基于情感特征增強的中文隱式情感分類模型
2024-03-03 11:21:40談光璞朱廣麗韋斯羽
計算機工程與應(yīng)用 2024年3期
談光璞,朱廣麗,韋斯羽
安徽理工大學(xué) 計算機科學(xué)與工程學(xué)院,安徽 淮南 232001
情感分析作為自然語言處理領(lǐng)域中的一個研究熱點,主要是對帶有情感色彩的主觀文本進(jìn)行情感識別的過程,在評論分析、民意分析和基于內(nèi)容推薦等領(lǐng)域具有巨大的實際應(yīng)用潛力。它根據(jù)人們情感的主觀性和客觀性將情感分為顯式情感和隱式情感。顯式情感分析受到學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注和研究,但隱式情感分析仍處于起步階段,面臨著一定的挑戰(zhàn)。
顯式情感與隱式情感的主要不同在于表達(dá)情感時是否包含顯示情感詞。顯式情感具有明顯的顯性情緒詞,能夠直接剖析和研究表達(dá)文本所包含的情感傾向。然而,通常情況下,人們傾向于以一種含蓄的方式來表達(dá)自己的情感,文本中不包含情感詞語,但所包含的情感卻豐富而抽象,很難直接判別情感極性。表1給出了隱式情感文本的兩個例句。

表1 隱式情感文本例句Table 1 Implicit sentiment example sentence
句1 中包含一種隱式的積極情緒,“包攬”“所有金牌”兩詞雖然不帶情感色彩,實則表達(dá)開心;句2中包含一種隱式的消極情緒,對不能參觀奧運而表示遺憾。雖然在語句中找不出明確的情感詞,卻仍能表達(dá)出不同的情感類別。
目前,有關(guān)隱式情感分析逐步受到外界的關(guān)注,隱式情感文本所面臨的主要挑戰(zhàn)有:(1)缺乏情感詞,情感特征提取困難;(2)無法深入挖掘文本的語義特征。
基于以上考慮,本文提出一種基于情感特征增強的中文隱式情感分類模型。目的是通過構(gòu)建積極和消極情感詞庫,并將情感詞進(jìn)行位置嵌入得到情感特征增強的句子,進(jìn)而提高分類準(zhǔn)確率。本文提出CISC 模型的具體框架如圖1所示。

圖1 CISC模型框架圖Fig.1 CISC model
主要由預(yù)處理層、數(shù)據(jù)處理層、特征處理層、分類層組成:
(1)預(yù)處理層:采用Jieba工具對文本進(jìn)行預(yù)處理和分詞,通過自注意力機制對句子中的每個詞進(jìn)行權(quán)重分配,并將兩種詞庫中的詞分別加入到詞語序列中權(quán)重值最大的詞前方,得到兩個新的詞語序列。
(2)數(shù)據(jù)處理層:將結(jié)合后的詞語序列輸入到數(shù)據(jù)處理層,利用Word2Vec 和多層注意力網(wǎng)絡(luò)(hierarchical attention networks,HAN)對其進(jìn)行情感特征增強的句子的構(gòu)建。
(3)預(yù)處理層:采用Jieba工具對文本進(jìn)行預(yù)處理和分詞,通過自注意力機制對句子中的每個詞進(jìn)行權(quán)重分配,并將兩種詞庫中的詞分別加入到詞語序列中權(quán)重值最大的詞前方,得到兩個新的詞語序列。
(4)數(shù)據(jù)處理層:將結(jié)合后的詞語序列輸入到數(shù)據(jù)處理層,利用Word2Vec 和多層注意力網(wǎng)絡(luò)(HAN)對其進(jìn)行情感特征增強的句子的構(gòu)建。
(5)特征處理層:通過Bi-GRU對句子的深層特征表示進(jìn)行獲取,并使用AOA抽取多種信息中的重要特征,后輸入到分類層中。
(6)分類層通過Softmax 對句子進(jìn)行情感傾向的概率計算,通過將結(jié)合積極詞句子的正向情感概率與結(jié)合消極詞句子的負(fù)向情感概率進(jìn)行均值計算并比較,得到最終的情感傾向。
本文的主要貢獻(xiàn)包括:
(1)構(gòu)建兩種情感詞庫和多層注意力網(wǎng)絡(luò)以增強句子中的情感特征。將原始句子的詞語序列分別結(jié)合積極詞庫中的積極詞和消極詞庫中的消極詞,并利用多層注意力網(wǎng)絡(luò)來生成對應(yīng)的情感特征增強的句子,有利于對隱式情感文本的情感極性進(jìn)行更好判斷。
(2)使用Bi-GRU-AOA 模型以深入挖掘語義特征。使用Bi-GRU對句子深層特征表示進(jìn)行獲取,使用AOA抽取多種信息中的重要特征,提高針對隱式情感文本進(jìn)行分類的準(zhǔn)確率。
1 相關(guān)工作
目前,有關(guān)情感分析的研究大多只關(guān)注顯式情感,對隱式情感的研究極其有限,因此對隱式情感分析的研究仍處于初始階段。然而隨著對自然語言處理領(lǐng)域的深入研究,對隱式情感分析研究的關(guān)注度也逐步提高。相關(guān)工作主要從情感分析和隱式情感分析兩個方面對隱式情感分析工作進(jìn)行研究。
1.1 情感分析方法
情感分析對蘊含情感特征的文本進(jìn)行分析處理的一個過程,對于文本進(jìn)行情感分析,可以更好地了解到人們對于某件事情或是某個物件的接受程度。Dauphin等人[1]利用卷積神經(jīng)網(wǎng)絡(luò)對較長的文本進(jìn)行分析,這個過程是基于門控機制的。Zhang等人[2]通過對單層CNN的敏感性進(jìn)行分析,探討了超參數(shù)這個指數(shù)對文字情緒分類的影響。Ma 等人[3]旨在從低維異構(gòu)網(wǎng)絡(luò)中學(xué)習(xí)有意義的表示向量,從而實現(xiàn)網(wǎng)絡(luò)結(jié)構(gòu)和屬性特征的提取。Yao 等人[4]構(gòu)建了一種文本分類模型,該模型基于圖卷積神經(jīng)網(wǎng)絡(luò),利用詞語之間的共現(xiàn)關(guān)系與待分析文本的聯(lián)系,從而構(gòu)造了文本圖譜。Chen等人[5]使用圖卷積神經(jīng)網(wǎng)絡(luò)和注意力機制對方面級的情感分類任務(wù)進(jìn)行處理分析。
Wang等人[6]為了解決CNN 和RNN 的缺點,提出了一種DRNN模型,它能夠同時獲得長距離依賴性以及關(guān)鍵文本信息。Devlin等人[7]設(shè)計了一種具備更高泛化能力的BERT 模型,并在后續(xù)的應(yīng)用中得到了廣泛的應(yīng)用。Sun 等人[8]對句子情緒極性差異進(jìn)行了分析,并給出了一種以多極正交注意力為基礎(chǔ)的LSTM 隱式情感分析方法。Wang 等人[9]構(gòu)建了一種HKEM 模型,利用分層知識強化將文本中的不同層面的知識信息進(jìn)行全面的整合,從而減輕了“弱特征”的問題。Zhuang等人[10]為了更好地獲取句子的語義信息,考慮了上下文信息、句法信息和語義信息的融合,并提出了一種新型神經(jīng)網(wǎng)絡(luò)模型。
在利用卷積神經(jīng)網(wǎng)絡(luò)對隱式情緒特征進(jìn)行提取時,池化運算將失去句子的位置特征[11],注意力機制在這時將發(fā)揮著關(guān)鍵作用[12]。Xiang 等人[13]在此基礎(chǔ)上,提出了一種以注意力神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)的事件隱式極性分析方法,此模型首先使用門控神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)句子來表達(dá),再利用注意機制捕捉到與情緒極性緊密有關(guān)的多個方面。趙容梅等人[14]利用卷積神經(jīng)網(wǎng)絡(luò)對文本進(jìn)行特征提取,與LSTM結(jié)構(gòu)的上下文信息相結(jié)合,并運用注意力機制,建立了一種新的混合神經(jīng)網(wǎng)絡(luò)模型,從而實現(xiàn)了對隱式情感的分析。
1.2 隱式情感分析方法
隱式情感分析是指文本在不具有明確的情感詞下進(jìn)行的任務(wù)分析,且大多數(shù)語料庫資源是針對隱式情感分析任務(wù)進(jìn)行構(gòu)建的。He等人[15]采用一種改進(jìn)的貝葉斯模型,對文字中的隱藏題材和情緒極性進(jìn)行分析。Liao 等人[16]通過對事實型隱式情感在句子層次的識別分析,給出了一種以表達(dá)學(xué)習(xí)的多級語義融合法來學(xué)習(xí)識別特征。郭鳳羽等人[17]在認(rèn)知學(xué)相關(guān)理論的基礎(chǔ)上,給出了一種基于語境的交互感知與模式篩選的隱式篇章關(guān)系識別方法(MATS),可以有效地提高模型的識別能力。Rana等人[18]利用了一種基于共現(xiàn)和相似的技術(shù),對隱含情緒任務(wù)極性分析,并基于共現(xiàn)和相似性的技術(shù),提出了一種對文字隱含的情緒進(jìn)行識別的方法,著重于對使用者觀點的隱含線索和使用者觀點的實際目標(biāo)隱含的方面線索進(jìn)行分析。Zhang等人[19]提出了一種以視點信息單位為基礎(chǔ)的層次情緒分類方法,以關(guān)鍵語作為隱式評估對象的識別依據(jù)。有助于使用者在方面層次上的情感分析做出較好的決定。
隨著神經(jīng)網(wǎng)絡(luò)的迅速發(fā)展,采用神經(jīng)網(wǎng)絡(luò)模型對隱式情感文本進(jìn)行分析,從而有效地改善對于中文隱式文本的進(jìn)行分類的準(zhǔn)確率。Wei等人[20]提出了一種多極性正交注意的BiLSTM 模型,相對于傳統(tǒng)的單一注意模式,采用多極性注意可以辨識出詞與情感化趨勢的不同,并運用正交限制機制來確保優(yōu)化過程中可以有效地提高性能。可以較好地應(yīng)用于隱式情感分析。Zhao等人[21]提出了一種融合CNN和門限值遞歸單元的的情感分析模型。具有很好的應(yīng)用前景。Yuan 等人[22]構(gòu)建了中文隱式情感分類模型GGBA,利用門控卷積神經(jīng)網(wǎng)絡(luò)(GCNN)對隱式情感句進(jìn)行局部重要的信息提取,并利用門控循環(huán)單元(GRU)網(wǎng)絡(luò)提高特征的時序信息。黃山成等人[23]針對隱式情感文本極性與句中實體、情感特征增強的句子和外部知識的相關(guān)特征,提出了一種ERNIE2.0-BiLSTM-Attention(EBA)隱式情感分析方法,可以很好地反映出隱式情感句的語義和上下文信息,從而有效地提高其識別能力。Chen等人[24]針對目前的序列化模型,對中文隱式情感分析中特性信息的提取不精確性,給出了一種基于雙向長短時神經(jīng)網(wǎng)絡(luò)與上下文感知的樹形遞歸神經(jīng)網(wǎng)絡(luò)的并行混合模型,該模型能有效地改善分類精度、時間代價少、性能得到較好的改善。
Yang 等人[25]第一次提出層次注意力網(wǎng)絡(luò)。楊善良等人[26]提出基于圖注意力神經(jīng)網(wǎng)絡(luò)的隱式情感分析模型ISA-GACNN,通過構(gòu)建文本和詞語的異構(gòu)圖譜,使用圖卷積操作傳播語義信息,并利用注意力機制針對詞語對在整體情感上的影響程度進(jìn)行計算。潘東行等人[27]根據(jù)隱式表達(dá)對上下文內(nèi)容的依賴性,設(shè)計了一種融合上下文語義特征和注意力機制的分類模型,增強了部分中立性隱式表達(dá)句的分類效果。
基于以上研究分析,目前的方法雖能很好地對包含隱式情感的文本進(jìn)行分類,但是仍然存在著一些缺陷,例如:分類精度較低等。本文通過引入情感詞來增強句子中的情感特征以及加入Bi-GRU-AOA 模型來提高分類準(zhǔn)確度。
2 情感特征增強方法
針對隱式情感語句進(jìn)行情感分析時,由于缺乏情感詞,句子中所表達(dá)的情感一般比較含蓄,不容易去進(jìn)行分析,傳統(tǒng)的分析中文隱式文本的方法主要是結(jié)合語義分析或上下文特征來進(jìn)行的,沒有考慮到情感特征增強的句子的問題,因此,本文考慮將情感詞作為一個重要的特征加入到原有的詞語序列,傳入到多層次注意力網(wǎng)絡(luò)中,構(gòu)建出更符合隱式情感文本語義的情感特征增強的句子,從而提高中文隱式情感句子的分類準(zhǔn)確率。
2.1 情感詞庫構(gòu)建
情感詞庫的構(gòu)建方法主要有人工標(biāo)注、基于詞典的方法和基于語料庫的方法,但由于人工標(biāo)注費時費力,因此基于詞典和基于語料的方法使用較多。將使用基于詞典的方法對本文所需詞庫進(jìn)行構(gòu)建,且該詞典為網(wǎng)上公開資源的“情感詞典及分類”詞典。基于已有的詞典,下面將給出積極和消極兩個詞庫的構(gòu)建過程。
(1)情感種子詞庫構(gòu)建
使用TF-IDF 算法構(gòu)建種子詞庫,并選定少量初始正面種子詞和初始負(fù)面種子詞,且選定的種子詞情感性傾向較為強烈,具有代表性,以免混入過多噪聲。例如:積極詞為“好”,消極詞為“差”。部分情感種子詞如表2所示。

表2 部分情感種子詞Table 2 Part of sentiment seed word
(2)情感傾向點互信息算法(SO-PMI算法)
通過SO-PMI算法輸出積極情感候選詞詞庫和消極情感候選詞詞庫。
先計算兩個不同的詞在已有詞典中同時出現(xiàn)的概率,如公式(1)所示:
接著計算已有詞典中的每個詞與積極和消極情感種子詞庫中的每個詞的PMI,觀察這個詞是更接近積極情感詞庫,還是更接近消極情感詞庫,如公式(2)所示:
其中,word1,word2表示已有詞典中兩個不同的詞,P(word1)、P(word2)分別表示在已有詞典中word1、word2出現(xiàn)的概率,PMI 為word1與word2同時出現(xiàn)的概率,且兩個詞出現(xiàn)的概率越大,其相關(guān)性越大。公式(2)中,num(pos)和num(neg)分別指的是積極基準(zhǔn)詞的總數(shù)和消極基準(zhǔn)詞的總數(shù)。PMI(word)表示在已有詞典中word 出現(xiàn)的概率,PMI(Posj)表示第j個積極基準(zhǔn)詞出現(xiàn)的概率,PMI(Negj)表示第j個消極基準(zhǔn)詞出現(xiàn)的概率,word指隨便一個詞。當(dāng)SO-PMI >0,表示這個詞更接近正向,即為積極詞;當(dāng)SO-PMI=0,表示這個詞為中性詞;當(dāng)SO-PMI <0,表示這個詞更接近負(fù)向,即為消極詞。
(3)情感詞庫
經(jīng)過計算,按照SO-PMI值對情感詞進(jìn)行從大到小的排序,并根據(jù)情感強度進(jìn)行抽取,從1 到5 分為五檔,1 表示強度最小,5 表示強度最大。分別各選取20個形容詞性積極和消極情感詞構(gòu)建成積極情感詞庫和消極情感詞庫。情感詞庫構(gòu)建的部分算法如算法1所示,積極情感詞庫如表3 所示,消極情感詞庫如表4所示。

表3 積極情感詞庫Table 3 Positive sentiment lexicon

表4 消極情感詞庫Table 4 Negative sentiment lexicon
算法1情感詞庫構(gòu)建部分算法
2.2 多層注意力網(wǎng)絡(luò)
中文隱式情感句子中所蘊含的情感表達(dá),通常不止是依賴于句子本身的語義,如表5 所示,句子所處的不同語境對句子中所表達(dá)的情感也是有很大影響的。中文隱式情感句的語境信息在判斷句子本身情感時起到了關(guān)鍵作用。

表5 不同語境下的隱式情感句Table 5 Implicit sentiment sentences in different contexts
為了更好地構(gòu)建隱式情感句的情感特征增強的句子,本文將兩種極性的情感詞分別加入到隱式情感句中,并構(gòu)建多層注意力網(wǎng)絡(luò)來更好地生成情感特征增強的句子。
多層注意力網(wǎng)絡(luò)的整體網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。

圖2 多層注意力網(wǎng)絡(luò)Fig.2 Hierarchical attention networks
3 基于情感特征增強的中文隱式情感分類模型
為了解決隱式情感語句缺少情感詞以及情感分類準(zhǔn)確率低的問題,本文提出一種基于情感特征增強的中文隱式情感分類模型,如圖3 所示,對中文隱式情感語句進(jìn)行判別,有效地提高了情感分類效果。
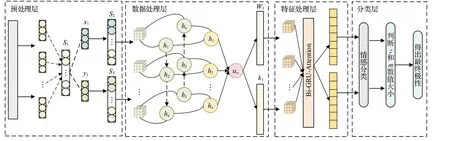
圖3 CISC模型示意圖Fig.3 Illustration of CISC
3.1 模型介紹
本文首先將待處理句子輸入到預(yù)處理層進(jìn)行預(yù)處理,排除影響句子進(jìn)行情感分析的一些因素,例如:刪除特殊字符、繁體字轉(zhuǎn)簡體字等。隨后對預(yù)處理后的句子進(jìn)行分詞,從而得到詞語序列S1。然后,在數(shù)據(jù)處理層將兩種詞庫中的詞分別加入到詞語序列S1中,得到詞語序列S2和S3,使用Word2Vec 將S2、S3轉(zhuǎn)換為詞序列,借助多層注意力網(wǎng)絡(luò)(HAN)構(gòu)建出S2、S3的情感特征增強的句子并輸入到特征處理層;進(jìn)一步,在特征處理層將處理后文本使用Word2Vec 轉(zhuǎn)換為詞向量后利用雙向門控循環(huán)單元(Bi-GRU)+交互注意力機制(attention-over-attention)充分提取語義特征,輸入到分類層;最終在分類層中通過計算分別得出兩個句子的兩種極性概率,并對兩種情感詞庫中的情感詞分別結(jié)合文本所得出的情感極性概率進(jìn)行平均值計算,通過對比隱式情感句子結(jié)合兩種詞庫所得到的平均值,得出隱式文本的最終情感極性。
3.2 數(shù)據(jù)預(yù)處理層
設(shè)原始語句為S,使用Jieba 工具對語句S進(jìn)行去除特殊字符、繁體字轉(zhuǎn)簡體字等預(yù)處理操作,并分詞后得到的詞語序列設(shè)為S1,用Wi表示詞語序列中的第i個詞。詞語序列S1如式(3)所示:
在詞語序列S1的基礎(chǔ)上,設(shè)積極情感詞庫為xa,消極情感詞庫為ya,其中a∈[1,20]。利用自注意力機制的情感詞檢測方法,將句子中的每個單詞經(jīng)過Encoder編碼,對句子中權(quán)重最大的詞進(jìn)行定位,設(shè)為Wβ,其中β∈[1,i],然后將積極和消極情感詞庫中對應(yīng)位置的第一個詞x1、y1分別加入該詞前方,得到詞語序列S2、S3,如式(4)、(5)所示:
預(yù)處理部分算法如算法2所示,具體的處理過程如圖4所示。

圖4 預(yù)處理示意圖Fig.4 Illustration of preprocessing
算法2預(yù)處理部分算法
3.3 數(shù)據(jù)處理層
設(shè)隱式文本句子分別和兩種情感詞構(gòu)成句子的情感特征增強的句子為jv、kv。
使用Word2Vec 將詞語序列S2、S3分別轉(zhuǎn)換為詞向量并輸入到多層注意力網(wǎng)絡(luò)中去,從而得到隱式文本句子分別和兩種情感詞構(gòu)成句子的情感特征增強的句子為jv、kv。
多層注意力網(wǎng)絡(luò)由詞序列編碼層、詞級注意力層、句子表示層,三個層次組成。
(1)詞序列編碼層
設(shè)詞語序列S,用Wi表示詞語序列中的第i個詞,t表示詞語序列中的詞語的數(shù)量。使用Word2Vec 工具將Wi映射為詞向量Ci,詞語序列中第i個詞的雙向隱藏層拼接矩陣Ri的計算公式如公式(6)、(7)、(8)所示:
其中,GRU為正反向讀取每個單詞的嵌入向量,hri和hli分別為前一時刻獲得的正反向隱藏層輸出。
(1)詞級注意力層
設(shè)詞語序列S的詞權(quán)重矩形為DW,使用單詞級別的注意力權(quán)重計算方式,具體計算公式如公式(9)、(10)所示:
其中,?i為詞語序列S中第i個單詞的注意力分值,Si表示隱藏層向量,ui表示Si在詞注意力層的隱含表示;uw表示一個初始化用以表示上下文的向量。
(3)句子表示層
句子S的編碼如公式(11)所示:
3.4 特征處理層
如公式(12)、(13)、(14)所示,使用Bi-GRU,在兩個不同方向的GRU 上進(jìn)行計算,從而提取出構(gòu)建語句中的重要特征,最終將兩個不同方向的隱藏層計算結(jié)果合并輸出。
其中,Bi-GRU在t時刻的隱藏層輸出ht是hrt和hlt的串聯(lián)。
為了加強對句子內(nèi)部結(jié)構(gòu)的特征學(xué)習(xí),使注意力權(quán)重矩陣分布更加準(zhǔn)確,本文采用了交叉注意力機制。計算公式(15)、(16)如下:
其中,Ke為關(guān)鍵詞矩陣,Ve為值矩陣,ma∈{1,2,…,he},ja∈{1,2,…,he},he為多頭注意力head的數(shù)量,為交叉注意力,dke為ke的維度。
將所有head 特征拼接并使用線性變換進(jìn)行特征學(xué)習(xí),得到Hmulti,并輸入到分類層中。計算公式如式(17)所示:
其中,Wo用于將串聯(lián)的多頭特征轉(zhuǎn)換到詞嵌入的維度后。
3.5 分類層
設(shè)加入積極詞后隱式文本為積極的概率為Mv,加入消極詞后隱式文本為消極的概率為Nv。設(shè)v=1,情感詞庫中詞的個數(shù)為q。
使用softmax分類器對隱式情感句子分別結(jié)合兩種情感詞所構(gòu)成的句子進(jìn)行情感極性的判斷,分別得出Jv為積極和Kv為消極的概率Mv、Nv,并進(jìn)行求和計算,求和結(jié)果如式(18)、(19)所示:
將v+1 后,重復(fù)3.1 至3.4 節(jié)步驟,當(dāng)v=q時,將Z和G分別除以q,得到平均值并比較,最終得出隱式情感句子的情感極性。對句子進(jìn)行情感分析的具體步驟如圖5所示。
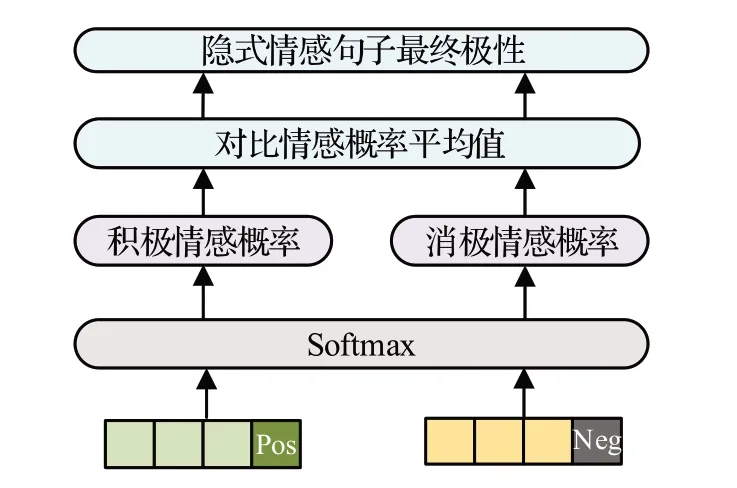
圖5 情感分析層Fig.5 Sentiment analysis layer
使用softmax分類器進(jìn)行情感分類步驟如下:
其中,T為隱式情感句子分別結(jié)合兩種情感詞所構(gòu)成句子的隱含表示,Q為概率值,wT為權(quán)重,bT為偏置。
本文使用的損失函數(shù)為:
其中,LOSS表示損失函數(shù)輸出的結(jié)果,egc為真實標(biāo)簽,e為預(yù)測標(biāo)簽。
4 實驗及結(jié)果分析
為了驗證本文提出的基于情感特征增強的中文隱式情感分類模型的效果,選取了網(wǎng)上公開的SMPECISA2019(https://download.csdn.net/download/qq_41479464/85825618?spm=1001.2014.3001.5503)數(shù)據(jù)集進(jìn)行對比實驗。
4.1 實驗數(shù)據(jù)
數(shù)據(jù)集:選用公開的SMP-ECISA2019數(shù)據(jù)集,包含超過20 000 多條各種極性的隱式情感句子。數(shù)據(jù)來源主要包括評論網(wǎng)站、休閑網(wǎng)站、產(chǎn)品交流,主要領(lǐng)域包括比賽、節(jié)日、評論、旅游等。部分實驗數(shù)據(jù)如表6 所示,數(shù)據(jù)標(biāo)注詳情如表7所示。

表7 實驗數(shù)據(jù)統(tǒng)計Table 7 Statistics of experimental data
4.2 評價指標(biāo)
實驗采用準(zhǔn)確率P、召回率R以及F1 指數(shù)。如公式(23)~(25)所示:
其中,TP為被模型預(yù)測為正類的正樣本;TN為被模型預(yù)測為負(fù)類的負(fù)樣本;FP為被模型預(yù)測為正類的負(fù)樣本;FN為被模型預(yù)測為負(fù)類的正樣本。
4.3 實驗方法
為了驗證本文提出的基于情感特征增強的中文隱式情感分類模型的效果,本文以網(wǎng)上公開的SMPECISA2019數(shù)據(jù)集為研究對象進(jìn)行實驗,設(shè)v=1,情感詞庫中詞的個數(shù)為q,具體實驗操作如下:
步驟1對于原始句子進(jìn)行預(yù)處理。去除特殊字符、繁體字轉(zhuǎn)簡體字等并分詞,得到詞語序列S1,將兩個詞庫中對應(yīng)位置的第一個詞Xv、Yv分別加入詞語序列中,得到詞語序列S2、S3。
步驟2構(gòu)建情感特征增強的句子。利用層注意力網(wǎng)絡(luò)根據(jù)詞語序列2、3 分別構(gòu)建情感特征增強的句子Jv、Kv。
步驟3特征處理。利用Bi-GRU+AOA 分別提取wv、kv句子深層特征并并輸入到下一層進(jìn)行情感分析。
步驟4情感分類。使用softmax 分類器對Jv、Kv進(jìn)行情感極性的判斷,分別得出Jv為積極和Kv為消極的概率Mv、Nv,并進(jìn)行求和計算。
步驟5將v+1 后,重復(fù)步驟1~步驟4,直到v=s為止,然后將Z和G分別除以q,得到平均值并比較,最終得出隱式情感句子的情感極性。
為了驗證本文提出的基于情感特征增強的中文隱式情感分類模型的有效性,將本文提出的模型得到的實驗結(jié)果與GGBA[22]、EBA[23]、CA-TRNN[24]、ISA-GACNN[26]四種模型進(jìn)行對比實驗。
4.4 實驗結(jié)果及分析
根據(jù)4.3節(jié)的實驗方法,本文做了如下實驗:
從NLP的官方數(shù)據(jù)集中選擇了SMP-ECISA2019數(shù)據(jù)集,采用Jieba 和Word2Vec 獲取兩組詞向量,將這兩組詞向量傳入層注意力網(wǎng)絡(luò)中,得到對應(yīng)的情感特征增強的句子,將其輸入到Bi-GRU-AOA 模型中去,得到對應(yīng)的特征向量,將特征向量輸入到分類層中求取不同極性的概率,并計算平均值后進(jìn)行對比,從而得出最終極性。本文提出的模型CISC 與GGBA、EBA、CA-TRNN三種模型進(jìn)行了對比實驗,實驗環(huán)境基于相同的硬件設(shè)施和環(huán)境配置。實驗結(jié)果如表8所示。
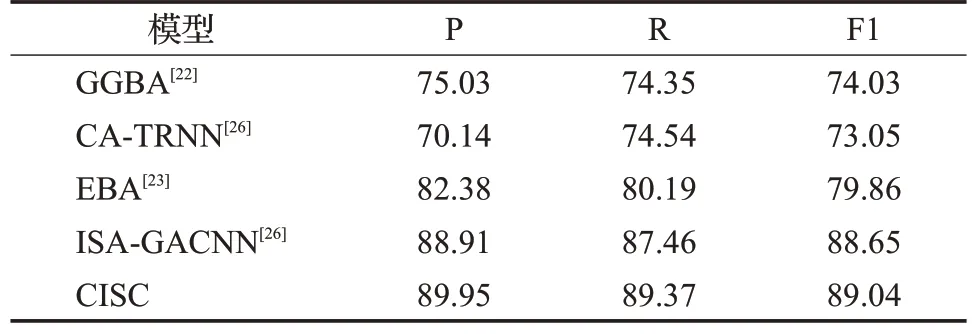
表8 在SMP-ECISA2019數(shù)據(jù)集上對比實驗結(jié)果Table 8 Results on SMP-ECISA2019 單位:%
從表8 中關(guān)于“SMP-ECISA2019 數(shù)據(jù)集”的實驗結(jié)果中可以得出以下結(jié)論:提出的模型在SMP-ECISA2019數(shù)據(jù)集上的F1 值達(dá)到89.04%,比ISA-GACNN 模型高出約0.39個百分點,P值提升了1.04個百分點,R值提高了1.91 個百分點。基于情感特征增強的中文隱式情感分類模型在P值、R值以及F1值上均有一定提升。對于隱式文本的情感分類準(zhǔn)確率得到提升的一個重要原因是本文提出的模型考慮了情感詞的引入,并利用層注意網(wǎng)絡(luò)生成情感特征增強的句子,充分考慮了待分析句子與不同情感詞的關(guān)聯(lián)度,深度挖掘了隱式文本的語義特征。
4.5 消融實驗
為驗證本文提出的基于情感特征增強的中隱式情感分類模型的有效性,進(jìn)行了消融實驗,實驗結(jié)果如表9所示。
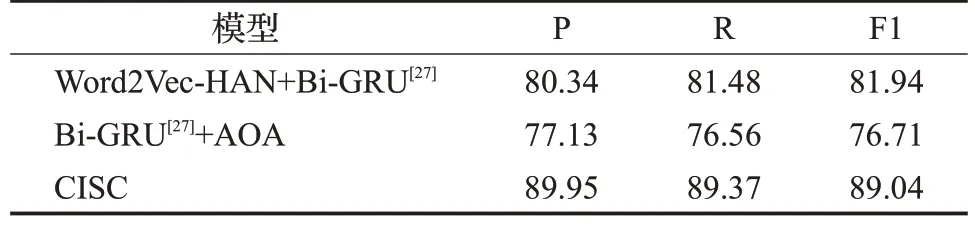
表9 消融實驗結(jié)果Table 9 Results of ablation experiment 單位:%
(1)Word2Vec-HAN+Bi-GRU。為了驗證交互注意力對于深入挖掘語義特征方面的影響,對比了在沒有交互注意力機制下的效果。從表9中可見,F(xiàn)1值與本文提出模型CISC相比降低了7.1個百分點,由此可以證明交互注意力在本文情感分類模型中的有效性。
(2)Bi-GRU+AOA。為了驗證層次注意力網(wǎng)絡(luò)對于隱式情感分類模型中情感特征增強的作用,本模型在使用Bi-GRU 的基礎(chǔ)上,只保留了AOA。從表9 中可見,F(xiàn)1值與本文提出模型CISC相比降低了12.33個百分點,由此可以證明構(gòu)建的情感特征增強的句子在本文提出模型CISC中的有效性。
上述實驗分析表明,本文所提的一種基于情感特征增強的中文隱式情感分類模型表現(xiàn)最佳。
5 總結(jié)與展望
為了更好地對隱式文本進(jìn)行分析處理,提高針對隱式情感文本進(jìn)行極性判斷的準(zhǔn)確率,了解人們的深層語義,本文提出了一種基于情感特征增強的中文隱式情感分類模型,將不同的情感詞分別引入到待處理句子中去,共同生成上下文語義,通過判斷兩個合成句子的情感極性,得出最終的情感極性,提高了對于隱式情感文本進(jìn)行分類的準(zhǔn)確率。
未來,針對本文提出的基于情感特征增強的中文隱式情感分類模型,將對分類效率進(jìn)行進(jìn)一步改進(jìn),推進(jìn)隱式情感文本的語義挖掘、特征提取等工作。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
