基于注意力模塊的移動設備多場景持續身份認證
2024-03-03 11:22:00金瑜瑤張曉梅王亞杰
計算機工程與應用 2024年3期
金瑜瑤,張曉梅,王亞杰
上海工程技術大學 電子電氣工程學院,上海 201620
根據Data.ai最新報告表明[1],2021年全球移動設備使用量為3.8 萬億小時,可見,移動設備的需求量上升,也存儲了更多的敏感和隱私數據,這些信息的丟失或者泄露必然會導致一定的安全隱患。為了保護這些私人數據不受未經授權的訪問,移動設備目前都采用傳統的顯式認證方法(密碼、PIN、面部識別[2]、指紋識別[3]),然而,這些方法很容易受到猜測、肩窺和偽造攻擊[4-7],此外,用戶只需在初次使用時進行認證,無法阻止通過初始認證的入侵者非法訪問設備。為了克服這些問題,持續身份認證成為研究者關注的焦點,其通過后臺采集用戶生物行為數據,在用戶初次訪問移動設備后進行持續監控,以達到實時認證的目的,保障了系統的安全性。
目前大多數研究更多地關注單一信息源的交互模式,然而,隨身攜帶移動設備已成為大部分用戶的習慣,當用戶轉換多個場景使用移動設備時,認證系統的持續性就會受到限制,單個設備存儲多個認證模型也會占用極大的資源。因此,本文考慮一種基于用戶與移動設備交互間的移動模式(movement patterns,MP),通過用戶特別的手部姿勢和手部運動的微變化實現。由于個體間的行為特征[8-9]和生理特征均存在顯著差異,用戶的慣用姿勢不同,會使用自己的方式來達到手持設備的穩定性和觸摸屏幕的準確性;同時,手掌大小、手指長度[10]和年齡差異[10-11]也會影響操作時的手指力量、滑動位置和滑動長度;最后,設備的大小和重量不同也會對用戶的操作造成影響。基于上述原因發現,特性的差異會影響用戶的操作行為,從而導致獨特的MP 特征,因此該特征能夠識別合法用戶和非法用戶。此外,該特征不受限于特定操作場景均可提取,包括動態場景,如步行和跑步,也包括靜態場景,如坐和站。
針對不同場景下數據差異大、特征提取繁瑣、用戶體驗度差的問題,本文提出了一種由注意力模塊和卷積神經網絡融合(CNN-SACA)的深度學習模型。目前,卷積神經網絡(convolutional neural network,CNN)憑借出色的特征提取能力被廣泛應用在車輛檢測[12]、情感分析[13]、視頻編碼[14]、醫療保健[15]等領域,既無需人工提取,也使得網絡過擬合危險降低,故本文以CNN 為基礎提取MP 特征進行持續身份認證。但是在多個場景轉換過程中,用戶的行為數據會產生偏移變化,導致簡單的CNN會忽略關鍵特征,將合法用戶在不同場景下的MP特征誤認為非法行為特征。由于多樣的注意力機制在融入不同網絡時會產生較優結果,因此,本文融入了注意力模塊來抑制多場景下有效信息的冗余部分,先按序通過空間和通道注意力子模塊,再在多層卷積后進行反序分配權重,使模型自適應地關注預測中更重要的MP特征,從而加快模型的收斂速度。與僅基于CNN 的工作相比,該融合模型能將認證精度提高1.5 個百分點,并且運算復雜度不高,也適用于硬件資源有限的移動設備。而且目前沒有其他工作將注意力機制應用于持續身份認證的深度學習方法。本文的主要貢獻有三個方面:
(1)提出了一種基于移動模式的多場景持續身份認證方案,旨在集成動態場景和靜態場景(即多場景)下的手部微運動特性,該MP特征通過用戶的手部運動和手部姿勢實現。通過大量實驗評估,本文使用內置傳感器的實時信息對行為特征MP進行建模,在多場景的情況下,能以較低的錯誤率驗證用戶身份。
(2)通過融合卷積神經網絡和注意力機制,提出了一種新的深度學習模型CNN-SACA。該模型以特定的SACA 注意力模塊結構,對預處理后的二維MP 特征進行不同權重分配,能夠提高多場景下的身份認證精度。
(3)本文在公開數據集上實現并評估了該方案的認證性能。實驗結果表明,該算法的準確率為99.6%,等錯誤率僅為1.32%,能有效提高用戶在切換場景使用移動設備時的安全性和體驗感。
1 相關工作
為了保障移動設備的安全性,早期利用機器學習算法[16-17]進行持續身份認證成為研究的熱點,但是傳統的機器學習算法在特征提取階段不僅需要人工參與,還需要充足的操作經驗。由于移動設備在操作過程中會發生位置變化,傳感器自身也會產生噪聲和異常信息,所以人工提取的行為特征在一定程度上會導致辨識度不佳,并且存在過擬合等問題,這都會影響身份認證的準確率。
近年來,深度學習技術特別是基于CNN 的身份認證技術因其強大的學習能力被廣泛應用到持續身份認證領域[18-21]。蘆效峰等人[18]結合卷積神經網絡和循環神經網絡(recurrent neural networks,RNN)對產生的擊鍵數據進行特征提取,訓練后的模型可以很好地體現個人擊鍵模式,擁有較好的準確率,但是只使用了相同鍵盤輸入的數據,并將行為限制在電腦端,無法實現移動設備的身份認證。Shiraga等人[19]提出了一種基于CNN的步態識別方法,引入步態能量圖像(GEI)作為模型的輸入,但是該方法必須擁有用戶的步態輪廓,即需要額外的攝像設備才能實現身份識別。Matteo 等人[20]和Zhao等人[21]以CNN 為特征提取網絡,通過智能手機的加速度和陀螺儀信號來表征用戶獨特的身份信息,但必須將智能手機綁定在用戶褲子前袋或后腰處采集信息。然而,上述研究均未考慮到用戶操作場景的轉變以及與移動設備交互的便捷性,使用淺層的CNN 缺乏識別類間相似特征的能力,只能識別單一場景的特征,例如單獨使用行走時的步態信息認證、使用坐姿狀態下的擊鍵數據認證等。此外,雖然Tang 等人[22]找到了包括走路、上下樓和坐、站、臥以及轉換數據在內的多場景數據集,但該實驗仍然限制傳感器佩戴位置,并且使用繁瑣的人工提取方法,用戶無法真正實現與移動設備交互。
實際應用場景的復雜性對持續身份認證方法的有效性帶來了挑戰。王欣等人[23]在MobileNetv2網絡中嵌入基于通道的注意力機制,王玲敏等人[24]將基于位置信息的通道注意力融入YOLOv5算法,Li等人[25]提出一種包含空間注意力模塊的網絡模型實現高光譜圖像分類。由此可見,通道或是空間注意力模塊融入不同網絡后可以讓模型從全局角度注意到關鍵目標,學習到目標更精細的特征,證明了改進網絡的有效性。此外,杜先君等人[26]和許文鑫等人[27]在模擬電路故障診斷和列車閘片偏磨狀態方面通過融入注意力機制CBAM改善了CNN無法自主分配關鍵特征的問題。該機制包括了通道和空間注意力,可以沿著兩個獨立的維度推斷注意力特征,并且有研究表明CBAM[28]可以無縫集成到任何CNN體系結構中。但是杜先君等人和許文鑫等人也僅將卷積神經網絡和注意力機制進行簡單地串聯組合,無法針對本文多場景特征進行自適應識別。受以上研究啟發,本文提出一種將改進的空間注意力(spatial attention module,SAM)和通道注意力模塊(channel attention module,CAM)融合嵌入到CNN中的多場景身份認證模型CNN-SACA,以克服蘆效峰、Shiraga、Matteo、Zhao、Tang等[18-22]工作的不足。
所提的持續身份認證方案通過捕捉多場景下用戶與移動設備間真正進行交互時產生的MP特征,從而進行持續身份認證。CNN-SACA模型將注意力模塊按不同順序融入到CNN 模型中,能夠對不同場景下的類內特征進行增強,自動獲取高相關性特征,并抑制其他低相關性特征,加強對多場景特征的檢測能力,使用戶與移動設備進行交互時,無需考慮場景變化問題,滿足了安全性的同時又兼顧了用戶體驗度。
2 多場景持續身份認證方案
2.1 持續認證框架
為實現用戶身份認證,本文構建基于深度學習和用戶移動模式的身份認證框架,包括訓練模型、身份認證、模型更新階段,流程如圖1所示。
身份認證的具體流程如下:
(1)訓練模型階段。先通過用戶與移動設備進行交互,在兩類場景(動態和靜態)中收集傳感器數據,本文選擇的三種傳感器是目前移動設備中常見的內置傳感器,無需外部傳感器的支持,并且分別提供不同維度的用戶行為信息。加速度計記錄用戶較大的運動模式,如手臂姿勢、走路姿勢等;陀螺儀記錄用戶細微的運動模式,如握持設備姿勢;磁力計記錄方向信息,如設備旋轉方向和角度。然后經過預處理,即特征轉換,對收集到的所有數據進行數據預處理,通過異常值處理、小波去噪、平均映射得到所需的二維圖像數據,再輸入到網絡中。最后進行模型訓練,在訓練過程中,調整不同的卷積神經網絡(CNN)參數,以達到最優的效果。再在此基礎上融入注意力模塊,最終得到最優參數的CNN-SACA深度學習網絡模型。
(2)身份認證階段。在構建好模型后,當合法用戶首次使用移動設備時,系統將持續不斷地通過后臺傳感器實時采集場景行為數據,這部分數據不曾參加訓練過程,再從原始信號中進行預處理,以生成MP特征向量,并輸入已構造的CNN-SACA 模型進行用戶認證,分析結果是否達到預期。
(3)模型更新階段。考慮到用戶行為會隨著時間、年齡、習慣的變化而改變,那么特征的認證就會產生差異。當合法用戶被錯認為非法用戶時,系統會提醒用戶進行顯示認證,若顯示認證通過,系統則將錯誤拒絕的用戶數據重新收集并訓練新的模型,達到一定的持續更新認證模型的作用。
2.2 注意力模塊
在其他應用中,注意力機制通常作為一個獨立的模塊嵌入到網絡中,通過對頻帶、像素或通道進行不等量加權來細化特征圖。本文受Woo等人[28]啟發,將通道注意力機制模塊(CAM)和改進后的空間注意力機制模塊(SAM)以最佳組合方式應用于CNN的模型中。
通道注意力模塊提取通道注意力的方式基本和SE-Net[29]類似,但增加了并行全局最大池化(global max pooling,GMP)的特征提取方式,可以取得更好的效果。如圖2 所示,輸入特征圖為fn=(f1,f2,…,fn),n為提取到的特征圖數,將特征圖fn通過最大池化層和平均池化層進行并行池化輸入,再分別經過多層感知器(multilayer perception,MLP),將MLP輸出的兩個特征向量進行加和操作并通過Sigmoid 激活函數得到結果向量,將該向量與原先的特征圖fn相乘,得到新的特征圖。CAM的過程可以表示為公式(1):
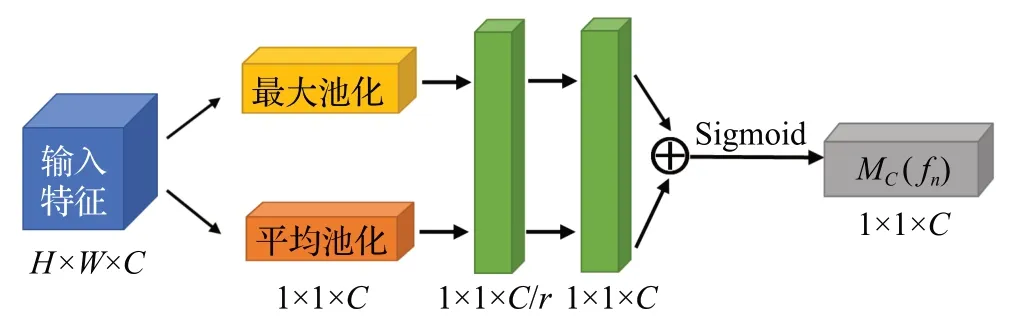
圖2 通道注意力模塊結構Fig.2 Structure of channel attention module
其中,σ表示sigmoid激活函數,Avg和Max表示平均池化和最大池化操作,W1∈RC×C/r和W0∈RC/r×C表示MLP 的共享權重,是經過平均池化和最大池化操作后的特征圖。
空間注意力模塊可以使神經網絡更加關注移動模式特征中對分類起決定作用的像素區域而過濾無關緊要的信息。特征圖輸入到傳統的SAM會進行基于通道維度的最大池化操作和平均池化操作,這種方式讓壓縮空間描述特征不夠充分。為了獲得空間上每個像素點的通道全局描述特征,本文在此基礎上添加了一個大小為1 的卷積操作,對特征序列逐個壓縮,充分表達第一特征圖的關鍵MP信息。如圖3所示,改進后的SAM首先通過最大池化、平均池化和1×1 的卷積操作,將它們拼接成具有三個通道的特征圖,最后由單卷積核卷積降為空間權重為H×W×1 的特征圖,并通過激活操作后與輸入特征圖相乘,從而生成最終的特征圖。改進的空間注意力模塊通過添加卷積操作更清晰地表達了特征圖空間位置的詳細權重,能有效提高對MP特征的辨別能力,其過程可以表示為公式(2):
其中,σ表示sigmoid激活函數,O表示卷積操作,表示經過均值池化、最大池化和卷積操作后的特征圖。
2.3 CNN-SACA深度學習模型設計
由于淺層的CNN 對行為特征提取不充分,認證精度不高,深層的CNN雖然一定程度上提高了認證精度,但是運算復雜度更高、占用資源大,因此本文設計了一個包含五層卷積層的卷積神經網絡,對MP特征生成的RGB 圖進行特征挖掘,以改善模型對多場景轉換下身份認證的準確率和檢測速度。而所提出的CNN-SACA模型是對該CNN的有效改進。由于個體在不同場景下與移動設備交互時具有不同的表現,為了精準提取和訓練MP 特征,進一步提高模型性能,本文設計并開發了CNN-SACA 深度學習網絡模型,并加入線性修正單元和注意力模塊,增加網絡稀疏性,緩和過擬合,使得計算資源分配更加合理化。
Woo 等人[28]提出了CBAM 注意力機制模型,按通道-空間注意力模塊的標準串聯組合可達到模型最優化,而在本文CNN 的結構中卻表現不佳。CNN-Ⅴ模型在通過第一層卷積層后,由于卷積核尺寸和步長較大,卷積過程中對空間信息的描述較多;而在最后一層卷積時,模型已經包含混合的空間及通道信息。因此,本文設計的CNN-SACA深度學習模型結構如圖4所示,Acc是加速度計,Gyro是陀螺儀,Mag是磁力計,本文提取該三個傳感器的數據,將其組合成專屬的MP特征作為模型的輸入。首先在模型的第一層卷積后嵌入SAM 和CAM的串聯組合,先對首次卷積后的MP特征圖分配空間注意力權重,再調整跨通道間的特征像素點;而后將所獲得的特征圖按順序投入到四個卷積層中,并對其進行快速抽象與匯總;最后在第五層卷積后按照標準模式依次嵌入CAM和SAM,對混合后的空間、通道MP特征信息進行調整,再經過Soft-max層完成對MP 特征的分類。實驗表明,以Conv-SACA-Conv-CASA為網絡結構的模型性能優于以標準串聯結構嵌入的模型,能提高整個模型提取MP 特征的效率。本文提出基于卷積神經網絡的注意力模塊算法如算法1所示。

圖4 CNN-SACA模型結構圖Fig.4 Model structure of CNN-SACA
算法1 基于卷積神經網絡的注意力模塊算法
CNN-SACA 模型算法中D表示包含實例E={e1,e2,…,en}的數據集,要規范化數據,第一步是將原數據通過平均映射為D1,下一步是使用NumPy函數將數據轉換為2D 矩陣D2。第三步是將三個傳感器的數據轉換成多重矩陣,使用重塑函數轉換為圖像F以三維的形式作為CNN-SACA 模型的輸入。此外,在第一次池化后進一步轉化為向量組V,作為注意力模塊的輸入,首先反序使用注意力模塊計算特征權重WS1,再通過多層快速卷積調整信息,最后按序通過注意力模塊接收該信息,分析數據序列之間的關聯,這些輸出的向量組與不同的權重分數WS3相乘,以預測目標標簽L。該過程根據數據的特殊性為數據分配分數,改進了學習過程,有助于在持續身份認證過程中實現更高的精度。
3 實驗結果與分析
3.1 數據來源
本文使用HMOG數據集研究本文移動設備持續認證方法。HMOG(hand movement,orientation,and grasp)數據集[30]。由威廉瑪麗學院(The College of William and Mary Hereby)的相關工作人員和學生團隊收集,使用加速計、陀螺儀和磁強計讀數,以不引人注目地捕捉用戶輕觸屏幕時產生的細微手部微動作和方向模式,在本文中,稱其為移動模式(MP)特征。該研究開發了一款數據采集工具,用于記錄用戶與手機交互調用的實時觸摸數據、傳感器數據和按鍵數據,記錄了智能手機上兩種場景數據(坐姿和行走)以及不同行為數據。該實驗招募了100 名志愿者進行大規模數據收集。每位志愿者預計進行24次會話(8次閱讀會話、8次寫作會話和8次地圖導航會話)這個數據集比任何現有的關于智能手機用戶交互的公共數據集具有更多的模式和更大的規模。
3.2 數據預處理
Holger[31]發現HMOG 數據集存在一些問題。本文在使用和分析該數據集的過程中也發現了一些問題:(1)用戶526 319和用戶796 581只有23次會話的數據,而其他用戶均是24次的會話數據;(2)數據文件夾名稱與其包含的數據不一致;(3)每個用戶采集到的數據數量分布以及采集時間不均等,有4人僅貢獻了1.5 h的行為特征。這些問題將導致MP特征缺失,從而使認證結果出現偏差,因此在實驗之前,將有缺失的用戶數據直接刪除,改正有微小錯誤的用戶數據,將剩余有效的用戶樣本構成新的HMOG-N數據集。
本文使用了加速度計、陀螺儀和磁力計三個傳感器的數據。通過對原數據的觀察可知,首先,每個用戶在操作過程中會產生異常噪聲,這種出現在高頻或低頻的運動偽影,如圖5(a)所示,這是用戶在Accelerometer 中x軸的一段數據,可以看到在實線框內的第19 750個數據點左右出現了異常噪聲,對于這部分異常數據段直接剔除,而虛線框內的數據則是正常操作智能手機后產生的數據,如圖5(b)所示。本文利用小波去噪對數據進行濾波處理,保證在消除噪聲的同時,最大可能地保留原始數據信號形狀、寬度等分布特征,如圖5(b)中,濾波前的數據是原始數據,而經過小波去噪后,數據波形就會變得平滑,并且保留了用戶與智能手機進行交互動作時產生的有效數據。可以看到,每200個數據點之間至少有一個交互動作產生。

圖5 某用戶加速度計x 軸的數據Fig.5 Data from x-axis of one user’s accelerometer
現階段大部分的深度學習方法都建立在卷積神經網絡的基礎上,由于其能在一定程度上實現對信息的區域感知和權重分享,因此在圖像識別領域中得到了廣泛運用。然而,HMOG數據集所獲取的數據是一維信號,為了充分發揮CNN的優點和最大限度地發揮注意力模塊的作用,本文將不同場景下的三個傳感器數據轉化為二維RGB 圖像。在輸入到深度學習模型之前,先將處理過后的傳感器數據進行平均映射,使其成為0~255范圍內的像素點,再將其排列組合成數據塊,最后轉成一定量的具有MP特征的RGB圖像,如圖6所示。

圖6 MP特征圖像Fig.6 MP feature image
在訓練時,選取除去合法用戶外的其余用戶的MP特征圖作為反例數據。每個用戶按照8∶1∶1 的比例獲得訓練集、測試集和驗證集,為了保持反例數據的有效性,則從其他所有用戶的數據集中分別等量抽取所需圖像數,加入到該用戶的False數據子集中,形成新的用戶數據集。
3.3 CNN模型參數設計
模型實驗選擇Adam優化器,損失函數為分類交叉熵損失函數,batch_size 為32,學習率為0.000 06。本文選用以下常用評價指標對實驗各個環節進行評估,分別是準確率(Accuracy)、召回率(Recall)、F1 分數(F1-socre)、錯誤拒絕率(FRR)、錯誤接受率(FAR)、等錯誤率(EER)、AUC值。
3.3.1 CNN模型選擇
為了選擇在多場景下表現更好的網絡模型,實驗中設計了多種不同參數的卷積神經網絡分別對用戶多場景下的MP特征進行分類認證,使用新數據集HMOG-N進行測試。表1 顯示了不同參數結構的CNN 模型在對靜態場景和動態場景下訓練后,其所需的訓練時間和驗證集所能達到的準確率。

表1 單場景下不同CNN模型的準確率和訓練時間對比Table 1 Comparison of accuracy and training time of different CNN models in single scenario
由表1可知,本文設計的多種參數結構的CNN模型在準確率方面都取得了不錯的結果,縱向對比,在靜態場景下身份認證的準確率均在96%以上,動態場景下的準確率略低于靜態場景,但也都在93%以上;橫向對比,在單場景下,卷積層為5層的CNN耗費的訓練時間雖然比有些淺層的模型長,但在準確率方面都表現得更好,且不同的卷積核大小和卷積核個數對結果并沒有很大的影響。對于更深層的模型來說,單場景下的準確率有所下降,僅個別動態場景達到了較高準確率,但訓練時間花費太多,效率較差。
此外,本文使用分類交叉熵損失函數來計算算法的損失值,從而評估單場景下不同網絡的性能,圖7 顯示了其收斂情況。圖7(a)是各模型在單場景-坐姿下的損失值,圖7(b)是各模型在單場景-步行下的損失值。由圖7(a)、(b)所示,在相同超參數下,模型Ⅴ、模型Ⅵ在單場景下的損失值明顯低于包含3層、4層以及6層卷積層的模型,并在同層數的模型中收斂更快、更平穩。

圖7 不同CNN模型的損失值Fig.7 Loss values for different CNN models
為了測試所設計模型在多場景下的身份認證性能,將混合后的多場景數據集輸入到網絡中。表2 是在多場景下不同結構的CNN 進行身份認證的準確率、召回率和F1 分數。圖8 是多種模型分別在單場景和多場景下的準確率對比,可以看到,模型Ⅴ、模型Ⅷ和模型Ⅸ在輸入多場景數據后,準確率得到了提升,而其他模型的準確率反而有所下降。由表2可知,較為深層的模型能更好地表達多場景下的MP 特征,相較于模型Ⅷ和模型Ⅸ,模型Ⅴ的召回率和F1-score 最高,達到了98%和0.98,證明模型Ⅴ能更好地識別多場景下的數據類型。綜上所述,本文選擇模型Ⅴ作為本文深度學習模型基礎。
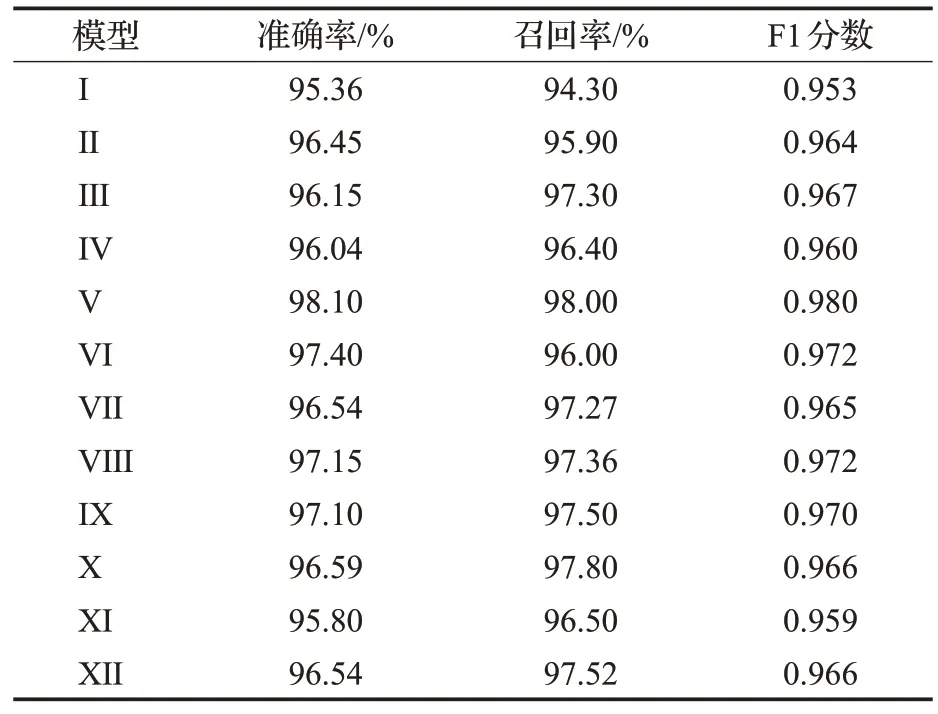
表2 多場景下不同模型的準確率、召回率和F1分數Table 2 Accuracy,Recall and F1 score of different models in multiple scenarios
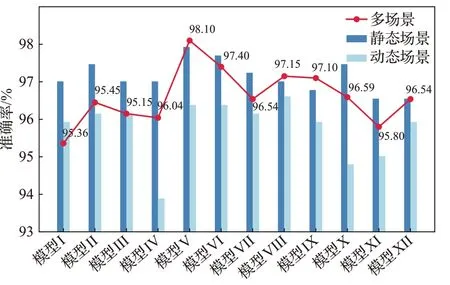
圖8 單場景和多場景下的認證準確率對比Fig.8 Comparison of authentication accuracy in single and multiple scenarios
3.3.2 超參數比較
超參數的設置會對網絡帶來不一樣的影響,本小節將改變參數bs(batch_size)和lr(學習率)驗證其對靜態場景和動態場景性能的影響。保持其他參數不變的同時,將bs從8 以2 的冪次方逐漸調整到256,將lr從0.01調整到0.000 001。結果如圖9所示,虛線代表的是準確率曲線,實線代表訓練時間變化。圖9(a)中,隨著bs的增加,兩種場景的性能也隨之增加,認證準確率在bs=32 達到極值,而后開始降低,模型泛化性下降。動態場景的準確率在bs=256 時得到細微提升,但還是低于bs=32 時的最佳值,且訓練時間顯著增加,這會耗費更多的計算資源。對于參數lr來說,在0.01 時損失值就急劇上升,導致模型無法完成正常訓練,出現準確率極低的現象。隨著lr逐漸減緩,如圖9(b)所示,兩種場景的認證準確率都在lr=0.000 06 時獲得優勢,而后又逐漸降低。另一方面,訓練時間在兩種場景中上下波動較大,但綜合來說,模型性能在lr=0.000 06時能達到最優。
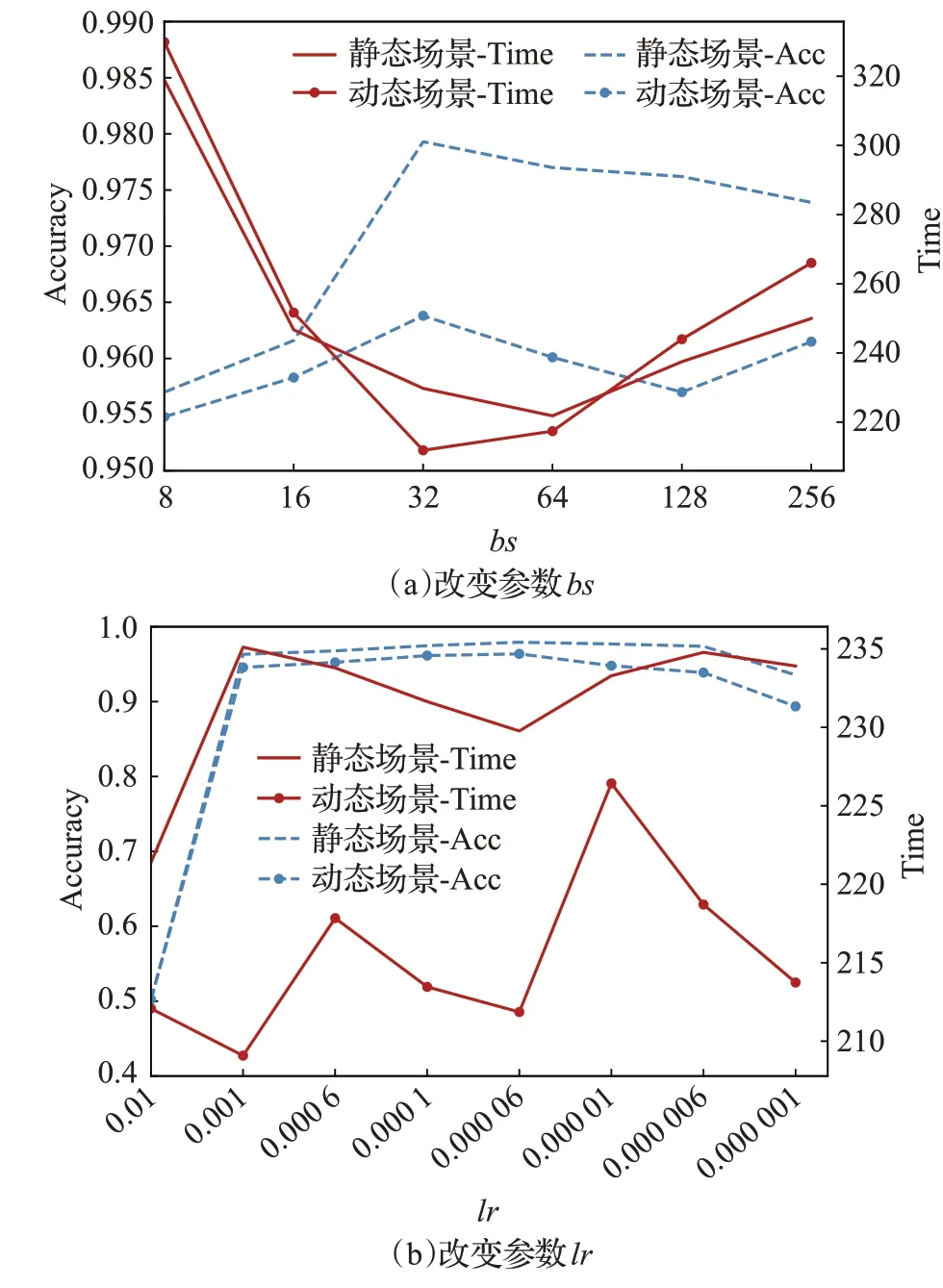
圖9 超參數比較Fig.9 Hyperparameter comparison
3.4 融入注意力模塊的模型對比
注意力機制模擬了人類的視覺,它能夠聚焦某些特定特征而不是整片區域,從而濾除大部分噪聲數據,提取有效信息。考慮到本文設計的CNN模型各方面的性能,選取模型Ⅴ融合注意力模塊進行實驗,以測試模型的認證準確性。由表3可知,在五層CNN模型中融入注意力模塊,并改變其排列方式可以得到不同的準確率。本文所設計的CNN-SACA模型,即在模型Ⅴ第一層卷積層后按序通過改進的空間注意力子模塊和通道注意力子模塊,再在第五層卷積層后按反序輸入注意力模塊時,能達到最高的準確率99.6%。因此,本文模型采用的順序融合方式優于其他模型的組合方式,更能關注到多場景下的MP特征,達到高準確率的身份識別。

表3 注意力模塊不同融合方式的認證準確率Table 3 Authentication accuracy of different fusion methods of attention module
3.5 實驗結果綜合分析
3.5.1 多場景認證性能評估
本小節對CNN-SACA 模型在單場景和多場景下的認證性能以及不同行為下的認證性能進行評估。圖10 給出了CNN-SACA模型分別在靜態場景,動態場景以及多場景下性能評估。可以看到,所提出的CNNSACA 模型在單個場景下的準確率表現不錯,能達到98.1%(靜態場景)和97.7%(動態場景)的準確率,但是多場景下的認證準確率更高,能達到99.6%的準確率,由圖10(b)可知,ROC 曲線表現也更好,多場景下的AUC值為0.997。結果表明,CNN-SACA模型具有強大的特征提取能力,能夠對不同用戶的MP特征進行準確地識別,驗證了本模型在多場景下進行身份認證的可行性。

圖10 CNN-SACA模型在不同場景下的性能Fig.10 Performance of CNN-SACA model in different scenarios
此外,針對多場景下不同行為特征的差異對CNNSACA 模型性能的影響,本文對數據集中的三種行為(reading、writing、map)進行分類。如圖11所示,不限場景的情況下,三種行為的身份認證準確率可以達到97.5%以上,特別地在writing 行為下,準確率能達到99%以上,說明用戶在輸入文本時產生的MP 特征具有更強地辨識性,也證明了本文所設計的模型在不同行為下仍具有較高的認證準確率。

圖11 CNN-SACA模型在不同行為下的準確率曲線Fig.11 Accuracy curves of CNN-SACA model under different behaviours
3.5.2 CNN-Ⅴ與CNN-SACA對比分析
本小節將進一步對所提出的兩種深度學習網絡模型進行實驗分析。單獨的CNN 和CNN-SACA 在單場景和多場景下各自的ROC曲線如圖12、圖13所示。由圖可知,六種情況下的AUC值均在0.97以上,說明提出的MP特征具有很強的辨識性,可以有效地鑒別出合法用戶或非法用戶。而當單場景的真正率未達到0.6、多場景的真正率未達到0.8時,真正率都快速提升,變化較為一致,說明兩種模型響應迅速,但在達到0.6 和0.8 以上時,CNN模型的真正率開始變化緩慢,表明其誤差分類逐漸增加,模型性能開始變差,不如融合了注意力模塊的CNN-SACA 模型。由此證明,無論是單場景還是多場景條件,CNN-SACA 模型的性能均比CNN 模型好,此外,CNN-SACA 的AUC 值也都高于單獨的CNN模型,多場景下幾乎達到1,證明了該模型的有效性和優越性。

圖12 CNN-Ⅴ與CNN-SACA模型在單場景下的ROC曲線Fig.12 ROC curves of CNN-Ⅴand CNN-SACA models in single scenario

圖13 CNN-Ⅴ與CNN-SACA模型在多場景下的ROC曲線Fig.13 ROC curves of CNN-Ⅴand CNN-SACA models in multiple scenarios
同時,如圖14所示,本文通過計算認證結果的錯誤接受率FAR、錯誤拒絕率FRR、等錯誤率EER證明,在多場景的驗證下,本文設計的單獨的CNN 模型可以達到不錯的認證結果,FAR 為3.54%,FRR 為1.76%,EER 為2.65%,而融合了注意力模塊的CNN-SACA 模型三項指標均低于單獨的CNN,且EER 降至1.32%。綜上所述,相比于單獨的CNN,所提CNN-SACA模型能更好地識別多場景下的MP特征,達到更好的認證效率。

圖14 CNN-Ⅴ與CNN-SACA模型的FAR、FRR、EER對比Fig.14 Comparison of FAR,FRR and EER for CNN-Ⅴand CNN-SACA models
3.5.3 與其他算法的對比分析
本小節將證明所提出的CNN-SACA模型的有效性和合理性,表4 將本文算法與SVM、RF、CNN-Ⅴ、CNNLSTM、VGGNet、ResNet 和CNN-SE 進行了性能比較。實驗結果表明,SVM與RF在驗證集上的認證準確率明顯比其他深度學習算法低,可見未通過手動選擇特征的機器學習方法在認證準確率方面效果不佳。而在不同的深度學習算法中,本文所使用的MP特征基本能在多場景下達到準確認證的結果,準確率可達到97%以上,并且認證時間只需在2 s以內。而本文模型在驗證集上的準確率可達99.6%,比CNN-V 模型提高了1.5 個百分點,證明模型泛化能力強,能較好地識別多場景下的MP特征。

表4 不同算法的準確率和單次訓練時間Table 4 Accuracy and single training time of different algorithms
為了進一步研究融入注意力模塊對網絡復雜度的影響,表5分別從模型的參數量、浮點運算數GFLOPs等三個方面來評估該四種深度學習模型的復雜度。本文方法融入兩層注意力模塊后,使模型參數量比原設計的CNN 模型降低了4×106,加快了模型收斂;而在運算復雜度方面也僅升高了0.3,但是相較于加了長短時記憶網絡的卷積神經網絡、深層的VGG 和ResNet 來說分別縮小了0.4、12.6 和1.3,說明在硬件資源有限的情況下,本文方法也能滿足部署模型的要求;此外,VGG和ResNet網絡在MemR+W 方面比本文模型分別增加了近12 倍和4 倍。而融合了SE 注意力機制的CNN-SE 模型與本文模型在復雜度方面基本相當,但是在公開數據集上的準確率卻遠不及本文模型。綜上所述,更深層的網絡以及單通道的注意力模型并不適用于MP特征的提取,而本文方法兼顧了模型運算復雜度與認證準確率。
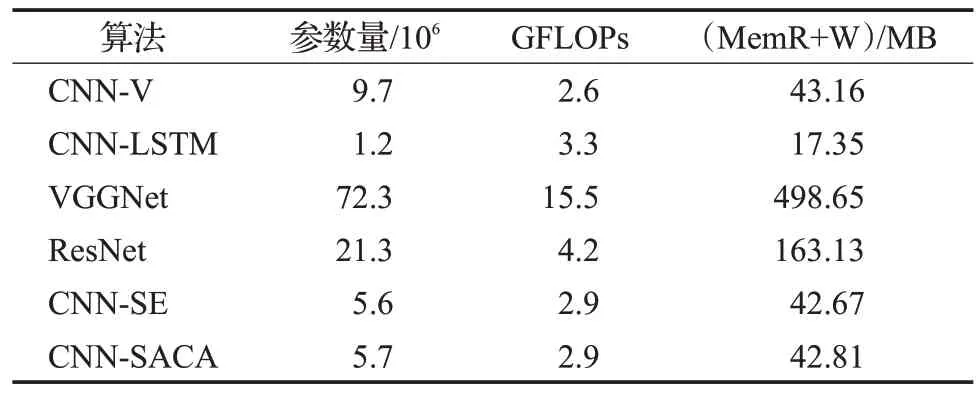
表5 不同算法的復雜度比較Table 5 Comparison of complexity of different algorithms
3.5.4 與其他相關研究對比
本節通過與其他采用同一數據集的不同類型的模型進行比較,以檢驗本文研究模型的優越性和有效性。表6 為各個網絡模型的性能評價結果。在文獻[32]中,作者利用Scaled Manhattan 分類器,使EER 達到7.16%(步行)和10.05%(坐著),而本文在多場景下的EER 僅為1.32%。文獻[33]使用Siamese CNN 提取特征,再通過支持向量機進行分類,其實驗準確率達到了97.8%。將本文所設計的CNN 模型與Siamese CNN+SVM 相比,準確率會有0.3 個百分點的提升,而在融合了CNN和注意力模塊的情況下,認證準確率會再次提高1.5 個百分點。文獻[34]利用HMM(隱馬爾可夫模型)使FAR達到5.13%,FRR達到6.74%,而本文的FAR僅為1.99%,FRR 僅為1.32%。文獻[35]在KRR-TRBF6 分類器下,Sensor CA 系統的中位等錯誤率最低為3.0%;文獻[36]使用OCSVM,使EER 達到4.66%,而在本文中,CNNSACA 模型的EER 僅為1.32%。以上分析表明,基于CNN-SACA和移動模式特征的持續身份認證方法能達到更高的認證準確率,EER也達到了最優。

表6 相關工作對比Table 6 Comparison of related work
4 結束語
本文提出基于移動模式特征和深度學習的持續身份認證方法,采集移動設備多場景下的加速度傳感器、陀螺儀傳感器、磁場傳感器數據,利用這些數據生成獨特的MP 特征,并通過CNN-SACA 模型進行訓練,實現在多場景下對用戶身份的持續認證。實驗結果表明,無論與單場景特征身份認證,還是單獨的CNN模型相比,該方法可有效阻止非法訪問者入侵移動設備,認證準確率更高。但是目前工作仍有部分情況未考慮到,例如同一用戶可能持有多個移動設備,在切換設備使用時會產生誤差。在今后的工作中,將優化本文多場景模型并應用在跨設備上。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
