基于異構指令圖的惡意軟件分類方法研究
2024-03-03 11:22:02錢麗萍吉曉梅
計算機工程與應用 2024年3期
錢麗萍,吉曉梅
1.北京建筑大學 電氣與信息工程學院,北京 100044
2.北京建筑大學 建筑大數據智能處理方法研究北京市重點實驗室,北京 100044
惡意軟件是當今互聯網上最大的威脅之一,它未經授權而訪問網絡設備,以竊取信息數據。據AVTest 報告顯示[1],惡意軟件數量一直呈指數級增長,平均每天注冊超過45萬個新的惡意軟件,截至2023年,惡意軟件數量已達10.3億。美國《福布斯》雙周刊網站報道,2023年值得警惕的三大網絡安全威脅:網絡釣魚、惡意軟件、供應鏈攻擊[2],因此惡意軟件問題亟需解決。
傳統的惡意軟件分類嚴重依賴于手工特征提取,常見的特征包括可打印字符串、PE文件頭、操作碼序列、n-gram、API 調用等。手工特征提取需要大量的先驗知識,耗費大量的時間和精力,面對日以萬增的惡意軟件,這顯然不太現實。隨著人工智能的興起,深度學習在各個領域中都取得了顯著的成果,如圖像識別、自然語言處理、語音識別等。不少網絡安全研究人員也開始應用深度學習模型,實現自動化特征提取。主要分為兩個方向:基于圖像的方法,首先將惡意軟件可視化為灰度圖像或彩色圖像,再進行分類研究。基于字符串的方法,將惡意軟件二進制文件反匯編,對匯編文件研究。
現有研究雖然都取得了不錯的成果,但是仍有不足,通過離散圖來表示樣本,所以樣本之間相互獨立,不受影響,面對各種各樣的樣本數據,同家族的惡意軟件間匯編代碼有很大的相似性,惡意樣本也不是一個獨立的個體,并且現有研究沒有充分挖掘匯編代碼的內在特征。本研究旨在從指令語義的角度,生成異構指令圖(heterogeneous instruction graph,HIG),使控制流圖(control flow graph,CFG)等其他的語義圖包含更多的指令語義信息,同時使數據樣本不再獨立。使CFG 包括控制流信息的同時不局限于局部結構特征,而關注長距離指令交互信息,這樣抗混淆性更強,語義信息更加豐富。由此可見,本研究在惡意軟件分類檢測中有著重要的意義,可以很好地解決目前分類模型語義信息不足和抗混淆性不好的問題。
本文貢獻如下:
(1)首次提出異構指令圖HIG,提取語義結構信息,使CFG包含更多的指令語義信息,此外捕獲樣本之間的消息傳遞,使樣本不是一個獨立的個體,提高整體性能。
(2)提出了一個新的基于圖神經網絡的惡意軟件分類模型MCHIG,分三個階段完成惡意軟件分類過程。首先通過異構指令圖結點分類,生成指令嵌入向量,然后基于CFG實現自動化分類過程。
1 相關工作
1.1 基于傳統深度學習
Li 等人[3]基于API 序列使用深度學習模型,充分挖掘API序列的內在特征信息,不再僅停留在API名稱和頻率特征,表明了API 序列內在特征的有效性。Liu 等人[4]用控制流圖CFG 和反匯編代碼相結合來表示惡意樣本,并將嵌入結果傳入CNN 和改進的LSTM 相結合構建的網絡模型中,結果表明反匯編代碼中也包含了豐富的語義信息。
1.2 基于圖深度學習
Yan等人[5]提出了MAGIC惡意軟件分類模型,用CFG表示惡意樣本,并矢量化為ACFG,取得了與最先進的手工制作特征相當的方法,Xia 等人[6]引入了詞頻-逆文檔頻率(term frequency-inverse document frequency,TF-IDF)表示文本頻率信息,研究發現基于TF-IDF可以提高分類效果,也證明了CFG 指令中包含更多未發掘的特征信息。
Wu 等人[7]提出了MCBG 惡意軟件分類模型,引入BERT,通過BERT 來提取指令語義信息,通過GIN-JK來捕獲CFG結構信息,不同于MCBG,Wu等人[8]基于函數調用圖(function call graph,FCG)提出了GEMAL 惡意軟件分類模型,將指令視為單詞,函數視為句子,使用CBOW自動提取語義特征生成AFCG,之后基于圖嵌入網絡生成惡意樣本的嵌入向量。Gao等人[9]使用MiniLM生成CFG 基本塊的初始特征向量,并使用圖同構網絡GIN壓縮向量,便于后續分類。它們都取得了非常不錯的結果,但語言模型語義提取階段訓練時間較長,不適用于實時惡意軟件分類。
FCG 函數體由CFG 控制流信息組成,Wang 等人[10]和Ling等人[11]提出了基于FCG和CFG的層次圖來表示惡意樣本,FCG 用于捕獲函數間的語義交互,CFG 用于捕獲函數內的語義交互,前者利用BERT和圖注意力網絡來實現惡意軟件分類,研究表明該模型的泛化性很好,后者進行對抗性攻擊,發現其表現更強的魯棒性,并且Malgraph[11]性能優于MAGIC、EMBER[12]、MalConv[13]。
Zhang 等人[14]提出了簡化指令依賴圖RIDG 的概念,基于RIDG、基本塊、函數和程序四層模式來判斷惡意程序的相似度,研究表明該方法具有很好的抗混淆功能。Tang 等人[15]基于中間表示程序首次提出了數據轉換圖,可以完整地表示數據流語義信息,并重新設計了圖網絡的消息傳遞函數和聚合函數,可以有效地提取數據流語義信息,抵抗常見的混淆技術,但是將二進制程序反匯編為中間表示程序,容易造成信息丟失,難以恢復完整的數據流信息。有關該方面的研究較少,本文致力于探尋更細粒度的語義圖表示。
1.3 圖神經網絡
圖神經網絡可以有效地處理非歐式數據,在鏈接預測[16]、文本分類[17]、知識圖譜[18]等都取得了很好的結果。Kipf 等人[19]提出了GCN,但是其靈活性較差,難以擴展到大規模網絡,并且收斂速度較慢。隨著DGCNN[20]的提出,網絡層數可以達到6層,效果相比GCN顯著提升,但是增加深度會因為過度平滑的問題降低模型效果,隨后Hamilton 等人[21]提出了GraphSAGE,相比較GCN,GraphSAGE可以分批訓練,可以很好地處理大型圖。
在惡意軟件分類研究中,圖神經網絡也取得了不錯的成果。張雪濤等人[22]提出了基于GCN的安卓惡意軟件檢測模型,基于精簡函數調用圖取得了不錯的結果。MAGIC提出使用DGCNN提取CFG的結構信息,MCBG提出使用帶跳躍知識的圖同構網絡來獲取CFG的語義信息和結構信息,它們的性能優于最先進的手工提取特征方法,證明了在基本塊上建立語義模型的有效性。可見圖神經網絡在惡意軟件研究中十分有效。
2 MCHIG模型概述
對現有的基于語義圖的惡意軟件分類方法進行了研究,發現主要包括四個方面,基于手工特征選取[5-6]、基于自然語言處理模型[7-9]、基于細粒度語義圖表示[14-15]以及語義圖的組合使用[10-11]。常見的語義圖由控制流圖CFG、函數調用圖FCG 和依賴圖(dependency graph,DG)等。常見語義圖語義信息有限、將數據樣本表示為獨立的個體,實際上同類別的樣本數據來自同一變體,并不獨立,因此提出了異構指令圖,使樣本數據不再獨立,從而包含更多的語義信息。
本文提出了MCHIG惡意軟件分類模型,首先將PE文件反匯編生成匯編文件,緊接著在數據預處理階段規范化指令信息,然后從匯編文件直接生成異構指令圖MyHIG 作為數據集,最后將生成的MyHIG 傳入圖網絡GraphSAGE,自動學習指令語義信息,最后執行下游任務測試模型的性能。整體框架見圖1。
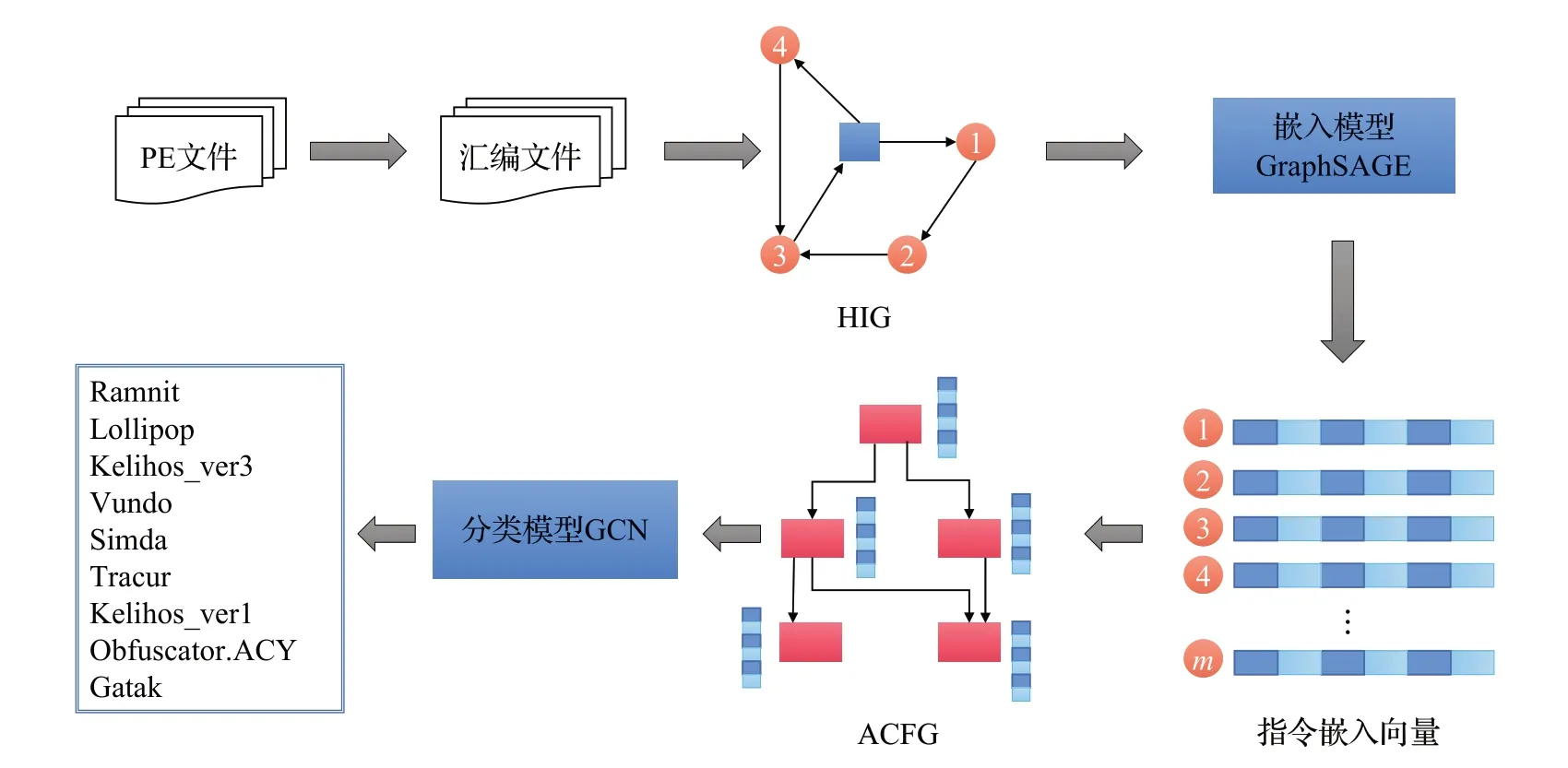
圖1 MCHIG系統概述Fig.1 System overview of MCHIG
2.1 異構指令圖
控制流程圖是一個過程或程序的抽象表示,標示計算機程序執行過程中所經過的所有路徑。結點代表基本塊,內含程序語句,邊代表控制流,即如何執行。現有研究[5-7]基于控制流圖都取得了不錯的成果,但是基于單個樣本生成控制流圖,缺少了樣本間的消息傳遞,基于此本文提出了異構指令圖。
從匯編文件中直接提取的HIG指令信息過于冗余,借鑒GEMAL[8]中所提出的規范化代碼的方法,對指令信息進行規范化處理。主要包含三部分:將所有數值常量替換為“N”;將所有不規則字符串替換為“M”;用“_”連接操作碼和操作數,規范化過程見圖2(a)。

圖2 匯編指令規范化和HIG例子Fig.2 Assembly instruction normalization and HIG example
異構指令圖HIG為G=(V,E),V代表頂點的集合,V=(Vp,Vi),頂點V有兩種類型分別為Vp和Vi,Vp代表文件結點,,Vi代表指令結點,其中n=10 807,m=248 948,dk代表第k層結點的維度,其中d0=128 。E=(epaper_contain_insn,einsn_belong_paper,einsn_cooccurence_insn,einsn_jmp_insn),E代表邊的集合,可見邊類型有四種。
關于HIG 的詳細信息見表1,圖2(b)展示了一個簡單的HIG 例子,paper1 包含基本塊1,paper2 包含基本塊2,其中e1、e8邊類型為epaper_contain_insn,e5、e10邊類型為einsn_belong_paper,e2、e3、e4、e7、e9邊類型為einsn_cooccurence_insn,e6、e11邊類型為einsn_jmp_insn。

表1 異構指令圖符號Table 1 Heterogeneous instruction graph symbols
可見惡意軟件匯編文件中包含了豐富的指令信息,異構指令圖不僅可以獲取樣本內的指令信息傳遞,還可以獲取樣本之間的消息傳遞,使樣本不是一個獨立的個體,對于其他語義圖同樣適用。
2.2 圖神經網絡
本文采用GraphSAGE 獲取HIG 的指令嵌入向量。其主要包括三個部分,首先對鄰居結點進行隨機采樣,其次生成目標結點的嵌入,對于結點v,在第k層的嵌入結果如下:
其中,Nk(v) 表示結點v在第k層的鄰居結點。aggregate 代表消息聚合,concat 代表消息拼接。代碼實現如下:
直觀理解為將鄰居對應的特征聚合后,進行一個維度變換,再加上結點自身經過維度變換的特征,就是結點最終生成的嵌入。相比GCN,結點v和鄰居u使用了不同的W,投射到了不同的特征空間,這大大加強了模型的表達能力。
GraphSAGE 對部分鄰居采樣,進行消息聚合,大大提升了效率,并且保留了樣本原始特征,解決了過度平滑的問題。基于本文所提出的HIG,將不同類型的邊分別傳入GraphSAGE網絡模型,再進行信息聚合,此外引入了Dropout層,網絡模型結構如下:
其中,ei代表HIG 的邊類型,i={0,1,2,3},aggr 代表聚合,常見的聚合方式有sum、max等。
GraphSAGE 時間復雜度主要取決于鄰居采樣和聚合,與圖的規模沒有直接關系。假設對于每個結點v,鄰居數目為k,每個結點在每一層采樣的鄰居數目為s,每層聚合時使用的神經網絡的計算復雜度為O(f),那么這段代碼的時間復雜度可以表示為O(Lksf),其中L是迭代次數。
最后使用交叉熵損失函數對模型進行訓練,公式如下:
其中,M代表類別數,pic為符號函數(0 或1),如果樣本i的真實類別等于c,則pic=1,否則為0,yic代表樣本i屬于類別c的概率。
3 實驗
在一個較大的公開的網絡安全數據集上評估了MCHIG模型,下面展示了實驗設置和實驗結果,并與其他模型進行對比。本研究對Android和Windows平臺都適用。所有實驗在i9-11900、RTX3090上完成。
3.1 數據集
3.1.1 BIG2015數據集
本實驗選取微軟在Kaggle 平臺上發起的惡意代碼分類比賽所提供的數據集BIG2015[23]。BIG2015數據集包含9 個家族,分別為Ramnit、Lollipop、Kelihos_ver3、Vundo、Simda、Tracur、Kelihos_ver1、Obfuscator.ACY、Gatak,樣本總數為10 868,每個樣本包含一個.bytes 文件和一個.asm文件,其中.asm文件由IDA pro反匯編獲得。提取HIG時發現BIG2015中有61個樣本沒有代碼塊,最終有效樣本數為10 807,表2展示了BIG2015類別名稱、類別編號以及最終各類別的有效樣本數。

表2 BIG2015數據集Table 2 BIG2015 dataset
基于BIG2015,提取異構指令圖HIG,并通過PyTorch Geometric(PyG)生成本研究的數據集,見圖3,其中paper 指文件名,insn 代表規范化后的指令名,對paper 和insn 都進行了特征向量初始化,維度為128 維,(insn,belong,paper)、(paper,contain,insn)、(insn,cooccurence,insn)和(insn,jmp,insn)代表四種類型的邊,以此作為后續研究的數據集,命名為MyHIG。MyHIG,將所有樣本數據用一張圖表示,而圖本身是多對多的關系,是相互影響的,因此所有樣本不再獨立。

圖3 數據集MyHIG Fig.3 MyHIG dataset
3.1.2 BODMAS_mini數據集
BODMAS[24]數據集收集了2019年8月至2020年9月的57 293個惡意樣本和77 142個良性樣本,共有581個家族。為了進一步驗證模型的有效性,本文從BODMAS數據集中選擇了9 個家族的少樣本數據與BIG2015 的結果做對比分析,并命名為BODMAS_mini。BODMAS_mini 數據集的家族類別包括:ausiv、ditertag、vigorf、mocrt、dorv、fuerboos、zbot、fakeav、smokeloader,樣本總數為2 617,每個樣本數據都對應一個.exe 文件,通過IDA pro 將.exe 文件反匯編為.asm 文件用于后續研究,反匯編后樣本數總數為2 404。表3 展示了數據集BODMAS_mini的詳細信息。

表3 BODMAS_mini數據集Table 3 BODMAS_mini dataset
3.2 基線
(1)MAGIC[5]:手動將CFG 矢量化為ACFG,傳入DGCNN 學習ACFG 中的固有結構信息,取得了與先進的手工制作的惡意軟件特征相當的效果。
(2)GEMAL[8]:基于FCG 和圖嵌入,將指令視為單詞,將函數視為句子,使用CBOW 提取語義特征,使用圖嵌入網絡將結構特征和語義特征相結合,生成嵌入向量,用于惡意軟件分類。
(3)MCBG[7]:基于CFG,使用BERT 學習結點語義信息、GIN-JK學習CFG結構信息,其性能優于MAGIC。
3.3 性能指標
選擇了分類研究中較常見的性能指標,即準確度(acc)、精確度(precision)、召回率(recall)和F1 值(F1-score)。
F1 值是對精確度與召回率的調和平均,優點在于能賦予精確度和召回率相同的權重以平衡二者。
3.4 基于BIG2015的惡意軟件分類研究
3.4.1 指令嵌入模型訓練
在HIG 指令嵌入階段,使用python 和PyG 框架訓練模型,針對MyHIG 數據集,隨機打亂樣本數據,選取前70%為訓練集,其余為測試集。表4列出了實驗調整的超參數,當消息傳遞模型為GraphSAGE,卷積層(num_layers)為2 時,64 層隱藏層和128 層隱藏層取得了相當的結果,但是64 層消耗671 s,128 層消耗881 s,是64 層的1.3 倍,因此令隱藏層為64。圖4 展示了不同num_layers 的分類準確度曲線圖,可見60 次迭代后,準確度趨于穩定,但是num_layers 值越大,整體分類準確度越高。表5 展示了不同卷積層下的最佳分類準確度和消耗時間,發現在num_layers=6時準確度達到最高為97.81%,共消耗2 420 s,平均每個樣本0.224 s。

表4 超參數調整Table 4 Hyperparameter adjustment

表5 不同卷積層層數下的最佳準確度和消耗時間Table 5 Best accuracy and time consuming under different convolutional layers

圖4 不同卷積層下的準確度曲線Fig.4 Accuracy curves under different convolutional layers
在實驗中,分別使用了SAGEConv、GATConv、TransformerConv 三種算法進行了對比分析,具體結果見表6,研究發現,GATConv的準確率最低只有87.91%,SAGEConv 準確率最高為97.81%,TransformerConv 準確率比SAGEConv低0.19個百分點,可見SAGEConv準確率最高,為保證結點嵌入的有效性,選擇SAGEConv做嵌入分類。

表6 不同算法比較分析Table 6 Comparative analysis of different algorithms
最終使用SAGEConv模型信息傳遞,設置學習率為0.003,優化器為adam,損失函數為交叉熵損失函數,迭代次數為150 次,隱藏層為64,卷積層為6,在測試集上取得了最佳性能。圖5展示了訓練集和測試集的acc曲線和loss 曲線,根據loss 曲線,可以發現,epoch 超過67之后,測試集上的loss值開始上升,出現過擬合現象,所以選取epoch 為67 時,模型訓練生成的指令嵌入向量,供后續惡意軟件分類研究。混淆矩陣見圖6,可見在3 242個樣本中,有71個樣本被錯誤分類。

圖5 BIG2015的acc曲線和loss曲線Fig.5 Acc curve and loss curve of BIG2015

圖6 BIG2015的混淆矩陣Fig.6 Confusion matrix of BIG2015
3.4.2 惡意軟件分類
在指令嵌入階段,MCHIG 生成了每個指令的初始向量,便于后續分類任務,在惡意軟件分類階段,基于CFG,并使用GCN 做分類任務。依舊使用pytorch 框架訓練模型,模型中包括兩個GCN卷積層和一個線性層,利用圖pooling,提取每張圖的全局特征,用于后續分類任務。設置學習率為0.001,優化器為adam,損失函數為交叉熵損失函數,迭代次數為1 000次,準確度最高為98.82%。為了與其他研究做對比,使用五折和十折交叉驗證進行訓練,在訓練過程中設置epoch為70。
五折交叉驗證分類結果(精確度、召回率、F1值)見圖7,具體數據見表7,可見9 個家族都取得了不錯的驗證分數,精確度都高于0.97,召回率都高于0.96,F1值都高于0.98,其中Lollipop、Vundo、Simda、Gatak 四個家族的性能指標全為1。五折交叉驗證分類混淆矩陣見圖8,可見在2 162個樣本中,有10個樣本被錯誤分類。

表7 MCHIG在BIG2015數據集上的五折交叉驗證結果Table 7 Five-fold cross-validation results of MCHIG on BIG2015 dataset

圖7 BIG2015的五折交叉驗證結果Fig.7 Five-fold cross-validation results of BIG2015

圖8 BIG2015的五折交叉驗證混淆矩陣Fig.8 Five-fold cross-validation confusion matrix of BIG2015
準確度是模型性能的直觀反映,F1 值是對精確度與召回率的調和平均,所以準確度和F1 值的結合能很好地反映模型的整體性能,因此模型對比分析中主要關注準確度和F1 值兩個性能指標。表8 列出了較先進模型的五折交叉驗證的實驗結果,從整體性能指標來看,MCHIG 的準確度和F1 值都優于基于手工特征提取的MAGIC,準確度提升0.002 9,F1 值提升0.003 2,并且整個過程實現自動化提取和分類,不需要專業知識,更具有通用性,MCHIG 的準確度和F1 值都優于基于BERT提取語義信息的MCBG,準確度提升0.000 1,F1值提升0.001 9,所以從整體性能看MCHIG 優于MCBG,此外MCHIG 的準確度與GEMAL 相同,但是GEMAL 的F1值比MCHIG 高0.000 2,考慮可能是特征類型的不同導致的,在GEMAL 中基于FCG 進行分類,并通過CBOW語言模型進行語義信息提取,而FCG 的每個結點本身就是由CFG構成的,也就是說GEMAL同時提取了FCG和CFG 的語義信息,而MCHIG 只通過提取CFG 的語義信息就達到了與GEMAL 相當的效果,由此可見MCHIG 可以更好地挖掘語義指令信息。綜上MCHIG優于MAGIC和MCBG,與GEMAL效果相當,證明了使用異構圖神經網絡生成指令嵌入向量的有效性。

表8 在BIG2015數據集上不同模型的五折交叉驗證對比Table 8 Five-fold cross-validation comparison of different models on BIG2015 dataset
十折交叉驗證分類結果(精確度、召回率、F1值)見圖9,其結果優于五折交叉驗證,確切數值見表9,可見大多數類別的精確度、召回率和F1 值都達到了1,只有Obfuscator.ACY的精確度、F1值和Ramnit的召回率、F1值除外,但也都高于0.99。十折交叉驗證分類混淆矩陣見圖10,可見在1 081 個樣本中,只有1 個被錯誤分類,取得了非常好的分類結果。

表9 MCHIG在BIG2015數據集上的十折交叉驗證結果Table 9 Ten-fold cross-validation results of MCHIG on BIG2015 dataset

圖9 BIG2015的十折交叉驗證結果Fig.9 Ten-fold cross-validation results of BIG2015
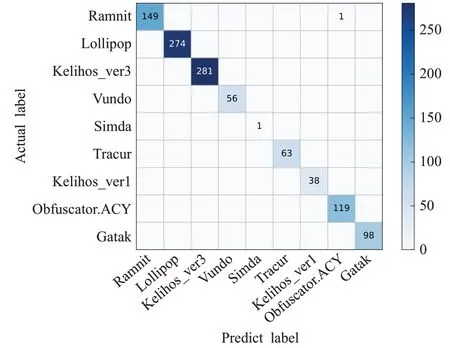
圖10 BIG2015的十折交叉驗證混淆矩陣Fig.10 Ten-fold cross-validation confusion matrix of BIG2015
為了進一步驗證模型的有效性,不同于五折交叉驗證與較先進的基于圖深度學習模型進行對比分析,在十折交叉驗證中選擇了基于傳統深度學習和集成學習模型進行對比分析。
表10 列出了MCHIG 與基于傳統深度學習和集成學習的對比分析。MalConv 在整個可執行文件的原始字節上使用神經網絡,避免過分關注局部信息,準確度達到0.964 1,F1值為0.889 4,而本文所提出的MCHIG,準確度提升0.035,F1 值提升0.109 8,效果顯著。Gibert等人[25]根據從圖像可視化中提取的一組判別模式有效地將惡意軟件分類,準確度達到0.975 0,F1 值為0.94,而MCHIG 基于匯編文件,將準確度提升0.024 1,F1 值提升0.059 2,可見MCHIG 可以很好地挖掘語義信息。Mays 等人[26]創建了一個分類器的聯盟,每個分類器使用不同的特征,其中包括一個將字節數據作為圖像處理的卷積神經網絡和一個利用操作碼n-gram特征的深度前饋神經網絡,準確度達到0.972 4,F1 值為0.961 8,而MCHIG 不依賴于多分類器,通過異構圖神經網絡嵌入和圖卷積神經網絡分類,準確度提升0.026 7,F1值提升0.037 4。Gibert 等人[27]提出了HYDRA,利用多模態學習將來自各種信息源的惡意軟件特征結合起來,其中包括APIs、字節序列和操作碼序列,準確度達到0.997 5,F1 值為0.995 1,而MCHIG 不依賴多特征融合,通過充分挖掘CFG語義和結構信息,準確度提升0.001 6,F1值提升0.004 1。由表10可見基于傳統的深度學習和集成學習的方法,取得了不錯的成果,但是本文所提出的MCHIG 準確度達到0.999 1,F1 值為0.999 2,相較其他模型不管是準確度還是F1值都有顯著提升。

表10 在BIG2015數據集上不同模型的十折交叉驗證對比Table 10 Ten-fold cross-validation comparison of different models on BIG2015 dataset
本研究基于異構指令圖數據集MyHIG,將惡意樣本緊密聯系起來,不再是獨立的個體,為后續研究提供了新思路,研究發現MCHIG 相比基于傳統深度學習和集成學習的惡意軟件分類模型,準確度最高提升0.035,F1值最高提升0.109 8,整體性能顯著提升,相比目前較先進的基于圖深度學習的惡意軟件分類模型,準確度最高提升0.002 9,F1 值最高提升0.003 2,這表明了MCHIG 的有效性,能夠從圖中挖掘更豐富的指令語義信息,此外MCHIG 在嵌入分類階段平均每個樣本僅需0.224 s,可用于實時惡意軟件分類。
3.5 基于BODMAS_mini的少樣本惡意軟件分類研究
采用同3.4 節同樣的研究方法和調優方法,在指令嵌入階段,使用SAGEConv 模型信息傳遞,設置學習率為0.003,優化器為adam,損失函數為交叉熵損失函數,迭代次數為150 次,隱藏層為64,卷積層為7,在測試集上取得了最佳性能,最佳準確率達到96.53%,共消耗634 s,平均每個樣本0.263 s。
圖11 展示了訓練集和測試集的acc 曲線和loss 曲線,根據loss曲線,可以發現,epoch超過67之后,測試集上的loss值開始上升,出現過擬合現象,所以選取epoch為67時,模型訓練生成的指令嵌入向量,供后續惡意軟件分類研究。混淆矩陣見圖12,可見在2 404個樣本中,有25個樣本被錯誤分類。

圖11 BODMAS_mini的acc曲線和loss曲線Fig.11 Acc curve and loss curve of BODMAS_mini

圖12 BODMAS_mini的混淆矩陣Fig.12 Confusion matrix of BODMAS_mini
在惡意軟件分類階段,在BODMAS_mini數據集上分別進行了五折和十折交叉驗證,在訓練過程中設置epoch為70。發現十折交叉驗證結果優于五折交叉驗證,五折最佳準確率達到97.29%,十折最佳準確率為98.76%。
十折交叉驗證分類結果(精確度、召回率、F1值)具體數據見表11。可見本次交叉驗證測試集中vigorf 家族樣本數為0,smokeloader、ausiv、mocrt、dorv 和fakeav五個家族的精確度、召回率、F1均等于1,由圖13十折交叉的混淆矩陣可知,在241個樣本中,有3個樣本被錯誤分類,可見MCHIG 在少樣本數據集中也取得了很好的結果,可用于少樣本惡意軟件分類研究。

表11 MCHIG在BODMAS_mini數據集上的十折交叉驗證結果Table 11 Ten-fold cross-validation results of MCHIG on BODMAS_mini dataset

圖13 BODMAS_mini的十折交叉驗證混淆矩陣Fig.13 Ten-fold cross-validation confusion matrix of BODMAS_mini
4 結論
在本文提出了MCHIG,一個惡意軟件分類模型。MCHIG主要包括三個階段,異構指令圖生成階段、指令嵌入階段和惡意軟件分類階段。在指令嵌入階段,基于異構指令圖HIG,采用異構圖神經網絡GraphSAGE進行消息傳遞,學習指令語義信息,最后為每個指令結點生成向量表示;在惡意軟件分類階段,將嵌入階段生成的向量作為指令初始向量,用CFG表示惡意樣本,用GCN模型做惡意軟件分類,MCHIG使樣本不再是獨立的個體,能夠獲取樣本之間的消息傳遞。在微軟發布的BIG2015數據集上進行了實驗,最佳準確度達到99.91%,在BODMAS_mini 少樣本數據集上的最佳準確率達到98.76%,可見MCHIG優于目前較先進的其他惡意軟件分類模型。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
