中文糾錯任務為例的數據集增強質量評價方法
2024-03-03 11:22:08謝振平
計算機工程與應用 2024年3期
宋 程,謝振平,2
1.江南大學 人工智能與計算機學院,江蘇 無錫 214000
2.江南大學 江蘇省媒體設計與軟件技術重點實驗室,江蘇 無錫 214000
近年來,隨著互聯網相關技術的快速發展,多種多樣的數據正在大量的產生。與此同時,大量先進的機器學習相關研究對數據的要求也越發增大,并且數據質量對訓練模型的準確性和泛化能力有著重要影響,因此獲取高標準的數據質量的重要性已得到從業者和研究人員的廣泛認可。其次,要獲取與任務相關并且可靠的訓練數據主要依靠專家或雇傭工人。但是使用這種方法存在一些問題,因為越先進的系統對訓練數據規模的要求也越大,而大規模的數據往往伴隨著高昂的人工成本。所以對于如何生成與任務相關并能夠有效提升模型效果的數據集,數據增強被認為是一種有效的方法[1]。但是通過數據增強方法構建有效提升模型性能的增強數據集,現有的方法主要還是通過模型訓練進行篩選,使用這種方法存在一定的局限性,比如多次訓練模型的時間成本過大、模型性能對測試集數據分布的偏向性等問題。因此,評估增強數據集質量對于訓練出高質量的機器學習模型有著重要研究意義。
早期數據質量的評估主要通過領域專家以定性的方式為不同場景下的數據定義多維度的指標。Alizamini等人[2]將數據質量評估結果和使用者的需求相關聯起來,在滿足所提出的指標的情況下的高質量數據能夠在使用時發揮更高的價值。Wang 等人[3]將信息在系統設計中預期用途作為分析數據質量的方法,由于系統的設計服務于用戶,因此將用戶的觀點定義為數據質量的標準,進而總結出了最常引用的26個質量維度,而對于這些指標并沒有進一步提供具體量化的方法。
隨著人工智能的快速發展,通過深度學習模型提取數據的特征來進行質量評估逐漸變成一種主流的方式。Wu等人[4]提出了兩種多樣性的優化算法用于眾包場景下的數據收集,分別是相似度和任務驅動模型,但這兩種模型并未考慮內在質量對數據集的影響。李安然等人[5]提出了一個面向特定任務的針對大規模數據集的具有高效可解釋性的質量評估系統,該系統可以通過對數據集內在質量和上下文質量評估來為特定的機器學習任務挑選多個高質量數據集,但這種方法卻沒有考慮數據集對整個高維空間的覆蓋程度。Kang 等人[6]針對對話系統中眾包數據收集過程中無法確定數據內在質量提供了明確的建議,提出了多樣性和覆蓋度兩種指標用于評估數據的質量,但對于評價指標沒有給出一個合適的計算方法。Chen 等人[7]提出了一個包含質量標準及其相應的評價方法的數據質量評估框架,通過所提出的三個指標全面性、正確性和多樣性來量化分析醫學概念規范化的數據集,但是并未考慮結合不同維度的結果進行解釋分析。Taleb 等人[8]提出一種處理非結構化大數據質量評價的模型,該模型主要是使用文本挖掘技術來獲取有用的信息進行評估其質量,最后對樣本數據運行評估算法,構建質量報告,但該模型并沒有給出具體的案例分析。Xiao等人[9]提出一種以多樣性為驅動的不確定數據收集框架,通過數據空間中數據噪聲的分布來構建出一個綜合模型用于完成數據的收集,但考慮的因素單一,并不能獲取有效的高質量數據集。
綜上所述,目前的工作對于數據集質量評估還存在所設計的評價指標考慮的因素不完善、不能綜合多個維度結果進行解釋分析。因此,本文提出了一種以中文糾錯任務為例的數據集增強質量評價方法來更加全面地量化增強數據集的質量。首先通過將原始語句轉換到高維空間,其次結合文獻[10]中所給出的內在質量和上下文質量來考慮增強數據集與特定任務的關聯性、數據點之間的關系和對整體高維空間的覆蓋程度等三個方面來進行評價,最后對多個維度指標進行融合來完成增強數據集的評價結果排序,進而篩選出最適合當前任務的增強數據集。總而言之,本文的主要貢獻如下:
(1)設計并實現了一種以中文糾錯任務為例的數據集增強質量評價方法,可以獨立于測試集性能檢驗方法來為不同數據增強方法生成的訓練集選用提供依據。
(2)本文在四種數據增強方法、兩個中文糾錯數據集和三個中文糾錯模型進行了廣泛的評估,通過聯系模型精度和評價結果排名的方式來驗證該設計的合理性。實驗結果表明,在面向中文糾錯任務上質量越高的增強數據集在模型性能的提升上會有更好的表現。
1 數據集增強質量評價方法
數據集增強質量評價方法通過給定一組增強數據集D、面向中文糾錯任務的測試集T和由標準正態分布生成的模擬數據集S來進行評估,其衡量過程首先對增強數據集進行特征提取,再把增強數據集多個維度的指標進行量化,最后通過融合不同維度的評價結果來對增強數據集進行質量排序,具體過程如圖1所示。

圖1 質量評價方法Fig.1 Quality evaluation method
1.1 特征提取
對于數據集增強質量的評價方法,一種有效的特征提取方式是非常重要的環節之一。因此為了獲得更加有效的句子表征,本文使用自變壓器雙向編碼器(bidirectional encoder representations from transformers,BERT)來生成句向量。同時為了能夠獲取更加準確的向量表示,收集了常用的與中文糾錯相關的數據集,然后將整理后的數據集用于無監督語義相似度任務,但是直接用BERT 輸出的句向量做無監督語義相似度計算效果會很差,文獻[11]驗證了原因在于BERT 輸出向量分布的非線性和奇異性,任意兩個句子的句向量的余弦相似度都非常高。為了解決這一問題,使用文獻[12]中提出的方法,在計算句向量的過程中引入對比學習的方法來提升表示空間的質量,使用對比學習可以讓空間中的向量分布更加均勻,進而達到優化句向量的效果。
1.2 互覆蓋度
互覆蓋度旨在模擬增強數據集覆蓋相應任務表達式空間的程度。考慮到不同任務都有常用的測試數據集來驗證模型在該任務上的表現,因此,本文使用測試集作為中文糾錯任務的表達式空間的近似表示。而對于中文語法和拼寫糾錯這兩類任務,分別使用了NLPCC2018和SIGHAN Bake-off 2015中的測試集。
為了測量給定測試集的訓練集的覆蓋程度,首先將預訓練模型輸出的錯誤和正確句子的向量進行拼接,其次通過余弦相似度來為每一個測試集中的句子對在訓練集中識別出最相似的句子對。然后,通過對測試集中所有句子對的最大相似度求平均來導出互覆蓋度。對于給定的測試集,希望訓練集具有盡可能高的覆蓋率。具體地,對于測試集T和訓練集D,其計算公式如式(1)所示:
其中,Ti和Di分別表示測試集T和訓練集D中的句子對,cos(a,b)表示測試集和訓練集中句子對的余弦相似度。
1.3 總分散度
總分散度旨在評估增強數據集本身在空間中的分散程度。其背后的思想是,訓練數據集越分散,下游模型越不可能過擬合,因此它將更好地推廣到測試集中。
為了測量給定訓練集的分散程度,首先對每一個訓練集中的句子去識別出另一個相似度最低的句子。然后,通過對訓練集中所有句子的最不相似度求平均來導出總分散度。最后為了讓不同維度指標趨勢一致,增加了一個負號來保證該值越接近1,訓練集的分散程度也越好。具體地,對于訓練集D,其計算公式如式(2)所示:
1.4 自支撐度
自支撐度旨在模擬增強數據集對完整向量空間的覆蓋程度。其基本思路是句子的向量表示可以代表其周邊的小范圍的空間,那么當這些小范圍空間覆蓋到完整空間的時候,這些組成小范圍空間的句子向量表示的數量被認為是對完整空間的近似表示。
那么為了實現上述思路,需要解決兩個問題,第一個是如何確定一個句子向量表示可以覆蓋到的范圍,第二個是如何計算出組成完整空間的句子向量表示的數量。
為了解決第一個問題,本文將相似句子之間的距離作為句子向量表示能夠覆蓋到的范圍,對于每一對相似句子可以看成是對原始句子進行的編輯操作,那么將相似句子之間的編輯距離和句向量之間的余弦距離聯系在一起,就可以將真實世界和高維空間中相似的句子關聯起來,進而推測出相似句子所能覆蓋到的范圍。因此,首先將隨機插入、刪除、替換和交換作為基本編輯操作,然后在不同大小的編輯距離中隨機挑選句子對計算余弦距離,進而得到余弦距離分布密度圖,最后觀察在不同編輯距離的情況下余弦距離的變化趨勢。如圖2所示,可以發現隨著編輯距離的增加余弦距離的大小會以更高的概率變大,因此選擇余弦距離等于0.1 作為單個句子向量表示的最大覆蓋范圍。
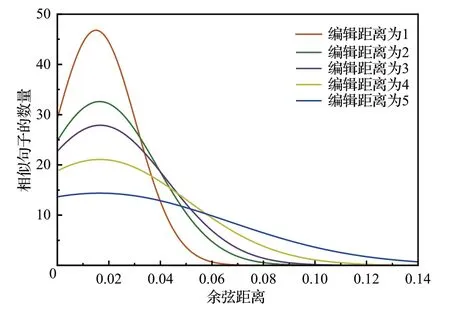
圖2 余弦距離在不同編輯距離下的變化曲線Fig.2 Change curve of cosine distance at different edit distances
針對第二個問題,為了能夠使用有限的數據來覆蓋到完整向量空間,本文首先使用標準正態分布生成5維向量的數據,其次對于如何計算出組成完整空間的向量表示的數量,可以把它看成一個集合覆蓋問題,由所有句向量組成全集,而每一個向量都對應一個集合,該集合中包含的向量與當前向量的余弦距離都小于所設定的覆蓋范圍。然后用最少的集合來覆蓋全集,這些最少集合的數量可以作為組成完整空間的最少覆蓋數量。最后為了減少誤差,本文模擬了100 萬到500 萬的5 維向量,并且讓余弦距離從0到0.11以0.004作為間隔,分別計算在不同覆蓋范圍下完整空間的最少覆蓋數量。如圖3 所示,隨著覆蓋范圍的不斷增大,完整空間的最少覆蓋數量也隨之減少,并且隨著數據量規模的增大,曲線變化也越接近,因此當數據量規模為500 萬的時候,余弦距離從0.004到0.1之間的曲線下方面積可以被認為是完整空間的近似表示。

圖3 不同數量下的最少覆蓋數量變化曲線Fig.3 Change curves of minimum coverage quantity under different quantities
為了測量給定訓練集的自支撐度,首先需要將預訓練模型輸出的向量進行降維和聚類來減小數據規模,之后通過貪心算法對每一類計算出最少覆蓋數量,最后整合所有類別結果畫出完整空間最少覆蓋數量變化曲線。對于給定的訓練集,通過訓練集所構造的曲線越接近模擬曲線越好。具體地,對于訓練集D和模擬數據集S,其計算公式如式(3)所示:
其中,area(D)和area(S)分別表示真實曲線和模擬曲線面積。
1.5 質量融合
給定任意數量的通過數據增強方法構造的數據集,可以通過之前介紹的方法來完成各維度的質量評價。但是對于不同維度的質量評價結果并沒有一種可以比較的方式,因此將三種維度的質量值進行融合。
考慮到三個維度的評價結果的取值范圍都在0 到1,并且不同維度的理想趨勢是一致的,都是越接近于1越好,那么如果存在一個增強數據集其各質量維度都能夠達到最優值,那么這個增強數據集就可以被認為是理想上最好的。因此,采用了文獻[13]中給出的乘法合成法來作為不同維度指標綜合的方法,可以對增強數據集給出一個整體評價的結果。因此,對于任意一個增強數據集D、測試數據集T和模擬數據集S,其質量融合的計算公式如式(4)所示:
其中,coverage(T,D)代表互覆蓋度,dispersity(D)表示總分散度,support(D,S)表示自支撐度。其中,對于互覆蓋度的結果,本文設置了一個因子γ,因為在數據規模上升的情況下,總分散度和自支撐度可以進行穩定的提升,而互覆蓋度由于測試集的局限性,其增長速率會隨著數據量的上升而逐漸減緩,所以在數據量較小的時候因子γ應該設置的較大來增大互覆蓋度對整體評價的影響,而在數據量足夠大的時候可以將因子γ設置為1來保證三個維度對整體評價有相同的影響。因此,在不到1萬條SIGHAN Bake-off 2015訓練集的拼寫糾錯任務上本文將因子γ設置為5,而在10 萬條NLPCC2018訓練集的語法糾錯任務上將因子γ設置為2。
2 實驗設計
本文提出了一種以中文糾錯任務為例的數據集增強質量評價方法,可用于篩選出高質量的增強數據集。為了驗證不同方法生成的數據集對模型性能的影響,采用文獻[14]中使用的方法,首先使用增強數據集對模型進行預訓練,然后用人工生成的訓練集來對模型進行微調。其次,將不同數據增強方法生成的數據集進行質量評估并與糾錯模型訓練結果進行關聯起來,嘗試使用不同數據增強策略、同一種數據增強策略下設置不同參數和數據量規模增大的情況下來驗證質量評價的合理性。
2.1 數據集增強質量評價實驗方法
為了衡量增強數據集的質量,首先需要通過預訓練模型來提取文本的數據特征,因此將NLPCC2018 數據集一共120 萬和SIGHAN Bake-off 2013—2015 年比賽提供的訓練數據集6 476條數據通過對比學習的方式來優化預訓練模型輸出的句向量。
對于互覆蓋度的計算,為測試集中每一個句子對在增強數據集中找到相似度最高的句子對,但是通過BERT 輸出的句向量是768 維,將正確句子和錯誤句子拼接后達到1 536 維,如果采用傳統的方法兩兩計算余弦相似度值,再獲取最小值,由公式(1)可知時間復雜度為O(n×m),n為增強數據集的大小,m為測試集的大小。因此,為了能夠減少在高維向量之間的余弦相似度計算時間,本文使用文獻[15]中的方法,使用分層的可導航小世界(hierarchical navigable small world,HNSW)進行高維向量檢索,通過HNSW 對由增強數據集生成的句向量進行分層構圖,然后對測試集中的所有句子對生成的向量,都可以快速在分層圖中查找到最相似的增強數據集中的句子對,其時間復雜度為O(m)。
針對總分散度的計算,對增強數據集中每一個句向量都需要進行計算再求平均,那么當數據規模和維度都很大的時候,其計算開銷和時間成本都會很大,由公式(2)可知時間復雜度為O(n2),n為增強數據集的大小。因此,為了減少運行時間,在計算過程中首先將數據集劃分成k個部分,每一部分包含1 萬條向量,然后將每兩個部分構建成的向量矩陣計算出余弦相似度矩陣,最后比較所有相似度矩陣得出總分散度結果,其時間復雜度為O(k2)。
為了計算自支撐度,由于增強數據集通過基于BERT 的預訓練模型輸出的句向量為768 維,而通過標準正態分布模擬的數據只有5維,所以本文首先使用等距離映射(isometric feature mapping,Isomap)來對高維向量進行降維。然后使用基于層次結構的平衡迭代聚類方法(balanced iterative reducing and clustering using hierarchies,BIRCH)來對高維向量進行聚類。最后,通過貪心算法對每一個類別計算自支撐度,再綜合所有類別結果就可以畫出增強數據集對完整空間的最少覆蓋數量變化曲線,其時間復雜度為O(l×d×m),l為聚類的簇數,d為類別中向量的平均個數,m為每一個向量對應的子集。
對于上述實驗,本文將原始方法與所提出的優化算法的運行時間在NLPCC2018數據集上進行了對比。其中,原始方法指直接計算數據集中向量之間的余弦距離,不考慮使用HNSW 和數據集劃分的方法來減少計算開銷。而對于自支撐度只給出了優化方法的運行時間,原因在于不通過聚類方法來減小數據規模的情況下直接用貪心算法來計算最少覆蓋數量會花費較大的時間成本,其時間復雜度為O(n×m),n為增強數據集中向量個數,m為每一個向量對應的子集。如圖4(a)和圖4(b)所示,隨著數據量的不斷上升,本文的優化方法與原始方法相比大大減少了運行時間。在同等數據規模下,自支撐度的運行時間結果如圖4(c)所示。

圖4 數據集增強質量評價結果及運行時間Fig.4 Dataset enhancement quality evaluation results and running time
2.2 數據集及數據增強方法
為了驗證本文方法的有效性,本文分別在用于語法糾錯上的NLPCC2018 數據集上隨機抽取10 萬條數據和拼寫糾錯上的SIGHAN Bake-off 2013—2015年比賽CSC 任務中提供的訓練數據集6 476 條數據進行微調模型,然后使用四種數據增強方案來生成同等規模下的訓練數據用于對模型的預訓練。測試集分別使用NLPCC2018 公開評測比賽的測試集一共2 000 條句子對和SIGHAN Bake-off 2015年比賽提供的測試集一共1 100條句子對。
針對中文糾錯任務的應用場景,需要使用數據增強方法對原始數據增加噪聲來模擬中文錯誤,從而構建出句子對用于模型的訓練。為了能夠更好地衡量不同方法對模型性能的提升,本文主要通過兩類方法,分別是無監督和有監督的方法,無監督方法主要是通過對原始句子修改的方式來構造樣本,有監督方法是通過生成模型來實現由正確文本生成錯誤樣本。具體的數據增強方法如下所示:
(1)基于腐化語料的單語數據增強[16]。首先通過jieba分詞工具對原始語句進行分詞,然后通過腐化算法按30%的概率對每個詞進行隨機添加、替換或刪除,其中設置隨機操作的比例為1∶1∶1。
(2)EDA[17]。同樣使用jieba分詞工具對原始語句進行分詞,然后按10%的概率隨機選擇位置進行隨機刪除、插入、交換或同義詞替換。
(3)反向翻譯[18]。使用NLPCC2018和SIGHAN Bakeoff 2013—2015的數據集,通過正確樣本到錯誤樣本來訓練一個Transformer 模型來模擬中文錯誤方式,生成錯誤語句。
(4)OCR+ASR[19]。通過文本轉語音或圖片,再對語音或圖片添加噪聲后再轉換為文本來模擬中文音似和形似錯誤類型。
對于上述增強方法,除了反向翻譯需要先訓練一個模型所以需要花費較大的時間成本,其余方法都可以直接實現,并且在實驗過程中都使用NLPCC2018 和SIGHAN Bake-off 2013—2015訓練集中的正確語句生成相同大小的增強數據來保證數據量的一致性。
2.3 實驗設置
本文在數據集增強質量評價過程中選擇Pytorch為深度學習的框架,在PyCharm 2021,CPU 為i7-10700k,GPU 為RTX2060,16 GB 內存,Python 3.8,Win10 64 位操作系統下進行實驗。
為了分析不同數據集在中文糾錯模型上表現如何,本文使用了三個中文糾錯模型,分別是GECToR、基于中文BART 的seq2seq 模型和基于RNN 的seq2seq 模型。GECToR 和基于中文BART 的seq2seq 模型是使用文獻[20]提供的代碼及默認參數設置,但是將中文BART 的預訓練權重修改為BART-base。基于RNN 的seq2seq模型使用的是文獻[21]中的默認參數設置。
2.4 評價指標
2.4.1 中文語法糾錯評價指標
本文實驗采用公開的標準評價指標最大匹配分數(M2-Scorer[22])對中文語法糾錯模型在NLPCC2018測試集上的結果進行評估。對于糾錯模型輸出的改正結果,M2-Scorer 在所有標準編輯集合中計算出與改正結果重疊程度最高的編輯序列。其計算結果包括精確率(Precision,P)、召回率(Recall,R)和F0.5值。具體的計算公式如式(5)~(8)所示:
其中,{e1,e2,…,en} 是由糾錯模型輸出的改正的集合,{g1,g2,…,gn} 是M2-Scorer 工具包中給出的標準改正集合。
2.4.2 中文拼寫糾錯評價指標
對于中文拼寫糾錯任務的評價指標,本文采用SIGHAN Bake-off 2013—2015年比賽中CSC任務提供的計算方法。評價指標的混淆矩陣如表1所示,其中TP(True Positive)表示糾錯模型能夠正確識別出有拼寫錯誤的句子數;FP(False Positive)表示將沒有拼寫錯誤但被識別為錯誤的句子數;TN(True Negative)表示沒有拼寫錯誤的句子被標記為沒有出錯的句子數;FN(False Positive)表示存在拼寫錯誤卻被識別為沒有錯誤的句子數。

表1 混淆矩陣表Table 1 Confusion matrix table
在混淆矩陣的幫助下,本文采用的評價指標包含包括精確率(Precision,P)、召回率(Recall,R)和F0.5值。具體的計算公式如式(9)~(11)所示:
其中,TP+FP表示被糾錯模型識別為錯誤的句子數,TP+FN表示真實存在錯誤的句子數。
2.5 實驗結果
在這一節,本文分別做了三組實驗,來驗證所提出的質量評價方法的有效性。第一組實驗通過對不同數據增強方法生成的數據集在模型上進行預訓練,用相同的人工數據集進行微調,然后觀察模型在測試集上F值和數據集增強的質量評價結果的關聯性;第二組是在同一種數據增強方法下設置不同的錯誤類型的實驗;第三組是在數據量規模增大的情況下進行的實驗。
圖5 是使用不同數據增強方法生成相同數量大小的訓練集分別在NLPCC2018和SIGHAN2015測試集上的模型精度和增強數據集質量評估結果。由圖5(a)可知,四種數據增強方法生成的數據集質量融合結果是依次上升的,在三個糾錯模型上,前三種方法生成數據集的F 值也是依次上升的,但是對于OCR+ASR 的方法有不同的結果。因為在中文語法糾錯任務上,錯誤類型包含多字、少字、錯字和排序錯誤,但是使用OCR+ASR生成錯誤樣本只有錯字,所以不同模型在該方法上的表現會有所差異。其次,在三個模型中只有RNN 的模型沒有使用通過大規模數據進行預訓練增強,所以它在使用OCR+ASR這種方法下的效果會最差。在表2中總結了NLPCC2018上不同增強數據集的質量評價結果。實驗結果表明在NLPCC2018測試集中使用反向翻譯生成的增強數據集可以更有效地提升模型的性能。

表2 NLPCC2018上增強數據集質量評價結果Table 2 Enhanced dataset quality evaluation results on NLPCC2018

圖5 不同數據增強方法下的評估結果Fig.5 Evaluation results under different data augmentation methods
由圖5(b)可知,增強數據集質量融合指標結果是依次上升的,在所有糾錯模型中使用OCR+ASR的方法達到最優,腐化語料的效果最差,對于另外兩種增強方法的結果有不同的結果。因為在中文拼寫糾錯任務上,錯誤類型只包含錯字,而除了OCR+ASR這種方法,另外的方法都包含其他錯誤,對于這些錯誤并不能保證模型能夠學習到有用的部分。在表3中總結了SIGHAN2013—2015 上不同增強數據集的質量評價結果。實驗結果表明在SIGHAN2015 的測試集中使用OCR+ASR 的方法生成的增強數據集可以達到最優的效果。
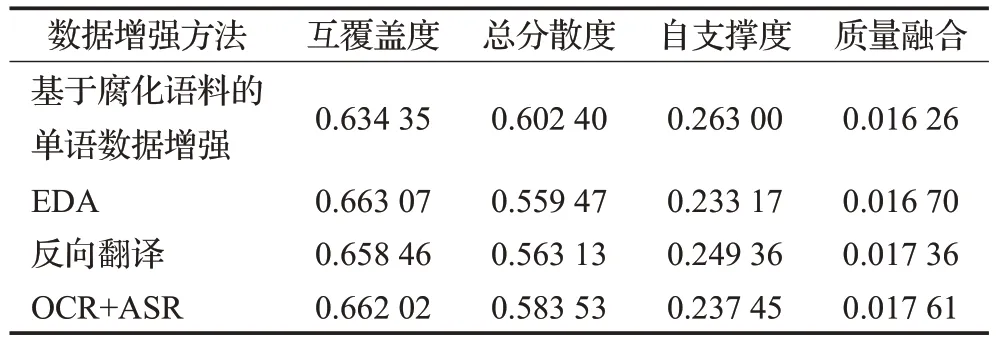
表3 SIGHAN2013—2015上增強數據集質量評價結果Table 3 Enhanced dataset quality evaluation results on SIGHAN2013—2015
圖6 是對基于腐化語料的單語數據增強方法中的錯誤類型進行修改后在兩個測試集上運行的模型精度和增強數據集質量評估結果。由圖6(a)可知,對于生成增強數據集的方式,使用了單一的錯誤類型。實驗結果表明,質量融合和模型精度結果保持一致,刪除方式效果最好,其次是添加方式,最差的是對句子中詞的替換。因此,只使用單一的錯誤類型對模型最終結果都會有一定的影響。相對而言,在NLPCC2018 測試集上使用替換方式對模型性能增強的效果最差,而刪除和添加方式對模型性能增強的效果會較高一點。
由于中文拼寫糾錯任務只包含錯字的錯誤類型,所以在單一錯誤類型上,只驗證了刪除和替換錯誤方式。因此由圖6(b)可知,質量融合結果和GECToR模型精度保持一致,但是在RNN和BART模型上運行結果相反,原因可能在于當前測試集只有錯字的錯誤類型,并且這兩個模型都是將中文糾錯看作是一個錯誤句子翻譯為正確句子的過程,所以能夠從替換的錯誤方式中學到更多有用的錯誤。因此,通過實驗結果表明在SIGHAN2015測試集上使用替換方式對RNN和BART模型的增強效果最好,刪除方式對GECToR模型的增強效果最好。
圖7和圖8是在數據量規模增大的情況下對模型召回率和增強數據集質量評估的結果,分別對基于腐化語料的單語數據增強和EDA方法生成的數據集依次擴充到5倍,可以發現質量融合結果上升的速度是逐漸減緩的,而對于BART 和GECToR 模型來說,隨著數據量的增加,模型的召回率會有所增加,但當數據量增加到一定規模的時候,召回率就有下降的趨勢,說明此時通過重復數據增強生成的句子對會對模型的性能有一定的影響,并不是數據量越多越好。
但是RNN 模型的召回率并沒有此規律,該模型之前沒有經過大規模的數據預訓練過,因此對于不同數據規模的數據集可以學習到不同的錯誤。
在表4 和表5 中分別給出NLPCC2018 測試集和SIGHAN2015 測試集上使用基于腐化語料的單語數據增強方法生成的不同數據規模的增強數據集在GECToR模型上的訓練結果。實驗結果表明,在NLPCC2018 測試集上,使用相同的訓練數據,通過數據增強方法進行規模增長的方式并不能獲取有效的模型性能增益。而在SIGHAN2015測試集上,通過數據規模的增長可以明顯看到性能的有效提升,但是并不能保證數據規模的增大的同時模型性能也保持穩定的上升。對于這一問題,原因在于拼寫糾錯數據集規模較小,所以在數據量規模增大的情況下對模型性能有明顯的提升,而NLPCC2018數據集規模較大,所以使用數據增強方法進行規模增長的方式并不能有效提升模型性能。
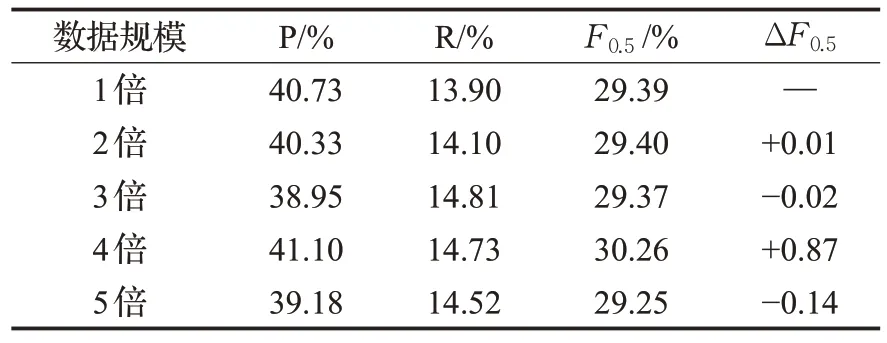
表4 NLPCC2018上模型訓練結果Table 4 Model training results on NLPCC2018
3 結束語
本文提出了一種以中文糾錯任務為例的數據集增強質量評價方法,以此緩解在不同應用任務中缺乏有效的方法來評估增強數據集質量的影響。該方法根據增強數據集的多維質量進行評估并通過質量融合的方式來進行排序,本文通過訓練已知算法的模型并將質量融合指標與模型精度相關聯來驗證質量評價的有效性。實驗結果表明,具有更高的整體質量的數據集可以在中文糾錯任務上實現更好的性能。未來的工作將通過質量評價來探索更適合特定任務的數據集構建方法,從而獲得具有更高質量、更高效的與任務相關的增強數據集。
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
Coco薇(2016年2期)2016-03-22 02:42:52
汽車觀察(2016年3期)2016-02-28 13:16:26
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
