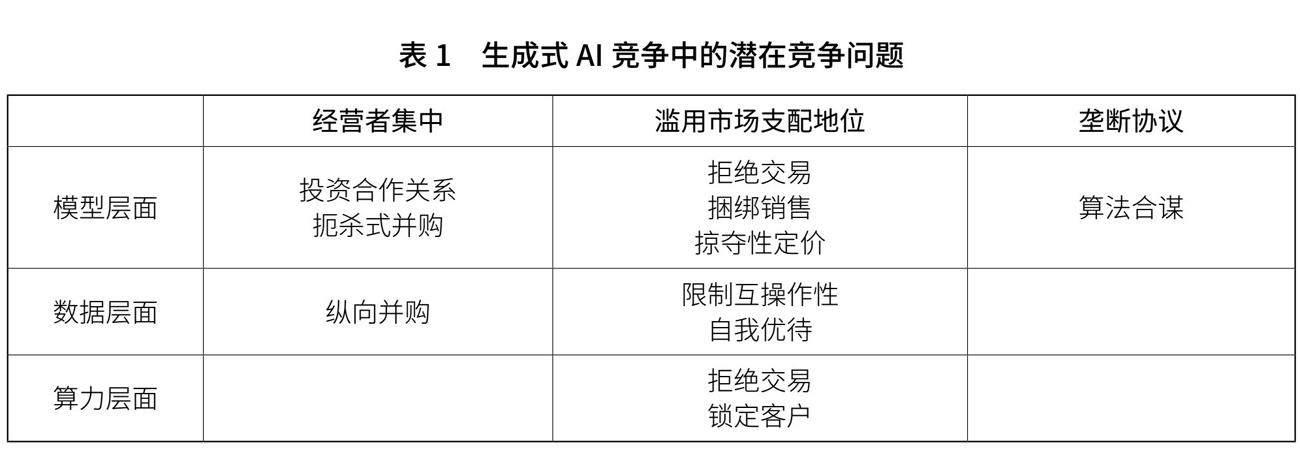
和所有其他的市場一樣,在生成式AI的市場上也存在著很多潛在的競爭問題。表1對其中的一些問題進行了總結。下面,我們將對這些問題分別進行簡單的說明。
1.模型層面的競爭問題
在生成式AI的模型層面,存在著很多值得關注的問題。比如,在經營者集中方面,以財務投資為掩護的新型合作關系以及扼殺式并購是十分值得注意的;在濫用市場支配地位方面,拒絕交易、捆綁銷售、掠奪性定價等問題都可能存在;而在壟斷協議方面,算法合謀將會是一個需要引起重視的問題。
(1)投資合作關系
在生成式AI市場上,有不少科技巨頭與具有強大研發能力的新創企業采取了一種新型的投資合作關系。對于科技巨頭而言,這種類型的合作不僅可以很好地規避企業制度對投資規模的限制,還可以有效地避免研發失敗所帶來的種種負面效應,因而非常具有吸引力。
以微軟和OpenAI為例,這兩家企業在對AI模型的研發過程中采取的合作關系非常新穎:微軟向OpenAI投資130億美元,以獲得其49%的股份和75%的利潤分成權。隨著微軟從OpenAI所獲利潤收入的增加,其在OpenAI的股份占比將逐漸減少。最終,當微軟從OpenAI獲得的利潤超過1500億美元后,OpenAI將回收微軟手中的全部股份。從表面上看,微軟對OpenAI的投資是純粹的財務投資,并沒有對后者的控制權進行圖謀和干預。因此,在名義上微軟和OpenAI依然是兩個獨立決策的個體。基于這樣的原因,所以這次投資很好地躲過了很多國家的經營者集中審查。但事實上,這種財務上的合作顯然是促成兩家共同行動的重要契機。在現實中,兩家企業在研發和產品推廣上都存在著非常緊密的合作。微軟不僅向OpenAI提供了極為寶貴的GPU資源,還在GPT等模型的研發過程中提供了很多的技術支持。作為回報,OpenAI也允許微軟優先使用其產品,甚至在GPT-4模型正式發布之前,微軟的必應搜索和Office 365已經搭載了這款模型。雖然從兩家企業的公開表態看,它們之間的合作關系與微軟的投資和占股并沒有直接的關系,但這似乎很難讓人信服。
客觀地說,上述這樣的投資合作關系可以很好地克服各種制度障礙,從而讓巨頭和新創企業都更好地發揮自己在技術創新過程中的積極作用,但與此同時,其負面的效果也是明顯的。例如,在微軟和OpenAI的合作案例中,微軟就在很多領域(比如SaaS辦公產品)獲得了GPT模型的獨家授權,從而妨礙了其他競爭對手取得該模型的使用。容易看到,這可能會讓微軟在這些領域排除和限制競爭,進一步鞏固其市場地位。
基于以上原因,很多國家和地區的反壟斷執法機關已經對這種新型的投資合作關系給予了重視。比如美國的FTC、歐盟委員會,以及英國的CMA都已經分別對微軟和OpenAI之間的這種關系展開了調查,以明確微軟是否通過財務合作事實上獲取了OpenAI的控制權。不過,到目前為止,上述調查都還在進行中,究竟對于這種合作關系如何進行評價和規制,依然是一個開放性的問題。
(2)扼殺式并購
所謂“扼殺式并購”(Killer Acquisition),狹義上指的是“以停止目標企業的創新項目,以規避未來競爭為目的”的并購;廣義上指的是針對具有潛在競爭威脅的新創企業的并購。
在AI模型的市場競爭中,扼殺式并購十分常見。比如,2014年谷歌對DeepMind的并購就經常被視為扼殺式并購的典型;微軟在發展AI的過程中,曾經并購過Maluuba、Builder.ai等大量的優秀AI初創企業;而據報道,蘋果僅在2023年,就并購了32家AI初創企業。
關于扼殺式并購的總體影響究竟如何,依然存在著很大爭議:一方面,它可以為優秀的AI初創企業提供額外的退出渠道,從而更好地激發人們的創業熱情。但另一方面,它也可能讓在位的壟斷企業排除潛在競爭,鞏固其市場支配地位,從而破壞市場的競爭秩序。從競爭的角度看,這必須得到高度重視。值得指出的是,由于初創企業的估值通常較低,以它們為目標的并購會更容易被經營者集中審查所放行,而很多潛在的競爭風險則可能因此被忽視。從長期看,這對于市場環境造成的負面影響將可能是相當顯著的。
(3)拒絕交易
在實踐當中,一些AI模型企業會拒絕對特定的用戶群體提供服務。比如,OpenAI曾經拒絕一些國家和地區的用戶進行訪問,同時拒絕對這些國家和地區的開發者開放API。最近,它又禁止了字節跳動等與其具有潛在競爭關系的企業訪問GPT。類似這樣的情況,就可能構成拒絕交易行為。
需要指出的是,從反壟斷的角度看,單純的拒絕交易未必會被認定為違法。事實上,在當前的市場上,存在著很多可以相互替代的AI模型,其中的相當一部分模型甚至是開源的。這種情況下,某一家企業拒絕用戶使用其模型暫時難以構成實質上的競爭損害。
不過,從理論上講,這種風險依然是存在的。尤其是當某些企業將AI和其先前的業務相結合后,這種風險還可能越來越大。舉例來說,目前谷歌對于為其Chrome瀏覽器開發AI應用插件的開發者并沒有限制其調用的AI產品,所以開發者完全可以用OpenAI的GPT來進行相關插件的開發。然而,在外來的某個時間,谷歌出于推廣其AI產品Gemini的需要,很可能會要求開發者只能用Gemini來開發插件,或者直接通過技術條件來直接實現這一點。在這種情況下,如果谷歌再拒絕對某些開發者開放Gemini的API,就可能造成非常直接的競爭損害。
(4)捆綁銷售
在當前的生成式AI市場上,不少AI模型的推廣都是通過捆綁銷售來實現的。舉例來說,目前微軟在其辦公產品Office 365、協同辦公產品Teams、云產品Azure,以及搜索產品必應當中都搭載了其合作伙伴OpenAI出品的GPT模型。
捆綁銷售可能造成市場力量的杠桿傳導,從而讓在某個市場上具有支配地位的企業將其市場力量傳導到其他市場。至少在微軟和OpenAI的案例中,這一點似乎是不可忽視的。眾所周知,微軟本來就在辦公軟件、云產品等多個市場上擁有相當的市場力量,因而將GPT模型與這些產品進行捆綁無疑有助于增加GPT模型在市場上的競爭力,讓其可以更容易地占據更大份額的市場。反過來,GPT模型由于其優秀的表現,也在市場上獲得了相當程度的認可,因而將其捆綁到微軟的產品當中也有助于鞏固微軟在這些市場上的地位。
很顯然,從反壟斷的角度看,上述這樣的效應是不可忽視的。可以預見,捆綁銷售問題將成為生成式AI領域最需要重視的反壟斷問題之一。
(5)掠奪性定價
所謂掠奪性定價,指的是企業通過在一定時期內設定低價,以排擠競爭對手,或者阻礙潛在競爭對手進入的行為。這所謂“低價”,是相對于成本而言的。企業之所以采用掠奪性定價策略,是為了用低價先將對手逐出市場,讓自己成為市場上的壟斷者,然后再索取壟斷高價。
在生成式AI領域,掠奪性定價主要表現為企業的“先開源、后閉源”策略。如前所述,在市場上,有部分AI模型的提供商先通過開源策略獲取了很高的市場占有率,并通過大量的用戶反饋,對模型進行了快速的迭代。此后,這些模型就轉向了閉源,按照訂閱或開放API的方式向用戶收費。容易看到,這樣的策略就十分有可能涉嫌掠奪性定價問題。
當然,要確定“先開源、后閉源”策略究竟是否真的構成掠奪性定價,還需要對其定價策略進行進一步地考察。一般認為,掠奪性定價需要經歷兩個階段:第一個階段,企業需要將價格定在其成本之下,從而造成虧損;第二階段,企業需要收取高價,讓其利潤成功補償前期因低價造成的虧損。究竟“先開源、后閉源”的策略是否能和這兩個階段對應,是需要分析的。事實上,即使企業對模型進行了開源,它依然可以通過提供咨詢、定制服務等方式獲取一定的收入,同時開源還分擔了模型的維護成本,因而在開源階段,它們也未必會虧損。如果是這樣,那么掠奪性定價的定性就不能成立。
(6)算法合謀
在AI興起之后,算法合謀就成為反壟斷學界重點關注的一個問題。人工智能不僅可以作為工具,幫助人們更容易達成合謀,還可能因算法設計上的相似性,在處理價格等市場變量時自發達成一致,從而形成事實上的合謀。這一切,都可能對市場的競爭秩序造成負面的影響。
具體到生成式AI,由于大批的用戶都可以調用同一模型進行交互,通過共同使用的模型這個中介,不同的用戶之間將可以在一定程度上實現信息的交換,從而達到合謀的目的。關于通過模型進行信息交換這個機制,現在已經有了一些證據的佐證。比如,三星曾要求其員工停止使用GPT,其理由是GPT可能造成內部敏感信息的外泄。如果三星表述的事實成立,那就說明不同用戶直接通過模型間接交換信息的機制是成立的,因而也就不能排除他們可以通過這種信息交互達成合謀的可能性。除此之外,一些模型本身包含的信息也可能誘發不同用戶之間的協同行為,這在事實上也會造成類似默契合謀的后果。在一些特殊的情況下,AI模型的提供商甚至可以控制模型向用戶們輸出誘導合謀的信息,從而促成合謀的達成。考慮到這些情況,在生成式AI領域,算法合謀問題將依然是一個需要十分重視的話題。
2.數據層面的競爭問題
在生成式AI的數據層面,同樣有很多潛在的競爭問題值得重視。比如,在經營者集中方面,以爭奪數據源為目的的縱向并購將會是一個值得關注的問題;在濫用市場支配地位方面,限制互操作性和自我優待將可能成為突出的問題。
(1)縱向并購
對于科技企業而言,數據是極為關鍵的投入品。為了對這種投入品進行爭奪,企業會把對優質數據源的獲取作為并購的主要目標之一。在過去的幾年中,已經出現了不少相關的案例。比如,在蘋果并購Shazam、臉書并購WhatsApp、臉書并購Instagram、谷歌并購DoubleClick等案件背后,獲取數據都是驅動并購的主要目的之一。
在生成式AI的競爭中,市場上的在位企業對優質數據的渴求變得比過去更為強烈,這就使得它們發動了更多和數據相關的縱向并購,其中著名的案例就包括微軟并購GitHub、谷歌并購Kaggle等。當這些企業實施了并購之后,可能會拒絕將原本開放的數據源提供給與之具有競爭關系的企業使用,由此阻斷對手對關鍵數據的獲取,或至少讓它們獲得數據的成本大幅上升。這樣的封鎖(foreclosure)行為可能會排除潛在的競爭,幫助AI市場上的在位企業進一步鞏固其市場地位。
(2)限制互操作性
在生成式AI市場上,很多企業本身就是重要數據源的控制者。比如,Meta就掌握了臉書、Instagram等多個社交平臺,這些社交平臺每天都會生成大量的數據。很多AI的開發商為了獲取訓練數據來訓練模型,都需要向這些企業申請數據開放。不過,出于排除和限制競爭的考慮,這些掌握了數據源的企業很可能會限制對申請者的互操作性。比如,在2020年的FTC訴臉書案中,臉書就被指控拒絕向那些與其具有競爭關系的開發者們開放API。
如果相關數據是必須而不可替代的,那么上述的限制互操作行為將可能對競爭對手產生顯著的封鎖效應,由此可能會對市場的競爭秩序造成破壞。
(3)自我優待
所謂“自我優待”,指的是同時經營多個市場的企業利用其中一個市場上的資源和優勢來為另一個市場的競爭進行服務。嚴格來說,自我優待并不是一種獨立的壟斷行為,而是多種壟斷行為的合稱。在不同的語境當中,包括搜索操控、顯著展示、預裝,甚至縱向并購、捆綁銷售等行為都曾被納入自我優待的范疇。
具體到生成式AI競爭的數據層面,其涉及的自我優待問題主要集中在“數據抓取”(data scraping)上。具體來說,很多AI模型的提供商本身也是平臺運營商,為第三方商戶或開發者提供著服務。比如,微軟本身也運營Azure云平臺;亞馬遜不僅運營亞馬遜電商平臺,還運營著亞馬遜云平臺;Meta運營的臉書等平臺也允許第三方應用軟件的接入。在現實中,有不少第三方的商戶和開發者也都提供AI服務,因而會和上述這些平臺運營者構成競爭關系。然而,由于它們的開發或運營都需要經過平臺,所以平臺運營者很容易獲取它們的這些數據。在這種情況下,云服務商就會比這些第三方商戶和開發商擁有更多的信息和數據優勢,從而讓自己在競爭中占據更為有利的位置。
3.算力層面的競爭問題
在生成式AI競爭的算力層面,最主要的競爭問題有兩個:一是拒絕交易,二是鎖定客戶。
(1)拒絕交易
在生成式AI市場上,很多中小規模的模型開發商都沒有能力自行購置足夠的算力資源。為了開發和訓練模型,它們通常需要租用云資源。然而,一些云服務的提供商本身也是AI模型的開發者。出于排除潛在競爭對手的需要,它們就可能拒絕為某些模型開發者提供服務。由于云服務市場的結構十分集中,因而如果開發者被幾家主要的服務提供商拒絕交易,它就可能很難以相對低廉的價格獲取所需的算力。
值得注意的是,在AI日益成為國家間競爭焦點的大背景下,拒絕提供算力也正在成為一種新型的貿易封鎖策略。比如,不久之前,美國政府就要求本國的云服務商停止向中國的AI企業提供算力服務。由于美國企業在云服務,尤其是AI算力的供應方面占據非常高的份額,因而這項禁令很可能會對中國中小型AI企業的研發產生顯著的負面影響。
(2)鎖定客戶
實踐中,一些提供AI算力的云服務商為了鎖定自己的客戶,會想方設法為其遷移設置各種障礙。首先,在技術層面,不少云服務商會故意限制與其他云服務商之間的互操作性。這樣,如果有客戶要從一家云服務商遷移到另一家,它們將會需要負擔很大的遷移成本。其次,在規則層面,一些云服務商會在服務合同中設置“退出費”(egress fee)條款。這樣,如果有客戶要求終止服務合同,就可能需要支付一筆不菲的費用。再次,云服務商還會嘗試用生態策略來對客戶進行鎖定。具體來說,很多云服務商在提供算力供應時,還會為客戶提供很多開發工具以及其他互補產品。這樣,如果客戶試圖進行遷移,它就必須同時放棄對這些工具和產品的使用。在一定程度上,這也增加了它們的遷移成本。
四、相關政策探討
雖然生成式AI的發展會帶來很多新的創新機會,從而在相當程度上促進生產力的提升,但與此同時,它也會帶來很多新的競爭問題。那些在生成式AI的研發上取得先機的企業很可能會成為新的壟斷者,或者用它們在AI方面的優勢進一步鞏固其在其他市場上的優勢。面對這樣的情況,為了維護生成式AI市場的持續穩定發展,保證廣大開發者都有公平參與市場競爭、分享市場機遇的權利,就必須未雨綢繆,對這些問題提前做好準備。具體來說,如下幾方面工作是值得重視的:
第一,應加強和生成式AI相關的研究,為制定相關的政策提供理論基礎。
生成式AI是一種全新的技術,在這個市場上,競爭表現出了很多新的方式。究竟這些新的競爭方式會帶來怎樣的后果,又會對市場的競爭秩序和運行效率產生怎樣的影響,目前人們還所知甚少。在這種情況下,如果貿然用過去的監管思路去對這個市場進行管理,可能不僅無益于改善市場秩序,還可能影響該市場的正常運行。因此,為了讓相關政策可以做到有的放矢,就必須先做好調查研究工作,切實摸清楚市場的特點。
鑒于目前歐美等國在生成式AI方面的產業實踐要比我國更為成熟,在規制生成式AI的競爭方面也比我國有更多的實踐,我們應當本著“他山之石,可以攻玉”的態度,對這些國家和地區的經驗和教訓做好學習。尤其是對這些國家和地區的相關立法,以及典型案例,應該切實消化吸收。
第二,應當用好政策手段幫助創造更好的競爭環境,限制生成式AI市場上壟斷格局的形成。
生成式AI公司的市場力量可能來自模型、數據和算力,因此為了限制這些市場上形成壟斷的格局,應從這三個角度出發,營建更好的競爭環境。具體來說:(i)在模型層面,應當加強開源模型的應用。與閉源模型相比,使用開源模型的AI公司通常更難形成市場力量。因而,出于促進市場競爭的考慮,應當對開源模型予以推廣,鼓勵開源生態的建設。(ii)在數據層面,應當保證數據獲取與使用的公平性。在市場上,一些AI公司的市場力量并非來自其模型,而是來自于其對數據源的壟斷。因此,為了促進市場的競爭,就需要打破數據壟斷,推進不同企業之間的互操作和數據可攜帶,讓更多企業可以以相對低的成本共享優質的數據源。(iii)在算力層面,應當加強對云服務商的規范。對于云計算領域存在的違法行為,應當積極予以糾正,以此確保所有的AI開發企業,尤其是中小AI企業可以公平地獲得所需要的算力資源。
第三,應當綜合用好各種規制手段,對生成式AI市場上的競爭問題予以應對。
在應對競爭問題時,我們有很多不同的工具可以選擇。這些工具包括反壟斷、行業管制,以及像市場調查等一些新型的規制工具。對于生成式AI領域遇到的各種不同問題,應當根據其性質的不同,對這些不同的工具選擇性地加以使用。
應當看到,各種規制工具在性質上存在著很大的差異。例如,作為一種事后規制手段,反壟斷更側重于在競爭問題發生之后對其進行糾正。由于在反壟斷介入時,問題已經發生,因而用它來糾正競爭問題可以較好地回避將合法行為誤判為非法的情況。相比之下,行業管制則是事前的規制手段。為了規避某些問題的產生,有關部門會事先制定規則,對可能產生問題的行為予以禁止。這雖然可以在理論上做到防患于未然,但同時也可能對企業的競爭和創新行為產生過多的限制,從而阻礙行業的發展。容易看到,無論是反壟斷還是管制,抑或其他的規制工具,在實踐當中都存在著各自的利弊。因此,對于生成式AI領域的各種競爭問題,究竟應當選擇哪種工具加以應對,還應當實事求是地根據具體問題具體地進行選擇。
第四,應當加強相關企業的自我審查和合規整改,鼓勵社會監督。
限于相關資源和相關知識的不足,監管機構很難對生成式AI領域的所有競爭問題都做到及時發現、及時處理。在這種情況下,呼吁企業自身對其競爭行為進行審查和合規就變得十分重要。應當積極發揮企業以及行業協會的作用,制定生成式AI領域的競爭規范,并號召行業中的所有企業都自覺對其進行遵守。對于競爭中出現的各種問題,企業應積極做好自糾、互糾。除此之外,也應該鼓勵廣大的AI應用者加入到監督的行列當中,充分發揮社會力量對AI公司的監督。
第五,應當建立監管沙盒,鼓勵企業對新商業模式進行創新。
在生成式AI領域,很多競爭問題都是伴隨著創新產生的。這些創新及其所伴生的問題究竟會帶來怎樣的收益和成本,在事先通常很難確知。針對這一情況,應當考慮建立監管沙盒,讓企業在一定范圍、一定規則之下開展創新試驗,并對其后果及時進行評估。在此基礎之上,再確認是否對創新進行認可,以及用怎樣的工具對創新進行規范。
第六,應當積極開展國際合作,與國際同行一起探索對生成式AI的規制思路。
生成式AI技術帶來的革命是世界性的,生成式AI公司之間的競爭也是在全球范圍內展開的,由此產生的問題也是全球性的。在這種情況下,中國應該與世界各國加強合作,交流、溝通這一領域的規制經驗,分享相關的信息。在此基礎上,共同制定國際標準和規范,推動全球范圍內生成式AI的公平競爭。
總而言之,雖然生成式AI會帶來很多新的競爭問題,但只要秉承實事求是的態度,用好政策對其發展做好引導,就一定可以揚長避短,讓我們享受這項技術帶來的各種好處時盡可能減少隨之產生的負面影響。
The "Triple Competition" and Competition Problems of Generative AI
Abstract: As a new technology, the rise of generative AI has brought many new opportunities as well as many new problems. Specifically in the field of competition, generative AI not only brings new sources of market power, but also spawns many new monopolistic behaviors. To address these issues, it is necessary to have a full understanding of the competitive laws of the generative AI market. This article first summarizes the competitive essence of generative AI, pointing out that the competition in this market is actually a "triple competition" around models, data, and computing power. On this basis, this article further analyzes how these three factors have brought market power to enterprises and what competitive problems they may bring. Finally, this article also proposes some feasible ideas on how to deal with the problems caused by generative AI.
Keywords: Generative AI; Model; Data; Computing Power
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
